PyTorch使用Tricks:学习率衰减 !!
文章目录
在训练神经网络时,如果学习率过大,优化算法可能会在最优解附近震荡而无法收敛;如果学习率过小,优化算法的收敛速度可能会非常慢。因此,一种常见的策略是在训练初期使用较大的学习率来快速接近最优解,然后逐渐减小学习率,使得优化算法可以更精细地调整模型参数,从而找到更好的最优解。
通常学习率衰减有以下的措施:
- 指数衰减:学习率按照指数的形式衰减,每次乘以一个固定的衰减系数,可以使用 torch.optim.lr_scheduler.ExponentialLR 类来实现,需要指定优化器和衰减系数。
- 固定步长衰减:学习率每隔一定步数(或者epoch)就减少为原来的一定比例,可以使用 torch.optim.lr_scheduler.StepLR 类来实现,需要指定优化器、步长和衰减比例。
- 多步长衰减:学习率在指定的区间内保持不变,在区间的右侧值进行一次衰减,可以使用 torch.optim.lr_scheduler.MultiStepLR 类来实现,需要指定优化器、区间列表和衰减比例。
- 余弦退火衰减:学习率按照余弦函数的周期和最值进行变化,可以使用 torch.optim.lr_scheduler.CosineAnnealingLR 类来实现,需要指定优化器、周期和最小值。
- 自适应学习率衰减:这种策略会根据模型的训练进度自动调整学习率,可以使用 torch.optim.lr_scheduler.ReduceLROnPlateau 类来实现。例如,如果模型的验证误差停止下降,那么就减小学习率;如果模型的训练误差上升,那么就增大学习率。
- 自适应函数实现学习率调整:不同层不同的学习率。
1、指数衰减
指数衰减是一种常用的学习率调整策略,其主要思想是在每个训练周期(epoch)结束时,将当前学习率乘以一个固定的衰减系数(gamma),从而实现学习率的指数衰减。这种策略可以帮助模型在训练初期快速收敛,同时在训练后期通过降低学习率来提高模型的泛化能力。
在PyTorch中,可以使用 torch.optim.lr_scheduler.ExponentialLR 类来实现指数衰减。该类的构造函数需要两个参数:一个优化器对象和一个衰减系数。在每个训练周期结束时,需要调用ExponentialLR 对象的 step() 方法来更新学习率。
以下是一个使用 ExponentialLR代码示例:
import torch
from torch.optim import SGD
from torch.optim.lr_scheduler import ExponentialLR# 假设有一个模型参数
model_param = torch.nn.Parameter(torch.randn(2, 2, requires_grad=True))# 使用SGD优化器,初始学习率设置为0.1
optimizer = SGD([model_param], lr=0.1)# 创建ExponentialLR对象,衰减系数设置为0.9
scheduler = ExponentialLR(optimizer, gamma=0.9)# 在每个训练周期结束时,调用step()方法来更新学习率
for epoch in range(100):# 这里省略了模型的训练代码# ...# 更新学习率scheduler.step()在这个例子中,初始的学习率是0.1,每个训练周期结束时,学习率会乘以0.9,因此学习率会按照指数的形式衰减。
2、固定步长衰减
固定步长衰减是一种学习率调整策略,它的原理是每隔一定的迭代次数(或者epoch),就将学习率乘以一个固定的比例,从而使学习率逐渐减小。这样做的目的是在训练初期使用较大的学习率,加快收敛速度,而在训练后期使用较小的学习率,提高模型精度。
PyTorch提供了 torch.optim.lr_scheduler.StepLR 类来实现固定步长衰减,它的参数有:
- optimizer:要进行学习率衰减的优化器,例如 torch.optim.SGD 或 torch.optim.Adam等。
- step_size:每隔多少隔迭代次数(或者epoch)进行一次学习率衰减,必须是正整数。
- gamma:学习率衰减的乘法因子,必须是0到1之间的数,表示每次衰减为原来的 gamma倍。
- last_epoch:最后一个epoch的索引,用于恢复训练的状态,默认为-1,表示从头开始训练。
- verbose:是否打印学习率更新的信息,默认为False。
下面是一个使用 torch.optim.lr_scheduler.StepLR 类的具体例子,假设有一个简单的线性模型,使用 torch.optim.SGD 作为优化器,初始学习率为0.1,每隔5个epoch就将学习率乘以0.8,训练100个epoch:
import torch
import matplotlib.pyplot as plt# 定义一个简单的线性模型
class Net(torch.nn.Module):def __init__(self):super(Net, self).__init__()self.fc = torch.nn.Linear(1, 1)def forward(self, x):return self.fc(x)# 创建模型和优化器
model = Net()
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)# 创建固定步长衰减的学习率调度器
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=5, gamma=0.8)# 记录学习率变化
lr_list = []# 模拟训练过程
for epoch in range(100):# 更新学习率scheduler.step()# 记录当前学习率lr_list.append(optimizer.param_groups[0]['lr'])# 绘制学习率曲线
plt.plot(range(100), lr_list, color='r')
plt.xlabel('Epoch')
plt.ylabel('Learning Rate')
plt.show()学习率在每个5个epoch后都会下降为原来的0.8倍,直到最后接近0。
固定步长衰减和指数衰减都是学习率衰减的策略,但它们在衰减的方式和速度上有所不同:
- 固定步长衰减:在每隔固定的步数(或epoch)后,学习率会减少为原来的一定比例。这种策略的衰减速度是均匀的,不会随着训练的进行而改变。
- 指数衰减:在每个训练周期(或epoch)结束时,学习率会乘以一个固定的衰减系数,从而实现学习率的指数衰减。这种策略的衰减速度是逐渐加快的,因为每次衰减都是基于当前的学习率进行的。
3、多步长衰减
多步长衰减是一种学习率调整策略,它在指定的训练周期(或epoch)达到预设的里程碑时,将学习率减少为原来的一定比例。这种策略可以在模型训练的关键阶段动态调整学习率。
在PyTorch中,可以使用 torch.optim.lr_scheduler.MultiStepLR 类来实现多步长衰减。以下是一个使用 MultiStepLR 的代码示例:
import torch
import torch.optim as optim
from torch.optim.lr_scheduler import MultiStepLR# 假设有一个简单的模型
