力扣601 体育馆的人流量
在解决"连续三天及以上人流量超过100的记录"问题时,MySQL方案作为力扣解决问题的方案通过窗口函数和分组技巧高效地识别连续记录。而Python与Pandas方案作为扩展则展示了在数据处理和分析方面的灵活性,通过行号变换和分组计数来筛选符合条件的数据行。
目录
题目描述
解题思路
完整代码
使用python- pandas扩展
题目描述
表:Stadium
+---------------+---------+ | Column Name | Type | +---------------+---------+ | id | int | | visit_date | date | | people | int | +---------------+---------+ visit_date 是该表中具有唯一值的列。 每日人流量信息被记录在这三列信息中:序号 (id)、日期 (visit_date)、 人流量 (people) 每天只有一行记录,日期随着 id 的增加而增加
编写解决方案找出每行的人数大于或等于 100 且 id 连续的三行或更多行记录。
返回按 visit_date 升序排列 的结果表。
查询结果格式如下所示。
示例 1:
输入:
Stadium 表:
+------+------------+-----------+
| id | visit_date | people |
+------+------------+-----------+
| 1 | 2017-01-01 | 10 |
| 2 | 2017-01-02 | 109 |
| 3 | 2017-01-03 | 150 |
| 4 | 2017-01-04 | 99 |
| 5 | 2017-01-05 | 145 |
| 6 | 2017-01-06 | 1455 |
| 7 | 2017-01-07 | 199 |
| 8 | 2017-01-09 | 188 |
+------+------------+-----------+
输出:
+------+------------+-----------+
| id | visit_date | people |
+------+------------+-----------+
| 5 | 2017-01-05 | 145 |
| 6 | 2017-01-06 | 1455 |
| 7 | 2017-01-07 | 199 |
| 8 | 2017-01-09 | 188 |
+------+------------+-----------+
解释:
id 为 5、6、7、8 的四行 id 连续,并且每行都有 >= 100 的人数记录。
请注意,即使第 7 行和第 8 行的 visit_date 不是连续的,输出也应当包含第 8 行,因为我们只需要考虑 id 连续的记录。
不输出 id 为 2 和 3 的行,因为至少需要三条 id 连续的记录。解题思路
- 标记符合条件的行:首先,我们需要找出
people大于等于100的行。 - 寻找连续的行:接着,我们需要找出这些行中
id连续的部分。这一步稍微复杂,因为我们需要检查每行的id是否与前一行的id相差1。 - 统计连续行的数量:为了确保连续行至少有三行,我们可以使用窗口函数(如
ROW_NUMBER())来为这些连续行分组,并计算每组中的行数。 - 筛选结果:最后,我们只保留那些组内行数大于等于3的行。
完整代码
WITH RankedStadium AS (SELECT id, visit_date, people,-- 为连续的行分配相同的组号id - ROW_NUMBER() OVER (ORDER BY id) AS grpFROM StadiumWHERE people >= 100
),
GroupedStadium AS (SELECTid,visit_date,people,grp,-- 计算每个组内的行数COUNT(*) OVER (PARTITION BY grp) AS cntFROMRankedStadium
)-- 选择那些组内行数大于等于3的记录
SELECT id, visit_date, people
FROM GroupedStadium
WHERE cnt >= 3
ORDER BY visit_date;
这段代码通过WITH语句先创建了一个临时的RankedStadium视图来找出人数大于等于100的行,并为连续的行分配相同的组号。然后在GroupedStadium视图中,它计算每个组内的行数。最后,它选择那些组内行数大于等于3的记录,并按visit_date排序。这样就能找到至少有三行连续id且people大于等于100的记录。
通过

