C++ 创建并初始化对象
创建并初始化C++对象
当我们创建一个C++对象时,它需要占用一些内存,即使我们写一个完全为空的类,类中没有成员,什么也没有,它至少也要占用一个字节的内存。但是我们类中有很多成员,它们需要存储在某地方,当我们决定开始使用这个对象时,我们会创建一堆变量,对象有一堆变量,我们需要在电脑的某个地方分配内存,这样我们就可以记住这些变量设置的值。
应用程序会将内存主要分为两部分,栈和堆,还有其他部分的内存,比如源代码的区域。
在C++中我们要选择对象要放在哪里,对象是在栈上还是在堆上创建,它们有不同的功能差异。
栈:栈对象有一个自动的生存期,他们的生存期实际上是由它声明的地方的作用域决定的,只要变量超出作用域,也就是说内存被释放了,因为当作用域结束的时候,栈会弹出作用域里面的东西,栈上的任何东西会被释放。
堆:一旦在堆中分配一个对象,实际上你已经在堆上创建了一个对象,它会一直待在那里,直到你做出决定,确定不需要它,想要释放这个对象,那怎末处理这段内存都行。
代码案例:
在栈上创建:
在什么时候在栈上创建对象?
几乎所有的时候,如果你能像这样在栈上创建对象,那就像这样创建对象,因为这是C++中最快的方法,也是可以管控的方法,去初始化对象
某些情况下不能这么做的原因?
1、如果将实例化对象放到main函数的生存期外
void Function(){int a = 2;Entity entity;}一旦到达函数结尾的花括号,这个entity会从内存中被销毁
当我们在main函数中调用Function时,就为这个函数创建了一个栈结构,它包含了我们声明的所有局部变量,其中包括基本类型,也包括我们的类和对象,当函数结束时,栈帧会被销毁,即栈上所有的内存,所有创建的变量都消失了
如果想让括号{}内的实例化对象在作用域之外依然存在,就不能分配到栈上,需要使用堆分配。
2、如果entity的规模太大,可能有太多的entity,可能没有足够的空间在栈上分配,因为栈通常非常小,通常是1M/2M
# include <iostream>
# include <string>
using namespace std;class Entity
{
private:string m_Name; //只有一个成员,是一个字符串
public:Entity() : m_Name("Unknown") {}Entity(const string& name) : m_Name(name) {}const string& GetName() const { return m_Name; }
};int main()
{// 1、在栈上创建Entity entity; // 实际上调用了默认构造函数Entity() : m_Name("Unknown")cout << entity.GetName() << endl;Entity entity1("chen");// 等价于 Entity entity1 = Entity("chen")cout << entity1.GetName() << endl;/*在什么时候在栈上创建对象?几乎所有的时候如果你能像这样在栈上创建对象,那就像这样创建对象,因为这是C++中最快的方法,也是可以管控的方法,去初始化对象某些情况下不能这么做的原因?1、如果将实例化对象放到main函数的生存期外void Function(){int a = 2;Entity entity;}一旦到达这个花括号,这个entity会从内存中被销毁当我们调用Function时,就为这个函数创建了一个栈结构,它包含了我们声明的所有局部变量,其中包括基本类型,也包括我们的类和对象,当函数结束时,栈帧会被销毁,即栈上所有的内存,所有创建的变量都消失了Entity* e;{Entity entity2("cherno");e = &entity2;cout << entity2.GetName() << endl;} 一旦出了{}作用域,就到达了栈端,entity2对象就已经不存在了如果想让括号{}内的实例化对象在作用域之外依然存在,就不能分配到栈上,需要使用堆分配cin.get();return 0;
}在堆上创建:
在堆上创建,首先要做的就是在改变类型,将Entity改成Entity*,通过new关键字,这里最大的区别不是那个类型变成了指针,而是new关键字,new关键字是关键。
Entity* entity = new Entity("cherno");当我们调用new Entity时,会在栈上分配内存,调用构造函数,这个new Entity实际上会返回一个Entity*,它会返回entity在堆上被分配的内存地址。
使用new关键字必须调用delete释放内存
delete + 变量名:delete entity;
性能问题:在堆上分配要比栈花费更长的时间,而且在堆上分配的话,您必须手动释放被分配的内存
# include <iostream>
# include <string>
using namespace std;class Entity
{
private:string m_Name; //只有一个成员,是一个字符串
public:Entity() : m_Name("Unknown") {}Entity(const string& name) : m_Name(name) {}const string& GetName() const { return m_Name; }
};int main()
{// 2、在堆上创建/*在堆上创建,首先要做的就是在改变类型,将Entity改成Entity*,通过new关键字,这里最大的区别不是那个类型变成了指针,而是new关键字,new关键字是关键当我们调用new Entity时,会在栈上分配内存,调用构造函数,这个new Entity实际上会返回一个Entity*,它会返回entity在堆上被分配的内存地址*/Entity* entity = new Entity("cherno");//释放内存//delete 变量名;delete entity;/*性能问题:在堆上分配要比栈花费更长的时间,而且在堆上分配的话,您必须手动释放被分配的内存*/cin.get();return 0;
}创建对象的两种方法,如何选择?
如果对象太大,或者需要显示地控制对象的生存期,那就是用堆创建,其他情况就是用栈创建。
相关文章:

C++ 创建并初始化对象
创建并初始化C对象 当我们创建一个C对象时,它需要占用一些内存,即使我们写一个完全为空的类,类中没有成员,什么也没有,它至少也要占用一个字节的内存。但是我们类中有很多成员,它们需要存储在某地方&#…...
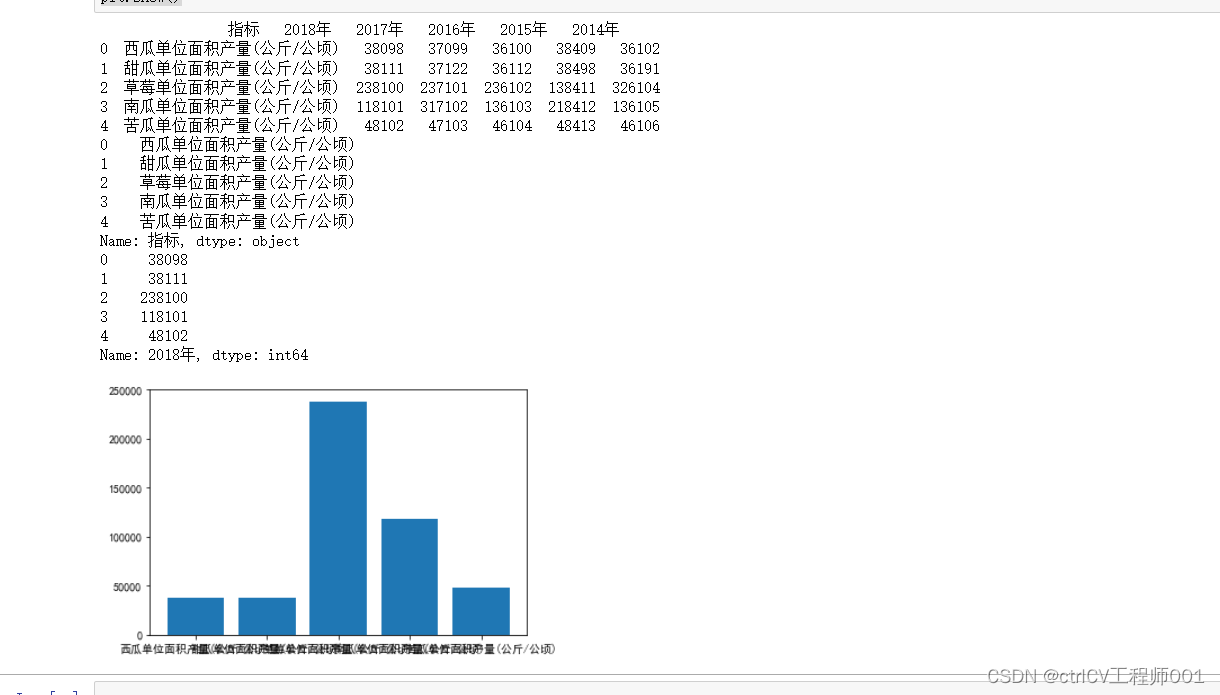
大数据可视化python01
import pandas as pd import matplotlib.pyplot as plt# 设置中文改写字体 plt.rcParams[font.sans-serif] [SimHei]# 读取数据 data pd.read_csv(C:/Users/wzf/Desktop/读取数据进行数据可视化练习/实训作业练习/瓜果类单位面积产量.csv ,encoding utf-8)#输出 print(data)…...

