链表基础知识详解(非常详细简单易懂)
概述:
链表作为 C 语言中一种基础的数据结构,在平时写程序的时候用的并不多,但在操作系统里面使用的非常多。不管是RTOS还是Linux等使用非常广泛,所以必须要搞懂链表,链表分为单向链表和双向链表,单向链表很少用,使用最多的还是双向链表。单向链表懂了双向链表自然就会了。
文章目录
一、链表的概念
链表的构成:
链表的操作:
双向链表
链表与数组的对比
二、链表的创建
三、链表的遍历
四、链表的释放
五、链表节点的查找
六、链表节点的删除
七、链表中插入一个节点
八、链表排序
九、双向链表的创建和遍历
十、双向链表插入节点
一、链表的概念
定义:
链表是一种物理存储上非连续,数据元素的逻辑顺序通过链表中的指针链接次序,实现的一种线性存储结构。
特点:
链表由一系列节点(链表中每一个元素称为节点)组成,节点在运行时动态生成 (malloc),每个节点包括两个部分:
一个是存储数据元素的数据域
另一个是存储下一个节点地址的指针域

图1 单向链表
链表的构成:
链表由一个个节点构成,每个节点一般采用结构体的形式组织,例如:
typedef struct student{int num;char name[20];struct student *next;}STU;链表节点分为两个域
数据域:存放各种实际的数据,如:num、score等
指针域:存放下一节点的首地址,如:next等.

图2 节点内嵌在一个数据结构中
链表的操作:
链表最大的作用是通过节点把离散的数据链接在一起,组成一个表,这大概就是链表 的字面解释了吧。 链表常规的操作就是节点的插入和删除,为了顺利的插入,通常一条链 表我们会人为地规定一个根节点,这个根节点称为生产者。通常根节点还会有一个节点计 数器,用于统计整条链表的节点个数,具体见图3中的 root_node。

图3带根节点的链表
双向链表
双向链表与单向链表的区别就是节点中有两个节点指针,分别指向前后两个节点,其 它完全一样。有关双向链表的文字描述参考单向链表小节即可,有关双向链表的示意图具体见图4

图4双向链表
链表与数组的对比
在很多公司的嵌入式面试中,通常会问到链表和数组的区别。在 C 语言中,链表与数 组确实很像,两者的示意图具体见图5,这里以双向链表为例。
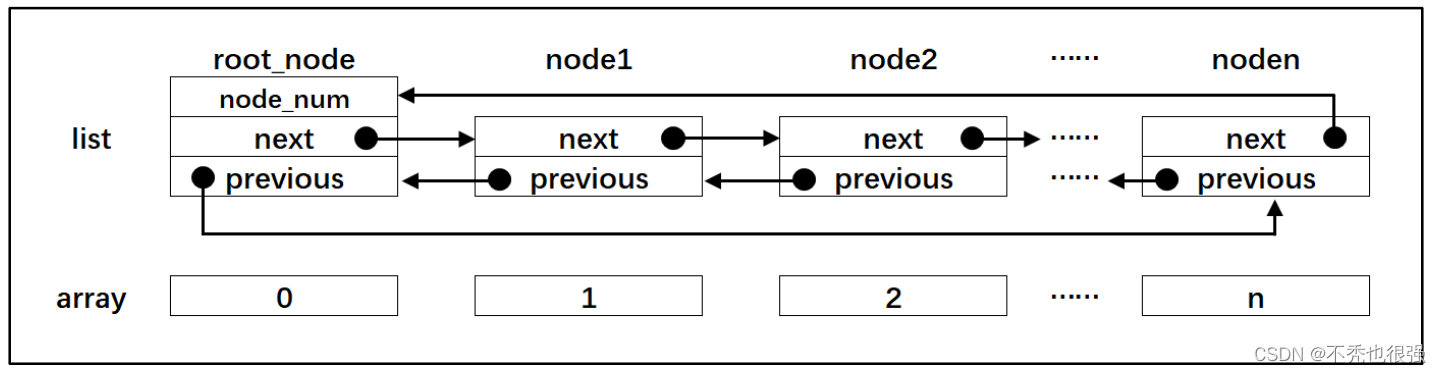 图5 链表与数组的对比
图5 链表与数组的对比
链表是通过节点把离散的数据链接成一个表,通过对节点的插入和删除操作从而实现 对数据的存取。而数组是通过开辟一段连续的内存来存储数据,这是数组和链表最大的区 别。数组的每个成员对应链表的节点,成员和节点的数据类型可以是标准的 C 类型或者是 用户自定义的结构体。数组有起始地址和结束地址,而链表是一个圈,没有头和尾之分, 但是为了方便节点的插入和删除操作会人为的规定一个根节点。
二、链表的创建
第一步:创建一个节点
![]()
第二步:创建第二个节点,将其放在第一个节点的后面(第一的节点的指针域保存第二个节点的地址)
![]()
第三步:再次创建节点,找到原本链表中的最后一个节点,接着讲最后一个节点的指针域保存新节点的地址,以此内推。
![]()
#include <stdio.h>
#include <stdlib.h>
//定义结点结构体
typedef struct student
{//数据域int num; //学号int score; //分数char name[20]; //姓名//指针域struct student *next;
}STU;void link_creat_head(STU **p_head,STU *p_new)
{STU *p_mov = *p_head;if(*p_head == NULL) //当第一次加入链表为空时,head执行p_new{*p_head = p_new;p_new->next=NULL;}else //第二次及以后加入链表{while(p_mov->next!=NULL){p_mov=p_mov->next; //找到原有链表的最后一个节点}p_mov->next = p_new; //将新申请的节点加入链表p_new->next = NULL;}
}int main()
{STU *head = NULL,*p_new = NULL;int num,i;printf("请输入链表初始个数:\n");scanf("%d",&num);for(i = 0; i < num;i++){p_new = (STU*)malloc(sizeof(STU));//申请一个新节点printf("请输入学号、分数、名字:\n"); //给新节点赋值scanf("%d %d %s",&p_new->num,&p_new->score,p_new->name);link_creat_head(&head,p_new); //将新节点加入链表}
}
三、链表的遍历
第一步:输出第一个节点的数据域,输出完毕后,让指针保存后一个节点的地址
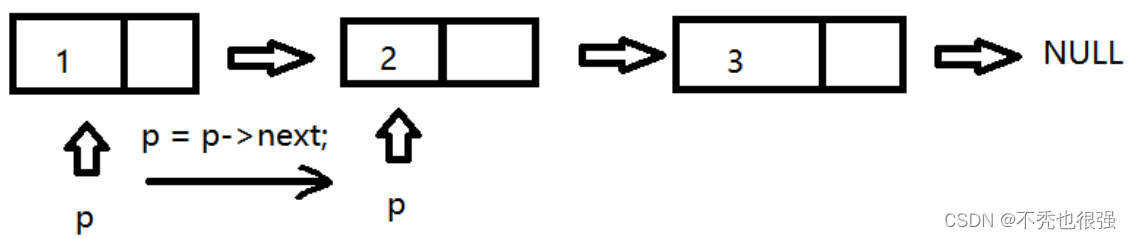
第二步:输出移动地址对应的节点的数据域,输出完毕后,指针继续后移
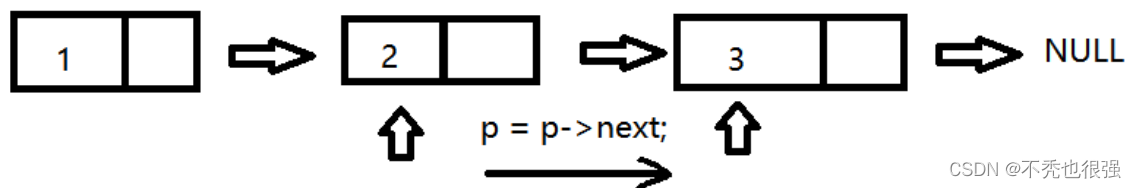
第三步:以此类推,直到节点的指针域为NULL
//链表的遍历
void link_print(STU *head)
{STU *p_mov;//定义新的指针保存链表的首地址,防止使用head改变原本链表p_mov = head;//当指针保存最后一个结点的指针域为NULL时,循环结束while(p_mov!=NULL){//先打印当前指针保存结点的指针域printf("num=%d score=%d name:%s\n",p_mov->num,\p_mov->score,p_mov->name);//指针后移,保存下一个结点的地址p_mov = p_mov->next;}
}四、链表的释放
重新定义一个指针q,保存p指向节点的地址,然后p后移保存下一个节点的地址,然后释放q对应的节点,以此类推,直到p为NULL为止

