【pytorch】常用代码
文章目录
- 条件与概率
- torch.tensor()
- torch.rand()
- torch.randn()
- torch.randint()
- torch.multinominal()
- 逻辑运算
- torch.argmax()
- torch.max()
- torch.sum()
- torch.tanh()
- torch.pow()
- 功能性操作 torch.nn.functional
- F.normalize()
- F.elu()
- F.relu()
- F.softmax()
- 张量计算
- torch.zeros()
- torch.from_numpy()
- torch.stack() 张量堆叠
- torch.Tensor()
- squeeze()
- tensor.repeat()
- .unsqueece()
- torch.cat()
- .view()
- action.flatten()
- 模型构建
- torch.nn
- nn.ModuleList()
- nn.Sequential() 构建序贯模型
- nn.ModuleList() 与 nn.Sequential()的区别
- 自定义模型
- super(son_class_name, self).__init__()
- 层结构
- nn.Conv2d()
- nn.Linear()
- nn.Embeding()
- indices = torch.stack((torch.arange(action.shape[0]), action.sequeeze()), dim=0)
- 设置梯度
- optimizer = optim.Adam()
- with torch.no_grad():
- y_tensor = x_tensor.detach()
- detach()与with torch.no_grad(): 的区别
- optimzer.zero_grad()、optimzier.step()
- 损失计算
- nn.L1lose
- nn.MSELoss()
- nn.CrossEntropyLoss()
- loss_ = loss_.sum() / loss_.flatten().shape[0]
- 模型保存与加载
- torch.save()
- 设备
- cuda
- 一些补充
- 查看输入输出维度
- 动态图与静态图
- random.seed(42)
条件与概率
torch.tensor()
torch.tensor() 用于创建一个新的张量(Tensor)。
该函数可以接收多种类型的输入,包括列表、元组、NumPy 数组等,并将它们转换为 PyTorch Tensor。
当调用 torch.tensor() 时,可以选择性地传递一些额外的参数以定制Tensor。
可以通过 dtype 参数来指定你想要的数据类型,如 torch.float32、torch.int64 等。
可以通过 device 参数来指定 Tensor应该被创建在哪个设备上,比如 CPU 或 GPU。
import torch# 创建一个包含数字的列表,并将其转换为 Tensor
tensor_list = torch.tensor([1, 2, 3])
print(tensor_list)# 创建一个 NumPy 数组,并将其转换为 Tensor
numpy_array = torch.tensor(np.array([4, 5, 6]))
print(numpy_array)# 创建一个具有特定数据类型和张量的 Tensor
specific_dtype_tensor = torch.tensor([7, 8, 9], dtype=torch.float32)
print(specific_dtype_tensor)# 创建一个位于 GPU 上的 Tensor
gpu_tensor = torch.tensor([10, 11, 12], device='cuda')
print(gpu_tensor)
输出结果
tensor([1, 2, 3])
tensor([4, 5, 6], dtype=torch.int32)
tensor([7., 8., 9.])
tensor([10, 11, 12])
值得注意的是,如果传递给 torch.tensor() 的输入已经是一个 Tensor,那么该函数将会尝试重用输入 Tensor 的内存空间,而不是创建一个新的 Tensor。这样做可以提高效率,但可能会改变原始 Tensor 的数据。因此,如果你不希望修改原始 Tensor,你应该先对其进行复制。
torch.rand()
torch.rand() 是 PyTorch 中的一个函数,用于生成一个填充了随机数的张量。这些随机数是从均匀分布中抽取的,范围从 0 到 1。
以下是 torch.rand() 的一些基本用法:
import torch# 生成一个形状为 (2, 3) 的随机张量
x = torch.rand(2, 3)
print(x)# 生成一个形状为 (2, 3, 4) 的随机张量
y = torch.rand(2, 3, 4)
print(y)# 生成一个形状为 (2, 3) 的随机张量,并且指定数据类型为 float64
z = torch.rand(2, 3, dtype=torch.float64)
print(z)
输出结果
tensor([[0.7737, 0.1984, 0.5063],[0.0678, 0.2937, 0.5074]])tensor([[[0.8139, 0.4975, 0.5486, 0.8712],[0.8165, 0.5168, 0.0253, 0.9529],[0.6147, 0.7410, 0.5361, 0.8880]],[[0.1819, 0.3584, 0.7158, 0.2515],[0.7295, 0.8665, 0.0207, 0.3815],[0.5506, 0.8611, 0.1727, 0.0158]]])tensor([[0.5108, 0.7117, 0.2116],[0.7108, 0.4592, 0.5483]], dtype=torch.float64)
torch.randn()
torch.randn 是 PyTorch 中的一个函数,用于生成符合标准正态分布(均值为0,方差为1)的张量。
以下是一些使用 torch.randn 的例子:
import torch# 生成一个形状为 (2, 3) 的张量
x = torch.randn(2, 3)
print(x)# 生成一个形状为 (2, 3, 4) 的张量
y = torch.randn(2, 3, 4)
print(y)# 生成一个形状为 (2, 3, 4, 5) 的张量
z = torch.randn(2, 3, 4, 5)
print(z)
在这些例子中,我们都使用了 torch.randn 来生成张量。函数的第一个参数是一个元组,表示要生成的张量的形状。
需要注意的是,torch.randn 生成的张量中的元素是随机的,每次运行程序时都可能得到不同的结果。这是因为 torch.randn 使用的是伪随机数生成器,其种子默认为当前时间。
torch.randint()
生成一个从low到high的随机数
dic = torch.randint(low=0, high=7,size=(1,))
torch.multinominal()
torch.multinomial 是 PyTorch 中的一个函数,用于按多项式分布从指定的张量中进行采样。它可以用来进行随机抽样,其中每个元素根据其相对概率进行抽取。
这是 torch.multinomial() 的常用形式:
torch.multinomial(input, num_samples, replacement=False, generator=None)
input是一个张量,包含了每个样本的概率分布。它的形状可以是 (N, K),其中 N 是样本数,K 是类别数。num_samples是需要采样的样本数。replacement表示是否允许重复抽样。默认情况下,不允许重复抽样。generator是一个随机数生成器对象。默认情况下,使用全局默认的随机数生成器。
下面是一个示例:
import torch# 创建一个概率分布张量
probs = torch.tensor([[0.2, 0.3, 0.5]])# 从概率分布中抽取3个样本
samples = torch.multinomial(probs, num_samples=3)print(samples)
输出结果可能为:
tensor([[1, 2, 0]])
在上面的例子中,我们创建了一个概率分布张量 probs,其中包含了一个样本的概率分布。然后我们使用 torch.multinomial() 从概率分布中抽取了3个样本。抽取的样本被存储在张量 samples 中。
请注意,输出的样本是按照概率分布进行采样的,并且每个样本对应一个索引值,表示该样本属于的类别。
逻辑运算
torch.argmax()
torch.argmax() 是 PyTorch 中的一个函数,用于返回给定输入张量(tensor)中最大值的索引,常用在需要确定某个维度上最大值的位置时。比如在进行分类任务中,对softmax 的结果进行 取最大值对应的索引
下面是 torch.argmax() 的基本用法:
import torch# 创建一个随机的二维张量
x = torch.rand(3, 4)
print(x)# 获取每一行最大元素的索引
row_indices = torch.argmax(x, dim=1)
print(row_indices)# 获取整个张量最大元素的索引
max_index = torch.argmax(x)
print(max_index)# 指定dim参数为0表示按列查找最大值索引
column_indices = torch.argmax(x, dim=0)
print(column_indices)
输出结果
tensor([[0.9540, 0.4029, 0.9523, 0.6004],[0.4379, 0.5691, 0.2361, 0.7110],[0.7628, 0.6789, 0.5160, 0.3752]])
tensor([0, 3, 0])
tensor(0)
tensor([0, 2, 0, 1])
在这个例子中,我们首先创建了一个形状为 (3, 4) 的随机张量 x。然后使用 torch.argmax() 来找到每行和每列的最大元素索引。
- 当不指定
dim参数时,默认在整个张量上寻找最大值索引。 - 当指定
dim=0或dim=1时,分别按照列或行的方向寻找最大值索引。
此外,torch.argmax() 还可以接受其他参数,例如 keepdim 。
当设置 keepdim=True 时,输出的张量将保持原张量的维度不变,默认为False;从上面的代码可以看出keepdim=False输出的结果会压缩张量维度,而keepdim=True会保留原先张量的维度结构。
示例
import torch# 创建一个随机的二维张量
x = torch.rand(3, 4)
print(x)# 获取每一行最大元素的索引
row_indices = torch.argmax(x, dim=1,keepdim=True)
输出结果
tensor([[0.8178, 0.7284, 0.3020, 0.4067],[0.5941, 0.0325, 0.0488, 0.4419],[0.2692, 0.0472, 0.5445, 0.5994]])
tensor([[0],[0],[3]])
torch.max()
torch.argmax() 和 torch.max() 是 PyTorch 中的两个函数,用于在张量中寻找最大值的索引和最大值本身。
torch.argmax() 函数返回张量的最大值所在的索引。它的语法如下:
torch.argmax(input, dim=None, keepdim=False, *, out=None, dtype=None)
其中:
input:输入张量。dim:指定要沿着哪个维度进行最大值索引的计算。如果不指定dim,则默认为全局最大值,返回的索引是一个扁平化的一维张量。keepdim:指定是否保持输出张量的尺寸与输入张量尺寸相同。默认为False,即输出张量会缩小为一维。out(可选):输出张量的可选目标位置。dtype(可选):输出张量的数据类型。
下面是一个例子,展示如何使用 torch.argmax() 函数:
import torchx = torch.tensor([[1, 2, 3],[4, 5, 6],[7, 8, 9]])max_values, indices = torch.max(x, dim=1)
print(max_values) # 输出张量的最大值
print(indices) # 最大值所在的索引
输出结果:
tensor([3, 6, 9])
tensor([2, 2, 2])
在这个例子中,我们创建了一个形状为 (3, 3) 的张量 x。通过指定 dim=1,我们在每一行中找到最大值的索引和最大值本身。
相比之下,torch.max() 函数返回张量的最大值而不是索引。它的语法如下:
torch.max(input, dim=None, keepdim=False, *, out=None)
参数与 torch.argmax() 函数相似,不同之处是它只返回最大值本身,而不是索引。
下面是一个使用 torch.max() 函数的例子:
import torchx = torch.tensor([[1, 2, 3],[4, 5, 6],[7, 8, 9]])max_value = torch.max(x)
print(max_value) # 输出张量的最大值
输出结果:
tensor(9)
在这个例子中,我们得到了张量 x 中的最大值,而不关心其所在的索引。
torch.sum()
torch.tanh()
torch.pow()
功能性操作 torch.nn.functional
F.normalize()
import torch.nn.functional as F
x = F.normalize(x)
y = F.elu(self.conv1(x))
F.elu()
x = F.normalize(x)
y = F.elu(self.conv1(x))
F.relu()
F.softmax()
张量计算
torch.zeros()
torch.from_numpy()
torch.from_numpy() 是 PyTorch 中的一个函数,用于将 NumPy 数组转换为 PyTorch 张量(Tensor)。它创建了一个与给定NumPy数组共享数据的张量,而不需要复制数据。
下面是使用 torch.from_numpy() 的示例:
import numpy as np
import torch# 创建一个 NumPy 数组
arr = np.array([1, 2, 3, 4, 5])# 使用 torch.from_numpy() 将 NumPy 数组转换为张量
tensor = torch.from_numpy(arr)print(tensor)
输出结果为:
tensor([1, 2, 3, 4, 5], dtype=torch.int32)
torch.from_numpy() 返回的张量将与原始 NumPy 数组共享数据内存,因此对其中一个的修改会影响另一个。这样可以在 NumPy 数组和 PyTorch 张量之间进行数据交互,无需数据复制就能提高效率。
需要注意的是,torch.from_numpy() 只能用于将数据类型为 np.ndarray 的 NumPy 数组转换为张量。如果想将其他类型的数组或类似数组的对象转换为张量,可以使用 torch.Tensor() 来创建张量,并将其作为参数传递给该函数。
torch.stack() 张量堆叠
torch.stack() 是 PyTorch 中的一个函数,用于将一组张量沿着一个新的维度进行堆叠。
语法如下:
torch.stack(tensors, dim=0, *, out=None)
参数说明:
tensors:要堆叠的一组张量,可以是相同形状的张量或者具有相同形状的可迭代对象。dim:指定要沿着的新维度的索引。默认值是0,表示在新的零号维度上堆叠张量。out(可选):输出张量的可选目标位置,如果不为 None,则结果将被赋值给它。
堆叠操作会创建一个新的张量,将输入张量按照指定的维度进行堆叠。结果张量的形状将是输入张量形状的扩展。如果输入张量的形状是 (n1, n2, ..., ni),则结果张量的形状将是 (n1, n2, ..., ni, num_tensors),其中 num_tensors 是堆叠的张量数量。
以下是一个例子,展示如何使用 torch.stack() 函数:
import torchx = torch.tensor([1, 2, 3])
y = torch.tensor([4, 5, 6])
z = torch.tensor([7, 8, 9])stacked = torch.stack([x, y, z])
print(stacked)
输出结果:
tensor([[1, 2, 3],[4, 5, 6],[7, 8, 9]])
在这个例子中,我们创建了三个形状相同的张量 x、y、z,然后使用 torch.stack() 函数将它们在零号维度上堆叠,创建了一个形状为(3, 3)的新张量 stacked。
torch.stack() 函数主要用于将已经是张量的数据进行堆叠操作。它要求输入的数据是张量或具有相同形状的可迭代对象,然后沿着指定的维度进行堆叠。
如果你有一组已经是张量的数据,并且希望将它们沿着某个维度进行堆叠,那么 torch.stack() 是很方便的函数。
例如,在上面提供的例子中,我们创建了三个张量 x、y、z,然后使用 torch.stack() 将它们在零号维度上堆叠,生成了新的形状为 (3, 3) 的张量。
但是如果你有非张量的数据,想要将它们转换为张量并进行堆叠,可以使用其他函数或方法,比如 torch.Tensor() 。
torch.Tensor()
torch.Tensor() 是 PyTorch 中用于创建张量(Tensor)的构造函数。它可以接受各种不同的参数来创建不同类型和形状的张量。
下面是使用 torch.Tensor() 创建张量的示例:
import torch# 创建一个空的张量
empty_tensor = torch.Tensor()
print(empty_tensor)# 创建一个指定形状的张量
ones_tensor = torch.Tensor(2, 3)
print(ones_tensor)# 创建一个张量并用指定值填充
data_tensor = torch.Tensor([1, 2, 3, 4, 5])
print(data_tensor)
输出结果为:
tensor([])
tensor([[1., 1., 1.],[1., 1., 1.]])
tensor([1., 2., 3., 4., 5.])
在上述示例中:
- 第一个示例创建了一个空的张量
empty_tensor。 - 第二个示例创建了一个形状为 2x3 的张量
ones_tensor,并将其元素初始化为默认值 1.0。 - 第三个示例通过传递一个 Python 列表作为参数,来创建一个张量
data_tensor,其中包含列表中的元素。
torch.Tensor() 构造函数还可以接受其他参数,如 dtype 来指定张量的数据类型,以及 device 来指定在哪个设备上存储张量(如 CPU 或 GPU)。
需要注意的是,与 torch.from_numpy() 不同,torch.Tensor() 不会与其他数据类型(如 NumPy 数组)共享内存。它会创建一个新的张量,并根据提供的数据或形状进行初始化。
squeeze()
squeeze()是一个用于操作张量的函数。它的作用是去除张量中维度大小为1的维度,从而降低维度的数量。具体来说,squeeze()函数会将张量中维度大小为1的维度压缩掉,使得张量变得更紧凑。
例如,如果一个张量的形状为(1, 3, 1, 5),其中有两个维度的大小为1,那么使用squeeze()函数后,张量的形状将变为(3, 5),即去掉了维度大小为1的维度。
需要注意的是,squeeze()函数只会压缩维度大小为1的维度,对于其他维度,它不会产生任何影响。如果想要压缩指定维度,可以使用squeeze(dim)函数,其中dim是要压缩的维度的索引。
tensor.repeat()
repeat 是一个张量的方法,用于沿指定的维度重复张量的元素。它的参数是一个元组,包含了每个维度上重复的次数。
state_.repeat((N, 1, 1)) 表示沿着维度0重复 state_ 的元素 N 次。维度0通常用于表示样本或批次的维度。而后面两个维度1和1保持不变,即不进行重复。
具体来说,假设 state_ 的形状为 (A, B, C),那么重复后的结果的形状为 (N*A, B, C),其中 N 是重复的次数。
下面是一个简单的示例:
import torch# 创建一个形状为 (2, 3, 4) 的张量
x = torch.tensor([[[1, 2, 3, 4],[5, 6, 7, 8],[9, 10, 11, 12]],[[13, 14, 15, 16],[17, 18, 19, 20],[21, 22, 23, 24]]])# 沿维度0重复2次
y = x.repeat((2, 1, 1))print(y)
输出结果为:
tensor([[[ 1, 2, 3, 4],[ 5, 6, 7, 8],[ 9, 10, 11, 12]],[[13, 14, 15, 16],[17, 18, 19, 20],[21, 22, 23, 24]],[[ 1, 2, 3, 4],[ 5, 6, 7, 8],[ 9, 10, 11, 12]],[[13, 14, 15, 16],[17, 18, 19, 20],[21, 22, 23, 24]]])
在上面的例子中,我们创建了一个形状为 (2, 3, 4) 的张量 x,然后使用 x.repeat((2, 1, 1)) 对其进行重复。结果是一个形状为 (4, 3, 4) 的新张量 y,其中 x 的内容在维度0上重复了2次。
.unsqueece()
在 PyTorch 中,.unsqueeze(dim=1) 是一个方法,它可以在指定的维度上对张量进行扩展,使其维度增加 1。具体而言,.unsqueeze(dim=1) 可以在给定维度上插入一个大小为 1 的维度。
以下是一个示例,展示了如何使用 .unsqueeze(dim=1) 方法:
import torchx = torch.tensor([1, 2, 3])unsqueeze_x = x.unsqueeze(dim=1)
print(unsqueeze_x)
输出结果:
tensor([[1],[2],[3]])
在这个例子中,我们创建了一个形状为 (3,) 的张量 x。通过使用 .unsqueeze(dim=1),我们在维度 1 上插入了一个新的维度,使得张量 unsqueeze_x 的形状变为 (3, 1)。
这样做有时会对某些操作或模型有帮助,特别是在需要扩展维度以进行广播操作或与其他形状不匹配的张量进行计算时。
以下代码为构建批量做准备
return torch.from_numpy(downscale_obs(state, to_gray=True)).float().unsqueeze(dim=0)
torch.cat()
torch.cat() 是 PyTorch 中用于连接(拼接)张量的函数。它可以将多个张量沿指定的维度进行拼接。
torch.cat() 的语法如下:
torch.cat(tensors, dim=0, *, out=None)
其中:
tensors:是一个需要拼接的张量序列,可以是一个列表或元组。dim:指定拼接的维度,即在哪个维度上进行拼接。默认为 0,表示在第一个维度上拼接。out(可选):输出张量的可选目标位置。
下面是一个示例,展示了如何使用 torch.cat() 拼接张量:
import torchx1 = torch.tensor([[1, 2],[3, 4]])x2 = torch.tensor([[5, 6],[7, 8]])# 沿着行维度拼接张量