model = torch.nn.Linear(10, 2)
optimizer = optim.SGD(model.parameters(), lr=0.1)# 创建 MultiStepLR 对象,设定在第 30 和 80 个 epoch 时学习率衰减为原来的 0.1 倍
scheduler = MultiStepLR(optimizer, milestones=[30, 80], gamma=0.1)# 在每个训练周期结束时,调用 step() 方法来更新学习率
for epoch in range(100):# 这里省略了模型的训练代码# ...# 更新学习率scheduler.step()在这个例子中,初始的学习率是0.1,当训练到第30个epoch时,学习率会变为0.01(即0.1*0.1),当训练到第80个epoch时,学习率会再次衰减为0.001(即0.01*0.1)。
4、余弦退火衰减
余弦退火衰减是一种学习率调整策略,它按照余弦函数的周期和最值来调整学习率。在PyTorch中,可以使用 torch.optim.lr_scheduler.CosineAnnealingLR 类来实现余弦退火衰减。
以下是一个使用 CosineAnnealingLR 的代码示例:
import torch
import torch.nn as nn
from torch.optim.lr_scheduler import CosineAnnealingLR
import matplotlib.pyplot as plt# 假设有一个简单的模型
class SimpleModel(nn.Module):def __init__(self):super(SimpleModel, self).__init__()self.linear = nn.Linear(10, 2)model = SimpleModel()
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)# 创建 CosineAnnealingLR 对象,周期设置为 10,最小学习率设置为 0.01
scheduler = CosineAnnealingLR(optimizer, T_max=10, eta_min=0.01)lr_list = []
# 在每个训练周期结束时,调用 step() 方法来更新学习率
for epoch in range(100):# 这里省略了模型的训练代码# ...# 更新学习率scheduler.step()lr_list.append(optimizer.param_groups[0]['lr'])# 绘制学习率变化曲线
plt.plot(range(100), lr_list)
plt.xlabel('Epoch')
plt.ylabel('Learning Rate')
plt.title("Learning rate schedule: CosineAnnealingLR")
plt.show()在这个例子中,初始的学习率是0.1,学习率会按照余弦函数的形式在0.01到0.1之间变化,周期为10个epoch。
5、自适应学习率衰减
自适应学习率衰减是一种学习率调整策略,它会根据模型的训练进度自动调整学习率。例如,如果模型的验证误差停止下降,那么就减小学习率;如果模型的训练误差上升,那么就增大学习率。在PyTorch中,可以使用 torch.optim.lr_scheduler.ReduceLROnPlateau 类来实现自适应学习率衰减。
以下是一个使用 ReduceLROnPlateau 的代码示例:
import torch
import torch.nn as nn
from torch.optim.lr_scheduler import ReduceLROnPlateau# 假设有一个简单的模型
model = nn.Linear(10, 2)
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)# 创建 ReduceLROnPlateau 对象,当验证误差在 10 个 epoch 内没有下降时,将学习率减小为原来的 0.1 倍
scheduler = ReduceLROnPlateau(optimizer, 'min', patience=10, factor=0.1)# 模拟训练过程
for epoch in range(100):# 这里省略了模型的训练代码# ...# 假设有一个验证误差val_loss = ...# 在每个训练周期结束时,调用 step() 方法来更新学习率scheduler.step(val_loss)6、自定义函数实现学习率调整:不同层不同的学习率
可以通过为优化器提供一个参数组列表来实现对不同层使用不同的学习率。每个参数组是一个字典,其中包含一组参数和这组参数的学习率。
以下是一个具体的例子,假设有一个包含两个线性层的模型,想要对第一层使用学习率0.01,对第二层使用学习率0.001:
import torch
import torch.nn as nn
import torch.optim as optim# 定义一个包含两个线性层的模型
class SimpleModel(nn.Module):def __init__(self):super(SimpleModel, self).__init__()self.layer1 = nn.Linear(10, 2)self.layer2 = nn.Linear(2, 10)model = SimpleModel()# 创建一个参数组列表,每个参数组包含一组参数和这组参数的学习率
params = [{'params': model.layer1.parameters(), 'lr': 0.01},{'params': model.layer2.parameters(), 'lr': 0.001}]# 创建优化器
optimizer = optim.SGD(params)# 现在,当调用 optimizer.step() 时,第一层的参数会使用学习率 0.01 进行更新,第二层的参数会使用学习率 0.001 进行更新在这个例子中,首先定义了一个包含两个线性层的模型。然后,创建一个参数组列表,每个参数组都包含一组参数和这组参数的学习率。最后创建了一个优化器SGD,将这个参数组列表传递给优化器。这样,当调用 optimizer.step() 时,第一层的参数会使用学习率0.01进行更新,第二层的参数会使用学习率0.001进行更新。
参考:深度图学习与大模型LLM
相关文章:
PyTorch使用Tricks:学习率衰减 !!
文章目录 前言 1、指数衰减 2、固定步长衰减 3、多步长衰减 4、余弦退火衰减 5、自适应学习率衰减 6、自定义函数实现学习率调整:不同层不同的学习率 前言 在训练神经网络时,如果学习率过大,优化算法可能会在最优解附近震荡而无法收敛&#x…...
10MARL深度强化学习 Value Decomposition in Common-Reward Games
文章目录 前言1、价值分解的研究现状2、Individual-Global-Max Property3、Linear and Monotonic Value Decomposition3.1线性值分解3.2 单调值分解 前言 中心化价值函数能够缓解一些多智能体强化学习当中的问题,如非平稳性、局部可观测、信用分配与均衡选择等问题…...

