【MySQL】视图、索引
目录
- 视图
- 视图的用途
- 优点
- 视图的缺点
- 创建视图
- 查看视图
- 修改视图
- 删除视图
- 注意事项
- 索引
- 索引的原理
- 索引的数据结构
- 二分查找法
- Hash结构
- Hash冲突!!!
- B树
- 二叉查找树
- 存在问题
- 改造二叉树——B树
- 降低树的高度
- B树特点
- 案例
- 继续优化的方向
- 改造B树——B+树
- 对比
- 案例分析
- 等值查询
- ==范围查询==
- 索引的分类
- 主键索引
- 案例分析
- 辅助索引【普通索引】
- 唯一索引
- 主键索引与唯一索引的区别
- 组合索引
- 组合索引的数据结构
- 组合索引的查询过程
- 组合索引的最左匹配原则
- 覆盖索引
- 执行计划分析
- 覆盖索引
- 未覆盖索引
- SQL优化方向之一——避免回表
- 案例分析
- 联合索引
- 联合索引的创建原则
- 联合索引的使用
- 索引的设计原则
- 索引失效的情况
- 搜集来的SQL优化经验(欢迎补充)
视图
- 视图是一张虚拟表,表示一张表的部分数据或多张表的综合数据。
- 其结构和数据是建立在对表的查询基础上
- 视图中不存放数据,数据存放在视图所引用的原始表中
- 一个原始表,根据不同用户的不同需求,可以创建不同的视图
视图的用途
- 简化复杂查询:通过将复杂的查询逻辑封装到视图中,可以简化应用程序中的查询操作。
- 数据安全性:视图可以限制用户对底层表的访问权限,从而提供更高的数据安全性和隐私保护。
- 数据抽象和封装:通过视图,可以将多个表的数据抽象为一个虚拟表,简化数据模型和应用程序开发。
- 性能优化:视图可以预先计算和存储结果集,以提高查询性能,并避免重复执行复杂查询。
优点
-
数据的抽象和简化:视图是一个虚拟表,它可以根据特定的查询语句从一个或多个表中选择、过滤和计算数据。通过使用视图,可以将复杂的查询逻辑和多表连接操作封装为一个简化的视图查询,提供了更简洁、更易于理解的数据模型。
-
数据安全性:视图可以限制用户对底层表的访问权限。通过给用户授予对视图的访问权限,可以隐藏底层表的结构和敏感数据,只允许用户在特定条件下查看和操作数据。这为数据库提供了更高的安全性和数据保护。
-
逻辑数据分离和模块化:通过视图,可以将数据逻辑分离为不同的模块。这使得数据库的维护和管理更加灵活,可以根据需要对各个模块进行独立的修改和优化,而无需影响其他模块。
-
提高查询性能:视图可以预先计算和存储查询结果,从而提高查询性能。当使用视图进行查询时,MySQL 可以利用预先计算的结果,而不需要重新执行复杂的查询操作。这对于频繁执行相同查询的场景非常有用。
-
简化应用开发:通过将复杂的查询逻辑封装为视图,应用程序开发人员可以更快速、更轻松地构建应用程序。他们只需要简单地查询视图,而无需关心视图背后的复杂查询逻辑和表结构。
视图的缺点
-
性能影响:视图查询可能在执行时产生额外的性能开销。因为视图是根据查询语句动态生成的,每次查询时都需要重新计算视图的结果。对于复杂的视图和大型数据集,这可能导致查询较慢,影响数据库性能。
-
更新限制:默认情况下,MySQL 不允许对包含特定条件的视图进行更新操作。这些条件包括使用聚合函数、DISTINCT、GROUP BY 和 HAVING 等的视图。因此,如果你使用的视图有这些限制条件,你将无法对其进行直接的插入、更新或删除操作。
-
数据一致性:视图查询的结果是根据底层表的数据动态生成的,而不是存储实际的数据副本。这意味着如果底层表的数据发生了变化,但视图查询结果没有及时更新,可能导致数据一致性的问题。
-
限制和复杂性:视图的使用是受到一些限制的,特别是在涉及复杂的查询和多表连接时。一些复杂的查询逻辑和操作可能无法在视图中实现,这可能需要使用其他技术或重新设计查询。
-
管理复杂性:随着数据库中视图的数量增加,管理和维护视图变得更加困难。复杂的视图层次结构和依赖关系可能会导致维护和调试问题的增加
创建视图
CREATE VIEW view_name AS <SELECT 语句>;
#创建方便教师查看成绩的视图
DROP VIEW IF EXISTS `v_result`;
CREATE VIEW v_result
AS
SELECT s.studentno AS sno,studentname AS sname
,studentresult AS score
FROM student AS s
LEFT JOIN
result AS r
ON s.`studentno`=r.`studentno`;
查看视图
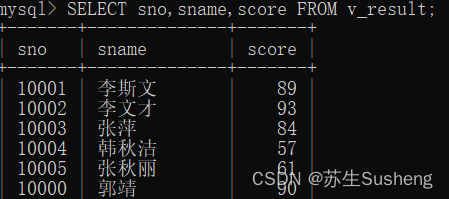
#使用视图
SELECT sno,sname,score FROM v_result;
修改视图
ALTER VIEW view_name AS <SELECT 语句>
删除视图
DROP VIEW IF EXISTS `v_result`;
注意事项
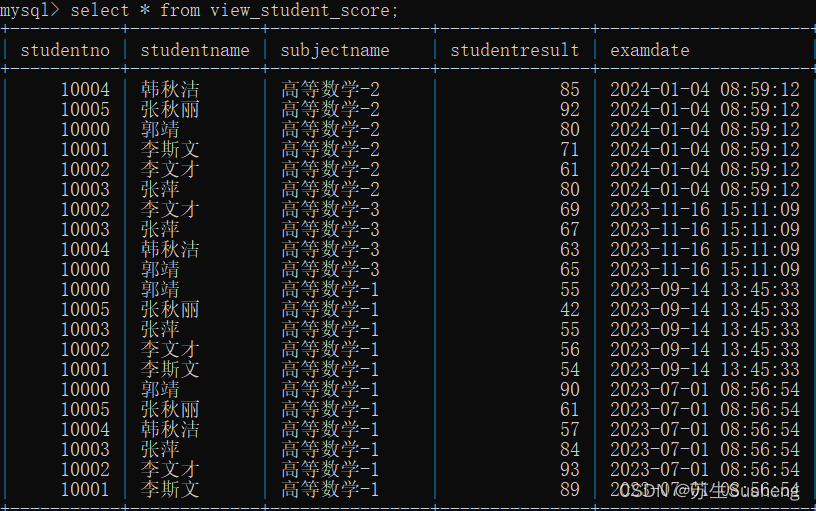
- 视图中可以使用多个表
create view view_student_score as select s.studentno,studentname,subjectname,studentresult,examdate from student s join result r on s.studentno=r.studentno join subject su on r.subjectno=su.subjectno order by examdate desc;create view view_student_grade as select studentno,studentname,gradename from student s join grade g on s.gradeid=g.gradeid;