merged_tensor = torch.cat((x1, x2), dim=0)
print(merged_tensor)
输出结果:
tensor([[1, 2],[3, 4],[5, 6],[7, 8]])
在这个例子中,我们有两个形状为 (2, 2) 的张量 x1 和 x2。通过使用 torch.cat((x1, x2), dim=0),我们沿着行维度(维度 0)拼接了这两个张量,得到了形状为 (4, 2) 的合并张量。
需要注意的是,所有要拼接的张量在除了指定维度外的其他维度上的大小必须相同。
torch.cat() 还可以在其他维度上进行拼接,只需根据需要更改 dim 参数即可。
.view()
在 PyTorch 中,.view() 是一个方法,用于调整张量的形状。.view() 可以通过改变张量的维度来重新组织数据。
具体而言,.view() 方法可以用来改变张量的形状,但需要注意的是,调整后的形状的元素数量必须与原始形状的元素数量保持一致。
下面是一个示例,展示如何使用 .view() 方法来重新组织张量的形状:
import torchx = torch.tensor([[1, 2],[3, 4],[5, 6]])reshaped_x = x.view(2, 3) # 将 x 调整为 2 行 3 列的形状
print(reshaped_x)
输出结果:
tensor([[1, 2, 3],[4, 5, 6]])
在这个例子中,我们创建了一个形状为 (3, 2) 的张量 x。通过使用 .view(2, 3),我们将 x 的形状调整为 2 行 3 列的形状。
需要注意的是,调整后的形状必须满足元素数量匹配的要求。在这个例子中,原始张量 x 包含了 6 个元素,调整后的形状 (2, 3) 也必须保持 6 个元素。
总之,.view() 方法可以用于调整张量的形状,以便与各种计算和模型的输入或输出对齐。
action.flatten()
模型构建
torch.nn
nn.ModuleList()
nn.ModuleList 是 PyTorch 中的一个类,它是 nn.Module 的子类,用于创建一个动态的模块列表。这意味着你可以像操作普通 Python 列表那样添加或删除模块,而且 PyTorch 会自动将这些模块注册到整个网络中,并更新网络的参数。
以下是一个简单的例子,展示了如何使用 nn.ModuleList:
import torch
import torch.nn as nn# 创建一个 ModuleList 对象
my_list = nn.ModuleList([nn.Linear(10, 5), nn.ReLU(), nn.Linear(5, 1)])# 打印 ModuleList 对象
print(my_list)
在这个例子中,我们首先创建了一个 nn.ModuleList 对象,并向其中添加了两个 nn.Linear 层和一个 nn.ReLU 激活函数。然后,我们打印了这个 ModuleList 对象,可以看到它包含了这三个模块。
nn.ModuleList 的一个常见用途是在构建更复杂的神经网络结构时,可以将一组相关的层组合在一起作为一个模块,这样可以使网络的结构更加清晰和易于管理。
比如Transformers中的Encoder部分
class Encoder(nn.Module):def __init__(self, src_vocab_size,embed_size,num_layers,heads,device,forward_expansion,dropout,max_length):super(Encoder, self).__init__()self.embed_size = embed_sizeself.device = deviceself.word_embedding = nn.Embedding(src_vocab_size, embed_size) self.position_embedding = nn.Embedding(max_length, embed_size)def forward(self, x, mask):N, seq_lengh = x.shapepositions = torch.arange(0, seq_lengh).expand(N, seq_lengh).to(self.device)out = self.dropout(self.word_embedding(x) + self.position_embedding(positions))for layer in self.layers:out = layer(out, out, out, mask)return out
注意看forward()方法中的for layer in self.layers:。因为nn.ModuleList() 并没有提供类似 nn.Sequential 那样的整体前向传播接口,所以我们必须显式地遍历 ModuleList 并调用每个模块。
nn.Sequential() 构建序贯模型
import torch
from torch import nnmodel = nn.Sequential(torch.nn.Linear(l1,l2),torch.nn.ReLU(),torch.nn.Linear(l2,l3),torch.nn.ReLU(),torch.nn.Linear(l3,l4))
nn.ModuleList() 与 nn.Sequential()的区别
nn.ModuleList 和 nn.Sequential 都是 PyTorch 中用于构建神经网络结构的容器模块,但它们之间存在一些关键的区别:
-
顺序访问 vs 键值访问:
nn.Sequential是一个有序的容器,只能按照添加的顺序访问模块。而nn.ModuleList则更像一个普通的 Python 列表,支持基于索引或键名的访问方式。 -
可变性:
nn.Sequential是一个不可变容器,一旦添加了模块,就不能更改顺序。而nn.ModuleList则是可变的,可以在任意位置插入或删除模块。 -
注册参数:两者都会自动注册其包含的模块及其参数,这意味着你可以直接通过模型访问这些参数,例如使用
model.parameters()方法。 -
前向传播:
nn.Sequential会自动构建一条从输入到输出的前向传播路径,你只需要将输入传递给Sequential对象即可。而nn.ModuleList则需要你自己定义前向传播逻辑,将输入依次传递给每个模块。 -
使用场景:
nn.Sequential适合于那些模块间没有复杂依赖关系的简单网络结构,而nn.ModuleList则适用于那些需要灵活控制模块顺序和访问方式的复杂网络结构。
总的来说,选择使用哪一个取决于你的具体需求。如果你需要一个有序且不可变的容器,并且不需要手动定义前向传播逻辑,那么 nn.Sequential 可能是更好的选择。反之,如果你需要更灵活的容器来组织你的网络结构,那么 nn.ModuleList 将更适合你。
代码体现两者的区别,展示了 nn.ModuleList 和 nn.Sequential 的区别:
import torch
import torch.nn as nn# 使用 nn.Sequential
seq_model = nn.Sequential(nn.Linear(10, 5),nn.ReLU(),nn.Linear(5, 1)
)# 使用 nn.ModuleList
mod_list_model = nn.ModuleList([nn.Linear(10, 5),nn.ReLU(),nn.Linear(5, 1)
])# 打印两种模型的前向传播结果
input = torch.randn(1, 10)
print("Sequential Model Output:", seq_model(input))
print("ModuleList Model Output:", mod_list_model[0](input)) # 注意这里只调用了第一个模块
在这个例子中,我们首先创建了一个 nn.Sequential 模型和一个 nn.ModuleList 模型,它们都包含了相同的三个模块:一个线性层,一个 ReLU 激活函数,以及另一个线性层。
然后,我们打印了两个模型的前向传播结果。对于 nn.Sequential 模型,我们只需要将输入传递给模型,模型就会自动按照添加的顺序执行每个模块的前向传播。而对于 nn.ModuleList 模型,我们需要自己遍历模型,将输入逐个传递给每个模块。
需要注意的是,nn.ModuleList 并没有提供类似 nn.Sequential 那样的整体前向传播接口,所以我们必须显式地遍历 ModuleList 并调用每个模块。
当最后一行代码改为print("ModuleList Model Output:", mod_list_model(input) 会引发错误NotImplementedError: Module [ModuleList] is missing the required "forward" function 说明其前向传播需要我们遍历实现
自定义模型
好奇心机制的编码器模型
class Phi(nn.Module):def __init__(self):super(Phi, self).__init__()self.conv1 = nn.Conv2d(3, 32, kernel_size=(3,3), stride=2, padding=1)self.conv2 = nn.Conv2d(32,32, kernel_size=(3,3), stride=2, padding=1)self.conv3 = nn.Conv2d(32,32, kernel_size=(3,3), stride=2, padding=1)self.conv4 = nn.Conv2d(32,32, kernel_size=(3,3), stride=2, padding=1)def forward(self,x):x = F.normalize(x)y = F.elu(self.conv1(x))y = F.elu(self.conv2(y))y = F.elu(self.conv3(y))y = F.elu(self.conv4(y))y = y.flatten(start_dim=1)return y
好奇心机制的正向模型
class Fnet(nn.Module):def __init__(self):super(Fner, self).__init__()self.linear1 = nn.Linear(300,256)self.linear2 = nn.Linear(256,288)def forward(self, state, action):action_ = torch.zeros(action.shape[0],12)indices = torch.stack((torch.arange(action.shape[0], action.squeeze()), dim=0)indices = indices.tolist()action_[indices] = 1x = torch.cat((state,action_), dim=1)y = F.relu(self.linear1(x))y = self.linear2((y)return y
好奇心机制的DQN模型
class Qnetwork(nn.Module):def __init__(self):super(Qnetwork, self).__init__()self.conv1 = nn.Conv2d(in_channels=3, out_channels=32, kernel_size=(3, 3), stride=2, padding=1)self.conv2 = nn.Conv2d(32, 32, kernel_size=(3, 3), stride=2, padding=1)self.conv3 = nn.Conv2d(32, 32, kernel_size=(3, 3), stride=2, padding=1)self.conv4 = nn.Conv2d(32, 32, kernel_size=(3, 3), stride=2, padding=1)self.linear1 = nn.Linear(288, 100)self.linear2 = nn.Linear(100, 12)def forward(self, x):x = F.normalize(x)y = F.elu(self.conv1(x))y = F.elu(self.conv2(y))y = F.elu(self.conv3(y))y = F.elu(self.conv4(y))y = y.flatten(start_dim=2)y = y.view(y.shape[0], -1, 32)y = y.flatten(start_dim=1)y = F.elu(self.linear1(y))y = self.linear2(y)return y
