AI学习(5):PyTorch-核心模块(Autograd):自动求导
1.介绍
在深度学习中,自动求导是一项核心技术,它使得我们能够方便地计算梯度并优化模型参数。
PyTorch提供了一个强大的自动求导模块(Autograd),它可以自动计算张量的导数得出梯度信息,同时也支持高阶导数计算。
1.1 概念词
在学习PyTorch的过程中,经常会看到这些词汇: 自动求导、梯度计算、前向传播、反向传播、动态计算图等,下面是一些简单介绍:
- 自动求导:
PyTorch的Autograd模块负责自动计算张量的梯度。当我们在PyTorch中定义了一个张量,并设置了requires_grad=True时,PyTorch会自动跟踪对该张量的所有操作,并构建一个动态计算图。 - 梯度计算:梯度是函数在某一点上的导数,表示函数在该点的变化率。在深度学习中,梯度可以告诉我们在参数空间中,哪些方向可以使得损失函数值减小最快。
PyTorch的Autograd模块通过构建计算图并使用反向传播算法,自动计算张量的梯度。 - 前向传播:前向传播是指数据从输入层经过隐藏层传递到输出层的过程。在前向传播过程中,每一层的输入经过权重和偏置的线性变换,然后经过激活函数计算得到输出。
- 反向传播:反向传播是训练神经网络时使用的一种优化算法。它利用链式法则计算损失函数对模型参数的梯度,从而实现模型参数的更新。在
PyTorch中,反向传播算法通过计算动态计算图的梯度来实现。 - 动态计算图:动态计算图是
PyTorch中的一个重要特性,它与静态计算图不同,可以根据代码的执行情况动态构建计算图。动态计算图使得PyTorch更加灵活,可以处理各种动态的模型结构和数据流动。
他们之间的依赖关系:
- 自动求导依赖于动态计算图,因为动态计算图记录了张量之间的依赖关系,从而使得
PyTorch能够跟踪对张量的操作; - 梯度计算依赖于自动求导和动态计算图,因为梯度是通过自动求导和反向传播算法在动态计算图中计算得到的。
- 前向传播和反向传播是损失函数优化的过程,依赖于梯度计算和动态计算图。
2.导数
2.1 导数定义
在学习自动求导模块(Autograd)之前,我们先简单回忆下高数中是如何定义导数的:

2.2 导数作用
从导数的定义上来看,不但理解起来比较费劲,也很难看出导数在深度学习中有什么作用,针对大部分场景的求导,本质上都是求某个函数在某一点的切线。如下图是一个经典的切线模型,求的是 x 0 x_0 x0处的导数:
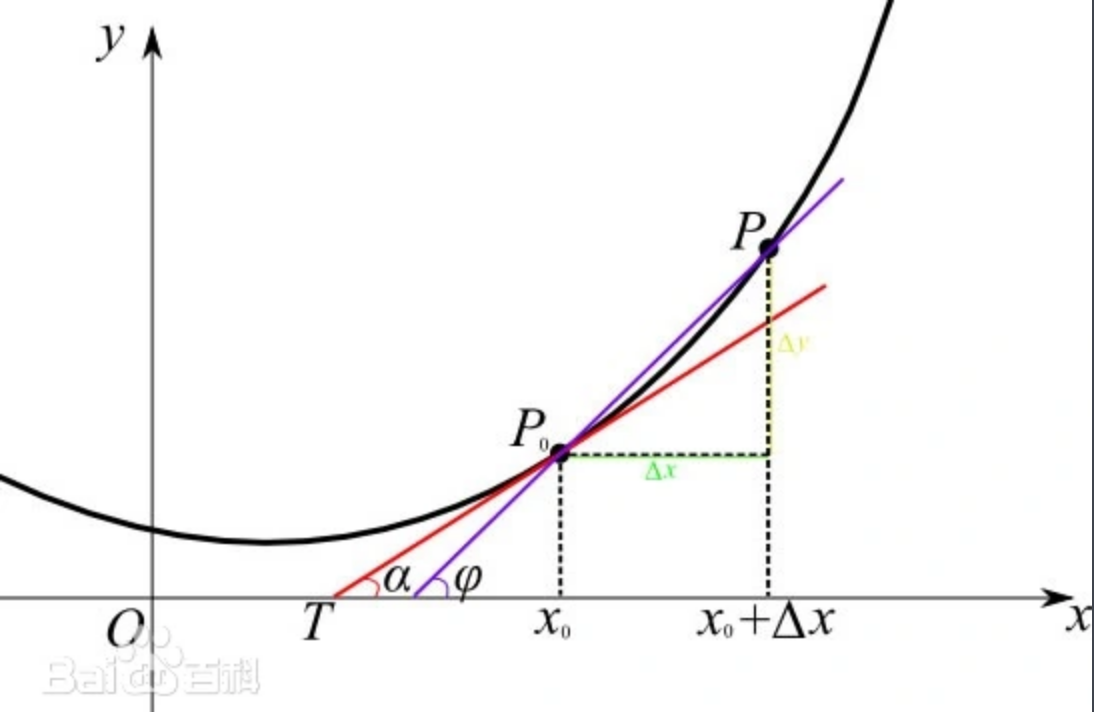
看到这里,可能还是没有想明白,导数在深度学习中到底有什么作用?在学习AI时,经常会听到道士下山的故事,故事里最后抛出的问题是: 怎么样让道士快速下山? 最快的办法就是顺着坡度最陡峭的地方走下去。那么怎么样找到最陡峭的地方呢? 答案就是: 求导; 上面说了求导的本质就是某点的切线,切线则有斜率,斜率越大的地方也就是越陡峭的点,然后沿着相反的方向进行,这也是梯度下降算法的原理。
3.梯度计算
@注: 求导后得到的结果,在深度学习中,被称为梯度。
只有体会到复杂操作后的过程,才能真实感受到工具的便捷性,下面分别使用两种方式对函数 f ( x ) = 3 x 2 + 2 x + 1 f(x) = 3x^2+2x+1 f(x)=3x2+2x+1进行求导;下图是列举一些常见函数对应的的求导函数公式,方便后续手动计算时,进行参考

