第3.6章:StarRocks数据导入——DataX StarRocksWriter
一、Datax
1.1 DataX 3.0概述
DataX3.0是一个异构数据源离线同步工具,可以方便的对各种异构数据源进行高效的数据同步。 其github地址为:
https://github.com/alibaba/DataX/blob/master/introduction.md![]() https://github.com/alibaba/DataX/blob/master/introduction.md
https://github.com/alibaba/DataX/blob/master/introduction.md
GitCode - 开发者的代码家园![]() https://gitcode.com/alibaba/datax/overview
https://gitcode.com/alibaba/datax/overview
1.2 DataX3.0框架设计
DataX将复杂的网状的同步链路变成了星型数据链路,DataX自身作为中间传输载体负责连接各种数据源,解决了异构数据源同步问题。Datax采用的是
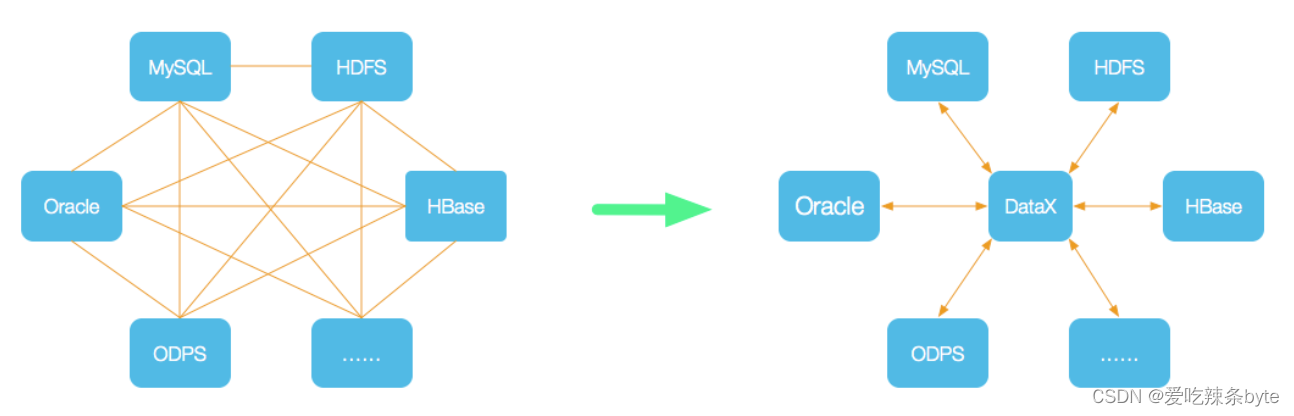
DataX本身作为离线数据同步框架,采用Framework + plugin架构构建。将数据源读取和写入抽象成为Reader/Writer插件,纳入到整个同步框架中:
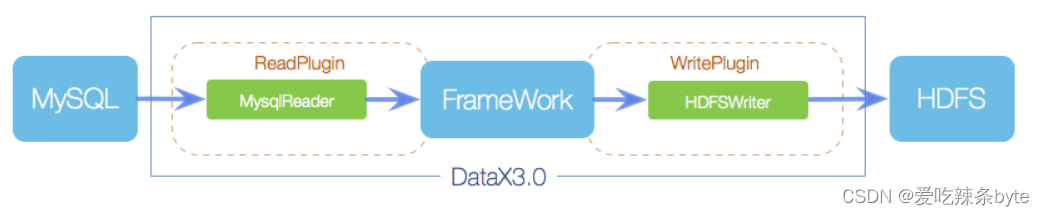
- Reader:Reader为数据采集模块,负责采集数据源的数据,将数据发送给Framework。
- Writer:Writer为数据写入模块,负责不断向Framework取数据,并将数据写入到目的端。
- Framework:Framework用于连接reader和writer,作为两者的数据传输通道,并处理缓冲,流控,并发,数据转换等核心技术问题。
1.3 DataX3.0核心架构
DataX 3.0 开源版本支持单机多线程模式完成同步作业运行。基于DataX作业生命周期的时序图,从整体架构设计角度来阐述DataX各个模块相互关系。

