【数据挖掘与商务智能决策】第一章 数据分析与三重工具
numpy基础
numpy与数组
import numpy as np # 用np代替numpy,让代码更简洁
a = [1, 2, 3, 4] # 创建列表a
b = np.array([1, 2, 3, 4]) #从列表ach
print(a)
print(b)
print(type(a)) #打印a类型
print(type(b)) #打印b类型
[1, 2, 3, 4]
[1 2 3 4]
<class ‘list’>
<class ‘numpy.ndarray’>
# 接下来通过列表索引和数组索引来访问列表和数组中的元素,代码如下:
print(a[1])
print(b[1])
print(a[0:2])
print(b[0:2])
2
2
[1, 2]
[1 2]
从上面结果可以看到列表和数组有着相同的索引机制,唯一的区别好像就是数组里面是通过空格分隔元素,而列表用的是逗号。
Numpy数组与列表的区别
从上面的分析得知Numpy数组和列表很类似,那么为什么Python又要创建一个Numpy库呢?其原因很多,这里主要讲两点:
1.数组可以比较方便的进行一些数学运算,而列表则比较麻烦;
2.数组可以支持多维的数据,而列表通常只能储存一维的数据。
c = a * 2
d = b * 2
print(c)
print(d)
[1, 2, 3, 4, 1, 2, 3, 4]
[2 4 6 8]
e = [[1,2], [3,4], [5,6]] # 列表里的元素为小列表
f = np.array([[1,2], [3,4], [5,6]]) # 创建二维数组的一种方式
print(e)
print(f)
[[1, 2], [3, 4], [5, 6]]
[[1 2]
[3 4]
[5 6]]
可以看到列表虽然包含着三个小列表,但其还是一个一维的结构,而创建的二维数组则是一个三行两列的二维结构内容,这个也是之后学习pandas库的核心内容了,因为数据数据处理中经常用到二维数组,也即二维表格结构。
# 创建一维数组
b = np.array([1, 2, 3, 4])
# 创建二维数组
f = np.array([[1,2], [3,4], [5,6]])print(b)
print(f)
[1 2 3 4]
[[1 2]
[3 4]
[5 6]]
除此之外,还有一些常见的创建数组的方式,这里以一维数组为例,我们还可以采用np.arange()函数来产生一维数组,其中括号里可以选择1个或2个或3个参数,代码如下:
# 一个参数 参数值为终点,起点取默认值0,步长取默认值1
x = np.arange(5)
# 两个参数 第一个参数为起点,第二个参数为终点,步长取默认值1,左闭右开
y = np.arange(5,10)
# 三个参数 第一个参数为起点,第二个参数为终点,第三个参数为步长,左闭右开
z = np.arange(5, 10, 0.5)
print(x)
print(y)
print(z)
[0 1 2 3 4]
[5 6 7 8 9]
[5. 5.5 6. 6.5 7. 7.5 8. 8.5 9. 9.5]
我们还可以通过np.random模块来创建随机一维数组,比如可以通过np.random.randn(3)来创建一个服从正太分布(均值为0,方差为1的分布)的3个随机数一维数组,代码如下:
a = np.random.randn(3)
print(a) # 因为随机,所以每次运行的结果都会不太一样
[ 0.39911225 -0.94948119 0.84185058]
如果把np.random.randn(3)换成np.random.rand(3),那生成的就是0-1之间的3个随机数,这个在之后2.3.1小节演示绘制散点图的时候会用到。
至于二维数组的创建与学习,可以利用一维数组中的np.arange()函数和reshape方法产生一个二维数组,比如将0到11个数转换成3行4列的二维数组,代码如下:
a = np.arange(12).reshape(3,4)
print(a)
[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]]
这里再简单提一种随机二维数组的创建,代码如下。其中np.random.randint()函数用来创建随机整数,括号里第一个元素0表示起始数,第二个元素10表示终止数,第三个元素(4, 4)则表示生成一个4行4列的二维数组
a = np.random.randint(0, 10, (4, 4))
print(a)
[[4 9 8 4]
[1 7 6 0]
[6 6 1 1]
[9 6 7 3]]
pandas基础
引言
相较于Numpy来说,Pandas更善于处理二维数据。Pandas主要有两种数据结构:Series和DataFrame。Series类似于通过Numpy产生的一维数组,不同的是Series对象不仅包含数值,还包含一组索引,其创建方式如下:
import pandas as pd
s1 = pd.Series(['丁一', '王二', '张三'])
print(s1)
0 丁一
1 王二
2 张三
dtype: object
# 它也是一个一维数据结构,并且对于每个元素都有一个行索引可以用来定位,比如可以通过s1[1]来定位到第二个元素“王二”。
print(s1[1])
王二
Series单独使用相对较少,pandas主要采用DataFrame数据结构。DataFrame是一种二维表格数据结构,直观一点的话可以将其看作一个Excel表格。
二维数据表格DataFrame的创建
有三种DataFrame常见的创建方法:通过列表创建、通过字典创建及通过二维数组创建。
1. 通过列表创建DataFrame
import pandas as pd
a = pd.DataFrame([[1, 2], [3, 4], [5, 6]])
a # 在Jupyter Nobebook中,代码框中最后一行代码可以只输入变量名称,即可自动打印,而无需通过print()函数
| 0 | 1 | |
|---|---|---|
| 0 | 1 | 2 |
| 1 | 3 | 4 |
| 2 | 5 | 6 |
可以看到通过pandas的DataFrame功能生成的二维数组更像我们在Excel中看到二维表格数据,它也有行索引和列索引,其中这里的索引序号都是从0开始的。
# 我们还可以自定义其列索引和行索引名称,代码如下:
a = pd.DataFrame([[1, 2], [3, 4], [5, 6]], columns=['date', 'score'], index=['A', 'B', 'C'])# 通过列表生成DataFrame还可以采用如下的方式,演示代码如下:
a = pd.DataFrame() # 创建一个空DataFrame
date = [1, 3, 5]
score = [2, 4, 6]
a['date'] = date
a['score'] = score
a
| date | score | |
|---|---|---|
| 0 | 1 | 2 |
| 1 | 3 | 4 |
| 2 | 5 | 6 |
2. 通过字典创建DataFrame
# 通过Pandas创建二维数组 - 字典法
b = pd.DataFrame({'a': [1, 3, 5], 'b': [2, 4, 6]}, index=['x', 'y', 'z'])
b # 在Jupyter Notebook编辑器中可以直接输入b进行查看
| a | b | |
|---|---|---|
| x | 1 | 2 |
| y | 3 | 4 |
| z | 5 | 6 |
# 如果想让字典键变成行索引,可以通过from_dict的方式来将字典转换成DataFrame,并同时设置orient参数为index,代码如下:
c = pd.DataFrame.from_dict({'a': [1, 3, 5], 'b': [2, 4, 6]}, orient="index")
c
print(c) # 也可以直接输入c进行查看变量结果
0 1 2
a 1 3 5
b 2 4 6
其中orient参数指定字典键对应的方向,默认值为columns,如果不设置成index的话,则还是默认字典键为列索引
补充知识点:通过.T来对表格进行转置
b = pd.DataFrame({'a': [1, 3, 5], 'b': [2, 4, 6]})
print(b)
print(b.T)
a b
0 1 2
1 3 4
2 5 60 1 2
a 1 3 5
b 2 4 6
3. 通过二维数组创建
import numpy as np
np.arange(12).reshape(3,4)
array([[ 0, 1, 2, 3],[ 4, 5, 6, 7],[ 8, 9, 10, 11]])
# 通过Numpy产生的二维数组,也可以创建DataFrame,这里以2.1.3小节里提到的二维数组为例生成一个3行4列的DataFrame,代码如下:
import numpy as np
d = pd.DataFrame(np.arange(12).reshape(3,4), index=[1, 2, 3], columns=['A', 'B', 'C', 'D'])
d
| A | B | C | D | |
|---|---|---|---|---|
| 1 | 0 | 1 | 2 | 3 |
| 2 | 4 | 5 | 6 | 7 |
| 3 | 8 | 9 | 10 | 11 |
补充知识点:修改行索引或列索引名称
a = pd.DataFrame([[1, 2], [3, 4]], columns=['date', 'score'], index=['A', 'B'])
a
| date | score | |
|---|---|---|
| A | 1 | 2 |
| B | 3 | 4 |
# 如果想对索引进行重命名的话,rename()函数的使用方法如下:
a = a.rename(index={'A':'阿里', 'B':'腾讯'}, columns={'date':'日期','score':'分数'})
a
| 日期 | 分数 | |
|---|---|---|
| 阿里 | 1 | 2 |
| 腾讯 | 3 | 4 |
补充知识点:这里通过rename之后并没有改变原表格结构,需要重新赋值给a才能改变原表格;或者在rename()中设置inplace参数为True,也能实现真正替换,代码如下:
a = pd.DataFrame([[1, 2], [3, 4]], columns=['date', 'score'], index=['A', 'B'])
a.rename(index={'A':'阿里', 'B':'腾讯'}, columns={'date':'日期','score':'分数'}, inplace=True) # 另一种方法
a
| 日期 | 分数 | |
|---|---|---|
| 阿里 | 1 | 2 |
| 腾讯 | 3 | 4 |
# 通过.values属性,也可以查看此时的index值
print(a.index.values)
['阿里' '腾讯']
# 如果想给行索引命名,也可以通过如下代码
a.index.name = '艾尔海森'
a
| 日期 | 分数 | |
|---|---|---|
| 艾尔海森 | ||
| 阿里 | 1 | 2 |
| 腾讯 | 3 | 4 |
# 如果想把行索引变成某列的内容,可以使用set_index()函数,代码如下:
a = a.set_index('日期')
a
| 分数 | |
|---|---|
| 日期 | |
| 1 | 2 |
| 3 | 4 |
# 如果此时想把行索引换成数字索引,则可以使用reset_index()函数,代码如下:
a = a.reset_index()
a
| 日期 | 分数 | |
|---|---|---|
| 0 | 1 | 2 |
| 1 | 3 | 4 |
Excel等文件的读取和写入
1. 文件的读取
# 输入以下代码,用于读取Excel数据:
import pandas as pd
data = pd.read_excel('D://coder//randomnumbers//datamining//Chap2//data.xlsx') # data为DataFrame结构
data.head() # 通过head()可以查看前5行数据,如果写成head(10)则可以查看前10行数据
D:\coder\randomnumbers\venv\lib\site-packages\openpyxl\worksheet\header_footer.py:48: UserWarning: Cannot parse header or footer so it will be ignoredwarn("""Cannot parse header or footer so it will be ignored""")
| date | score | price | |
|---|---|---|---|
| 0 | 2018-09-03 | 70 | 23.55 |
| 1 | 2018-09-04 | 75 | 24.43 |
| 2 | 2018-09-05 | 65 | 23.41 |
| 3 | 2018-09-06 | 60 | 22.81 |
| 4 | 2018-09-07 | 70 | 23.21 |
# 其中read_excel还可以设定参数,使用方式如下:
# pd.read_excel('data.xlsx', sheet_name=0, encoding='utf-8')
# 输入以下代码,用于读取CSV文件:
data = pd.read_csv('data.csv')
data.head()
| date | score | price | |
|---|---|---|---|
| 0 | 2018-09-03 | 70 | 23.55 |
| 1 | 2018-09-04 | 75 | 24.43 |
| 2 | 2018-09-05 | 65 | 23.41 |
| 3 | 2018-09-06 | 60 | 22.81 |
| 4 | 2018-09-07 | 70 | 23.21 |
# read_csv也可以指定参数,使用方式如下:
# data = pd.read_csv('data.csv', delimiter=',', encoding='utf-8')
2. 文件写入
# 先生成一个DataFrame
data = pd.DataFrame([[1, 2], [3, 4], [5, 6]], columns=['A列','B列'])
# 将DataFrame导入到Excel当中
data.to_excel('data_new.xlsx')
运行之后将在代码所在的文件夹生成一个名为data_new的Excel文件m
在上表中,保存的Excel第一列还保留了索引信息,如果想将其删去,可以设置to_excel的参数index为False。to_excel的常见参数有如下一些:sheet_name:数据表名;index:True or False,默认为True保存索引信息,即输出文件的第一列为索引值,选择False的话则忽略索引信息;columns:选择所需要的列;encoding:编码方式。
例如要将数据表格导入到Excel文件中并忽略行索引信息,则代码如下:
data.to_excel('data_new.xlsx', index=False)
# 通过类似的方式,可以将数据写入到CSV文件当中,代码如下:
data.to_csv('data_new.csv')
和to_excel类似,to_csv也可以设置index、columns、encoding等参数。注意,如果在导出CSV文件事出现了中文乱码现象,且encoding参数设置成“utf-8”失效,则需要将encoding参数设置成“utf_8_sig”,代码如下:
data.to_csv('演示.csv', index=False, encoding="utf_8_sig")
补充知识点:文件相对路径与绝对路径
相对路径
文件相对路径,即代码所在的文件夹,例如上面案例中写的data.to_excel(‘data.xlsx’)就是在代码所在的文件夹生成Excel文件。
绝对路径
文件绝对路径,就是文件完整的路径名称,例如’E:\大数据分析\data.xlsx’就是绝对路径,不过因为在Python中反斜杠“\”经常有特殊含义,比如说“\n”表示换行,所以通常建议写绝对路径的时候写两个反斜杠取消可能存在的单个反斜杠的特殊含义,写成’E:\\大数据分析\\data.xlsx’。
除了用两个反斜杠来取消一个反斜杠的特殊意义外,还可以在文件路径的字符串前面加一个r,也可以取消单个反斜杠的特殊含义,代码如下:
data.to_excel('E:\\大数据分析\\data.xlsx') # 绝对路径推荐写法1,此时E盘要有一个名为“大数据分析”的文件夹
data.to_excel(r'E:\大数据分析\data.xlsx') # 绝对路径推荐写法2,此时E盘要有一个名为“大数据分析”的文件夹
数据读取与筛选
# 首先创建一个三行三列的表格,行索引设定为r1、r2和r3,列索引设定为c1、c2和c3,以此为例来演示数据的读取与筛选,代码如下:
import pandas as pd
data = pd.DataFrame([[1, 2, 3], [4, 5, 6], [7, 8, 9]], index=['r1', 'r2', 'r3'], columns=['c1', 'c2', 'c3'])
data
| c1 | c2 | c3 | |
|---|---|---|---|
| r1 | 1 | 2 | 3 |
| r2 | 4 | 5 | 6 |
| r3 | 7 | 8 | 9 |
data = pd.DataFrame(np.arange(1,10).reshape(3,3), index=['r1', 'r2', 'r3'], columns=['c1', 'c2', 'c3'])
data
| c1 | c2 | c3 | |
|---|---|---|---|
| r1 | 1 | 2 | 3 |
| r2 | 4 | 5 | 6 |
| r3 | 7 | 8 | 9 |
1. 数据选取
(1) 按列选取数据
# 通过以下代码可以通过列来选取数据,这里先选取单列。
a = data['c1']
a
r1 1
r2 4
r3 7
Name: c1, dtype: int32
此时返回的结果里没有表头信息了,这是因为通过data[‘c1’]选取一列的时候返回的是一个一维序列结构的类,也可以通过如下代码返回一个二维的表格数据。
b = data[['c1']]
b
| c1 | |
|---|---|
| r1 | 1 |
| r2 | 4 |
| r3 | 7 |
若要选取多列,则需要在中括号[]中给个列表,比如要读取c1和c3列,则可以写为data[[‘c1’, ‘c3’]]。这里需要特别注意的是,必须是一个列表,而不能是data[‘c1’, ‘c3’],代码如下:
c = data[['c1', 'c3']]
c
| c1 | c3 | |
|---|---|---|
| r1 | 1 | 3 |
| r2 | 4 | 6 |
| r3 | 7 | 9 |
(2) 按行选取数据
# 选取第2到3行的数据,注意序号从0开始,左闭右开
a = data[1:3]
a
| c1 | c2 | c3 | |
|---|---|---|---|
| r2 | 4 | 5 | 6 |
| r3 | 7 | 8 | 9 |
而pandas推荐使用iloc方法来根据行的序号进行行选取,它是根据行序号选取的另一种方法,pandas觉得这样更加直观,不会像data[1:3]可能会引起混淆,代码如下:
b = data.iloc[1:3]
b
| c1 | c2 | c3 | |
|---|---|---|---|
| r2 | 4 | 5 | 6 |
| r3 | 7 | 8 | 9 |
而且如果要选取单行的话,就必须得用iloc了,比如选择倒数第一行,代码如下:
c = data.iloc[-1]
c
c1 7
c2 8
c3 9
Name: r3, dtype: int32
除了通过行的序号选取外,还可以通过loc方法根据行的名称来进行选取,代码如下:
d = data.loc[['r2', 'r3']]
d
| c1 | c2 | c3 | |
