【Linux笔记】文件系统与软硬链接
一、文件系统概述
1.1、先来聊一聊“磁盘”
在讲解文件系统之前,我觉得有必要先聊一下“磁盘”,因为我觉得如果弄懂了磁盘的存储原理,大家可能更容易理解文件系统是怎么管理数据的,并且理解计算机是怎么将磁盘抽象到文件系统的。
当然,我们毕竟不是学硬件的,也不需要将磁盘弄得一清二楚,我们只需要搞懂它的大致存储原理即可。
1.1.1、磁盘的运动寻址原理
现在我们用的笔记本电脑已经不装磁盘了,现在的笔记本电脑用都是固态硬盘了。但是理解好磁盘还是能帮助我们更好的理解文件系统。
我们电脑中的磁盘一般都长这样:

没错,就是这个有点像关盘一样的方块,它就是我们电脑中用来存储数据的主要硬件,它的主要构成有两个:磁头和盘片。磁头就是上面图中有点像针尖一样的东西,盘片就是那个圆圆的铁片。
上面的图片可能角度不对,看到的好像就只有一个磁头和盘片,但是整个“磁盘方块”里面可不止一个磁头和盘片,而是有很多个磁头和盘片:

但弄懂磁盘的工作原理只需要弄懂一个磁盘和盘片是怎么工作的就行了,其他的磁头和盘片的工作原理也一定是相同的。
磁盘的工作原理:
磁盘的工作和存储主要是有磁头和盘片来完成的,是通过磁头在磁盘上“扫描”来定位磁盘上的任意位置传递信息存储数据的。
首先磁头是可以来回摆动的,并且盘片可以来回转动,通过磁头和盘片的来回运动,磁头就可以定位到盘片上的任意位置:

这其实就好比在盘片上建立了一个“直角坐标系”,磁头是来回在y轴上来会运动,而盘片的运动就好比在x轴上来会运动,这样这个坐标系内的所有角落都能被磁头所扫描到了:

那磁头的“寻址”究竟是在寻什么呢?
那就要把盘片拿出来好好聊一下了,站在使用磁盘的角度,盘片其实是由很多个“同心环”组成的;

这每一个环有一个名字叫做“磁道”,这就很像是我们现实生活中学校中的环形塑胶跑道。
而磁头的来回摆动其实就是在定位某一个磁道,而对于每一个环形的磁道,我们又可以将其分成很多份,而这每一份这是我们磁盘中的最小存储单元——扇区:

注意:“扇区”并不是上图中像一块三角形“披萨”的一整块区域,而是我上面专门标红色的那一块像一根短的“管子”的区域。
所以磁头和盘片的来回协同工作其实就是在定位磁盘中的最小存储单位——扇区,然后由磁头来传递信息存储数据,至于磁头到底是传递什么信息来存储数据的,我们不用关心,我们只需要知道磁头和盘片协同工作的目的是定位扇区就行了。
1.1.2、磁盘的存储逻辑抽象
那我们的文件系统难道要来控制磁头和盘片的运动来找到对应的扇区吗?
其实不是的,其实文件系统在上层并不关心什么扇区和磁头。
那文件系统是如何定位扇区的呢?
这就需要我们对磁盘进行再次的抽象了,我们上面说到的“磁道”其实我们也可以不把它想象成一个环,也可以把它想象成一个长方形或者是一个长长的带子,就有点像是以前的磁带:

然后我们再把一条条磁带连接成一条更长的磁带,就像下面这样:

所以,这不就是我们经常使用的数组吗?!所以在文件系统中其实并不用关心什么扇区和磁头磁道,只需要找到这个“数组”中的对应位置即可定位扇区,即找到对应的下标,至于真正找到对应的扇区的工作就交给磁盘这个硬件了。
所以对于一个盘片是这样,那对于其它盘片也一定是这样,无非就是上面的数组更长了些,磁盘硬件在寻址的时候多做一些工作比如找对应的磁头,找对应的盘面罢了。
1.2、将磁盘的逻辑再抽象到软件层
上面讲到的扇区是磁盘的最小存储单位,扇区的大小一般是512字节,但是对于文件系统来说,512字节还是太小了,所以在文件系统中最小的存储单位一般是8个扇区,这8个扇区就租成了一个“块”,文件系统的最小存储单位是“块”,一个扇区是512字节,那8个扇区就是4096字节,也就是4Kb,所以文件系统中的最小存储单位块的大小一般是4字节。

但是现在的磁盘一般都有几百GB的大小,大的有几TB大小,这么大的一块空间,如果文件文件系统想要整体管理起来也是压力很大的,所以分区的概念就出来了。
就像上面说的,我们将一个盘片管理好了,那其他的盘片的管理方法既可以照搬之前的盘片的管理方法。文件系统中的分区也是一样,我们只需要将一个分区管理好,那其他的分区也就可以照搬之前的分区的管理方法了。
例如现在有一个500GB的磁盘,那我们就可以将它分成4个分区,其中三个分区每个分区100GB,剩下一个分区是200GB:

这也就是我们平时用的电脑为什么会分出C盘、D盘、E盘、F盘……的原因,我们的电脑上虽然分出了C盘、D盘……但这却不是说明我们的电脑上有多个磁盘哦,这些C盘等等其实都只是“分区”,其实我们的电脑上至始至终都只有一个磁盘!
1.3、磁盘分区怎么管理?
虽然操作系统已经帮我们把整个磁盘分成了几个分区,但是对于一个分区来说,分区还是觉得让它直接来管理100GB到200GB的空间有点压力大,所以分区有将自己分成了好多个“组”,从此以后只要将一个组管理好了,那么分区中的剩下的组的管理方案就可以直接复用一个的管理方案了。
比如我们现在有一个100GB的分区,我们就可以将它分成2GB一组,总共分成50组:
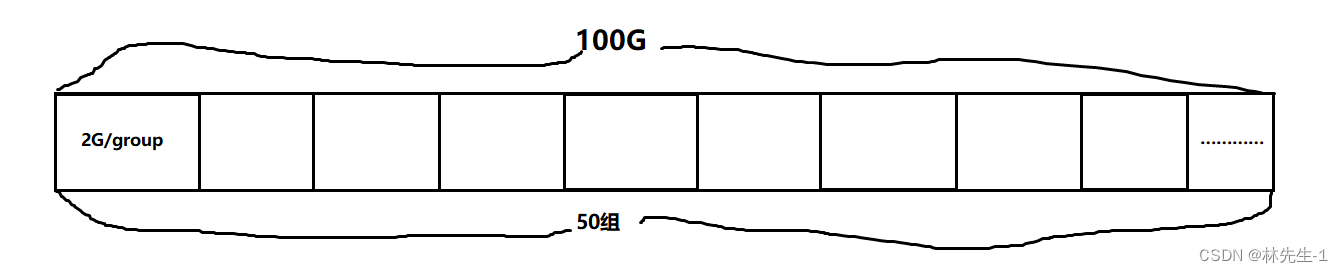
其实上面的一系列从磁盘到分区再从分区到分组,其实就是一种“大事化小、分而治之”的策略,也就是是分治算法的核心思想,所以由此可以看出,操作系统的设计也是有算法的支持的。
那么文件系统最重要做的就是对一个分组进行管理,既然要管理一个组,那么这个组内就一定要有很多管理信息。
一个组内的管理信息大致如下图所示:

所以接下来就是大致的介绍一些组内的各个管理信息模块具体是什么。
1.3.1、inode Table
在讲inode Table之前,我们必须先弄懂什么是inode?
ls指令是我们在shell中经常用到的指令,但是不知道大家有没有用过ls的一个选项-i?使用了这个选项之后,在我们下是的文件面前会比以前多出一列数据:
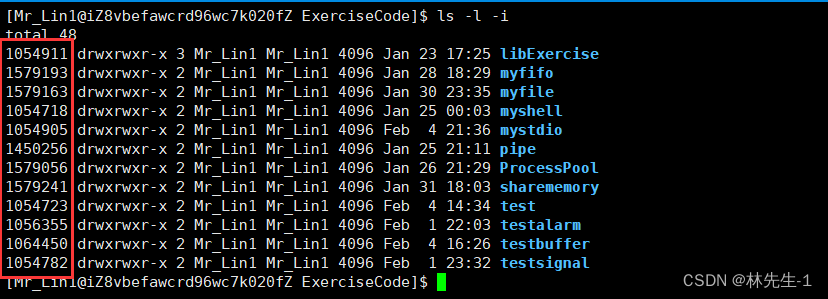
而这一列多出来的数据就是我们今天要讲的inode。
这一列数据我们以前好像从来没见过啊?事实上,这个inode我们不用见,而且见了也没用,因为只有操作系统有权利使用它。这个inode是操作系统识别一个文件的唯一标识,也就是说操作系统在识别文件的时候只和inode有关,与文件名及其他属性无关!
而这个inode本质上也是一个内核级的结构体,其结构体名称就叫做inode,这个结构体中有很多关于对应文件的属性,包括:大小、权限、所有者、所属组、ACM时间、inode编号等。我们上面查到的显示在文件最前列的其实只是这个结构体的inode编号,操作系统在识别一个文件的时候,其实也是根据这个inode编号来识别的。
而这个inode编号在分区内具有唯一性,跨分区就可能不唯一了,但这没问题因为操作系统在查找一个文件的时候会先确定在哪一个分区。
而在系统内会将文件路径和inode编号建立映射,之后用户在查找一个文件的时候,其实是系统先根据文件路径找到对应的inode编号,再由inode编号找到对应的文件,所以这也就解释了为什么同一个目录下不允许存在同名文件了,因为inode是可以保证唯一的,路径也是可以保证唯一的,而如果文件名在同一个目录下不保证唯一,那么在查找inode的时候就会存在歧义。
所以这个inodeTable就是用来存储该组中存储的所有文件对应的inode结构体,它的本质就是一个结构体数组。
而对应文件的内容其实是存储在Data blocks中的。
1.3.2、Data blocks
其实这个Data blocks才是整个组内的主要存储空间,其他的都是些辅助描述的模块,这个Data blocks里面就是一个个的数据快,即上面所说的有8个扇区组成的4kb大小的“块”:

而这个Data blocks实际上也相当于一个二维数组,所以想要在里面定位某一个块,也只需要找到对应的下标即可。
而inode既然是存储文件属性的结构体,那当然也要存储对应文件所在的块信息了,所以在inode结构体中有一个数组int blocks[N],里面就存储这inode所对应的文件的内容所在的块信息。
所以操作系统在打开一个文件的时候,只需要找到inode,再通过inode中的blocks数组找到文件内容所在的块,讲这些块中的数据加载到内存即可。
1.3.3、Block Bitmap和inode Bitmap
那一个组内肯定能存储很多个文件,所以也就会存在很多个inode,而且一个组内也一定会有很多个数据块,我们怎么知道某一个inode或某一个数据块是否被使用呢?
很显然我们现在只需要知道某一个niode或块是否被使用,而我们以前学过一个很高效的存储是或否的数据结构——位图。
所以Block Bitmap和inode Bitmap正如它们的名字一样是两个位图。
所以我们想要创建一个文件,就只需要分配一个未被使用过的inode编号,然后加载文件属性到inode结构体中,然后在分配一些未被使用过的数据块存储文件的内容。接着再将Block Bitmap和inode Bitmap中对应的比特位为由0置1即可。
而删除一个文件就简单了,我们只需要将Block Bitmap和inode Bitmap中对应的比特位由1置0即可,不需要将对应的inode结构体和数据块内的数据全部清空,因为后面再有新的文件创建的时候这些数据是可以被覆盖的。
1.3.4、super block
而这个super block则存放的是文件系统本身的信息。记录的主要信息有:block和inode的总量,未被使用的block和inode的数量,一个block和inode的大小,最近一次挂载的时间,最近一次写入数据的时间等等等等……
这个super block也是相当重要的,因为它存储的是管理文件系统本身的结构信息,所以若是super block被损坏了,那么整个文件系统也就被破坏了,而文件系统损坏了,电脑也肯定会出很多的问题,也有可能会直接报废了。
正是因为super block如此重要,我们的文件系统就为我们多创建了几份super block的拷贝,放在不同的块组中,一旦有一个super block损坏了,文件系统就会通过备份的super block来自动修复。
1.4、文件系统与用户层的联系
那么文件系统又是怎么和用户层进行联系的呢?或者说我们平时看到的文件名、目录、普通文件的本质是什么呢?
先来看看目录,我们可以试着用vim来打开一个目录文件:
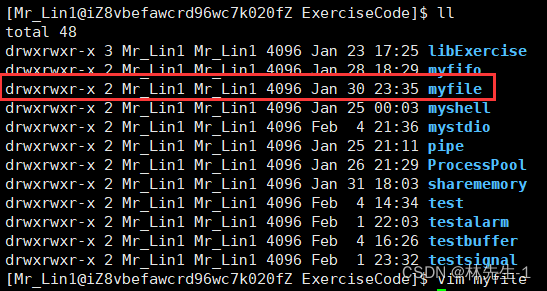
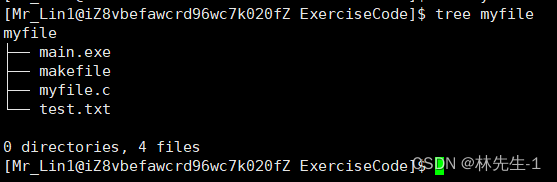

我们发现一个目录文件也是可以用vim打开的,而这个目录文件里面好像写的就是该目录的路径和目录中所有文件的文件名和一个上级目录..
而我们知道Linux的文件结构其实就是一颗多叉树的结构:
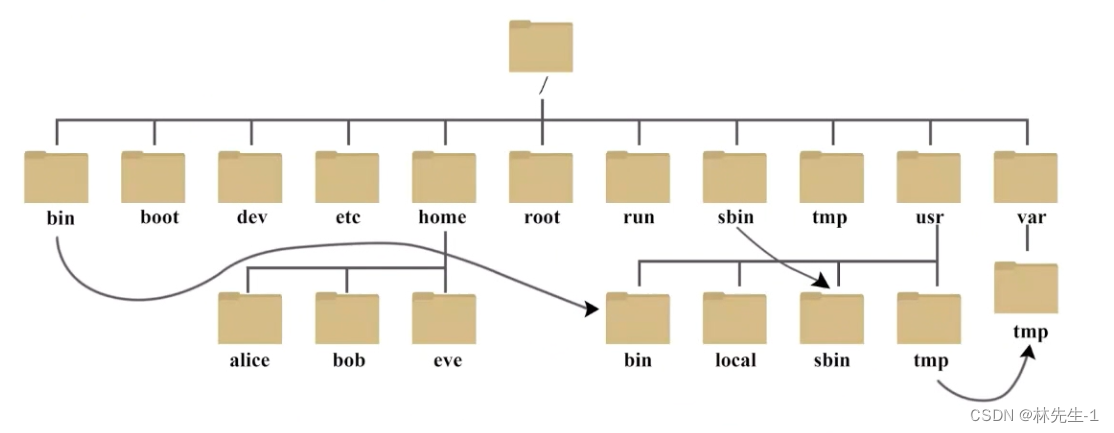
而一个目录,在这颗多叉树中我们可以理解成一个父节点,一个普通文件我们可以理解成一个叶结点。
所以也就注定了文件系统在查找一个文件的时候,遇到目录一再要向下寻找,而我们说过操作系统在识别一个文件的时候只认inode,所以目录中的文件名一定就要有与对应的inode的映射关系。
所以目录中的内容就是保存着目录中所有文件的包括自身的文件名和inode的映射关系!而一个普通文件(我们在用户层看到的)就只是一个文件名和inode的映射。
或者说我们看到的只是一个key值,因为inode和文件名可以说是一个互为键值的关系。
二、硬连接与软连接
2.1、什么是硬连接与软连接
硬连接和软连接其实和他们的名字一样,只是起到了一个“链接”作用而已。
先来看软连接:
如果我们想要在系统中创建一个软连接,可以用ln -s指令:

然后我们可以像使用原test.txt文件一样使用test.soft,对它们两个其中任意一个的任何操作都是一样的:
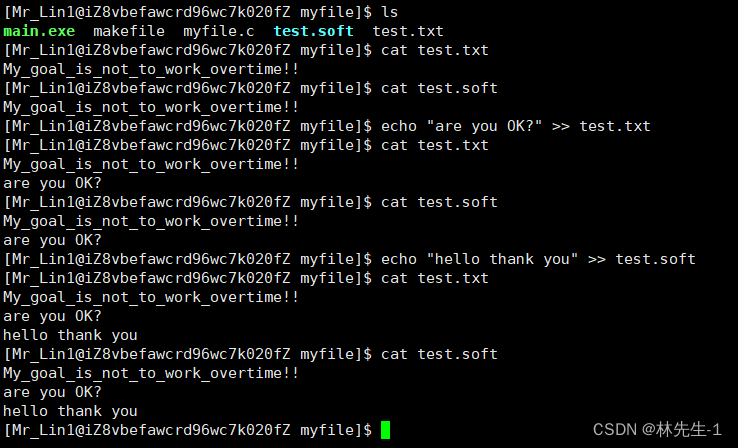
我们可以看到,对于它们两个中任意一个写入,两个文件中的内容都是一致的,那这是不是说明他们两个是同一个文件呢?
根据我们上面所说的,我们也应该知道每一个文件都有一个唯一的inode,所以我们只需要看看这两个文件的inode是否相同即可:

而结果是这两个文件的inode并不相同,所以它们并不是同一个文件,也就是说软连接是一个独立的文件。
那为什么它们的数据会同步呢?
其实大家根据这里的同步效果,可能已经想到了我们windows中的一个类似的链接方式——快捷方式:

事实上,Linux中的这个软连接就相当于windows中的快捷方式,而为什么要有这样的快捷方式其实也很好理解,有些时候我们的程序可能藏的比较深,我们想要访问到它可能需要打开很多的文件夹去寻找,这时候我们就可以在我们的桌面创建一个这样的快捷方式,这样我们以后想访问这个程序就直接打开我们桌面的这个快捷方式即可。
那我们应该怎样理解这个软连接呢?它是怎么做到帮我们快速连接一个文件的呢?
其实很简单,就如我们上面所说的系统在查找一个文件的本质其实就是通过文件的路径去找到对应的inode,所以我们想要找到一个文件就只需要找到这个文件所在的路径即可,所以软连接中存储的其实就是目标文件的路径!
这个其实在windows中就能很好的看出来:
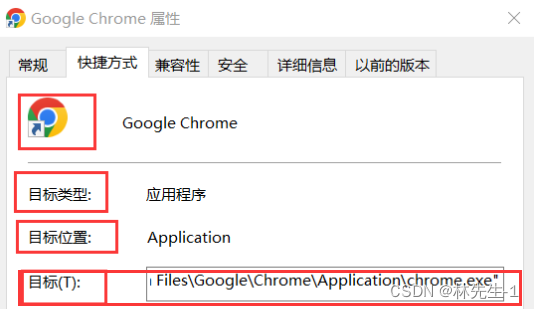
所以结论就是:软连接就是一个独立的普通文件,而这个普通文件中存储的就是目标文件对应的路径,系统在通过软连接打开目标文件时,其实是通过软连接文件中存储的路径去访问对应的目标文件的。
那么什么又是硬链接呢?
如果我们想要在系统中创建一个硬链接,可以使用ln指令:
 、
、
而硬链接和软连接一样,信息也是同步的:

那它们俩是不是同一个文件呢?我们看一看他们的inode就知道了:
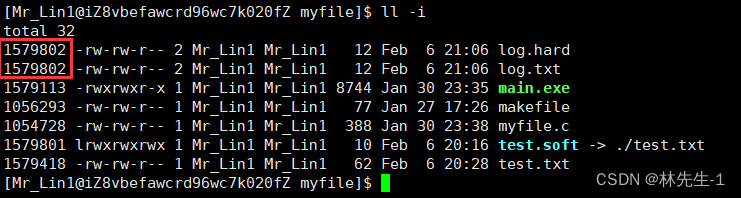
从结果中我们会惊奇的发现,目标文件和硬连接文件的inode竟然是相同的,那这不就说明了它们两个是同一个文件了吗?
严格来说,一个链接并不是一个文件,它只是一个指定目录下的一组文件名和inode的映射关系。
因为操作系统不会做任何浪费时间或空间的事情,如果一个文件和另一个文件完全相同,操作系统是不会为我们多创建一个的!
为什么能这么说呢?怎么证明呢?
我们先来看一个现象,如果我们现在将目标文件log.txt删除会发生什么:

我们会发现硬链接并没有被删除,而且上面的这个圈出来的这个数字由2变成了1,而这个数字就是一个“引用计数”,这个引用计数其实就表示的是当今有多少个文件名与该inode进行映射。
所以结论是:硬链接并不是一个独立的文件,它只是一个文件名与inode的映射关系。
2.2、每个目录中的默认的硬连接
上面说到引用计数表示的是,有多少个文件名与一个inode有映射关系,但是不知道大家是否发现一个奇怪的现象,就是如果我们新建一个空目录,它的引用计数默认是2:

这是因为我们创建的新目录它里面并不完全是空的,每一个新的目录中都有一个隐藏的"."表示当前目录:

而这个.其实就是操作系统为每一个目录创建的一个默认的硬链接,我们通过观察它们的inode就可以看出:
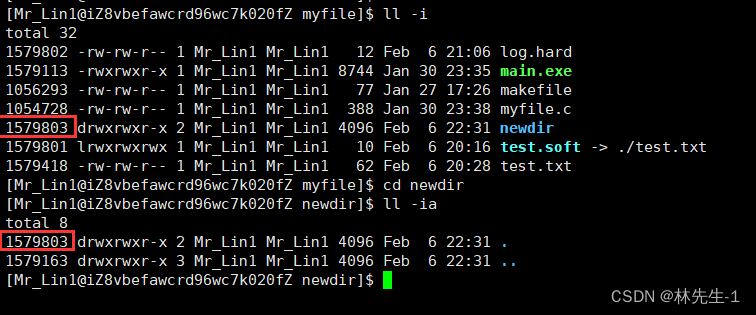
那同理的,每一个目录中也有一个.. 表示上级目录,所以接下来的现象也就不奇怪了:

我们在newdir里面新建了一个newnewdir之后,newdir的引用计数就变成了三,这是因为newnewdir里面有一个..的硬链接指向了newdir:
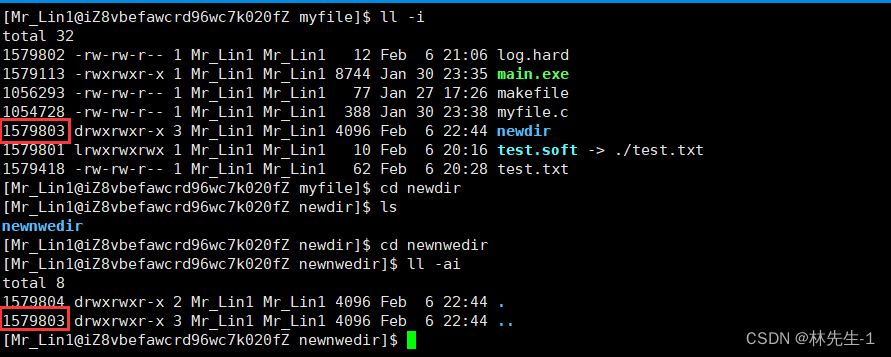
所以我们现在也就明白了,其实我们以前刚开始学到的.和..其实是两个硬链接啊。
相关文章:
【Linux笔记】文件系统与软硬链接
一、文件系统概述 1.1、先来聊一聊“磁盘” 在讲解文件系统之前,我觉得有必要先聊一下“磁盘”,因为我觉得如果弄懂了磁盘的存储原理,大家可能更容易理解文件系统是怎么管理数据的,并且理解计算机是怎么将磁盘抽象到文件系统的。…...
vue3(笔记)
组合式Api setup-----相当于beforeCreate, create生命周期 reactive–定义状态 对象形式 响应式原理 toRefs— Pinia (只有state、getters和actions) 更加简洁的语法,完美支持Vue3的Composition api 和 对TypesCcript的完美支持...
Java面向对象 this
this 在Java中,this 是一个特殊的引用变量,它引用了当前对象实例。当在类的非静态方法或构造方法中使用时,this 关键字指代当前的对象实例。它经常用于区分对象的成员变量和局部变量,或者调用其他重载的方法。 以下是一些使用 t…...

阿里云游戏服务器租用价格表,2024最新报价
阿里云游戏服务器租用价格表:4核16G服务器26元1个月、146元半年,游戏专业服务器8核32G配置90元一个月、271元3个月,阿里云服务器网aliyunfuwuqi.com分享阿里云游戏专用服务器详细配置和精准报价: 阿里云游戏服务器租用价格表 阿…...

2-1 动手学深度学习v2-Softmax回归-笔记
回归 VS 分类 回归估计一个连续值分类预测一个离散类别 从回归到多类分类 回归 单连续数值输出输出的区间:自然区间 R \mathbb{R} R损失:跟真实值的区别 分类 通常多个输出(这个输出的个数是等于类别的个数)输出的第 i i i…...
laravel distinct查询问题,laravel子查询写法
直接调用后,count查询会和实际查询的数据对不上,count还是查询全部数据,而实际的列表是去重的。 给distinct加上参数,比如去重的值的id,就加id。 另一种写法是使用group by id 子查询。 sql语句: selec…...
AI助力农作物自动采摘,基于DETR(DEtection TRansformer)开发构建作物生产场景下番茄采摘检测计数分析系统
去年十一那会无意间刷到一个视频展示的就是德国机械收割机非常高效自动化地24小时不间断地在超广阔的土地上采摘各种作物,专家设计出来了很多用于采摘不同农作物的大型机械,看着非常震撼,但是我们国内农业的发展还是相对比较滞后的࿰…...