总结就是,自定义模块总要部分在于__init__()方法与forward()方法
class Class_Name(nn.Module):def __init__(self, params):super(Class_Name, self).__init__()self.params = paramsdef forward(self,x):return y
super(son_class_name, self).init()
```python
class Phi(nn.Module):def __init__(self):super(Phi, self).__init__()self.conv1 = nn.Conv2d(3, 32, kernel_size=(3,3), stride=2, padding=1)self.conv2 = nn.Conv2d(32,32, kernel_size=(3,3), stride=2, padding=1)self.conv3 = nn.Conv2d(32,32, kernel_size=(3,3), stride=2, padding=1)self.conv4 = nn.Conv2d(32,32, kernel_size=(3,3), stride=2, padding=1)def forward(self,x):x = F.normalize(x)y = F.elu(self.conv1(x))y = F.elu(self.conv2(y))y = F.elu(self.conv3(y))y = F.elu(self.conv4(y))y = y.flatten(start_dim=1)return y
super(Phi, self).__init__() 这行代码是在 Python 中调用父类(在这里是 nn.Module)的构造函数。这是在子类中初始化父类的标准做法。
在 Python 中,当我们创建一个新的类时,我们可以继承一个或多个现有的类。在这种情况下,新的类被称为子类,而被继承的类被称为父类。
在 PyTorch 中,nn.Module 是所有神经网络模块的基类。当你创建一个新的神经网络模型时,通常会继承 nn.Module。在你的模型的构造函数中,你需要调用 super().__init__() 来确保 nn.Module 的构造函数被正确地调用。这是因为 nn.Module 的构造函数负责一些必要的初始化工作,比如设置一些属性等。
所以,super(Phi, self).__init__() 这行代码的作用就是确保 nn.Module 的构造函数被正确地调用,从而让你的 Phi 类能够正常工作。
层结构
nn.Conv2d()
from torch import nnself.conv1 = nn.Conv2d(3, 32, kernel_size=(3,3), stride=2, padding=1)
nn.Linear()
from torch import nnself.linear1 = nn.Linear(576,256)
nn.Embeding()
nn.Embedding() 是 PyTorch 中的一个模块,用于创建一个嵌入层,这是一种常见的神经网络结构,常用于处理离散的类别变量。
嵌入层的主要思想是将每个类别映射到一个固定大小的向量,这个过程也被称为“嵌入”。这种处理方式在许多任务中都非常有用,例如自然语言处理中的词嵌入,推荐系统中的物品嵌入等。
import torch
import torch.nn as nn# 假设我们有10个类别,每个类别将被嵌入到一个大小为3的向量中
embedding = nn.Embedding(num_embeddings=10, embedding_dim=3)# 创建一个包含三个类别的张量
input = torch.tensor([1, 2, 3])# 将输入张量送入嵌入层
output = embedding(input)print(output)
输出结果
tensor([[ 0.7962, -1.8463, 0.2988],[-1.0745, 1.5030, -0.2322],[-1.4668, -0.2942, 2.2095]], grad_fn=<EmbeddingBackward0>)
首先,实例 nn.Embedding() ,其中 num_embeddings 参数指定了类别的数量,embedding_dim 参数指定了嵌入向量的大小。
然后,我们创建了一个包含三个类别的张量,并将其送入嵌入层。
最后, 打印出了嵌入层的输出,这是一个形状为 (3, 3) 的张量,其中的每一行都是一个类别的嵌入向量。
nn.Embedding() 是 PyTorch 深度学习框架中的一个嵌入层模块,它的主要功能是将离散的类别变量转换为连续的向量表示。这一过程在自然语言处理和其他领域中非常重要,因为它允许模型捕捉到类别之间的语义关系。
嵌入层的工作原理
-
nn.Embedding()本身并不包含任何预训练的知识或模型,其权重是随机初始化的。在训练过程中,通过与其它神经网络层结合使用,并通过学习数据集中的模式来逐渐调整其内部的权重。在训练过程中,嵌入层会学习这些向量,使得相似的词在向量空间中更加接近。例如,“king"和"queen”、"man"和"woman"等词的向量会在向量空间中彼此靠近 -
嵌入层的工作原理类似于一个字典或查找表,它内部维护着一个固定大小的矩阵,矩阵的每一行对应一个类别的嵌入向量。当我们将一个类别索引传递给嵌入层时,它会返回对应的嵌入向量。
-
假设我们有一个词汇表大小为1000的词嵌入层,嵌入维度为5。那么,嵌入层内部会存储着1000个长度为5的向量。当我们输入一个索引为50的词时,嵌入层会返回第50个长度为5的向量。当输入的类别数量超出
num_embedings参数设定的值的时候,会报错IndexError: index out of range in self -
在实际应用中,嵌入层通常与其它神经网络层结合使用,例如全连接层或循环神经网络层,以实现更复杂的任务,如文本分类、情感分析等。
indices = torch.stack((torch.arange(action.shape[0]), action.sequeeze()), dim=0)
代码 indices = torch.stack((torch.arange(action.shape[0]), action.squeeze()), dim=0) 的作用是创建一个张量 indices,该张量的形状是 (2, N),其中 N 是 action 张量的第一个维度的大小。
具体解释如下:
torch.arange(action.shape[0])生成一个从 0 到action.shape[0]-1的整数张量,形状为(action.shape[0],)。这表示生成一个从 0 到action.shape[0]-1的数列。action.squeeze()将action张量中的尺寸为 1 的维度进行压缩,即去除尺寸为 1 的维度。如果action张量的尺寸为(1, M),则压缩后的形状为(M,)。torch.stack((torch.arange(action.shape[0]), action.squeeze()), dim=0)将torch.arange(action.shape[0])和action.squeeze()张量按照维度 0 进行堆叠,生成一个形状为(2, N)的张量indices。其中,第一行是torch.arange(action.shape[0]),第二行是action.squeeze()。
请注意,在使用上述代码之前,确保 action 张量已经定义和赋值。另外,如果 action 张量的维度或尺寸不符合要求,可能会导致代码执行错误。
设置梯度
optimizer = optim.Adam()
optimizer = torch.optim.Adam(params=model.parameters(), lr=learning_rate) 用于创建一个 Adam 优化器,用于优化模型的参数。
Adam 是一种常用的优化算法,用于调整模型的参数以最小化损失函数。
-
params指定需要进行训练的权重,model.parameters()返回模型中所有需要训练的参数。这些参数将被传递给 Adam 优化器,用于更新它们的值。 -
lr=learning_rate参数指定了学习率(learning rate),它控制着每次参数更新的大小。学习率越大,则参数更新越大;学习率越小,则参数更新越小。可以根据具体问题和经验来选择合适的学习率。
以下是一个示例,展示如何使用 Adam 优化器进行参数更新:
import torch
import torch.optim as optim# 定义模型
model = MyModel()# 定义优化器
learning_rate = 0.001
optimizer = optim.Adam(model.parameters(), lr=learning_rate)# 迭代训练
for epoch in range(num_epochs):# 前向传播outputs = model(inputs)loss = loss_function(outputs, labels)# 梯度清零optimizer.zero_grad()# 反向传播loss.backward()# 参数更新optimizer.step()
在上述代码中,我们首先定义了一个模型 MyModel(),然后使用 optim.Adam() 创建了一个 Adam 优化器。在训练过程中,我们迭代多个 epoch,在每个 epoch 中进行前向传播、计算损失、反向传播等步骤。最后,调用 optimizer.step() 来实际更新模型的参数。
重要的几个部分
optimizer = optim.Adam(model.parameters(), lr=learning_rate)创建优化器loss = loss_function(outputs, labels)计算损失optimizer.zero_grad()梯度清零loss.backward()误差反向传播optimizer.step()优化器更新参数
Adam 优化器根据计算得到的梯度和学习率来更新模型的参数。通过反复迭代和更新,我们可以让模型逐渐优化,并找到损失函数最小化的参数。
with torch.no_grad():
with torch.no_grad() 是在 PyTorch 中的一个上下文管理器(context manager),用于禁用梯度计算。在这个上下文中,所有的操作都不会被记录梯度,从而减少了内存消耗和加快了计算速度。
通常情况下,PyTorch 中的张量会自动跟踪并记录梯度信息,以便进行自动求导和反向传播。但是,在某些情况下,我们可能只想进行前向计算或推理,并且不需要计算梯度,这时就可以使用 torch.no_grad() 来暂时禁用梯度计算。
下面是使用 with torch.no_grad() 的示例:
import torch# 创建张量并设置 requires_grad=True 来跟踪梯度
x = torch.tensor([1.0, 2.0, 3.0], requires_grad=True)# 在上下文中进行前向计算,但不记录梯度
with torch.no_grad():y = x * 2z = y + 1print(y) # 不会进行梯度计算
print(z) # 不会进行梯度计算
输出结果为:
tensor([2., 4., 6.])