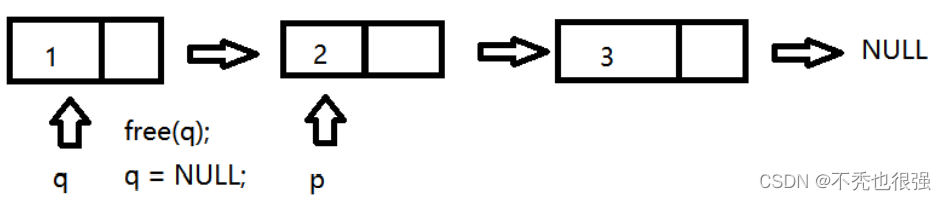
//链表的释放void link_free(STU **p_head){//定义一个指针变量保存头结点的地址STU *pb=*p_head;while(*p_head!=NULL){//先保存p_head指向的结点的地址pb=*p_head;//p_head保存下一个结点地址*p_head=(*p_head)‐>next;//释放结点并防止野指针free(pb);pb = NULL;}}五、链表节点的查找
先对比第一个结点的数据域是否是想要的数据,如果是就直接返回,如果不是则继续查找下 一个结点,如果到达最后一个结点的时候都没有匹配的数据,说明要查找数据不存在
//链表的查找
//按照学号查找
STU * link_search_num(STU *head,int num)
{STU *p_mov;//定义的指针变量保存第一个结点的地址p_mov=head;//当没有到达最后一个结点的指针域时循环继续while(p_mov!=NULL){//如果找到是当前结点的数据,则返回当前结点的地址if(p_mov->num == num)//找到了{return p_mov;}//如果没有找到,则继续对比下一个结点的指针域p_mov=p_mov->next;}//当循环结束的时候还没有找到,说明要查找的数据不存在,返回NULL进行标识return NULL;//没有找到
}//按照姓名查找
STU * link_search_name(STU *head,char *name)
{STU *p_mov;p_mov=head;while(p_mov!=NULL){if(strcmp(p_mov->name,name)==0)//找到了{return p_mov;}p_mov=p_mov->next;}return NULL;//没有找到
}六、链表节点的删除
如果链表为空,不需要删除 如果删除的是第一个结点,则需要将保存链表首地址的指针保存第一个结点的下一个结点的 地址 如果删除的是中间结点,则找到中间结点的前一个结点,让前一个结点的指针域保存这个结 点的后一个结点的地址即可
//链表结点的删除
void link_delete_num(STU **p_head,int num)
{STU *pb,*pf;pb=pf=*p_head;if(*p_head == NULL)//链表为空,不用删{printf("链表为空,没有您要删的节点");\return ;}while(pb->num != num && pb->next !=NULL)//循环找,要删除的节点{pf=pb;pb=pb->next;}if(pb->num == num)//找到了一个节点的num和num相同{if(pb == *p_head)//要删除的节点是头节点{//让保存头结点的指针保存后一个结点的地址*p_head = pb->next;}else{//前一个结点的指针域保存要删除的后一个结点的地址pf->next = pb->next;}//释放空间free(pb);pb = NULL;}else//没有找到{printf("没有您要删除的节点\n");}
}七、链表中插入一个节点
链表中插入一个结点,按照原本链表的顺序插入,找到合适的位置
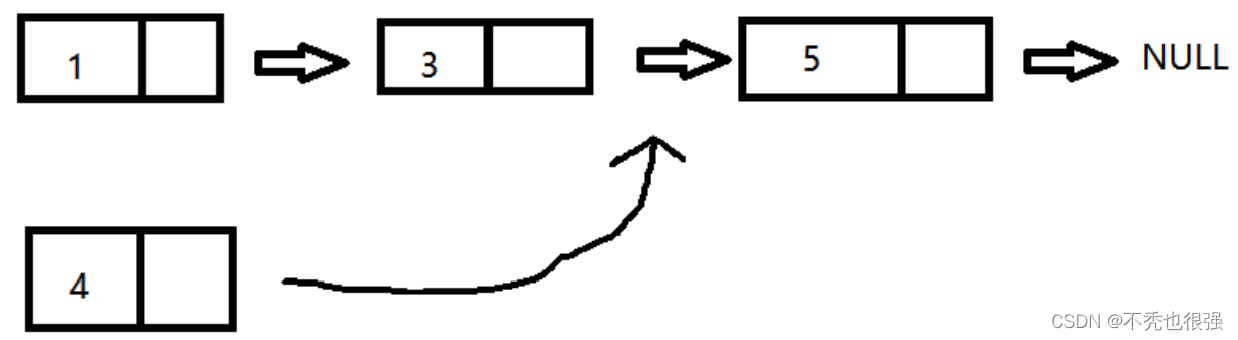
情况(按照从小到大):
如果链表没有结点,则新插入的就是第一个结点。
如果新插入的结点的数值最小,则作为头结点。
如果新插入的结点的数值在中间位置,则找到前一个,然后插入到他们中间。
如果新插入的结点的数值最大,则插入到最后。
//链表的插入:按照学号的顺序插入
void link_insert_num(STU **p_head,STU *p_new)
{STU *pb,*pf;pb=pf=*p_head;if(*p_head ==NULL)// 链表为空链表{*p_head = p_new;p_new->next=NULL;return ;}while((p_new->num >= pb->num) && (pb->next !=NULL) ){pf=pb;pb=pb->next;}if(p_new->num < pb->num)//找到一个节点的num比新来的节点num大,插在pb的前面{if(pb== *p_head)//找到的节点是头节点,插在最前面{p_new->next= *p_head;*p_head =p_new;}else{pf->next=p_new;p_new->next = pb;}}else//没有找到pb的num比p_new->num大的节点,插在最后{pb->next =p_new;p_new->next =NULL;}
}八、链表排序
如果链表为空,不需要排序。
如果链表只有一个结点,不需要排序。
先将第一个结点与后面所有的结点依次对比数据域,只要有比第一个结点数据域小的,则交 换位置。
交换之后,拿新的第一个结点的数据域与下一个结点再次对比,如果比他小,再次交换,依 次类推。
第一个结点确定完毕之后,接下来再将第二个结点与后面所有的结点对比,直到最后一个结 点也对比完毕为止。
//链表的排序
void link_order(STU *head)
{STU *pb,*pf,temp;pf=head;if(head==NULL){printf("链表为空,不用排序\n");return ;}if(head->next ==NULL){printf("只有一个节点,不用排序\n");return ;}while(pf->next !=NULL)//以pf指向的节点为基准节点,{pb=pf->next;//pb从基准元素的下个元素开始while(pb!=NULL){if(pf->num > pb->num){temp=*pb;*pb=*pf;*pf=temp;temp.next=pb->next;pb->next=pf->next;pf->next=temp.next;}pb=pb->next;}pf=pf->next;}
}九、双向链表的创建和遍历
第一步:创建一个节点作为头节点,将两个指针域都保存NULL
第二步:先找到链表中的最后一个节点,然后让最后一个节点的指针域保存新插入节点的地址,新插入节点的两个指针域,一个保存上一个节点的地址,一个保存NULL
#include <stdio.h>
#include <stdlib.h>//定义结点结构体
typedef struct student
{//数据域int num; //学号int score; //分数char name[20]; //姓名//指针域struct student *front; //保存上一个结点的地址struct student *next; //保存下一个结点的地址
}STU;void double_link_creat_head(STU **p_head,STU *p_new)
{STU *p_mov=*p_head;if(*p_head==NULL) //当第一次加入链表为空时,head执行p_new{*p_head = p_new;p_new->front = NULL;p_new->next = NULL;}else //第二次及以后加入链表{while(p_mov->next!=NULL){p_mov=p_mov->next; //找到原有链表的最后一个节点}p_mov->next = p_new; //将新申请的节点加入链表p_new->front = p_mov;p_new->next = NULL;}
