【论文精读】IBOT
摘要
掩码语言建模(MLM)是一种流行的语言模型预训练范式,在nlp领域取得了巨大的成功。然而,它对视觉Transformer (ViT)的潜力尚未得到充分开发。为在视觉领域延续MLM的成功,故而探索掩码图像建模(MIM),以训练更好的视觉transformer,使其可以像NLP一样作为标准组件。
MLM最关键的问题是语言标记器(lingual tokenizer),其功能是将语言分成语义上有意义的标记。类似,MIM的关键也在于视觉标记器(vision tokenizer)的设计,以及实际要训练的目标网络(target network)。但是,由于图像的连续特性,视觉语义的提取非常困难,故而以往Beit等算法都是分步先计算tokenizer,在根据tokenizer训练target network。然而,由于获取视觉语义是tokenizer和target network的共同目的,理论上两者可联合优化。

本文提出iBOT,即用online tokenizer进行图像BERT预训练。通过将MIM制定为知识蒸馏(KD)来激励iBOT,使target network学会从tokenizer中提取知识(知识蒸馏)。具体,目标网络用masked图像作为输入,而online tokenizer用原始图像作为输入。 目标是让target network将每个masked patch token恢复到其相应的tokenizer输出(上图)。归纳为:
- tokenizer通过对[CLS] token执行跨视图图像的相似性来逐步学习高级视觉语义
- 所提出的tokenizer不需要额外预处理,其通过EMA与MIM联合优化
框架

掩码图像建模(MIM)
给定图像token patches x = { x i } i = 1 N x=\{{x_i}\}^N_{i=1} x={xi}i=1N,MIM首先根据预测比率 r r r采样一组随机mask m ∈ { 0 , 1 } N m \in \{ {0,1}\}^N m∈{0,1}N,其中 N N N是token的数量。对于patch token x i x_i xi、若对应 m i = 1 m_i=1 mi=1,则masked patch token表示为 x ˜ ≜ { x i ∣ m i = 1 } \~{x} \triangleq\{ { x_i |m_i=1} \} x˜≜{xi∣mi=1} ,对应位置用mask token e [ M A S K ] e_{[MASK]} e[MASK]替换,则生成损坏的图像 x ^ ≜ { x ^ i ∣ ( 1 − m i ) x i + m i e [ M A S K ] } i = 1 N \hat x \triangleq\{ {\hat x_i |(1-m_i)x_i+m_ie_{[MASK]}} \}^N_{i=1} x^≜{x^i∣(1−mi)xi+mie[MASK]}i=1N。此时,MIM的目标是从损坏的图像 x ^ \hat x x^中恢复masked patch token x ˜ \~{x} x˜, 故目标为最大化:
l o g q θ ( x ˜ ∣ x ^ ) ≈ ∑ i = 1 N m i ⋅ l o g q θ ( x i ∣ x ^ ) log \ q_{\theta}(\~{x}|\hat x)≈\sum^N_{i=1}m_i \cdot log \ q_{\theta}(x_i|\hat x) log qθ(x˜∣x^)≈i=1∑Nmi⋅log qθ(xi∣x^)
其中 ≈ ≈ ≈具有独立性假设,即每个mask token 可以单独重建。
在BEiT中, q θ q_{\theta} qθ被建模为分类分布,任务是最小化:
− ∑ i = 1 N m i ⋅ P ϕ ( x i ) T log P θ ( x ^ i ) -\sum^N_{i=1}m_i \cdot P_{\phi}(x_i)^T \log P_{\theta}(\hat x_i) −i=1∑Nmi⋅Pϕ(xi)TlogPθ(x^i)
其中 P ( ⋅ ) P(\cdot) P(⋅)将输入转换为 K K K维概率分布, ϕ \phi ϕ是离散VAE的参数,该参数将图像patch聚类为 K K K个类别,并为每个patch token分配一个识别其类别的one-hot编码。这种损失的表述类似于知识蒸馏,其中知识从由 ϕ \phi ϕ参数化的前缀 tokenizer蒸馏到由 θ \theta θ参数化的模型。
自蒸馏
类似于DINO,给定训练集 I I I,均匀采样图像 x ∼ I x \sim I x∼I。对 x x x应用两个随机增强,产生两个扭曲视图 u u u和 v v v放入一个教师-学生框架中,以从[CLS] token: v t [ C L S ] = P θ ′ [ C L S ] ( v ) v^{[CLS]}_t=P^{[CLS]}_{θ'} (v) vt[CLS]=Pθ′[CLS](v)、 u t [ C L S ] = P θ [ C L S ] ( u ) u^{[CLS]}_t=P^{[CLS]}_\theta(u) ut[CLS]=Pθ[CLS](u)中获得预测类别分布。知识通过最小化交叉熵从教师向学生传递,表示为:
L [ C L S ] = − P θ ′ [ C L S ] ( v ) T log P θ [ C L S ] ( u ) L_{[CLS]}=-P_{\theta'}^{[CLS]}(v)^T \log P_{\theta}^{[CLS]}(u) L[CLS]=−Pθ′[CLS](v)TlogPθ[CLS](u)
其中教师和学生共享一个主干网络 f f f和一个投影头 h [ C L S ] h^{[CLS]} h[CLS] 架构。教师网络 θ ′ θ' θ′通过学生网络 θ \theta θ的参数指数移动平均(EMA)学习。
iBOT
整体框架如图3。结合MIM和自蒸馏方法,框架包含patch tokens和CLS两部分。
patch tokens部分在两个增强视图 u u u和 v v v执行blockwise masking(同BEiT)得到masked views u ^ \hat u u^和 v ^ \hat v v^。输入教师-学生网络后,学生网络输出其patch tokens的masked view u ^ \hat u u^的投影 u ^ s p a t c h = P θ p a t c h ( u ^ ) \hat u^{patch}_s=P^{patch}_\theta(\hat u) u^spatch=Pθpatch(u^),教师网络输出其patch tokens的non-masked view u u u的投影 u t p a t c h = P θ ′ p a t c h ( u ) u_t^{patch}=P^{patch}_{θ'}(u) utpatch=Pθ′patch(u)。在此将MIM在iBOT中的训练目标定义为:
L M I M = − ∑ i = 1 N m i ⋅ P θ ′ p a t c h ( u i ) T log P θ p a t c h ( u ^ i ) L_{MIM}=-\sum^N_{i=1}m_i \cdot P_{\theta'}^{patch}(u_i)^T \log P_{\theta}^{patch}(\hat u_i) LMIM=−i=1∑Nmi⋅Pθ′patch(ui)TlogPθpatch(u^i)
同样的方法可得到 v ^ s p a t c h \hat v^{patch}_s v^spatch和 v t p a t c h v_t^{patch} vtpatch的损失,这两项求和平均后可得到最终的 L M I M L_{MIM} LMIM。故教师骨干网络和投影头 h t p a t c h ⋅ f t h^{patch}_t \cdot f_t htpatch⋅ft是一个visual tokenizer,其为每个学生网络的masked patch token生成online token分布。iBOT中使用的tokenizer可以联合到MIM目标,故其的特征是可以从当前数据集中提取领域知识,而不是到指定的数据集。
CLS部分,为了确保online tokenizer具有语义意义,故需对跨视图图像的[CLS] token进行自蒸馏学习,以便其获得视觉语义。在实践中,采用DINO的 L [ C L S ] L_{[CLS]} L[CLS] 训练,且使用 u ^ s [ C L S ] \hat u_s^{[CLS]} u^s[CLS]、 v ^ s [ C L S ] \hat v_s^{[CLS]} v^s[CLS]为学生网络的输入。为了进一步采用从[CLS]上自蒸馏获得的语义抽象能力,可共享CLS和patch tokens的投影头参数,令 h s [ C L S ] = h s p a t c h h^{[CLS]}_s=h_s^{patch} hs[CLS]=hspatch、 h t [ C L S ] = h t p a t c h h^{[CLS]}_t=h_t^{patch} ht[CLS]=htpatch,其比使用单独的头产生更好的结果。最后的监督信号使用softmax之后的token分布。
算法伪代码