1.3.1 核心模块介绍
- DataX完成单个数据同步的作业,我们称之为Job,DataX接受到一个Job之后,将启动一个进程来完成整个作业同步过程。DataX Job模块是单个作业的中枢管理节点,承担了数据清理、子任务切分(将单一作业计算转化为多个子Task)、TaskGroup管理等功能。
- DataXJob启动后,会根据不同的源端切分策略,将Job切分成多个小的Task(子任务),以便于并发执行。Task便是DataX作业的最小单元,每一个Task都会负责一部分数据的同步工作。
- 切分多个Task之后,DataX Job会调用Scheduler模块,根据配置的并发数据量,将拆分成的Task重新组合,组装成TaskGroup(任务组)。每一个TaskGroup负责以一定的并发运行完毕分配好的所有Task,默认单个任务组的并发数量为5。
- 每一个Task都由TaskGroup负责启动,Task启动后,会固定启动Reader—>Channel—>Writer的线程来完成任务同步工作。
- DataX作业运行起来之后, Job监控并等待多个TaskGroup模块任务完成,等待所有TaskGroup任务完成后Job成功退出。否则,异常退出,进程退出值非0。
1.3.2 DataX调度流程
用户提交了一个DataX作业,并且配置了DataX Channel并发数为20个,需求是将一个100张分表的mysql数据同步到starrocks里面, 则DataX的调度决策思路是:
- DataXJob根据分库分表切分成了100个Task。
- 根据20个并发,DataX计算共需要分配4个TaskGroup。
- 4个TaskGroup平分切分好的100个Task,每一个TaskGroup负责以5个并发共计运行25个Task。
二、StarRocksWriter
DataX基于StarRocks开发的StarRocksWriter插件支持MySQL、Oracle等数据库中的数据导入至 StarRocks。在底层实现上,StarRocksWriter内部将各种reader读取的数据进行缓存攒批(以csv或 json格式),之后采用Stream Load 方式批量导入至 StarRocks。总体的数据流是Source -->Reader -->DataX channel --> Writer ---> StarRocks
官网文章地址:
使用 DataX 导入 | StarRocks
三、创建配置文件
为导入作业创建 JSON 格式配置文件, 这里列举几种Datax同步脚本。
(1)同步oracle数据至starrocks:oracle2starrocks.json
{"job": {"setting": {"speed": {"channel": 1},"errorLimit": {"record": 0,"percentage": 0}},"content": [{"reader": {"name": "oraclereader","parameter": {"username": "root","password": "root","connection": [{"querySql": ["select fid,f_diccode,concat(substr(qhcode,1,2),'0000') as partition_no from nannd.test1"],"jdbcUrl": ["jdbc:oracle:thin:@192.168.22.115:1521/init"]}]}},"writer": {"name": "starrockswriter","parameter": {"username": "root","password": "root","database": "","table": "test2","column": ["fid","f_diccode","partition_no"],"preSql": ["truncate table des.test2"],"postSql": [],"jdbcUrl": "jdbc:mysql://192.168.10.103:9030","loadUrl": ["192.168.10.101:8030","192.168.10.102:8030","192.168.10.103:8030"],"loadProps": {"format": "json","strip_outer_array": true}}}}]}
}- OracleReader的配置说明见:
https://github.com/alibaba/DataX/blob/master/introduction.md
https://github.com/alibaba/DataX/blob/master/oraclereader/doc/oraclereader.md
- StarRocksWriter的配置说明见:官网
使用 DataX 导入 | StarRocks