}void double_link_print(STU *head)
{STU *pb;pb=head;while(pb->next!=NULL){printf("num=%d score=%d name:%s\n",pb->num,pb->score,pb->name);pb=pb->next;}printf("num=%d score=%d name:%s\n",pb->num,pb->score,pb->name);printf("***********************\n");while(pb!=NULL){printf("num=%d score=%d name:%s\n",pb->num,pb->score,pb->name);pb=pb->front;}
}int main()
{STU *head=NULL,*p_new=NULL;int num,i;printf("请输入链表初始个数:\n");scanf("%d",&num);for(i=0;i<num;i++){p_new=(STU*)malloc(sizeof(STU));//申请一个新节点printf("请输入学号、分数、名字:\n"); //给新节点赋值scanf("%d %d %s",&p_new->num,&p_new->score,p_new->name);double_link_creat_head(&head,p_new); //将新节点加入链表}double_link_print(head);
}
十、双向链表插入节点
按照顺序插入结点
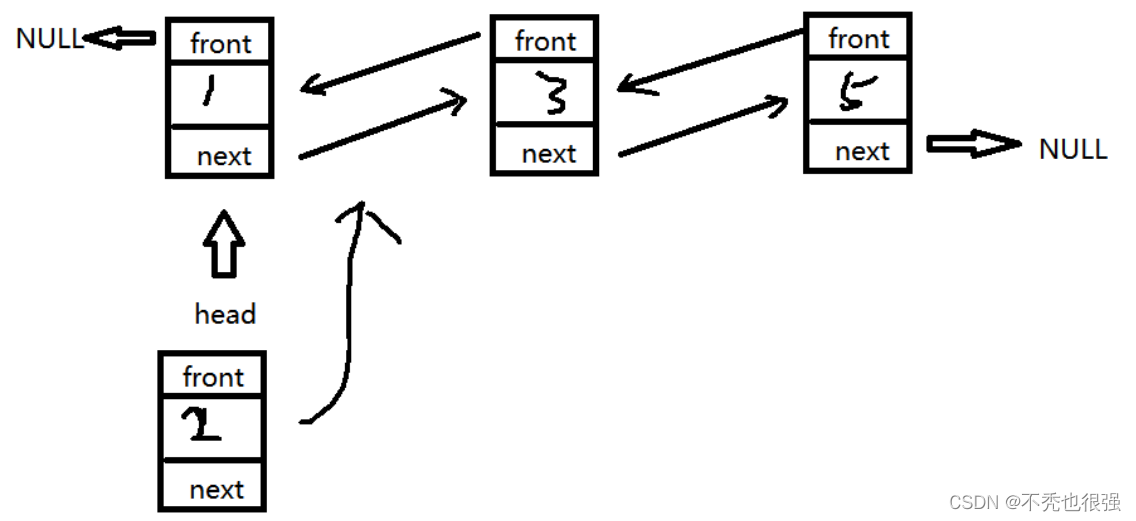
#include <stdio.h>
#include <stdlib.h>//定义结点结构体
typedef struct student
{//数据域int num; //学号int score; //分数char name[20]; //姓名//指针域struct student *front; //保存上一个结点的地址struct student *next; //保存下一个结点的地址
}STU;void double_link_creat_head(STU **p_head,STU *p_new)
{STU *p_mov=*p_head;if(*p_head==NULL) //当第一次加入链表为空时,head执行p_new{*p_head = p_new;p_new->front = NULL;p_new->next = NULL;}else //第二次及以后加入链表{while(p_mov->next!=NULL){p_mov=p_mov->next; //找到原有链表的最后一个节点}p_mov->next = p_new; //将新申请的节点加入链表p_new->front = p_mov;p_new->next = NULL;}
}void double_link_print(STU *head)
{STU *pb;pb=head;while(pb->next!=NULL){printf("num=%d score=%d name:%s\n",pb->num,pb->score,pb->name);pb=pb->next;}printf("num=%d score=%d name:%s\n",pb->num,pb->score,pb->name);printf("***********************\n");while(pb!=NULL){printf("num=%d score=%d name:%s\n",pb->num,pb->score,pb->name);pb=pb->front;}
}//双向链表的删除
void double_link_delete_num(STU **p_head,int num)
{STU *pb,*pf;pb=*p_head;if(*p_head==NULL)//链表为空,不需要删除{printf("链表为空,没有您要删除的节点\n");return ;}while((pb->num != num) && (pb->next != NULL) ){pb=pb->next;}if(pb->num == num)//找到了一个节点的num和num相同,删除pb指向的节点{if(pb == *p_head)//找到的节点是头节点{if((*p_head)->next==NULL)//只有一个节点的情况{*p_head=pb->next;}else//有多个节点的情况{*p_head = pb->next;//main函数中的head指向下个节点(*p_head)->front=NULL;}}else//要删的节点是其他节点{if(pb->next!=NULL)//删除中间节点{pf=pb->front;//让pf指向找到的节点的前一个节点pf->next=pb->next; //前一个结点的next保存后一个结点的地址(pb->next)->front=pf; //后一个结点的front保存前一个结点的地址}else//删除尾节点{pf=pb->front;pf->next=NULL;}}free(pb);//释放找到的节点}else//没找到{printf("没有您要删除的节点\n");}
}int main()
{STU *head=NULL,*p_new=NULL;int num,i;printf("请输入链表初始个数:\n");scanf("%d",&num);for(i=0;i<num;i++){p_new=(STU*)malloc(sizeof(STU));//申请一个新节点printf("请输入学号、分数、名字:\n"); //给新节点赋值scanf("%d %d %s",&p_new->num,&p_new->score,p_new->name);double_link_creat_head(&head,p_new); //将新节点加入链表}double_link_print(head);printf("请输入您要删除的节点的num\n");scanf("%d",&num);double_link_delete_num(&head,num);double_link_print(head);}
相关文章:
链表基础知识详解(非常详细简单易懂)
概述: 链表作为 C 语言中一种基础的数据结构,在平时写程序的时候用的并不多,但在操作系统里面使用的非常多。不管是RTOS还是Linux等使用非常广泛,所以必须要搞懂链表,链表分为单向链表和双向链表,单向链表很…...
SAP PP学习笔记05 - BOM配置(Customize)1 - 修正参数
上次学习了BOM相关的内容。 SAP PP学习笔记04 - BOM1 - BOM创建,用途,形式,默认值,群组BOM等_sap销售bom与生产bom-CSDN博客 SAP PP学习笔记04 - BOM2 -通过Serial来做简单的BOM变式配置,副明细,BOM状态&…...
前端从普通登录到单点登录(SSO)
随着前端登录场景的日益复杂化和技术思想的不断演进,前端在登录方面的知识结构变得越来越复杂。对于前端开发者来说,在日常工作中根据不同的登录场景提供合适的解决方案是我们的职责所在,本文将梳理前端登录的演变过程。 1、无状态的HTTP H…...
)
考研总计划(基础篇)
分为数学,专业课,英语三个部分 数学规划表 高数基础:3月初到4月15号 具体实行计划:分为看课日和写题日 看课日:早上10点到12点半看课,19:30到21:30继续看课。 写题日:早上10点到12点半复习前一天的题目࿰…...