训练配置
骨干网络使用具有不同数量参数的Vision transformer和Swin transformer, ViT-S/16、ViT-B/16、ViT-L/16和Swin-t/{7,14}。 对于ViT/16表示patch大小为16。对于Swin-s/{7,14}表示窗口大小为7或14。使用224大小的图像对transformer进行预训练和微调,因此patch token的总数量为196。投影头 h h h是3层mlp,在DINO之后有 l 2 − n o r m a l i z e d l_2-normalized l2−normalized。模型共享CLS和patch tokens的投影头参数,共享头的输出维度设置为8192。
使用AdamW优化器和1024的batchsize在ImageNet-1K上预训练iBOT,ViT-S/16预训练iBOT为800 epoch, ViT-B/16为400 epoch, ViT-L/16为250 epoch, Swin-T/{7,14}为300 epoch。在ImageNet-22K上预训练则,ViT-B/16用80 epoch, ViT-L/16用50 epoch。学习率在第一个10 epoch期间线性上升到其基值,并随总批处理大小缩放: l r = 5 e − 4 × b a t c h s i z e / 256 lr=5e^{-4} \times batchsize/256 lr=5e−4×batchsize/256。使用随机MIM,0.5的概率将预测率 r r r设置为0,另外0.5的概率并从范围[0.1, 0.5]中均匀采样。总loss将 L [ C L S ] L_{[CLS]} L[CLS]和 L M I M L_{MIM} LMIM相加,不进行缩放。
实验
定量对比

上图显示iBOT与其他sota无监督算法在ImageNet上的线性检测精度,相比与ResNet类算法,iBOT可在同等规模参数下得到更高的精度。

上图为KNN和线性检测结合iBOT在ImageNet预训练上的测试结果。观察到ViT-S/16达到了77.9%的线性检测精度;ViT-B/16的线性检测精度为79.5%;ViT-L/16的线性检测精度为81.0%,KNN精度为78.0%,实现了最先进的性能。使用Swin-T/{7,14},iBOT分别实现了78.6%和79.3%的线性检测精度。
使用ViT-L/16和ImageNet-22K作为预训练数据,iBOT进一步实现了线性检测精度82.3%,超过EsViT的Swin-B/14达到的81.3%;ViT-B/16的线性检测精度为79.5%,与SimCLRv2的79.8%相当,但参数量少10%。
随着参数的增加,与DINO相比的性能提升更大(0.9%w/ ViT-S vs 1.3%w/ ViT-B),这表明iBOT对更大的模型更具可扩展性。

上图为研究在ImageNet-1K上的微调并重点比较transformer的自监督方法及其监督基准线。
如表2:iBOT分别在ViT-S/16, ViT-B/16和ViT-L/16上取得了82.3%,84.0%和84.8%的top-1准确率。
如表3:iBOT用ImageNet-22K预训练的ViT-B/16和ViT-L/16分别实现了84.4%和86.6%的top-1精度,比ImageNet-22K预训练的BEiT分别高出0.7%和0.6%。当在512的图像大小上进行微调时,达到了87.8%的准确率。使用ViT-L/16,iBOT在使用1K数据时比BEiT差0.4%,但在使用22K数据时好0.6%,意味着iBOT在更多的数据来训练更大的模型可达到更好的性能。

上图比较了遵循无监督预训练、有监督微调范式的各种方法。iBOT在使用ImageNet-1K1%和10%的数据时,比DINO分别提高了1.6% 和0.8%,表明具有更高的标签效率。

上图对无监督学习测试,使用标准的评估指标,包括精度(ACC)、调整随机指数(ARI)、归一化互信息(NMI)和Fowlkes-Mallows指数(FMI)。将 iBOT与SimCLRv2、Self-label、InfoMin和SCAN进行了比较。实现了32.8% 的NMI,比之前的最先进水平高出1.8%,表明MIM有助于模型在全局范围内学习更强的视觉语义。

