政安晨:示例演绎TensorFlow的官方指南(二){Estimator}
咱们接着演绎TensorFlow官方指南,我的这个系列的上一篇文章为:
政安晨:示例演绎TensorFlow的官方指南(一){基础知识}![]() https://blog.csdn.net/snowdenkeke/article/details/136067030为什么要演绎官方指南,我在上一篇说过了,这次没有废话,直接开始。
https://blog.csdn.net/snowdenkeke/article/details/136067030为什么要演绎官方指南,我在上一篇说过了,这次没有废话,直接开始。
Estimator介绍

政安晨:
咱们先看一下Estimator的背景。
TensorFlow的Estimator API是一种高级的机器学习API,用于简化模型的训练、评估和推理过程。它提供了一种更加高层次的抽象,使开发者能够更加专注于模型的架构和数据流水线的设计,而不需要太多地关注底层的实现细节。
Estimator API提供了一套统一的接口,可以用于各种机器学习任务,如分类、回归、聚类等。它具有以下几个主要特点:
-
封装了模型的训练、评估和推理过程,提供了一种简单且一致的方式来组织代码和配置模型。
-
支持分布式训练,可以轻松地在多个GPU或多台机器上进行训练,以加速模型的训练过程。
-
提供了一系列内置的模型,如线性模型、DNN模型、CNN模型等,可以根据任务的需求快速构建模型。
-
可以使用预定义的特征列(feature columns)来处理和预处理输入数据,简化了数据准备的过程。
-
可以使用高层的tf.data.Dataset API来读取和处理数据,使数据加载和预处理过程更加灵活和高效。
使用Estimator API时,需要定义一个Estimator对象,这个对象包含了模型的结构和参数。然后,通过调用Estimator对象的train()方法来训练模型,evaluate()方法来评估模型,predict()方法来进行预测。在训练模型时,可以通过tf.estimator.TrainSpec对象来指定训练数据的路径和其他相关参数。在评估模型时,可以通过tf.estimator.EvalSpec对象来指定评估数据的路径和其他相关参数。
总之,Estimator API提供了一种简单、灵活且高效的方式来构建、训练和评估机器学习模型,使开发者能够更加专注于模型的设计和业务逻辑。
这篇官方文档介绍了 tf.estimator,它是一种高级 TensorFlow API。Estimator 封装了以下操作:
- 训练
- 评估
- 预测
- 导出以供使用
您可以使用我们提供的预制 Estimator 或编写您自己的自定义 Estimator。所有 Estimator(无论是预制还是自定义)都是基于 tf.estimator.Estimator 类的类。
有关 API 设计概述,请参阅白皮书。
优势
与 tf.keras.Model 类似,estimator 是模型级别的抽象。tf.estimator 提供了一些目前仍在为 tf.keras 开发中的功能。包括:
- 基于参数服务器的训练
- 完整的 TFX 集成
政安晨:
为了后面的演绎,我们先设置一下环境:
Estimator 功能
Estimator 提供了以下优势:
- 您可以在本地主机上或分布式多服务器环境中运行基于 Estimator 的模型,而无需更改模型。此外,您还可以在 CPU、GPU 或 TPU 上运行基于 Estimator 的模型,而无需重新编码模型。
- Estimator 提供了安全的分布式训练循环,可控制如何以及何时进行以下操作:
- 加载数据
- 处理异常
- 创建检查点文件并从故障中恢复
- 保存 TensorBoard 摘要
在用 Estimator 编写应用时,您必须将数据输入流水线与模型分离。这种分离简化了使用不同数据集进行的实验。
预制 Estimator
使用预制 Estimator,您能够在比基础 TensorFlow API 高很多的概念层面上工作。您无需再担心创建计算图或会话,因为 Estimator 会替您完成所有“基础工作”。此外,使用预制 Estimator,您只需改动较少代码就能试验不同的模型架构。例如,tf.estimator.DNNClassifier 是一个预制 Estimator 类,可基于密集的前馈神经网络对分类模型进行训练。
预制 Estimator 程序结构
依赖于预制 Estimator 的 TensorFlow 程序通常包括以下四个步骤:
1. 编写一个或多个数据集导入函数。
例如,您可以创建一个函数来导入训练集,创建另一个函数来导入测试集。每个数据集导入函数必须返回以下两个对象:
- 字典,其中键是特征名称,值是包含相应特征数据的张量(或 SparseTensor)
- 包含一个或多个标签的张量
例如,以下代码展示了输入函数的基本框架:
def input_fn(dataset): ... # manipulate dataset, extracting the feature dict and the label return feature_dict, label政安晨:
数据框架其实是这样的,不知为何官方文档中没有给出?
def train_input_fn():titanic_file = tf.keras.utils.get_file("train.csv", "https://storage.googleapis.com/tf-datasets/titanic/train.csv")titanic = tf.data.experimental.make_csv_dataset(titanic_file, batch_size=32,label_name="survived")titanic_batches = (titanic.cache().repeat().shuffle(500).prefetch(tf.data.AUTOTUNE))return titanic_batches执行如下:

2. 定义特征列。
每个 tf.feature_column 标识了特征名称、特征类型,以及任何输入预处理。例如,以下代码段创建了三个包含整数或浮点数据的特征列。前两个特征列仅标识了特征的名称和类型。第三个特征列还指定了一个会被程序调用以缩放原始数据的 lambda:
# Define three numeric feature columns. population = tf.feature_column.numeric_column('population') crime_rate = tf.feature_column.numeric_column('crime_rate') median_education = tf.feature_column.numeric_column( 'median_education', normalizer_fn=lambda x: x - global_education_mean)3. 实例化相关预制 Estimator。
例如,下面是对名为 LinearClassifier 的预制 Estimator 进行实例化的示例:
# Instantiate an estimator, passing the feature columns. estimator = tf.estimator.LinearClassifier( feature_columns=[population, crime_rate, median_education])4. 调用训练、评估或推断方法。
例如,所有 Estimator 都会提供一个用于训练模型的 train 方法。
# `input_fn` is the function created in Step 1 estimator.train(input_fn=my_training_set, steps=2000)预制 Estimator 的优势
预制 Estimator 对最佳做法进行了编码,具有以下优势:
- 确定计算图不同部分的运行位置,以及在单台机器或集群上实施策略的最佳做法。
- 事件(摘要)编写和通用摘要的最佳做法。
如果不使用预制 Estimator,则您必须自己实现上述功能。
自定义 Estimator
每个 Estimator(无论预制还是自定义)的核心是其模型函数,这是一种为训练、评估和预测构建计算图的方法。当您使用预制 Estimator 时,已经有人为您实现了模型函数。当使用自定义 Estimator 时,您必须自己编写模型函数。
推荐工作流
- 假设存在一个合适的预制 Estimator,用它构建您的第一个模型,并将其结果作为基准。
- 使用此预制 Estimator 构建并测试您的整个流水线,包括数据的完整性和可靠性。
- 如果有其他合适的预制 Estimator,可通过运行实验确定哪个预制 Estimator 能够生成最佳结果。
- 如果可能,您可以通过构建自己的自定义 Estimator 进一步改进模型。
import tensorflow as tfimport tensorflow_datasets as tfds
tfds.disable_progress_bar()从 Keras 模型创建 Estimator
您可以使用 tf.keras.estimator.model_to_estimator 将现有的 Keras 模型转换为 Estimator。这样一来,您的 Keras 模型就可以利用 Estimator 的优势,例如分布式训练。