力扣周赛387
第一题 代码 package Competition.The387Competitioin;public class Demo1 {public static void main(String[] args) {}public int[] resultArray(int[] nums) {int ans[]new int[nums.length];int arr1[]new int[nums.length];int arr2[]new int[nums.length];if(nums.leng…...
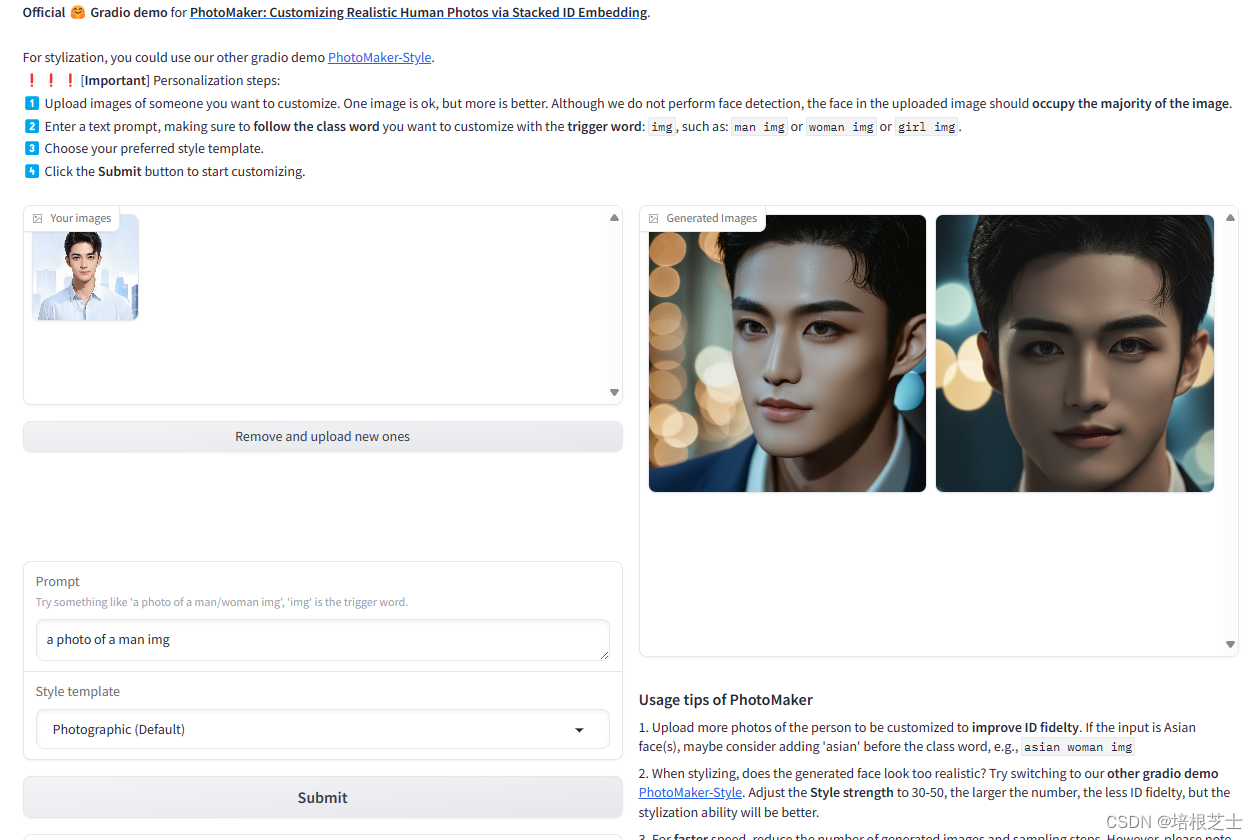
部署PhotoMaker通过堆叠 ID 嵌入自定义逼真的人物照片
PhotoMaker只需要一张人脸照片就可以生成不同风格的人物照片,可以快速出图,无需额外的LoRA培训。 安装环境 python 3.10gitVisual Studio 2022 安装依赖库 git clone https://github.com/bmaltais/PhotoMaker.git cd PhotoMaker python -m venv venv…...
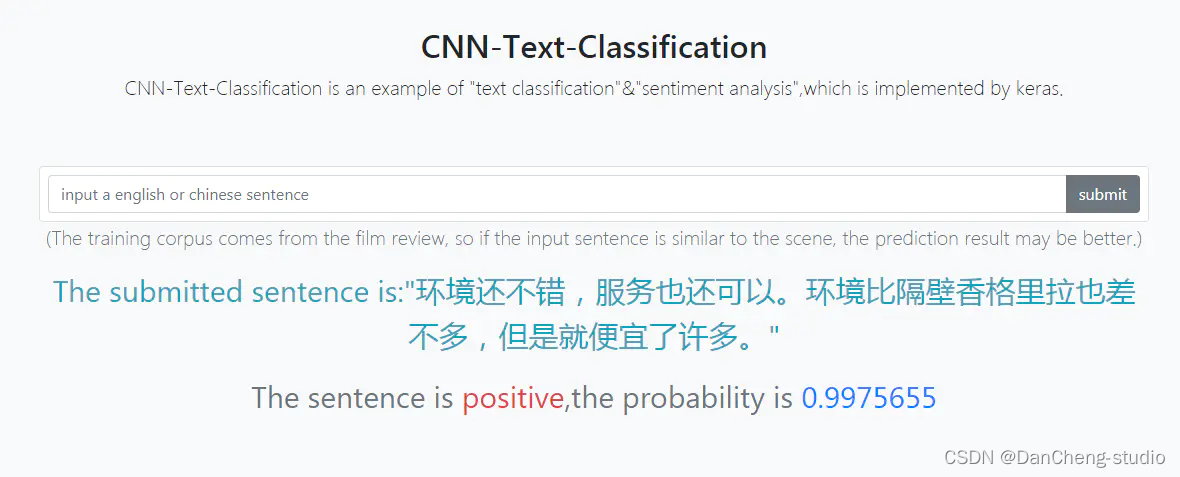
挑战杯 基于深度学习的中文情感分类 - 卷积神经网络 情感分类 情感分析 情感识别 评论情感分类
文章目录 1 前言2 情感文本分类2.1 参考论文2.2 输入层2.3 第一层卷积层:2.4 池化层:2.5 全连接softmax层:2.6 训练方案 3 实现3.1 sentence部分3.2 filters部分3.3 featuremaps部分3.4 1max部分3.5 concat1max部分3.6 关键代码 4 实现效果4.…...