Java底层自学大纲_分布式篇
分布式专题_自学大纲所属类别学习主题建议课时(h)A 分布式锁001 Zookeeper实现分布式锁l-常规实现方式2.5A 分布式锁002 Zookeeper实现分布式锁II-续命&超时&羊群效应问题解决方案2.5A 分布式锁003 Zookeeper实现分布式锁III-基于Curator框架实现…...
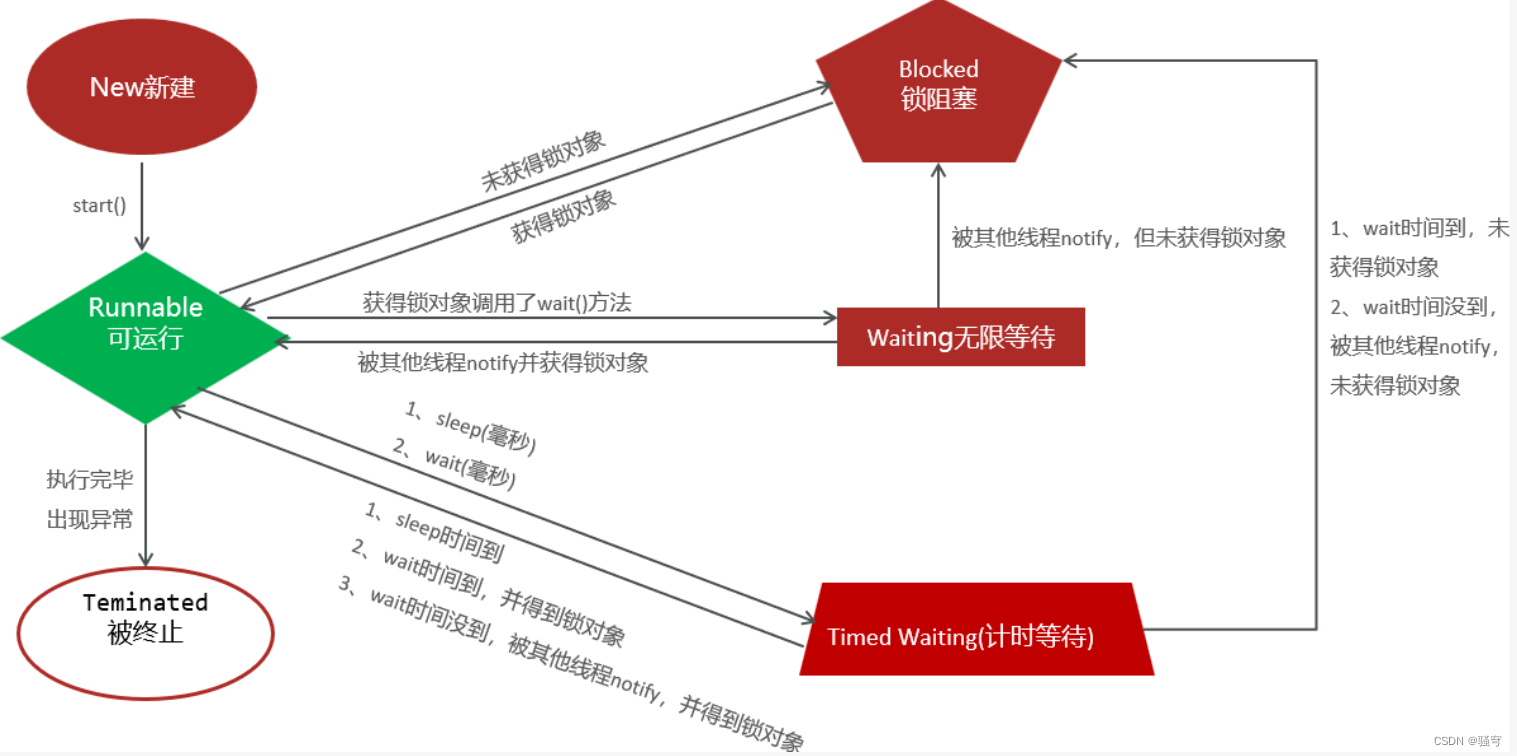
Thread多线程(创建,方法,安全,通信,线程池,并发,并行,线程的生命周期)【全详解】
目录 1.多线程概述 2.多线程的创建 3.Thread的常用方法 4.线程安全 5.线程同步 6.线程通信 7.线程池 8.其它细节知识:并发、并行 9.其它细节知识:线程的生命周期 1.多线程概述 线程是什么? 线程(Thread)是一个程序内部的一条执行…...