2 Nacos适配达梦数据库实现方案
1、修改源代码方式 Nacos 原生是不支持达梦数据库的,所以就要想办法让它 “支持”,因为是开源软件,我们可以从源码入手,在流行的 1.x 、2.x 或最新版本代码的基本上进行修改。 主要涉及到以下内容的修改: com/alibaba/nacos/persistence/datasource/ExternalDataS...
【Gitea】配置 Push To Create
引 在 Git 代码管理工具使用过程中,经常需要将一个文件夹作为仓库上传到一个未创建的代码仓库。如果 Git 服务端使用的是 Gitea,通常会推送失败。 PS D:\tmp\git-test> git remote add origin http://192.1.1.1:3000/root/git-test.git PS D:\tmp\g…...
)
关于postgresql数据库单独设置某个用户日志级别(日志审计)
前言: 很多时候我们想让数据库日志打印详细一点,但是又担心会对数据库本身产生一些不可控的影响,还会担心数据库产生的庞大的日志导致主机资源不太够用的影响。那么今天我们就通过讲解给单个用户设置 log_statement来解决以上这些问题。 注…...
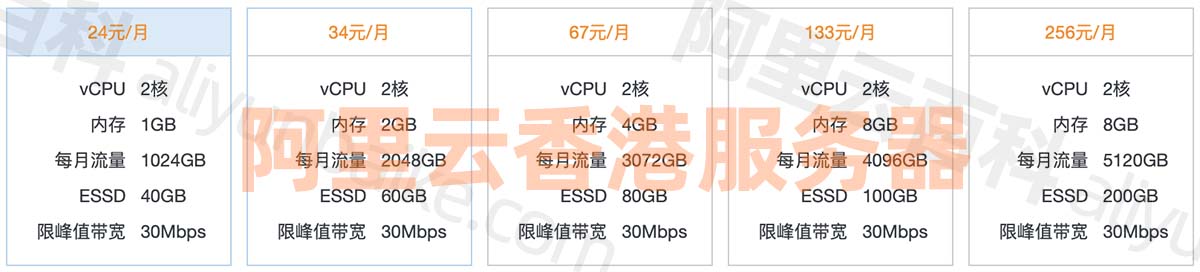
阿里云ECS香港服务器性能强大、cn2高速网络租用价格表
阿里云香港服务器中国香港数据中心网络线路类型BGP多线精品,中国电信CN2高速网络高质量、大规格BGP带宽,运营商精品公网直连中国内地,时延更低,优化海外回中国内地流量的公网线路,可以提高国际业务访问质量。阿里云服务…...
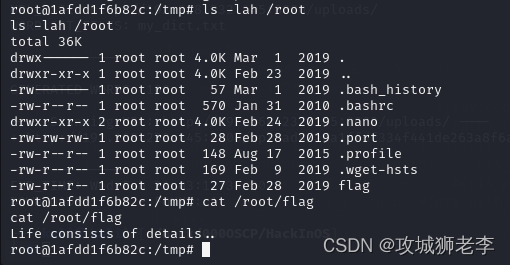
实战打靶集锦-025-HackInOS
文章目录 1. 主机发现2. 端口扫描3. 服务枚举4. 服务探查5. 提权5.1 枚举系统信息5.2 探索一下passwd5.3 枚举可执行文件5.4 查看capabilities位5.5 目录探索5.6 枚举定时任务5.7 Linpeas提权 靶机地址:https://download.vulnhub.com/hackinos/HackInOS.ova 1. 主机…...
.forEach()和list.forEach()的区别)
list.stream().forEach()和list.forEach()的区别
list.stream().forEach() 和 list.forEach() 在 Java 中都是用于遍历集合元素的方法,但它们在使用场景和功能上有所不同: list.forEach(): 是从 Java 8 开始引入到 java.util.List 接口的标准方法。直接对列表进行迭代,它采用内部…...
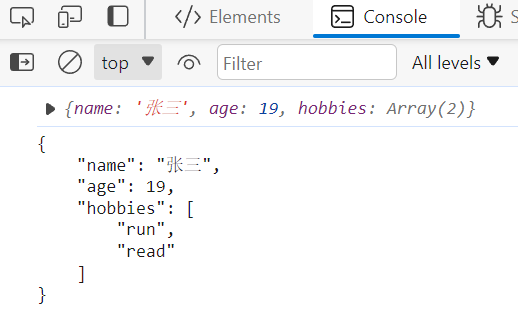
JS基础之JSON对象
JS基础之JSON对象 目录 JS基础之JSON对象对象转JSON字符串JSON转JS对象 对象转JSON字符串 JSON.stringify(value,replacer,space) value:要转换的JS对象 replacer:(可选)用于过滤和转换结果的函数或数组 space:(可选)指定缩进量 // 创建JS对象 let date {name:"张三…...
嵌入式学习之Linux入门篇——使用VMware创建Unbuntu虚拟机
目录 主机硬件要求 VMware 安装 安装Unbuntu 18.04.6 LTS 新建虚拟机 进入Unbuntu安装环节 主机硬件要求 内存最少16G 硬盘最好分出一个单独的盘,而且最少预留200G,可以使用移动固态操作系统win7/10/11 VMware 安装 版本:VMware Works…...

