Python爬虫之关系型数据库存储#5
关系型数据库是基于关系模型的数据库,而关系模型是通过二维表来保存的,所以它的存储方式就是行列组成的表,每一列是一个字段,每一行是一条记录。表可以看作某个实体的集合,而实体之间存在联系,这就需要表与表之间的关联关系来体现,如主键外键的关联关系。多个表组成一个数据库,也就是关系型数据库。
关系型数据库有多种,如 SQLite、MySQL、Oracle、SQL Server、DB2 等。
MySQL 的存储
本节中,我们主要介绍 Python 3 下 MySQL 的存储。
在 Python 2 中,连接 MySQL 的库大多是使用 MySQLdb,但是此库的官方并不支持 Python 3,所以这里推荐使用的库是 PyMySQL。
本节中,我们就来讲解使用 PyMySQL 操作 MySQL 数据库的方法。
1. 准备工作
在开始之前,请确保已经安装好了 MySQL 数据库并保证它能正常运行,而且需要安装好 Py MySQL 库。如果没有安装,可以参考第 1 章。
2. 连接数据库
这里,首先尝试连接一下数据库。假设当前的 MySQL 运行在本地,用户名为 root,密码为 123456,运行端口为 3306。这里利用 PyMySQL 先连接 MySQL,然后创建一个新的数据库,名字叫作 spiders,代码如下:
import pymysql
db = pymysql.connect(host='localhost',user='root', password='123456', port=3306)
cursor = db.cursor()
cursor.execute('SELECT VERSION()')
data = cursor.fetchone()
print('Database version:', data)
cursor.execute("CREATE DATABASE spiders DEFAULT CHARACTER SET utf8")
db.close()
运行结果如下:
Database version: ('5.6.22',)
这里通过 PyMySQL 的 connect 方法声明一个 MySQL 连接对象 db,此时需要传入 MySQL 运行的 host(即 IP)。由于 MySQL 在本地运行,所以传入的是 localhost。如果 MySQL 在远程运行,则传入其公网 IP 地址。后续的参数 user 即用户名,password 即密码,port 即端口(默认为 3306)。
连接成功后,需要再调用 cursor 方法获得 MySQL 的操作游标,利用游标来执行 SQL 语句。这里我们执行了两句 SQL,直接用 execute 方法执行即可。第一句 SQL 用于获得 MySQL 的当前版本,然后调用 fetchone 方法获得第一条数据,也就得到了版本号。第二句 SQL 执行创建数据库的操作,数据库名叫作 spiders,默认编码为 UTF-8。由于该语句不是查询语句,所以直接执行后就成功创建了数据库 spiders。接着,再利用这个数据库进行后续的操作。
3. 创建表
一般来说,创建数据库的操作只需要执行一次就好了。当然,我们也可以手动创建数据库。以后,我们的操作都在 spiders 数据库上执行。
创建数据库后,在连接时需要额外指定一个参数 db。
接下来,新创建一个数据表 students,此时执行创建表的 SQL 语句即可。这里指定 3 个字段,结构如表 5-1 所示。
表 5-1 数据表 students
| 字 段 名 | 含 义 | 类 型 |
|---|---|---|
| id | 学号 | varchar |
| name | 姓名 | varchar |
| age | 年龄 | int |
创建该表的示例代码如下:
import pymysql db = pymysql.connect(host='localhost', user='root', password='123456', port=3306, db='spiders') cursor = db.cursor() sql = 'CREATE TABLE IF NOT EXISTS students (id VARCHAR(255) NOT NULL, name VARCHAR(255) NOT NULL, age INT NOT NULL, PRIMARY KEY (id))' cursor.execute(sql) db.close()
运行之后,我们便创建了一个名为 students 的数据表。
当然,为了演示,这里只指定了最简单的几个字段。实际上,在爬虫过程中,我们会根据爬取结果设计特定的字段。
4. 插入数据
下一步就是向数据库中插入数据了。例如,这里爬取了一个学生信息,学号为 20120001,名字为 Bob,年龄为 20,那么如何将该条数据插入数据库呢?示例代码如下:
import pymysql id = '20120001' user = 'Bob' age = 20 db = pymysql.connect(host='localhost', user='root', password='123456', port=3306, db='spiders') cursor = db.cursor() sql = 'INSERT INTO students(id, name, age) values(% s, % s, % s)' try:cursor.execute(sql, (id, user, age))db.commit() except:db.rollback() db.close()
这里首先构造了一个 SQL 语句,其 Value 值没有用字符串拼接的方式来构造,如:
sql = 'INSERT INTO students(id, name, age) values(' + id + ', ' + name + ', ' + age + ')'
这样的写法烦琐而且不直观,所以我们选择直接用格式化符 % s 来实现。有几个 Value 写几个 % s,我们只需要在 execute 方法的第一个参数传入该 SQL 语句,Value 值用统一的元组传过来就好了。这样的写法既可以避免字符串拼接的麻烦,又可以避免引号冲突的问题。
之后值得注意的是,需要执行 db 对象的 commit 方法才可实现数据插入,这个方法才是真正将语句提交到数据库执行的方法。对于数据插入、更新、删除操作,都需要调用该方法才能生效。
接下来,我们加了一层异常处理。如果执行失败,则调用 rollback 执行数据回滚,相当于什么都没有发生过。
这里涉及事务的问题。事务机制可以确保数据的一致性,也就是这件事要么发生了,要么没有发生。比如插入一条数据,不会存在插入一半的情况,要么全部插入,要么都不插入,这就是事务的原子性。另外,事务还有 3 个属性 —— 一致性、隔离性和持久性。这 4 个属性通常称为 ACID 特性,具体如表所示。
事务的 4 个属性
| 属 性 | 解 释 |
|---|---|
| 原子性(atomicity) | 事务是一个不可分割的工作单位,事务中包括的诸操作要么都做,要么都不做 |
| 一致性(consistency) | 事务必须使数据库从一个一致性状态变到另一个一致性状态。一致性与原子性是密切相关的 |
| 隔离性(isolation) | 一个事务的执行不能被其他事务干扰,即一个事务内部的操作及使用的数据对并发的其他事务是隔离的,并发执行的各个事务之间不能互相干扰 |
| 持久性(durability) | 持续性也称永久性(permanence),指一个事务一旦提交,它对数据库中数据的改变就应该是永久性的。接下来的其他操作或故障不应该对其有任何影响 |
插入、更新和删除操作都是对数据库进行更改的操作,而更改操作都必须为一个事务,所以这些操作的标准写法就是:
try:cursor.execute(sql)db.commit() except:db.rollback()
这样便可以保证数据的一致性。这里的 commit 和 rollback 方法就为事务的实现提供了支持。
上面数据插入的操作是通过构造 SQL 语句实现的,但是很明显,这有一个极其不方便的地方,比如突然增加了性别字段 gender,此时 SQL 语句就需要改成:
INSERT INTO students(id, name, age, gender) values(% s, % s, % s, % s)
相应的元组参数则需要改成:
(id, name, age, gender)
这显然不是我们想要的。在很多情况下,我们要达到的效果是插入方法无需改动,做成一个通用方法,只需要传入一个动态变化的字典就好了。比如,构造这样一个字典:
{'id': '20120001','name': 'Bob','age': 20
}
然后 SQL 语句会根据字典动态构造,元组也动态构造,这样才能实现通用的插入方法。所以,这里我们需要改写一下插入方法:
data = {'id': '20120001','name': 'Bob','age': 20
}
table = 'students'
keys = ', '.join(data.keys())
values = ', '.join(['% s'] * len(data))