C语言——字符串大小写互换
前言: 在C语言中,大小写字母相互转换是一个常见的操作。本文将详细介绍C语言中实现大小写字母相互转换的各种方法,并附上代码示例。 目录 一、使用tolower()和toupper()函数 二、使用位操作 三、使用字符串操作函数 一、使用tolower()和t…...

macOS的设置与常用软件(含IntelliJ IDEA 2023.3.2 Ultimate安装,SIP的关闭与开启)
目录 1 系统设置1.1 触控板1.2 键盘 2 软件篇2.1 [科学上网](https://justmysocks5.net/members/)2.1 [安装Chrome浏览器](https://www.google.cn/chrome/index.html)2.2 [安装utools](https://www.u.tools)2.3 [安装搜狗输入法](https://shurufa.sogou.com/)2.4 [安装snipaste…...
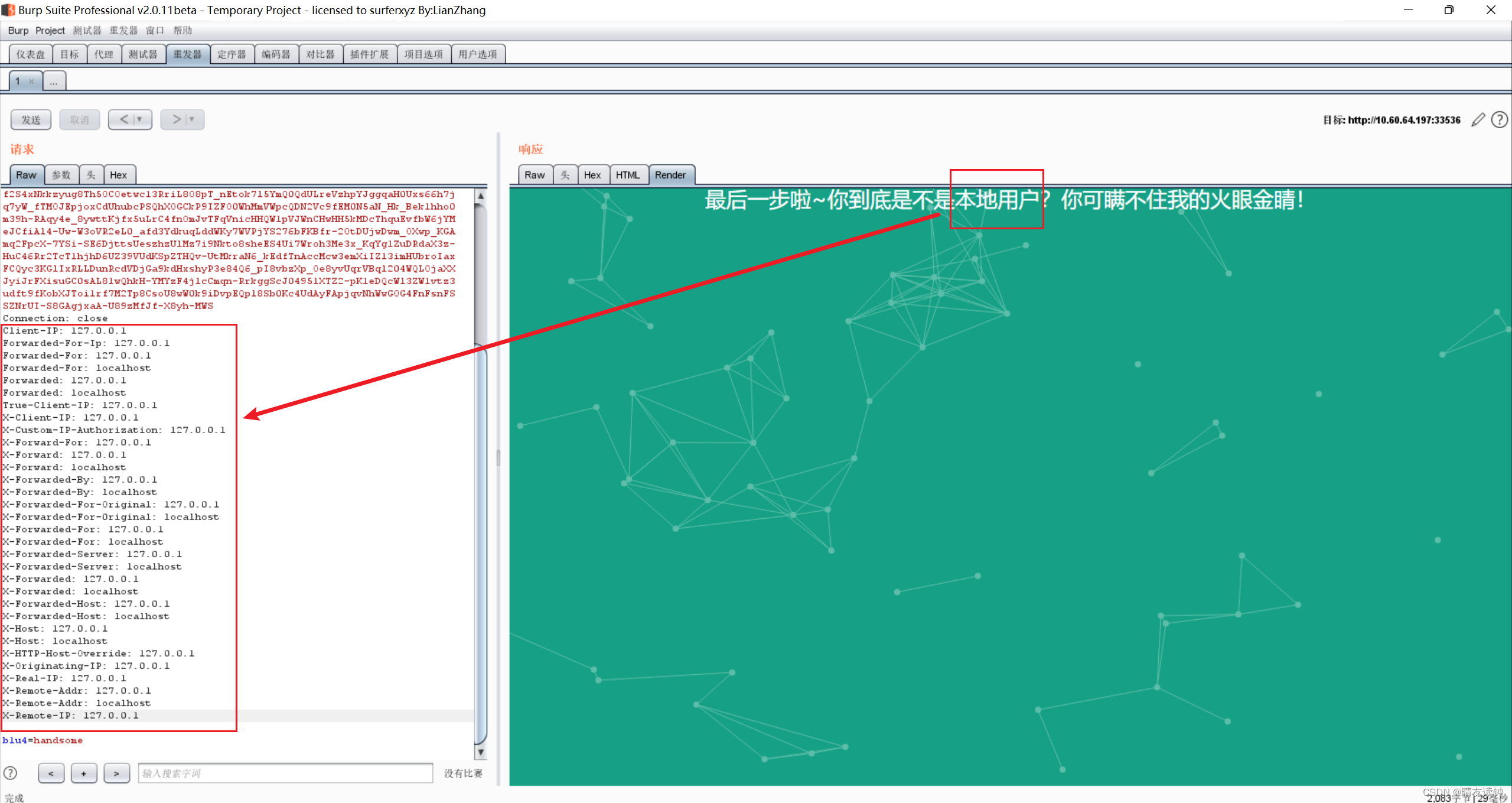
http伪造本地用户字段系列总结
本篇记录了http伪造本地用户的多条字段,便于快速解决题目 用法举例: 直接把伪造本地用户的多个字段复制到请求头中,光速解决部分字段被过滤的问题。 Client-IP: 127.0.0.1 Forwarded-For-Ip: 127.0.0.1 Forwarded-For: 127.0.0.1 Forwarded…...
Hadoop-IDEA开发平台搭建
1.安装下载Hadoop文件 1)hadoop-3.3.5 将下载的文件保存到英文路径下,名称一定要短。否则容易出问题; 2)解压下载下来的文件,配置环境变量 3)我的电脑-属性-高级设置-环境变量 4.详细配置文件如下&#…...