上图在COCO上测试目标检测与实例分割及在ADE20K的测试语义分割。目标检测和实例分割需要同时进行目标定位和分类,级联Mask R-CNN可以在COCO数据集上同时产生边界框和实例掩码。
左图对比有监督Swin-T 及其自监督对应对象MoBY的结果,该结果与有监督ViT-S/16类似的结果。iBOT则将ViT-S的 A P b AP^b APb从46.2提高到49.4, A P m AP^m APm从40.1提高到42.6,超过了有监督的swit、ViT-S/16和自监督MoBY。图右对比ViT-B/16,iBOT有51.2 A P b AP^b APb,44.2 A P m AP^m APm,大大超过了以前的最好成绩。
语义分割是像素级别的分类问题,主要在ADE20K数据集上测试。 可以看到iBOT在ViT-S/16上以0.9mIoU的差距提高了其监督基线,且超过了Swin-T。通过ViT-B/16,iBOT用UperNet将之前的最佳方法DINO提高了3.2mIoU。 注意到使用线性头的BEiT的性能下降,这表明BEiT的特征缺乏局部语义。与具有线性头的监督基线在mIoU上相比,iBOT强局部语义的特性产生了2.9mIoU的增益。

上图测试了迁移学习。iBOT在ImageNet-1K上进行预训练,在几个较小的数据集上进行微调。观察到虽然在几个数据集(CIFAR10、CIFAR100、Flowers和Cars)上的结果几乎停滞不前,但iBOT与其他SSL框架相比始终表现良好,实现了最先进的迁移结果。
在更大的数据集(如iNaturalist18和iNaturalist19)中,观察到比DINO更大的性能提升。对于更大的模型,比DINO获得更大的性能增益(在iNaturalist18上ViT/S-16为1.7%,而在iNaturalist18上ViT/B-16为2.0%,在iNaturalist19上ViT/S-16为0.3%,而在iNaturalist19上ViT/B-16为1.0%)。
模式布局


上图4可视化在ImageNet-1K验证集上自蒸馏的投影头置信度最高的patch token,模型采用800 epoch预训练的ViT-S/16,并为每个 16 × 16 16 \times 16 16×16 patch可视化5倍上下文(橙色)。可以观察到高级语义和低级细节的出现,左1、2观察到高级语义大灯和狗耳,3、4突出了低级纹理。
相对比,图16从BEiT和DINO的patch提取的布局中,虽然可以看到更复杂的纹理,但大多数补丁共享类似的局部细节,而不是高级语义。
自注意力判别

用ViT-S/16可视化自注意力图,选择[CLS] token作为查询,并使用不同颜色可视化最后一层不同头部的注意力图。观察到iBOT分离不同对象或一个对象的不同部分的能力。在最左边的图中, iBOT明显地区别了鸟和树枝。iBOT注意力主要集中在物体的区分部分(汽车的轮子,鸟的喙)。这些属性对于iBOT擅长图像识别至关重要,特别是在有物体遮挡或分散注意力的情况下。

上图显示iBOT最后一层的多个头部的自注意力图可视化。与DINO相比,iBOT提供更细致的可视化结果,在视觉上显示出更强的分离不同物体或一个物体的不同部分的能力。例如,在第五列中,iBOT中有一个注意力头,只负责狐狸的耳朵;在第八列中,iBOT将蘑菇分成语义上更有意义的部分。

Correspondence between two views of one image是从一幅图像的两个视图中采样的图像对,在比例和颜色上增强。观察到从iBOT中提取的图像间语义匹配大部分正确。
Correspondence between two images of one class是从一个类别的两幅图像中采样的图像对。第一行具有显著物体但大小、位置和纹理不同的图像。第二行来自动物的图像,可以更清楚地观察到iBOT正确匹配了动物的语义部分(狐狸的尾巴,鸟的喙)。第三行以人体或服装为中心的图像。第四行是自然或家庭场景,其中显著的物体是不可见的。虽然没有明确的语义部分可以匹配到人类的理解,但仍然可以观察到iBOT可以根据它们的纹理或颜色,招牌和盒子的木质纹理)提取语义对应。这些可视化结果表明iBOT在局部尺度上具有很强的局部检索和匹配能力。
鲁棒性

上图从3方面对鲁棒性进行了定量测试:背景变化、遮挡和out-of-distribution的例子,用ViT-S/16在800 epoch进行了预训练,然后对100 epoch进行了线性评估。
对于背景变化,在ImageNet-9 (IN-9)数据集上研究7种变化类型下的图像。IN-9通过混合不同图像的前景和背景,包括9种粗粒度类和7种变体。Only-FG (O.F.)、Mixed-Same (M.S.)、Mixed-Rand (M.R.)和Mixed-Next (M.N.)原始前景存在,但背景被修改;而No-FG (N.F.)、Only-BG-B (O.BB.)和Only-BG-T (O.BT.)前景被掩盖。观察到除了O.BT以外的性能相比DINO全部得到提升。表明iBOT对背景变化具有鲁棒性。
对于遮挡,研究了信息损失率为0.5下显著性和非显著性斑块下降的线性精度,iBOT在这两种设置下的性能下降较小。
对于out-of-distribution的例子,研究了ImageNet-A 中的自然对抗样本和ImageNet-C 中的图像损坏,iBOTImageNet-A上有更高的准确性,在ImageNet-C上有更小的平均损坏误差(mCE)。

上图实验提供了在三种丢弃设置下(随机、显著和非显著)不同信息损失率的图像遮挡鲁棒性研究结果。展示了iBOT端到端微调或在预训练骨干上用线性头的结果。包括了ViT-S/16和ResNet-50的监督结果以进行比较。
与CNN对应的ResNet-50相比,ViT显示出更高的鲁棒性,因为transformer的动态感受野使其较少依赖于图像的空间结构。经验发现iBOT与其监督基线相比,对遮挡具有更强的鲁棒性,MIM有助于用自注意力对图像块序列之间的相互作用进行建模,使得丢弃部分元素不会显著降低性能。