|---|---|---|---|
| r2 | 4 | 5 | 6 |
| r3 | 7 | 8 | 9 |
有的时候如果行数很多,可以通过head()方法来选取前5行,代码如下:
e = data.head()
e
| c1 | c2 | c3 | |
|---|---|---|---|
| r1 | 1 | 2 | 3 |
| r2 | 4 | 5 | 6 |
| r3 | 7 | 8 | 9 |
这里因为只创建了3行数据,所以通过data.head()会把全部数据都取到,如果只想取前两行的数据,可以写成data.head(2)。
(3) 按照区块来选取
# 如果想选取某几行的某几列,则可以通过如下代码来实现,比如获得c1和c3列的前二行。
a = data[['c1', 'c3']][0:2] # 也可写成data[0:2][['c1', 'c3']]
a
| c1 | c3 | |
|---|---|---|
| r1 | 1 | 3 |
| r2 | 4 | 6 |
# 在实战中,通常采用iloc和列选取混合的方式来选取特定的区块或值,代码如下:
b = data.iloc[0:2][['c1', 'c3']]
b
| c1 | c3 | |
|---|---|---|
| r1 | 1 | 3 |
| r2 | 4 | 6 |
# 如果要选取单个的值,那么该方法就更有优势,比如选取c3列第一行的信息,就不能写成data['c3'][0]或data[0]['c3']了。下面的写法则比较清晰,iloc[0]先选取第一行,然后再选取c3列。
c = data.iloc[0]['c3']
c
3
# 也可以通过iloc和loc方法来同时选择行和列,代码如下:
d = data.loc[['r1', 'r2'], ['c1', 'c3']]
e = data.iloc[0:2, [0, 2]]
print(d)
print(e)
c1 c3
r1 1 3
r2 4 6c1 c3
r1 1 3
r2 4 6
# 老版本DataFrame还有一个ix选择区域的方法,它也可以同时选择行和列,而且里面的内容不像loc或者iloc必须为字符索引或者数字索引,代码如下:
#f = data.ix[0:2, ['c1', 'c3']]
#f
2. 数据筛选
# 在方括号里还可以通过判断条件来过滤行,比如选取c1列数字大于1的行,代码如下:
a = data[data['c1'] > 1]
a
| c1 | c2 | c3 | |
|---|---|---|---|
| r2 | 4 | 5 | 6 |
| r3 | 7 | 8 | 9 |
# 如果有多个筛选条件,则可以通过“&”符号(表示“且”)或“|”(表示“或”)连接,比如这边筛选,c1列数字大于1且c2列数字小于8的行,代码如下,注意要记得加判断条件两旁的小括号。
b = data[(data['c1'] > 1) & (data['c2'] < 8)]
b
| c1 | c2 | c3 | |
|---|---|---|---|
| r2 | 4 | 5 | 6 |
3. 数据整体情况查看
# 通过表格的shape属性,可以查看表格整体的行数和列数,在表格数据量较大的时候能快速了解表格的行数和列数。
data.shape
(3, 3)
# 通过表格的describe()函数可以快速的查看表格每一列的数量、平均值、标准差、最小值、25分位数、50分位数、75分位数、最大值等信息,代码如下:
data.describe()
| c1 | c2 | c3 | |
|---|---|---|---|
| count | 3.0 | 3.0 | 3.0 |
| mean | 4.0 | 5.0 | 6.0 |
| std | 3.0 | 3.0 | 3.0 |
| min | 1.0 | 2.0 | 3.0 |
| 25% | 2.5 | 3.5 | 4.5 |
| 50% | 4.0 | 5.0 | 6.0 |
| 75% | 5.5 | 6.5 | 7.5 |
| max | 7.0 | 8.0 | 9.0 |
# 通过value_counts()函数则可以快速的查看某一列都有什么数据,以及该数据出现的频次,代码如下:
data['c1'].value_counts()
1 1
4 1
7 1
Name: c1, dtype: int64
4. 数据运算、排序与删除
(1) 数据运算
# 从已有的列中,通过数据运算创造一个新的一列,代码如下:
data['c4'] = data['c3'] - data['c1']
data.head()
| c1 | c2 | c3 | c4 | |
|---|---|---|---|---|
| r1 | 1 | 2 | 3 | 2 |
| r2 | 4 | 5 | 6 | 2 |
| r3 | 7 | 8 | 9 | 2 |
(2) 数据排序
# 通过sort_values()可以根据列对数据进行排序,比如要对c2列进行降序排序,代码如下:
a = data.sort_values(by='c2', ascending=False)
a
| c1 | c2 | c3 | c4 | |
|---|---|---|---|---|
| r3 | 7 | 8 | 9 | 2 |
| r2 | 4 | 5 | 6 | 2 |
| r1 | 1 | 2 | 3 | 2 |
# 其实如果是按列筛选,我们也可以直接写成如下代码,不用写“by=”,效果一样:
a = data.sort_values('c2', ascending=False)
a
| c1 | c2 | c3 | c4 | |
|---|---|---|---|---|
| r3 | 7 | 8 | 9 | 2 |
| r2 | 4 | 5 | 6 | 2 |
| r1 | 1 | 2 | 3 | 2 |
# 此外,通过sort_index()可以根据行索引进行排序,如按行索引进行升序排列,代码如下:
a = a.sort_index()
a
| c1 | c2 | c3 | c4 | |
|---|---|---|---|---|
| r1 | 1 | 2 | 3 | 2 |
| r2 | 4 | 5 | 6 | 2 |
| r3 | 7 | 8 | 9 | 2 |
(3) 数据删除
# 例如删除c1列的数据,代码如下:
a = data.drop(columns='c1')
a
| c2 | c3 | c4 | |
|---|---|---|---|
| r1 | 2 | 3 | 2 |
| r2 | 5 | 6 | 2 |
| r3 | 8 | 9 | 2 |
# 删除多列的数据,比如c1和c3列,可以通过列表的方式将所需删除的列声明,代码如下:
b = data.drop(columns=['c1', 'c3'])
b
| c2 | c4 | |
|---|---|---|
| r1 | 2 | 2 |
| r2 | 5 | 2 |
| r3 | 8 | 2 |
# 如果要删除行数据,比如删去第一行和第三行的数据,代码如下:
c = data.drop(index=['r1','r3'])
c
| c1 | c2 | c3 | c4 | |
|---|---|---|---|---|
| r2 | 4 | 5 | 6 | 2 |
注意这里要输入行索引的名称而不是数字序号,不过如果行索引名称本来就是数字,那么可以输入对应数字。上面删除数据后又赋值给新的变量不会改变原来表格data的结构,如果想改变原来表格的结构,可以令inplace参数为True,代码如下:
data.drop(index=['r1','r3'], inplace=True)
data
| c1 | c2 | c3 | c4 | |
|---|---|---|---|---|
| r2 | 4 | 5 | 6 | 2 |
数据表拼接
# 假设有如下两个DataFrame表格,需要对它们进行合并:
import pandas as pd
df1 = pd.DataFrame({'公司': ['万科', '阿里', '百度'], '分数': [90, 95, 85]})
df2 = pd.DataFrame({'公司': ['万科', '阿里', '京东'], '股价': [20, 180, 30]})
df1
| 公司 | 分数 | |
|---|---|---|
| 0 | 万科 | 90 |
| 1 | 阿里 | 95 |
| 2 | 百度 | 85 |
df2
| 公司 | 股价 | |
|---|---|---|
| 0 | 万科 | 20 |
| 1 | 阿里 | 180 |
| 2 | 京东 | 30 |
1. merge()函数
# merge()函数根据一个或多个键将不同表格中的行连接起来,示例如下:
df3 = pd.merge(df1, df2)
df3
| 公司 | 分数 | 股价 | |
|---|---|---|---|
| 0 | 万科 | 90 | 20 |
| 1 | 阿里 | 95 | 180 |
可以看到通过merge()函数直接选取相同的列名(“公司”这一列)进行合并,而且默认选取的是两种表共有的列内容(万科、阿里),有的时候如果相同的列名不止一个,可以通过on参数指定按照哪一列进行合并,代码如下:
df3 = pd.merge(df1, df2, on=‘公司’)
默认的合并其实是取交集(inner连接),也即取两表共有的内容,如果想取并集(outer连接),也即选取两表所有的内容,可以设置how参数,代码如下:
df3 = pd.merge(df1, df2, how='outer')
df3
| 公司 | 分数 | 股价 | |
|---|---|---|---|
| 0 | 万科 | 90.0 | 20.0 |
| 1 | 阿里 | 95.0 | 180.0 |
| 2 | 百度 | 85.0 | NaN |
| 3 | 京东 | NaN | 30.0 |
如果想保留左表全部内容,而对右表不太在意的话,可以将how参数设置为left:
df3 = pd.merge(df1, df2, how='left')
df3
| 公司 | 分数 | 股价 | |
|---|---|---|---|
| 0 | 万科 | 90 | 20.0 |
| 1 | 阿里 | 95 | 180.0 |
| 2 | 百度 | 85 | NaN |
同理,如果想保留右表全部内容,而对左表不太在意的话,可以将how参数设置为right。
# 如果想根据行索引进行合并,可以通过设置left_index和right_index参数,代码如下:
df3 = pd.merge(df1, df2, left_index=True, right_index=True)
df3
| 公司_x | 分数 | 公司_y | 股价 | |
|---|---|---|---|---|
| 0 | 万科 | 90 | 万科 | 20 |
| 1 | 阿里 | 95 | 阿里 | 180 |
| 2 | 百度 | 85 | 京东 | 30 |
补充知识点:根据行索引合并的join()函数
通过join()函数也可以根据行索引进行表格合并。join()函数也是一种数据表拼接的常见函数,它是通过行索引进行合并,演示代码如下:
df3 = df1.join(df2, lsuffix='_x', rsuffix='_y')
df3
| 公司_x | 分数 | 公司_y | 股价 | |
|---|---|---|---|---|
| 0 | 万科 | 90 | 万科 | 20 |
| 1 | 阿里 | 95 | 阿里 | 180 |
| 2 | 百度 | 85 | 京东 | 30 |
注意在通过join()函数进行拼接的时候,两张表格中不能有名字相同的列名,如果存在的话,则需要设置lsuffix参数(左表同名列的后缀,suffix的中文翻译就是后缀的意思,l表示left)和rsuffix参数(右表同名列的后缀,这里的r表示right),没有相同列名的话,则可以直接写df1.join(df2),相对于merge()函数写法较为简洁一些。
实战中可以只记merge()函数的用法,这里讲解join()函数的目的是为了看到别人用join()函数的时候能够理解。该知识点在14.3.3小节进行数据表合并的时候便有应用。
2. concat()函数
# 默认情况下,axis=0,按行方向进行连接。
df3 = pd.concat([df1,df2], axis=0)
df3
| 公司 | 分数 | 股价 | |
|---|---|---|---|
| 0 | 万科 | 90.0 | NaN |
| 1 | 阿里 | 95.0 | NaN |
| 2 | 百度 | 85.0 | NaN |
| 0 | 万科 | NaN | 20.0 |
| 1 | 阿里 | NaN | 180.0 |
| 2 | 京东 | NaN | 30.0 |
此时行索引为原来两张表各自的索引,如果想重置索引,可以使用6.2.1小节讲过的reset_index()方法将索引重置,或者在concat()中设置ignore_index=True,忽略原有索引,按新数字索引进行排序。
# 如果想按列方向进行连接,可以设置axis参数为1。
df3 = pd.concat([df1,df2],axis=1)
df3
| 公司 | 分数 | 公司 | 股价 | |
|---|---|---|---|---|
| 0 | 万科 | 90 | 万科 | 20 |
| 1 | 阿里 | 95 | 阿里 | 180 |
| 2 | 百度 | 85 | 京东 | 30 |
3. append()函数
# append()函数可以说concat()函数的简化版,效果和pd.concat([df1,df2]) 类似,代码如下:
df3 = df1.append(df2)
df3
| 公司 | 分数 | 股价 | |
|---|---|---|---|
| 0 | 万科 | 90.0 | NaN |
| 1 | 阿里 | 95.0 | NaN |
| 2 | 百度 | 85.0 | NaN |
| 0 | 万科 | NaN | 20.0 |
| 1 | 阿里 | NaN | 180.0 |
| 2 | 京东 | NaN | 30.0 |
# append()函数还有个常用的功能,和列表.append()一样,可用来新增元素,代码如下:
df3 = df1.append({'公司': '腾讯', '分数': '90'}, ignore_index=True)
df3
| 公司 | 分数 | |
|---|---|---|
| 0 | 万科 | 90 |
| 1 | 阿里 | 95 |
| 2 | 百度 | 85 |
| 3 | 腾讯 | 90 |
Matplotlib数据可视化基础
基本图形绘制
1. 绘制折线图
%matplotlib inline
import matplotlib.pyplot as plt
x = [1, 2, 3]
y = [2, 4, 6]
plt.plot(x, y) # 绘制折线图
import pylab as pl
pl.xticks(rotation=45)
plt.show() # 展示图形
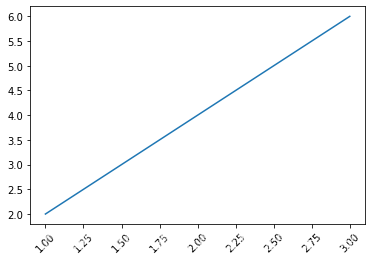
如果想让x和y之间有些数学关系,列表是不太容易进行数学运算的,这时候就可以通过2.1.2小节所讲的Numpy库引入一维数组进行数学运算,代码如下:
import numpy as np
import matplotlib.pyplot as pltx1 = np.array([1, 2, 3])# 第一条线:y = x + 1
y1 = x1 + 1
plt.plot(x1, y1) # 使用默认参数画图# 第二条线:y = x*2
y2 = x1*2
# color设置颜色,linewidth设置线宽,单位像素,linestyle默认为实线,“--”表示虚线
plt.plot(x1, y2, color='red', linewidth=3, linestyle='--')plt.show()
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0MMvVPBi-1678026263862)(output_6_0.png)]](https://img-blog.csdnimg.cn/ef39f6c5d886430291729c499afc0682.png)
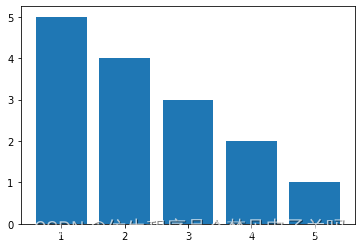
2. 绘制柱状图
import matplotlib.pyplot as plt
x = [1, 2, 3, 4, 5]
y = [5, 4, 3, 2, 1]
plt.bar(x, y)
plt.show()
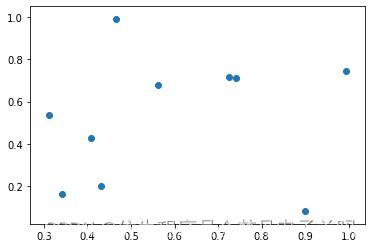
3. 绘制散点图
import matplotlib.pyplot as plt
import numpy as npx = np.random.rand(10)
y = np.random.rand(10)
plt.scatter(x, y)
plt.show()
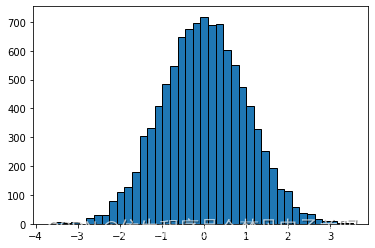
4. 绘制直方图
import matplotlib.pyplot as plt
import numpy as np # 随机生成10000个服从正态分布的数据
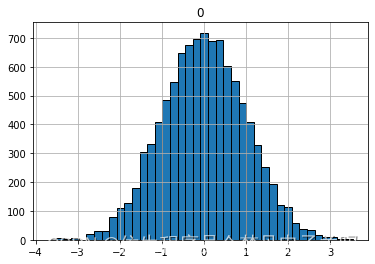
data = np.random.randn(10000)# 绘制直方图,bins为颗粒度,即直方图的长条形数目,edgecolor为长条形边框颜色
plt.hist(data, bins=40, edgecolor='black')plt.show()
补充知识点:在pandas库中的快捷绘图技巧
# 这种写法只适合pandas中的DataFrame,不能直接用于Numpy的数组
import pandas as pd
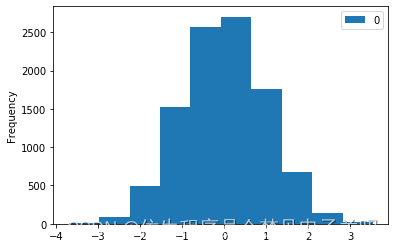
df = pd.DataFrame(data) # 将绘制直方图中的data数组转换成DataFrame()格式
df.hist(bins=40, edgecolor='black')
array([[<matplotlib.axes._subplots.AxesSubplot object at 0x000001E7E77685F8>]],dtype=object)
# 此外,除了写df.hist()外,还可以通过下面这种pandas库里的通用绘图代码绘图:
df.plot(kind='hist')
<matplotlib.axes._subplots.AxesSubplot at 0x1e7e785e518>
这里是通过设置kind参数为hist来绘制直方图,通过这种通用绘图代码,pandas库除了可以便捷的绘制直方图外,它还可以通过设置kind参数快捷地绘制其他图形,演示代码如下,首先通过2.2.1节的知识点创建一个二维DataFrame表格df。
import pandas as pd
df = pd.DataFrame([[8000, 6000], [7000, 5000], [6500, 4000]], columns=['人均收入', '人均支出'], index=['北京', '上海', '广州'])
df
| 人均收入 | 人均支出 | |
|---|---|---|
| 北京 | 8000 | 6000 |
| 上海 | 7000 | 5000 |
| 广州 | 6500 | 4000 |
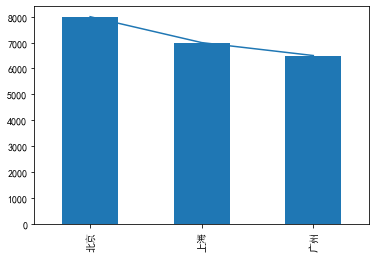
# 此时可以通过pandas同时绘制折线图或者柱状图,代码如下:
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 解决负号'-'显示为方块的问题df['人均收入'].plot(kind='line') # kind=line绘制折线图,不设置则默认折线图
df['人均收入'].plot(kind='bar') # kind=bar绘制柱状图
<matplotlib.axes._subplots.AxesSubplot at 0x1e7e78da9e8>
df['人均收入'].plot(kind='pie') # kind=pie绘制饼图
<matplotlib.axes._subplots.AxesSubplot at 0x1e7e79757f0>