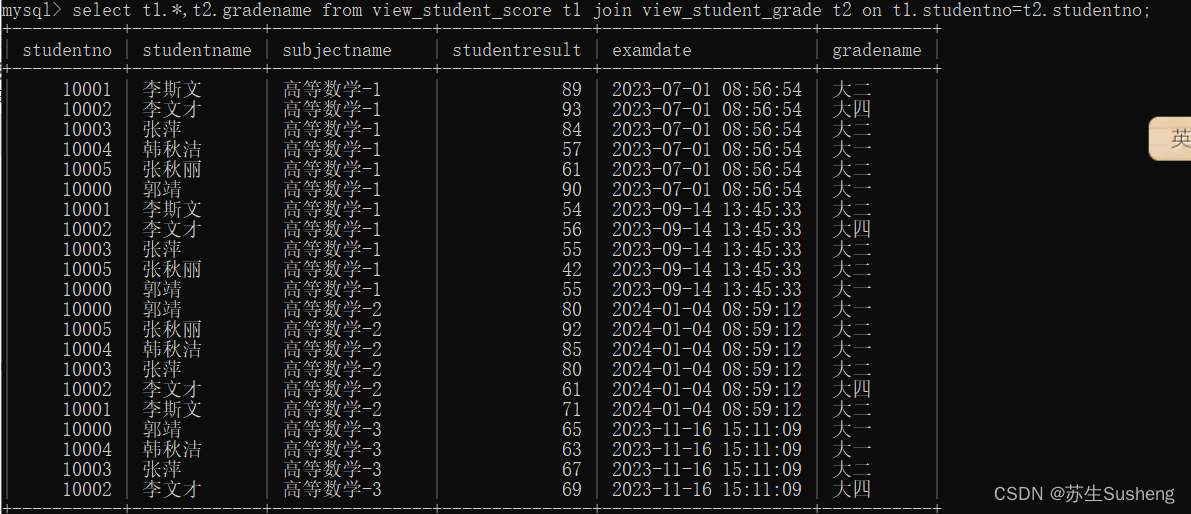
- 一个视图可以嵌套另一个视图
select t1.*,t2.gradename from view_student_score t1 join view_student_grade t2 on t1.studentno=t2.studentno;
- 对视图数据进行添加、更新和删除操作直接影响所引用表中的数据【不建议!!!】
- 当视图数据来自多个表时,不允许添加和删除数据
使用视图修改数据会有许多限制,一般在实际开发中视图仅用作查询
索引
- 举例:汉语字典中的汉字按页存放,一般都有汉语拼音目录(索引)、偏旁部首目录等。我们可以根据拼音或偏旁部首,快速查找某个字词。
- MySQL官方对索引定义:是存储引擎用于快速查找记录的一种数据结构。需要额外开辟空间和数据维护工作。
- 索引底层数据结构存在很多种类型,常见的索引结构有: B 树, B+树 和 Hash、红黑树。在 MySQL 中,无论是 Innodb 还是 MyIsam,都使用了 B+树作为索引结构。
索引的原理
简单来说:以空间换时间。
- 一般来说索引本身也很大,不可能全部存储在内存中,因此索引往往是存储在磁盘上的文件中的(可能存储在单独的索引文件中,也可能和数据一起存储在数据文件中)。
- 数据库在未添加索引进行查询的时候默认是进行全文搜索,也就是说有多少数据就进行多少次查询,然后找到相应的数据就把它们放到结果集中,直到全文扫描完毕。
- 索引是物理数据页存储,在数据文件中(InnoDB,ibd文件),利用数据页(page)存储。
- 索引可以加快检索速度,但是同时也会降低增删改操作速度,索引维护需要代价。
- 索引涉及的理论知识:二分查找法、Hash和B+Tree。
索引的数据结构
二分查找法
二分查找法也叫作折半查找法,它是在有序数组中查找指定数据的搜索算法。它的优点是等值查询、范围查询性能优秀,缺点是更新数据、新增数据、删除数据维护成本高。
- 首先定位left和right两个指针
- 计算(left+right)/2
- 判断除2后索引位置值与目标值的大小比对
- 索引位置值大于目标值就-1,right移动;如果小于目标值就+1,left移动
举个例子,下面的有序数组有17 个值,查找的目标值是7,过程如下:- 第一次查找:
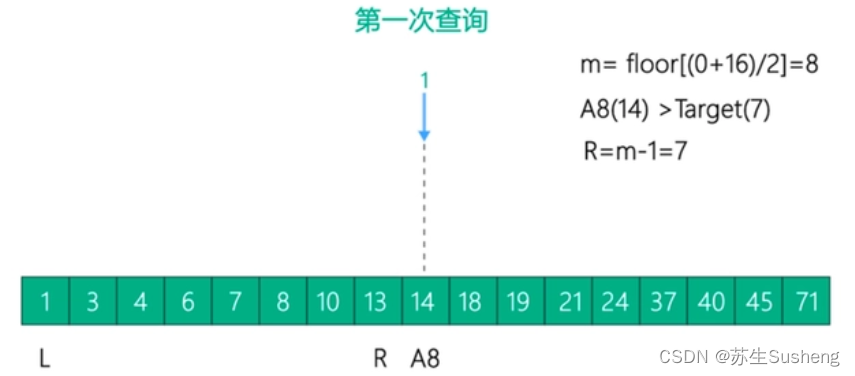
- 第二次查找:
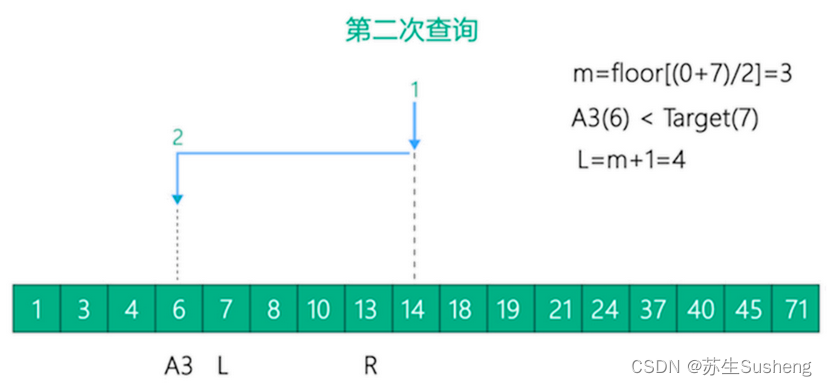
- 第三次查找:…
- 第四次查找:…
- 第一次查找:
Hash结构
- 哈希表是键值对的集合,通过键(key)即可快速取出对应的值(value),因此哈希表可以快速检索数据(接近 O(1))。
- 为何能够通过 key 快速取出 value 呢? 原因在于 哈希算法。通过哈希算法,我们可以快速找到 key 对应的 index,找到了 index 也就找到了对应的 value。
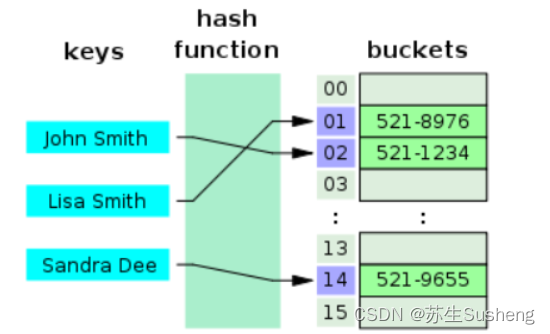
Hash冲突!!!
- 哈希算法有个 Hash 冲突 问题,也就是说多个不同的 key 最后得到的 index 相同。
- 通常情况下,我们常用的解决办法是 链地址法。链地址法就是将哈希冲突数据存放在链表中。
- 就比如 JDK1.8 之前 HashMap 就是通过链地址法来解决哈希冲突的。不过,JDK1.8 以后HashMap为了减少链表过长的时候搜索时间过长引入了红黑树。
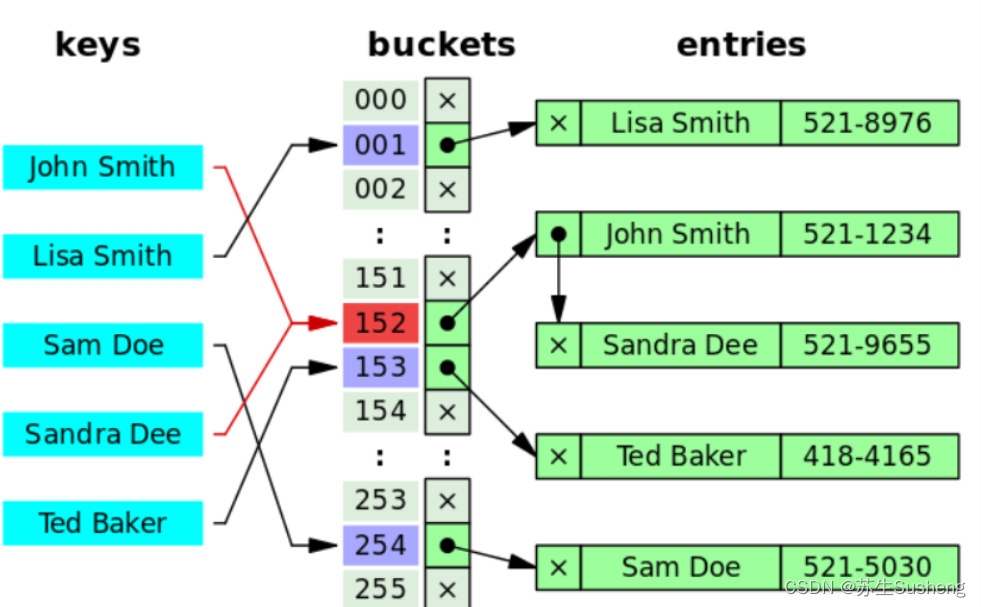
- 为了减少 Hash 冲突的发生,一个好的哈希函数应该“均匀地”将数据分布在整个可能的哈希值集合中。
既然哈希表这么快,为什么 MySQL 没有使用其作为索引的数据结构呢?
- 主要是因为 Hash 索引不支持顺序和范围查询。假如我们要对表中的数据进行排序或者进行范围查询,那 Hash 索引可就不行了。并且,每次 IO 只能取一个
SELECT * FROM tb1 WHERE id < 500;
在这种范围查询中,直接遍历比 500 小的叶子节点就够了。而 Hash 索引是根据 hash 算法来定位的,如果把 1 - 499 的数据,每个都进行一次 hash 计算来定位…
B树
说B树之前先说二叉查找树吧
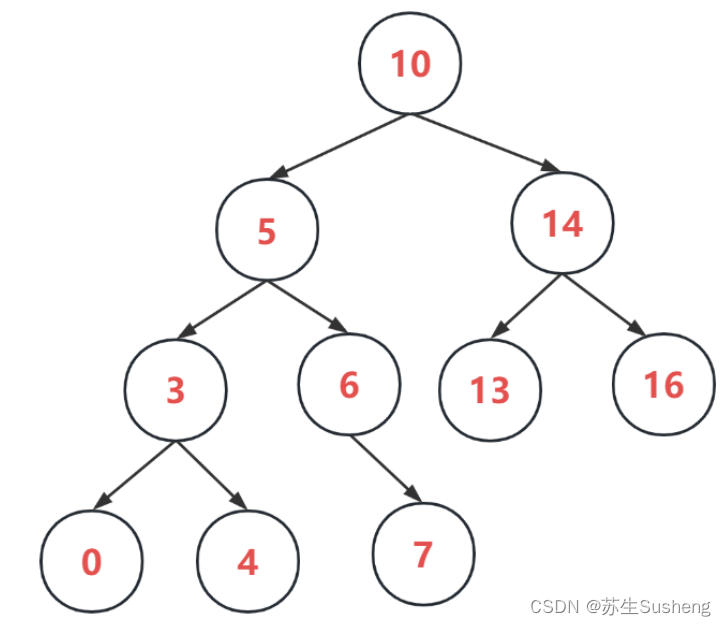
二叉查找树
- 若它的左子树不为空,则左子树上所有节点的值都小于根节点的值
- 若它的右子树不为空,则右子树上所有节点的值都大于根节点的值
- 左右子树也分别为二叉查找树。
存在问题
- 时间复杂度和树高相关。
- 树有多高就需要检索多少次,每个节点的读取,都对应一次磁盘 IO 操作。
- 树的高度就等于每次查询数据时磁盘 IO 操作的次数。
- 磁盘每次寻道时间为10ms,在表数据量大时,查询性能就会很差。(1百万的数据量,log2n约等于20次磁盘IO,时间20*10=0.2s)
- 平衡二叉树不支持范围查询快速查找,范围查询时需要从根节点多次遍历,查询效率不高。
- 当二叉查找树是平衡的时候,也就是树的每个节点的左右子树深度相差不超过 1 的时候,查询的时间复杂度为 O(log2(N)),具有比较高的效率。然而,当二叉查找树不平衡时,例如在最坏情况下(有序插入节点),树会退化成线性链表(也被称为斜树),导致查询效率急剧下降,时间复杂退化为 O(N)
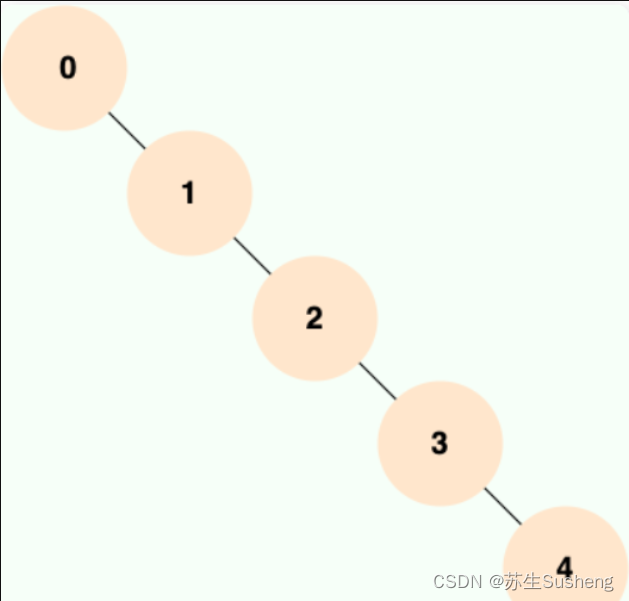