大模型中的token是什么?
定义 大模型的"token"是指在自然语言处理(NLP)任务中,模型所使用的输入数据的最小单元。这些token可以是单词、子词或字符等,具体取决于模型的设计和训练方式。 大模型的token可以是单词级别的,也可以是子…...
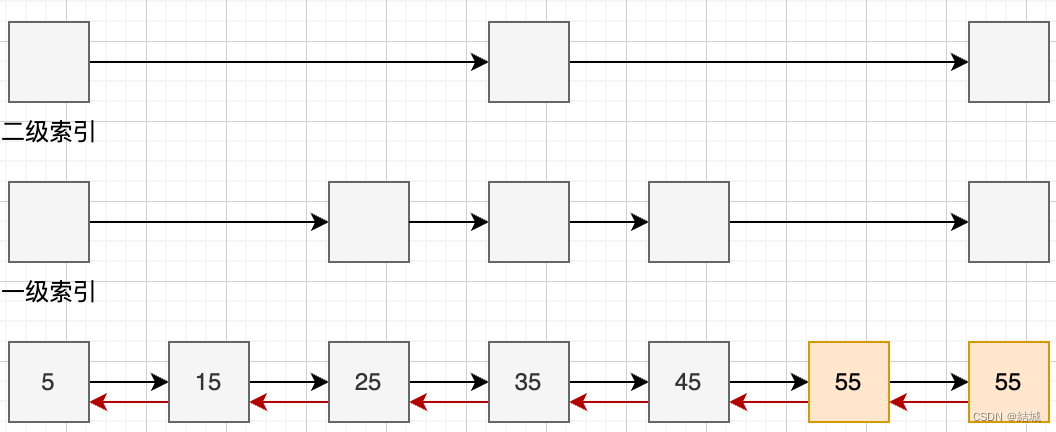
跳表是一种什么样的数据结构
跳表是有序集合的底层数据结构,它其实是链表的一种进化体。正常链表是一个接着一个用指针连起来的,但这样查找效率低只有O(n),为了解决这个问题,提出了跳表,实际上就是增加了高级索引。朴素的跳表指针是单向的并且元素…...