使用python- pandas扩展
- 筛选符合条件的行:首先,我们需要筛选出
people字段大于等于100的行。 - 寻找连续的行:然后,我们需要找到
id连续的行。由于id是连续增加的,我们可以通过检查当前行的id是否比前一行的id大1来判断是否连续。 - 标记连续的组:为了识别连续的行,我们可以用
id减去行号来为每个连续的块创建一个唯一的标识符。 - 统计每组的行数:通过分组并统计每个组的行数,我们可以找出至少包含3行的组。
- 筛选结果:最后,我们筛选出那些组内行数大于等于3的行。
import pandas as pd# 假设stadium_df是包含Stadium表数据的DataFrame
stadium_df = pd.DataFrame({'id': [1, 2, 3, 4, 5, 6, 7, 8],'visit_date': ['2017-01-01', '2017-01-02', '2017-01-03', '2017-01-04', '2017-01-05', '2017-01-06', '2017-01-07', '2017-01-09'],'people': [10, 109, 150, 99, 145, 1455, 199, 188]
})# 筛选people大于等于100的行
filtered_df = stadium_df[stadium_df['people'] >= 100]# 通过id减去行号创建组标识符
filtered_df['group'] = filtered_df['id'] - filtered_df.reset_index().index# 计算每组的行数
group_counts = filtered_df.groupby('group').size()# 筛选出组内行数大于等于3的组
valid_groups = group_counts[group_counts >= 3].index# 最终结果
result_df = filtered_df[filtered_df['group'].isin(valid_groups)].drop('group', axis=1)print(result_df)
相关文章:
力扣601 体育馆的人流量
在解决"连续三天及以上人流量超过100的记录"问题时,MySQL方案作为力扣解决问题的方案通过窗口函数和分组技巧高效地识别连续记录。而Python与Pandas方案作为扩展则展示了在数据处理和分析方面的灵活性,通过行号变换和分组计数来筛选符合条件的…...

ubuntu20.04设置docker容器开机自启动
ubuntu20.04设置docker容器开机自启动 1 docker自动启动2 容器设置自动启动3 容器自启动失败处理 1 docker自动启动 (1)查看已启动的服务 $ sudo systemctl list-units --typeservice此命令会列出所有当前加载的服务单元。默认情况下,此命令…...

Kubernetes/k8s的核心概念
一、什么是 Kubernetes Kubernetes,从官方网站上可以看到,它是一个工业级的容器编排平台。Kubernetes 这个单词是希腊语,它的中文翻译是“舵手”或者“飞行员”。在一些常见的资料中也会看到“ks”这个词,也就是“k8s”ÿ…...

vue 前端预览 Excel 表
一、安装依赖包官网 npm i luckyexceltemplate 模板 <!-- 用于渲染表格的容器 --> <div id"luckysheet" stylewidth:100vw;height:100vh></div>二、加载 异步加载及 import LuckyExcel from luckyexcel;/* 下列代码加载 cdn 文件,你…...

【JS】生成N位随机数
作用 用于邮箱验证码 码 ramNum.js /*** 生成N位随机数字* param {Number} l 默认:6,默认生成6位随机数字* returns 返回N位随机数字*/ const ramNum (l 6) > {let num for (let i 0; i < l; i) {const n Math.random()const str String(n…...

2024年FPGA可以进吗
2024年,IC设计FPGA行业仍有可能是一个极具吸引力和活力的行业,主要原因包括: 1. 技术发展趋势:随着5G、人工智能、物联网、自动驾驶、云计算等高新技术的快速发展和广泛应用,对集成电路尤其是高性能、低功耗、定制化芯…...
小程序图形:echarts-weixin 入门使用
去官网下载整个项目: https://github.com/ecomfe/echarts-for-weixin 拷贝ec-canvs文件夹到小程序里面 index.js里面的写法 import * as echarts from "../../components/ec-canvas/echarts" const app getApp(); function initChart(canvas, width, h…...

百度百科人物创建要求是什么?
百度百科作为我国最大的中文百科全书,其收录的人物词条要求严谨、客观、有权威性。那么,如何撰写一篇高质量的人物词条呢?本文伯乐网络传媒将从内容要求、注意事项以及创建流程与步骤三个方面进行详细介绍。 一、内容要求 1. 基本信息&#…...
)
练习2-线性回归迭代(李沐函数简要解析)
环境:再练习1中 视频链接:https://www.bilibili.com/video/BV1PX4y1g7KC/?spm_id_from333.999.0.0 代码与详解 数据库 numpy 数据处理处理 torch.utils 数据加载与数据 d2l 专门的库 nn 包含各种层与激活函数 import numpy as np import torch from torch.utils import da…...