因此二叉查找树不适合作为 MySQL 底层索引的数据结构
改造二叉树——B树
MySQL的数据是存储在磁盘文件中的,查询处理数据时,需要先把磁盘中的数据加载到内存中,磁盘IO 操作非常耗时,所以我们优化的重点就是尽量减少磁盘 IO 操作。访问二叉树的每个节点就会发生一次IO,如果想要减少磁盘IO操作,就需要尽量降低树的高度
降低树的高度
假如key为bigint=8字节,每个节点有两个指针,每个指针为4个字节,一个节点占用的空间16个字节(8+4*2=16)
- 因为在MySQL的InnoDB存储引擎一次IO会读取的一页(默认一页16K)的数据量,而二叉树一次IO有效数据量只有16字节,空间利用率极低。
- 为了最大化利用一次IO空间,一个简单的想法是在每个节点存储多个元素,在每个节点尽可能多的存储数据。
- 每个节点可以存储1000个索引(16k/16=1000),这样就将二叉树改造成了多叉树,通过增加树的叉树,将树从高瘦变为矮胖。
- 构建1百万条数据,树的高度只需要2层就可以(1000*1000=1百万),也就是说只需要2次磁盘IO就可以查询到数据。磁盘IO次数变少了,查询数据的效率也就提高了
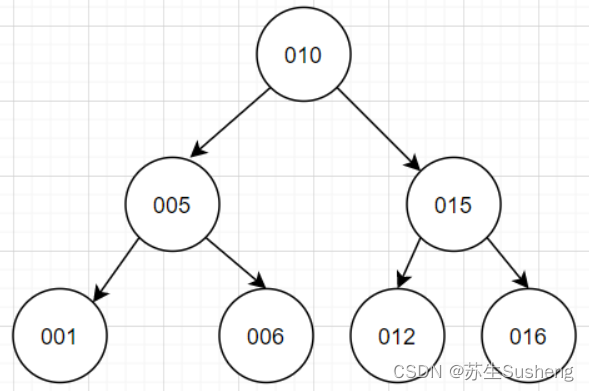
B树特点
- B树的节点中存储着多个元素,每个内节点有多个分叉。
- 节点中的元素包含键值和数据,节点中的键值从大到小排列。也就是说,在所有的节点都储存数据。
- 父节点当中的元素不会出现在子节点中。
- 所有的叶子结点都位于同一层,叶节点具有相同的深度,叶节点之间没有指针连接。
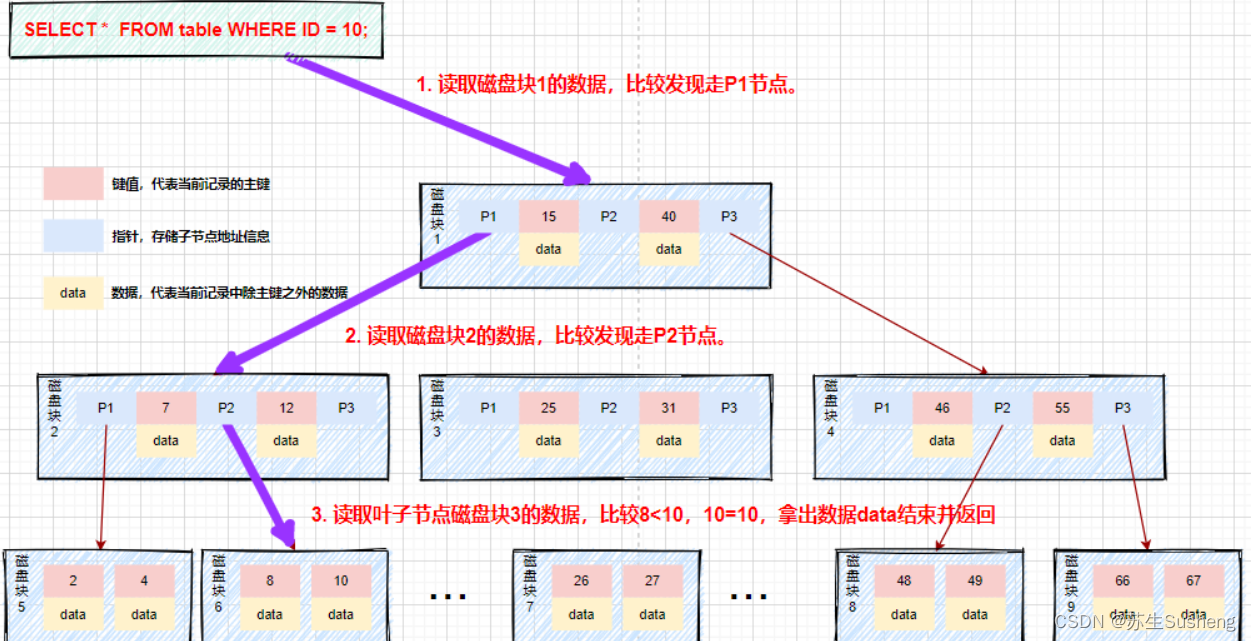
案例
假如我们查询值等于10的数据。查询路径磁盘块1->磁盘块2->磁盘块5。
- 第一次磁盘IO:将磁盘块1加载到内存中,在内存中从头遍历比较,10<15,走左路,到磁盘寻址磁盘块2。
- 第二次磁盘IO:将磁盘块2加载到内存中,在内存中从头遍历比较,7<10,到磁盘中寻址定位到磁盘块5。
- 第三次磁盘IO:将磁盘块5加载到内存中,在内存中从头遍历比较,10=10,找到10,取出data,如果data存储的行记录,取出data,查询结束。如果存储的是磁盘地址,还需要根据磁盘地址到磁盘中取出数据,查询终止。
相比二叉平衡查找树,在整个查找过程中,虽然数据的比较次数并没有明显减少,但是磁盘IO次数会大大减少。同时,由于我们的比较是在内存中进行的,比较的耗时可以忽略不计。B树的高度一般2至3层就能满足大部分的应用场景,所以使用B树构建索引可以很好的提升查询的效率。
继续优化的方向
- B树不支持范围查询的快速查找,你想想这么一个情况如果我们想要查找10和35之间的数据,查找到15之后,需要回到根节点重新遍历查找,需要从根节点进行多次遍历,查询效率有待提高。
- 如果data存储的是行记录,行的大小随着列数的增多,所占空间会变大。这时,一个页中可存储的数据量就会变少,树相应就会变高,磁盘IO次数就会变大。
改造B树——B+树
在B树基础上,MySQL在B树的基础上继续改造,使用B+树构建索引。B+树和B树最主要的区别在于非叶子节点是否存储数据的问题
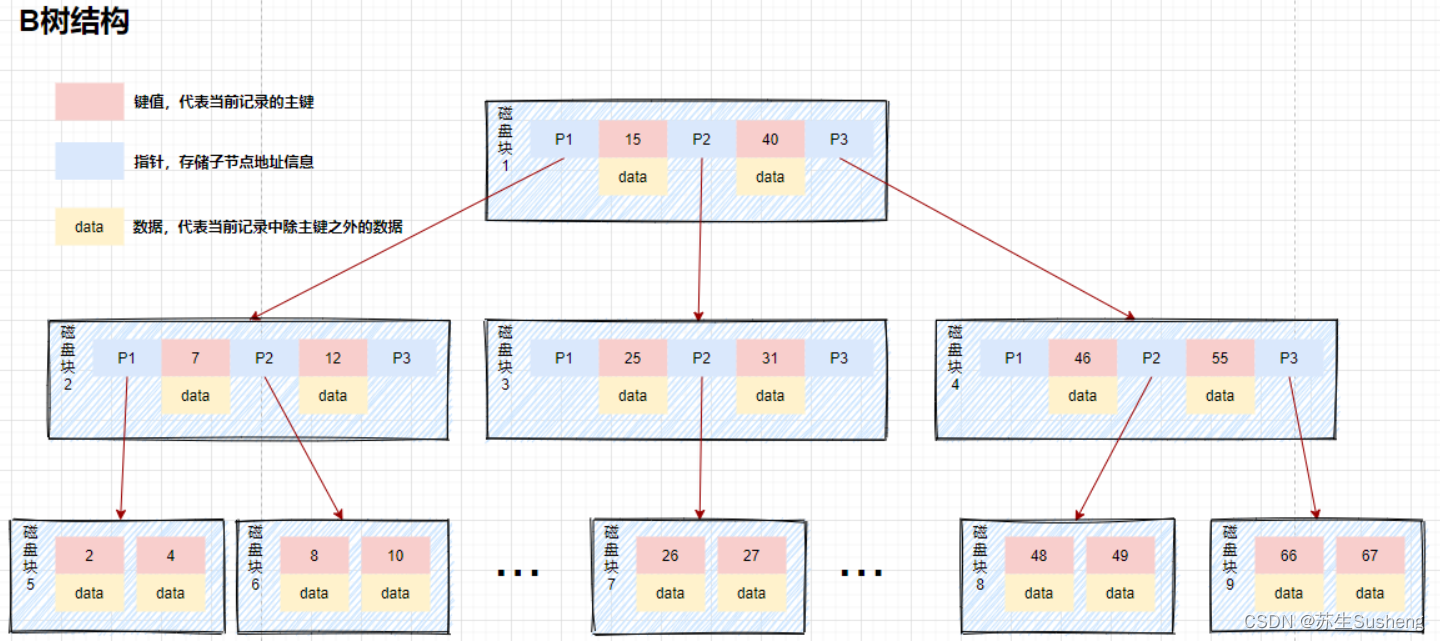
对比
- B树:非叶子节点和叶子节点都会存储数据。
- B+树:只有叶子节点才会存储数据,非叶子节点至存储键值。叶子节点之间使用双向指针连接,最底层的叶子节点形成了一个双向有序链表
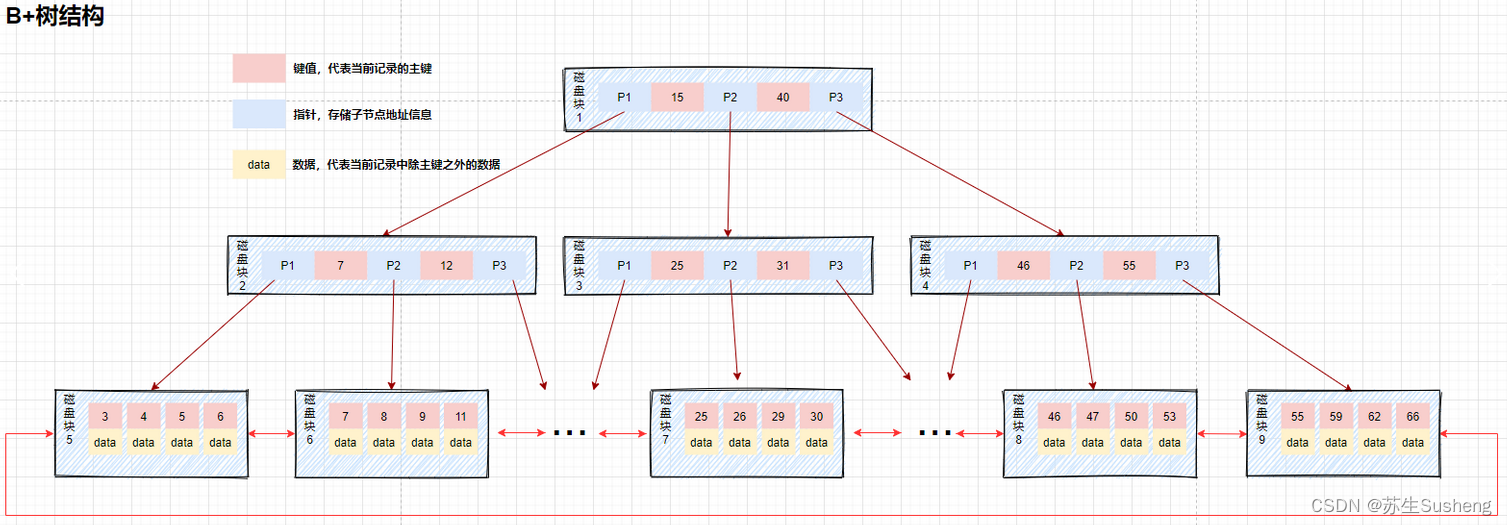
- B+树的最底层叶子节点包含了所有的索引项。从图上可以看到,B+树在查找数据的时候,由于数据都存放在最底层的叶子节点上,所以每次查找都需要检索到叶子节点才能查询到数据。
- 在需要查询数据的情况下每次的磁盘的IO跟树高有直接的关系,但是从另一方面来说,由于数据都被放到了叶子节点,所以放索引的磁盘块锁存放的索引数量是会跟这增加的,所以相对于B树来说,B+树的树高理论上情况下是比B树要矮的。
- 存在索引覆盖查询的情况,在索引中数据满足了当前查询语句所需要的全部数据,此时只需要找到索引即可立刻返回,不需要检索到最底层的叶子节点。
案例分析
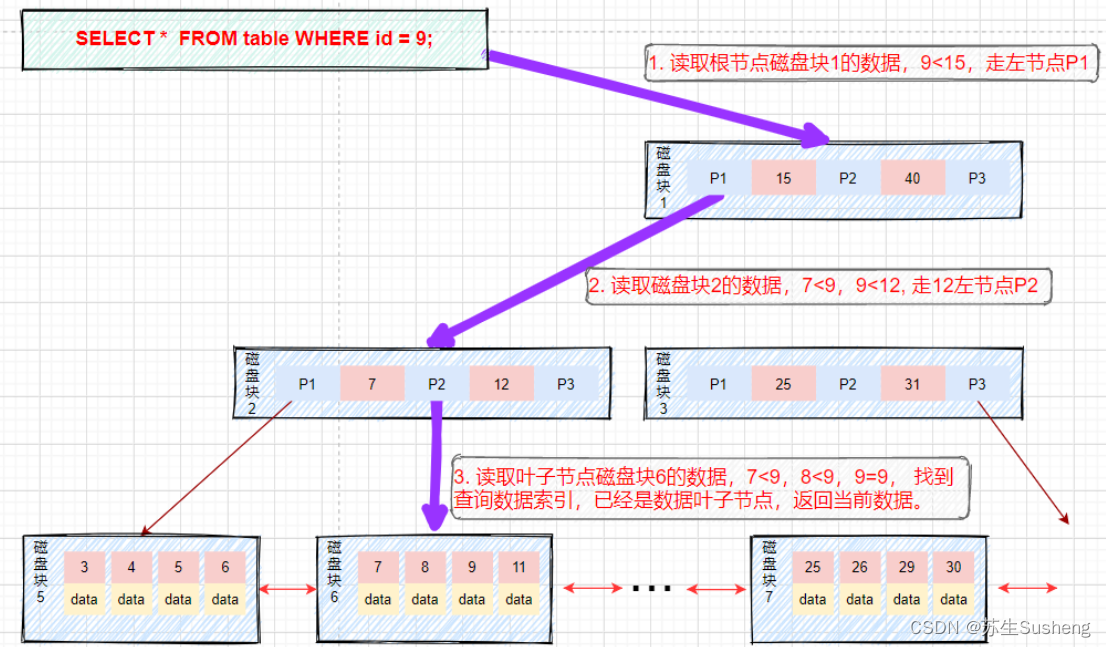
等值查询
假如我们查询值等于9的数据。查询路径磁盘块1->磁盘块2->磁盘块6。
- 第一次磁盘IO:将磁盘块1加载到内存中,在内存中从头遍历比较,9<15,走左路,到磁盘寻址磁盘块2。
- 第二次磁盘IO:将磁盘块2加载到内存中,在内存中从头遍历比较,7<9<12,到磁盘中寻址定位到磁盘块6。
- 第三次磁盘IO:将磁盘块6加载到内存中,在内存中从头遍历比较,在第三个索引中找到9,取出data,如果data存储的行记录,取出data,查询结束。如果存储的是磁盘地址,还需要根据磁盘地址到磁盘中取出数据,查询终止。(这里需要区分的是在InnoDB中Data存储的为行数据,而MyIsam中存储的是磁盘地址。)
范围查询
假如我们想要查找9和26之间的数据。查找路径是磁盘块1->磁盘块2->磁盘块6->磁盘块7。
- 首先查找值等于9的数据,将值等于9的数据缓存到结果集。这一步和前面等值查询流程一样,发生了三次磁盘IO。
- 查找到15之后,底层的叶子节点是一个有序列表,我们从磁盘块6,键值9开始向后遍历筛选所有符合筛选条件的数据。
- 第四次磁盘IO:根据磁盘6后继指针到磁盘中寻址定位到磁盘块7,将磁盘7加载到内存中,在内存中从头遍历比较,9<25<26,9<26<=26,将data缓存到结果集。
- 主键具备唯一性(后面不会有<=26的数据),不需再向后查找,查询终止。将结果集返回给用户