block任务块、rescue和always、loop循环、role角色概述、role角色应用、ansible-vault、sudo提权、特殊的主机清单变量
任务块 可以通过block关键字,将多个任务组合到一起可以将整个block任务组,一起控制是否要执行 # 如果webservers组中的主机系统发行版是Rocky,则安装并启动nginx[rootpubserver ansible]# vim block1.yml---- name: block taskshosts: webse…...
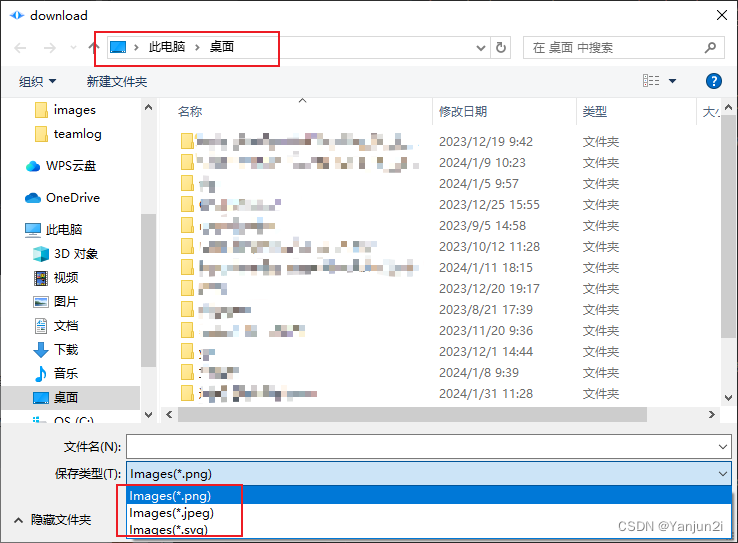
Qt:QFileDialog
目录 一、介绍 二、功能 三、具体事例 1、将某个界面保存为图片,后缀名可选PNG、JPEG、SVG等 一、介绍 QFileDialog提供了一个对话框,允许用户选择文件或者目录,也允许用户遍历文件系统,用以选择一个或多个文件或者目录。 QF…...

我的QQ编程学习群
欢迎大家加入我的QQ编程学习群。 群号:950365002 群里面有许多的大学生大佬,有编程上的疑惑可以随时问,也可以聊一些休闲的东西。 热烈欢迎大家加入!! 上限:150人。...

【C++】类与对象(四)——初始化列表|explicit关键字|static成员|友元|匿名对象
前言: 初始化列表,explicit关键字,static成员,友元,匿名对象 文章目录 一、构造函数的初始化列表1.1 构造函数体内赋值1.2 初始化列表 二、explicit关键字三、static成员四、友元4.1 友元函数4.2 友元类 五、内部类六、…...
ChatGPT高效提问—prompt常见用法
ChatGPT高效提问—prompt常见用法 1.1 角色扮演 prompt最为常见的用法是ChatGPT进行角色扮演。通常我们在和ChatGPT对话时,最常用的方式是一问一答,把ChatGPT当作一个单纯的“陪聊者”。而当我们通过prompt为ChatGPT赋予角色属性后,即使…...
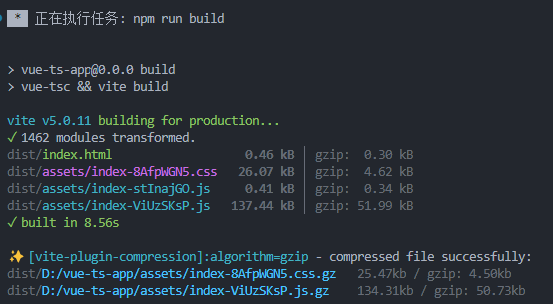
使用vite创建vue+ts项目,整合常用插件(scss、vue-router、pinia、axios等)和配置
一、检查node版本 指令:node -v 为什么要检查node版本? Vite 需要 Node.js 版本 18,20。然而,有些模板需要依赖更高的 Node 版本才能正常运行,当你的包管理器发出警告时,请注意升级你的 Node 版本。 二、创…...
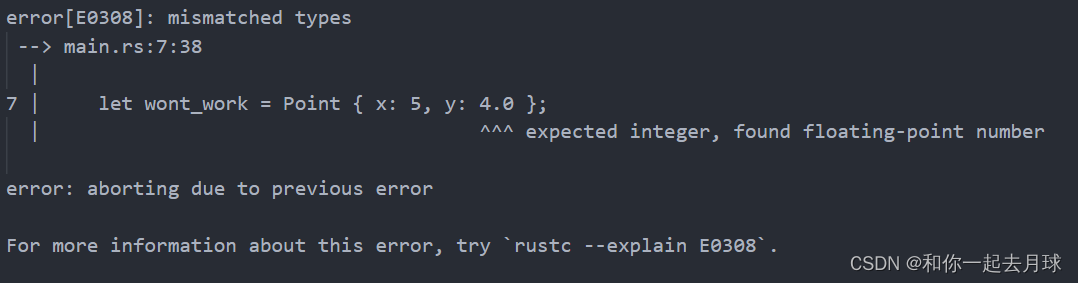
泛型、Trait 和生命周期(上)
目录 1、提取函数来减少重复 2、在函数定义中使用泛型 3、结构体定义中的泛型 4、枚举定义中的泛型 5、方法定义中的泛型 6、泛型代码的性能 每一门编程语言都有高效处理重复概念的工具。在 Rust 中其工具之一就是 泛型(generics)。泛型是具体类型…...