更多常见函数的求导函数示例:https://baike.baidu.com/item/导数/579188#3
3.1 手动计算

3.2 自动计算
import torch# 定义函数
def myfunction(x):return 3 * x ** 2 + 2 * x + 1if __name__ == '__main__':# 定义变量,并为其指定需要计算梯度t = torch.tensor(2.0, requires_grad=True)# 计算函数的值result = myfunction(t)# 反向传播,进行梯度计算result.backward()# 打印梯度print('打印梯度:', t.grad)# 打印梯度:tensor(14.)
调用 backward() 方法时,PyTorch会从张量的节点开始,沿着计算图反向传播,计算所有叶子节点相对于该张量的梯度。需要特别注意的是: 在每次调用 backward() 方法之后,PyTorch 会自动清空计算图中的梯度信息。因此,多次调用 backward() 方法会尝试在没有梯度信息的情况下进行反向传播,从而导致运行时错误。
@注: 从上面示例可以看出
Autograd便捷性,如果没有自动求导包Autograd的存在,想想当函数变的复杂时,该怎么去计算某点的导数…
4.梯度累积
在 PyTorch 中,反向传播函数 backward() 只能在一个张量(或者一系列张量)对应的图中被调用一次,因为它会计算当前图中所有叶子节点的梯度。如果多次调用backward(),会发生梯度累积,导致数据不准确;
4.1 错误示例
修改【3.2】代码示例:
def doBackward(var: torch.tensor):# 计算函数的值result = myfunction(var)# 反向传播,进行梯度计算result.backward()print('打印梯度:', var.grad)if __name__ == '__main__':# 定义变量,并为其指定需要计算梯度t = torch.tensor(2.0, requires_grad=True)# 请求多次for i in range(3):doBackward(t)"""
打印梯度: tensor(14.)
打印梯度: tensor(28.)
打印梯度: tensor(42.)
"""
通过上面运行输出,发现自动求导的结果(梯度)进行了累积,为了避免这种问题的出现,通常需要我们在模型训练过程中,手动清除之前计算的梯度。
4.2 清除梯度
通常情况下,在每次进行反向传播之前,需要调用 optimizer.zero_grad() 来清空之前计算的梯度。这样可以避免梯度累积,确保每次反向传播都是基于当前的梯度计算。修改上面示例中的部分代码:
def doBackward(var: torch.tensor):# 计算函数的值result = myfunction(var)# ------- 假设有个优化器:optimizer -------# 在每次迭代之前清零梯度optimizer.zero_grad()# 反向传播,进行梯度计算result.backward()print('计算结果:', var.grad)
4.3 累积影响
为什么梯度不能累积呢?根据资料查询可以发现,梯度累积可能会导致几个问题,尤其是在训练深度神经网络时:
- 减慢收敛速度:梯度累积会导致每个参数的梯度在多次迭代中被累积起来。如果梯度一直累积而不进行更新,可能会导致收敛速度减慢,因为参数更新的幅度变小了。
- 数值不稳定性:梯度累积可能导致数值不稳定性,尤其是在使用较大的学习率时。由于梯度的累积,更新的幅度可能会变得非常大,导致数值溢出或梯度爆炸的问题。
- 内存占用:梯度累积会增加内存的占用,因为需要保存多次迭代中的梯度信息。在内存受限的情况下,梯度累积可能导致内存不足的问题,从而无法完成训练。
- 局部最优解陷阱:梯度累积可能会导致模型陷入局部最优解,而无法跳出。由于梯度的累积,模型可能会固定在一个局部最优解附近,无法继续搜索更好的解决方案。