关于RSA公私钥加密报错Data must not be longer than 117 bytes问题解决办法
一、问题描述 1.背景 大家都知道,在日常项目开发过程中,数据的传输安全一直都是值得重视的问题,当然了市面上解决此类办法的技术也有很多,本项目在提供给第三方使用是数据以及校验第三方传递的参数,采用常用的RSA公私…...
【云原生】kubeadm快速搭建K8s集群Kubernetes1.19.0
目录 一、 Kubernetes 的概述 二、服务器配置 2.1 服务器部署规划 2.2服务器初始化配置 三、安装Docker/kubeadm/kubelet【所有节点】 3.1 安装Docker 3.2 添加阿里云YUM软件源 3.3 安装kubeadm,kubelet和kubectl 四、部署Kubernetes Master 五、部署Kube…...

Android 开发环境搭建的步骤
本文将为您详细讲解 Android 开发环境搭建的步骤。搭建 Android 开发环境需要准备一些软件和工具,以下是一些基础步骤: 1. 安装 Java Development Kit (JDK) 首先,您需要安装 Java Development Kit (JDK)。JDK 是 Android 开发的基础…...
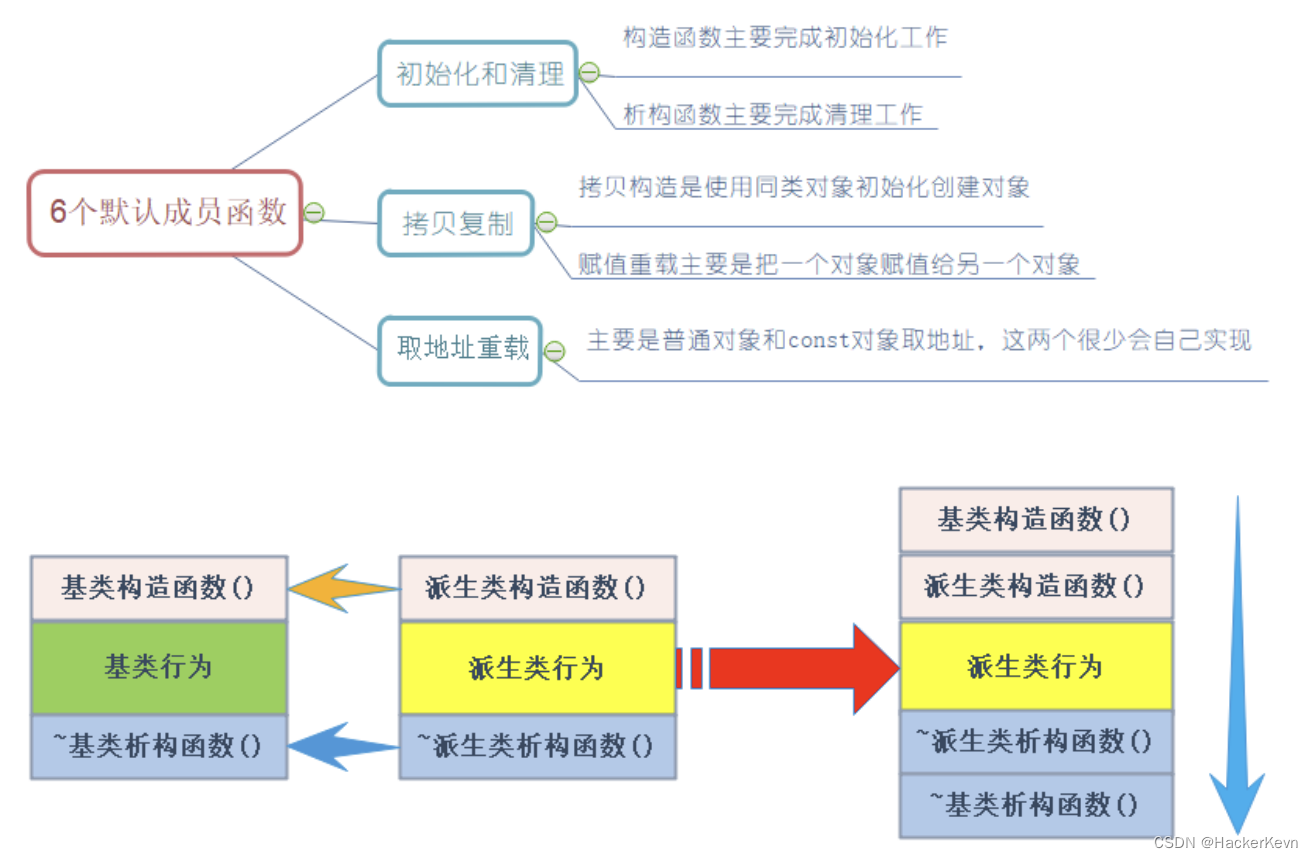
六、继承(一)
1 继承的引入 以往我们想分别实现描述学生、老师的类,可能会这样子做: class Student {string _name;string _number;int _tel;int id;string _address;int _age; }; class Teacher {string _name;int _level;int _tel;int id;string _address;int _ag…...
