【大数据】Flink SQL 语法篇(十):EXPLAIN、USE、LOAD、SET、SQL Hints
《Flink SQL 语法篇》系列,共包含以下 10 篇文章:
- Flink SQL 语法篇(一):CREATE
- Flink SQL 语法篇(二):WITH、SELECT & WHERE、SELECT DISTINCT
- Flink SQL 语法篇(三):窗口聚合(TUMBLE、HOP、SESSION、CUMULATE)
- Flink SQL 语法篇(四):Group 聚合、Over 聚合
- Flink SQL 语法篇(五):Regular Join、Interval Join
- Flink SQL 语法篇(六):Temporal Join
- Flink SQL 语法篇(七):Lookup Join、Array Expansion、Table Function
- Flink SQL 语法篇(八):集合、Order By、Limit、TopN
- Flink SQL 语法篇(九):Window TopN、Deduplication
- Flink SQL 语法篇(十):EXPLAIN、USE、LOAD、SET、SQL Hints
😊 如果您觉得这篇文章有用 ✔️ 的话,请给博主一个一键三连 🚀🚀🚀 吧 (点赞 🧡、关注 💛、收藏 💚)!!!您的支持 💖💖💖 将激励 🔥 博主输出更多优质内容!!!
Flink SQL 语法篇(十):EXPLAIN、USE、LOAD、SET、SQL Hints
- 1.EXPLAIN 子句
- 2.USE 子句
- 3.SHOW 子句
- 4.LOAD、UNLOAD 子句
- 5.SET、RESET 子句
- 6.SQL Hints
1.EXPLAIN 子句
EXPLAIN 子句其实就是用于查看当前这个 SQL 查询的逻辑计划以及优化的执行计划。
SQL 语法标准:
EXPLAIN PLAN FOR <query_statement_or_insert_statement>
实际案例:
public class Explain_Test {public static void main(String[] args) throws Exception {FlinkEnv flinkEnv = FlinkEnvUtils.getStreamTableEnv(args);flinkEnv.env().setParallelism(1);String sql = "CREATE TABLE source_table (\n"+ " user_id BIGINT COMMENT '用户 id',\n"+ " name STRING COMMENT '用户姓名',\n"+ " server_timestamp BIGINT COMMENT '用户访问时间戳',\n"+ " proctime AS PROCTIME()\n"+ ") WITH (\n"+ " 'connector' = 'datagen',\n"+ " 'rows-per-second' = '1',\n"+ " 'fields.name.length' = '1',\n"+ " 'fields.user_id.min' = '1',\n"+ " 'fields.user_id.max' = '10',\n"+ " 'fields.server_timestamp.min' = '1',\n"+ " 'fields.server_timestamp.max' = '100000'\n"+ ");\n"+ "\n"+ "CREATE TABLE sink_table (\n"+ " user_id BIGINT,\n"+ " name STRING,\n"+ " server_timestamp BIGINT\n"+ ") WITH (\n"+ " 'connector' = 'print'\n"+ ");\n"+ "\n"+ "EXPLAIN PLAN FOR\n"+ "INSERT INTO sink_table\n"+ "select user_id,\n"+ " name,\n"+ " server_timestamp\n"+ "from (\n"+ " SELECT\n"+ " user_id,\n"+ " name,\n"+ " server_timestamp,\n"+ " row_number() over(partition by user_id order by proctime) as rn\n"+ " FROM source_table\n"+ ")\n"+ "where rn = 1";/*** 算子 {@link org.apache.flink.streaming.api.operators.KeyedProcessOperator}* -- {@link org.apache.flink.table.runtime.operators.deduplicate.ProcTimeDeduplicateKeepFirstRowFunction}*/for (String innerSql : sql.split(";")) {TableResult tableResult = flinkEnv.streamTEnv().executeSql(innerSql);tableResult.print();}}
}
上述代码执行结果如下:
1. 抽象语法树
== Abstract Syntax Tree ==
LogicalSink(table=[default_catalog.default_database.sink_table], fields=[user_id, name, server_timestamp])
+- LogicalProject(user_id=[$0], name=[$1], server_timestamp=[$2])+- LogicalFilter(condition=[=($3, 1)])+- LogicalProject(user_id=[$0], name=[$1], server_timestamp=[$2], rn=[ROW_NUMBER() OVER (PARTITION BY $0 ORDER BY PROCTIME() NULLS FIRST)])+- LogicalTableScan(table=[[default_catalog, default_database, source_table]])2. 优化后的物理计划
== Optimized Physical Plan ==
Sink(table=[default_catalog.default_database.sink_table], fields=[user_id, name, server_timestamp])
+- Calc(select=[user_id, name, server_timestamp])+- Deduplicate(keep=[FirstRow], key=[user_id], order=[PROCTIME])+- Exchange(distribution=[hash[user_id]])+- Calc(select=[user_id, name, server_timestamp, PROCTIME() AS $3])+- TableSourceScan(table=[[default_catalog, default_database, source_table]], fields=[user_id, name, server_timestamp])3. 优化后的执行计划
== Optimized Execution Plan ==
Sink(table=[default_catalog.default_database.sink_table], fields=[user_id, name, server_timestamp])