tensor([3., 5., 7.])
在这个示例中,x 是一个张量,并通过设置 requires_grad=True 来告知 PyTorch 跟踪梯度。然后,在 with torch.no_grad() 的上下文中,我们进行了一系列的计算,但这些计算不会被记录梯度。
torch.no_grad() 可以与训练循环或评估模型时的推理过程结合使用。在推理过程中,我们不需要计算梯度,因为只关心模型的输出而不是梯度值。
y_tensor = x_tensor.detach()
在 PyTorch 中,detach() 是一个用于切断反向传播关系的方法,用于从计算图中分离出张量,并返回一个新的不具有梯度信息的张量。具体来说,detach() 会返回一个与原始张量共享数据存储的新张量,但新张量不参与梯度计算,也不会被反向传播。
detach() 的主要作用包括:
- 切断梯度反向传播关系,使得从一个张量开始的计算不会影响到原始张量的梯度计算。
- 生成一个不需要梯度的张量,用于一些只需计算前向传播结果的任务。
以下是 detach() 方法的使用示例:
import torchx = torch.randn(3, requires_grad=True)
y = x.detach() # 分离 x,得到一个不需要梯度的张量 y# 进行前向传播计算
z = y * 2
loss = z.sum()# 反向传播
loss.backward()print(x.grad) # 输出为 None,由于 y 分离自 x,连接断开,因此 x 的梯度为 None
在上述示例中,我们首先创建一个张量 x,并将 requires_grad 设置为 True,表示我们希望计算关于 x 的梯度。然后,我们使用 detach() 方法,将 x 分离为 y,得到一个新的不需要梯度的张量。接下来,我们进行一系列前向传播计算,并计算出一个损失 loss。最后,通过调用 loss.backward() 来进行反向传播,但由于 y 已经分离自 x,因此 x 的梯度为 None。
通过使用 detach() 方法,我们可以在某些情况下切断计算图,从而在不需要梯度的情况下进行前向传播或忽略部分张量的反向传播。
detach()与with torch.no_grad(): 的区别
with torch.no_grad() 和 detach() 都是在 PyTorch 中用于控制梯度计算和反向传播的机制,但它们有一些区别。
detach() 和 with torch.no_grad(): 都是在PyTorch中进行梯度计算的上下文管理,但它们之间有一些关键的区别。
-
作用域:
with torch.no_grad():是一个上下文管理器,它会在进入代码块时禁用梯度计算,并在退出代码块时重新启用。这意味着你在with torch.no_grad():代码块内进行的任何操作都不会影响梯度,常用在模型训练完成后的推理阶段。而detach()方法则会立即返回一个新的Tensor,这个新的Tensor不会参与到当前的梯度计算中。 这对于只需要前向传播而无需计算梯度的情况非常有用。示例如下:import torchx = torch.randn(3, requires_grad=True)with torch.no_grad():y = x * 2z = y.mean()print(y.requires_grad) # False,y 不需要梯度 print(z.requires_grad) # False,z 不需要梯度 -
返回值:
detach()方法会返回一个新的Tensor,这个新的Tensor和原来的Tensor共享相同的内存空间,但不会被计算图所追踪。而with torch.no_grad():并不会返回任何值,它只是改变了当前代码块的梯度计算状态。import torchx = torch.randn(3, requires_grad=True)y = x.detach()print(y.requires_grad) # False,y 不需要梯度 -
灵活性:
detach()方法可以让你更灵活地控制哪些Tensor需要参与梯度计算,哪些不需要。而with torch.no_grad():则是一次性地为整个代码块禁用梯度计算,不提供这种细粒度的控制。
总的来说,detach() 和 with torch.no_grad(): 都可以在不进行梯度计算的情况下处理Tensor,但它们的适用场景和使用方式有所不同。在选择使用哪一个时,需要根据具体的应用场景和需求来决定。
optimzer.zero_grad()、optimzier.step()
optimizer.zero_grad() 的目的是将之前迭代中的梯度清零,而不是完全清除梯度。它将参数的梯度设置为零,以便在接下来的反向传播过程中,新的梯度可以正确地累积。这是为了避免梯度的累积干扰或错误更新模型参数。
反向传播是依赖梯度的。清零梯度只是为了确保每次迭代时,梯度是新计算的,并且不受之前迭代的影响。
具体流程如下:
调用 optimizer.zero_grad() 清零梯度。
通过前向传播计算出模型的输出。
根据模型输出和目标数据计算出损失值。
调用 loss.backward() 执行反向传播,计算模型参数的梯度。
调用 optimizer.step() 根据梯度更新模型的参数
optimizer.zero_grad()
loss = loss_fn(X,Y)
# loss_list.append(loss.item()) # 保存输出loss
loss.backward()
optimzier.step()
损失计算
nn.L1lose
https://blog.51cto.com/u_15274944/4999058
nn.MSELoss()
forward_loss = nn.MSELoss(reduction='none')
qloss = nn.MSELoss()
nn.CrossEntropyLoss()
inverse_loss = nn.CrossEntropyLoss(reduction='none')
loss_ = loss_.sum() / loss_.flatten().shape[0]
代码 loss_ = loss_.sum() / loss_.flatten().shape[0] 的作用是将张量 loss_ 进行求和并计算平均值,从而得到一个标量值作为最终的损失。
具体解释如下:
loss_.sum()对张量loss_进行求和操作,将所有元素相加得到一个标量值。loss_.flatten()将张量loss_展平为一维张量。loss_.flatten().shape[0]获取展平后张量的第一个维度的大小,在这里即为张量loss_中元素的总个数。loss_.sum() / loss_.flatten().shape[0]计算求和后的值除以元素总个数,从而得到平均值。
通过执行上述代码,将张量 loss_ 进行求和并计算平均值,将结果存储在 loss_ 中。现在,loss_ 是一个标量值,表示了损失的平均值。
请注意,在使用上述代码之前,确保 loss_ 张量已经定义和赋值。另外,如果 loss_ 张量的维度或尺寸不符合要求,可能会导致代码执行错误。
模型保存与加载
torch.save()
在PyTorch中,模型的保存和加载可以通过两种方式实现:
- 保存整个模型:使用
torch.save(model, "models/dongtai.pt"),这种方式会将模型的整个结构以及其中的参数一同保存下来。当需要加载这个模型时,可以直接使用model = torch.load("models/dongtai.pt"),这样就可以得到一个完全相同的模型副本,包括它的结构和参数。
# 模型保存
torch.save(model,"models/model_weights.pt")
# 模型加载,带模型结构
mode = torch.load("models/model_weights.pt")
- 保存模型的参数状态字典:
使用torch.save(model.state_dict(), "models/dongtai_state_dict.pt"),这种方式只会保存模型的参数状态,而不包括模型的结构。
当需要加载这个模型时,需要先生成一个新的模型实例,然后使用model.load_state_dict(torch.load("models/dongtai_state_dict.pt"))来加载参数。
# 模型保存
torch.save(model.state_dict(),"models/model_weights.pt")
# 实例模型
model = Model_class()
# 加载模型权重
weights = torch.load("models/model_weights.pt")
model.load_state_dict(weights)
设备
cuda
参考
cuda是否可用import torch print(torch.cuda.is_available()) # 输出为True 或者 False- GPU 设备的数量
print("available gpu devices: {}".format(torch.cuda.device_count())) - GPU设备的名称
print("gpu device name: {}".format(torch.cuda.get_device_name(torch.device("cuda:0"))))
一些补充
查看输入输出维度
对于保存了整个模型的
Qmodel = torch.load('ICM_Qmodel.pt',map_location=torch.device('cpu'))
for key, value in Qmodel.state_dict().items():print(key,value.size(),sep=" ")
对于只保存了模型权重
state_dict = torch.load('ICM_Qmodel.pt')
for key, value in state_dict.items():print(key,value.size(),sep=" ")
两者的输出结果相同,只是模型的保存方式不同,对应的查看方式有略微差别

动态图与静态图
静态图和动态图的概念,它们是深度学习框架中执行计算图的不同方式:
-
静态图:静态图是指在运行前就构建好整个计算图,然后在运行时仅执行计算图。静态图通常更高效,因为它允许编译器和硬件优化图执行。然而,静态图不太灵活,因为一旦图构建完成,就很难进行修改。TensorFlow早期版本主要使用静态图。
-
动态图:动态图是指每次运行时都会构建计算图,并且在运行时执行。动态图提供了更大的灵活性,因为它允许在运行时更改模型结构。动态图通常更适合研究和原型设计,因为它更容易调试和理解。PyTorch主要使用动态图。
random.seed(42)
random.seed()函数使用给定值初始化随机数生成器。
种子被赋予一个整数值,以确保伪随机生成的结果是可重现的。通过重新使用种子值,只要不是多线程,相同的序列应该可以在运行之间重现。可重复性是一个非常重要的概念,它确保任何重新运行代码的人都能获得完全相同的输出。
random.seed(42) 的意义是什么?