数字化转型导师鹏:政府数字化转型政务服务类案例研究
政府数字化转型政务服务类案例研究 课程背景: 很多地方政府存在以下问题: 不清楚标杆省政府数字化转型的政务服务类成功案例 不清楚地级市政府数字化转型的政务服务类成功案例 不清楚县区级政府数字化转型的政务服务类成功案例 课程特色&#x…...
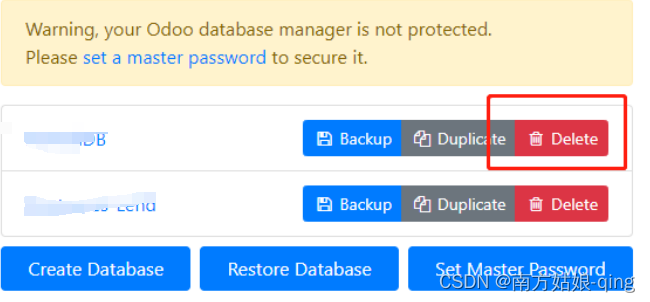
解决ODOO12 恢复数据库提示内存不够报错
1. 现象 点击 ‘restore database’ 控制台报错: 2. 解决措施 a. 进入启动脚本的文件夹 cd odoo/odoo-12.0/输入命令 ./odoo-bin --addons-pathaddons --databaseodoo --db_userodoo --db_passwordodoo --db_hostlocalhost --db_port5432 -i INITb. 刷新页面…...
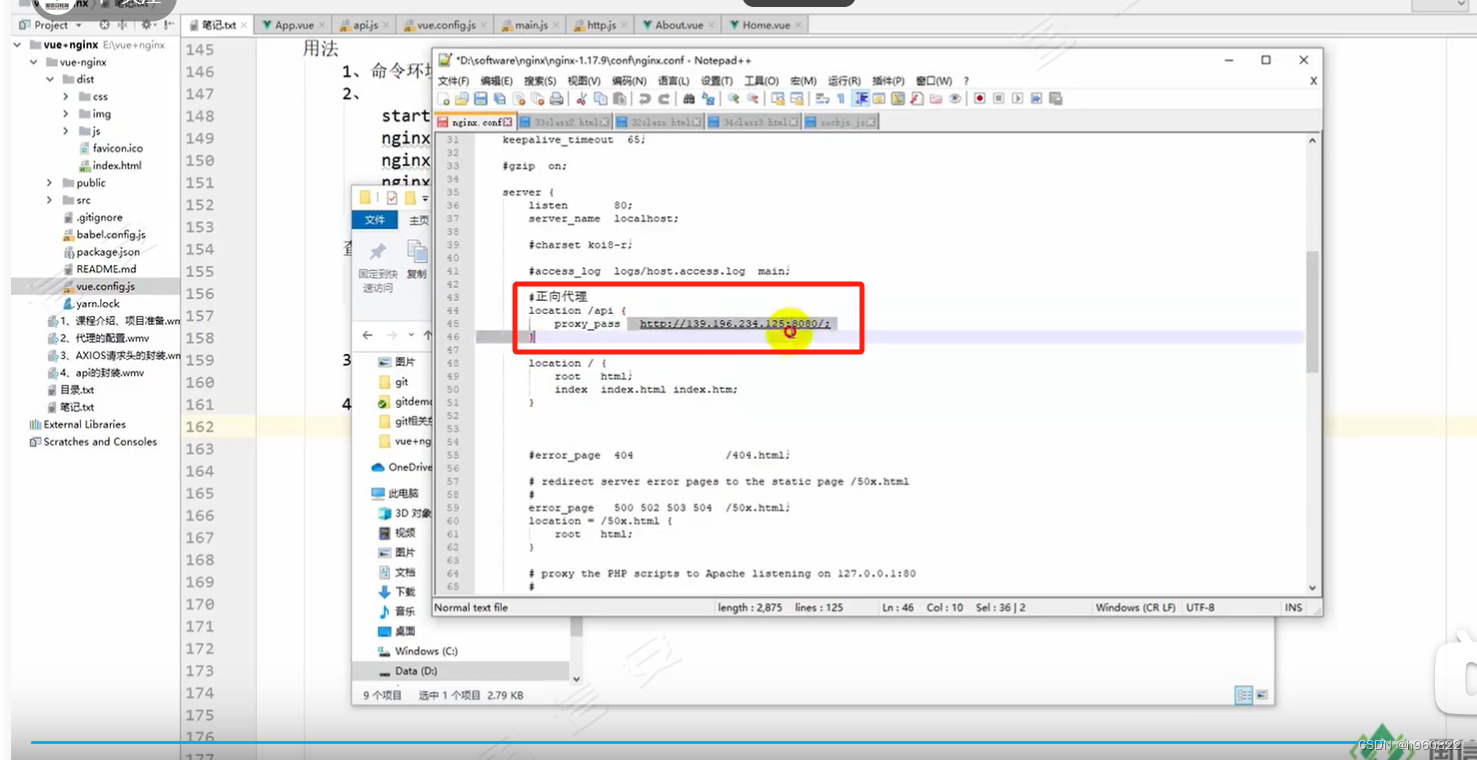
关于数据提交上传服务端的数据类型以及项目打包上线的流程
1 请求头的类型: content-type; 01: application/json 数据以json格式请求:{"key":"value"} 02: application/x-www.form-urlencoded from表单的数据格式 name"zs"&age12 03 mutipart/form-data…...