自定义View中的ListView和ScrollView嵌套的问题
当我们在使用到ScrollView和ListView的时候可能会出现显示不全的问题。那我们可以进行以下分析 ScrollView在测量子布局的时候会用UNSPECIFIED。通过源码观察, 在ScrollView的onMeasure方法中 Overrideprotected void onMeasure(int widthMeasureSpec, int heightMe…...
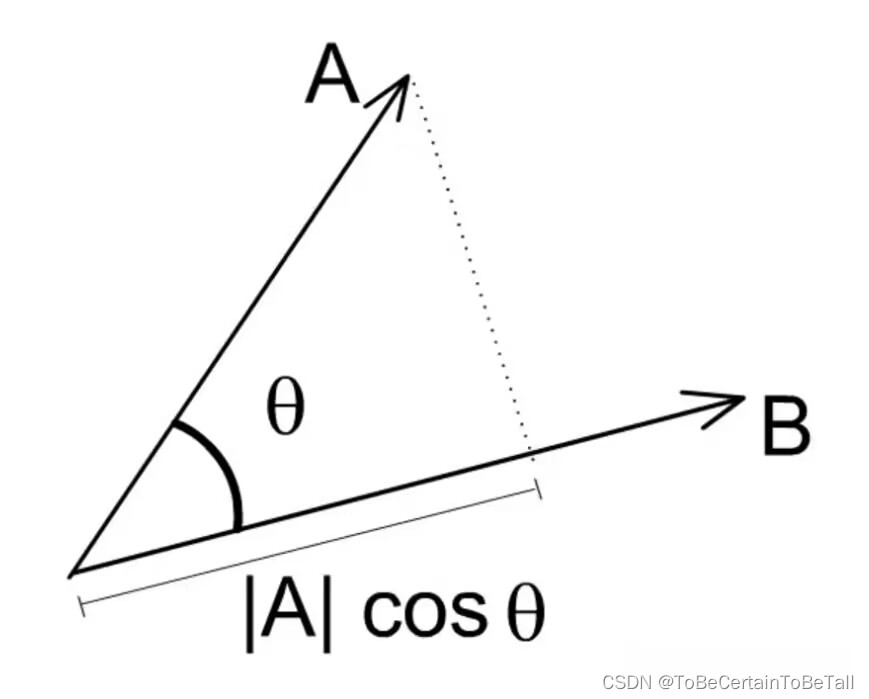
支持向量机 SVM | 线性可分:硬间隔模型公式推导
目录 一. SVM的优越性二. SVM算法推导小节概念 在开始讲述SVM算法之前,我们先来看一段定义: 支持向量机(Support