上图实验对输入图像patch块打乱来研究模型对空间结构的敏感性。展示了iBOT端到端微调或在预训练骨干上用线性头的结果,包括了ViT-S/16和ResNet-50的监督结果以进行比较。(打乱网格大小1表示没有打乱,打乱网格大小196表示所有patch token都打乱了)
观察到iBOT比其监督基线和ResNet-50保持更好的准确性,表明iBOT更少地依赖于位置嵌入来保持正确的分类决策的全局图像上下文。
消融实验

上图消融研究了使用300 epoch预训练的ViT-S/16的语义有意义的tokenizer的重要性,该tokenizer的预测比率为 r = 0.3 r=0.3 r=0.3,且不进行 Multi-Crop增强。
iBOT通过跨视图图像 L [ C L S ] L_{[CLS]} L[CLS]对[CLS] token进行自蒸馏,以获得视觉语义。为了验证该设置的有效性,在没有 L [ C L S ] L_{[CLS]} L[CLS]的情况下执行MIM,或使用其他模型作为视觉tokenizer。 ◦ ◦ ◦表示单独使用DINO, △ △ △表示预训练的DALL-E编码器。
观察到,在没有 L [ C L S ] L_{[CLS]} L[CLS]的情况下执行MIM会导致9.5%KNN精度和29.8%的线性精度的不良结果,这表明仅使用MIM很难获得视觉语义。虽然DINO作为tokenizer会出现视觉语义,但其没有达到一个不错的结果(KNN的准确率为44.3%vs69.1%)。 将iBOT与DINO和BEiT (DINO+BEiT)的多任务处理进行比较,看到将自蒸馏获得的视觉语义与tokenizer合并的优势,iBOT在线性探测方面有11.5%的提高,在微调方面有0.3%的提高。根据经验观察到使用[CLS] token和patch token的共享投影头(SH)可实现性能改进,因为其将[CLS] token中获得的语义共享给MIM。
reference
Zhou, J. , Wei, C. , Wang, H. , Shen, W. , Xie, C. , & Yuille, A. , et al. (2021). Ibot: image bert pre-training with online tokenizer. arXiv e-prints.
相关文章:
【论文精读】IBOT
摘要 掩码语言建模(MLM)是一种流行的语言模型预训练范式,在nlp领域取得了巨大的成功。然而,它对视觉Transformer (ViT)的潜力尚未得到充分开发。为在视觉领域延续MLM的成功,故而探索掩码图像建模(MIM),以训练更好的视觉transforme…...

Yolo V5在实时视频流中的建筑物与彩钢房检测:性能评估与改进方法
Yolo V5在实时视频流中的建筑物与彩钢房检测:性能评估与改进方法 文章目录 Yolo V5在实时视频流中的建筑物与彩钢房检测:性能评估与改进方法概述Yolo V5模型概述建筑物与彩钢房检测的挑战实时视频流处理流程模型性能评估改进方法实验与分析结论与展望 概…...
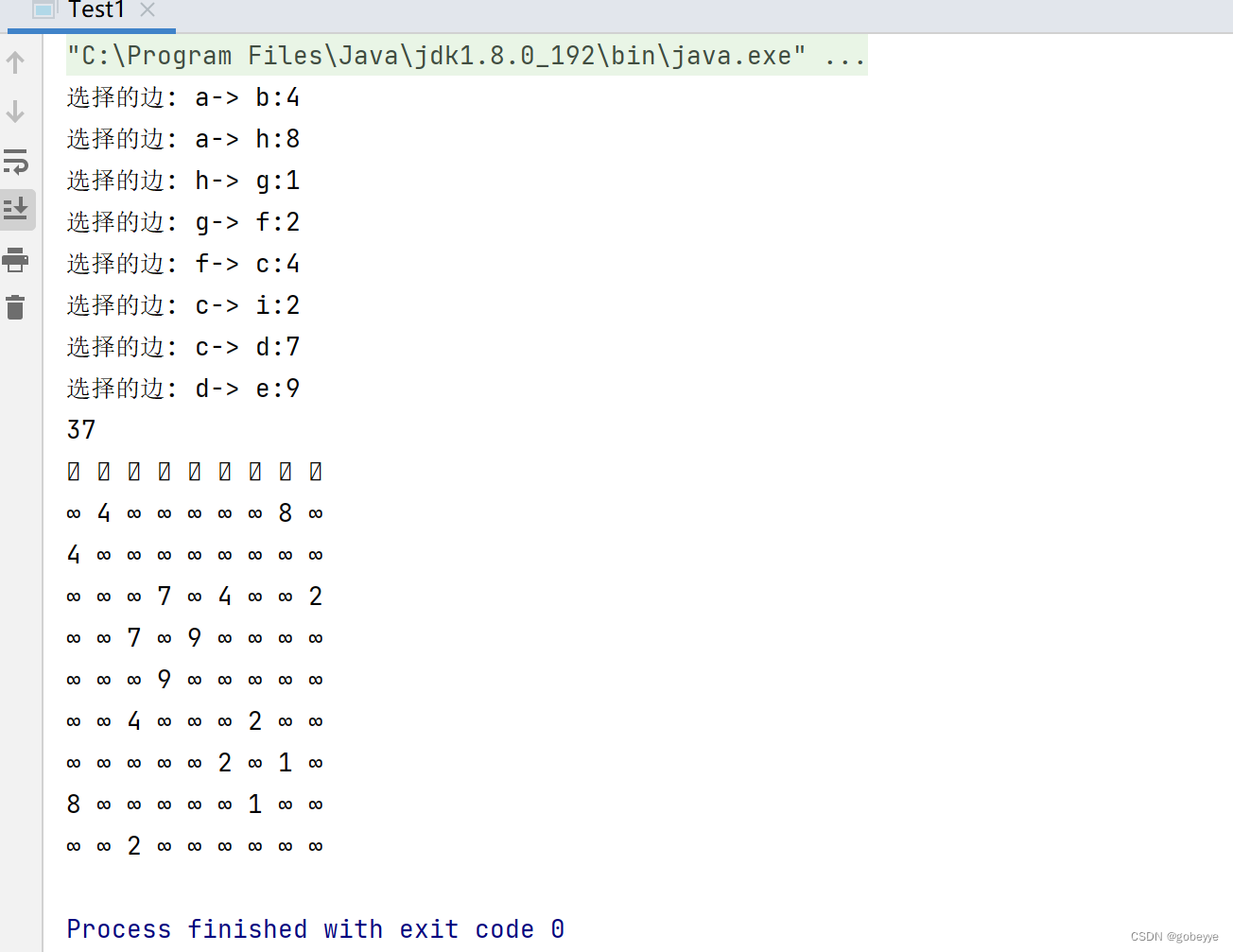
图——最小生成树实现(Kruskal算法,prime算法)
目录 预备知识: 最小生成树概念: Kruskal算法: 代码实现如下: 测试: Prime算法 : 代码实现如下: 测试: 结语: 预备知识: 连通图:在无向图…...