+- Calc(select=[user_id, name, server_timestamp])+- Deduplicate(keep=[FirstRow], key=[user_id], order=[PROCTIME])+- Exchange(distribution=[hash[user_id]])+- Calc(select=[user_id, name, server_timestamp, PROCTIME() AS $3])+- TableSourceScan(table=[[default_catalog, default_database, source_table]], fields=[user_id, name, server_timestamp])
2.USE 子句
如果熟悉 MySQL 的同学会非常熟悉这个子句,在 MySQL 中,USE 子句通常被用于切换库,那么在 Flink SQL 体系中,它的作用也是和 MySQL 中 USE 子句的功能基本一致,用于切换 Catalog,DataBase,使用 Module。
- 切换 Catalog
USE CATALOG catalog_name
- 使用 Module
USE MODULES module_name1[, module_name2, ...]
- 切换 Database
USE db名称
实际案例:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);// create a catalog
tEnv.executeSql("CREATE CATALOG cat1 WITH (...)");
tEnv.executeSql("SHOW CATALOGS").print();
// +-----------------+
// | catalog name |
// +-----------------+
// | default_catalog |
// | cat1 |
// +-----------------+// change default catalog
tEnv.executeSql("USE CATALOG cat1");tEnv.executeSql("SHOW DATABASES").print();
// databases are empty
// +---------------+
// | database name |
// +---------------+
// +---------------+// create a database
tEnv.executeSql("CREATE DATABASE db1 WITH (...)");
tEnv.executeSql("SHOW DATABASES").print();
// +---------------+
// | database name |
// +---------------+
// | db1 |
// +---------------+// change default database
tEnv.executeSql("USE db1");// change module resolution order and enabled status
tEnv.executeSql("USE MODULES hive");
tEnv.executeSql("SHOW FULL MODULES").print();
// +-------------+-------+
// | module name | used |
// +-------------+-------+
// | hive | true |
// | core | false |
// +-------------+-------+
3.SHOW 子句
如果熟悉 MySQL 的同学会非常熟悉这个子句,在 MySQL 中,SHOW 子句常常用于查询库、表、函数等,在 Flink SQL 体系中也类似。Flink SQL 支持 SHOW 以下内容。
SQL 语法标准:
SHOW CATALOGS:展示所有 CatalogSHOW CURRENT CATALOG:展示当前的 CatalogSHOW DATABASES:展示当前 Catalog 下所有 DatabaseSHOW CURRENT DATABASE:展示当前的 DatabaseSHOW TABLES:展示当前 Database 下所有表SHOW VIEWS:展示所有视图SHOW FUNCTIONS:展示所有的函数SHOW MODULES:展示所有的 Module(Module 是用于 UDF 扩展)
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);// show catalogs
tEnv.executeSql("SHOW CATALOGS").print();
// +-----------------+
// | catalog name |
// +-----------------+
// | default_catalog |
// +-----------------+// show current catalog
tEnv.executeSql("SHOW CURRENT CATALOG").print();
// +----------------------+
// | current catalog name |
// +----------------------+
// | default_catalog |
// +----------------------+// show databases
tEnv.executeSql("SHOW DATABASES").print();
// +------------------+
// | database name |
// +------------------+
// | default_database |
// +------------------+// show current database
tEnv.executeSql("SHOW CURRENT DATABASE").print();
// +-----------------------+
// | current database name |
// +-----------------------+
// | default_database |
// +-----------------------+// create a table
tEnv.executeSql("CREATE TABLE my_table (...) WITH (...)");
// show tables
tEnv.executeSql("SHOW TABLES").print();
// +------------+
// | table name |
// +------------+
// | my_table |
// +------------+// create a view
tEnv.executeSql("CREATE VIEW my_view AS ...");
// show views
tEnv.executeSql("SHOW VIEWS").print();
// +-----------+
// | view name |
// +-----------+
// | my_view |
// +-----------+// show functions
tEnv.executeSql("SHOW FUNCTIONS").print();
// +---------------+