VecorMachine, SVM)本身是一个二元分类算法,支持线性分类和非线性分类的分类应用,同时通过OvR或者OvO的方式可以应用…...
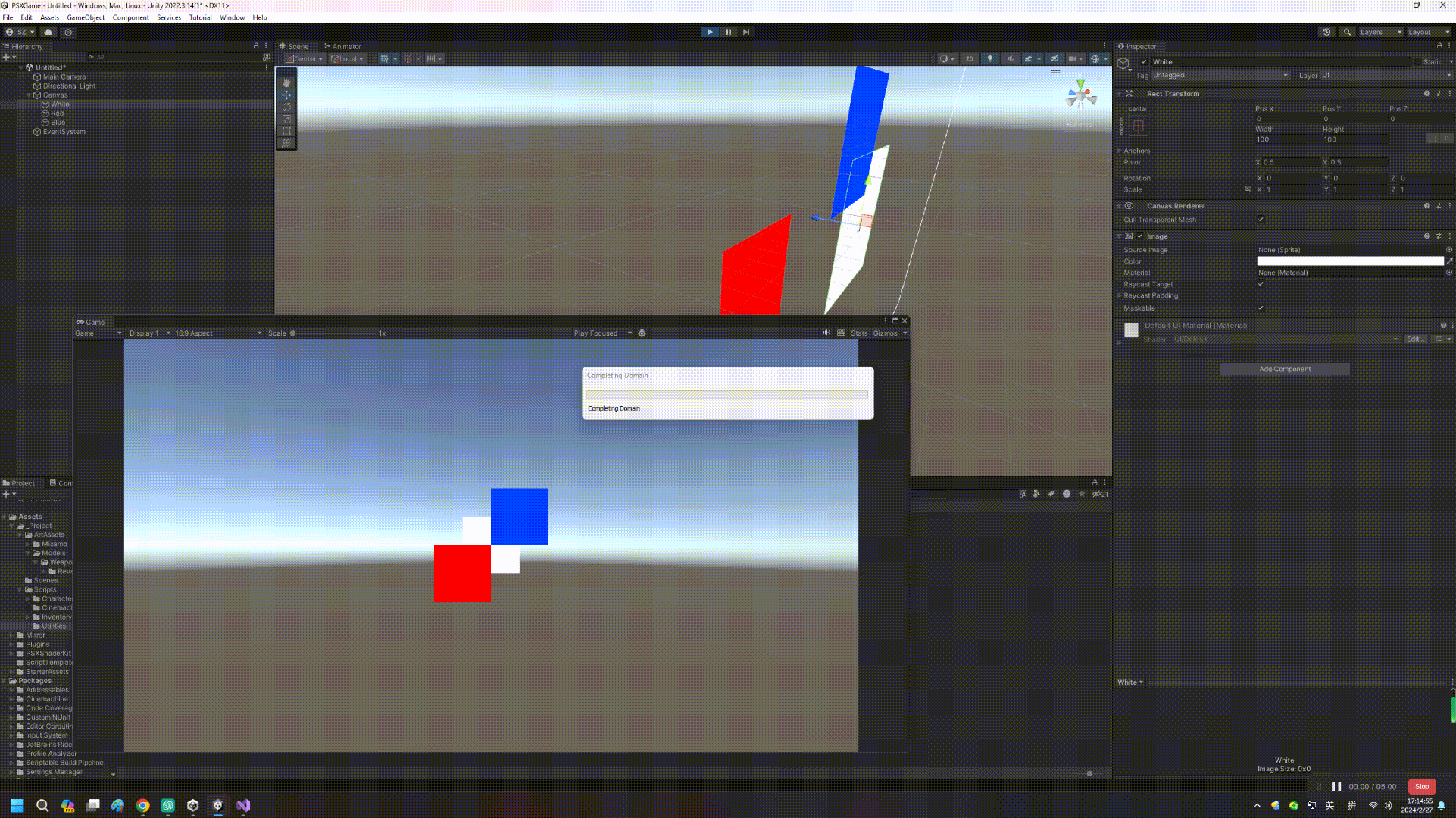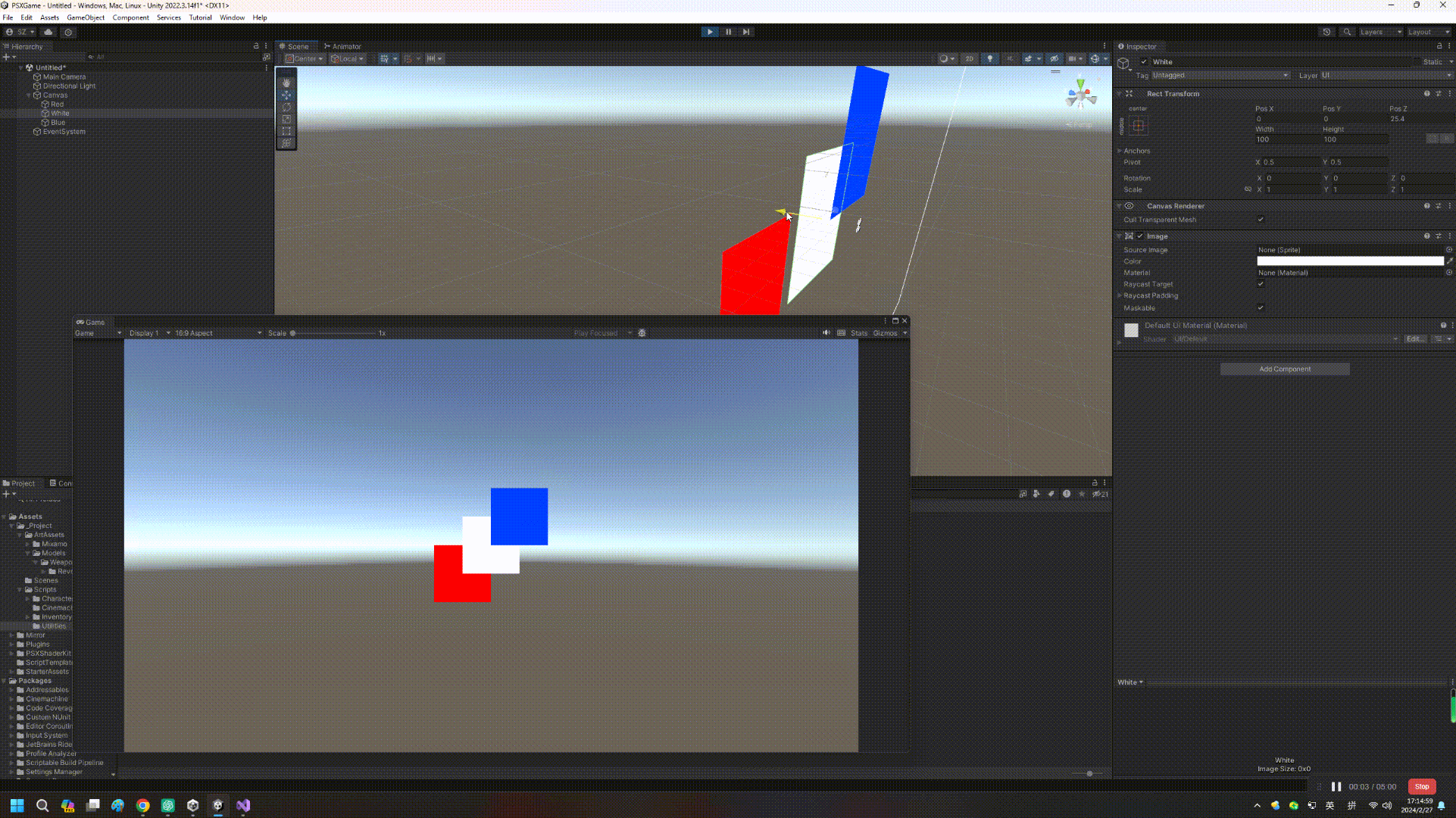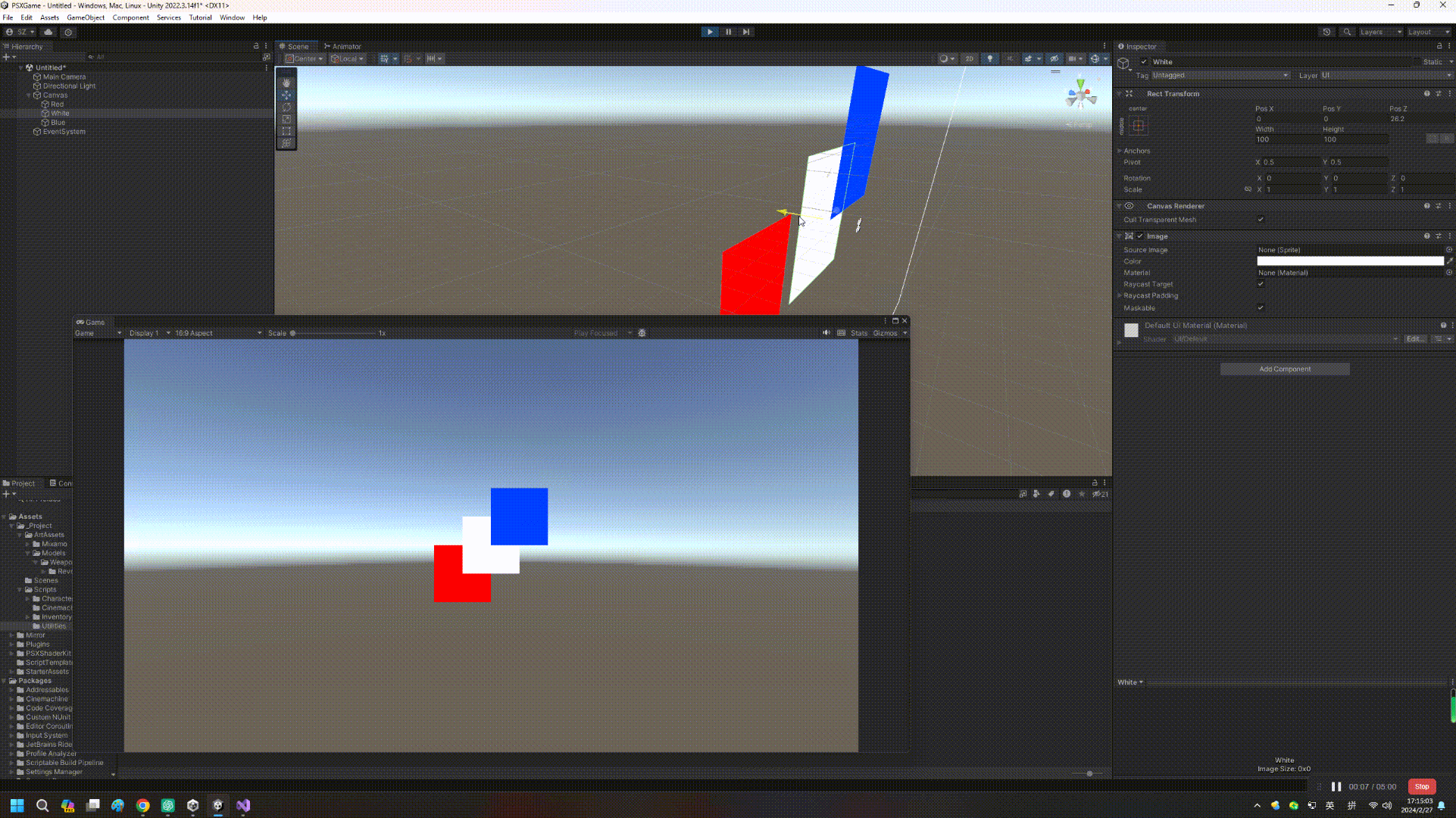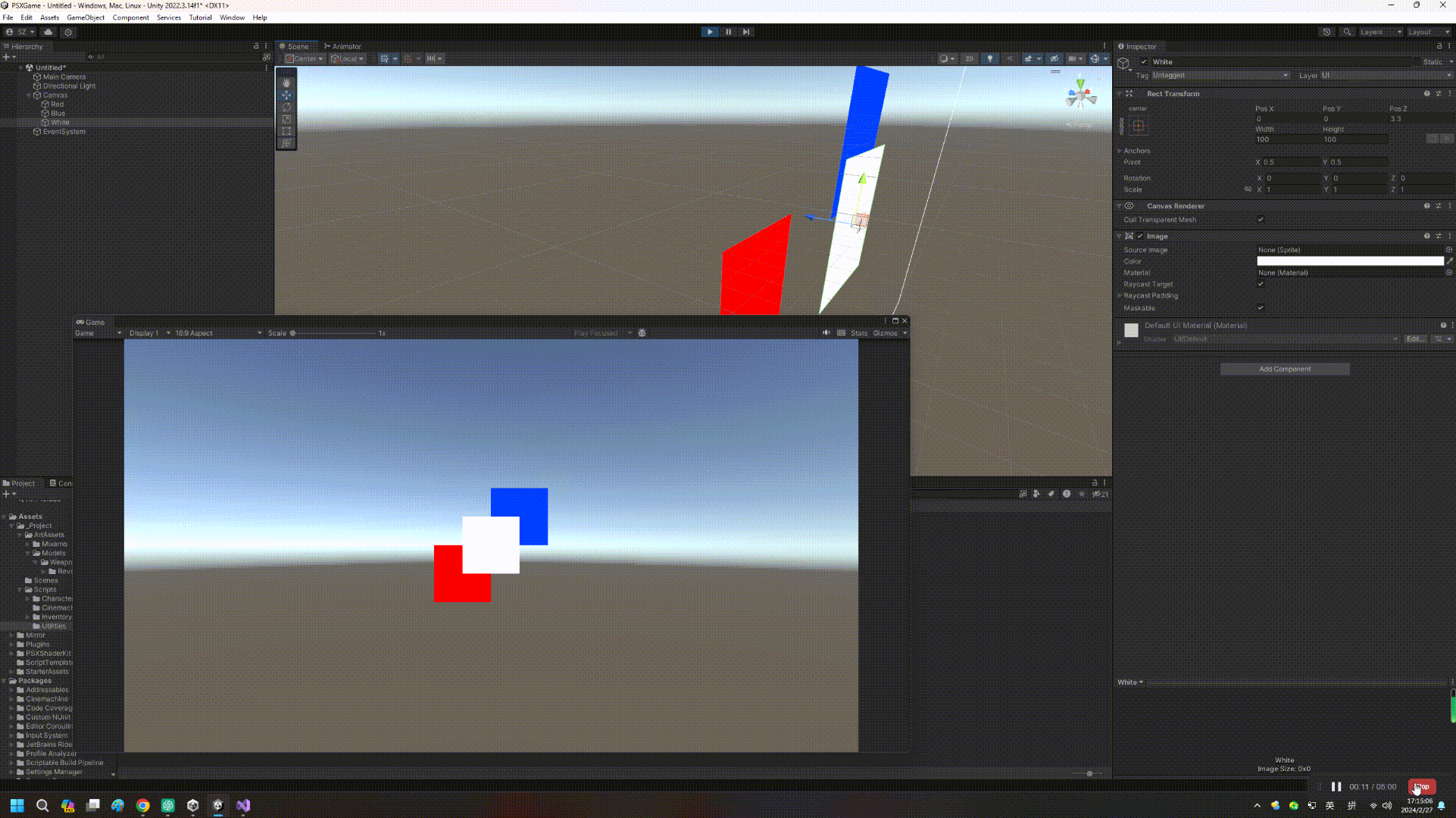
【Unity实战】UGUI和Z轴排序那点事儿
如果读者是从Unity 4.x时代过来的,可能都用过NGUI这个插件(后来也是土匪成了正规军),NGUI一大特点是可以靠transform位移的Z值进行遮挡排序,然而这个事情在UGUI成了难题(Sorting Layer、Inspector顺序等因素…...