Unity3D xLua开发环境搭建详解
前言 xLua是一种基于Lua语言的开发框架,可以帮助开发者在Unity3D中使用Lua脚本来开发游戏。 对惹,这里有一个游戏开发交流小组,希望大家可以点击进来一起交流一下开发经验呀! 在本文中,我们将详细介绍如何搭建Unity…...
.init(root)的作用)
Python笔记-super().init(root)的作用
假设我们有一个名为Animal的父类,它有一个属性color,在其构造函数__init__中被初始化: class Animal:def __init__(self, color):self.color color现在,我们想创建一个Animal的子类,名为Dog。Dog类有自己的属性name&…...
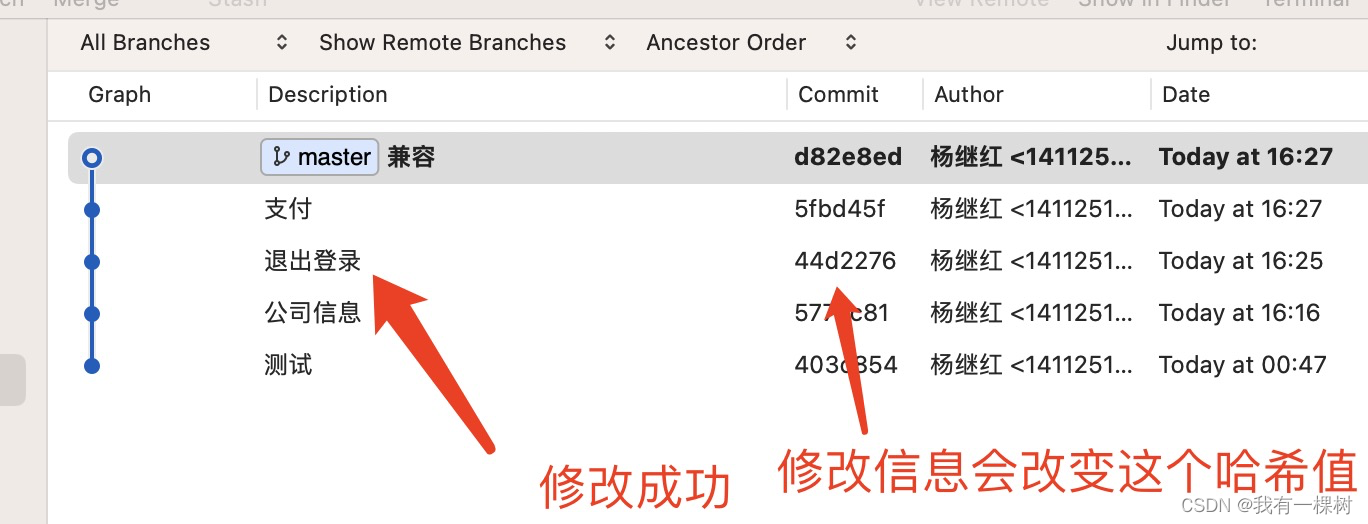
【git 使用】使用 git rebase -i 修改任意的提交信息/合并多个提交
修改最近一次的提交信息的方法有很多,可以参考这篇文章,但是对于之前的提交信息进行修改只能使用 rebase。 修改提交信息 假设我们想修改下面这个提交信息,想把【登录】改成【退出登录】步骤如下 运行 git rebase -i head~3 打开了一个文本…...