(2)同步mysql库的数据至starrocks:mysql2starrocks.json
{"job": {"setting": {"speed": {"channel": 1},"errorLimit": {"record": 0,"percentage": 0}},"content": [{"reader": {"name": "mysqlreader","parameter": {"username": "root","password": "root","column": ["OBJECTID","xmmc","shengmc","shimc","xianmc",],"connection": [{"table": ["init2.test6"],"jdbcUrl": ["jdbc:mysql://192.168.22.156:3306/init2"]}]}},"writer": {"name": "starrockswriter","parameter": {"username": "root","password": "root","database": "des3","table": "test7","column": ["OBJECTID","shengmc","shimc","xianmc",],"preSql": [],"postSql": [],"jdbcUrl": "","loadUrl": ["192.168.10.101:8030","192.168.10.102:8030","192.168.10.103:8030"],"loadProps": {"format": "json","strip_outer_array": true}}}}]}
}- MysqlReader的配置说明见:
https://github.com/alibaba/DataX/blob/master/mysqlreader/doc/mysqlreader.md
- StarRocksWriter的配置说明见:官网
(3)同步tidb库的数据至starrocks:tidb2starrocks.json
{"job": {"setting": {"speed": {"channel": 1},"errorLimit": {"record": 0,"percentage": 0}},"content": [{"reader": {"name": "mysqlreader","parameter": {"username": "root","password": "root@sq2023","connection": [{"querySql": ["select id,member_id,create_time,update_time,now() as run_dt from test2"],"jdbcUrl": ["jdbc:mysql://192.168.22.143:4000/init1"]}]}},"writer": {"name": "starrockswriter","parameter": {"username": "root","password": "root","database": "des1","table": "test3","column": ["id","member_id","create_time","update_time","run_dt"],"preSql": [],"postSql": [],"jdbcUrl": "","loadUrl": ["192.168.10.101:8030","192.168.10.102:8030","192.168.10.103:8030"],"loadProps": {"format": "json","strip_outer_array": true}}}}]}
}
ps:从tidb数据读取数据,采用的read插件还是MysqlReder,不赘述。
四、常见问题记录
4.1 常规排查方案
例如:针对配置文件job.json启动导入任务,设置JVM 调优参数(--jvm="-Xms6G -Xmx6G")以及日志等级(--loglevel=debug),日志等级用来任务失败时打印更详细的作业执行信息