<网络安全>《18 数据安全交换系统》
1 概念 企业为了保护核心数据安全,都会采取一些措施,比如做网络隔离划分,分成了不同的安全级别网络,或者安全域,接下来就是需要建设跨网络、跨安全域的安全数据交换系统,将安全保障与数据交换功能有机整合…...
Kafka 生产调优
Kafka生产调优 文章目录 Kafka生产调优一、Kafka 硬件配置选择场景说明服务器台数选择磁盘选择内存选择CPU选择 二、Kafka Broker调优Broker 核心参数配置服役新节点/退役旧节点增加副本因子调整分区副本存储 三、Kafka 生产者调优生产者如何提高吞吐量数据可靠性数据去重数据乱…...

Qwen2.5-32B-Instruct开发指南:vscode安装与插件配置
Qwen2.5-32B-Instruct开发指南:vscode安装与插件配置 1. 引言 如果你正准备开始使用Qwen2.5-32B-Instruct这个强大的AI模型进行开发,那么一个高效的编程环境就是你的第一站。作为阿里云推出的320亿参数指令微调模型,Qwen2.5-32B-Instruct在…...

科哥IndexTTS2 V23应用案例:虚拟主播语音定制,情感控制更强
科哥IndexTTS2 V23应用案例:虚拟主播语音定制,情感控制更强 1. 引言:虚拟主播语音定制的新标杆 在虚拟主播行业蓬勃发展的今天,语音表现力已成为决定用户体验的关键因素。传统语音合成系统往往只能提供机械化的朗读效果…...

宝藏分享!实用AI写教材工具,快速产出低查重专业教材!
AI写教材工具:提升创作效率的利器 在撰写教材的过程中,总会遇到一种令人沮丧的“慢节奏”。尽管框架与资料已经准备就绪,内容创作却常常陷入困境:一句话反复推敲数十分钟,还是觉得表达不够完美;章节间的衔…...

计算机网络知识应用:保障分布式StructBERT微服务集群通信
计算机网络知识应用:保障分布式StructBERT微服务集群通信 最近在搞一个基于StructBERT模型的智能问答系统,随着用户量上来,单台服务器明显扛不住了,响应慢不说,还动不动就挂掉。没办法,只能上微服务集群&a…...

突破学术写作瓶颈:WPS-Zotero革新文献管理工作流
突破学术写作瓶颈:WPS-Zotero革新文献管理工作流 【免费下载链接】WPS-Zotero An add-on for WPS Writer to integrate with Zotero. 项目地址: https://gitcode.com/gh_mirrors/wp/WPS-Zotero 在学术写作的征途上,文献管理如同隐形的绊脚石&…...

零基础上手!基于vLLM的GLM-4-9B-Chat-1M模型保姆级部署指南
零基础上手!基于vLLM的GLM-4-9B-Chat-1M模型保姆级部署指南 1. 模型简介与核心优势 GLM-4-9B-Chat-1M是智谱AI推出的最新一代开源对话模型,基于vLLM框架部署,支持惊人的1M上下文长度(约200万中文字符)。这个模型在多…...

Windows下OpenClaw安装详解:GLM-4.7-Flash模型联调全流程
Windows下OpenClaw安装详解:GLM-4.7-Flash模型联调全流程 1. 为什么选择OpenClawGLM-4.7-Flash组合 去年我在处理个人知识管理时,发现每天要重复执行大量机械操作:整理网页摘录、归类PDF文档、生成日报摘要。尝试过各种自动化工具后&#x…...

Kubernetes 自动扩缩容最佳实践
Kubernetes 自动扩缩容最佳实践 一、前言 哥们,别整那些花里胡哨的。Kubernetes 自动扩缩容是保证应用高可用和成本优化的关键,今天直接上硬货,教你如何配置和优化自动扩缩容。 二、扩缩容类型对比 类型适用场景优势劣势HPA水平扩缩容响应…...

DeepSeek-R1-Distill-Qwen-7B效果展示:复杂问题推理实测
DeepSeek-R1-Distill-Qwen-7B效果展示:复杂问题推理实测 1. 模型能力概览 DeepSeek-R1-Distill-Qwen-7B是DeepSeek团队基于Qwen架构开发的7B参数推理模型,通过强化学习训练和知识蒸馏技术优化,在数学推理、代码生成和逻辑分析任务上展现出卓…...

GME-Qwen2-VL-2B-Instruct部署详解:CUDA版本兼容性与FP16加载验证
GME-Qwen2-VL-2B-Instruct部署详解:CUDA版本兼容性与FP16加载验证 1. 项目概述 GME-Qwen2-VL-2B-Instruct是一个专为图文匹配度计算优化的多模态模型工具。它解决了原生调用中常见的打分不准问题,通过本地化部署实现了高效、安全的图文检索功能。 1.1…...