Vue/React 前端高频面试
说一说vue钩子函数 钩子函数是Vue实例创建和销毁过程中自动执行的函数。按照组件生命周期的过程分为:挂载阶段 -> 更新阶段 -> 销毁阶段。 每个阶段对应的钩子函数分别为:挂载阶段(beforeCreate,created,befor…...
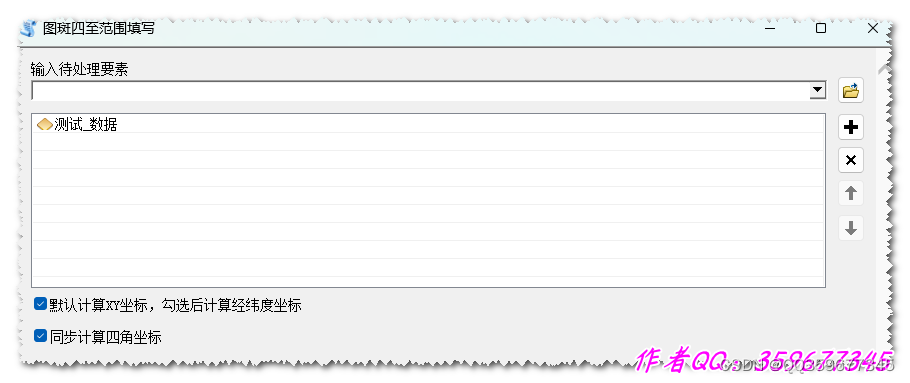
[技巧]Arcgis之图斑四至范围批量计算
ArcGIS图层(点、线、面三类图形)四至范围计算 例外一篇介绍:[技巧]Arcgis之图斑四至点批量计算 说明:如下图画出来的框(范围标记不是很准) ,图斑的x最大和x最小,y最大,…...
C/C++工程师面试题(STL篇)
STL 中有哪些常见的容器 STL 中容器分为顺序容器、关联式容器、容器适配器三种类型,三种类型容器特性分别如下: 1. 顺序容器 容器并非排序的,元素的插入位置同元素的值无关,包含 vector、deque、list vector:动态数组…...