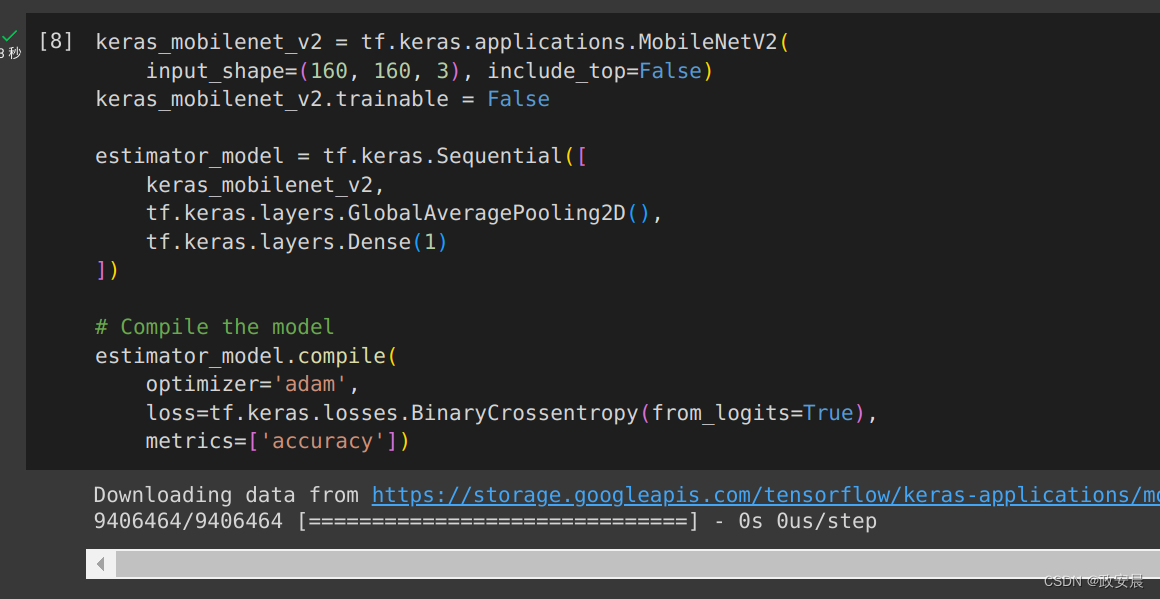
实例化 Keras MobileNet V2 模型并用训练中使用的优化器、损失和指标来编译模型:
keras_mobilenet_v2 = tf.keras.applications.MobileNetV2(input_shape=(160, 160, 3), include_top=False)
keras_mobilenet_v2.trainable = Falseestimator_model = tf.keras.Sequential([keras_mobilenet_v2,tf.keras.layers.GlobalAveragePooling2D(),tf.keras.layers.Dense(1)
])# Compile the model
estimator_model.compile(optimizer='adam',loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),metrics=['accuracy'])政安晨执行:
从已编译的 Keras 模型创建 Estimator。Keras 模型的初始模型状态会保留在已创建的 Estimator中:
est_mobilenet_v2 = tf.keras.estimator.model_to_estimator(keras_model=estimator_model)
您可以像对待任何其他 Estimator 一样对待派生的 Estimator。
IMG_SIZE = 160 # All images will be resized to 160x160def preprocess(image, label):image = tf.cast(image, tf.float32)image = (image/127.5) - 1image = tf.image.resize(image, (IMG_SIZE, IMG_SIZE))return image, labeldef train_input_fn(batch_size):data = tfds.load('cats_vs_dogs', as_supervised=True)train_data = data['train']train_data = train_data.map(preprocess).shuffle(500).batch(batch_size)return train_data要进行训练,可调用 Estimator 的训练函数:
est_mobilenet_v2.train(input_fn=lambda: train_input_fn(32), steps=500)同样,要进行评估,可调用 Estimator 的评估函数:
est_mobilenet_v2.evaluate(input_fn=lambda: train_input_fn(32), steps=10)有关详细信息,请参阅 tf.keras.estimator.model_to_estimator 文档。
写在最后
其实这一篇中官方指南并不详尽,尤其是最后的训练部分,咱们补充了一些,但仍然存在缺失,我将在后续的文章中以实际项目为例,详细演绎。
相关文章:

政安晨:示例演绎TensorFlow的官方指南(二){Estimator}
咱们接着演绎TensorFlow官方指南,我的这个系列的上一篇文章为: 政安晨:示例演绎TensorFlow的官方指南(一){基础知识}https://blog.csdn.net/snowdenkeke/article/details/136067030为什么要演绎官方指南,我…...
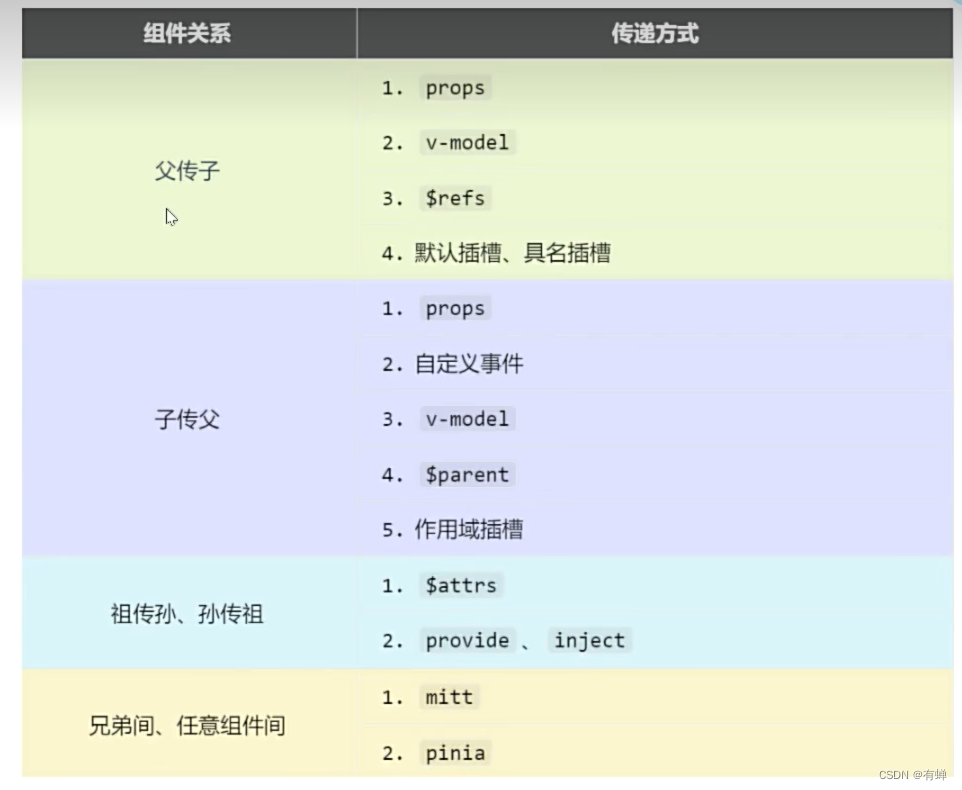
vue3:24—组件通信方式
目录 1、props 2、自定义事件 (emit) 3、mitt(任意组件的通讯) 4、v-model【封装ui组件库用的多,平时用的少。和vue2有点不同】 5、$attrs 6、$refs和$parent 7、provide和inject 8、pinia(即vue2中…...