// | function name |
// +---------------+
// | mod |
// | sha256 |
// | ... |
// +---------------+// create a user defined function
tEnv.executeSql("CREATE FUNCTION f1 AS ...");
// show user defined functions
tEnv.executeSql("SHOW USER FUNCTIONS").print();
// +---------------+
// | function name |
// +---------------+
// | f1 |
// | ... |
// +---------------+// show modules
tEnv.executeSql("SHOW MODULES").print();
// +-------------+
// | module name |
// +-------------+
// | core |
// +-------------+// show full modules
tEnv.executeSql("SHOW FULL MODULES").print();
// +-------------+-------+
// | module name | used |
// +-------------+-------+
// | core | true |
// | hive | false |
// +-------------+-------+
4.LOAD、UNLOAD 子句
我们可以使用 LOAD 子句去加载 Flink SQL 体系内置的或者用户自定义的 Module,UNLOAD 子句去卸载 Flink SQL 体系内置的或者用户自定义的 Module。
SQL 语法标准:
-- 加载
LOAD MODULE module_name [WITH ('key1' = 'val1', 'key2' = 'val2', ...)]-- 卸载
UNLOAD MODULE module_name
- LOAD 案例
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);// 加载 Flink SQL 体系内置的 Hive module
tEnv.executeSql("LOAD MODULE hive WITH ('hive-version' = '3.1.2')");
tEnv.executeSql("SHOW MODULES").print();
// +-------------+
// | module name |
// +-------------+
// | core |
// | hive |
// +-------------+
- UNLOAD 案例
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);// 卸载唯一的一个 CoreModule
tEnv.executeSql("UNLOAD MODULE core");
tEnv.executeSql("SHOW MODULES").print();
// 结果啥 Moudle 都没有了
5.SET、RESET 子句
SET 子句可以用于修改一些 Flink SQL 的环境配置,RESET 子句是可以将所有的环境配置恢复成默认配置,但只能在 SQL CLI 中进行使用,主要是为了让用户更纯粹的使用 SQL 而不必使用其他方式或者切换系统环境。
SET (key = value)?RESET (key)?
启动一个 SQL CLI 之后,在 SQL CLI 中可以进行以下 SET 设置:
Flink SQL> SET table.planner = blink;
[INFO] Session property has been set.Flink SQL> SET;
table.planner=blink;Flink SQL> RESET table.planner;
[INFO] Session property has been reset.Flink SQL> RESET;
[INFO] All session properties have been set to their default values.
6.SQL Hints
Hints(提示)是一种机制,用来告诉优化器按照我们的告诉它的方式生成执行计划。
比如有一个 Kafka 数据源表 kafka_table1,用户想直接从 latest-offset Select 一些数据出来预览,其元数据已经存储在 Hive MetaStore 中,但是 Hive MetaStore 中存储的配置中的 scan.startup.mode 是 earliest-offset,通过 SQL Hints,用户可以在 DML 语句中将 scan.startup.mode 改为 latest-offset 查询,因此可以看出 SQL Hints 常用语这种比较临时的参数修改,比如 Ad-hoc 这种临时查询中,方便用户使用自定义的新的表参数而不是 Catalog 中已有的表参数。
以下 DML SQL 中的 /*+ OPTIONS(key=val [, key=val]*) */ 就是 SQL Hints。
SELECT *
FROM table_path /*+ OPTIONS(key=val [, key=val]*) */
启动一个 SQL CLI 之后,在 SQL CLI 中可以进行以下 SET 设置:
CREATE TABLE kafka_table1 (id BIGINT, name STRING, age INT) WITH (...);
CREATE TABLE kafka_table2 (id BIGINT, name STRING, age INT) WITH (...);-- 1. 使用 'scan.startup.mode'='earliest-offset' 覆盖原来的 scan.startup.mode
select id, name from kafka_table1 /*+ OPTIONS('scan.startup.mode'='earliest-offset') */;-- 2. 使用 'scan.startup.mode'='earliest-offset' 覆盖原来的 scan.startup.mode
select * fromkafka_table1 /*+ OPTIONS('scan.startup.mode'='earliest-offset') */ t1joinkafka_table2 /*+ OPTIONS('scan.startup.mode'='earliest-offset') */ t2on t1.id = t2.id;-- 3. 使用 'sink.partitioner'='round-robin' 覆盖原来的 Sink 表的 sink.partitioner
insert into kafka_table1 /*+ OPTIONS('sink.partitioner'='round-robin') */ select * from kafka_table2;
相关文章:
:EXPLAIN、USE、LOAD、SET、SQL Hints)
【大数据】Flink SQL 语法篇(十):EXPLAIN、USE、LOAD、SET、SQL Hints
《Flink SQL 语法篇》系列,共包含以下 10 篇文章: Flink SQL 语法篇(一):CREATEFlink SQL 语法篇(二):WITH、SELECT & WHERE、SELECT DISTINCTFlink SQL 语法篇(三&…...