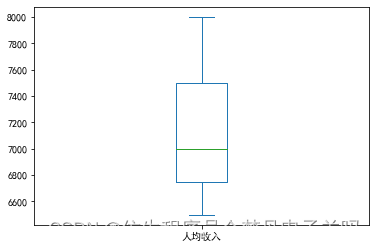
df['人均收入'].plot(kind='box') # kind=box绘制箱体图
<matplotlib.axes._subplots.AxesSubplot at 0x1e7e79d24a8>
数据可视化常见小技巧
1. 添加文字说明
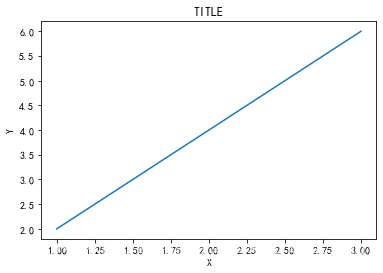
# 通过plt.title(name)给图画添加标题;通过plt.xlable(),plt.ylable()用于添加x轴和y轴标签。
import matplotlib.pyplot as pltx = [1, 2, 3]
y = [2, 4, 6]
plt.plot(x, y)
plt.title('TITLE') # 添加标题
plt.xlabel('X') # 添加X轴标签
plt.ylabel('Y') # 添加Y轴标签
plt.show() # 显示图片
2. 添加图例
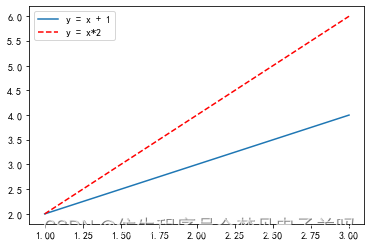
# 通过plt.legend()来添加图例,添加前需要设置好lable(标签)参数,代码如下:
import numpy as np
import matplotlib.pyplot as plt# 第一条线, 设定标签lable为y = x + 1
x1 = np.array([1, 2, 3])
y1 = x1 + 1
plt.plot(x1, y1, label='y = x + 1') # 第二条线, 设定标签lable为y = x*2
y2 = x1*2
plt.plot(x1, y2, color='red', linestyle='--', label='y = x*2')plt.legend(loc='upper left') # 图例位置设置为左上角
plt.show()
3. 设置双坐标轴
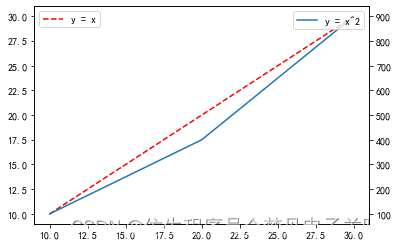
上面的例子可以在一张图里画出两条线,但如果两条线的取值范围相差比较大,那么画出来的图效果便不太好,那么此时如何来画出两条y坐标轴呢?可以在画完第一个图之后,写如下一行代码即可设置双坐标轴。
plt.twinx()
需要注意的是如果设置了双坐标轴,那么添加图例的时候,每画一次图就得添加一次,而不能在最后统一添加。这里以y = x和y = x^2为例,演示下如何设置双坐标轴,代码如下:
import numpy as np
import matplotlib.pyplot as plt# 第一条线, 设定标签lable为y = x
x1 = np.array([10, 20, 30])
y1 = x1
plt.plot(x1, y1, color='red', linestyle='--', label='y = x')
plt.legend(loc='upper left') # 该图图例设置在左上角plt.twinx() # 设置双坐标轴# 第二条线, 设定标签lable为y = x^2
y2 = x1*x1
plt.plot(x1, y2, label='y = x^2')
plt.legend(loc='upper right') # 改图图例设置在右上角plt.show()
4. 设置图片大小
plt.rcParams['figure.figsize'] = (8, 6)
x = [1, 2, 3]
y = [2, 4, 6]
plt.plot(x, y)
plt.show() # 显示图片
5. 设置X轴刻度的角度
import matplotlib.pyplot as plt
x = [1, 2, 3]
y = [2, 4, 6]
plt.plot(x, y) # 绘制折线图import pylab as pl
pl.xticks(rotation=45) # 设置角度为45度plt.show() # 展示图形
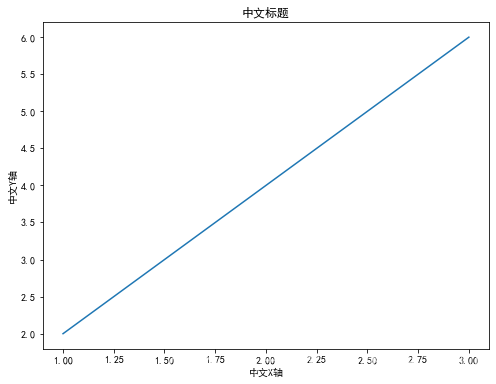
6. 解决中文显示问题
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 解决负号'-'显示为方块的问题x = [1, 2, 3]
y = [2, 4, 6]
plt.plot(x, y)
plt.title('中文标题') # 添加标题
plt.xlabel('中文X轴') # 添加X轴标签
plt.ylabel('中文Y轴') # 添加Y轴标签
plt.show() # 显示图片
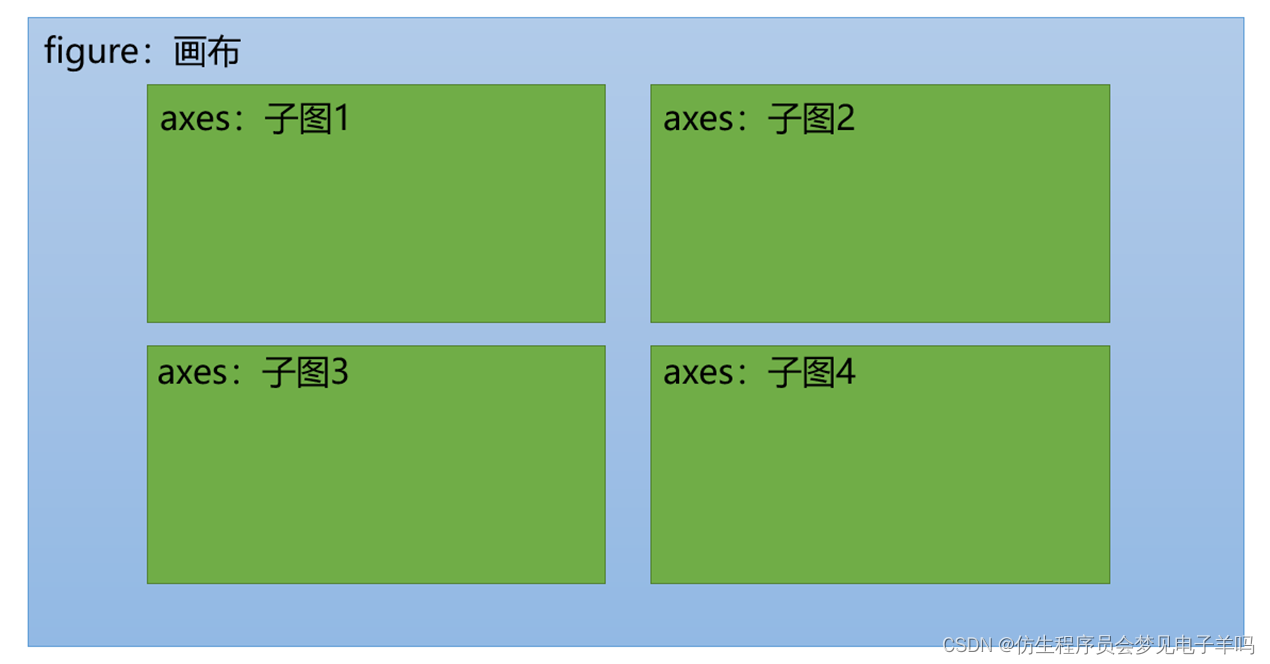
7. 绘制多图
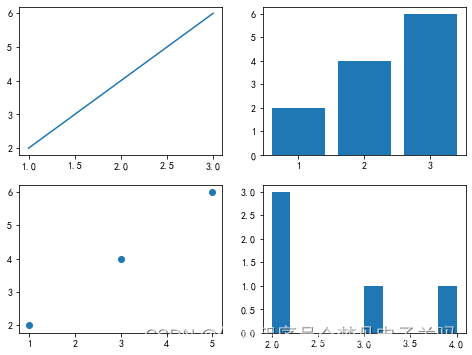
如下图所示,有时我们需要在一张画布上输出多个图形,在Matplotlib库中有当前的图形(figure)以及当前轴(axes)概念,其对应的就是当前画布以及当前子图,在一张画布(figure)上可以绘制多个子图(axes)。绘制多图通常采用subplot()函数或subplots()函数,
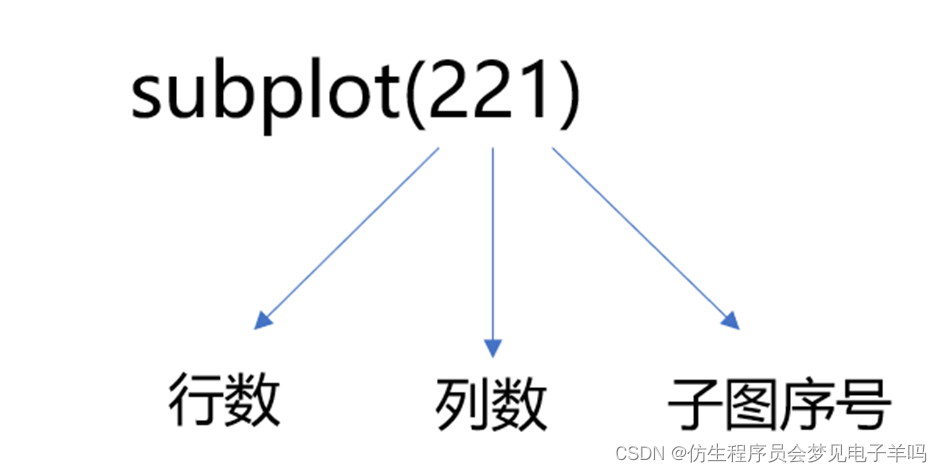
首先来讲解subplot()函数,如下图所示,它通常含有三个参数,子图的行数、列数以及第几个子图,例如subplot(221)表示的就是绘制2行2列的子图(共4个子图),并在第1个子图上进行绘图。
# 演示代码如下:
import matplotlib.pyplot as plt
# 绘制第一个子图:折线图
ax1 = plt.subplot(221)
plt.plot([1, 2, 3], [2, 4, 6]) # 这里plt其实也可以换成ax1# 绘制第二个子图:柱状图
ax2 = plt.subplot(222)
plt.bar([1, 2, 3], [2, 4, 6])# 绘制第三个子图:散点图
ax3 = plt.subplot(223)
plt.scatter([1, 3, 5], [2, 4, 6])# 绘制第四个子图:直方图
ax4 = plt.subplot(224)
plt.hist([2, 2, 2, 3, 4])
(array([3., 0., 0., 0., 0., 1., 0., 0., 0., 1.]),array([2. , 2.2, 2.4, 2.6, 2.8, 3. , 3.2, 3.4, 3.6, 3.8, 4. ]),<a list of 10 Patch objects>)
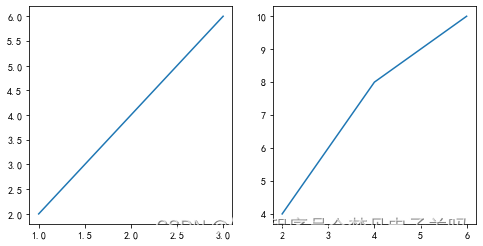
为了加强大家对画布(figure)和子图(axes)的理解,我们通过下面的代码来做一个简单演示:
plt.rcParams['figure.figsize'] = (8, 4) # 设置画布大小plt.figure(1) # 第一张画布
ax1 = plt.subplot(121) # 第一张画布的第一个子图
plt.plot([1, 2, 3], [2, 4, 6]) # 这里的plt可以换成ax1ax2 = plt.subplot(122) # 第一张画布的第二个子图
plt.plot([2, 4, 6], [4, 8, 10])plt.figure(2) # 第二张画布
plt.plot([1, 2, 3], [4, 5, 6])
[<matplotlib.lines.Line2D at 0x1cb635bbf60>]
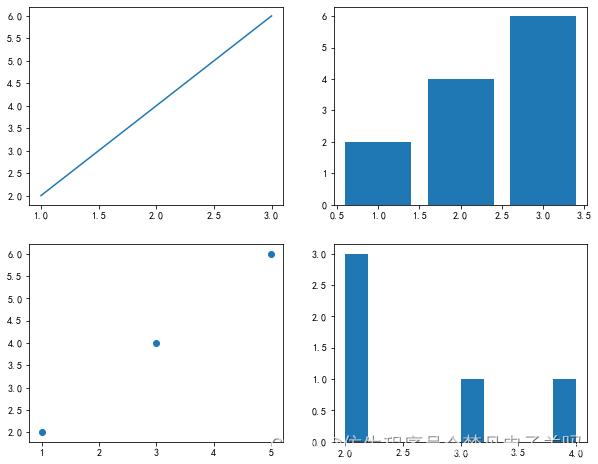
在使用subplot()函数的时候,每次在新的子图上画图时,都得调用subplot()函数,例如第四个子图就得写成ax4 = plt.subplot(224),那有没有什么办法,一次性就生成多个子图呢?这时候就可以用到subplots()函数,代码如下:
fig, axes = plt.subplots(2, 2, figsize=(10, 8))
ax1, ax2, ax3, ax4 = axes.flatten()
ax1.plot([1, 2, 3], [2, 4, 6]) # 绘制第一个子图
ax2.bar([1, 2, 3], [2, 4, 6]) # 绘制第二个子图
ax3.scatter([1, 3, 5], [2, 4, 6]) # 绘制第三个子图
ax4.hist([2, 2, 2, 3, 4]) # 绘制第四个子图
(array([3., 0., 0., 0., 0., 1., 0., 0., 0., 1.]),array([2. , 2.2, 2.4, 2.6, 2.8, 3. , 3.2, 3.4, 3.6, 3.8, 4. ]),<a list of 10 Patch objects>)
此外,如果要在subplot()函数或者subplots()函数生成的子图中设置子图标题、X轴标签或Y轴标签,得通过set_title()函数、set_xlabel()函数、set_ylabel()函数进行设置,演示代码如下:
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
fig, axes = plt.subplots(2, 2, figsize=(10, 8))
ax1, ax2, ax3, ax4 = axes.flatten()
ax1.plot([1, 2, 3], [2, 4, 6]) # 绘制第一个子图
ax1.set_title('子图1')
ax1.set_xlabel('日期')
ax1.set_ylabel('分数')
ax2.bar([1, 2, 3], [2, 4, 6]) # 绘制第二个子图
ax3.scatter([1, 3, 5], [2, 4, 6]) # 绘制第三个子图
ax4.hist([2, 2, 2, 3, 4]) # 绘制第四个子图
(array([3., 0., 0., 0., 0., 1., 0., 0., 0., 1.]),array([2. , 2.2, 2.4, 2.6, 2.8, 3. , 3.2, 3.4, 3.6, 3.8, 4. ]),<a list of 10 Patch objects>)
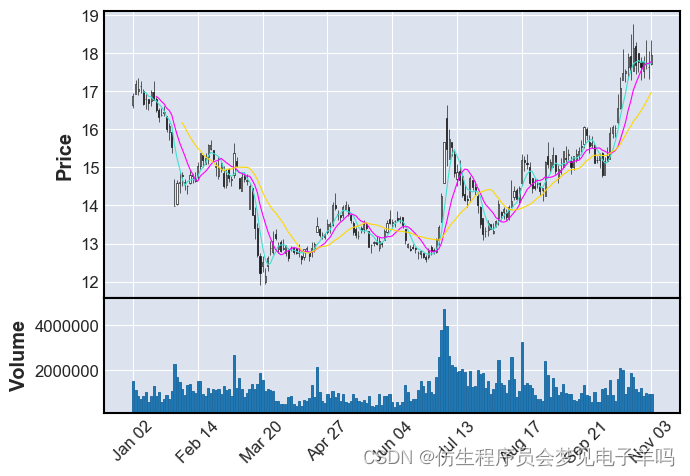
综合案例实战 : 股票数据读取与K线图绘制
%matplotlib inline
import tushare as ts
import mplfinance as mpf
from pylab import mpl
import pandas as pdpro = ts.pro_api('9d674d000f7c730dd3108701a1a1c534bf51bfb03a0ff169a9d11848') #
#https://tushare.pro/user/token
df = pro.daily(ts_code='000001.SZ', start_date='20200101', end_date='20201103')#df.sort_values(by='trade_date',ascending=False)
#取所有行数据,后面取date列,open列等数据
data = df.loc[:, ['trade_date', 'open', 'close', 'high', 'low', 'vol']]
data = data.rename(columns={'trade_date': 'Date', 'open': 'Open', 'close': 'Close', 'high': 'High', 'low': 'Low', 'vol': 'Volume'}) #更换列名,为后面函数变量做准备
#设置date列为索引,覆盖原来索引,这个时候索引还是 object 类型,就是字符串类型。
data.set_index('Date', inplace=True)
#将object类型转化成 DateIndex 类型,pd.DatetimeIndex 是把某一列进行转换,同时把该列的数据设置为索引 index。
data.index = pd.DatetimeIndex(data.index)#将时间顺序升序,符合时间序列
data = data.sort_index(ascending=True)# pd.set_option()就是pycharm输出控制显示的设置,下面这几行代码其实没用上,暂时也留在这儿吧
pd.set_option('expand_frame_repr', False)#True就是可以换行显示。设置成False的时候不允许换行
pd.set_option('display.max_columns', None)# 显示所有列
#pd.set_option('display.max_rows', None)# 显示所有行
pd.set_option('colheader_justify', 'centre')# 显示居中mpl.rcParams['font.sans-serif'] = ['SimHei'] # 指定默认字体
mpl.rcParams["figure.figsize"] = [6.4, 4.8]
mpl.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题mpf.plot(data, type='candle', mav=(5, 10, 20), volume=True, show_nontrading=False)
下面有的代码新版本废弃了,注意新版本用法
初步尝试 - 股票数据读取与可视化
1. 股票数据读取:Tushare库的安装与使用
首先推荐通过PIP安装法来安装可以调用股价数据的Tushare库(Tushare库官方地址为:http://tushare.org/
以Windows系统为例,具体方法是:通过Win + R组合键调出运行框,输入cmd后回车,然后在弹出框中输入pip install tushare后按一下Enter回车键的方法来进行安装。如果在1.2.3节讲到的Jupyter Notebook编辑器中安装的话,只需要在代码框中输入如下代码然后运行该行代码框即可(注意是英文格式下的!):
!pip install tushare
# 我们只需要通过如下2行代码便可获取到股票基本数据:
import tushare as ts