【刷题记录】最大公因数,最小公倍数(辗转相除法、欧几里得算法)
本系列博客为个人刷题思路分享,有需要借鉴即可。 1.题目链接: 无 2.详解思路: 题目描述:输入两个正整数,输出其最大公因数和最小公倍数 一般方法:最大公因数:穷加法;最小公倍数&…...
ETL快速拉取物流信息
我国作为世界第一的物流大国,但是在目前的物流信息系统还存在着几大的痛点。主要包括以下几个方面: 数据孤岛:有些物流企业各个部门之间的数据标准不一致,难以实现数据共享和协同,容易导致信息孤岛。 操作繁琐&#x…...
)
17.1 SpringMVC框架_SpringMVC入门与数据绑定(❤❤)
17.1 SpringMVC框架_SpringMVC入门与数据绑定 1. SpringMVC入门1.1 MVC介绍1.2 环境配置1. 依赖引入2. web配置文件:DispatchServlet配置3. applicationContext.xml配置4. 开发Controller控制器(❤❤)1.3 MVC处理流程图2. Spring MVC数据绑定2.1 URL Mapping2.2 URL Mapping三个…...
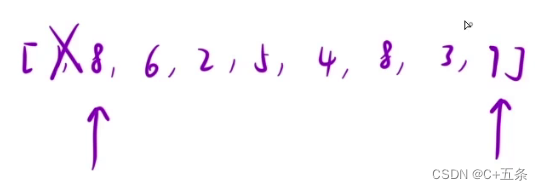
Leetcode 11.盛水最多的容器
题目 给定一个长度为 n 的整数数组 height 。有 n 条垂线,第 i 条线的两个端点是 (i, 0) 和 (i, height[i]) 。 找出其中的两条线,使得它们与 x 轴共同构成的容器可以容纳最多的水。 返回容器可以储存的最大水量。 说明:你不能倾斜容器。…...