python datax/bin/datax.py --jvm="-Xms6G -Xmx6G" --loglevel=debug datax/job/job.json4.2 时区问题
如果源数据库与目标数据库时区不同,需要命令行中添加 -Duser.timezone=GMTxxx 选项设置源数据库的时区信息。例如,源库使用 UTC 时区,则启动任务时需添加参数 -Duser.timezone=GMT+0
4.3 性能调优
4.3.1 合理拆分任务
合理配置任务参数,让DataX任务拆分为多个Task,同时,提升DataX Channel并发数。以mysqlreader为例,就要合理配置splitPk参数,如果splitPk不填写(包括不提供splitPk或者splitPk值为空),DataX会视作使用单通道同步该表数据。
4.3.2 配置堆内存
当提升DataX Job内Channel并发数时,内存的占用也会显著增加,因为DataX作为数据交换通道,在内存中会缓存较多的数据。例如Channel中会有一个Buffer,作为临时的数据交换的缓冲区,而在部分Reader和Writer的中,也会存在一些Buffer,为了防止OOM等错误,调大JVM的堆内存。调整JVM xms xmx参数的两种方式:一种是直接更改datax.py脚本;另一种是在启动的时候,在命令行添加对应的参数,如下:(xms:初始化堆内存; xmx:堆最大内存)
python datax/bin/datax.py --jvm="-Xms6G -Xmx6G" --loglevel=debug datax/job/job.jsonps:建议将初始化堆内存与堆最大内存配置一致,这样可以让同步数据处理起来更快,也可以避免内存的抖动。
4.3.3 任务限速
使用DataX进行数据同步的另一个优势是可以限速,进而降低同步过程中对业务库的压力影响。DataX3.0提供了包括通道(并发)、记录流、字节流三种流控模式,可以方便的控制同步作业速度,让同步作业在库可以承受的范围内达到最佳的同步速度。以最常用的字节流限速为例:
-
修改datax/conf/core.json,限制单个chanel的速度为2M (2*1024*1024= 2097152 byte):
"speed": {"byte": 2097152,},- 同时修改作业json部分的速度限制,例如限制为4M(这样任务会用4/2=2个channel并发进行任务),修改:
"job": {"setting": {"speed": {"byte" : 4194304}},...}- 以及:
"speed": {"channel": 5,"byte": 1048576,"record": 10000}4.3.4 读取StarRocks数据
StarRocks兼容MySQL协议,当我们需要将StarRocks中的数据同步至其他数据库时,可以使用mysqlreader来直接读取,但这种JDBC的方式性能可能不是很好,推荐Flink Connector或者Spark Connector来进行处理。
参考文章:
第3.5章:StarRocks数据导入--DataX StarRocksWriter_datax-starrockswriter-CSDN博客
相关文章:
第3.6章:StarRocks数据导入——DataX StarRocksWriter
一、Datax 1.1 DataX 3.0概述 DataX3.0是一个异构数据源离线同步工具,可以方便的对各种异构数据源进行高效的数据同步。 其github地址为: https://github.com/alibaba/DataX/blob/master/introduction.mdhttps://github.com/alibaba/DataX/blob/mast…...
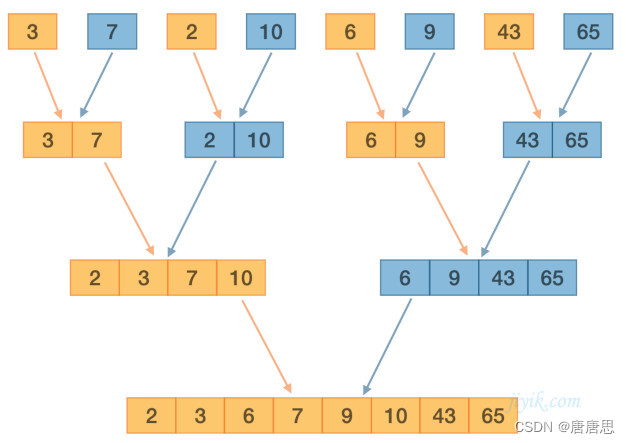
【非递归版】归并排序算法(2)
目录 MergeSortNonR归并排序 非递归&归并排序VS快速排序 整体思想 图解分析 代码实现 时间复杂度 归并排序在硬盘上的应用(外排序) MergeSortNonR归并排序 前面的快速排序的非递归实现,我们借助栈实现。这里我们能否也借助栈去…...