df = ts.get_k_data('000002', start='2009-01-01', end='2019-01-01')
df.head()
本接口即将停止更新,请尽快使用Pro版接口:https://tushare.pro/document/2
| date | open | close | high | low | volume | code | |
|---|---|---|---|---|---|---|---|
| 0 | 2009-01-05 | 5.086 | 5.178 | 5.178 | 5.008 | 936048.88 | 000002 |
| 1 | 2009-01-06 | 5.163 | 5.333 | 5.372 | 5.109 | 1216831.18 | 000002 |
| 2 | 2009-01-07 | 5.356 | 5.302 | 5.457 | 5.302 | 834829.31 | 000002 |
| 3 | 2009-01-08 | 5.217 | 5.333 | 5.410 | 5.163 | 837661.70 | 000002 |
| 4 | 2009-01-09 | 5.333 | 5.325 | 5.418 | 5.263 | 626815.66 | 000002 |
# 此时如果想要将股票数据获取到Excel文件中,则可以使用2.2.2节相关知识点,代码如下:
df.to_excel('股价数据.xlsx', index=False)
2. 绘制股价走势图
已经有了股价数据后,我们可以通过可视化的方式将其展示出来,这里我们首先利用2.2.1节的补充知识点中的set_index()函数将日期设置为行索引,这样方便等会直接用pandas库进行绘图,代码如下:
df.set_index('date', inplace=True)
df.head()
| open | close | high | low | volume | code | |
|---|---|---|---|---|---|---|
| date | ||||||
| 2009-01-05 | 5.086 | 5.178 | 5.178 | 5.008 | 936048.88 | 000002 |
| 2009-01-06 | 5.163 | 5.333 | 5.372 | 5.109 | 1216831.18 | 000002 |
| 2009-01-07 | 5.356 | 5.302 | 5.457 | 5.302 | 834829.31 | 000002 |
| 2009-01-08 | 5.217 | 5.333 | 5.410 | 5.163 | 837661.70 | 000002 |
| 2009-01-09 | 5.333 | 5.325 | 5.418 | 5.263 | 626815.66 | 000002 |
通过2.3.1节补充知识点中pandas绘图的相关知识点来进行图形绘制,代码如下。因为在pandas库中plot()函数默认绘制的是折线图,所以直接写plot()即可,不需要传入kind参数。此外在金融领域,通常用收盘价作为当天价格来绘制股价走势图,因此这里选择的是close这一列。
df['close'].plot()
<matplotlib.axes._subplots.AxesSubplot at 0x1fd670f1550>
如果想给图片加一个标题,在pandas库中使用可以在plot()可以在里面传入一个title参数,代码如下,注意因为标题是中文内容,所以要写2.3.2节最后讲到的两行代码防止中文乱码。
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
df['close'].plot(title='万科股价走势图')
<matplotlib.axes._subplots.AxesSubplot at 0x1fd67546780>
补充知识点:直接使用Matplotlib库绘制图表
上面使用的是pandas库中的plot()函数,pandas库其实是集成了Matplotlib库的一些功能,如果有的读者想直接用Matplotlib库进行股价走势画图,可以采用如下代码:
# 通过Tushare库获取股价数据
import tushare as ts
df = ts.get_k_data('000002', start='2009-01-01', end='2019-01-01')# 要注意的细节:调整日期格式使得横坐标显示清晰
from datetime import datetime
df['date'] = df['date'].apply(lambda x:datetime.strptime(x,'%Y-%m-%d'))# 绘制折线图
import matplotlib.pyplot as plt
plt.plot(df['date'], df['close'])
plt.show()
本接口即将停止更新,请尽快使用Pro版接口:https://tushare.pro/document/2C:\Users\LYJZB\Anaconda3\lib\site-packages\matplotlib\cbook\__init__.py:1402: FutureWarning: Support for multi-dimensional indexing (e.g. `obj[:, None]`) is deprecated and will be removed in a future version. Convert to a numpy array before indexing instead.x[:, None]
C:\Users\LYJZB\Anaconda3\lib\site-packages\matplotlib\cbook\__init__.py:1402: FutureWarning: Support for multi-dimensional indexing (e.g. `obj[:, None]`) is deprecated and will be removed in a future version. Convert to a numpy array before indexing instead.x[:, None]
C:\Users\LYJZB\Anaconda3\lib\site-packages\matplotlib\axes\_base.py:276: FutureWarning: Support for multi-dimensional indexing (e.g. `obj[:, None]`) is deprecated and will be removed in a future version. Convert to a numpy array before indexing instead.x = x[:, np.newaxis]
C:\Users\LYJZB\Anaconda3\lib\site-packages\matplotlib\axes\_base.py:278: FutureWarning: Support for multi-dimensional indexing (e.g. `obj[:, None]`) is deprecated and will be removed in a future version. Convert to a numpy array before indexing instead.y = y[:, np.newaxis]
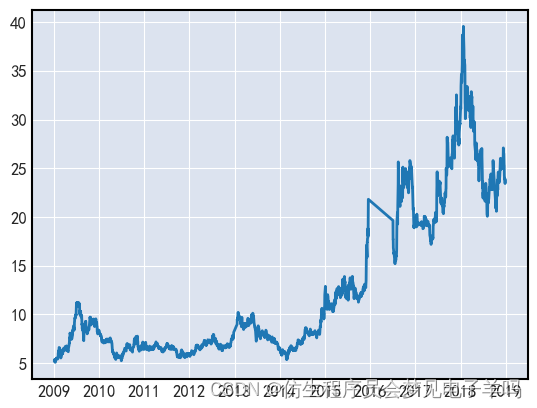
进阶实战: 股票K线图绘制
1. 股票K线图基础知识
一个实际中的股票K线图如下图所示(这个是“贵州茅台”股票的日线级别的K线图):
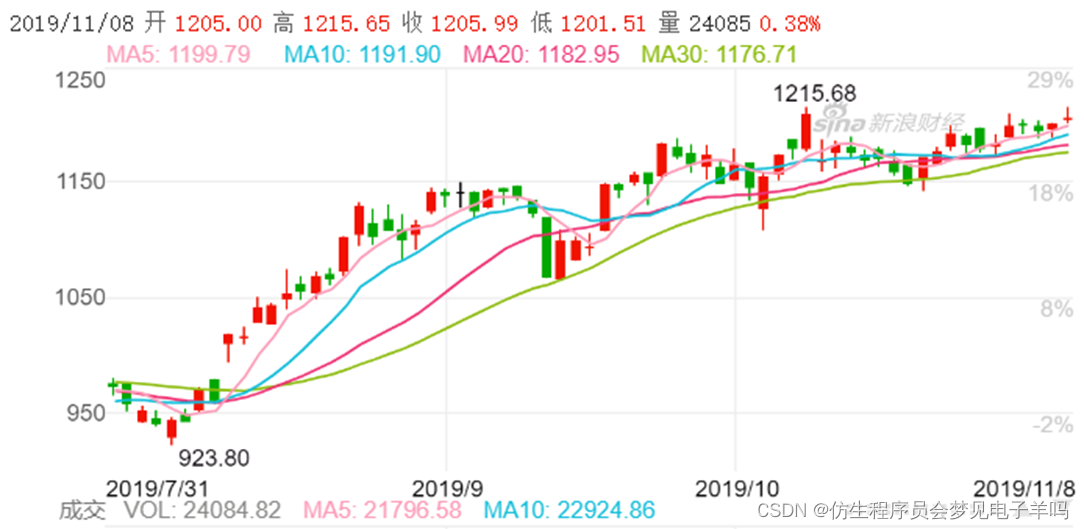
没有接触过股票的读者可能会被里面的各个柱状图和折线图搞得一头雾水,而这些图形其实都是通过一些很基础的数据绘制而成,这一节便主要来科普下股票K线图的基本知识。
这些柱状图,通常称之为“K线图”,是由股票的四个价格来绘制的:开盘价(当天上午9点半开始交易时的价格)、收盘价(当天下午3点结束交易时的价格)、最高价(当天股价波动中的最高价)、最低价(当天股价波动中的最低价),简称“高、开、低、收”四个价格。
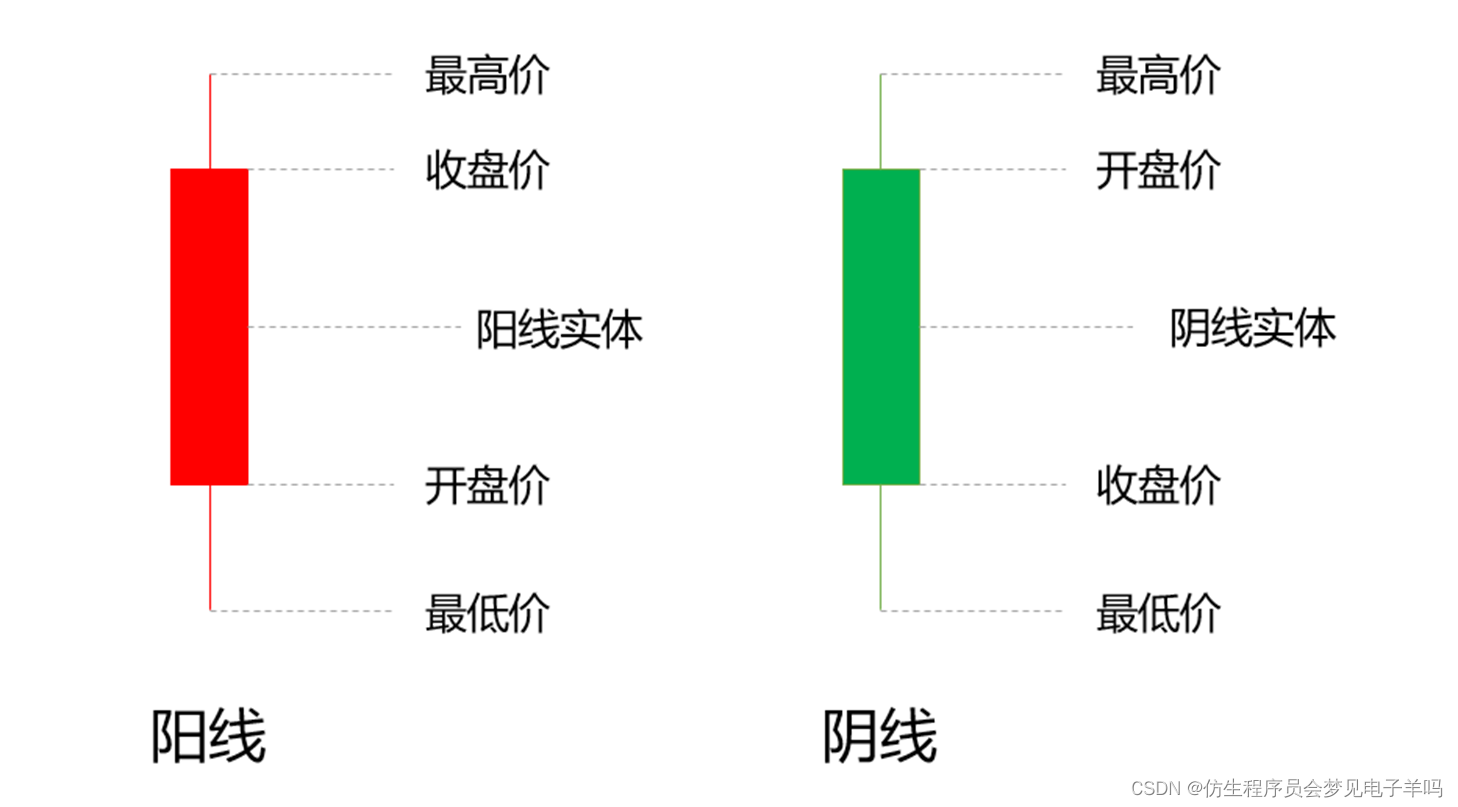
如下图所示,根据这四个价格便可以绘制出红色和绿色的K线图,因为形似蜡烛,因此也常被称之为蜡烛图。K线图分为两种,如果当天的收盘价高于开盘价,也就是说当天的价格上涨,则称之为阳线,通常绘制成红色;反之如果当天的收盘价低于开盘价,也就是说当天的价格下跌,则称之为阴线,通常绘制成绿色。补充说一句,在美国,反而是红色代表跌,绿色代表涨。
这里再解释下均线图,也就是那些折线图的绘制原理。均线分为5日均线(通常称之为MA5)、10日均线(通常称之为MA10)、20日均线(通常称之为MA20)等,其原理就是将股价的收盘价求均值,例如5日均线就是最近连续5个交易日收盘价之和的平均值,具体的计算公式如下,其中Close1为当天的收盘价,Close2为前一天的收盘价,其余依次类推。
MA5 = (Close1 + Close2 + Close3 + Close4 + Close5)/5
把每个5日均线的值连成一条平滑的曲线就是5日均线图了,同理10日均线图和20日均线图也是类似的原理,这些均线图也就是我们在这一小节最开始看到图中的那些折线图。
了解了股票K线图的基本知识后,下面我们就来进行K线图的绘制工作。
2.绘制股票K线图
(1) 安装绘制K线图的mplfinance库
首先需要安装绘制K线图的相关库:mpl_finance库,其安装办法稍微麻烦一点,推荐通过PIP安装法安装,以Windows系统为例,具体方法是:通过Win + R组合键调出运行框,输入cmd后回车,然后在弹出框中输入如下内容,按一下Enter回车键进行安装:
pip install mplfinance
如果是在在1.2.3节讲到的Jupyter Notebook中安装,则在pip前面加一个英文的感叹号“!”然后运行该代码块即可。
# 通过如下代码,可以在Jupyter Notebook中安装。(需取消注释)
# !pip install https://github.com/matplotlib/mpl_finance/archive/master.zip
(2) 引入绘图相关库
# 首先引入一些绘图需要用到的库,代码如下:
import tushare as ts
import matplotlib.pyplot as plt
import mplfinance as mpf
import seaborn as sns
sns.set()
第一个引入2.4.1节讲到的Tushare库,第二引入2.3.1节讲到的Matplotlib库在;第三个引入刚刚安装的mpl_finance库;第四个seaborn库是一个图表美化库,通过sns.set()即可激活,如果是通过1.2.1节Anaconda安装的Python,那么就自带该库了,无需额外安装。上面的代码直接拿去运行即可。
(3) 通过Tushare库获取股票基本数据
# 通过Tushare库获取股票代码为“000002”的股票“万科A”在2019-06-01至2019-09-30的股价数据,代码如下:
df = ts.get_k_data('000002','2019-06-01', '2019-09-30')
df.head()
本接口即将停止更新,请尽快使用Pro版接口:https://tushare.pro/document/2
| date | open | close | high | low | volume | code | |
|---|---|---|---|---|---|---|---|
| 99 | 2019-06-03 | 26.81 | 26.44 | 27.02 | 26.28 | 317567.0 | 000002 |
| 100 | 2019-06-04 | 26.47 | 26.30 | 26.54 | 26.25 | 203260.0 | 000002 |
| 101 | 2019-06-05 | 26.64 | 27.03 | 27.28 | 26.63 | 576164.0 | 000002 |
| 102 | 2019-06-06 | 27.01 | 27.12 | 27.29 | 26.92 | 333792.0 | 000002 |
| 103 | 2019-06-10 | 27.29 | 27.81 | 28.05 | 27.17 | 527547.0 | 000002 |
(4) 日期格式调整及表格转换
因为绘制K线图的candlestick_ochl()函数只能接收特定格式的日期格式,以及数组格式的内容,所以我们需要将原来文本类型的日期格式调整一下,代码如下:
# 导入日期格式调整涉及的两个库
from matplotlib.pylab import date2num
import datetime# 对tushare获取到的日期数据转换成candlestick_ohlc()函数可读取的数字格式
def date_to_num(dates):num_time = []for date in dates:date_time = datetime.datetime.strptime(date,'%Y-%m-%d')num_date = date2num(date_time)num_time.append(num_date)return num_time# 将DataFrame转换为二维数组,并利用date_to_num()函数转换日期
df_arr = df.values # 将DataFrame格式的数据,转换为array二维数组
df_arr[:,0] = date_to_num(df_arr[:,0]) # 将原来日期格式的日期换成数字格式df_arr[0:5] # 查看此时的df_arr的前5项
