【微服务】Spring Boot集成ELK实用案例
推荐一款我一直在用国内很火的
AI网站,包含GPT3.5/4.0、文心一言、通义千问、智谱AI等多个AI模型,支持PC、APP、VScode插件同步使用,点击链接跳转->ChatGPT4.0中文版
一、前言
在现代软件开发中,微服务架构已成为一种流行趋势。随之而来的挑战之一是如何有效地管理和分析分布在各个服务中的日志数据。本文将深入探讨如何在Spring Boot中集成ELK栈,以实现集中日志管理的目标。
二、为什么需要ELK
随着微服务架构的普及,服务数量的增加导致日志数据分散在不同的服务器上,这使得日志管理变得复杂。ELK栈的引入能够帮助我们集中管理日志,提供实时监控,快速搜索以及日志分析的能力,从而提升系统的可维护性和可观察性。
三、ELK介绍
3.1 什么是ELK
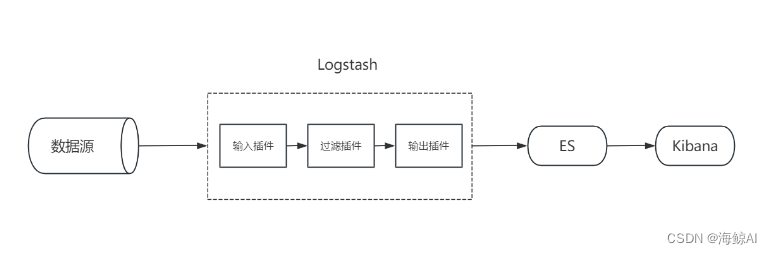
ELK是Elasticsearch、Logstash和Kibana的缩写。这三个组件协同工作,提供了一个强大的解决方案,用于日志的收集、存储、搜索和可视化。
3.2 ELK工作原理
ELK的工作原理基于以下流程:
- Logstash 处理来自不同源的日志数据,并将其转换成结构化的格式。
- Elasticsearch 作为搜索和分析引擎,存储和索引日志数据。
- Kibana 为用户提供了一个强大的前端界面,用于数据的搜索、展示和图形化分析。
四、ELK环境搭建
4.1 搭建Elasticsearch环境
4.1.1 获取Elasticsearch镜像
使用Docker可以轻松获取Elasticsearch镜像。
docker pull docker.elastic.co/elasticsearch/elasticsearch:7.9.3
4.1.2 启动Elasticsearch容器
使用Docker启动Elasticsearch容器,并映射必要的端口。
docker run -d --name elasticsearch -p 9200:9200 -p 9300:9300 elasticsearch:7.9.3
4.1.3 配置Elasticsearch参数
通过修改配置文件elasticsearch.yml,可以设置集群名称、节点名称等参数。
4.1.4 重启Elasticsearch容器并访问
重启容器以应用配置更改,并通过浏览器访问http://localhost:9200验证是否启动成功。
4.2 搭建Kibana
4.2.1 拉取Kibana镜像
docker pull docker.elastic.co/kibana/kibana:7.9.3
4.2.2 启动Kibana容器
docker run -d --name kibana --link elasticsearch:elasticsearch -p 5601:5601 kibana:7.9.3
4.2.3 修改配置文件
在kibana.yml中配置Elasticsearch的URL。
4.2.4 重启容器并访问
重启Kibana容器,并通过http://localhost:5601访问Kibana界面。
4.3 搭建Logstash
4.3.1 下载安装包
从官方网站下载Logstash的安装包。
wget https://artifacts.elastic.co/downloads/logstash/logstash-7.1.0.tar.gz
4.3.2 解压安装包
解压下载的安装包到指定目录。
tar -zxvf logstash-7.1.0.tar.gz
4.3.3 新增配置Logstash文件
创建Logstash配置文件,定义输入、过滤器和输出。
cd cd logstash-7.1.0/mkdir log-confvi logstash.confinput {tcp {mode => "server"host => "0.0.0.0"port => 4560codec => json}
}
output {elasticsearch {hosts => "es公网地址:9200"index => "springboot-logstash-%{+YYYY.MM.dd}"},stdout { codec => rubydebug }