Java中List接口常见的实现类
目录 ArrayList实现类 数据存储 构造器 成员方法:CRUD Vector实现类 数据存储 构造器方法 成员方法 LinkedList实现类 数据存储 构造器方法 成员方法CRUD List总结 ArrayList:数组实现,随机访问速度快,增删慢&#x…...

SPI通信
SPI通信: 四根通信线:SCK,MOSI,MISO,SS(从机选择线) 同步时钟,全双工 支持总线挂载多个设备,一主多从 SPI相对IIC传输更快,最简单,最快速 SPI没有接收和应答机制,发送就发…...

【动态规划】【数论】【区间合并】3041. 修改数组后最大化数组中的连续元素数目
作者推荐 视频算法专题 本文涉及知识点 动态规划汇总 数论 区间合并 LeetCode3041. 修改数组后最大化数组中的连续元素数目 给你一个下标从 0 开始只包含 正 整数的数组 nums 。 一开始,你可以将数组中 任意数量 元素增加 至多 1 。 修改后,你可以从…...

字节后端实习 一面凉经
心脏和字节永远都在跳动 深圳还有没有大厂招后端日常实习生啊,求捞~(boss小公司也不理我) 很纠结要不要干脆直接面暑期实习,又怕因为没有后端实习经历,面不到大厂实习。死锁了...

倒计时37天
复习1001. 马走日问题: 1.P1002 [NOIP2002 普及组] 过河卒 - 洛谷 | 计算机科学教育新生态 (luogu.com.cn) //日常碎碎念:谁懂啊,dev突然不能用了,也不知道是哪里出了问题下了五六次都不能用,,,找远程安…...
【计算机考研】考408,还是不考408性价比高?
首先综合考虑,如果其他科目并不是很优秀,需要我们花一定的时间去复习,408的性价比就不高,各个科目的时间互相挤压,如果备考时间不充裕,考虑其他专业课也未尝不可。 复习408本来就是费力不讨好的事情 不同…...

测试入门篇
测试: 这里写目录标题 测试:基础概念:BUG:创建一个合理的bug:bug 的级别:跟开发争执如何解决: 测试用例:编写测试用例的万能公式:案例: 登录功能的测试:设计测试用例的方法: 进阶篇(主要介绍测试方法):自动化测试:自动化测试的分类:selenium( web 自动化测试工具 )环境部署:什么…...