其实是一种流行文化,是一种计算机领域的默认传统,在道格拉斯·亚当斯 1979 年广受欢迎的科幻小说《银河系漫游指南》中,在书的最后,超级计算机Deep Thought揭示了“生命、宇宙和一切”这个重大问题的答案是 42
https://zhuanlan.zhihu.com/p/458809368
相关文章:
【pytorch】常用代码
文章目录 条件与概率torch.tensor()torch.rand()torch.randn()torch.randint()torch.multinominal() 逻辑运算torch.argmax()torch.max()torch.sum()torch.tanh()torch.pow() 功能性操作 torch.nn.functionalF.normalize()F.elu()F.relu()F.softmax() 张量计算torch.zeros()tor…...
GB28181 —— Ubuntu20.04下使用ZLMediaKit+WVP搭建GB28181流媒体监控平台(连接带云台摄像机)
最终效果 简介 GB28181协议是视频监控领域的国家标准。该标准规定了公共安全视频监控联网系统的互联结构, 传输、交换、控制的基本要求和安全性要求, 以及控制、传输流程和协议接口等技术要求,是视频监控领域的国家标准。GB28181协议信令层面使用的是SIP(Session Initiatio…...
图片录入设备、方式与质量对图片转Excel的影响
随着数字化时代的到来,图片已经成为人们日常生活中不可或缺的一部分。在各行各业中,图片的应用越发广泛,从而促使了图片处理技术的快速发展。然而,图片的质量对于后续数据处理和分析的准确性和可靠性有着至关重要的影响。本文将从…...

Linux:ACL权限,特殊位和隐藏属性
目录 一.什么是ACL 二.操作步骤 ① 添加测试目录、用户、组,并将用户添加到组 ② 修改目录的所有者和所属组 ③ 设定权限 ④ 为临时用户分配权限 ⑤ 验证acl权限 ⑥ 控制组的acl权限 三. 删除ACL权限 一.什么是ACL 访问控制列表 (Access Control List):ACL 通…...
FL Studio21中文版本价格多少?值不值得购买?
FL Studio,也被称为Fruity Loops,是一款非常受欢迎的数字音频工作站(DAW),适合广泛的音乐制作人群使用。以下是适合使用FL Studio的人群: 初学者:FL Studio拥有直观且用户友好的界面,…...

【论文阅读】ICCV 2023 计算和数据高效后门攻击
文章目录 一.论文信息二.论文内容1.摘要2.引言3.主要图表4.结论 一.论文信息 论文题目: Computation and Data Efficient Backdoor Attacks(计算和数据高效后门攻击) 论文来源: 2023-ICCV(CCF-A) 论文团…...
JavaAPI常用类03
目录 java.lang.Math Math类 代码 运行 Random类 代码 运行 Date类/Calendar类/ SimpleDateFormat类 Date类 代码 运行 Calendar类 代码 运行 SimpleDateFormat类 代码一 运行 常用的转换符 代码二 运行 java.math BigInteger 代码 运行 BigDecimal …...
SpringBoot/Java中OCR实现,集成Tess4J实现图片文字识别
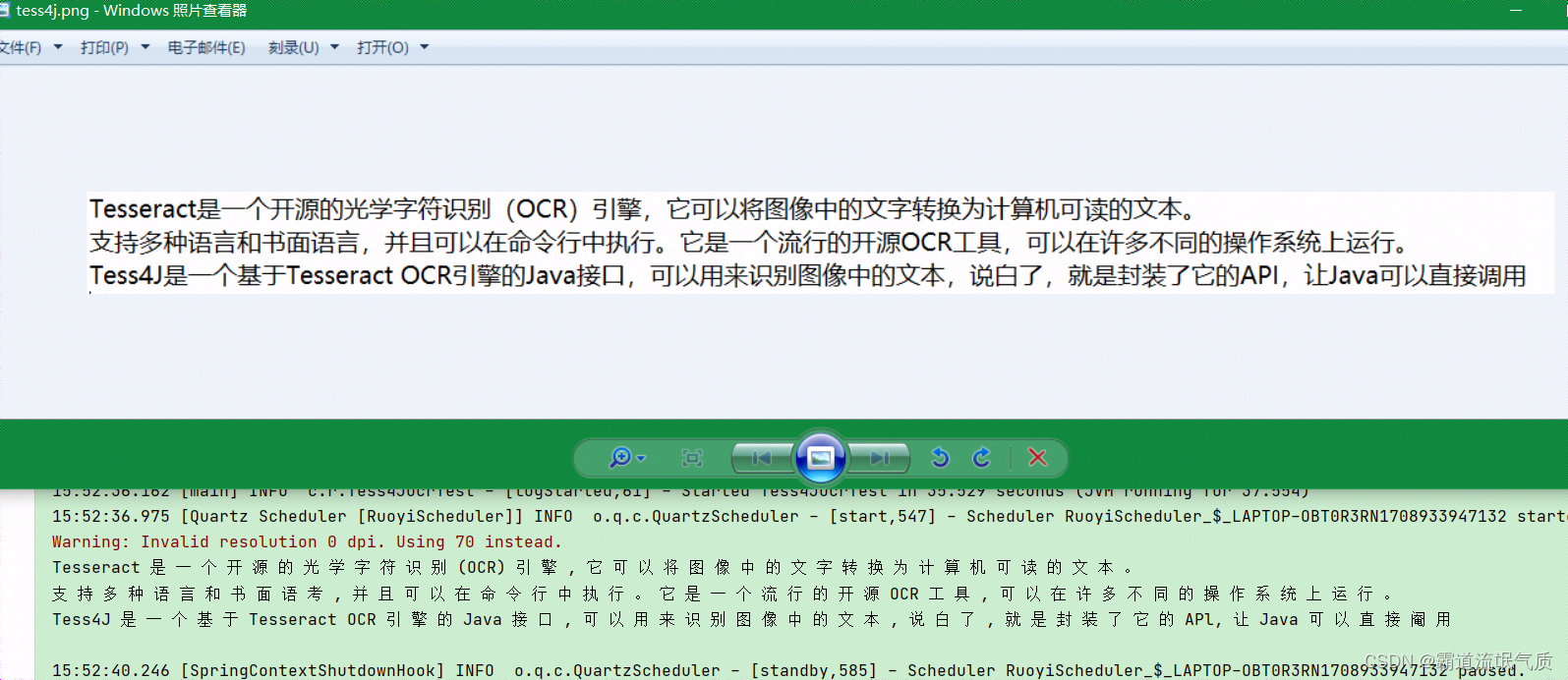
场景 Tesseract Tesseract是一个开源的光学字符识别(OCR)引擎,它可以将图像中的文字转换为计算机可读的文本。 支持多种语言和书面语言,并且可以在命令行中执行。它是一个流行的开源OCR工具,可以在许多不同的操作系…...