儿童悬吊训练系统:改善脑性麻痹儿童平衡感与运动能力的有效途径
脑性麻痹(CP)是一种运动障碍,常常由于早期的运动皮层损伤而引起。这种损伤可能导致姿势、操纵技能和行走能力的差异。平衡控制不良是 CP 患儿面临的一项主要挑战,它可能导致动作控制异常以及步态问题,从而影响日常活动…...
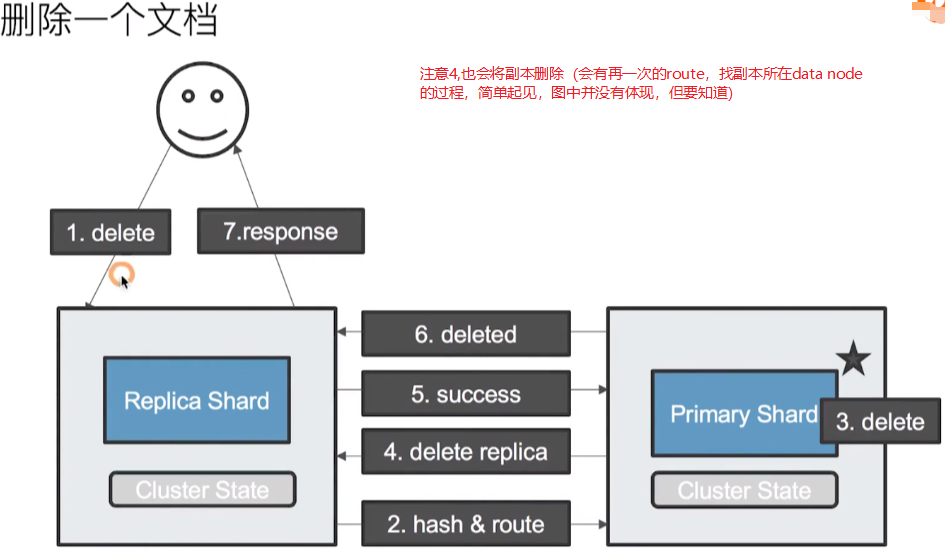
ElasticSearch之文档的存储
写在前面 本文看下文档的存储相关内容。 1:如何确定文档存储在哪个分片? 我们需要确保文档均匀分布在所有的分片中,避免某些部分机器空闲,部分机器繁忙的情况出现,想要实现均匀分布我们可以考虑如下的几种分片路由算…...