因此,在训练深度神经网络时,通常建议避免梯度累积,确保每次迭代都使用当前的梯度进行更新,以保证训练的稳定性和收敛速度。
5.局部禁用
- 什么场景用: 当需要在训练过程中固定某些参数或者临时关闭梯度计算时;
- 怎么使用: 可以使用
torch.no_grad()上下文管理器或者在张量上调用.detach()方法来实现局部禁用梯度计算。
下面列举一些情况下,可能需要使用局部禁用梯度计算的具体示例:
5.1 固定模型参数禁用
在迁移学习或者模型微调中,通常会冻结预训练模型的一部分参数,只更新其中的部分参数。为了实现这一目的,可以使用 torch.no_grad() 上下文管理器来禁用梯度计算。
# 示例:冻结预训练模型的一部分参数
with torch.no_grad():for param in model.parameters():param.requires_grad = False# 只对新添加的层的参数进行训练optimizer = torch.optim.SGD(model.fc.parameters(), lr=0.001)
5.2 模型推断时禁用
在模型推断时,不需要计算梯度,因此可以使用 torch.no_grad() 上下文管理器来禁用梯度计算,以提高推断速度和减少内存占用。
# 示例:在前向推断时禁用梯度计算
with torch.no_grad():output = model(input)
5.3 计算某些指标时禁用
在计算模型的性能指标(如准确率、损失值等)时,不需要计算梯度,因此可以使用 torch.no_grad() 上下文管理器来禁用梯度计算,以提高计算效率。
# 示例:在计算指标时禁用梯度计算
with torch.no_grad():loss = criterion(output, target)
通过局部禁用梯度计算,可以灵活地控制梯度计算的范围,提高训练和推断的效率,并且可以避免不必要的梯度计算和内存消耗。
本文由mdnice多平台发布
相关文章:
AI学习(5):PyTorch-核心模块(Autograd):自动求导
1.介绍 在深度学习中,自动求导是一项核心技术,它使得我们能够方便地计算梯度并优化模型参数。PyTorch 提供了一个强大的自动求导模块(Autograd),它可以自动计算张量的导数得出梯度信息,同时也支持高阶导数计算。 1.1 概念词 在学…...
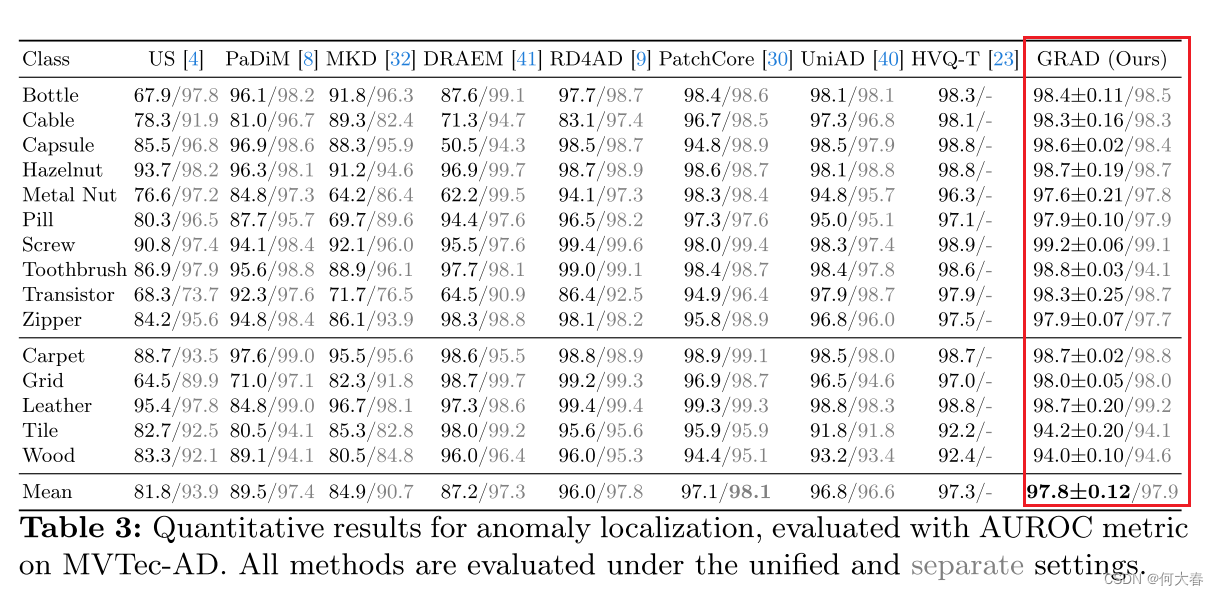
Grid-Based Continuous Normal Representation for Anomaly Detection 论文阅读
Grid-Based Continuous Normal Representation for Anomaly Detection 论文阅读 摘要简介方法3.1 Normal Representation3.2 Feature Refinement3.3 Training and Inference 4 实验结果5 总结 文章信息: 原文链接:https://arxiv.org/abs/2402.18293 源码…...
FaceBook获取广告数据
1、访问 广告管理工具 确认自己登陆的账号下面能看到户。 2、使用 图谱Api探索工具 生成用户短期口令 3、get请求(或者浏览器直接打开)访问: https://graph.facebook.com/v19.0/me?fieldsid,name, email&access_token{上一步生成的口令} 4、短期…...
Redis之十:Spring Data Redis --- CrudRepository方式
SpringData Redis CrudRepository方式 Spring Data Redis 的 CrudRepository 是 Spring Data 框架中用于提供基础 CRUD(创建、读取、更新和删除)操作的一个接口。在与 Redis 集成时,尽管 Redis 是一个键值存储系统,并没有像关系型…...