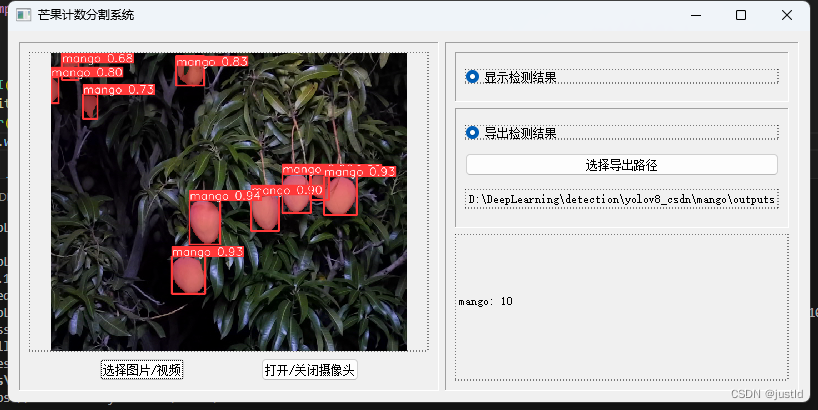
【深度学习目标检测】十九、基于深度学习的芒果计数分割系统-含数据集、GUI和源码(python,yolov8)
使用深度学习算法检测芒果具有显著的优势和应用价值。以下是几个主要原因: 特征学习的能力:深度学习,特别是卷积神经网络(CNN),能够从大量的芒果图像中自动学习和提取特征。这些特征可能是传统方法难以手动…...
-多人联机模式开发环境搭建)
骑砍战团MOD开发(48)-多人联机模式开发环境搭建
一.多人联机模式网络拓扑图 <1.局域网网络拓扑图 <2.互联网网络拓扑图 二.多人联机模式配置 MOD目录下module.ini修改配置项 has_multiplayer 1 has_single_player 1 三.服务端创建 引擎内置presentation页面: prsnt_game_multiplayer_admin_panel start_multi…...

Java+SpringBoot+Vue+MySQL:美食推荐系统的技术革新
✍✍计算机编程指导师 ⭐⭐个人介绍:自己非常喜欢研究技术问题!专业做Java、Python、微信小程序、安卓、大数据、爬虫、Golang、大屏等实战项目。 ⛽⛽实战项目:有源码或者技术上的问题欢迎在评论区一起讨论交流! ⚡⚡ Java实战 |…...
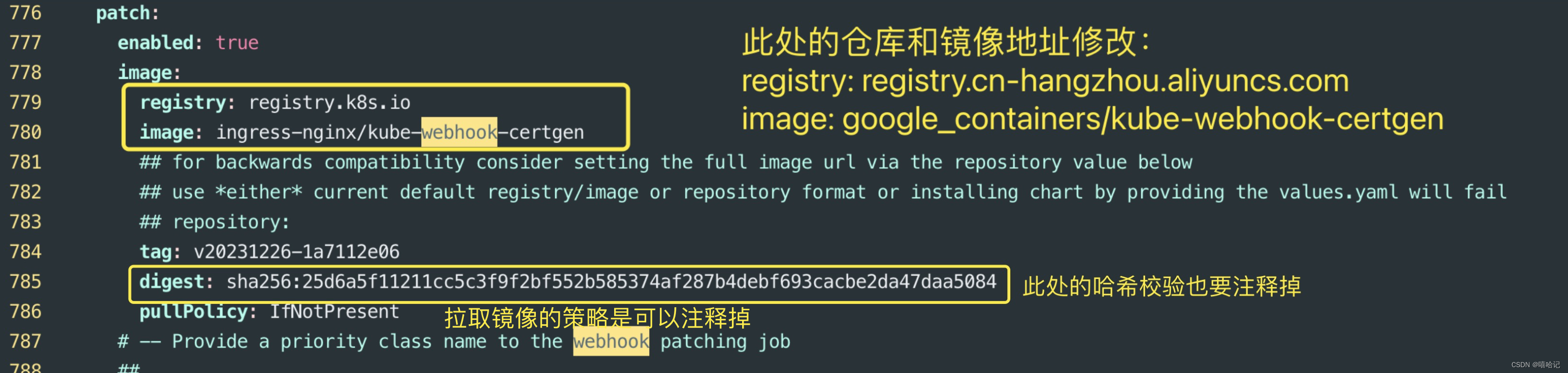
【服务发现--ingress】
1、ingress介绍 Ingress 提供从集群外部到集群内服务的 HTTP 和 HTTPS 路由。 流量路由由 Ingress 资源所定义的规则来控制。 Ingress 是对集群中服务的外部访问进行管理的 API 对象,典型的访问方式是 HTTP。 Ingress 可以提供负载均衡、SSL 终结和基于名称的虚拟…...
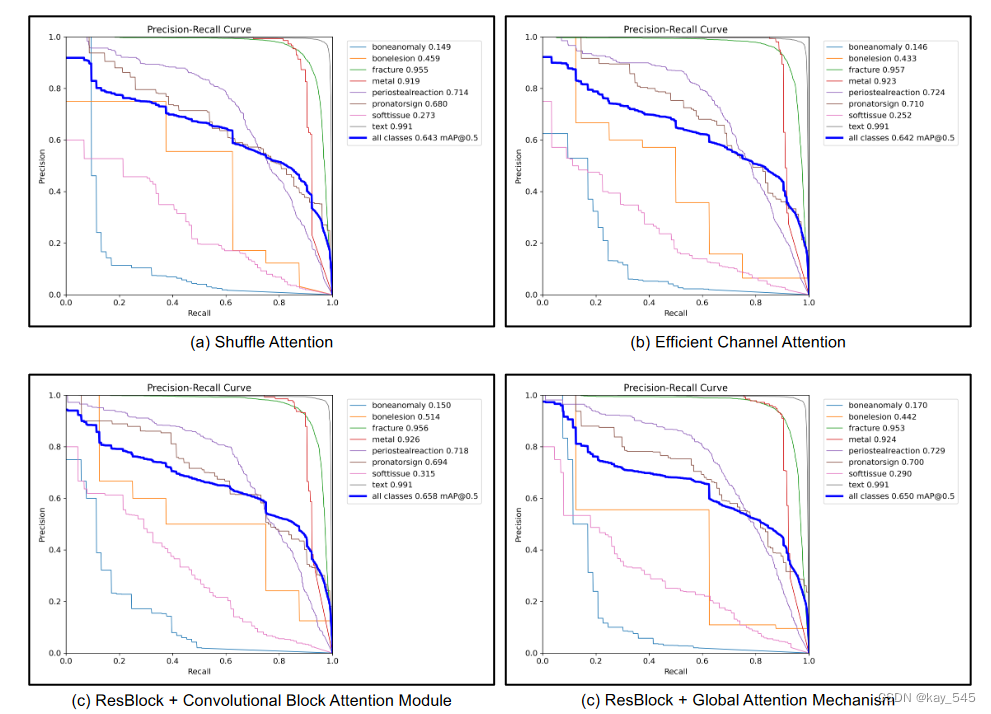
Yolov8有效涨点:YOLOv8-AM,添加多种注意力模块提高检测精度,含代码,超详细
前言 2023 年,Ultralytics 推出了最新版本的 YOLO 模型。注意力机制是提高模型性能最热门的方法之一。 本次介绍的是YOLOv8-AM,它将注意力机制融入到原始的YOLOv8架构中。具体来说,我们分别采用四个注意力模块:卷积块注意力模块…...

苹果分拣检测YOLOV8NANO
苹果分拣,可以检测成熟、切片、损坏、不成熟四种类型,YOLOV8NANO,训练得到PT模型,然后转换成ONNX,OPENCV的DNN调用,支持C,PYTHON 苹果分拣检测YOLOV8NANO,检测四种类型苹果...

使用 Verilog 做一个可编程数字延迟定时器 LS7211-7212
今天的项目是在 Verilog HDL 中实现可编程数字延迟定时器。完整呈现了延迟定时器的 Verilog 代码。 所实现的数字延迟定时器是 CMOS IC LS7212,用于生成可编程延迟。延迟定时器的规格可以在这里轻松找到。基本上,延迟定时器有 4 种操作模式:…...

戏说c语言文章汇总
c语言的起源GNU C和标准C第一篇: hello c!第二篇: 为什么需要编译第三篇: 当你运行./a.out时,发生了什么?第四篇: 简单的加法器第五篇: 两个正数相加竟然变成了负数!第六篇: 西西弗斯推石头(循环)第七篇: 九九乘法表(双循环)第八篇: 如果上天…...