[C++]C++实现本地TCP通讯的示例代码
这篇文章主要为大家详细介绍了C如何利用TCP技术,实现本地ROS1和ROS2的通讯,文中的示例代码讲解详细,感兴趣的小伙伴可以跟随小编一起学习一下 概要服务端代码 头文件源代码客户端代码 概要 利用TCP技术,实现本地ROS1和ROS2的通讯。 服务端代码 头文件 #include &…...

Sora - 探索AI视频模型的无限可能
文章目录 每日一句正能量前言技术解析应用场景未来展望伦理与创意用户体验与互动后记 每日一句正能量 . 一个人,如果没有经受过投资失败的痛楚,又怎么会看到绝望之后的海阔天空。很多时候,经历了人生中最艰难的事,反而锻造了最坚强…...

【JavaScript 漫游】【022】事件模型
文章简介 本篇文章为【JavaScript 漫游】专栏的第 022 篇文章,对 JavaScript 中事件模型相关的知识点进行了总结。 监听函数 浏览器的事件模型,就是通过监听函数(listener)对事件做出反应。事件发生后,浏览器监听到…...
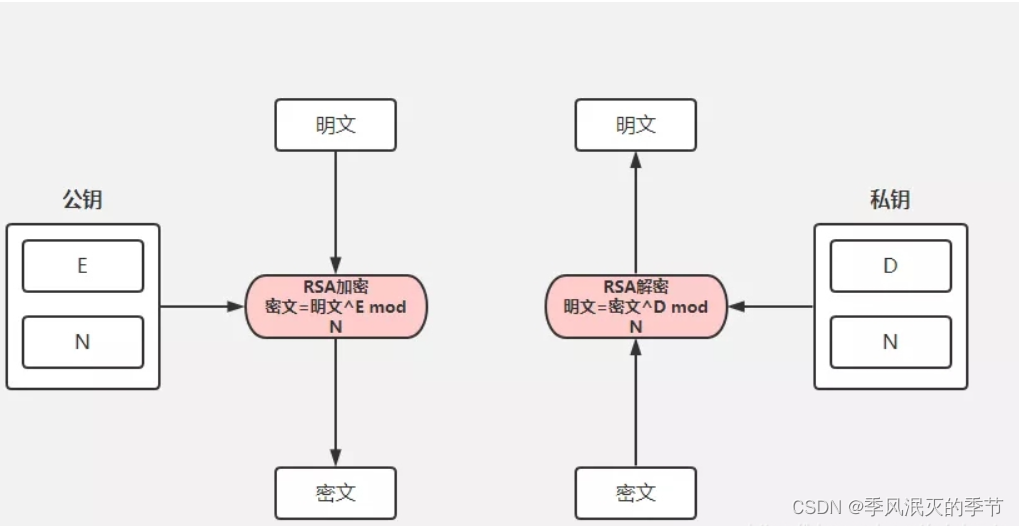
【加密算法】RSA非对称加密算法简介
目录 前言 工作原理 密钥生成 加密和解密 在Java中使用RSA 生成密钥对 加密和解密数据 加密数据 解密数据 注意事项和最佳实践 结论 前言 RSA(Rivest-Shamir-Adleman)是一种基于数论的非对称加密算法,广泛应用于数字签名、数据加密…...

深入理解 JavaScript 对象原型,解密原型链之谜(上)
🤍 前端开发工程师、技术日更博主、已过CET6 🍨 阿珊和她的猫_CSDN博客专家、23年度博客之星前端领域TOP1 🕠 牛客高级专题作者、打造专栏《前端面试必备》 、《2024面试高频手撕题》 🍚 蓝桥云课签约作者、上架课程《Vue.js 和 E…...
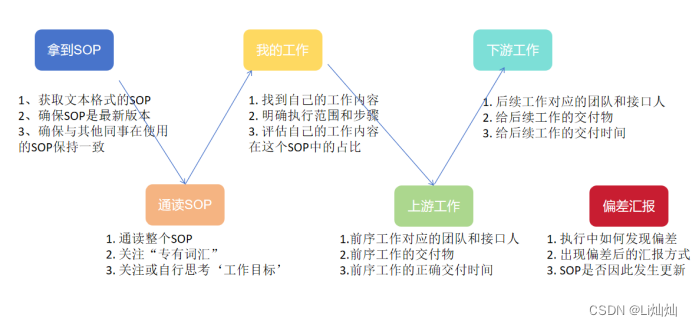
产品经理学习-产品运营《什么是SOP》
目录 什么是SOP 如何执行SOP 执行SOP的重点 什么是SOP SOP就是项目流程操作的说明书 日常工作中的例行操作: 例行操作是指,在每一天,针对每一个用户,在每个项目之中,都必须完成的操作,这些必须完成的操…...

大数据Hadoop生态圈
存储: HDFS(namenode,datanode) 计算:MapReduce(mapreduce,基于磁盘) 便于用sql操作:Hive(核心 metastore,存储这些结构化的数据),同类的还有Impala,hbase等 基于yaml的资源调度 hive &…...