sql = 'INSERT INTO {table}({keys}) VALUES ({values})'.format(table=table, keys=keys, values=values)
try:if cursor.execute(sql, tuple(data.values())):print('Successful')db.commit()
except:print('Failed')db.rollback()
db.close()
这里我们传入的数据是字典,并将其定义为 data 变量。表名也定义成变量 table。接下来,就需要构造一个动态的 SQL 语句了。
首先,需要构造插入的字段 id、name 和 age。这里只需要将 data 的键名拿过来,然后用逗号分隔即可。所以 ', '.join(data.keys()) 的结果就是 id, name, age,然后需要构造多个 % s 当作占位符,有几个字段构造几个即可。比如,这里有三个字段,就需要构造 % s, % s, % s。这里首先定义了长度为 1 的数组 ['% s'],然后用乘法将其扩充为 ['% s', '% s', '% s'],再调用 join 方法,最终变成 % s, % s, % s。最后,我们再利用字符串的 format 方法将表名、字段名和占位符构造出来。最终的 SQL 语句就被动态构造成了:
INSERT INTO students(id, name, age) VALUES (% s, % s, % s)
最后,为 execute 方法的第一个参数传入 sql 变量,第二个参数传入 data 的键值构造的元组,就可以成功插入数据了。
如此以来,我们便实现了传入一个字典来插入数据的方法,不需要再去修改 SQL 语句和插入操作了。
5. 更新数据
数据更新操作实际上也是执行 SQL 语句,最简单的方式就是构造一个 SQL 语句,然后执行:
sql = 'UPDATE students SET age = % s WHERE name = % s' try:cursor.execute(sql, (25, 'Bob'))db.commit() except:db.rollback() db.close()
这里同样用占位符的方式构造 SQL,然后执行 execute 方法,传入元组形式的参数,同样执行 commit 方法执行操作。如果要做简单的数据更新的话,完全可以使用此方法。
但是在实际的数据抓取过程中,大部分情况下需要插入数据,但是我们关心的是会不会出现重复数据,如果出现了,我们希望更新数据而不是重复保存一次。另外,就像前面所说的动态构造 SQL 的问题,所以这里可以再实现一种去重的方法,如果数据存在,则更新数据;如果数据不存在,则插入数据。另外,这种做法支持灵活的字典传值。示例如下:
data = {'id': '20120001','name': 'Bob','age': 21
}table = 'students'
keys = ', '.join(data.keys())
values = ', '.join(['% s'] * len(data))sql = 'INSERT INTO {table}({keys}) VALUES ({values}) ON DUPLICATE KEY UPDATE'.format(table=table, keys=keys, values=values)
update = ','.join(["{key} = % s".format(key=key) for key in data])
sql += update
try:if cursor.execute(sql, tuple(data.values())*2):print('Successful')db.commit()
except:print('Failed')db.rollback()
db.close()
这里构造的 SQL 语句其实是插入语句,但是我们在后面加了 ON DUPLICATE KEY UPDATE。这行代码的意思是如果主键已经存在,就执行更新操作。比如,我们传入的数据 id 仍然为 20120001,但是年龄有所变化,由 20 变成了 21,此时这条数据不会被插入,而是直接更新 id 为 20120001 的数据。完整的 SQL 构造出来是这样的:
INSERT INTO students(id, name, age) VALUES (% s, % s, % s) ON DUPLICATE KEY UPDATE id = % s, name = % s, age = % s
这里就变成了 6 个 % s。所以在后面的 execute 方法的第二个参数元组就需要乘以 2 变成原来的 2 倍。
如此一来,我们就可以实现主键不存在便插入数据,存在则更新数据的功能了。
6. 删除数据
删除操作相对简单,直接使用 DELETE 语句即可,只是需要指定要删除的目标表名和删除条件,而且仍然需要使用 db 的 commit 方法才能生效。示例如下:
table = 'students'
condition = 'age > 20'sql = 'DELETE FROM {table} WHERE {condition}'.format(table=table, condition=condition)
try:cursor.execute(sql)db.commit()
except:db.rollback()db.close()
因为删除条件有多种多样,运算符有大于、小于、等于、LIKE 等,条件连接符有 AND、OR 等,所以不再继续构造复杂的判断条件。这里直接将条件当作字符串来传递,以实现删除操作。
7. 查询数据
说完插入、修改和删除等操作,还剩下非常重要的一个操作,那就是查询。查询会用到 SELECT 语句,示例如下:
sql = 'SELECT * FROM students WHERE age >= 20'try:cursor.execute(sql)print('Count:', cursor.rowcount)one = cursor.fetchone()print('One:', one)results = cursor.fetchall()print('Results:', results)print('Results Type:', type(results))for row in results:print(row)
except:print('Error')
运行结果如下:
Count: 4
One: ('20120001', 'Bob', 25)
Results: (('20120011', 'Mary', 21), ('20120012', 'Mike', 20), ('20120013', 'James', 22))
Results Type: <class 'tuple'>
('20120011', 'Mary', 21)
('20120012', 'Mike', 20)
('20120013', 'James', 22)
这里我们构造了一条 SQL 语句,将年龄 20 岁及以上的学生查询出来,然后将其传给 execute 方法。注意,这里不再需要 db 的 commit 方法。接着,调用 cursor 的 rowcount 属性获取查询结果的条数,当前示例中是 4 条。
然后我们调用了 fetchone 方法,这个方法可以获取结果的第一条数据,返回结果是元组形式,元组的元素顺序跟字段一一对应,即第一个元素就是第一个字段 id,第二个元素就是第二个字段 name,以此类推。随后,我们又调用了 fetchall 方法,它可以得到结果的所有数据。然后将其结果和类型打印出来,它是二重元组,每个元素都是一条记录,我们将其遍历输出出来。
但是这里需要注意一个问题,这里显示的是 3 条数据而不是 4 条,fetchall 方法不是获取所有数据吗?这是因为它的内部实现有一个偏移指针用来指向查询结果,最开始偏移指针指向第一条数据,取一次之后,指针偏移到下一条数据,这样再取的话,就会取到下一条数据了。我们最初调用了一次 fetchone 方法,这样结果的偏移指针就指向下一条数据,fetchall 方法返回的是偏移指针指向的数据一直到结束的所有数据,所以该方法获取的结果就只剩 3 个了。
此外,我们还可以用 while 循环加 fetchone 方法来获取所有数据,而不是用 fetchall 全部一起获取出来。fetchall 会将结果以元组形式全部返回,如果数据量很大,那么占用的开销会非常高。因此,推荐使用如下方法来逐条取数据:
sql = 'SELECT * FROM students WHERE age >= 20'
try:cursor.execute(sql)print('Count:', cursor.rowcount)row = cursor.fetchone()while row:print('Row:', row)row = cursor.fetchone()
except:print('Error')
这样每循环一次,指针就会偏移一条数据,随用随取,简单高效。
本节中,我们介绍了如何使用 PyMySQL 操作 MySQL 数据库以及一些 SQL 语句的构造方法,后面会在实战案例中应用这些操作来存储数据。
相关文章:

Python爬虫之关系型数据库存储#5
关系型数据库是基于关系模型的数据库,而关系模型是通过二维表来保存的,所以它的存储方式就是行列组成的表,每一列是一个字段,每一行是一条记录。表可以看作某个实体的集合,而实体之间存在联系,这就需要表与…...

ANSI Escape Sequence 下落的方块
ANSI Escape Sequence 下落的方块 1. ANSI Escape 的用途 无意中发现 B站有人讲解, 完全基于终端实现俄罗斯方块。 基本想法是借助于 ANSI Escape Sequence 实现方方块的绘制、 下落动态效果等。对于只了解 ansi escape sequence 用于 log 的颜色打印的人来说&…...
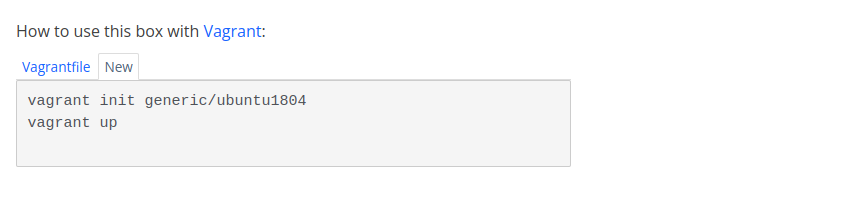
Vagrant 虚拟机工具基本操作指南
Vagrant 虚拟机工具基本操作指南 #虚拟机 # #vargant# #ubuntu# 虚拟机virtualbox ,VMWare及WSL等大家都很了解了,那Vagrant是什么东西? 它是一组命令行工具,可以象Docker管理容器一样管理虚拟机,这样快速创…...

中年低端中产程序员从西安出发到海南三亚低成本吃喝万里行:西安-南宁-湛江-雷州-徐闻-博鳌-陵水-三亚-重庆-西安
文章大纲 旅途规划来回行程的确定南宁 - 北海 - 湛江轮渡成为了最终最大的不确定性!感谢神州租车气温与游玩地点总体花费 游玩过程出发时间:Day1-1月25日星期四,西安飞南宁路途中:Day2-1月26日星期五,南宁-湛江-住雷州…...