面试redis篇-12Redis集群方案-分片集群
原理 主从和哨兵可以解决高可用、高并发读的问题。但是依然有两个问题没有解决: 海量数据存储问题高并发写的问题 使用分片集群可以解决上述问题,分片集群特征: 集群中有多个master,每个master保存不同数据每个master都可以有…...
【Java EE初阶二十三】servlet的简单理解
1. 初识servlet Servlet 是一个比较古老的编写网站的方式,早起Java 编写网站,主要使用 Servlet 的方式,后来 Java 中产生了一个Spring(一套框架),Spring 又是针对 Servlet 进行了进一步封装,从而让我们编写网站变的更简单了;Sprin…...

c++ http操作接口
很简单的使用libcurl来操作http与服务器来通讯,包含http与https,对外只开放 #include "request.h" #include "response.h" #include "url.h" 三个头文件,简单易用,使用的实例如下: vo…...
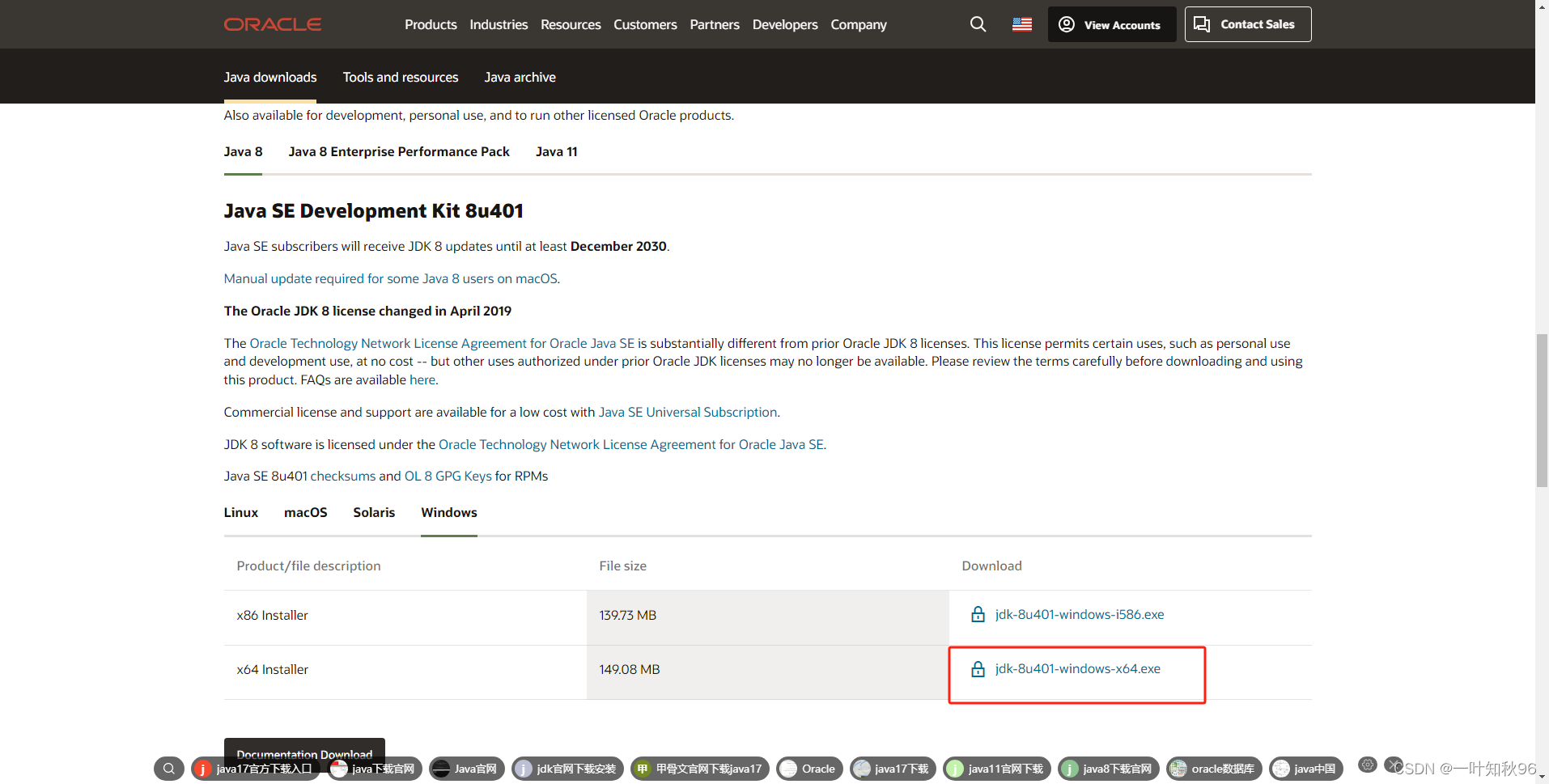
oracle官网下载早期jdk版本
Java Downloads | Oracle JDK Builds from Oracle 以上压缩版,以下安装版 Java Downloads | Oracle 该链接往下拉能看到jdk8和jdk11的安装版 -- end...

不再停留在概念!金融垂直智能体,营销风控价值逐步兑现
今年以来,OpenClaw 小龙虾的横空出世,再度唤醒了社会大众对智能体助手的追捧,这一热门趋势也进一步延伸到金融行业。尽管像OpenClaw这样的智能体能够为金融机构提供更平价、易用的智能体落地痛到,但是碍于金融行业的强数据驱动、严…...
快速定位Camera启动失败问题)
高通Camx架构实战:如何通过日志(Logcat)快速定位Camera启动失败问题
高通Camx架构实战:如何通过日志(Logcat)快速定位Camera启动失败问题 当你在调试高通平台的Camera模块时,是否遇到过这样的场景:应用调用了Camera API,但预览界面一片漆黑,或者直接抛出了Camera设…...

用《权游》学Prolog:逻辑编程实战指南
1. 项目概述:当逻辑编程遇上奇幻史诗去年冬天重刷《权力的游戏》时,我突发奇想:能不能用这部剧的复杂人物关系作为案例库,边追剧边学习Prolog?这个诞生于1972年的逻辑编程语言,在处理家族谱系、联盟关系这类…...

Spring Boot 配置属性绑定机制
Spring Boot配置属性绑定机制解析 在Spring Boot应用中,配置管理是开发的核心环节之一。通过灵活的属性绑定机制,开发者能够轻松将外部配置(如application.yml或环境变量)映射到Java对象中,大幅简化配置管理流程。这一…...
)
【收藏备用】2026年Java程序员必看:不用弃坑,靠大模型轻松涨薪(小白/在职通用)
说真的,2025到2026这一年,看着身边一群搞Java的兄弟纷纷转型大模型,心里挺有感触的。我们当初入门的时候,都是从写接口、搭Spring Boot、连MySQL、配Redis开始,一天天稳扎稳打,以为凭着这些硬技能就能安安稳…...

终极赛博朋克2077存档编辑器:从新手到专家的完全指南
终极赛博朋克2077存档编辑器:从新手到专家的完全指南 【免费下载链接】CyberpunkSaveEditor A tool to edit Cyberpunk 2077 sav.dat files 项目地址: https://gitcode.com/gh_mirrors/cy/CyberpunkSaveEditor 赛博朋克2077存档编辑器是一个强大的开源工具&a…...

从游戏角色碰撞到无人机航测:不规则多边形‘质心’计算的3个硬核实战场景
从游戏角色碰撞到无人机航测:不规则多边形‘质心’计算的3个硬核实战场景 在游戏开发中,当角色踩上一块摇晃的木板时,物理引擎如何确定木板的平衡点?无人机航测时,面对形状不规则的农田,如何快速找到最佳飞…...

Mem Reduct:深入解析Windows系统内存优化工具的核心原理与实践指南
Mem Reduct:深入解析Windows系统内存优化工具的核心原理与实践指南 【免费下载链接】memreduct Lightweight real-time memory management application to monitor and clean system memory on your computer. 项目地址: https://gitcode.com/gh_mirrors/me/memre…...
)
【会议征稿通知 | 大连交通大学主办 | IEEE出版 | EI 、Scopus稳定检索】第七届人工智能、网络与信息技术国际学术会议(AINIT 2026)
第七届人工智能、网络与信息技术国际学术会议(AINIT 2026) 2026 7th International Seminar on Artificial Intelligence, Networking and Information Technology 2026年5月15-17日 | 中国-大连 大会官网:www.ainit.org 截稿时间&…...

5步构建个性化数据可视化仪表盘:开源工具集成实战指南
5步构建个性化数据可视化仪表盘:开源工具集成实战指南 【免费下载链接】tiled Flexible level editor 项目地址: https://gitcode.com/gh_mirrors/ti/tiled 在当今数据驱动的时代,如何快速构建一个功能强大、美观实用的数据可视化仪表盘成为开发者…...