《Go 简易速速上手小册》第7章:包管理与模块(2024 最新版)
文章目录 7.1 使用 Go Modules 管理依赖 - 掌舵向未来7.1.1 基础知识讲解7.1.2 重点案例:Web 服务功能描述实现步骤扩展功能7.1.3 拓展案例 1:使用数据库功能描述实现步骤扩展功能7.1.4 拓展案例 2:集成 Redis 缓存功能描述实现步骤...

【论文精读】IBOT
摘要 掩码语言建模(MLM)是一种流行的语言模型预训练范式,在nlp领域取得了巨大的成功。然而,它对视觉Transformer (ViT)的潜力尚未得到充分开发。为在视觉领域延续MLM的成功,故而探索掩码图像建模(MIM),以训练更好的视觉transforme…...

Yolo V5在实时视频流中的建筑物与彩钢房检测:性能评估与改进方法
Yolo V5在实时视频流中的建筑物与彩钢房检测:性能评估与改进方法 文章目录 Yolo V5在实时视频流中的建筑物与彩钢房检测:性能评估与改进方法概述Yolo V5模型概述建筑物与彩钢房检测的挑战实时视频流处理流程模型性能评估改进方法实验与分析结论与展望 概…...
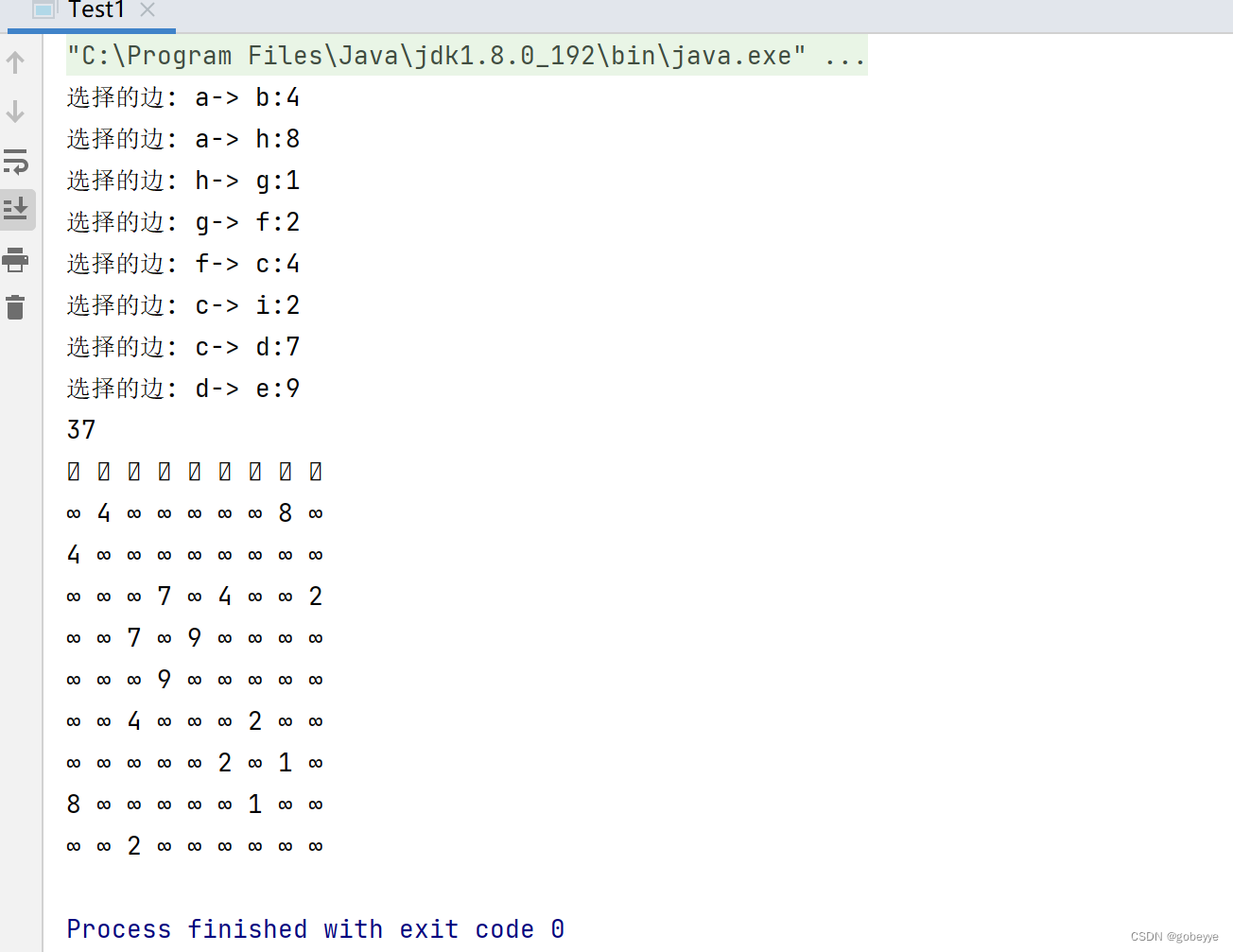
图——最小生成树实现(Kruskal算法,prime算法)
目录 预备知识: 最小生成树概念: Kruskal算法: 代码实现如下: 测试: Prime算法 : 代码实现如下: 测试: 结语: 预备知识: 连通图:在无向图…...