array([[737213.0, 26.81, 26.44, 27.02, 26.28, 317567.0, '000002'],[737214.0, 26.47, 26.3, 26.54, 26.25, 203260.0, '000002'],[737215.0, 26.64, 27.03, 27.28, 26.63, 576164.0, '000002'],[737216.0, 27.01, 27.12, 27.29, 26.92, 333792.0, '000002'],[737220.0, 27.29, 27.81, 28.05, 27.17, 527547.0, '000002']],dtype=object)
(5) 绘制K线图
转换好数据格式后,K线图的绘制就比较简单了,通过candlestick_ochl()函数便能够轻松的绘制K线图了,代码如下:
kdata = df.rename(columns={'date':'Date','open':'Open','close':'Close','high':'High','low':'Low','volume':'Volume','code':'Code'})
kdata = kdata.set_index('Date')
kdata.index = pd.DatetimeIndex(kdata.index)
#新版本废弃
#fig, ax = plt.subplots(figsize=(15,6))
#mpf.candlestick_ochl(ax, df_arr, width=0.6, colorup='r', colordown='g', alpha=1.0)
#plt.grid(True) # 绘制网格
#ax.xaxis_date() # 设置x轴的刻度为日期
candlestick_ochl()函数的参数:
ax:绘图Axes的实例,也就是画布中的子图;df_arr:股价历史数据;width:图像中红绿矩形的宽度;colorup:收盘价格大于开盘价格时矩形的颜色;colordown:收盘价格低于开盘价格时矩形的颜色;alpha:矩形的颜色的透明度;
mpf.plot(kdata, type='candle', show_nontrading=False)
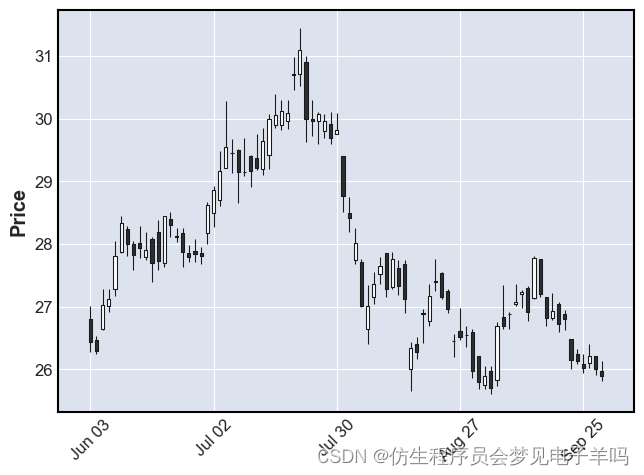
(6) 绘制K线图及均线图
有了K线图之后,我们再来补上均线图,这里我们主要补上5日均线和10日均线图,首先我们通过如下代码构造5日均线和10日均线数据:
df['MA5'] = df['close'].rolling(5).mean()
df['MA10'] = df['close'].rolling(10).mean()df.head(15) # 查看此时的前15行
| date | open | close | high | low | volume | code | MA5 | MA10 | |
|---|---|---|---|---|---|---|---|---|---|
| 99 | 2019-06-03 | 26.81 | 26.44 | 27.02 | 26.28 | 317567.0 | 000002 | NaN | NaN |
| 100 | 2019-06-04 | 26.47 | 26.30 | 26.54 | 26.25 | 203260.0 | 000002 | NaN | NaN |
| 101 | 2019-06-05 | 26.64 | 27.03 | 27.28 | 26.63 | 576164.0 | 000002 | NaN | NaN |
| 102 | 2019-06-06 | 27.01 | 27.12 | 27.29 | 26.92 | 333792.0 | 000002 | NaN | NaN |
| 103 | 2019-06-10 | 27.29 | 27.81 | 28.05 | 27.17 | 527547.0 | 000002 | 26.940 | NaN |
| 104 | 2019-06-11 | 27.87 | 28.33 | 28.45 | 27.85 | 449630.0 | 000002 | 27.318 | NaN |
| 105 | 2019-06-12 | 28.24 | 28.00 | 28.29 | 27.81 | 269372.0 | 000002 | 27.658 | NaN |
| 106 | 2019-06-13 | 28.00 | 27.83 | 28.05 | 27.58 | 250431.0 | 000002 | 27.818 | NaN |
| 107 | 2019-06-14 | 28.01 | 27.93 | 28.29 | 27.78 | 311417.0 | 000002 | 27.980 | NaN |
| 108 | 2019-06-17 | 27.80 | 27.91 | 28.20 | 27.75 | 171672.0 | 000002 | 28.000 | 27.470 |
| 109 | 2019-06-18 | 28.08 | 27.70 | 28.11 | 27.40 | 219162.0 | 000002 | 27.874 | 27.596 |
| 110 | 2019-06-19 | 28.20 | 27.73 | 28.38 | 27.59 | 390157.0 | 000002 | 27.820 | 27.739 |
| 111 | 2019-06-20 | 27.70 | 28.45 | 28.45 | 27.63 | 577484.0 | 000002 | 27.944 | 27.881 |
| 112 | 2019-06-21 | 28.40 | 28.31 | 28.52 | 28.12 | 492537.0 | 000002 | 28.020 | 28.000 |
| 113 | 2019-06-24 | 28.12 | 28.13 | 28.25 | 28.03 | 270128.0 | 000002 | 28.064 | 28.032 |
data = data.sort_index(ascending=True)
plt.rcParams['font.sans-serif'] = ['SimHei'] my_color = mpf.make_marketcolors(up='red', down='green', edge='i', wick='i', volume='in')
# 解决mplfinance绘制输出中文乱码
my_style = mpf.make_mpf_style(base_mpf_style='yahoo',marketcolors=my_color, gridaxis='both', gridstyle='-.', y_on_right=True,rc={'font.family': 'SimHei'})
mpf.plot(kdata, type='candle',style = my_style,title='万科A',ylabel='价格',xrotation=0,datetime_format='%Y-%m-%d',mav=(5, 10), show_nontrading=False,figratio=(15, 6),figscale=1)
# 绘制5日均线,10日均线
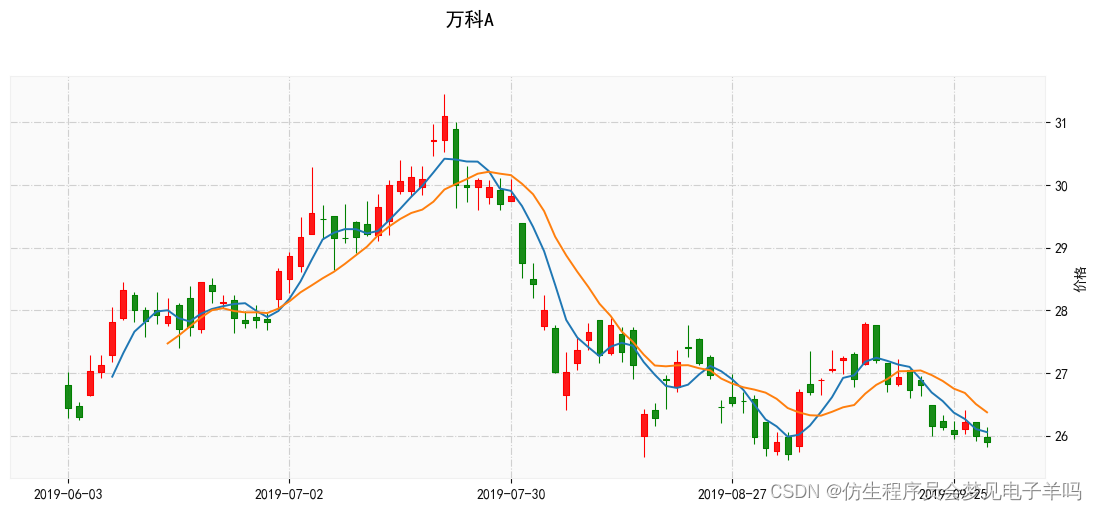
# 有了5日均线和10日均线数据后,就可以将其绘制在图形中了,代码如下:
#plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签#fig, ax = plt.subplots(figsize=(15,6))#mpf.candlestick_ochl(ax, df_arr, width=0.6, colorup='r', colordown='g', alpha=1.0)
#plt.plot(df_arr[:,0], df['MA5']) # 绘制5日均线
#plt.plot(df_arr[:,0], df['MA10']) # 绘制10日均线#plt.grid(True) # 绘制网格#plt.title('万科A') # 设置标题
#plt.xlabel('日期') # 设置X轴图例
#plt.ylabel('价格') # 设置Y轴图例#ax.xaxis_date () # 设置x轴的刻度为日期
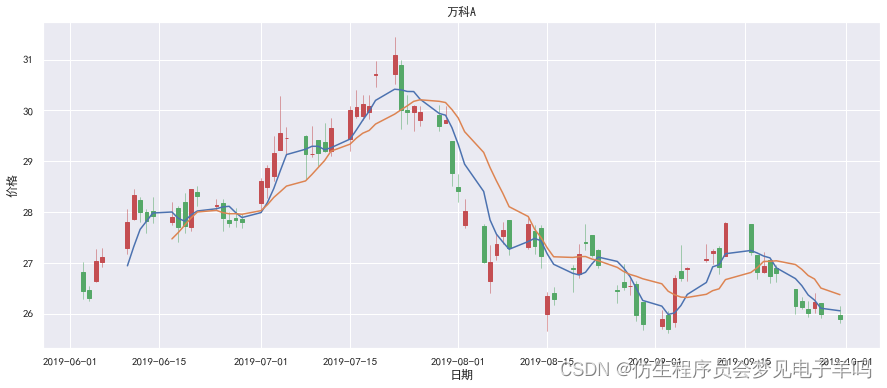
(7) 绘制股票K线图、均线图、成交量柱状图
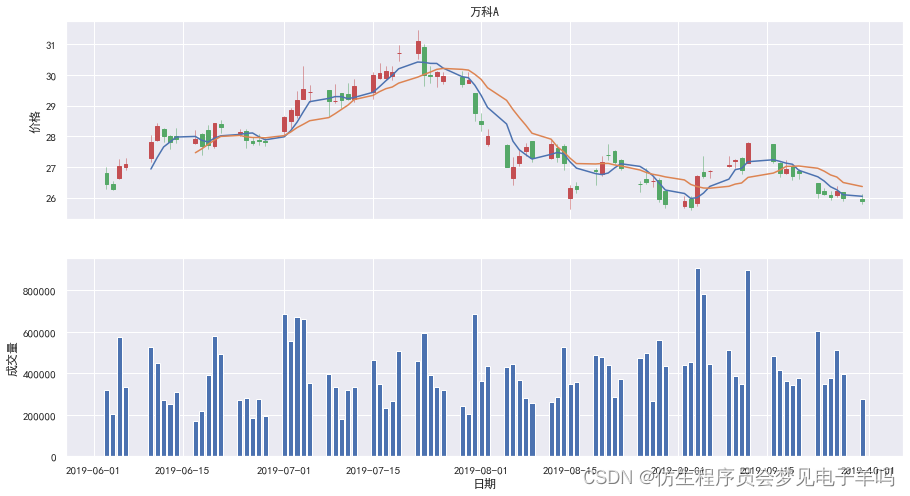
在现实中,和股票K线图、均线图一同出现的还有每日成交量的的柱状图,我们利用2.3.2节绘制多图的知识点,即可通过如下代码在一张画布中绘制两个子图,包含K线图、均线图、成交量柱状图:
#fig, axes = plt.subplots(2, 1, sharex=True, figsize=(15,8))
#ax1, ax2 = axes.flatten()# 绘制第一张子图:K线图和均线图
#mpf.candlestick_ochl(ax1, df_arr, width=0.6, colorup = 'r', colordown = 'g', alpha=1.0)#ax1.plot(df_arr[:,0], df['MA5']) # 绘制5日均线
#ax1.plot(df_arr[:,0], df['MA10']) # 绘制10日均线#ax1.set_title('万科A') # 设置子图标题
#ax1.set_ylabel('价格') # 设置子图Y轴标签
#ax1.grid(True)
#ax1.xaxis_date()# 绘制第二张子图:成交量图
#ax2.bar(df_arr[:,0], df_arr[:,5]) # 绘制成交量柱状图
#ax2.set_xlabel('日期') # 设置子图X轴标签
#ax2.set_ylabel('成交量') # 设置子图Y轴标签
#ax2.grid(True)
#ax2.xaxis_date()
plt.rcParams['font.sans-serif'] = ['SimHei'] my_color = mpf.make_marketcolors(up='red', down='green', edge='i', wick='i', volume='in')
# 解决mplfinance绘制输出中文乱码
my_style = mpf.make_mpf_style(base_mpf_style='yahoo',marketcolors=my_color, gridaxis='both', gridstyle='-.', y_on_right=True,rc={'font.family': 'SimHei'})
mpf.plot(kdata, type='candle',style = my_style,title='万科A',ylabel='价格',xrotation=0,datetime_format='%Y-%m-%d',mav=(5, 10), volume=True,show_nontrading=False,figratio=(15, 6),figscale=1)
# 绘制5日均线,10日均线
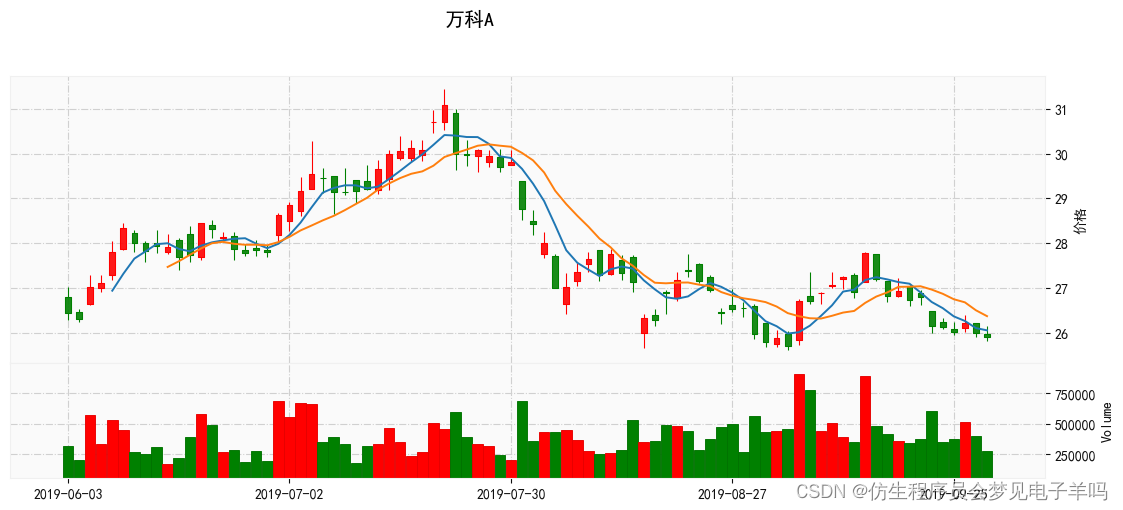
其中第1-2行代码利用2.3.2节绘制多图相关知识点先构造一个画布和两个子图,这里同时设置sharex参数为True,这样两张子图就可以共用一个坐标轴了;第4-13行绘制第一张子图,其中在子图中设置标题或者坐标轴标题得使用set_title()、set_ylabel()、set_xlabel()这样的函数;第15-20行绘制第二张子图:成交量图,其中df_arr[:,0]表示二维数组的第1列,也即日期那列,df_arr[:,5]表示二维数组的第6列,也即成交量那列数据,然后通过2.3.1节讲过的bar()函数绘制成柱状图。
我们可以和新浪财经网上的实际图像对比一下,如下图所示,发现通过Python绘制的K线图相关图片和网上的图片基本一致。
至此,数据分析的相关3大武器库已经给大家讲解完毕了,其实关于这三个库还有很多可以挖掘的知识点,由于篇幅有限,这里就不再赘述。这一章内容相对较多,读者朋友可以将这一章当作一个工具章,有需要的时候再返回看看需要用到的知识点。
相关文章:
【数据挖掘与商务智能决策】第一章 数据分析与三重工具
numpy基础 numpy与数组 import numpy as np # 用np代替numpy,让代码更简洁 a [1, 2, 3, 4] # 创建列表a b np.array([1, 2, 3, 4]) #从列表ach print(a) print(b) print(type(a)) #打印a类型 print(type(b)) #打印b类型[1, 2, 3, 4] [1 2 3 4] <class ‘list’>…...
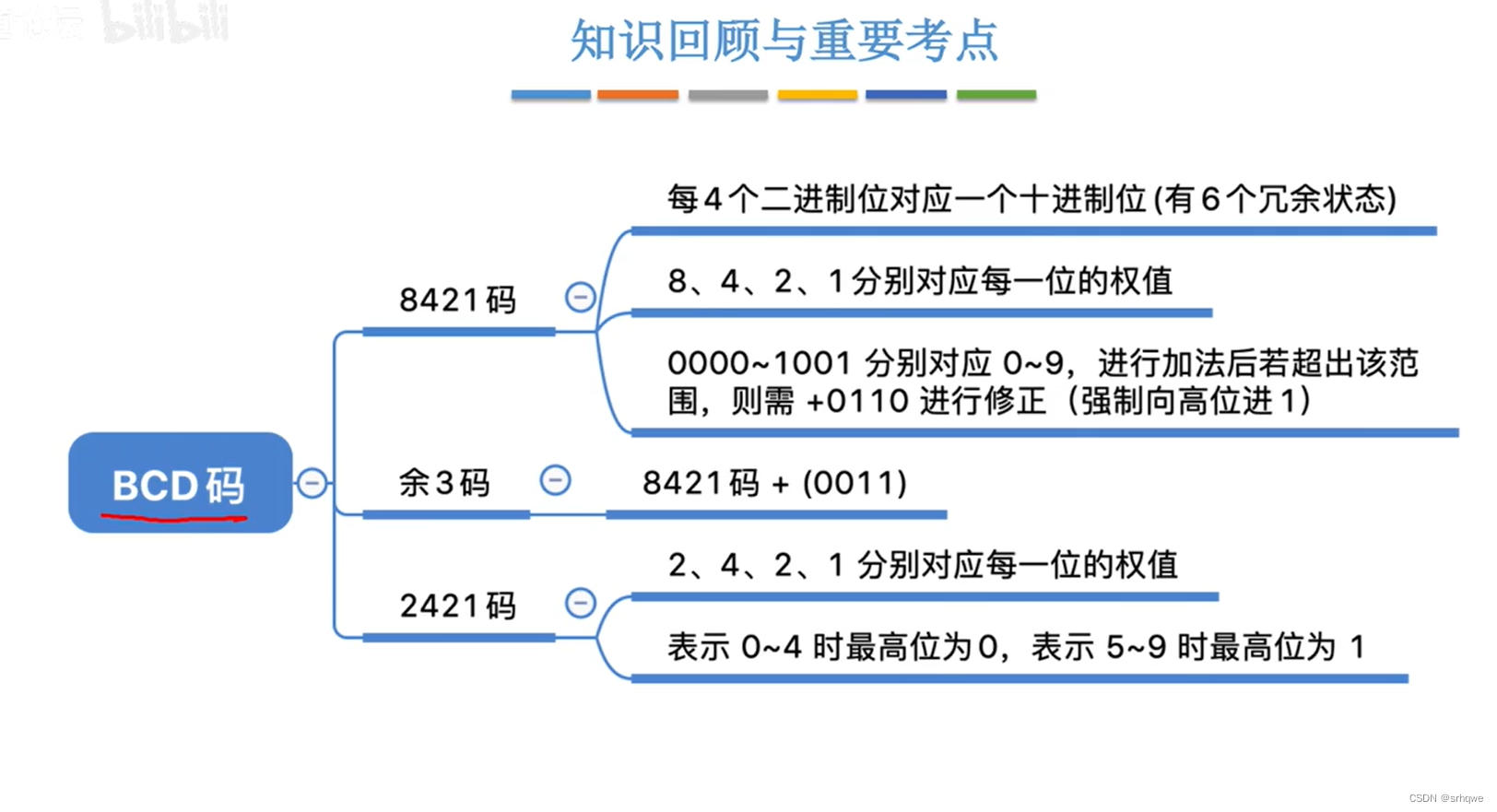
计算机底层:BDC码
计算机底层:BDC码 BDC码的作用: 人类喜欢十进制,而机器适合二进制,因此当机器要翻译二进制给人看时,就会进行二进制和十进制的转换,而常规的转换法(k*位权)太麻烦。因此就出现了不同…...
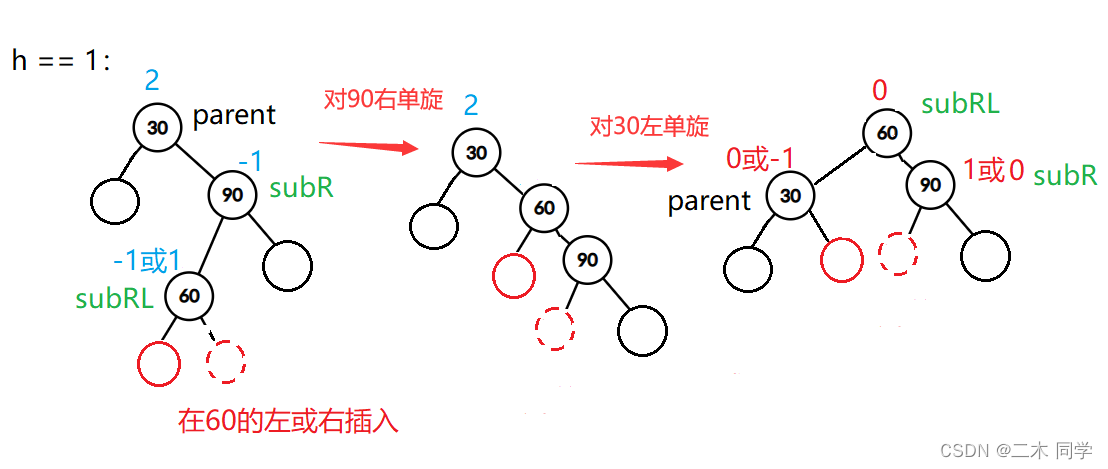
【C++】平衡二叉搜索(AVL)树的模拟实现
一、 AVL树的概念 map、multimap、set、multiset 在其文档介绍中可以发现,这几个容器有个共同点是:其底层都是按照二叉搜索树来实现的,但是二叉搜索树有其自身的缺陷,假如往树中插入的元素有序或者接近有序,二叉搜索树…...
[2019红帽杯]childRE
题目下载:下载 参考:re学习笔记(24)BUUCTF-re-[2019红帽杯]childRE_Forgo7ten的博客-CSDN博客 这道题涉及到c函数的修饰规则,按照规则来看应该是比较容易理解的。上面博客中有总结规则,可以学习一下。 载…...
(附源码))
2D图像处理:九点标定_下(机械手轴线与法兰轴线不重合)(附源码)
文章目录 2. 机械手轴线与法兰轴线不重合2.1 两次拍照避免标定旋转中心2.2 旋转中心标定2.3 非标定中心的方法2.3.1 预备内容-点坐标旋转计算2.3.2 工件存在平移和旋转3. 代码(待更新)上一篇:2D图像处理:九点标定_上(机械手轴线与法兰轴线重合)(附源码) 2. 机械手轴线…...