}五、Spring Boot集成ELK
5.1 集成过程
5.1.1 创建Spring Boot工程
使用Spring Initializr或者你喜欢的IDE创建一个新的Spring Boot项目。选择Web、Actuator和其他你需要的依赖。
5.1.2 导入依赖
在pom.xml中添加以下依赖,以便集成ELK:
<dependencies><!-- Logstash logback encoder --><dependency><groupId>net.logstash.logback</groupId><artifactId>logstash-logback-encoder</artifactId><version>6.6</version></dependency><!-- 其他依赖 -->
</dependencies>
5.1.3 配置logback日志
创建或修改logback-spring.xml文件,配置Logback以使用Logstash encoder,并将日志发送到Logstash:
<configuration><appender name="LOGSTASH" class="net.logstash.logback.appender.LogstashTcpSocketAppender"><destination>localhost:5000</destination> <!-- Logstash的地址 --><encoder class="net.logstash.logback.encoder.LogstashEncoder" /></appender><root level="INFO"><appender-ref ref="LOGSTASH" /></root>
</configuration>
5.1.4 增加测试接口
在你的Spring Boot应用中增加一个简单的REST接口,用于生成日志:
@RestController
public class LoggingController {private static final Logger logger = LoggerFactory.getLogger(LoggingController.class);@GetMapping("/log")public String log() {logger.info("Log message from Spring Boot");return "Check the logs for a message";}
}
5.2 效果演示
5.2.1 启动服务工程
运行Spring Boot应用,并确保所有的ELK服务都已经启动并运行。
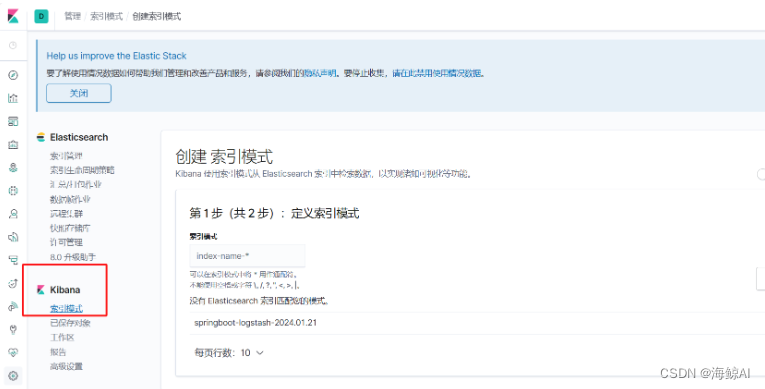
5.2.2 配置索引模式
在Kibana中创建一个索引模式,以便能够检索和查看Elasticsearch中的日志数据。
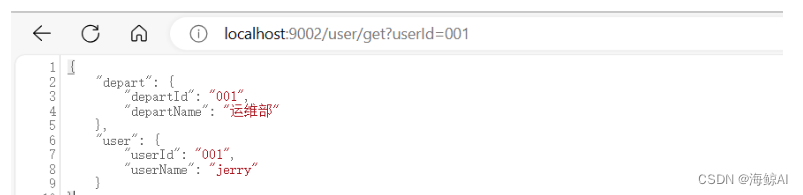
5.2.3 调用接口验证效果
通过调用之前创建的REST接口,生成日志。然后在Kibana中查看这些日志,验证集成是否成功。
5.3 ELK使用补充
在实际使用中,可能需要对ELK进行更多的配置,比如设置Logstash的过滤器来解析复杂的日志格式,或者在Kibana中创建复杂的仪表板来展示日志数据。
六、写在文末
通过本文的介绍,我们了解了如何在Spring Boot应用中集成ELK栈,从而实现高效的日志管理。ELK栈的强大功能能够帮助我们更好地理解和分析系统的运行情况,是微服务架构中不可或缺的工具之一。
集成ELK栈是一个涉及多个组件和配置的过程,可能会遇到各种问题。因此,耐心调试和仔细阅读文档是非常重要的。希望本文能够帮助你顺利完成集成,并且能够从中获得实际的价值。
相关文章:
【微服务】Spring Boot集成ELK实用案例
推荐一款我一直在用国内很火的AI网站,包含GPT3.5/4.0、文心一言、通义千问、智谱AI等多个AI模型,支持PC、APP、VScode插件同步使用,点击链接跳转->ChatGPT4.0中文版 一、前言 在现代软件开发中,微服务架构已成为一种流行趋势。…...