【Vue3】toRefs和toRef在reactive中的一些应用
💗💗💗欢迎来到我的博客,你将找到有关如何使用技术解决问题的文章,也会找到某个技术的学习路线。无论你是何种职业,我都希望我的博客对你有所帮助。最后不要忘记订阅我的博客以获取最新文章,也欢…...
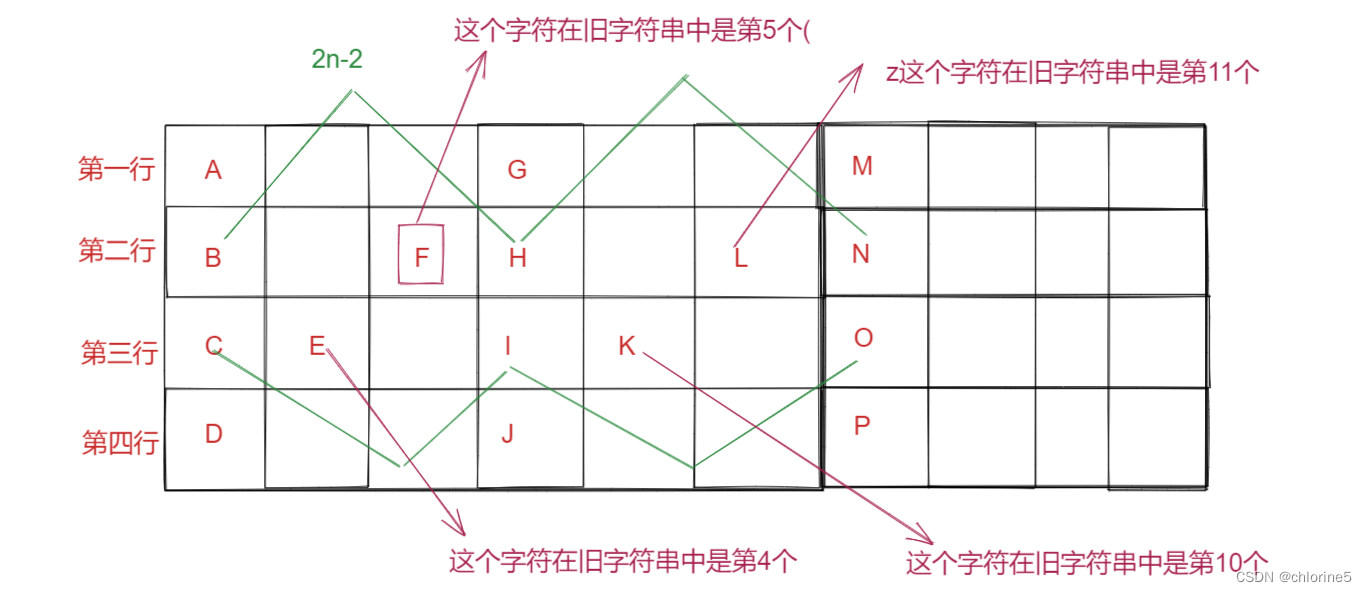
力扣精选算法100道——Z字形变换(模拟专题)
目录 🎈了解题意 🎈算法原理 🚩先处理第一行和最后一行 🚩再处理中间行 🎈实现代码 🎈了解题意 大家看到这个题目的时候肯定是很迷茫的,包括我自己也是搞不清楚题目什么意思,我…...
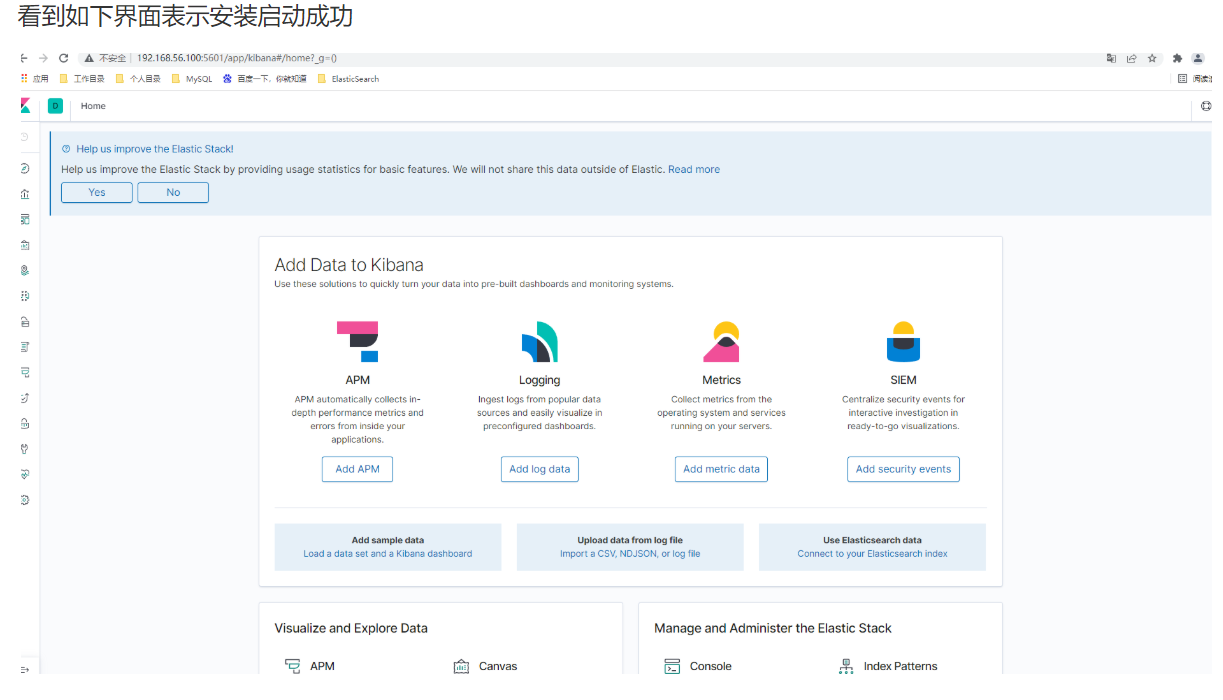
Elastic Stack--01--简介、安装
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 1. Elastic Stack 简介为什么要学习ESDB-Engines搜索引擎类数据库排名常年霸榜
.NET项目web自动化测试实战——Selenium 2.0
🔥 交流讨论:欢迎加入我们一起学习! 🔥 资源分享:耗时200小时精选的「软件测试」资料包 🔥 教程推荐:火遍全网的《软件测试》教程 📢欢迎点赞 👍 收藏 ⭐留言 …...