B+树可以保证等值和范围查询的快速查找,MySQL的索引就采用了B+树的数据结构
索引的分类
主键索引、唯一索引、普通索引、全文索引、组合索引、空间索引
主键索引
每个InnoDB表都有一个聚簇索引 ,聚簇索引使用B+树构建,叶子节点存储的数据是整行记录。一般情况下,聚簇索引等同于主键索引,当一个表没有创建主键索引时,InnoDB会自动创建一个ROWID字段来构建聚簇索引。InnoDB创建索引的具体规则如下
- 在表上定义主键PRIMARY KEY,InnoDB将主键索引用作聚簇索引。
- 如果表没有定义主键,InnoDB会选择第一个不为NULL的唯一索引列用作聚簇索引。
- 如果以上两个都没有,InnoDB 会使用一个6 字节长整型的隐式字段 ROWID字段构建聚簇索引。该ROWID字段会在插入新行时自动递增。
除聚簇索引之外的所有索引都称为辅助索引。在中InnoDB,辅助索引中的叶子节点存储的数据是该行的主键值都。 在检索时,InnoDB使用此主键值在聚簇索引中搜索行记录
案例分析
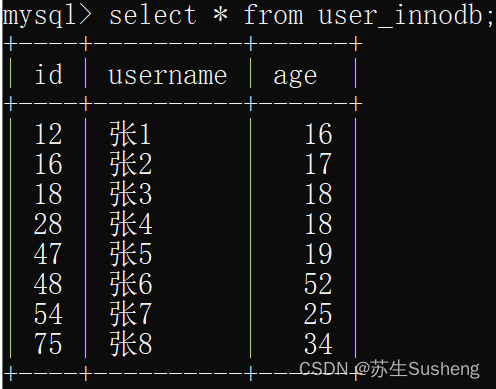
InnoDB的数据和索引存储在一个文件t_user_innodb.ibd中。InnoDB的数据组织方式,是聚簇索引。主键索引的叶子节点会存储数据行,辅助索引只会存储主键值。
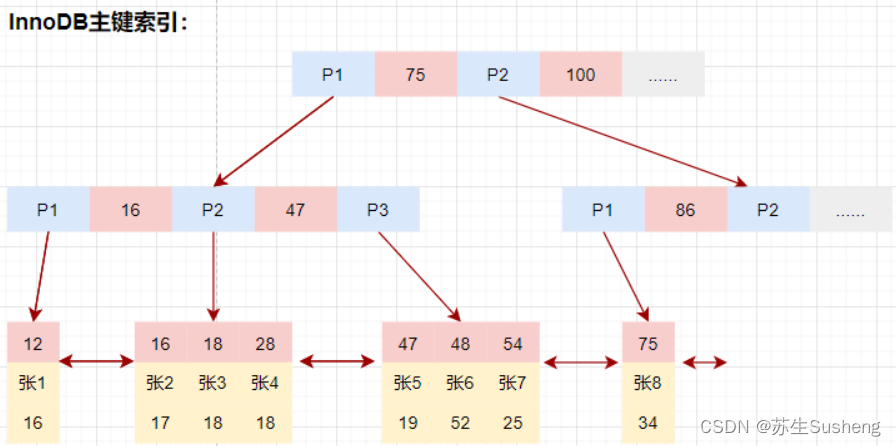
- 等值查询
select * from user_innodb where id = 28;磁盘IO数量:3次。- 先在主键树中从根节点开始检索,将根节点加载到内存,比较28<75,走左路。(1次磁盘IO)
- 将左子树节点加载到内存中,比较16<28<47,向下检索。(1次磁盘IO)
- 检索到叶节点,将节点加载到内存中遍历,比较16<28,18<28,28=28。查找到值等于28的索引项,直接可以获取整行数据。将改记录返回给客户端。(1次磁盘IO)