已解决: ImportError: cannot import name ‘relu‘ from ‘keras.layers‘ 问题
博主猫头虎的技术世界 🌟 欢迎来到猫头虎的博客 — 探索技术的无限可能! 专栏链接: 🔗 精选专栏: 《面试题大全》 — 面试准备的宝典!《IDEA开发秘籍》 — 提升你的IDEA技能!《100天精通鸿蒙》 …...
python-产品篇-火车票分析助手
文章目录 开发环境要求运行方法PyCarmVsCode 代码效果 开发环境要求 本系统的软件开发及运行环境具体如下。 (1)操作系统:操作系统:Windows 7、Windows 8、Windows 10。 (2)Python版本:Python …...

设计一个可以智能训练神经网络的流程
设计一个可以智能训练神经网络的流程,需要考虑以下几个关键步骤: 初始化参数:设定初始的batch size和learning rate,以及其他的神经网络参数。训练循环:开始训练过程,每次迭代更新网络的权重。监控loss:在每个训练周期(epoch)后,监控loss的变化情况。动态调整:根据l…...
:自然语言处理任务和应用程序)
自然语言处理(02/10):自然语言处理任务和应用程序
一、描述 在广阔的人工智能领域,自然语言处理 (NLP) 是一个迷人而充满活力的领域。NLP 弥合了计算机和人类语言之间的鸿沟,使机器能够理解、解释和生成类似人类的文本。这项变革性技术具有深远的影响,影响着我们日常生…...

Jmeter学习系列之三:测试计划详细介绍
目录 前言 步骤1:启动JMeter窗口 步骤2:添加/删除测试计划元素 步骤3:加载并保存测试计划元素。 步骤4:配置树元素 步骤5:保存JMeter测试计划 步骤6:运行JMeter测试计划...

mermaid使用指南+notion使用实例-持续更新中
最近一个月了吧,发现Notion插入图片的功能坏了,直接paste会404,本地上传也不行。电脑本地版和手机端都插不了图片,很头疼。解决方法也简单,用图床,放链接。 付费版我用的七牛,结合PicGo&#x…...

Pytroch 自写训练模板适合入门版 包含十五种经典的自己复现的一维模型 1D CNN
训练模板 在毕业之前,决定整理一下手头的代码,自己做1D-CNN这吗久,打算开源一下自己使用的1D-CNN的代码,包括用随机数生成一个模拟的数据集,到自己写的一个比较好的适合入门的基础训练模板,以及自己复现的…...

【30秒看懂大数据】变量
简单说 变量是指研究或观察中可能发生变化的事物、属性或特征,它们可以用来描述数据或现象的不同方面。 举例理解 一位热衷于烹饪的大厨老李,经常尝试不同的菜肴来满足不同顾客的口味。 1. 老李明白,每种食材都等同于一个重要的变量…...

Redis - 多集群数据源配置
目录 前言依赖yml配置redis多集群数据源配置类思考 redis工具类 前言 工作时有一个项目配置了多个redis数据源,使用时出现了指定了使用副数据源,数据却依然使用了主数据源的情况。经过排查,发现配置流程较为繁琐易错,此处做一个记…...

五大架构风格之四-虚拟机架构风格
虚拟机架构风格: 虚拟机架构风格是一种软件架构,它通过模拟完整的计算机系统(包括硬件)来运行程序。这种风格的核心是虚拟机监控器。如最出名的虚拟机VM,在使用虚拟机架构,一个或多个虚拟机可以在单一物理主…...