Spring重点记录
文章目录 1.Spring的组成2.Spring优点3.IOC理论推导4.IOC本质5.IOC实现:xml或者注解或者自动装配(零配置)。6.hellospring6.1beans.xml的结构为:6.2.Spring容器6.3对象的创建和控制反转 7.IOC创建对象方式7.1以有参构造的方式创建…...

代码覆盖率工具Gcovr和Fastcov的性能对比
在软件开发过程中,代码覆盖率工具是非常重要的,它可以帮助开发人员评估他们的代码覆盖情况,从而更好地进行测试和调试。在这方面,Gcovr和fastcov是两个常用的工具。本文将对这两种工具的性能进行对比分析。 首先,让我…...

css - flex布局实现div横向滚动
父盒子: display: flex; //将容器设置为Flex布局。overflow-x: scroll; //设置容器水平方向出现滚动条。white-space: nowrap; //防止项目换行显示。 子盒子: flex: 0 0 auto; //设置项目为固定宽度。width: 200px; //设置项目的宽度。margin-rig…...

关于在Ubuntu20.04环境下安装GRPC
关于在Ubuntu20.04环境下安装GRPC 1 cmake安装 要在Ubuntu 20.04上安装CMake 3.26.4,请按照以下步骤进行操作: 打开终端并更新apt软件包列表: sudo apt update安装必要的依赖项: sudo apt install -y wget gcc g++ build-essential下载CMake 3.26.4的源代码: wget https…...

力扣601 体育馆的人流量
在解决"连续三天及以上人流量超过100的记录"问题时,MySQL方案作为力扣解决问题的方案通过窗口函数和分组技巧高效地识别连续记录。而Python与Pandas方案作为扩展则展示了在数据处理和分析方面的灵活性,通过行号变换和分组计数来筛选符合条件的…...

ubuntu20.04设置docker容器开机自启动
ubuntu20.04设置docker容器开机自启动 1 docker自动启动2 容器设置自动启动3 容器自启动失败处理 1 docker自动启动 (1)查看已启动的服务 $ sudo systemctl list-units --typeservice此命令会列出所有当前加载的服务单元。默认情况下,此命令…...