企业级Spring boot项目 配置清单
目录 一、服务基础配置 二、配置数据库数据源 三、配置缓存 四、配置日志 五、配置统一异常处理 六、配置swagger文档 七、配置用户登录模块 八、配置websocket 九、配置定时任务 十、配置文件服务器 十一、配置Nacos 十二、配置项目启动数据库默认初始化(liquibas…...
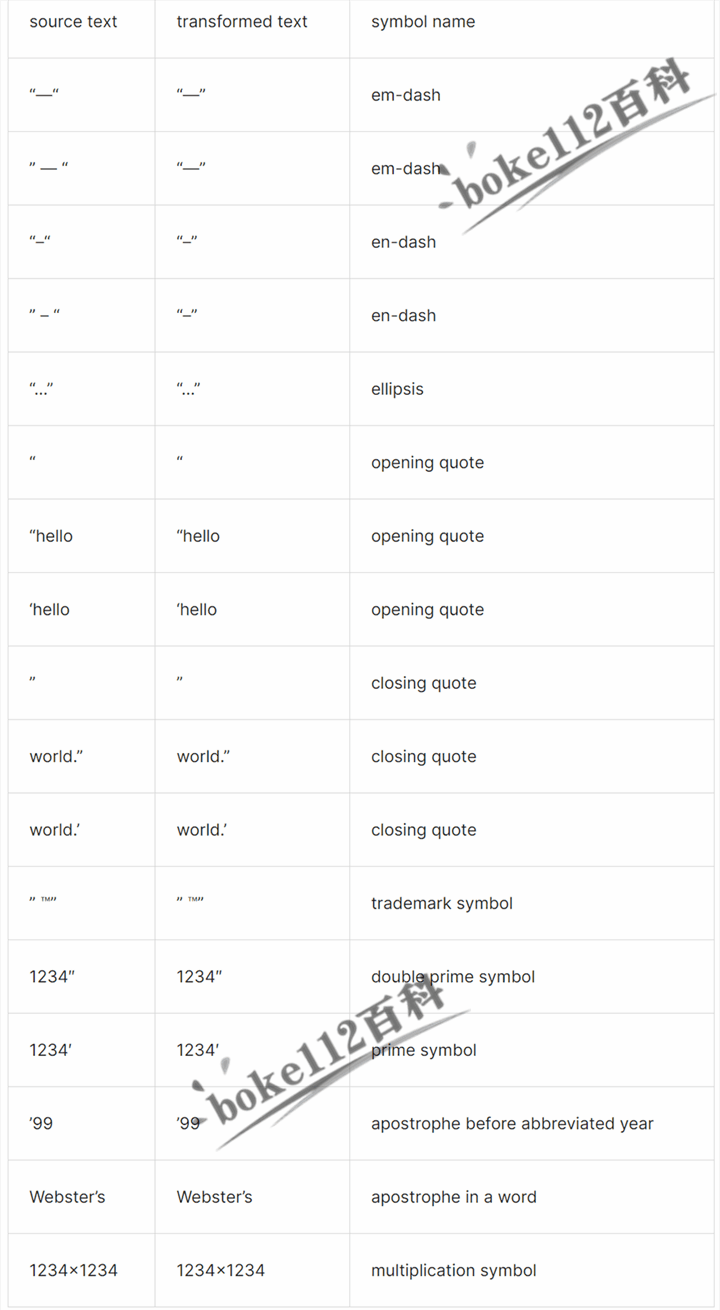
WordPress函数wptexturize的介绍及用法示例,字符串替换为HTML实体
在查看WordPress你好多莉插件时发现代码中使用了wptexturize()函数用来随机输出一句歌词,下面boke112百科就跟大家一起来学习一下WordPress函数wptexturize的介绍及用法示例。 WordPress函数wptexturize介绍 wptexturize( string $text, bool $reset false ): st…...