在 C# 中 checked 和 unchecked 关键字
在 C# 中,checked 和 unchecked 是用于控制整数运算溢出检查的关键字。它们允许我们明确指定在进行整数运算时是否要检查溢出,以及如何处理溢出情况。 默认情况下,C# 中的整数运算是未检查的,也就是说,当运算结果溢出…...
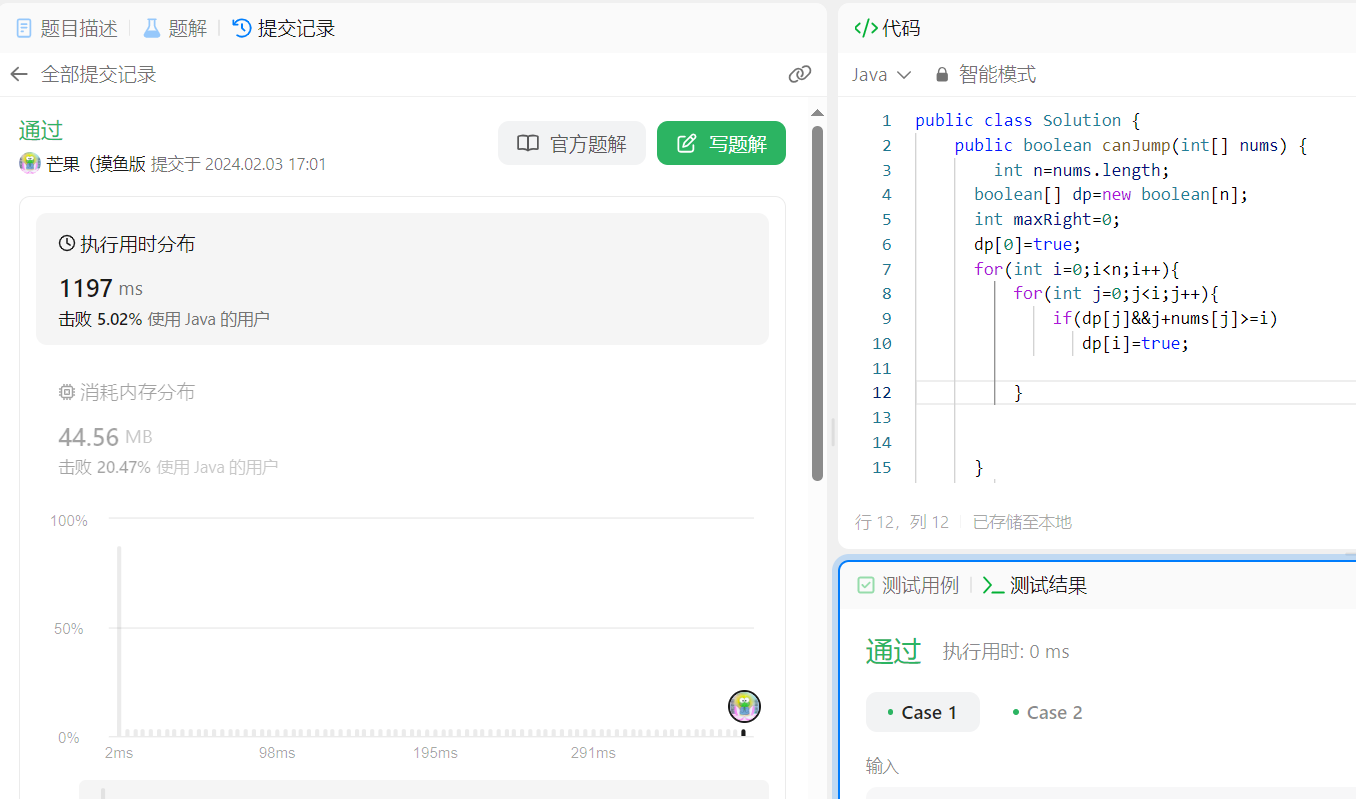
【算法分析与设计】跳跃游戏
📝个人主页:五敷有你 🔥系列专栏:算法分析与设计 ⛺️稳中求进,晒太阳 题目 给你一个非负整数数组 nums ,你最初位于数组的 第一个下标 。数组中的每个元素代表你在该位置可以跳跃的最大长度。 判断…...