辅助索引【普通索引】
除聚簇索引之外的所有索引都称为辅助索引,InnoDB的辅助索引只会存储主键值而非磁盘地址。以表user_innodb的age列为例,age索引的索引结果如下
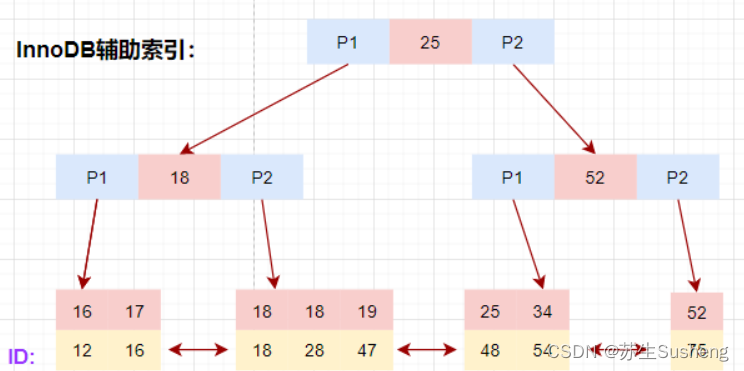
- 底层叶子节点的按照(age,id)的顺序排序,先按照age列从小到大排序,age列相同时按照id列从小到大排序。
- 使用辅助索引需要检索两遍索引:首先检索辅助索引获得主键,然后使用主键到主索引中检索获得记录
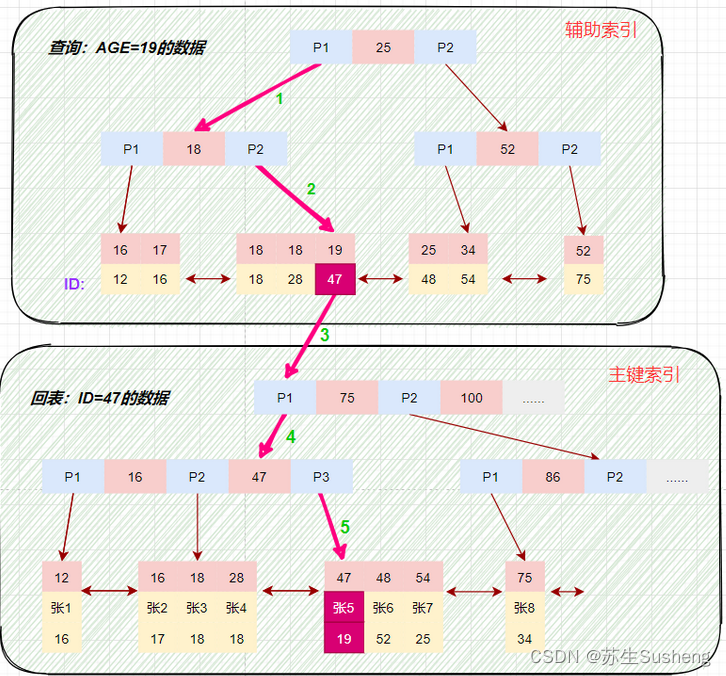
- 等值查询
select * from t_user_innodb where age=19;磁盘IO数:辅助索引3次+获取记录回表3次。根据在辅助索引树中获取的主键id,到主键索引树检索数据的过程称为回表查询。
唯一索引
- 在创建索引时,限制索引的字段值必须是唯一的。通过该类型的索引可以比普通索引更快速地查询某条记录
- 当我们给某给字段定义了唯一约束时,MySQL为了保证唯一性,便会自动给这个字段添加唯一索引,而之后再手动给这个字段添加唯一索引便是一些多余操作
- 唯一索引可以是单列,也可以是多列
- 最大的所用就是确保写入数据库的数据是唯一值。
主键索引与唯一索引的区别
- 唯一性约束所在的列允许空值,但是主键约束所在的列不允许空值。
- 可以把唯一性约束放在一个或者多个列上,这些列或列的组合必须有唯一的。但是,唯一性约束所在的列并不是表的主键列。
- 唯一性约束强制在指定的列上创建一个唯一性索引。在默认情况下,创建唯一性的非聚簇索引,但是,也可以指定所创建的索引是聚簇索引。
- 建立主键的目的是让外键来引用.
- 一个表最多只有一个主键,但可以有很多唯一键
组合索引
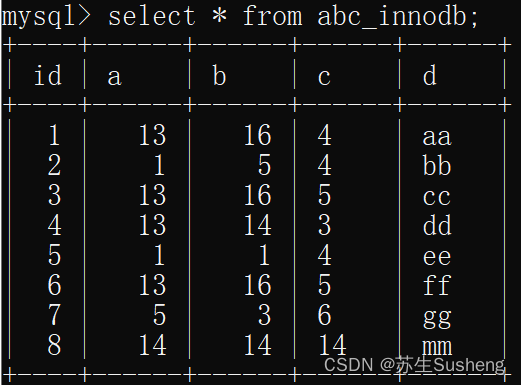
组合索引的数据结构
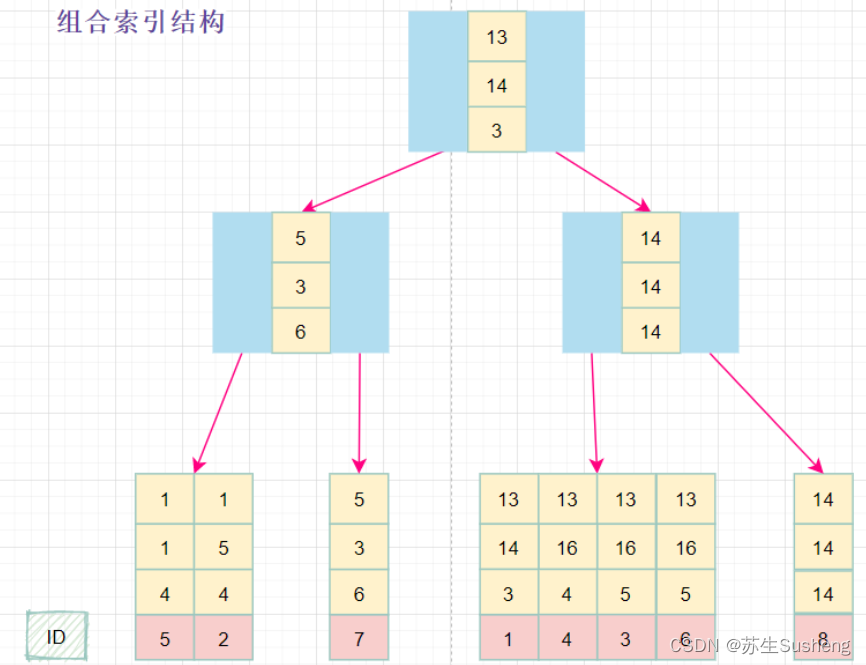
组合索引的查询过程
select * from abc_innodb where a = 13 and b = 16 and c = 4;
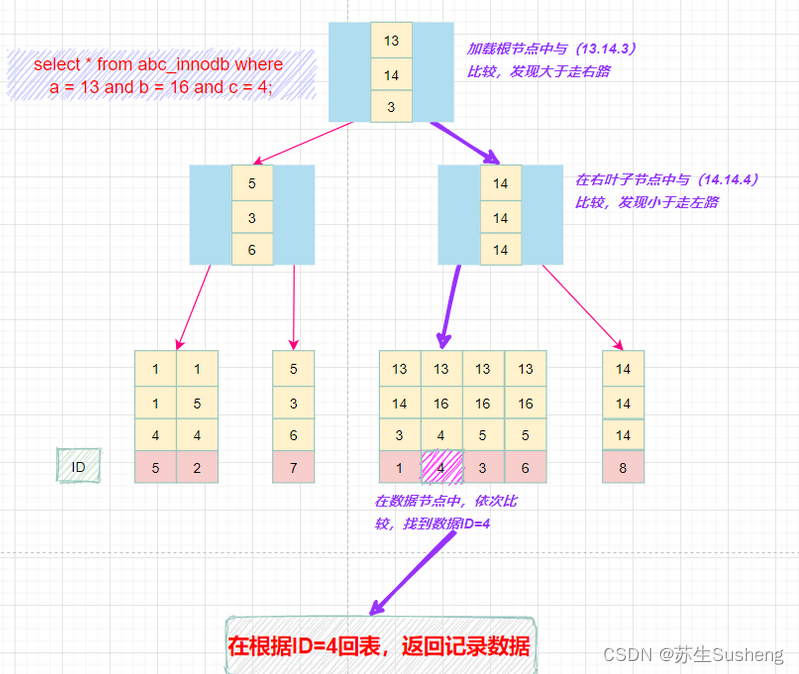
组合索引的最左匹配原则
- 最左前缀匹配原则和联合索引的索引存储结构和检索方式是有关系的。
- 在组合索引树中,最底层的叶子节点按照第一列a列从左到右递增排列,但是b列和c列是无序的,b列只有在a列值相等的情况下小范围内递增有序,而c列只能在a,b两列相等的情况下小范围内递增有序。
- 就像上面的查询,B+树会先比较a列来确定下一步应该搜索的方向,往左还是往右。如果a列相同再比较b列。但是如果查询条件没有a列,B+树就不知道第一步应该从哪个节点查起。
- 可以说创建的idx_abc(a,b,c)索引,相当于创建了(a)、(a,b)(a,b,c)三个索引。
- 使用组合索引查询时,mysql会一直向右匹配直至遇到范围查询(>、<、between、like)就停止匹配
覆盖索引
覆盖索引并不是说是索引结构,覆盖索引是一种很常用的优化手段。因为在使用辅助索引的时候,我们只可以拿到主键值,相当于获取数据还需要再根据主键查询主键索引再获取到数据。
但是在上面abc_innodb表中的组合索引查询时,如果我只需要abc字段的,那是不是意味着我们查询到组合索引的叶子节点就可以直接返回了,而不需要回表。这种情况就是覆盖索引。
执行计划分析
覆盖索引
explain select a,b,c from abc_innodb where a = 13 and b=14 and c=4;