【Iceberg学习三】Reporting和Partitioning原理
Metrics Reporting Type of Reports 从 1.1.0 版本开始,Iceberg 支持 MetricsReporter 和 MetricsReport API。这两个 API 允许表达不同的度量报告,并支持一种可插拔的方式来报告这些报告。 ScanReport(扫描报告) 扫描报告&am…...
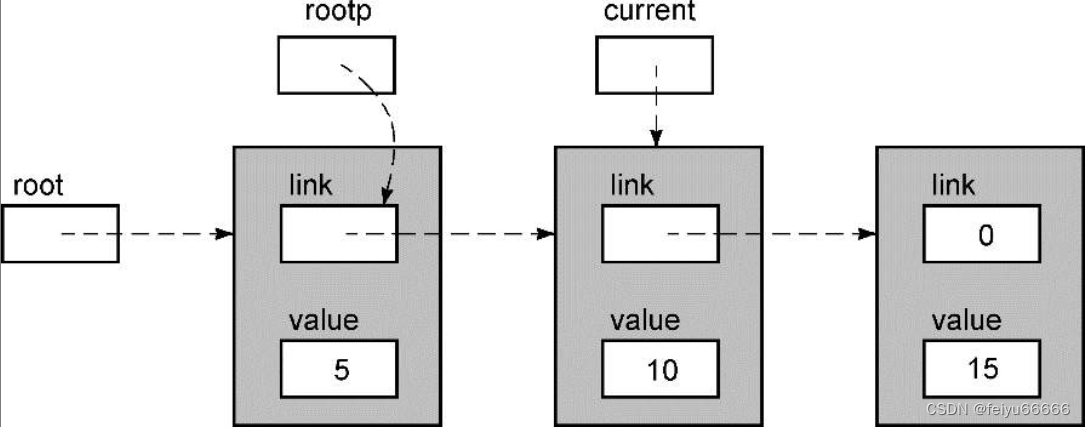
肯尼斯·里科《C和指针》第12章 使用结构和指针(1)链表
只恨当时学的时候没有读到这本书,,,,,, 12.1 链表 有些读者可能还不熟悉链表,这里对它作一简单介绍。链表(linked list)就一些包含数据的独立数据结构(通常称为节点)的集…...
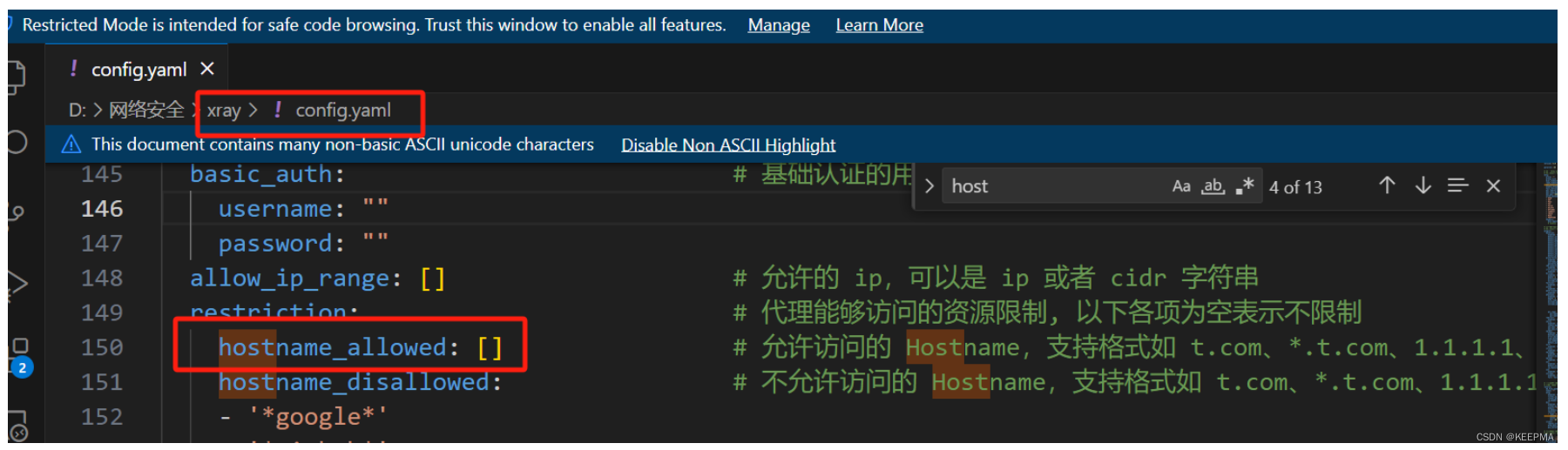
Xray 工具笔记
Xray 官方文档 扫描单个url(非爬虫) 并输出文件(不同文件类型) .\xray.exe webscan --url 10.0.0.6:8080 --text-output result.txt --json-output result.json --html-output report.html默认启动所以内置插件 ,指定…...

Linux环境下配置HTTP代理服务器教程
大家好,我是你们可爱的Linux小助手!今天,我将带你们一起探索如何在Linux环境下配置一个HTTP代理服务器。请注意,这不是一次火箭科学的实验,而是一次简单而有趣的冒险。 首先,我们需要明确什么是HTTP代理服…...
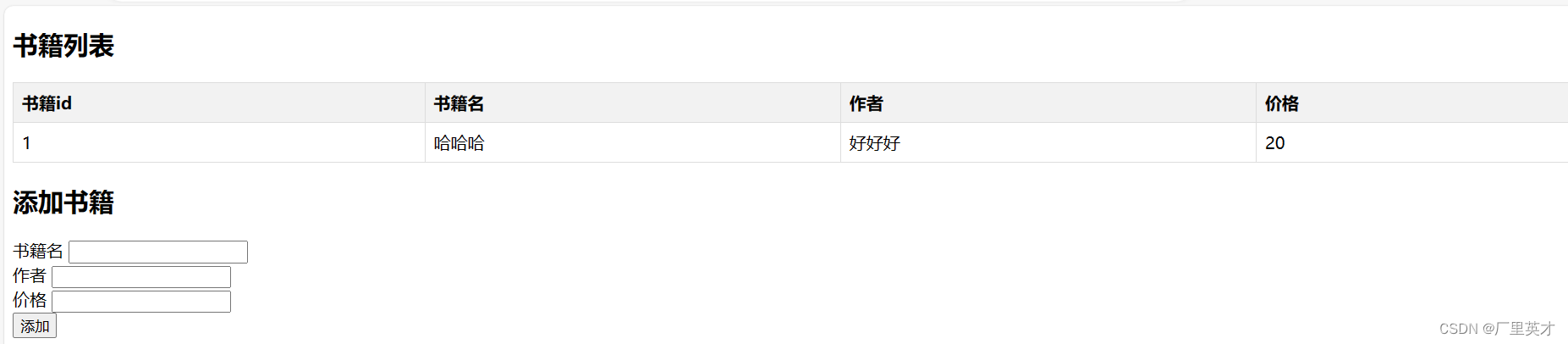
JavaEE作业-实验三
目录 1 实验内容 2 实验要求 3 思路 4 核心代码 5 实验结果 1 实验内容 简单的线上图书交易系统的web层 2 实验要求 ①采用SpringMVC框架,采用REST风格 ②要求具有如下功能:商品分类、订单、购物车、库存 ③独立完成,编写实验报告 …...