openssl3.2 - helpdoc - P12证书操作
文章目录 openssl3.2 - helpdoc - P12证书操作概述笔记/doc/html/man1/CA.pl.htmlCA.pl -newcaCA.pl -newreqCA.pl -signCA.pl -pkcs12 "My Test Certificate"/doc/html/man1/openssl-pkcs12.html备注END openssl3.2 - helpdoc - P12证书操作 概述 D:\3rd_prj\cryp…...
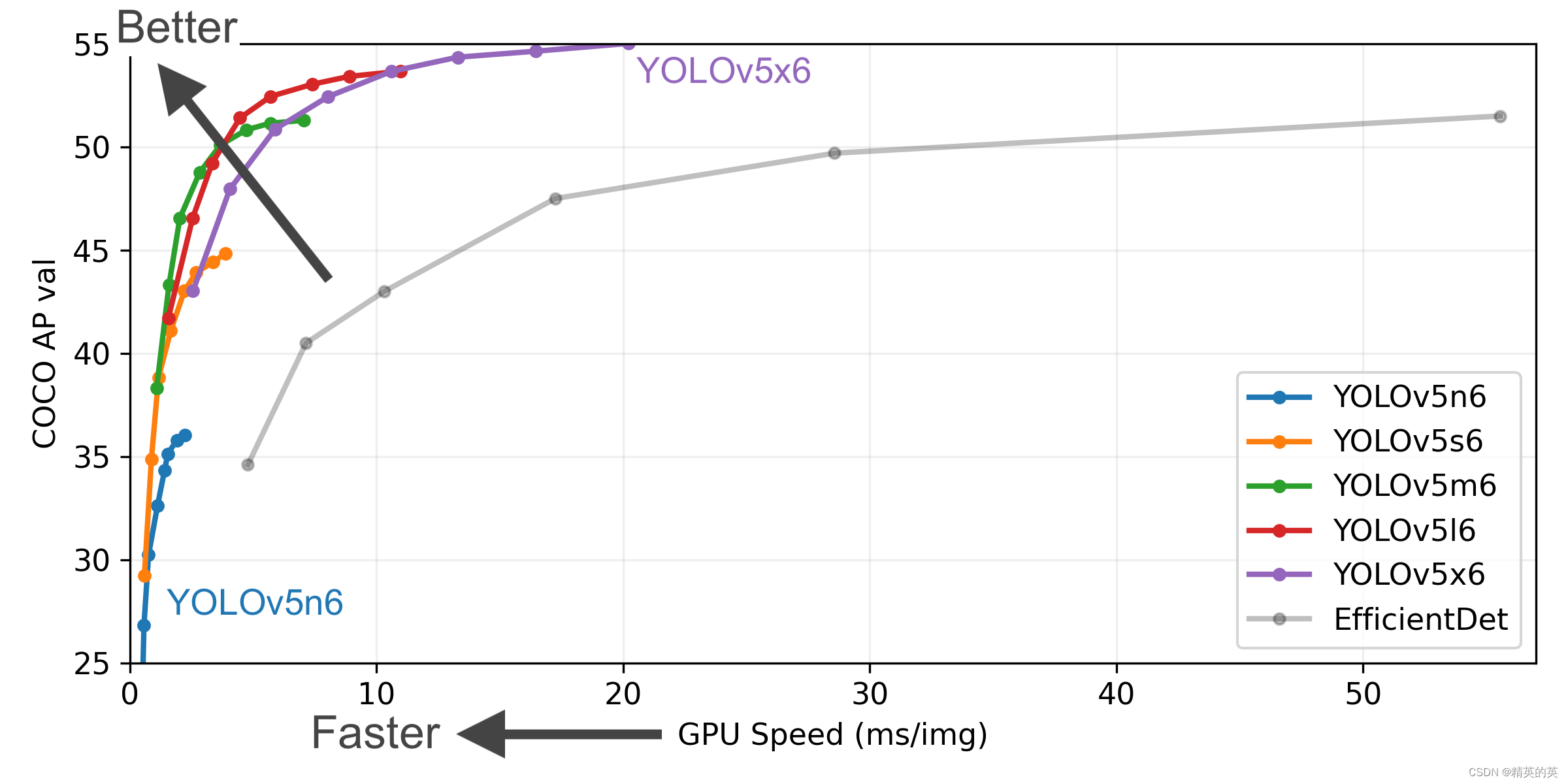
【产业实践】使用YOLO V5 训练自有数据集,并且在C# Winform上通过onnx模块进行预测全流程打通
使用YOLO V5 训练自有数据集,并且在C# Winform上通过onnx模块进行预测全流程打通 效果图 背景介绍 当谈到目标检测算法时,YOLO(You Only Look Once)系列算法是一个备受关注的领域。YOLO通过将目标检测任务转化为一个回归问题,实现了快速且准确的目标检测。以下是YOLO的基…...
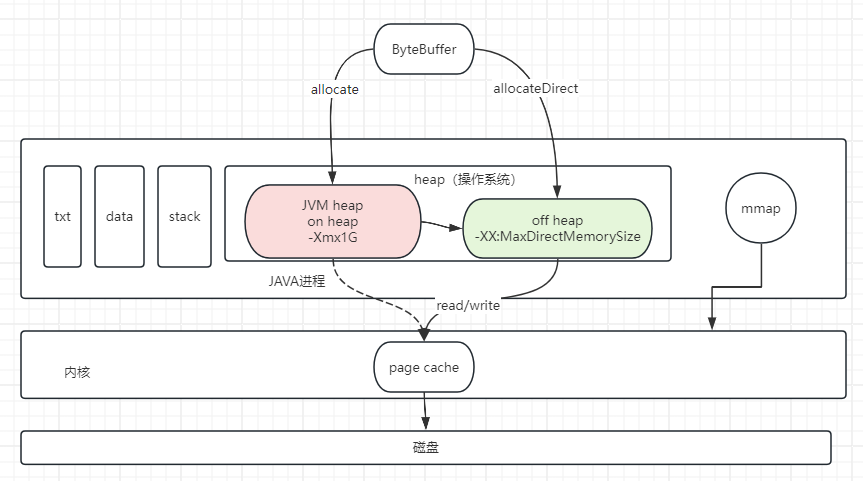
【操作系统】HeapByteBuffer和DirectByteBuffer的区别
DirectByteBuffer和HeapByteBuffer是Java NIO中ByteBuffer的两种实现方式。 HeapByteBuffer是在Java堆上分配的字节缓冲区,它使用数组来存储数据。HeapByteBuffer的优点是它具有良好的兼容性和可移植性,且在大多数情况下性能表现良好。它适用于大部分的…...