【Day53】代码随想录之动态规划_买卖股票ⅠⅡ
文章目录 动态规划理论基础动规五部曲:出现结果不正确: 1. 买卖股票的最佳时机2. 买卖股票的最佳时机Ⅱ 动态规划理论基础 动规五部曲: 确定dp数组 下标及dp[i] 的含义。递推公式:比如斐波那契数列 dp[i] dp[i-1] dp[i-2]。初…...
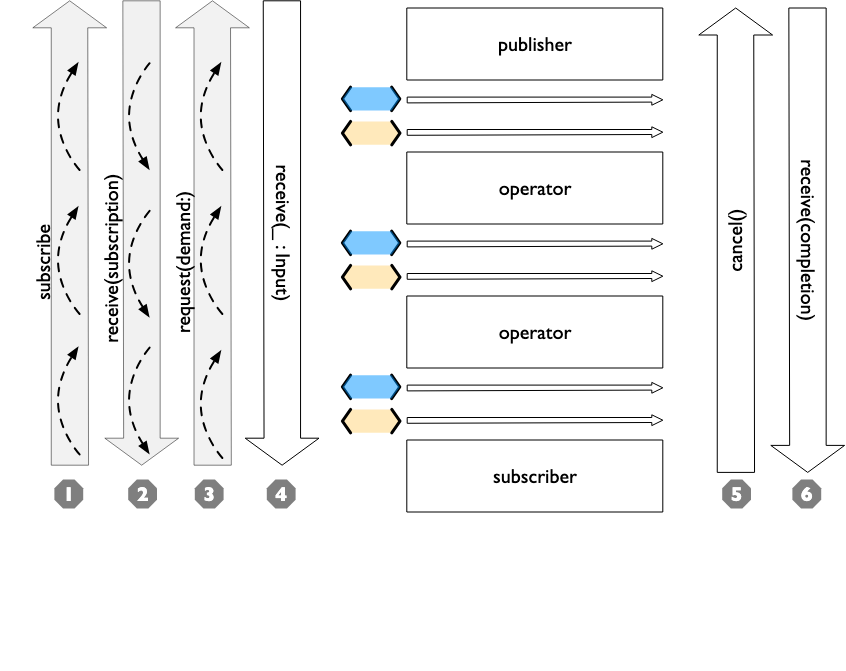
Swift Combine 使用调试器调试管道 从入门到精通二十六
Combine 系列 Swift Combine 从入门到精通一Swift Combine 发布者订阅者操作者 从入门到精通二Swift Combine 管道 从入门到精通三Swift Combine 发布者publisher的生命周期 从入门到精通四Swift Combine 操作符operations和Subjects发布者的生命周期 从入门到精通五Swift Com…...

go内置库函数实现client与server数据的发送接收
功能:客户端持续写入数据,直到输入exit退出,服务端读取数据并打印 注意:server和client目录在同一层级 服务端 server/main package mainimport ("fmt""net" )func main() {listen, err : net.Listen(&quo…...
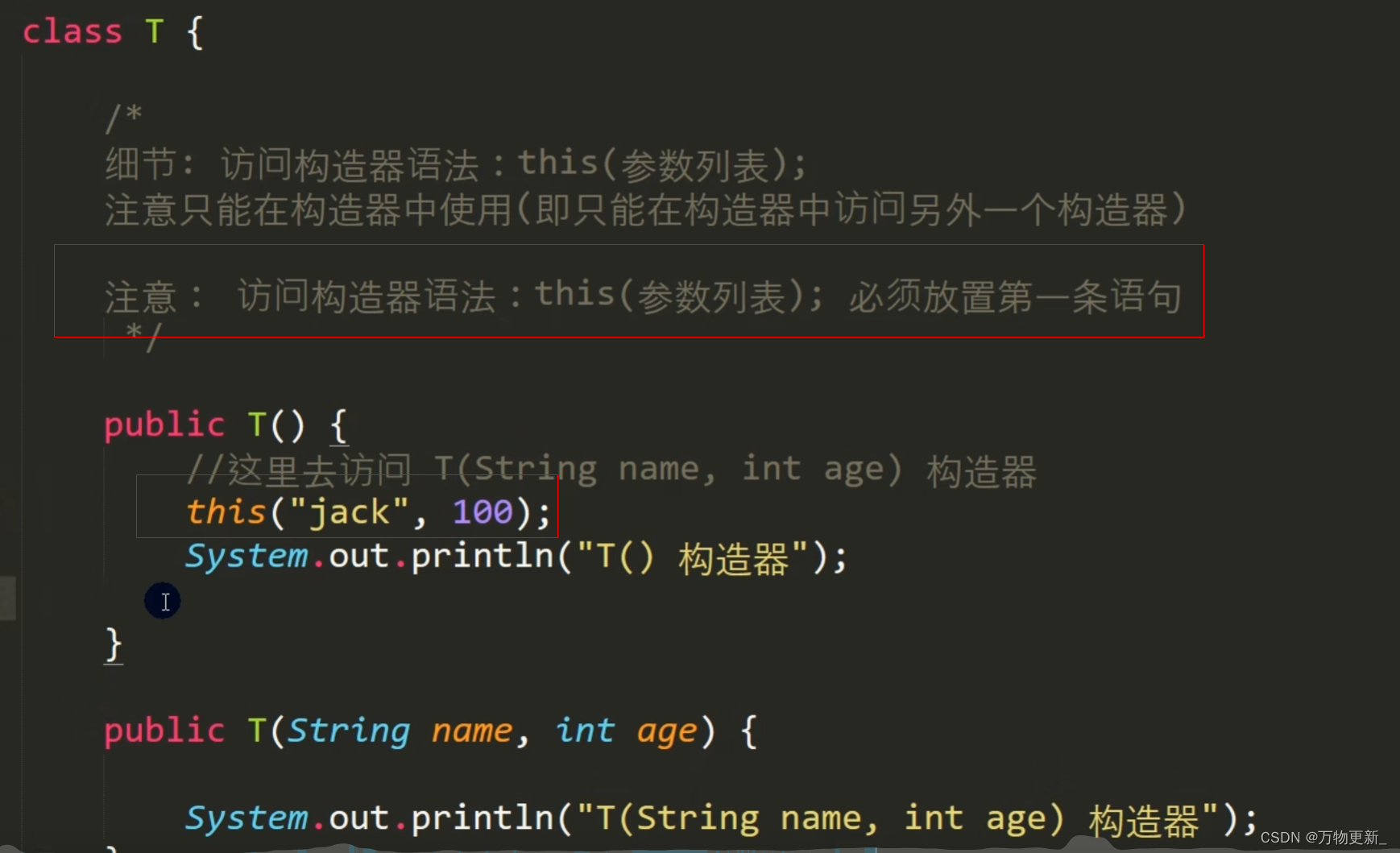
[java基础揉碎]this
引出this: 什么是this: java虚拟机会给每个对象分配 this,代表当前对象。 这里的this就是new出来的这个对象 this的本质: this是个引用在堆中指向它自己: this的细节: 访问成员方法: 访问构造器:...

vulnhub靶场之Deathnote
一.环境搭建 1.靶场描述 Level - easy Description : dont waste too much time thinking outside the box . It is a Straight forward box . This works better with VirtualBox rather than VMware 2.靶场下载 https://www.vulnhub.com/entry/deathnote-1,739/ 3.启动环…...