未覆盖索引
explain select * from abc_innodb where a = 13 and b=14 and c=4;

SQL优化方向之一——避免回表
在InnoDB的存储引擎中,使用辅助索引查询的时候,因为辅助索引叶子节点保存的数据不是当前记录的数据而是当前记录的主键索引,索引如果需要获取当前记录完整数据就必然需要根据主键值从主键索引继续查询。这个过程我们成位回表。想想回表必然是会消耗性能影响性能
案例分析
- 现有User表(id(PK),name(key),sex,address,hobby…)
- 如果在一个场景下,
select id,name,sex from user where name ='zhangsan';这个语句在业务上频繁使用到,而user表的其他字段使用频率远低于它,在这种情况下,如果我们在建立 name 字段的索引的时候,不是使用单一索引,而是使用联合索引(name,sex)这样的话再执行这个查询语句是不是根据辅助索引查询到的结果就可以获取当前语句的完整数据。这样就可以有效地避免了回表再获取sex的数据。
这里就是一个典型的使用覆盖索引的优化策略减少回表的情况。
联合索引
在建立索引的时候,尽量在多个单列索引上判断下是否可以使用联合索引。联合索引的使用不仅可以节省空间,还可以更容易的使用到索引覆盖。试想一下,索引的字段越多,是不是更容易满足查询需要返回的数据呢。比如联合索引(a_b_c),是不是等于有了索引:a,a_b,a_b_c三个索引,这样是不是节省了空间,当然节省的空间并不是三倍于(a,a_b,a_b_c)三个索引,因为索引树的数据没变,但是索引data字段的数据确实真实的节省了
联合索引的创建原则
在创建联合索引的时候因该把频繁使用的列、区分度高的列放在前面,频繁使用代表索引利用率高,区分度高代表筛选粒度大,这些都是在索引创建的需要考虑到的优化场景,也可以在常需要作为查询返回的字段上增加到联合索引中,如果在联合索引上增加一个字段而使用到了覆盖索引,那我建议这种情况下使用联合索引
联合索引的使用
- 考虑当前是否已经存在多个可以合并的单列索引,如果有,那么将当前多个单列索引创建为一个联合索引。
- 当前索引存在频繁使用作为返回字段的列,这个时候就可以考虑当前列是否可以加入到当前已经存在索引上,使其查询语句可以使用到覆盖索引。
索引的设计原则
按照下列标准选择建立索引的列
- 频繁搜索的列
- 经常用作查询选择的列
- 经常排序、分组的列
- 经常用作连接的列(主键/外键)
不要使用下面的列创建索引
- 仅包含几个不同值的列
- 表中仅包含几行
索引失效的情况
- 模糊查询like使用“name%”索引可用,“%name”索引失效
- 组合索引包含从左到右的字段使用索引,不包含左边的字段索引失效
- 组合索引范围搜索,范围搜索后的字段不使用索引
- 条件字段数据类型不匹配,导致索引失效
- 联合查询时,字符集不匹配导致索引失效
- 不等于导致索引失效,不等于的情况包括(!= 、<、>、not in)
- or前后条件都包含索引则走索引,or前后有一个不包含索引索引失效
- 添加索引的字段上使用函数或者计算,导致索引失效,函数包括ABS,UPPER,DATE,DAY,YEAR等
搜集来的SQL优化经验(欢迎补充)
- 应尽量避免在 where 子句中使用!=或<>操作符,否则将引擎放弃使用索引而进行全表扫描。
- 对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引。
- 应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索引而进行全表扫描
- 尽量避免在 where 子句中使用 or 来连接条件,否则将导致引擎放弃使用索引而进行全表扫描,
- 应尽量避免在 where 子句中对字段进行表达式操作,这将导致引擎放弃使用索引而进行全表扫描
- 应尽量避免在where子句中对字段进行函数操作,这将导致引擎放弃使用索引而进行全表扫描
- 不要在 查询条件的字段上进行函数、算术运算或其他表达式运算,否则系统将可能无法正确使用索引
- 在使用索引字段作为条件时,如果该索引是复合索引,那么必须使用到该索引中的第一个字段作为条件时才能保证系统使用该索引,否则该索引将不会被使 用,并且应尽可能的让字段顺序与索引顺序相一致
- 很多时候用 exists 代替 in 是一个好的选择
- 尽量避免大事务操作,提高系统并发能力
- 尽量避免向客户端返回大数据量,若数据量过大,应该考虑相应需求是否合理
- 索引并不是越多越好,索引固然可以提高相应的 select 的效率,但同时也降低了 insert 及 update 的效率,因为 insert 或 update 时有可能会重建索引,所以怎样建索引需要慎重考虑,视具体情况而定。一个表的索引数最好不要超过6个,若太多则应考虑一些不常使用到的列上建的索引是否有 必要
- where条件中,字段与参数的类型要保持一致,否则会导致索引失效
- 根据业务数据发生频率,定期重新生成或重新组织索引,进行碎片整理。
- WHERE子句中有多个条件表达式时,包含索引列的表达式应置于其他条件表达式之前;
- 索引应该尽量小,在字节数小的列上建立索引
- 查询时减少使用*返回全部列,不要返回不需要的列;
- 避免在ORDER BY子句中使用表达式。
相关文章:
【MySQL】视图、索引
目录 视图视图的用途优点视图的缺点创建视图查看视图修改视图删除视图注意事项 索引索引的原理索引的数据结构二分查找法Hash结构Hash冲突!!! B树二叉查找树 存在问题改造二叉树——B树降低树的高度 B树特点案例继续优化的方向 改造B树——B树…...
反编译java生成的.class文件
java代码编译后生成xxx.class文件,有时候需要反编译这个class文件看代码是怎么写的,可以使用下面这个工具。 工具已经上传到资源,链接: https://download.csdn.net/download/weixin_42556307/88915887 具体使用如下: …...