在Redhat 7 Linux上安装llama.cpp [ 错误stdatomic.h: No such file or directory]
前期准备 在github上下载llama.cpp或克隆。 GitHub - ggerganov/llama.cpp: LLM inference in C/C git clone https://github.com/ggerganov/llama.cpp.gitcd llama.cpp 执行make命令编译llama.cpp make 在huggingface里下载量化了的 gguf格式的llama2模型。 https:/…...

linux 常用 命令行HTTP客户端
在Linux环境中,命令行HTTP客户端是一种用于发送HTTP请求的工具,它们通常用于测试网站、服务器或API的响应。这些客户端支持各种HTTP方法,如GET、POST、PUT、DELETE等,并允许用户设置请求头、发送数据等。以下是一些常用的命令行HT…...

深入理解@Param注解:用于参数映射的利器
摘要:Param注解在Java开发中被广泛应用,它可以优雅地解决方法参数与SQL语句中占位符的映射问题,提高代码的可读性和可维护性。本文将深入探讨Param注解的背景、使用方法、解决的问题、映射原理,并对使用与不使用Param注解的情况进…...

OCP Secure boot必要特性
三点必需要求: The platform components must: 1. Provide a mechanism for securely anchoring a root of trust public key. // 提供一种用于安全地锚定信任根公钥的机制。 2. Verify the device firmware digital signature using the anchored public key /…...
)
别再让‘自己’说话了:用ZEGO SDK搞定RTC通话中的回声消除(附实战避坑清单)
从工单到解决方案:ZEGO SDK回声消除实战指南 1. 回声问题排查:从用户反馈到技术定位 "为什么每次通话对方都能听到自己的声音?"——这是开发者后台最常见的一类工单。不同于理论探讨,真实场景中的回声问题往往伴随着模糊…...

联发科MT6833与MT6853 5G核心板:规格对比与产品选型实战指南
1. 项目概述:两款5G安卓核心板的定位与价值在当前的移动设备开发领域,尤其是面向中高端市场的智能手机、平板电脑以及各类智能终端,选择一颗性能强劲、功能集成度高且成本可控的核心处理器平台,是决定产品成败的关键。联发科&…...

18分钟攻破GitHub:TeamPCP供应链攻击全技术解析与防御新范式
摘要 2026年5月18日,威胁组织TeamPCP通过一条精心设计的多级供应链攻击链,仅用18分钟就成功入侵全球最大代码托管平台GitHub的内部系统,窃取了约3800个核心私有仓库,涵盖Copilot、CodeQL、GitHub Actions等所有关键产品的源代码。…...

工厂MES数据自动采集怎样用AI完成?资深架构师的非侵入式集成落地指南
摘要: 我是架构师老王。在2026年工业数字化转型的深水区,工厂MES数据自动采集已不再是简单的“连线接口”,而是演变为一场关于“感知、决策与执行”的架构革命。面对老旧系统API缺失、烟囱式架构林立以及信创环境下严苛的安全合规要求&#x…...

选型必读丨高温定向传感器采购与使用的真实成本分析
在定向钻井设备采购决策中,价格往往不是唯一的考量因素。很多用户关注的是高温定向传感器的全生命周期总成本(TCO, Total Cost of Ownership)以及最终能带来怎样的投资回报(ROI)。本文将从专业角度,系统分析…...

5大核心功能+3个实战技巧:ESP32原生USB开发的全面指南
5大核心功能3个实战技巧:ESP32原生USB开发的全面指南 【免费下载链接】EspTinyUSB ESP32S2 native USB library. Implemented few common classes, like MIDI, CDC, HID or DFU (update). 项目地址: https://gitcode.com/gh_mirrors/es/EspTinyUSB 想让你的E…...

5分钟快速上手gInk:Windows上最轻量级的免费屏幕画笔工具完整指南
5分钟快速上手gInk:Windows上最轻量级的免费屏幕画笔工具完整指南 【免费下载链接】gInk An easy to use on-screen annotation software inspired by Epic Pen. 项目地址: https://gitcode.com/gh_mirrors/gi/gInk gInk是一款专为Windows设计的屏幕画笔工具…...

Wireshark TCP重传与乱序深度分析实战指南
1. 这个pcap文件不是“普通流量”,而是TCP重传与乱序的教科书级现场录像你打开Wireshark,载入wireshark0051.pcap,第一眼看到的不是HTTP请求、DNS查询或TLS握手——而是一连串标红的[TCP Retransmission]、[TCP Out-Of-Order]和[TCP Dup ACK]…...

终极指南:如何用amdgpu_top实时监控AMD显卡性能
终极指南:如何用amdgpu_top实时监控AMD显卡性能 【免费下载链接】amdgpu_top Tool to display AMDGPU usage 项目地址: https://gitcode.com/gh_mirrors/am/amdgpu_top 还在为AMD显卡性能监控而烦恼吗?想要像NVIDIA用户使用nvidia-smi那样轻松掌握…...

监控邮箱/邮箱自动回复/python
主题:QQ邮箱的实时监控和自动回复实现QQ邮箱的实时监控和自动回复思路(代码):1. 获取QQ邮箱授权码只有开启了QQ邮箱的IMAP SMTP服务,才能路径:登录QQ邮箱->设置->账号与安全->开启 IMAP/SMTP服务大…...