Docker安装Postgresql12
1、搜索仓库中postgres docker search postgres 2、拉取镜像 docker pull postgres docker pull postgres:12 #拉取12版本的PG库 3、创建数据库文件夹 cd /temp/ && mkdir -m 755 postgres-data 注:-m表示权限,类chmod命令 4、执行命令启动…...

服务器防火墙的应用技术有哪些类型?
随着互联网的发展,网络安全问题更加严峻。服务器防火墙技术作为一种基础的网络安全技术,对于保障我们的网络安全至关重要。本文将介绍服务器防火墙的概念和作用,以及主要的服务器防火墙技术,包括数据包过滤、状态检测、代理服务、…...

IP地理位置查询定位:技术原理与实际应用
在互联网时代,IP地址是连接世界的桥梁,而了解IP地址的地理位置对于网络管理、个性化服务以及安全监控都至关重要。IP数据云将深入探讨IP地理位置查询定位的技术原理、实际应用场景以及相关的隐私保护问题,旨在为读者提供全面了解和应用该技术…...

hbuilder运行不了php文件是什么原因?
如果 HBuilder 无法运行 PHP 文件,可能是由于以下几个常见原因导致的: 未安装 PHP 解释器: HBuilder 需要安装 PHP 解释器才能运行 PHP 文件。请确保您的系统中已经安装了 PHP,并且已正确配置了环境变量。 PHP 解释器路径错误&…...
)
C++从入门到精通 第十六章(STL常用算法)
写在前面: 本系列专栏主要介绍C的相关知识,思路以下面的参考链接教程为主,大部分笔记也出自该教程,笔者的原创部分主要在示例代码的注释部分。除了参考下面的链接教程以外,笔者还参考了其它的一些C教材(比…...
了!用Celery的Canvas原语(Group/Chain/Chord)构建复杂异步工作流)
别再只会用delay()了!用Celery的Canvas原语(Group/Chain/Chord)构建复杂异步工作流
别再只会用delay()了!用Celery的Canvas原语构建复杂异步工作流 在异步任务处理领域,Celery早已成为Python生态中的标配工具。但令人惊讶的是,大多数开发者仅仅停留在task.delay()的基础用法上,就像只学会了加减法却从未接触过微积…...

长波双色InAs/GaSb超晶格红外探测器芯片:从材料设计到焦平面集成
1. 项目概述:从“双色”到“芯片”的技术跨越在红外探测领域,追求“看得更清、看得更远、看得更准”是永恒的主题。我们这次要聊的“长/长波双色InAs/GaSb超晶格焦平面探测器芯片”,听起来名字很长很专业,但它本质上解决的是一个非…...

为什么你的扑克策略总在关键牌局失效?Desktop Postflop给你答案
为什么你的扑克策略总在关键牌局失效?Desktop Postflop给你答案 【免费下载链接】desktop-postflop [Development suspended] Advanced open-source Texas Holdem GTO solver with optimized performance 项目地址: https://gitcode.com/gh_mirrors/de/desktop-po…...
)
告别手动注册!用Inno Setup为你的C# SolidWorks插件制作一键安装包(附VS生成后事件脚本)
从代码到产品:用Inno Setup打造SolidWorks插件的专业安装体验 在SolidWorks二次开发领域,许多开发者投入大量精力完善插件功能,却在最后交付环节草草了事——简单复制DLL文件搭配批处理脚本的方式,不仅显得业余,更给终…...

drf-nested-routers测试指南:确保嵌套路由稳定性的完整方案
drf-nested-routers测试指南:确保嵌套路由稳定性的完整方案 【免费下载链接】drf-nested-routers Nested Routers for Django Rest Framework 项目地址: https://gitcode.com/gh_mirrors/dr/drf-nested-routers drf-nested-routers是Django Rest Framework的…...

从零构建YOLOv8火焰烟雾检测系统:GUI开发、模型训练与实战部署全解析
1. 项目背景与核心价值 火焰烟雾检测在工业安全、森林防火和智能家居等领域有着广泛的应用需求。传统检测方法主要依赖传感器,但存在响应慢、覆盖范围有限等问题。基于计算机视觉的解决方案能够突破物理限制,实现大范围实时监控。YOLOv8作为当前最先进的…...

CANN/asc-devkit Round接口文档
Round 【免费下载链接】asc-devkit 本项目是CANN 推出的昇腾AI处理器专用的算子程序开发语言,原生支持C和C标准规范,主要由类库和语言扩展层构成,提供多层级API,满足多维场景算子开发诉求。 项目地址: https://gitcode.com/cann…...

AI数据标注实战:如何高效、准确地标注训练数据
在AI模型的开发与迭代过程中,数据标注是连接原始数据与智能算法的关键桥梁,其质量与效率直接决定了模型的性能上限。对于软件测试从业者而言,掌握高效、准确的数据标注方法,不仅能为AI模型提供可靠的训练“食粮”,更能…...
)
从NTC103到PT100:手把手教你为Arduino和STM32选型与编程(温度传感器实战)
从NTC103到PT100:手把手教你为Arduino和STM32选型与编程(温度传感器实战) 在物联网和智能硬件项目中,温度监测是最基础也最关键的环节之一。无论是恒温箱、环境监测站还是工业控制系统,选择一款合适的温度传感器往往决…...

海底管道电伴热机理及系统建模与控制策略【附程序】
✨ 长期致力于电伴热、集肤效应、Hammerstein模型、参数辨识、约束广义预测控制算法、功率调节、场路耦合法研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1&#…...