Effective Programming 学习笔记
1 基本语句 1.1 断言 在南溪看来,断言可以用来有效地确定编程中当前代码运行的前置条件,尤其是以下情况: 第三方工具库对输入数据的依赖,例如:minitouch库对Android版本的要求...
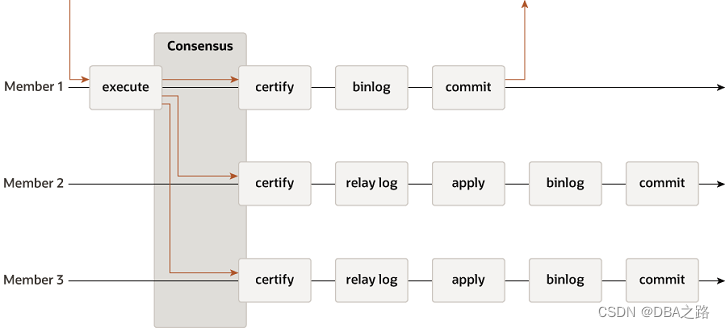
【MGR】MySQL Group Replication 背景
目录 17.1 Group Replication Background 17.1.1 Replication Technologies 17.1.1.1 Primary-Secondary Replication 17.1.1.2 Group Replication 17.1.2 Group Replication Use Cases 17.1.2.1 Examples of Use Case Scenarios 17.1.3 Group Replication Details 17.1…...