算法简介:查找与算法运行时间
文章目录 1. 二分查找与简单查找1.1 运行时间 2. 旅行商问题 算法是一组完成任务的指令。任何代码片段都可以视为算法。 1. 二分查找与简单查找 二分查找是一种算法,其输入是一个有序的元素列表,如果要查找的元素包含在列表中,二分查找返回…...

零基础C++开发上位机--基于QT5.15的串口助手(三)
本系列教程本着实践的目的,争取每一节课都带大家做一个小项目,让大家多实践多试验,这样才能知道自己学会与否。 接下来我们这节课,主要学习一下QT的串口编程。做一款自己的串口助手,那么这里默认大家都是具备串口通信…...

Facebook的虚拟社交愿景:元宇宙时代的新起点
在当今数字化时代,社交媒体已经成为人们生活中不可或缺的一部分。而随着科技的不断进步和社会的发展,元宇宙已经成为了人们关注的热点话题之一。作为社交媒体的领军企业之一,Facebook也在积极探索虚拟社交的未来,将其视为元宇宙时…...

【深度学习笔记】4_6 模型的GPU计算
注:本文为《动手学深度学习》开源内容,部分标注了个人理解,仅为个人学习记录,无抄袭搬运意图 4.6 GPU计算 到目前为止,我们一直在使用CPU计算。对复杂的神经网络和大规模的数据来说,使用CPU来计算可能不够…...

留学申请过程中如何合理使用AI?大学招生官怎么看?
我们采访过的学生表示,他们在写essay的过程中会使用 ChatGPT,主要用于以下两个方面:第一,生成想法和头脑风暴;第二,拼写和语法检查。 纽约时报的娜塔莎辛格(Natasha Singer)在一篇文…...