C++并发编程 -2.线程间共享数据
本章就以在C中进行安全的数据共享为主题。避免上述及其他潜在问题的发生的同时,将共享数据的优势发挥到最大。 一. 锁分类和使用 按照用途分为互斥、递归、读写、自旋、条件变量。本章节着重介绍前四种,条件变量后续章节单独介绍。 由于锁无法进行拷贝…...
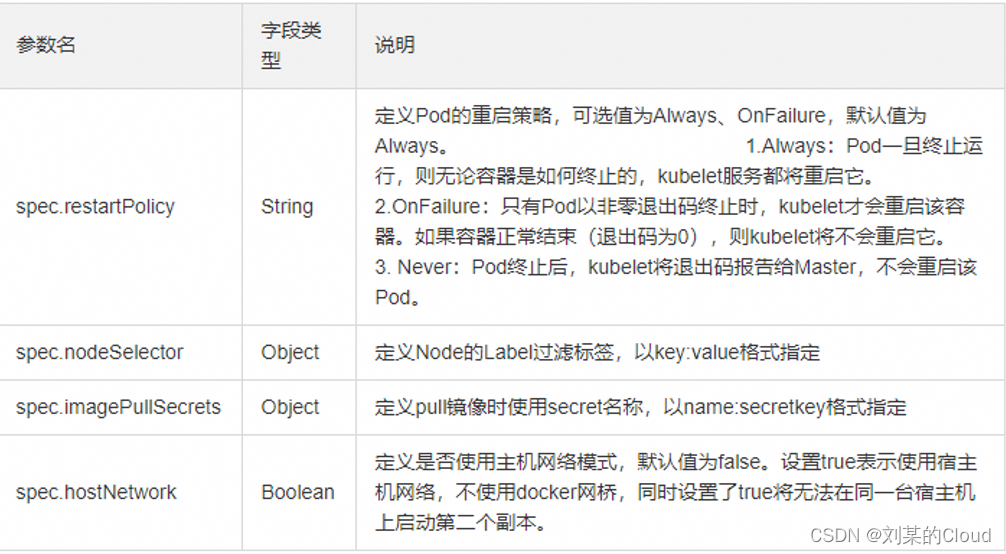
Kubernetes-资源清单
一、k8s中的资源 什么是资源清单 我们跟kubernetes集群进行交互的时候,我们需要给K8S集群传输数据,传输信息,K8S才能按照我们的要求来运行,这个传输的文件,基本上都会通过资源清单进行传递。资源清单是我们跟集群进行…...