b站小土堆pytorch学习记录—— P25-P26 网络模型的使用和修改、保存和读取
文章目录 一、修改1.方法2.代码 二、保存和读取1.方法2.代码(1)保存(2)加载 3.陷阱 一、修改 1.方法 add_module(name: str, module: Module) -> None name 是要添加的子模块的名称。 module 是要添加的子模块。 调用 add_m…...
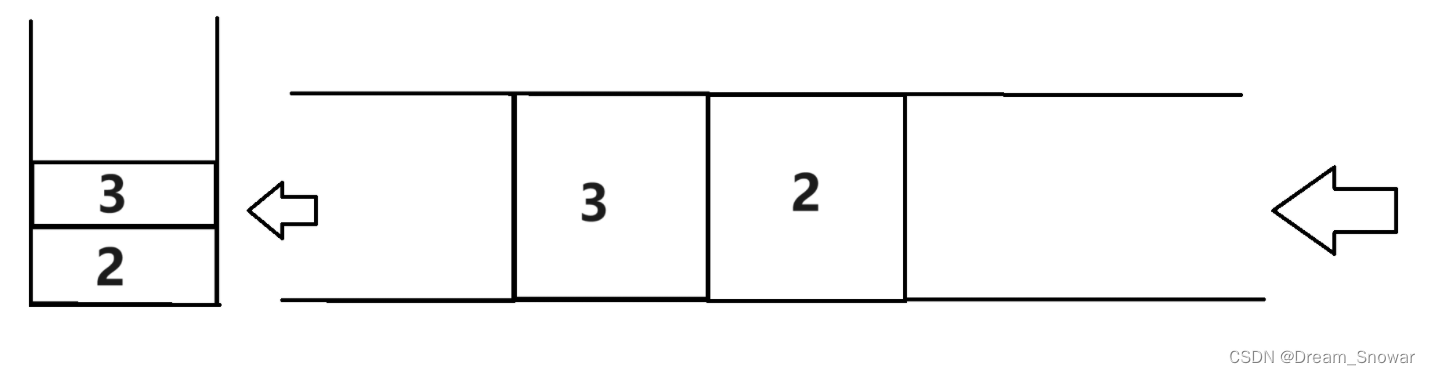
[数据结构]OJ用队列实现栈
225. 用队列实现栈 - 力扣(LeetCode) 官方题解:https://leetcode.cn/problems/implement-stack-using-queues/solutions/432204/yong-dui-lie-shi-xian-zhan-by-leetcode-solution/ 首先我们要知道 栈是一种后进先出的数据结构,…...

「优选算法刷题」:最长回文子串
一、题目 给你一个字符串 s,找到 s 中最长的回文子串。 如果字符串的反序与原始字符串相同,则该字符串称为回文字符串。 示例 1: 输入:s "babad" 输出:"bab" 解释:"aba"…...
Java项目:41 springboot大学生入学审核系统的设计与实现010
作者主页:舒克日记 简介:Java领域优质创作者、Java项目、学习资料、技术互助 文中获取源码 项目介绍 本大学生入学审核系统管理员和学生。 管理员功能有个人中心,学生管理,学籍信息管理,入学办理管理等。 学生功能有…...

【数据结构与算法】常见排序算法(Sorting Algorithm)
文章目录 相关概念1. 冒泡排序(Bubble Sort)2. 直接插入排序(Insertion Sort)3. 希尔排序(Shell Sort)4. 直接选择排序(Selection Sort)5. 堆排序(Heap Sort)…...

Unity3D学习之XLua实践——背包系统
文章目录 1 前言2 新建工程导入必要资源2.1 AB包设置2.2 C# 脚本2.3 VSCode 的环境搭建 3 面板拼凑3.1 主面板拼凑3.2 背包面板拼凑3.3 格子复合组件拼凑3.4 常用类别名准备3.5 数据准备3.5.1 图集准备3.5.2 json3.5.3 打AB包 4 Lua读取json表及准备玩家数据5 主面板逻辑6 背包…...

前端技术研究越深入,越觉得技术不是决定录用唯一条件。
一、拒绝抬杠 我说技能不是唯一条件,不是说技能不重要,招聘前端条件是1X,其中1是技能,X是其他条件。 如果X条件很优秀,1这个条件可以降格为0.8、0.5,甚至更低。 有人就抬杠,那为啥不招聘清洁工来干前端&…...

vue组件的重新渲染的问题
目录 1.方式1 2.方式2 1.方式1 修改组件上的key属性 Vue是通过diffing算法比较虚拟DOM和真实DOM,来判断新旧 DOM 的变化。key是虚拟DOM对象的标识,在更新显示时key表示着DOM的唯一性。 DOM是否变化的核心是通过判断新旧DOM的key值是否变化,…...
opengl 学习(二)-----你好,三角形
你好,三角形 分类demo效果解析 分类 opengl c demo #include "glad/glad.h" #include "glfw3.h" #include <iostream> #include <cmath> #include <vector>using namespace std;/** * 在学习此节之前,建议将这…...

mongodb4.2升级到5.0版本,升级到6.0版本, 升级到7.0版本案例
今天一客户想把自己当前使用的mongodb数据库4.2版本升级到7.0版本。难道mongodb能直接跳跃升级吗? 经过几经查找资料,貌似真不行呀。确定升级流程如下: 还得从mongo4.2升级到5.0。其次再从5.0升级到6.0。最后再从6.0升级到7.0。 开始升级之前将数据进行备份 这一步…...