人像背景分割SDK,智能图像处理
美摄科技人像背景分割SDK解决方案:引领企业步入智能图像处理新时代 随着科技的不断进步,图像处理技术已成为许多行业不可或缺的一部分。为了满足企业对于高质量、高效率人像背景分割的需求,美摄科技推出了一款领先的人像背景分割SDK…...
100M服务器能同时容纳多少人访问
100M服务器的并发容纳人数会受到多种因素的影响,这些因素包括单个用户的平均访问流量大小、每个用户的平均访问页面数、并发用户比例、服务器和网络的流量利用率以及服务器自身的处理能力。 点击以下任一云产品链接,跳转后登录,自动享有所有…...
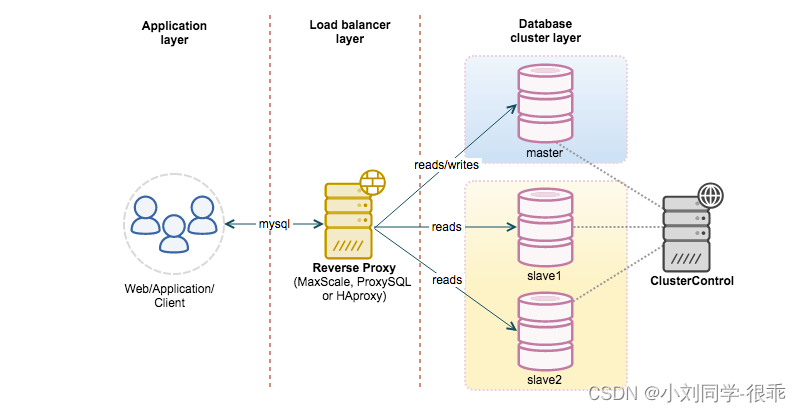
Mysql 的高可用详解
Mysql 高可用 复制 复制是解决系统高可用的常见手段。其思路就是:不要把鸡蛋都放在一个篮子里。 复制解决的基本问题是让一台服务器的数据与其他服务器保持同步。一台主库的数据可以同步到多台备库上,备库本身也可以被配置成另外一台服务器的主库。主…...
)
Acwing枚举、模拟与排序(一)
连号区间数 原题链接:https://www.acwing.com/problem/content/1212/ 初始最小值和最大值的依据是题目给出的数据范围。只要在数据范围之外就可以。 连号的时候,相邻元素元素之间,差值为1。那么区间右边界和左边界,的值的差&#…...

MySQL的主从同步原理
MySQL的主从同步(也称为复制)是一种数据同步技术,用于将一个MySQL服务器(主服务器)上的数据和变更实时复制到另一个或多个MySQL服务器(从服务器)。这项技术支持数据备份、读写分离、故障恢复等多…...
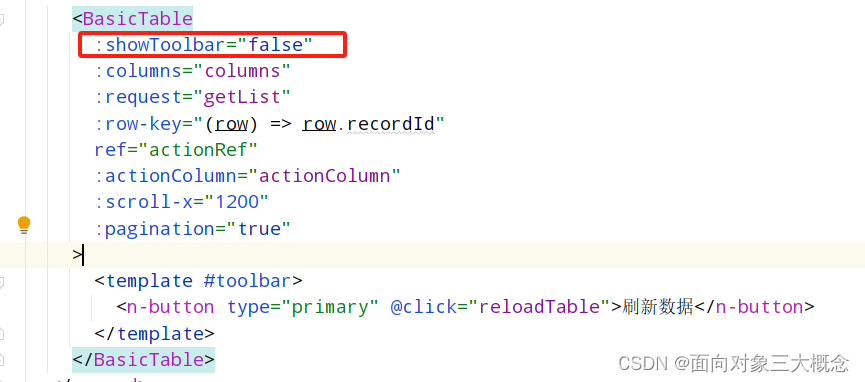
naive-ui-admin 表格去掉工具栏toolbar
使用naive-ui-admin的时候,有时候不需要显示工具栏,工具栏太占地方了。 1.在src/components/Table/src/props.ts 里面添加属性 showToolbar 默认显示,在不需要的地方传false。也可以默认不显示 ,这个根据需求来。 2.在src/compo…...

C++之结构体
结构体 //一、结构体的概念、定义和使用 // 概念:结构体属于用户自定义的数据类型,允许用户存储不同的数据类型 #include<iostream> using namespace std; #include<string> //1.创建学生数据类型:学生包括(姓名&am…...
)
分布式ID选型对比(1)
常见的几种ID生成方式对比: 种类 全局唯一 高性能 高可用 趋势递增 中心服务 缺点 UUID 是 高(本地生成,(无网络开销) 低(无序,不适用) 否 否 无序、字符串 数据库自增 单表唯一 中 中(宕机就会使业务服务中断) 是 否 安全性差,能猜出来规律 对于分库分表场景无法唯一 数据库自…...

T-SQL 高阶语法之存储过程
一:存储过程概念 预先存储好的sql程序,通过名称和参数进行执行,供应程序去调用,也可以有返回结果,存储过程可以包含sql语句 可以包含流程控制、逻辑语句等。 二:存储过程的优点 执行速度更快 允许模块化…...
解决鸿蒙模拟器卡顿的问题
缘起 最近在学习鸿蒙的时候,发现模拟器非常卡,不要说体验到鸿蒙的丝滑,甚至到严重影响使用的程度。 根据我开发Android的经验和在论坛翻了一圈,最终总结出了以下几个方案。 创建模拟器 1、在DevEco Virtual Device Configurat…...