ABAP 笔记--内表结构不一致,无法更新数据库MODIFY和UPDATE
目录 ABAP 笔记内表结构不一致,无法更新数据库MODIFY和UPDATE ABAP 笔记 内表结构不一致,无法更新数据库 MODIFY和UPDATE 如果是使用MODIFY或者UPDATE...
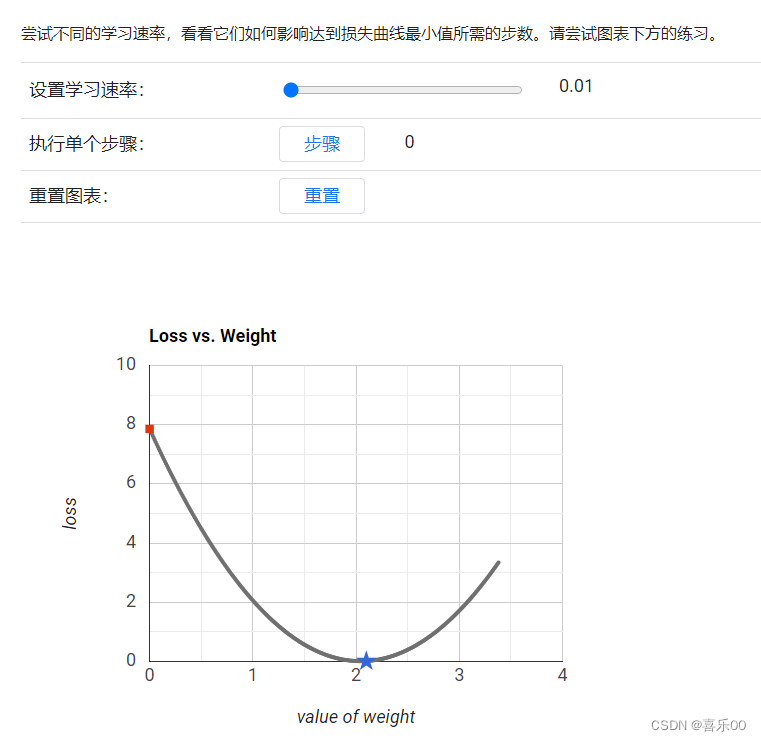
机器学习-3降低损失(Reducing Loss)
机器学习-3降低损失(Reducing Loss) 学习内容来自:谷歌ai学习 https://developers.google.cn/machine-learning/crash-course/framing/check-your-understanding?hlzh-cn 本文作为学习记录1.降低损失:迭代方法 迭代学习 下图展示了机器学习算法用于训…...