vue2与vue3的diff算法有什么区别
在 Vue 中,虚拟 DOM 是一种重要的概念,它通过将真实的 DOM 操作转化为对虚拟 DOM 的操作,从而提高应用的性能。Vue 框架在虚拟 DOM 的更新过程中采用了 Diff 算法,用于比较新旧虚拟节点树,找出需要更新的部分ÿ…...
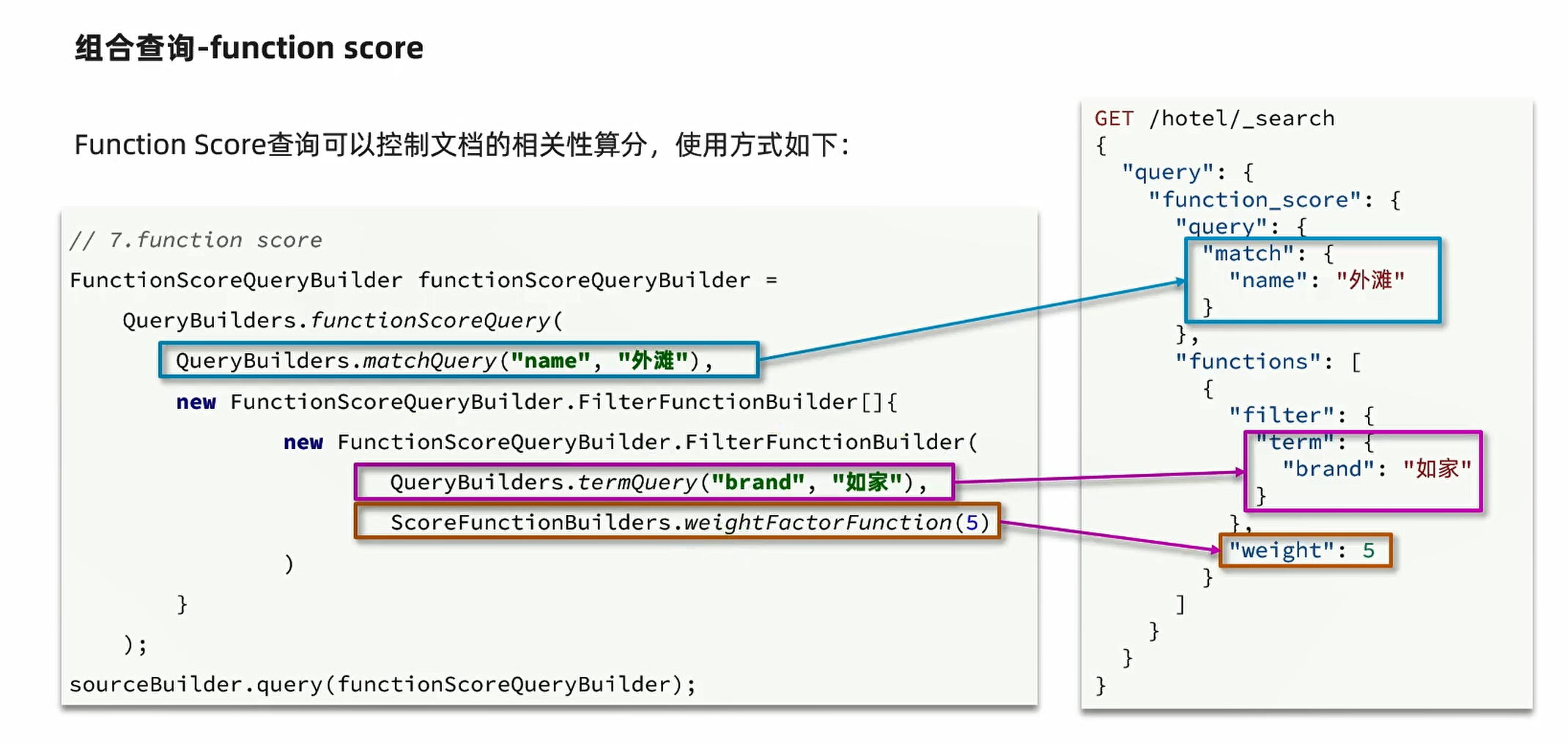
ES小总结
组合查询 FunctionScoreQueryBuilder functionScoreQuery QueryBuilders.functionScoreQuery(boolQuery,new FunctionScoreQueryBuilder.FilterFunctionBuilder[]{new FunctionScoreQueryBuilder.FilterFunctionBuilder(QueryBuilders.termQuery("isAD",true),Score…...

vue2与vue3中父子组件传参的区别
本次主要针对vue中父子组件传参所进行讲解 一、vue2和vue3父传子区别 1.vue2的父传子 1).在父组件子标签中自定义一个属性 <sonPage :子组件接收到的类名"传输的数据">子组件</sonPage> 2).在子组件中peops属性中拿到自定属性 props: {子组件接收的…...

使用vuetify实现全局v-alert消息通知
前排提示,本文为引流文,文章内容不全,更多信息前往:oldmoon.top 查看 简介 使用强大的Vuetify开发前端页面,结果发现官方没有提供简便的全局消息通知组件(像Element中的ElMessage那样)…...

CentOS 7.9上编译wireshark 3.6
工作环境是Centos 7.9,原本是通过flathub安装的wireshark,但是在gnome的application installer上升级到wireshark 4.2.3之后就运行不起来了,flatpak run org.wireshark.Wireshark启动提示缺少qt6,查了一下wireshark新版是依赖qt6的…...

初学学习408之数据结构--数据结构基本概念
初学学习408之数据结构我们先来了解一下数据结构的基本概念。 数据结构:是相互之间存在一种或多种特定关系的数据元素的集合。 本内容来源于参考书籍《大话数据结构》与《王道数据结构》。除去书籍中的内容,作为初学者的我会尽力详细直白地介绍数据结构的…...