K8S容器挂了后重启状态正常,但应用无法访问排查处理
K8S容器挂了后重启状态正常,但应用无法访问排查处理 背景: 应用迁移K8S后因POD OOM挂了后重启,集群上POD状态正常,但应用无法访问。 排查: 查看应用日志,是启动时调用特权账号管理系统超时,…...
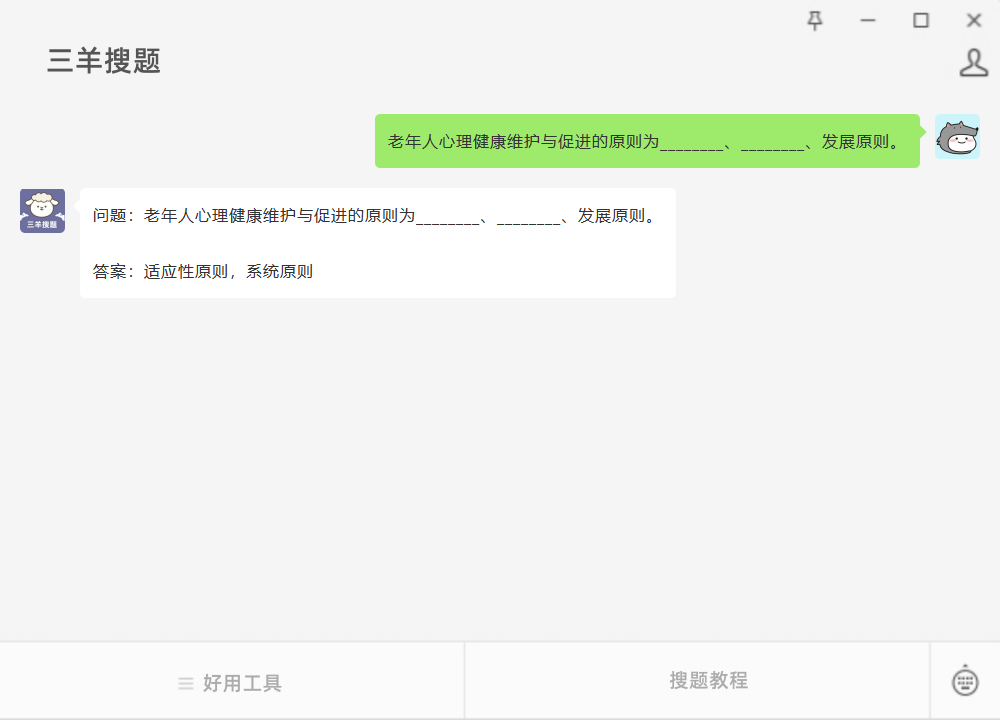
问题:老年人心理健康维护与促进的原则为________、________、发展原则。 #媒体#知识分享
问题:老年人心理健康维护与促进的原则为________、________、发展原则。 参考答案如图所示...