WebGL+Three.js入门与实战——绘制水平移动的点、通过鼠标控制绘制(点击绘制、移动绘制、模拟画笔)
个人简介 👀个人主页: 前端杂货铺 🙋♂️学习方向: 主攻前端方向,正逐渐往全干发展 📃个人状态: 研发工程师,现效力于中国工业软件事业 🚀人生格言: 积跬步…...

大数据环境搭建(一)-Hive
1 hive介绍 由Facebook开源的,用于解决海量结构化日志的数据统计的项目 本质上是将HQL转化为MapReduce、Tez、Spark等程序 Hive表的数据是HDFS上的目录和文件 Hive元数据 metastore,包含Hive表的数据库、表名、列、分区、表类型、表所在目录等。 根据Hive部署模…...
mac电脑上使用android studio创建flutter项目
mac电脑环境配置可以看这篇文章:https://xiaoshen.blog.csdn.net/article/details/136068650 配置玩环境之后,开始创建第一个flutter项目:点击new flutter project或者new project都可以 然后选择flutter: 并将sdk配置为解压后的…...
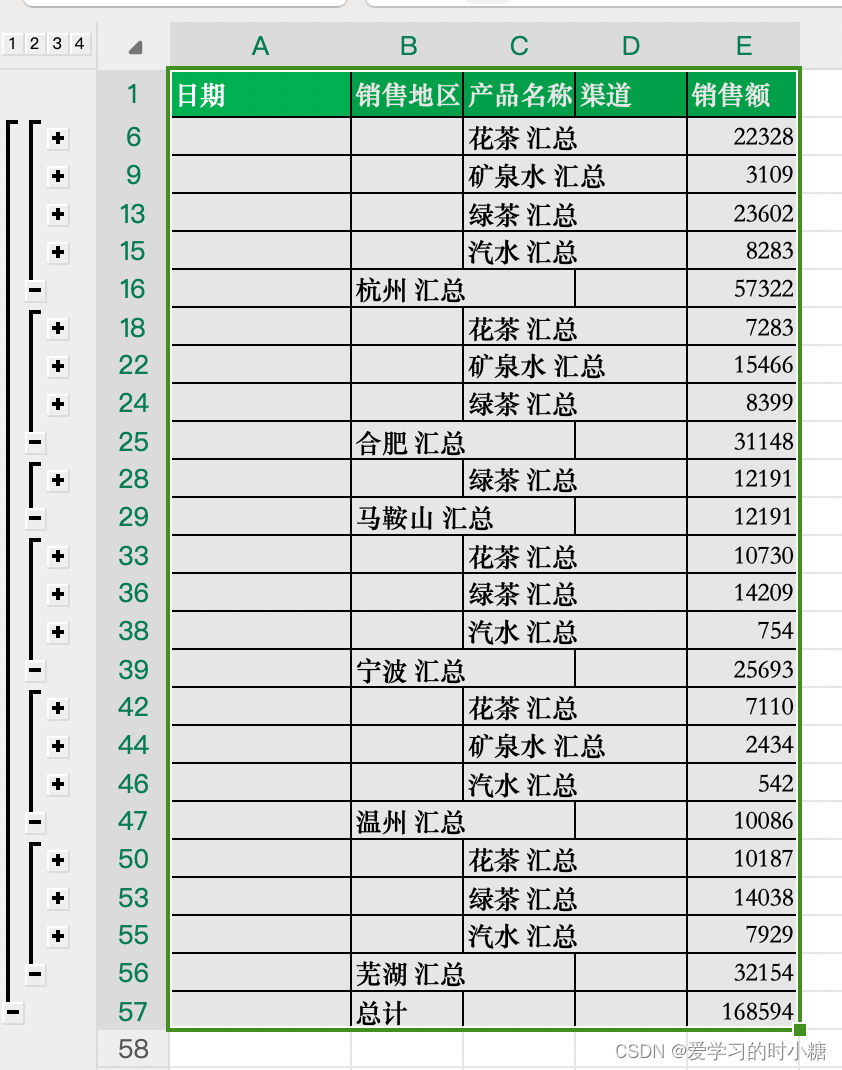
Excel——分类汇总
1.一级分类汇总 Q:请根据各销售地区统计销售额总数。 第一步:排序,我们需要根据销售地区汇总数据,我们就要对【销售地区】的内容进行排序。点击【销售地区】列中任意一个单元格,选择【数据】——【排序】,…...

Backtrader 文档学习- Observers - Reference
Backtrader 文档学习- Observers - Reference 1.Benchmark class backtrader.observers.Benchmark() 观察器存储策略的回报和参考资产的回报,参考资产是传递给系统的数据之一。 参数: timeframe (default: None) ,如果None,则将…...
鸿蒙(HarmonyOS)项目方舟框架(ArkUI)之Radio组件
鸿蒙(HarmonyOS)项目方舟框架(ArkUI)之Radio组件 一、操作环境 操作系统: Windows 10 专业版、IDE:DevEco Studio 3.1、SDK:HarmonyOS 3.1 二、Radio组件 单选框,提供相应的用户交互选择项。 子组件 无。 接口 …...

【go】结构体切片去重
场景 自定义结构体切片,去除切片中的重复元素(所有值完全相同) 代码 // 自定义struct去重 type AssetAppIntranets struct {ID string json:"id,omitempty"AppID string json:"app_id,omitempty"IP …...