深度探索JD-GUI:Java字节码逆向工程与代码解析实战剖析
深度探索JD-GUI:Java字节码逆向工程与代码解析实战剖析 【免费下载链接】jd-gui A standalone Java Decompiler GUI 项目地址: https://gitcode.com/gh_mirrors/jd/jd-gui 在Java开发与逆向工程领域,Java反编译、字节码分析、代码逆向已成为开发者…...

5分钟掌握PT一键转载神器:Auto Feed JS让资源分享效率提升10倍
5分钟掌握PT一键转载神器:Auto Feed JS让资源分享效率提升10倍 【免费下载链接】auto_feed_js PT站一键转载脚本 项目地址: https://gitcode.com/gh_mirrors/au/auto_feed_js 如果你是一位PT(Private Tracker)爱好者,一定经…...

【Claude Kubernetes配置终极指南】:20年SRE亲授生产环境零失误部署的7大黄金法则
更多请点击: https://intelliparadigm.com 第一章:Claude Kubernetes配置的核心理念与演进脉络 Claude 并非原生 Kubernetes 组件,而是 Anthropic 推出的大型语言模型系列;当将其部署于 Kubernetes 集群时,“Claude K…...

电子测试安全:示波器浮地测量与隔离变压器应用全解析
1. 项目概述:一次关于测试测量安全的深度探讨又到了周五,对于很多工程师来说,这可能是最想摸鱼但又不得不处理手头棘手问题的一天。想象一下这个场景:你面前摆着一台直接从市电取电的设备,它的某个测试点对地可能有高达…...

构建AI信任层TrustLayer:开源插件化架构保障AI输出安全与可靠
1. 项目概述:为什么我们需要一个AI信任层?最近几个月,我几乎把所有主流的AI工具都试了个遍。从代码助手到文案生成,从图像创作到数据分析,每个工具都承诺能提升效率。但用着用着,我发现一个越来越明显的问题…...

RedwoodJS数据备份与恢复终极指南:10个技巧保护你的应用数据安全 [特殊字符]
RedwoodJS数据备份与恢复终极指南:10个技巧保护你的应用数据安全 🔒 【免费下载链接】redwood RedwoodGraphQL 项目地址: https://gitcode.com/gh_mirrors/re/redwood RedwoodJS作为一款强大的全栈JavaScript框架,其数据安全保护机制对…...

迪士尼收购卢卡斯影业:顶级IP运营与商业并购的教科书案例
1. 一笔改变好莱坞格局的交易:迪士尼收购卢卡斯影业深度解析2012年10月30日,一则新闻震动了全球娱乐产业和无数影迷的心:华特迪士尼公司宣布,将以约40.5亿美元的价格,收购乔治卢卡斯创立的卢卡斯影业及其旗下最核心的资…...

阴阳师自动化脚本终极指南:如何用OnmyojiAutoScript一键托管你的日常游戏
阴阳师自动化脚本终极指南:如何用OnmyojiAutoScript一键托管你的日常游戏 【免费下载链接】OnmyojiAutoScript Onmyoji Auto Script | 阴阳师脚本 项目地址: https://gitcode.com/gh_mirrors/on/OnmyojiAutoScript 还在为阴阳师繁琐的日常任务而烦恼吗&#…...

短视频矩阵运营方法论——不同平台多账号协同的底层逻辑与避坑指南
短视频矩阵运营已成为品牌获取规模化流量的核心手段,但多账号协同背后的平台算法逻辑、账号关联风险、内容差异化策略等复杂问题,常常导致运营者踩入“雷区”。本文基于抖音、微信视频号、小红书三大主流平台官方规则与公开算法解读,系统梳理…...

工程师着装文化变迁:从安全规范到效率优化
1. 项目概述:从“着装规范”到工程师文化观察那天早上,我像往常一样,准备去马萨诸塞州纳蒂克的MathWorks公司拜访。出门前,我习惯性地套上了长裤。七月的波士顿,夏天终于姗姗来迟,气温宜人,其实…...