Cookie 探秘:了解 Web 浏览器中的小甜饼
🤍 前端开发工程师、技术日更博主、已过CET6 🍨 阿珊和她的猫_CSDN博客专家、23年度博客之星前端领域TOP1 🕠 牛客高级专题作者、打造专栏《前端面试必备》 、《2024面试高频手撕题》 🍚 蓝桥云课签约作者、上架课程《Vue.js 和 E…...

Python线性代数数字图像和小波分析之二
要点 数学方程:数字信号和傅里叶分析,离散时间滤波器,小波分析Python代码实现及应用变换过程: 读取音频和处理音频波,使用Karplus-强算法制作吉他音频离散傅里叶计算功能和绘制图示结果计算波形傅里叶系数正向和反向&…...

LC.exe”已退出,代码为 -1
尽管网络上已经有许多详尽的说明和资料,但鉴于个人对大量文字的理解有反感,我就写一个更为直观、简洁的方式来呈现我的解决方案。 1.问题图片。 2.删除licenses.licx 3.问题解决...

springboot + jpa + 达梦数据库兼容 Mysql的GenerationType.IDENTITY主键生成策略
导入达梦数据库对hibernate的方言包 <dependency><groupId>com.dameng</groupId><artifactId>DmDialect-for-hibernate5.6</artifactId><version>8.1.2.192</version></dependency>配置文件中添加方言配置和主键生成策略配置…...

Redis优化与应用
Redis性能调优 - Redis的性能调优是一个比较复杂的过程,需要从多个方面进行优化,如内存使用、命令使用等。 - 案例:减少不必要的持久化操作。默认情况下,Redis会执行RDB和AOF两种持久化方式。如果不需要持久化,或者可…...
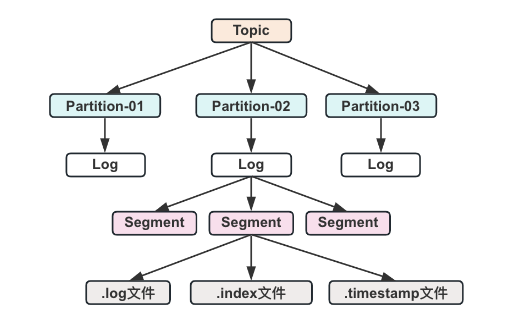
深入了解Kafka的文件存储原理
Kafka简介 Kafka最初由Linkedin公司开发的分布式、分区的、多副本的、多订阅者的消息系统。它提供了类似于JMS的特性,但是在设计实现上完全不同,此外它并不是JMS规范的实现。kafka对消息保存是根据Topic进行归类,发送消息者称为Producer&…...
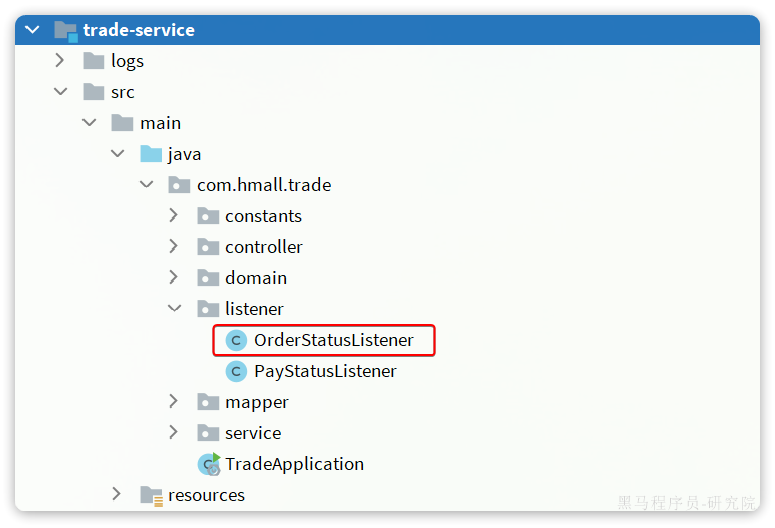
RabbitMQ 高级
在昨天的练习作业中,我们改造了余额支付功能,在支付成功后利用RabbitMQ通知交易服务,更新业务订单状态为已支付。 但是大家思考一下,如果这里MQ通知失败,支付服务中支付流水显示支付成功,而交易服务中的订单…...

音视频开发之旅——音频基础概念、交叉编译原理和实践(LAME的交叉编译)(Android)
本文主要讲解的是音频基础概念、交叉编译原理和实践(LAME的交叉编译),是基于Android平台,示例代码如下所示: AndroidAudioDemo 音频基础概念 在进行音频开发的之前,了解声学的基础还是很有必要的。 声音…...

直播美颜SDK开发指南:构建个性化的主播美颜工具
本篇文章,小编将带您深入了解如何构建个性化的主播美颜工具,从而为用户提供更优质的直播体验。 一、美颜技术概述 在开始SDK的开发之前,我们首先需要了解美颜技术的基本原理。美颜技术通常包括肤色检测、人脸检测、特征点定位、滤镜处理等步…...

羊大师揭秘,羊奶有哪些好处和不足呢?
羊大师揭秘,羊奶有哪些好处和不足呢? 羊奶的好处主要包括: 营养丰富:羊奶中含有多种人体所需的营养成分,如蛋白质、脂肪、碳水化合物、矿物质和维生素等。尤其是蛋白质含量高,且易于人体吸收利用。 增强免…...

鸿蒙问题之CustomDialog后持久化@state数据崩溃
开发需求:有一个字符串数组,可以通过弹框编辑其中的某个字符串,编辑完成后更新数组并持久化这个数组。 这个需求算是很简单,很常见的需求了。但是,开发过程中却遇到了一个不小的难题。 我的数组内容需要在组件中显示…...

微服务高性能通信技术-gRPC实战落地
在微服务架构中,服务之间的通信是至关重要的。为了实现高性能、低延迟和跨语言的服务间通信,gRPC是一个流行的选择。gRPC是一个开源的、高性能的、通用的RPC(远程过程调用)框架,基于HTTP/2协议和Protocol Buffers序列化…...

洛阳旅游攻略
洛阳旅游攻略 第一天(抵达当天): 1.先将行李放到酒店—2.老城十字街(打车可能会堵车)—3.洛邑古城—4.丽景门(步行) 第二天: 1.早起吃早餐—(打车三十分钟,…...
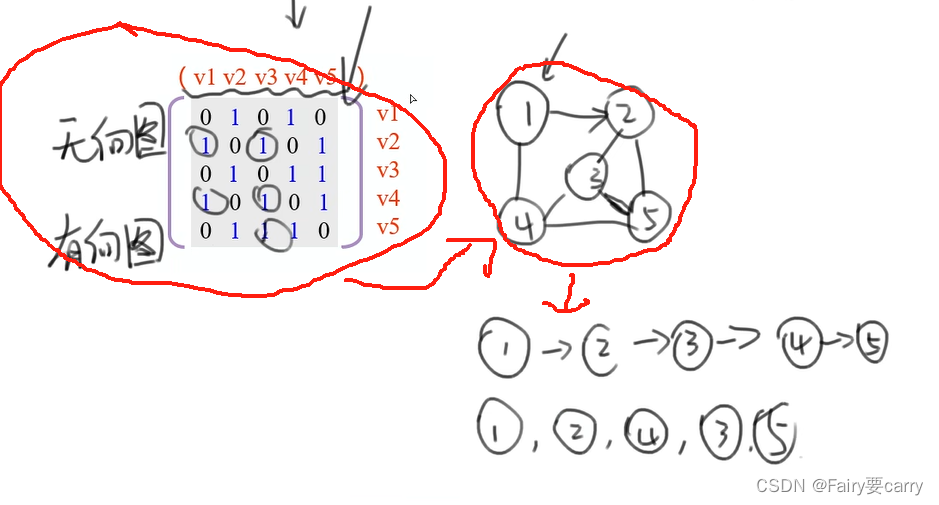
图论例题解析
1.图论基础概念 概念 (注意连通非连通情况,1节点) 无向图: 度是边的两倍(没有入度和出度的概念) 1.完全图: 假设一个图有n个节点,那么任意两个节点都有边则为完全图 2.连通图&…...