百面嵌入式专栏(面试题)C语言面试题22道
沉淀、分享、成长,让自己和他人都能有所收获!😄 📢本篇我们将介绍C语言相关面试题 。 宏定义是在编译的哪个阶段被处理的?答案:宏定义是在编译预处理阶段被处理的。 解读:编译预处理:头文件包含、宏替换、条件编译、去除注释、添加行号。 写一个“标准”宏MIN,这个…...

Docker方式创建keepalived连接MGR集群
记录一下简单的搭建步骤以便后期查验 目录 前言步骤1. 安装环境2. 重新制作镜像3. 导入新镜像4. 创建容器 前言 假设已经搭建了MySQL8的MGR集群方式(一主两从)。 MGR本身有故障转移重新选举新的主节点功能,但是上游的应用程序需要自己手动修…...

Oracle PL/SQL Programming 第5章:Iterative Processing with Loops 读书笔记
总的目录和进度,请参见开始读 Oracle PL/SQL Programming 第6版 本章探讨 PL/SQL 的迭代控制结构(也称为循环),它允许您重复执行相同的代码。 PL/SQL 提供了三种不同类型的循环结构: 简单或无限循环FOR 循环&#x…...

C入门番外篇——C, Are you OK?
今日路上看到一个车牌,52U0K,感觉很有意思,如果做一下简单的翻译就是,“我爱你,好么?” 这样让我脑子中闪现了这样的一个画面:“一个男生追一个女生,看到女生不怎么搭理自己的样子&a…...
python-产品篇-游戏-象棋
文章目录 代码效果 代码 import pygame import time import constants from button import Button import pieces import computerclass MainGame():window NoneStart_X constants.Start_XStart_Y constants.Start_YLine_Span constants.Line_SpanMax_X Start_X 8 * Lin…...

用linux文件系统的链接功能实现文件缓存LRU
概述: 目前,随着家庭宽带网络、无线宽带技术,以及终端设备性能的不断发展,基于多媒体的应用越来越广泛,特别是互联网视频的应用更是成为推动这些技术发展的源动力。作为互联网视频VOD的应用,提高视频播放的流畅度是一个非常重要的指标之一。除了编解码技术,视频C…...

AI大模型开发架构设计(10)——AI大模型架构体系与典型应用场景
文章目录 AI大模型架构体系与典型应用场景1 AI大模型架构体系你了解多少?GPT 助手训练流程GPT 助手训练数据预处理2个训练案例分析 2 AI 大模型的典型应用场景以及应用架构剖析AI 大模型的典型应用场景AI 大模型应用架构 AI大模型架构体系与典型应用场景 1 AI大模型架构体系你…...

C# async/await的使用
C# 中的 async 和 await 关键字是用于实现异步编程的重要工具,它们简化了编写和维护非阻塞代码的过程。以下是对这两个关键字用法的简要说明: async 关键字 定义异步方法:在方法声明前使用 async 关键字,表示该方法是一个异步方…...

C语言之找单身狗
个人主页(找往期文章包括但不限于本期文章中不懂的知识点): 我要学编程(ಥ_ಥ)-CSDN博客 题目: 在一个整型数组中,只有一个数字出现一次,其他数组都是成对出现的,请找出那个只出现一次的数字。…...

读懂 FastChat 大模型部署源码所需的异步编程基础
原文:读懂 FastChat 大模型部署源码所需的异步编程基础 - 知乎 目录 0. 前言 1. 同步与异步的区别 2. 协程 3. 事件循环 4. await 5. 组合协程 6. 使用 Semaphore 限制并发数 7. 运行阻塞任务 8. 异步迭代器 async for 9. 异步上下文管理器 async with …...

【华为】GRE VPN 实验配置
【华为】GRE VPN 实验配置 前言报文格式 实验需求配置思路配置拓扑GRE配置步骤R1基础配置GRE 配置 ISP_R2基础配置 R3基础配置GRE 配置 PCPC1PC2 抓包检查OSPF建立GRE隧道建立 配置文档 前言 VPN :(Virtual Private Network),即“…...