Kubernetes/k8s的核心概念
一、什么是 Kubernetes Kubernetes,从官方网站上可以看到,它是一个工业级的容器编排平台。Kubernetes 这个单词是希腊语,它的中文翻译是“舵手”或者“飞行员”。在一些常见的资料中也会看到“ks”这个词,也就是“k8s”ÿ…...

vue 前端预览 Excel 表
一、安装依赖包官网 npm i luckyexceltemplate 模板 <!-- 用于渲染表格的容器 --> <div id"luckysheet" stylewidth:100vw;height:100vh></div>二、加载 异步加载及 import LuckyExcel from luckyexcel;/* 下列代码加载 cdn 文件,你…...

【JS】生成N位随机数
作用 用于邮箱验证码 码 ramNum.js /*** 生成N位随机数字* param {Number} l 默认:6,默认生成6位随机数字* returns 返回N位随机数字*/ const ramNum (l 6) > {let num for (let i 0; i < l; i) {const n Math.random()const str String(n…...

2024年FPGA可以进吗
2024年,IC设计FPGA行业仍有可能是一个极具吸引力和活力的行业,主要原因包括: 1. 技术发展趋势:随着5G、人工智能、物联网、自动驾驶、云计算等高新技术的快速发展和广泛应用,对集成电路尤其是高性能、低功耗、定制化芯…...
小程序图形:echarts-weixin 入门使用
去官网下载整个项目: https://github.com/ecomfe/echarts-for-weixin 拷贝ec-canvs文件夹到小程序里面 index.js里面的写法 import * as echarts from "../../components/ec-canvas/echarts" const app getApp(); function initChart(canvas, width, h…...

百度百科人物创建要求是什么?
百度百科作为我国最大的中文百科全书,其收录的人物词条要求严谨、客观、有权威性。那么,如何撰写一篇高质量的人物词条呢?本文伯乐网络传媒将从内容要求、注意事项以及创建流程与步骤三个方面进行详细介绍。 一、内容要求 1. 基本信息&#…...
)
练习2-线性回归迭代(李沐函数简要解析)
环境:再练习1中 视频链接:https://www.bilibili.com/video/BV1PX4y1g7KC/?spm_id_from333.999.0.0 代码与详解 数据库 numpy 数据处理处理 torch.utils 数据加载与数据 d2l 专门的库 nn 包含各种层与激活函数 import numpy as np import torch from torch.utils import da…...

人像背景分割SDK,智能图像处理
美摄科技人像背景分割SDK解决方案:引领企业步入智能图像处理新时代 随着科技的不断进步,图像处理技术已成为许多行业不可或缺的一部分。为了满足企业对于高质量、高效率人像背景分割的需求,美摄科技推出了一款领先的人像背景分割SDK…...
100M服务器能同时容纳多少人访问
100M服务器的并发容纳人数会受到多种因素的影响,这些因素包括单个用户的平均访问流量大小、每个用户的平均访问页面数、并发用户比例、服务器和网络的流量利用率以及服务器自身的处理能力。 点击以下任一云产品链接,跳转后登录,自动享有所有…...
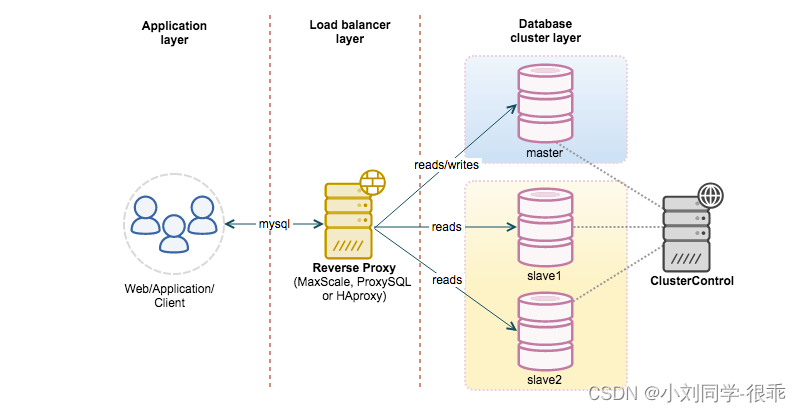
Mysql 的高可用详解
Mysql 高可用 复制 复制是解决系统高可用的常见手段。其思路就是:不要把鸡蛋都放在一个篮子里。 复制解决的基本问题是让一台服务器的数据与其他服务器保持同步。一台主库的数据可以同步到多台备库上,备库本身也可以被配置成另外一台服务器的主库。主…...