【超高效!保护隐私的新方法】针对图像到图像(l2l)生成模型遗忘学习:超高效且不需要重新训练就能从生成模型中移除特定数据
针对图像到图像生成模型遗忘学习:超高效且不需要重新训练就能从生成模型中移除特定数据 提出背景如何在不重训练模型的情况下从I2I生成模型中移除特定数据? 超高效的机器遗忘方法子问题1: 如何在图像到图像(I2I)生成模型中进行高效…...
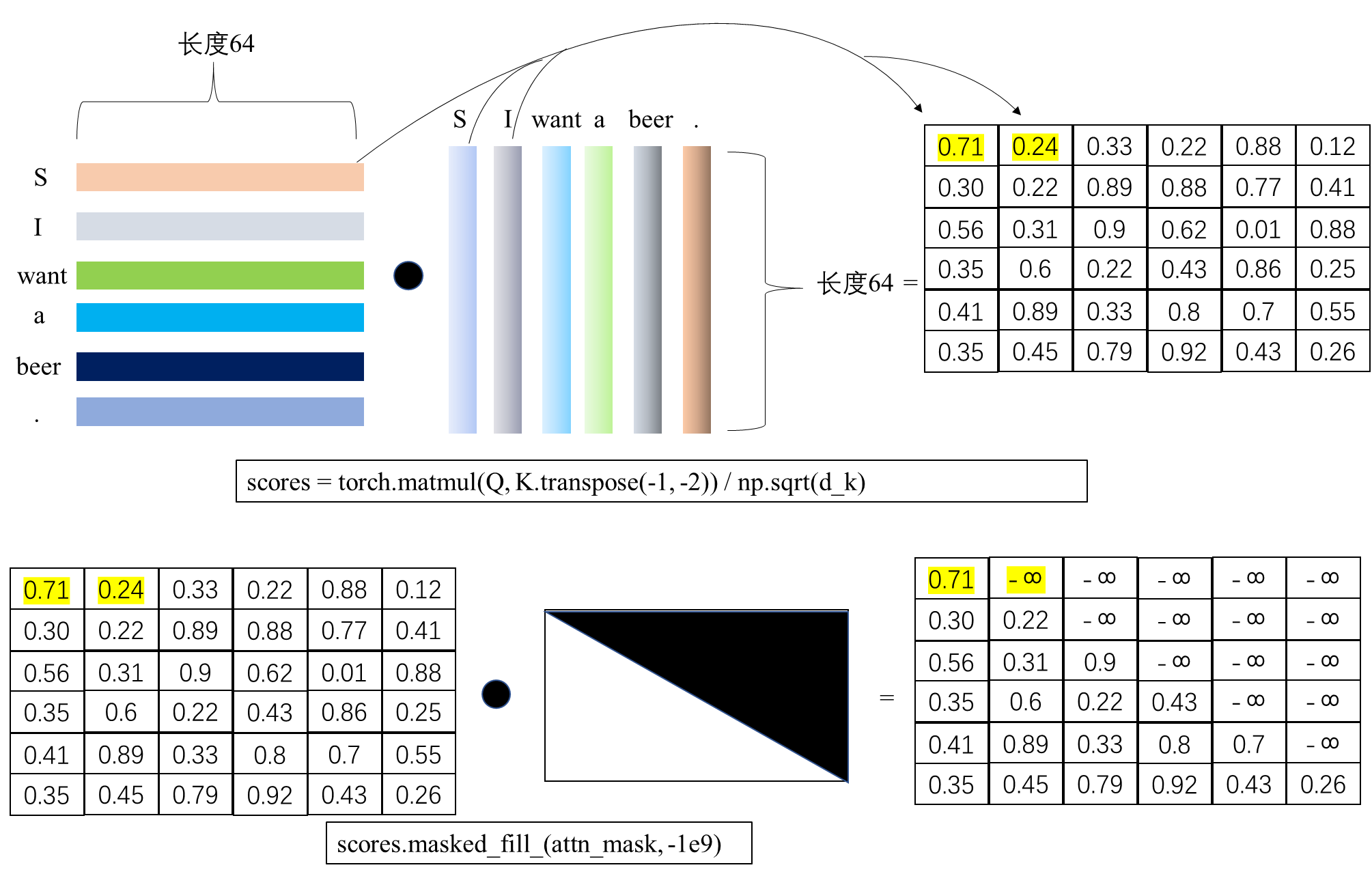
Transformer的PyTorch实现之若干问题探讨(二)
在《Transformer的PyTorch实现之若干问题探讨(一)》中探讨了Transformer的训练整体流程,本文进一步探讨Transformer训练过程中teacher forcing的实现原理。 1.Transformer中decoder的流程 在论文《Attention is all you need》中࿰…...
及其影响。描述Python中的垃圾回收机制。Python中的类变量和实例变量有什么区别)
解释Python中的GIL(全局解释器锁)及其影响。描述Python中的垃圾回收机制。Python中的类变量和实例变量有什么区别
解释Python中的GIL(全局解释器锁)及其影响 Python中的GIL(全局解释器锁)是CPython解释器中的一个机制,用于同步线程的执行。GIL确保任何时候只有一个线程在执行Python字节码。这意味着,即使在多核或多处理器…...
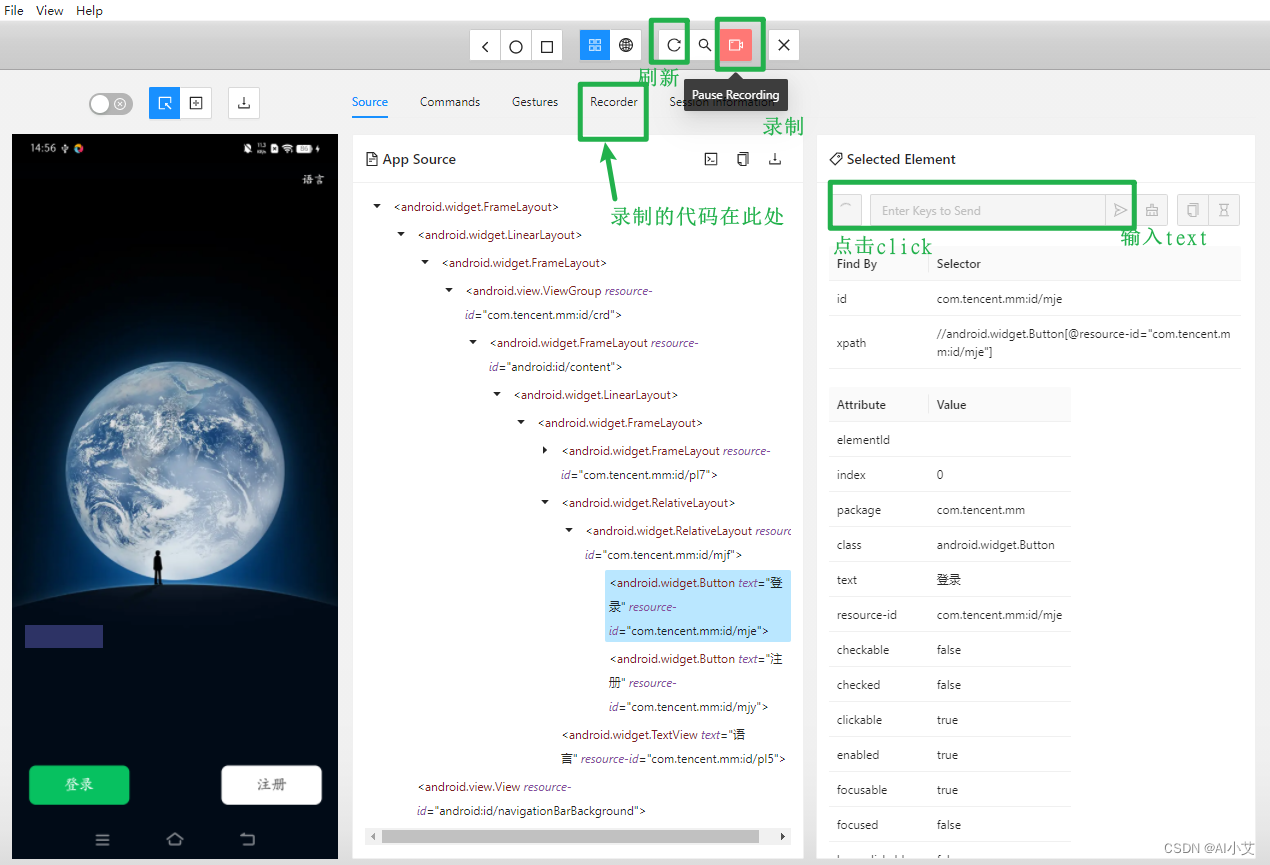
Appium使用初体验之参数配置,简单能够运行起来
一、服务器配置 Appium Server配置与Appium Server GUI(可视化客户端)中的配置对应,尤其是二者如果不在同一台机器上,那么就需要配置Appium Server GUI所在机器的IP(Appium Server GUI的HOST也需要配置本机IP…...