CPU处理器模式与异常
ARM架构中的Exception Level(EL) 在ARM架构中,Exception Level(EL)是一个关键概念,它表示了处理器当前处理异常或中断的层次。ARMv8-A架构定义了四个Exception Levels:EL0、EL1、EL2和EL3&…...

Day 53 |● 1143.最长公共子序列 ● 1035.不相交的线 ● 53. 最大子序和
1143.最长公共子序列 class Solution { public:int longestCommonSubsequence(string text1, string text2) {vector<vector<int>> dp(text1.size()1,vector<int>(text2.size()1,0));int res 0;for(int i 1; i < text1.size(); i){for(int j 1; j <…...

WinCC报表数据老丢?可能是全局动作的锅!一个标识变量搞定设备运行数据可靠存储
WinCC报表数据丢失的根源分析与高可靠存储方案 在工业自动化系统中,WinCC作为监控和数据采集(SCADA)的核心平台,其报表数据的完整性直接关系到生产运营分析和设备管理决策的准确性。许多工程师都遇到过这样的困扰:明明设备状态变化已经触发&…...

Python try...except ImportError 语句详解
在Python编程中,ImportError 是与模块导入相关的核心异常。优雅地处理它,是编写健壮、可维护和跨平台代码的关键。try...except ImportError 结构正是实现这一目标的标准工具。本文将为你抽丝剥茧,从基础概念到高级实践,全面解析这…...

Taotoken用量看板如何帮助个人开发者管理月度预算
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken用量看板如何帮助个人开发者管理月度预算 对于独立工作的个人开发者而言,项目预算往往是决定技术选型与使用策…...

Allegro 16.6 高效布线实战:Region规则、Xnet等长与模块复用的进阶技巧
Allegro 16.6 高效布线实战:Region规则、Xnet等长与模块复用的进阶技巧 在高速PCB设计领域,Allegro 16.6作为行业标杆工具,其深度功能往往决定了设计效率的天花板。当面对BGA封装密度突破1000pin、信号速率迈入10Gbps时代的复杂主板时&#x…...

基于Arduino与TSL2561的光照度测量系统:从硬件连接到软件调试
1. 项目概述:从园艺需求到嵌入式光测量方案最近在折腾一个园艺相关的项目,需要量化评估不同覆盖材料(比如遮阳网、塑料薄膜)对光线透射率的影响。说白了,就是想精确知道,盖上一层材料后,底下还能…...

nnU-Net v2实战:从零开始配置环境与训练自定义医学影像数据集
1. 环境配置:搭建nnU-Net v2的基础舞台 第一次接触nnU-Net时,我踩过的最大坑就是环境配置。当时为了赶项目进度,直接用了现有的Python 3.8环境,结果在安装时各种报错,浪费了大半天时间。后来才发现,nnU-Net…...

qmcdump终极指南:三步解锁QQ音乐加密音频文件
qmcdump终极指南:三步解锁QQ音乐加密音频文件 【免费下载链接】qmcdump 一个简单的QQ音乐解码(qmcflac/qmc0/qmc3 转 flac/mp3),仅为个人学习参考用。 项目地址: https://gitcode.com/gh_mirrors/qm/qmcdump 还在为QQ音乐下…...

OpenSpire:开源贡献者协作平台的设计理念与实战指南
1. 项目概述:一个面向开源贡献者的协作平台最近在和一些刚接触开源的朋友交流时,发现一个挺普遍的现象:很多人对参与开源项目充满热情,但第一步“如何找到合适的项目并上手”就卡住了。GitHub上项目浩如烟海,一个新手面…...

Emacs AI编程助手:ai-code-interface.el深度集成指南
1. 项目概述:一个为Emacs注入AI灵魂的代码接口如果你是一位Emacs的深度用户,同时又对AI辅助编程抱有极大的热情,那么你很可能已经厌倦了在浏览器、终端和编辑器之间反复横跳的割裂体验。tninja/ai-code-interface.el这个项目,正是…...

DLP/SLA光固化3D打印技术解析与Ember打印机实战指南
1. DLP/SLA 3D打印技术深度解析:从光与树脂的对话说起如果你是从FDM(熔丝制造)打印转向树脂打印的,那感觉就像从开手动挡卡车换到了开精密数控机床。DLP(数字光处理)和SLA(立体光刻)…...