别再乱配了!Modbus Slave模拟器与iPlat点表地址映射的保姆级避坑指南
Modbus Slave模拟器与工业平台联调实战:从地址映射原理到批量读取优化 工业物联网项目中,Modbus协议作为最常用的数据采集标准,其配置过程看似简单却暗藏玄机。我曾亲眼见过一个资深工程师花了三天时间排查数据采集失败问题,最终发…...

高级逆向工程分析:PC微信小程序wxapkg加密算法深度解析与实现
高级逆向工程分析:PC微信小程序wxapkg加密算法深度解析与实现 【免费下载链接】pc_wxapkg_decrypt_python PC微信小程序 wxapkg 解密 项目地址: https://gitcode.com/gh_mirrors/pc/pc_wxapkg_decrypt_python PC微信小程序逆向工程工具提供了精准的wxapkg加密…...

VisualCppRedist AIO:一站式解决Windows C++运行库依赖问题
VisualCppRedist AIO:一站式解决Windows C运行库依赖问题 【免费下载链接】vcredist AIO Repack for latest Microsoft Visual C Redistributable Runtimes 项目地址: https://gitcode.com/gh_mirrors/vc/vcredist Visual C运行库是Windows系统中许多应用程序…...
)
protobufjs 编译命令选错就报错?一文搞懂 pbjs 的 -w 参数(es6 vs commonjs 实战解析)
ProtobufJS编译模块类型选型指南:ES6与CommonJS的深度对比与实战避坑 最近在Vite项目中集成Protobuf时,编译后的模块导入总是抛出The requested module does not provide an export named错误。这个问题困扰了我整整两天,最终发现根源在于pbj…...

PotPlayer百度翻译插件终极指南:免费实现20+语言实时字幕翻译
PotPlayer百度翻译插件终极指南:免费实现20语言实时字幕翻译 【免费下载链接】PotPlayer_Subtitle_Translate_Baidu PotPlayer 字幕在线翻译插件 - 百度平台 项目地址: https://gitcode.com/gh_mirrors/po/PotPlayer_Subtitle_Translate_Baidu PotPlayer字幕…...

ClaudeCode安装与使用全攻略
一、安装 Claude Code 1. 安装 Claude Code 1.1 安装 Git 根据需求选择对应的安装方式: https://git-scm.com/book/zh/v2/%E8%B5%B7%E6%AD%A5-%E5%AE%89%E8%A3%85-Git windows 版本下载地址: https://git-scm.com/install/windows 1.2 安装 node…...
)
告别模型水土不服:用TENT的熵最小化,5分钟搞定测试时域自适应(附PyTorch代码)
实战TENT:5行代码解决模型部署中的“水土不服”问题 想象一下这样的场景:你花费数月训练的自动驾驶视觉模型在实验室测试中准确率高达98%,但当它遇到真实世界的暴雨天气时,识别率瞬间暴跌至60%。这种"实验室王者,…...

用C#给PowerMill做个外挂:手把手教你写第一个连接与断开PM的WinForm工具
用C#打造PowerMill效率工具:从零构建自动化控制面板 在CNC编程工程师的日常工作中,PowerMill作为行业领先的CAM软件,其强大的功能背后也隐藏着大量重复性操作。每天数十次的项目打开关闭、连接状态检查、刀具路径查询等机械式点击,…...

别再手动刷纹理了!用Blender 3.6的镂版映射,5分钟给苹果模型贴上真实贴图
别再手动刷纹理了!Blender 3.6镂版映射实战指南 在数字艺术创作中,给3D模型添加纹理是赋予物体真实感的关键步骤。许多Blender初学者在掌握了基础UV展开后,往往会陷入手动绘制纹理的低效循环——用笔刷一点一点"涂抹"贴图ÿ…...

MCP39F501电能计量芯片:高精度单相计量方案与工程实践详解
1. 项目概述:为什么我们需要一颗专用的电能计量芯片?在智能家居、工业物联网和新能源领域,精确测量交流电(AC)的用电参数——比如电压、电流、功率、电能——是底层最核心的需求之一。你可能觉得,用个高精度…...