Java:JDK8新特性(Stream流)、File类、递归 --黑马笔记
一、JDK8新特性(Stream流) 接下来我们学习一个全新的知识,叫做Stream流(也叫Stream API)。它是从JDK8以后才有的一个新特性,是专业用于对集合或者数组进行便捷操作的。有多方便呢?我们用一个案…...

【Unity ShaderGraph】| 物体靠近时局部溶解,根据坐标控制溶解的位置【文末送书】
前言 【Unity ShaderGraph】| 物体靠近时局部溶解,根据坐标控制溶解的位置一、效果展示二、根据坐标控制溶解的位置,物体靠近局部溶解三、应用实例👑评论区抽奖送书 前言 本文将使用ShaderGraph制作一个根据坐标控制溶解的位置,物…...

测试OpenSIPS3.4.3的lua模块
这几天测试OpenSIPS3.4.3的lua模块,记录如下: 有bug,但能用 但现实世界就是这样,总是不完美的,发现之后马上提了issue 下面这段代码运行报错: function func1(msg) xlog("ERR","…...
)
告别手动评分!用ImageJ的IHC Profiler插件,5分钟搞定免疫组化定量分析(附避坑指南)
告别手动评分!用ImageJ的IHC Profiler插件,5分钟搞定免疫组化定量分析(附避坑指南) 免疫组化(IHC)作为病理诊断和生物医学研究中的金标准技术,其结果的量化分析一直是困扰研究人员的难题。传统人…...
:使用指南)
One API 部署教程(下):使用指南
导读:前面两篇讲了本地和线上部署,现在 One API 已经跑起来了,接下来就是真正的使用环节! 理解核心概念 在开始之前,咱们先搞清楚几个关键概念,不然后面容易晕。 渠道(Channel):就是你的各个 AI 平台的 API Key。比如你有 DeepSeek 的 Key、OpenAI 的 Key、通义千问…...

WinMerge对比日志和备份文件?用过滤器精准匹配,效率翻倍
WinMerge对比日志和备份文件?用过滤器精准匹配,效率翻倍 在日常运维和办公场景中,我们经常需要对比不同版本的日志文件或备份文件。比如app.log.1和app.log.2的差异分析,或者report_20240520.xlsx与report_20240521.xlsx的内容比对…...

Java Stream流式编程实战
前言 在现代软件开发中,Java Stream流式编程实战是一个非常重要的技术点。本文将从原理到实践,带你深入理解这一技术,并通过完整的代码示例帮助你快速掌握核心知识点。 核心概念 基本原理 Java Stream流式编程实战的核心在于理解其底层机制。…...

初次使用 Taotoken 模型广场进行模型选型与测试的流程指引
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 初次使用 Taotoken 模型广场进行模型选型与测试的流程指引 对于刚接触大模型服务的开发者而言,面对众多厂商和模型&…...

Tina Linux音频开发指南:从ALSA框架到实战调试
1. 项目概述:为什么我们需要一份音频开发指南?在嵌入式Linux的世界里,音频开发常常被开发者们戏称为“玄学”。我见过太多项目,硬件电路设计得漂漂亮亮,系统也跑得飞快,但一到音频部分就卡壳——要么是播放…...

飞凌嵌入式i.MX 95xx核心板:高性能边缘计算与安全开发的硬件平台解析
1. 项目概述:一颗新旗舰的落地与嵌入式开发者的新选择最近,NXP(恩智浦)新一代的i.MX 95系列应用处理器正式进入量产阶段,而作为其重要的生态合作伙伴,飞凌嵌入式也同步发布了基于该系列芯片的全新核心板。这…...

在Trae 运行、调试这个项目的时候,我发现有些python子进程内存占用超过32G,导致系统内存跑超到100% 。是否项目存在内存泄漏的隐患?我应该怎么让Trae去处理呢?请给我发给Trae的指令
先上结论:Trae一如既往的好用!yan的repo:yan:基于 Python 生态的中文函数式编程语言项目 - AtomGit | GitCode 先问Dumate问题 在Windows10 用Trae 运行、调试yan这个中文编程项目的时候,我发现有些python子进程内存占用超过32G…...

【软考高级架构】论文范文21——论Kappa架构在大数据平台中的设计与应用
论Kappa架构在大数据平台中的设计与应用 摘要 随着大数据技术的快速发展,传统Lambda架构因需要同时维护批处理和流处理两套系统,导致开发复杂度高、数据口径不一致、运维成本大等问题日益突出。Kappa架构作为一种精简的统一处理范式,通过将数据全部视为流、以消息队列为核…...

地平线旭日X3派边缘AI开发板深度体验:从开箱到模型部署实战
1. 项目概述:当“地平线”升起时,我们看到了什么?最近几年,如果你关注边缘计算、机器人或者智能驾驶,那么“地平线”这个名字你一定不陌生。它早已不是那个遥远的天际线,而是成为了国内AI芯片领域一个响当当…...