【二分查找】分巧克力、机器人跳跃、数的范围
Halo,这里是Ppeua。平时主要更新C语言,C,数据结构算法......感兴趣就关注我吧!你定不会失望。 🌈个人主页:主页链接 🌈算法专栏:专栏链接 我会一直往里填充内容哒! &…...

Hyperf使用RabbitMQ消息队列
Hyperf连接使用RabbitMQ消息中间件 传送门 使用Docker部署RabbitMQ,->传送门<使用Docker部署Hyperf,->传送门-< 部署环境 安装amqp扩展 composer require hyperf/amqp安装command命令行扩展 composer require hyperf/command配置参数 假…...
【Linux】P3 用户与用户组
用户与用户组root 超级管理员设置超级管理员密码切换到超级管理员sudo 临时使用超级权限用户与用户组用户组管理用户管理getentroot 超级管理员 设置超级管理员密码 登陆后不会自动开启 root 访问权限,需要首先执行如下步骤设定 root 超级管理员密码 1、解除 roo…...

Spring核心模块——Aware接口
Aware接口前言基本内容例子结尾前言 Spring的依赖注入最大亮点是所有的Bean对Spring容器对存在都是没有意识到,Spring容器中的Bean的耦合度是很低的,我们可以将Spring容器很容易换成其他的容器。 但是实际开发的时候,我们经常要用到Spring容…...