【LeetCode每日一题】【BFS模版与例题】863.二叉树中所有距离为 K 的结点
BFS的基本概念 BFS 是广度优先搜索(Breadth-First Search)的缩写,是一种图遍历算法。它从给定的起始节点开始,逐层遍历图中的节点,直到遍历到目标节点或者遍历完所有可达节点。 BFS 算法的核心思想是先访问当前节点的…...

CustomStepper:28BYJ-48裸机步进控制库深度解析
1. CustomStepper 库深度解析:面向嵌入式工程师的 28BYJ-48 精密步进控制实践指南1.1 库定位与工程价值CustomStepper 是一个专为资源受限嵌入式平台设计的轻量级裸机(bare-metal)步进电机控制库,核心目标是为 28BYJ-48 型五相四线…...

电子电路中的“心脏”:电源匕
前言 Kubernetes 本身并不复杂,是我们把它搞复杂的。无论是刻意为之还是那种虽然出于好意却将优雅的原语堆砌成 鲁布戈德堡机械 的狂热。平台最初提供的 ReplicaSets、Services、ConfigMaps,这些基础组件简单直接,甚至显得有些枯燥。但后来我…...

终极网盘直链下载助手:八大平台一键获取真实链接,告别限速烦恼
终极网盘直链下载助手:八大平台一键获取真实链接,告别限速烦恼 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / …...

STM32 NVIC优先级设置详解:以红外传感器计数为例
STM32 NVIC优先级设置详解:以红外传感器计数为例 在嵌入式系统开发中,中断管理是确保实时响应和系统稳定性的核心机制。STM32微控制器凭借其强大的NVIC(嵌套向量中断控制器)为开发者提供了灵活的中断优先级配置方案。本文将以红外…...
)
【2026年网易互娱暑期实习/春招- 4月12日-第一题- 照明】(题目+思路+JavaC++Python解析+在线测试)
题目内容 给定一个 nnn 行 mmm 列的网格地图,每个格子是以下字符之一: ‘#’:障碍物; ‘.’:空地; ‘/’、’ \ :镜子; ‘LL...

SAP 后台作业自动化:从SM36配置到透明表数据同步
1. SAP后台作业自动化入门指南 第一次接触SAP后台作业时,我被这个功能惊艳到了。想象一下,你每天需要手动执行的报表程序,现在可以像闹钟一样准时自动运行,还能把结果自动保存到数据库表中。这简直就是程序员的"时间管理神器…...
:当技术让一切趋同,我们还剩什么?儇)
代码之外周刊(第期):当技术让一切趋同,我们还剩什么?儇
1. 前言 本文详细介绍如何使用 kylin v10 iso 文件构建出 docker image,docker 版本为 20.10.7。 2. 构建 yum 离线源 2.1. 挂载 ISO 文件 mount Kylin-Server-V10-GFB-Release-030-ARM64.iso /media 2.2. 添加离线 repo 文件 在/etc/yum.repos.d/下创建kylin…...
)
告别摄像头!用UWB雷达打造无感智能家居,手把手教你DIY人体存在传感器(基于ESP32)
告别摄像头!用UWB雷达打造无感智能家居,手把手教你DIY人体存在传感器(基于ESP32) 智能家居的终极理想是"无感交互"——设备能主动感知人的存在和需求,却不会带来任何隐私顾虑或操作负担。传统方案依赖摄像头…...
高效部署到边缘端?)
RK3588 NPU实战:如何将PC训练的人脸识别模型(ONNX)高效部署到边缘端?
RK3588 NPU实战:从ONNX模型到边缘端高效部署的人脸识别全流程解析 当你在PyTorch或TensorFlow中完成人脸识别模型的训练,导出为ONNX格式的那一刻,真正的挑战才刚刚开始。如何让这个模型在RK3588的NPU上以最佳性能运行?这是每个从云…...
:多轮对话SOTA模型在长记忆场景下的5项隐性衰减指标)
2026奇点大会闭门报告泄露(含原始benchmark数据):多轮对话SOTA模型在长记忆场景下的5项隐性衰减指标
第一章:2026奇点智能技术大会:大模型多轮对话 2026奇点智能技术大会(https://ml-summit.org) 在2026奇点智能技术大会上,大模型多轮对话能力成为核心议题之一。与会研究者展示了新一代对话系统在长程上下文建模、意图漂移检测与跨轮记忆对齐…...