从NASA航天电子设计看高可靠性电源与模拟电路工程实践
1. 从太空迷到电子工程师:我的技术启蒙之路我是一名不折不扣的太空迷。这个身份的烙印,始于童年时守在电视机前,目睹第一艘“水星号”载人飞船发射升空的那一天。沃尔特克朗凯特在新闻中从各个科学角度进行的详尽报道,让我整整一天…...
)
Cheat Engine 简单使用教程(新手版)
很多人第一次打开 Cheat Engine,都会被界面吓到。 其实真没那么复杂。 如果你只是想修改一下单机游戏里的金币、血量或者资源,掌握下面这几个步骤基本就够用了。 一、先打开游戏,再启动 Cheat Engine 这一点很多新人容易搞反。 正确顺序是…...

OpenClaw集成xAI Grok模型:一键配置与API兼容性解析
1. 项目概述:为OpenClaw解锁xAI Grok模型支持 如果你和我一样,既是OpenClaw的忠实用户,又对xAI推出的Grok系列模型(特别是Grok 4.1)的强大推理能力垂涎已久,那么之前肯定也卡在了同一个地方:Ope…...

Windows平台iOS模拟器开发革命:ipasim如何让iOS应用在Windows上“原生“运行
Windows平台iOS模拟器开发革命:ipasim如何让iOS应用在Windows上"原生"运行 【免费下载链接】ipasim iOS emulator for Windows 项目地址: https://gitcode.com/gh_mirrors/ip/ipasim 嘿,开发者朋友们!你是否曾经梦想过在Win…...
暨十三届第四期“麓峰”交叉科学论坛)
【湖南师范大学主办 | ACM出版,检索快且稳定 | 往届均已见刊并完成EI、Scopus检索】第三届智慧教育与计算机技术国际学术会议 (IECT 2026)暨十三届第四期“麓峰”交叉科学论坛
已通过ACM出版,ISBN号:979-8-4007-2365-0 教育方向结合:计算机、信息技术、人工智能、多媒体技术、大数据等主题均可投递 第三届智慧教育与计算机技术国际学术会议 (IECT 2026)暨十三届第四期“麓峰”交叉科学论坛 2026 3rd International…...

终极指南:如何用React JSON Schema Form快速构建专业表单设计语言
终极指南:如何用React JSON Schema Form快速构建专业表单设计语言 【免费下载链接】react-jsonschema-form A React component for building Web forms from JSON Schema. 项目地址: https://gitcode.com/gh_mirrors/re/react-jsonschema-form React JSON Sc…...

ARM Fast Models MTI插件开发与性能优化实战
1. Fast Models中的Model Trace Interface架构解析在嵌入式系统仿真领域,ARM Fast Models提供的Model Trace Interface(MTI)是一套高效的仿真数据采集框架。作为一位长期从事嵌入式调试工具开发的工程师,我发现MTI的独特设计使其成…...

基于Azure SQL与Semantic Kernel的RAG应用实战:低成本实现向量搜索与智能问答
1. 项目概述:当SQL数据库遇上向量搜索如果你正在用.NET技术栈构建智能应用,并且数据已经躺在Azure SQL Database里,那么“如何低成本、高效率地实现语义搜索和RAG(检索增强生成)”很可能就是你当前最头疼的问题。传统的…...
)
ChatGPT Instagram内容策略失效真相(92%运营者忽略的算法适配层)
更多请点击: https://intelliparadigm.com 第一章:ChatGPT Instagram内容策略失效的底层归因 Instagram 的算法演进与用户行为迁移,正系统性瓦解基于通用大模型(如 ChatGPT)生成的“模板化内容策略”。其失效并非源于…...

维他动力获5亿Pre-A轮启动人形研发;优必选与日立达成合作人形机器人赋能制造; 前小米高管创业工业通用具身大脑小雨智造获B+轮融资
1. 维他动力获5亿Pre-A轮启动人形研发牛喀网获悉,Vbot维他动力正式完成近5亿元Pre-A轮融资,创下当前消费级具身智能领域的最大单笔融资纪录,本轮由东方嘉富、华泰紫金、复星锐正联合领投,上汽旗下尚颀资本等机构参投。技术层面&am…...