Linux网络编程 第六天
目录 学习目标 libevent介绍 libevent的安装 libevent库的使用 libevent的使用 libevent的地基-event_base 等待事件产生-循环等待event_loop 使用libevent库的步骤: 事件驱动-event 编写一个基于event实现的tcp服务器: 自带buffer的事件-buff…...
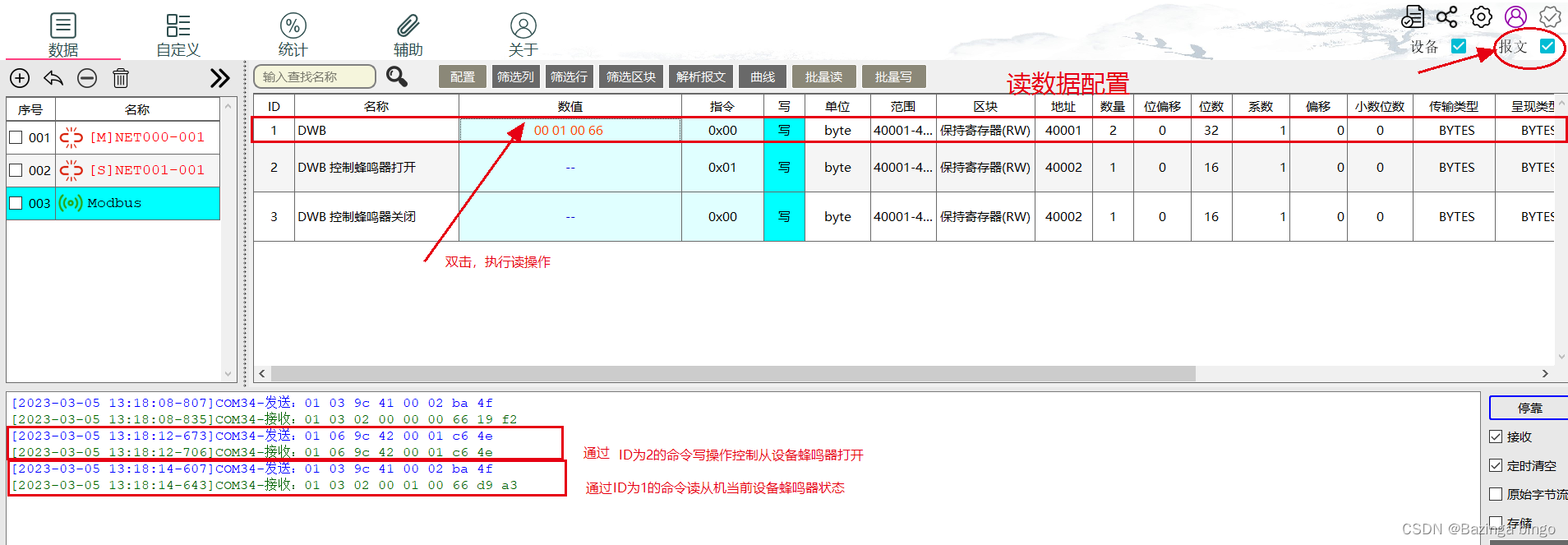
STM32开发(六)STM32F103 通信 —— RS485 Modbus通信编程详解
文章目录一、基础知识点二、开发环境三、STM32CubeMX相关配置1、STM32CubeMX基本配置2、STM32CubeMX RS485 相关配置四、Vscode代码讲解五、结果演示以及报文解析一、基础知识点 了解 RS485 Modbus协议技术 。本实验是基于STM32F103开发 实现 通过RS-485实现modbus协议。 准备…...