塞尔达存档定制工具:解锁海拉鲁冒险的无限可能
塞尔达存档定制工具:解锁海拉鲁冒险的无限可能 【免费下载链接】BOTW-Save-Editor-GUI A Work in Progress Save Editor for BOTW 项目地址: https://gitcode.com/gh_mirrors/bo/BOTW-Save-Editor-GUI 在海拉鲁大陆的冒险旅程中,每个玩家都曾面临…...
)
Flet实战:教你用Python把Todo应用打包成exe可执行文件(含界面美化技巧)
用Flet和Python打造专业级Todo应用:从开发到打包的完整指南 在当今快节奏的工作环境中,一个美观实用的Todo应用能显著提升个人效率。Python开发者现在有了一个强大的新选择——Flet框架,它让我们能够用纯Python构建跨平台的桌面应用…...

从俄罗斯电商数据到销量预测:Kaggle竞赛项目实战中的特征工程避坑指南
俄罗斯电商销量预测实战:特征工程中的7个关键陷阱与解决方案 在Kaggle的"Predict Future Sales"竞赛中,俄罗斯电商数据呈现出一系列独特挑战。本文将深入剖析特征工程环节中最易踩中的7个陷阱,并分享经过实战验证的解决方案。 1.…...
)
车载蓝牙只能打电话不能放音乐?教你排查A2DP协议支持问题(含车型适配清单)
车载蓝牙音乐播放失效?全面解析A2DP协议兼容性与实战修复指南 开车时想用蓝牙播放手机里的音乐,却发现只能接打电话?这种"半残"状态困扰着不少车主。问题的核心往往在于A2DP(高级音频分发协议)的支持与配置。…...

什么是KCP?QUIC?Websocket?
KCPKCP是一个基于UDP的可靠传输协议,其核心目标是在牺牲一定带宽利用率的前提下,尽可能降低传输延迟。它并非一个全新的传输层协议,而更像是在应用层对UDP数据包进行可靠性、顺序和流量控制的“增强外壳”。其底层具体来说就是在UDP的基础之上…...

火灾现场的无人机防御系统
2026年,XPrize参赛团队将继续角逐,力争防控灾害于萌芽阶段。在外行人眼中,眼前这架Alta X无人机要完成的似乎并不是一项特别复杂的任务。这架翼展超2米的黑色大型四旋翼无人机停在草坪上,起落架两个撑脚之间挂着一个注满水的红色气…...

智能座舱音频革命:如何用AVB交换机+TSN协议打造零延迟车载音响系统?
智能座舱音频革命:AVB交换机与TSN协议构建毫秒级同步音响系统 当你在驾驶舱内播放一首交响乐时,前排低音炮与后排高音单元的时差超过10毫秒,人耳就能感知声场撕裂——这种体验在传统车载音频架构中几乎无法避免。随着智能座舱向"第三生活…...

动态分区算法实战:首次适应与最佳适应的内存管理对比
1. 动态分区算法入门:内存管理的两大核心策略 想象你是一个仓库管理员,面对一堆大小不一的货物和不断变化的存取需求,如何高效利用有限空间?这就是操作系统内存管理要解决的核心问题。动态分区算法中的**首次适应(Firs…...

Applio实时语音处理揭秘:低延迟直播变声技术
Applio实时语音处理揭秘:低延迟直播变声技术 【免费下载链接】Applio A simple, high-quality voice conversion tool focused on ease of use and performance. 项目地址: https://gitcode.com/gh_mirrors/ap/Applio Applio是一款专注于易用性和高性能的实时…...

PCB圆弧拐角和45度拐角走线实操
目录 0 前言 1 PCB圆弧拐角实操 1.2参数设置,如上图所示 1.3筛选导线,如上图所示 1.4选中所有走线,如上图所示(按shift键框选) 1.5 45拐角变为圆弧拐角,如上图所示 1.6 优化前后对比图,如上图所示 2 PCB 45度拐角走线实操 2.1 进入设置,如上图所示 2.2 参数设…...