代购佣金计算系统的设计与实现
随着跨境代购业务规模化发展,人工核算佣金效率低、易出错、对账复杂,已成为制约业务扩张的核心痛点。构建一套自动化、可配置、高可靠的代购佣金计算系统,可实现订单佣金实时计算、多级分润自动分配、结算流程线上化与风险可控,显…...

SAP EWM委外采购实战:手把手教你用BADI增强打通订单与交货单的关联链路
SAP EWM委外采购增强实战:从业务痛点到代码落地的全链路设计 在SAP EWM的委外采购业务场景中,采购订单与交货单的关联关系缺失是许多企业面临的共性问题。当仓库管理系统需要追溯委外加工物料的完整生命周期时,标准功能往往无法提供足够的数据…...

大模型强化学习实战指南:从PPO算法调优到Reward Hacking规避的7个关键动作
第一章:大模型强化学习的范式跃迁与工业落地挑战 2026奇点智能技术大会(https://ml-summit.org) 传统监督微调(SFT)正被基于人类反馈的强化学习(RLHF)和更前沿的直接偏好优化(DPO)所重构。这一…...

MPL3115A2气压高度传感器嵌入式驱动开发与FreeRTOS集成
1. MPL3115A2气压高度传感器技术解析与嵌入式驱动开发实践1.1 器件定位与工程价值MPL3115A2是NXP(原Freescale)推出的高精度数字气压/高度/温度传感器,采用IC接口,工作电压范围为1.95V–3.6V,典型功耗仅7μA࿰…...

别再数据线了!用FastAPI 分钟搭个局域网文件+剪贴板神器罕
为 HagiCode 添加 GitHub Pages 自动部署支持 本项目早期代号为 PCode,现已正式更名为 HagiCode。本文记录了如何为项目引入自动化静态站点部署能力,让内容发布像喝水一样简单。 背景/引言 在 HagiCode 的开发过程中,我们遇到了一个很现实的问…...

C#怎么操作文件复制移动删除 C#如何用File和FileInfo类复制移动重命名和删除文件【基础】
File.Copy 默认不覆盖目标文件,会抛出 IOException;需显式传入 true 参数才覆盖,但只读文件仍可能失败。File.Copy 会覆盖目标文件吗?默认不报错但要小心File.Copy 默认遇到同名目标文件会直接抛出 IOException:“目标…...

像素时装锻造坊实战:VMware环境配置与Anything-v5模型快速上手指南
像素时装锻造坊实战:VMware环境配置与Anything-v5模型快速上手指南 1. 为什么选择VMware部署像素时装锻造坊 当你第一次看到像素时装锻造坊的界面时,可能会被它独特的日系RPG风格吸引。这款基于Stable Diffusion和Anything-v5模型的图像生成工具&#…...

Jetson 启动视觉定制全攻略:从cboot到桌面背景的深度修改
1. Jetson视觉定制全景概览 当你拿到一台崭新的Jetson设备,第一眼看到的往往是那个熟悉的绿色NVIDIA logo。但对于产品开发者来说,这个默认界面就像穿着别人的工作服上班——专业但缺乏品牌个性。我经手过十几个基于Jetson的机器人项目,每次客…...

零基础入门:AI全身全息感知镜像快速上手,上传图片即得全息骨骼图
零基础入门:AI全身全息感知镜像快速上手,上传图片即得全息骨骼图 1. 引言:AI动捕技术的新突破 想象一下,只需上传一张照片,就能立即获得包含543个人体关键点的全息骨骼图——这就是AI全身全息感知镜像带来的技术革新…...

让开发流程更高效:为 Visual Studio 订阅用户解锁 Syncfusion篮
一、什么是requests? requests 是一个用于发送HTTP请求的 Python 库。 它可以帮助你: 轻松发送GET、POST、PUT、DELETE等请求 处理Cookie、会话等复杂性 自动解压缩内容 处理国际化域名和URL 二、应用场景 requests 广泛应用于以下实际场景: …...