AcWing1049.大盗阿福题解
前言如果想看状态机的详解,点机这里:dp模型——状态机模型C详解1049. 大盗阿福阿福是一名经验丰富的大盗。趁着月黑风高,阿福打算今晚洗劫一条街上的店铺。这条街上一共有 N家店铺,每家店中都有一些现金。阿福事先调查得知,只有当…...

python日志模块,loggin模块
python日志模块,loggin模块loggin模块日志的格式处理器种类日志格式的参数使用loggin模块 logging库采用模块化方法,并提供了几类组件:记录器,处理程序,过滤器和格式化程序。 记录器(Logger)&a…...
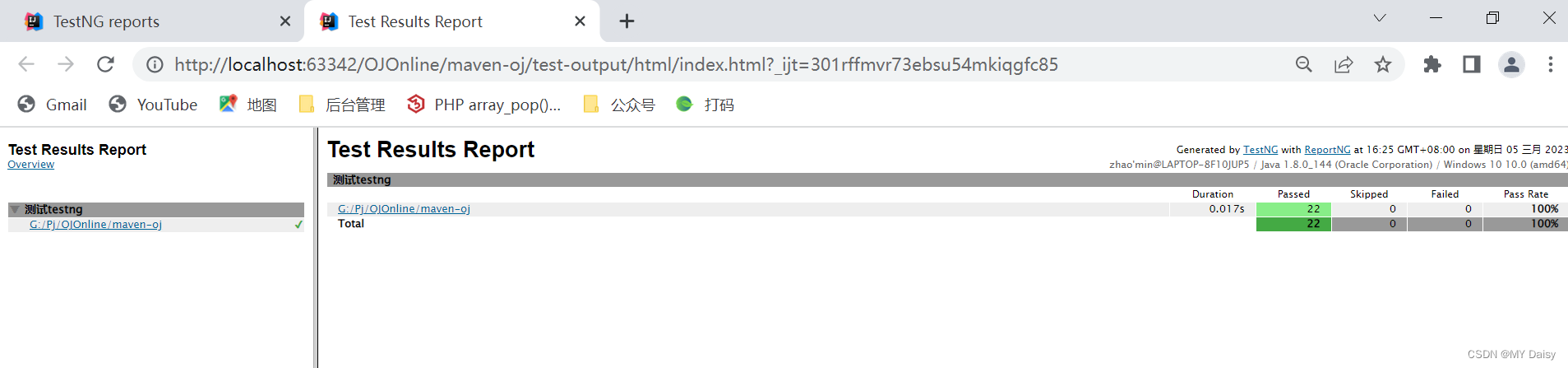
接口自动化入门-TestNg
目录1.TestNg介绍2、TestNG安装3、TestNG使用3.1 编写测试用例脚本3.2 创建TestNG.xml文件(1)创建testng.xml文件(2)修改testng.xml4、测试报告生成1.TestNg介绍 TestNg是Java中开源的自动化测试框架,灵感来源于Junit…...

Spring AOP —— 详解、实现原理、简单demo
目录 一、Spring AOP 是什么? 二、学习AOP 有什么作用? 三、AOP 的组成 3.1、切面(Aspect) 3.2、切点(Pointcut) 3.3、通知(Advice) 3.4、连接点 四、实现 Spring AOP 一个简…...

(蓝桥真题)异或数列(博弈)
题目链接:P8743 [蓝桥杯 2021 省 A] 异或数列 - 洛谷 | 计算机科学教育新生态 (luogu.com.cn) 样例输入: 4 1 1 1 0 2 2 1 7 992438 1006399 781139 985280 4729 872779 563580 样例输出: 1 0 1 1 分析:容易想到对于异或最大值…...

4万字数字政府建设总体规划方案WORD
本资料来源公开网络,仅供个人学习,请勿商用。部分资料内容: 我省“数字政府”架构 (一) 总体架构。 “数字政府”总体架构包括管理架构、业务架构、技术架构。其中,管理架构体现“管运分离”的建设运营模式…...

CCF/CSP 201709-2公共钥匙盒100分
试题编号:201709-2试题名称:公共钥匙盒时间限制:1.0s内存限制:256.0MB问题描述:问题描述 有一个学校的老师共用N个教室,按照规定,所有的钥匙都必须放在公共钥匙盒里,老师不能带钥…...

【OC】Blocks模式
1. Block语法 Block语法完整形式如下: ^void (int event) {printf("buttonId:%d event%d\n", i, event); }完整形式的Block语法与一般的C语言函数定义相比,仅有两点不同。 没有函数名。带有“^”(插入记号)。 因为O…...
软件设计师教程(七)计算机系统知识-操作系统知识
软件设计师教程 软件设计师教程(一)计算机系统知识-计算机系统基础知识 软件设计师教程(二)计算机系统知识-计算机体系结构 软件设计师教程(三)计算机系统知识-计算机体系结构 软件设计师教程(…...

告别繁琐文字提取:Text-Grab本地化OCR工具效率提升指南
告别繁琐文字提取:Text-Grab本地化OCR工具效率提升指南 【免费下载链接】Text-Grab Use OCR in Windows quickly and easily with Text Grab. With optional background process and notifications. 项目地址: https://gitcode.com/gh_mirrors/te/Text-Grab …...

5大场景落地指南:企业级语音识别服务从部署到优化全攻略
5大场景落地指南:企业级语音识别服务从部署到优化全攻略 【免费下载链接】whisper-asr-webservice OpenAI Whisper ASR Webservice API 项目地址: https://gitcode.com/gh_mirrors/wh/whisper-asr-webservice 【项目核心价值定位】解决3大语音识别痛点的开源…...

解锁音频频域密码:Spek声学频谱分析工具的全场景应用指南
解锁音频频域密码:Spek声学频谱分析工具的全场景应用指南 【免费下载链接】spek Acoustic spectrum analyser 项目地址: https://gitcode.com/gh_mirrors/sp/spek 在数字音频处理领域,准确理解信号的频率特性是解决音质问题、优化音频体验的关键。…...

02-从零开始编写操作系统 - BIOS 中断与屏幕显示
引导打印 - BIOS 中断与屏幕显示 从零开始编写操作系统 - 第二章 开始之前你可能需要 Google 了解的概念 interrupt, BIOS, ISR, IVT, int 0x10, cpu-registers 目的 使用 BIOS 中断在屏幕上打印字符和字符串 🌟 支持一下 如果这个教程对你有帮助,欢…...

AIVideo在软件测试领域的应用:自动化生成测试案例视频
AIVideo在软件测试领域的应用:自动化生成测试案例视频 1. 引言:测试视频制作的痛点与机遇 作为一名测试工程师,你是否曾经遇到过这样的困境:每次编写完测试用例后,还需要花费大量时间录制演示视频,展示测…...

从新手小白到资深开发者:GISBox与QGIS如何适配你的成长路径?
随着地理信息技术的加速演进,工具选型已成为提升空间数据处理效率的关键环节。本文立足于产品定位、功能体系与目标用户三大核心维度,系统梳理GISBox与QGIS的差异化特征,旨在为教育、科研、企业及个人开发者提供清晰、务实的工具决策依据。 …...

Python 闭包与装饰器
在 Python 学习中,闭包和装饰器是两个既关联又容易混淆的知识点,尤其是结合嵌套函数使用时,常常分不清执行逻辑。但其实只要抓住核心原理,再结合简单案例拆解,就能轻松掌握。 一、前置回顾:函数与局部变量的…...

深入解析Supabase与Flutter的用户认证问题
深入解析Supabase与Flutter的用户认证问题 当我们使用Flutter开发移动应用时,用户认证是一个不可或缺的部分。而Supabase作为一个开源的数据库和后端服务,提供了强大的功能来帮助我们实现这个需求。然而,在集成过程中,我们可能会遇到一些问题。本文将详细探讨如何解决在Su…...

MeteorSeed
从0构建WAV文件:读懂计算机文件的本质 虽然接触计算机有一段时间了,但是我的视野一直局限于一个较小的范围之内,往往只能看到于算法竞赛相关的内容,计算机各种文件在我看来十分复杂,认为构建他们并能达到目的是一件困难…...

跨平台办公自动化:OpenClaw+千问3.5-27B同步多端文件
跨平台办公自动化:OpenClaw千问3.5-27B同步多端文件 1. 为什么需要跨平台文件同步? 作为一个常年需要在Windows和Mac双系统切换的开发者,我经历过无数次这样的尴尬时刻:在Mac上修改的文档忘传到Windows,开会时找不到…...