300分钟吃透分布式缓存-17讲:如何理解、选择并使用Redis的核心数据类型?
Redis 数据类型 首先,来看一下 Redis 的核心数据类型。Redis 有 8 种核心数据类型,分别是 : & string 字符串类型; & list 列表类型; & set 集合类型; & sorted set 有序集合类型&…...

思科网络设备监控
思科是 IT 行业的先驱之一,提供从交换机到刀片服务器的各种设备,以满足中小企业和企业的各种 IT 管理需求。管理充满思科的 IT 车间涉及许多管理挑战,例如监控可用性和性能、管理配置更改、存档防火墙日志、排除带宽问题等等,这需…...

深入剖析k8s-控制器思想
引言 本文是《深入剖析Kubernetes》学习笔记——《深入剖析Kubernetes》 正文 控制器都遵循K8s的项目中一个通用的编排模式——控制循环 for {实际状态 : 获取集群中对象X的实际状态期望状态 : 获取集群中对象X的期望状态if 实际状态 期望状态 {// do nothing} else {执行…...
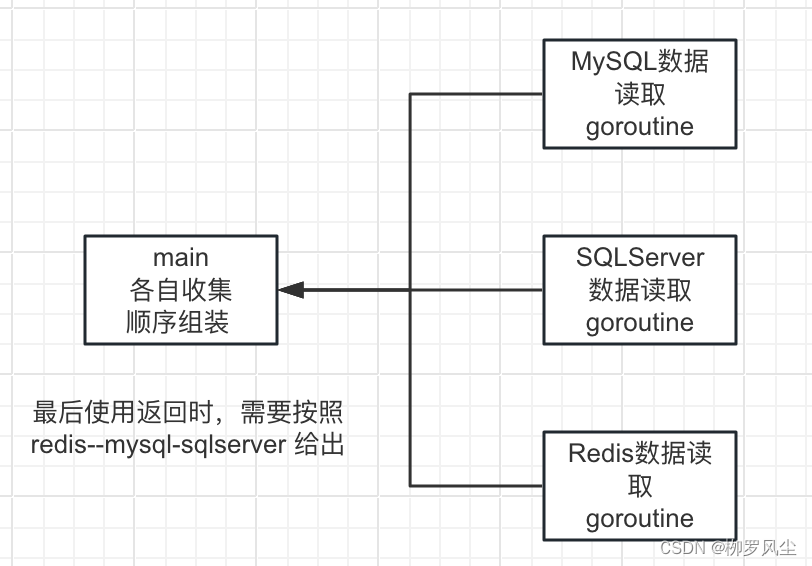
go并发模式之----使用时顺序模式
常见模式之二:使用时顺序模式 定义 顾名思义,起初goroutine不管是怎么个先后顺序,等到要使用的时候,需要按照一定的顺序来,也被称为未来使用模式 使用场景 每个goroutine函数都比较独立,不可通过参数循环…...
[动态规划]---part1
前言 作者:小蜗牛向前冲 专栏:小蜗牛算法之路 专栏介绍:"蜗牛之道,攀登大厂高峰,让我们携手学习算法。在这个专栏中,将涵盖动态规划、贪心算法、回溯等高阶技巧,不定期为你奉上基础数据结构…...
)
java 关于 Object 类中的 wait 和 notify 方法。(生产者和消费者模式!)
4、关于 Object 类中的 wait 和 notify 方法。(生产者和消费者模式!) 第一:wait 和 notify 方法不是线程对象的方法,是 java 中任何一个 java 对象都有的方法,因为这两个方法是 Object 类中自带的。 wait 方…...
YOLOv8姿态估计实战:训练自己的数据集
课程链接:https://edu.csdn.net/course/detail/39355 YOLOv8 基于先前 YOLO 版本的成功,引入了新功能和改进,进一步提升性能和灵活性。YOLOv8 同时支持目标检测和姿态估计任务。 本课程以熊猫姿态估计为例,将手把手地教大家使用C…...
【海贼王的数据航海:利用数据结构成为数据海洋的霸主】链表—双向链表
目录 往期 1 -> 带头双向循环链表(双链表) 1.1 -> 接口声明 1.2 -> 接口实现 1.2.1 -> 双向链表初始化 1.2.2 -> 动态申请一个结点 1.2.3 -> 双向链表销毁 1.2.4 -> 双向链表打印 1.2.5 -> 双向链表判空 1.2.6 -> 双向链表尾插 1.2.7 -&…...

AI工程师必备:三款主流工具的实操落地指南
1. 项目概述:一份真正“够用”的AI资讯简报,到底长什么样?你有没有过这种体验:每天早上打开邮箱,收进十几封AI领域的Newsletter——有的标题写着“深度解析LLM推理优化”,点开发现通篇是论文摘要堆砌&#…...

技术人准备英文面试:除了刷题,这五个表达习惯更关键
许多软件测试工程师在准备英文面试时,往往会陷入一个误区:将大量时间花在背诵专业术语(如“Equivalence Partitioning”、“Regression Testing”),或者在技术问答环节机械地复述测试用例的设计逻辑。诚然,…...

技术人的英语能力如何影响薪资?数据说话
打开任何一个招聘平台,搜索“软件测试工程师”,你会发现一个越来越普遍的现象。对于那些薪资范围宽、技术描述详尽、公司名号响亮的岗位,末尾往往会附上一句:“英语可作为工作语言”、“英文读写能力优异”、“CET-6以上优先”。这…...

解决Arm Compiler 5与6混合编译的链接警告问题
1. 问题现象解析当使用Arm Compiler 5工具链链接包含Arm Compiler 6构建对象文件的项目时,开发者常会遇到如下警告信息:Warning: L6418W: Tagging symbol __tagsym$$used.0 defined in .obj() is not recognized在包含MDK-Middleware组件的项目中&#x…...

抖音视频批量下载终极指南:免费保存无水印内容的最佳方案
抖音视频批量下载终极指南:免费保存无水印内容的最佳方案 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback su…...

为什么92%的团队仍在手写API文档?ChatGPT驱动的智能生成方案已上线,你还在等什么?
更多请点击: https://kaifayun.com 第一章:API文档手写困局的根源与行业现状 在现代微服务与云原生架构普及的背景下,API已成为系统间协作的核心契约。然而,大量团队仍依赖人工编写和维护 OpenAPI(Swagger࿰…...

Unity Stencil属性丢失根因与Property ID注册机制解析
1. 这个报错不是材质丢了,是Unity在“认人”时看错了身份证你在Unity编辑器里猛敲CtrlS保存场景,突然控制台炸出一行红字:Material xxx doesnt have _Stencil property。你第一反应可能是——“我明明在Shader里写了_Stencil,也加…...

Perseus补丁:碧蓝航线全皮肤解锁完整指南与快速配置教程
Perseus补丁:碧蓝航线全皮肤解锁完整指南与快速配置教程 【免费下载链接】Perseus Azur Lane scripts patcher. 项目地址: https://gitcode.com/gh_mirrors/pers/Perseus 还在为碧蓝航线中那些精美皮肤需要付费而烦恼吗?想要免费体验所有舰娘的不…...

使用curl命令直接调试taotoken大模型api接口的详细方法
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用curl命令直接调试Taotoken大模型API接口的详细方法 对于需要在无SDK环境下进行底层调试、自动化脚本编写或快速验证接口的开发…...

分布式/集群/微服务
分布式:将一个系统划分为多个子系统,每个子系统在不同的服务器上运行,并通过网络通信进行协作集群:一组相互独立的计算机系统协同工作,共同提供服务或处理任务,它们之间可以共享资源和负载均衡微服务&#…...