图解 TCP 拥塞控制
文章目录 什么是拥塞控制拥塞控制算法慢启动拥塞避免快速恢复 TCP拥塞控制状态机 什么是拥塞控制 拥塞控制是一种 确保网络中的数据包以可持续的速率传输 的机制,避免因为数据包太多而超过网络当前的承载能力,导致网络性能下降,甚至产生大量…...
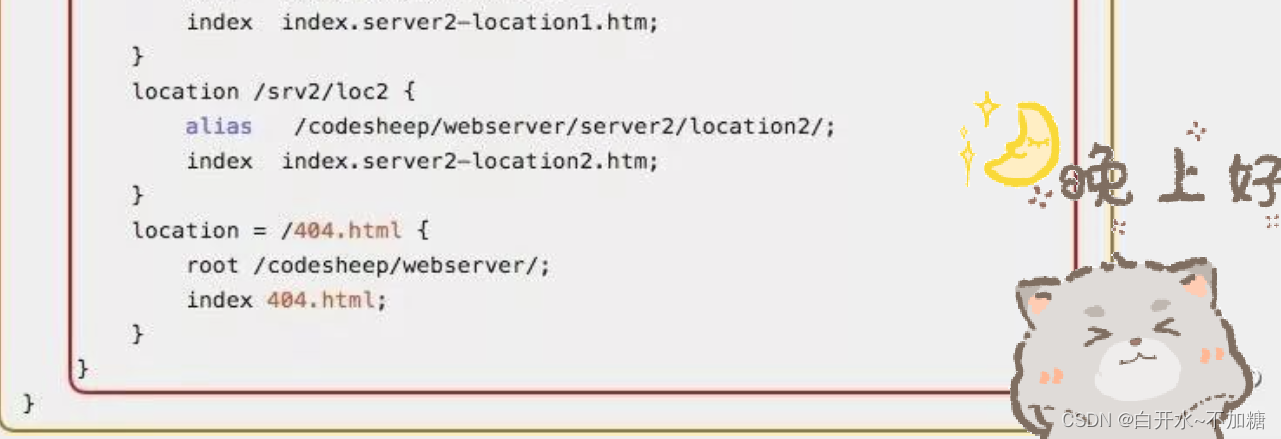
Nginx配置文件的整体结构
一、Nginx配置文件的整体结构 从图中可以看出主要包含以下几大部分内容: 1. 全局块 该部分配置主要影响Nginx全局,通常包括下面几个部分: 配置运行Nginx服务器用户(组) worker process数 Nginx进程PID存放路径 错误…...
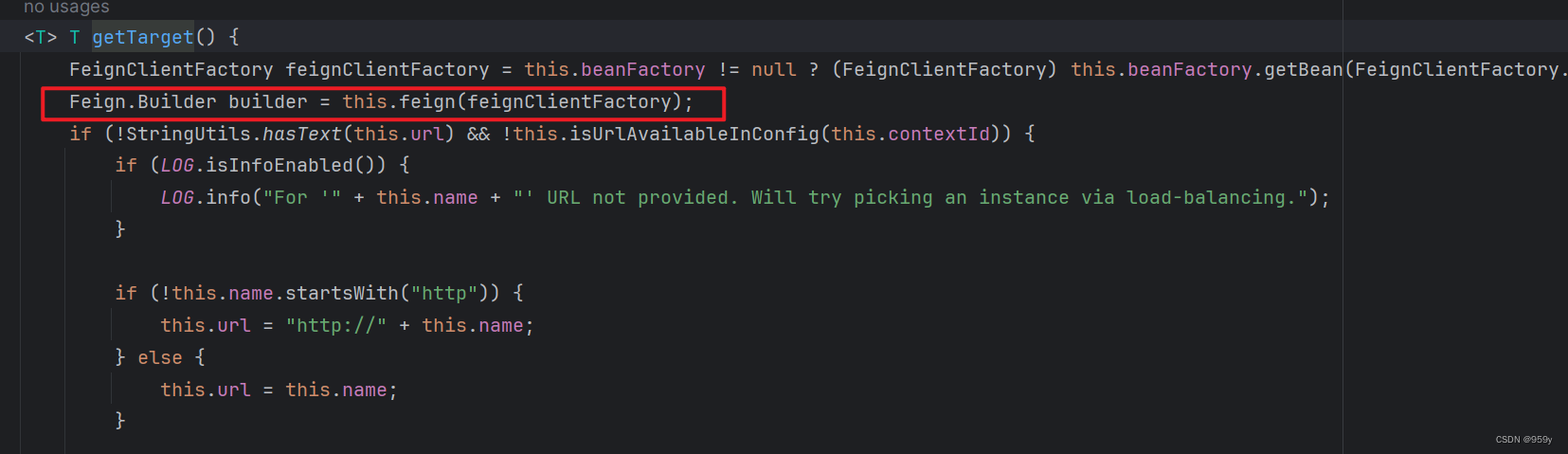
[SpringCloud] OpenFeign核心架构原理 (三)
文章目录 1.SpringCloud是如何整合Feign的1.1 将FeignClient接口注册到Spring中1.2 FeignClientFactoryBean相关 1.SpringCloud是如何整合Feign的 核心组件重新实现, 支持更多的SpringCloud生态的功能。将接口动态代理对象注入到Spring容器中。 1.1 将FeignClient接口注册到S…...

elementUI Table组件点击取当前行索引
在使用element UI Table组件时,需要点击取当前行索引,并删除当前行,看了element UI 文档好象没有这个的,仔细看下发现当前行索引是在scope里的$.index里。 element UI文档:https://www.uihtm.com/element/#/zh-CN/comp…...

为什么你需要一个完整的Unity历史版本下载库?开发者必备的版本管理解决方案
为什么你需要一个完整的Unity历史版本下载库?开发者必备的版本管理解决方案 【免费下载链接】download.unity.com Unity国际版下载,解决国内打不开网站和被重定向的问题 项目地址: https://gitcode.com/gh_mirrors/do/download.unity.com 在游戏开…...

TeamPass后台任务管理:自动化维护和清理操作手册
TeamPass后台任务管理:自动化维护和清理操作手册 【免费下载链接】TeamPass Collaborative Passwords Manager 项目地址: https://gitcode.com/gh_mirrors/te/TeamPass TeamPass作为一款协作密码管理器,其后台任务管理功能是确保系统高效稳定运行…...

HCK代码实现原理:揭秘AI辅助学术分析的核心算法
HCK代码实现原理:揭秘AI辅助学术分析的核心算法 【免费下载链接】sala-do-futuro-script O HCK um script de anlise acadmica assistida por IA, projetado para auxiliar estudantes na resoluo de questes de tarefas e provas da plataforma sala do futuro. …...

CausalImpact最佳实践:避免因果推断中的7个常见陷阱
CausalImpact最佳实践:避免因果推断中的7个常见陷阱 【免费下载链接】CausalImpact An R package for causal inference in time series 项目地址: https://gitcode.com/gh_mirrors/ca/CausalImpact 在时间序列分析领域,因果推断是揭示变量间真实…...

Taotoken多模型聚合在批量内容生成任务中的稳定性观察
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken多模型聚合在批量内容生成任务中的稳定性观察 1. 任务背景与挑战 在涉及大规模、长时间运行的内容生成任务中,…...
)
别再乱买粉了!联想领像M100系列打印机耗材选购与加粉全攻略(附三星通用粉型号)
联想领像M100系列打印机耗材选购与维护全指南 对于中小企业或家庭办公用户来说,打印机的耗材成本往往是长期使用中的一大支出。联想领像M100系列作为高性价比的激光打印机,其耗材选择与维护技巧直接关系到打印质量和设备寿命。本文将系统性地解析从耗材选…...

TPU核心引擎的‘血管网络’:用Python建模与可视化理解脉动阵列数据流
TPU核心引擎的‘血管网络’:用Python建模与可视化理解脉动阵列数据流 在AI加速器的世界里,TPU(张量处理单元)的脉动阵列就像一台精密的机械钟表,每个齿轮的咬合都遵循着严格的时序规律。但与硬件工程师通过RTL语言&qu…...
)
Perplexity地理信息查询API调用异常(2024最新错误码全解+经纬度偏移校准公式)
更多请点击: https://codechina.net 第一章:Perplexity地理信息查询API异常现象全景速览 Perplexity平台近期面向开发者开放的地理信息查询API(v1.2)在多区域部署中持续暴露非预期响应行为,涵盖HTTP状态码异常、地理坐…...
)
从CAN报文到转速值:手把手拆解SAE J1939-71的F004参数组(附Python解析代码)
从CAN报文到转速值:SAE J1939-71的F004参数组实战解析与Python实现 在汽车电子和商用车诊断领域,SAE J1939协议栈堪称工程师的"第二语言"。而其中J1939-71文档定义的参数组(PGN)解析,则是将原始CAN报文转化为工程价值的核心技能。本…...
)
【计算机组成原理】无符号整数乘法原理(基于移位累加,零基础看懂CPU乘法)
前言在数字电路与计算机组成原理中,加法是最基础的运算,而乘法是高频常用运算。很多初学者疑惑:计算机没有专门的乘法口诀,到底怎么实现二进制乘法?而在数字运算中,乘法是比加法更复杂、但底层逻辑完全依托…...