ANTLR4规则解析生成器(三):遍历语法分析树
文章目录
- 1 词法分析
- 2 语法分析
- 3 遍历语法分析树
- 3.1 Listener
- 3.2 Visitor
- 4 总结
1 词法分析
词法分析就是对给定的字符串进行分割,提取出其中的单词。
在antlr4中,词法规则的名称的首字母需要大写,右侧必须是终结符,通常将词法规则的名称全部大写。
例如,要匹配C语言中的变量名,就需要知道C语言中的变量名的规范:
- 变量只能由字母、数字、下划线组成
- 变量名的第一个字符必须是字母或者下划线,不能是数字
于是,变量名的词法规则就可以是:
VARNAME: [a-zA-Z_]+[a-zA-Z_0-9]*;
antlr4提供关键字fragment用于定义词法片段,可以把比较常用的正则表达式的一部分定义为片段进行复用,它本身并不会生成任何标记,但是能够提高可读性。
fragment DIGIT : [0-9]
fragment ALPHABET: [a-zA-Z]UNDERLINE: '_';VARNAME: (ALPHABET|UNDERLINE)+(ALPHABET|UNDERLINE|DIGIT)*
首先分别定义字母和数字的fragment,然后定义下划线的词法规则,再结合字母、数字、下划线定义变量名的词法规则。
2 语法分析
词法分析得到单词流后,就可以通过语法分析生成语法分析树。
语法规则的民成的首字母需要小写,以区分词法规则,通常将语法规则的名称全部小写。
例如,要匹配一个赋值表达式,就需要知道赋值表达式由哪些部分构成。
赋值表达式通常由四部分构成:
- 等号左侧,左侧通常是变量名,但是也可能在定义变量时进行初始化,不过也可能赋值给指针
- 等号
- 等号右侧,右侧可能是常量,也可能是函数调用
- 表达式结尾的分号
这里为了简化处理,只实现以下的赋值语句:
- 等号左侧只是变量名
- 等号右侧只有整数常量
语法规则就是:
ASSIGN: '=';
SEMI: ';';
NUMBER: DIGIT+;assign_expr: VARNAME ASSIGN NUMBER SEMI;
3 遍历语法分析树
在编写antlr4的语法规则文件时,可以在其中加入特定语言的动作,例如,需要在访问到某个规则的时候输出得到的字符串,就可以直接将该逻辑写在语法规则文件中,但是这种方式会使得语法规则文件和解析程序耦合,不同语言需要不同的节点访问逻辑,因此,编写完成语法规则文件后,通常生成对应语言的解析程序。利用该解析程序可以实现对语法分析树的遍历。
下一步就是对语法分析树进行遍历,为了方便对,antlr4提供了两种遍历语法分析树的模式:
- Listener
- Visitor
在使用antlr4工具生成对应语言的程序时,可以通过-listener和-visitor选项生成对应的遍历语法分析树的代码,-listener是默认选项,也就是默认得到Listener类型的遍历器。
在说明Listener和Visitor之前需要了解下语法分析树的结构和相关类型,以下的{GrammarName}表示语法名称,也就是grammar语句中的名称,{RuleName}表示语法文件中的规则名称,也就是冒号前面的单词。
antlr4为我们生成的解析器{GrammarName}Parser继承自antlr4.Parser,{GrammarName}Parser中会对每条规则定义一个类,类继承自antlr4.ParserRuleContext,例如,如果规则名是expr,就会创建一个类:class ExprContext(ParserRuleContext),同时对每条规则也会创建一个对应的方法,用于返回对应的类对象,例如,如果规则名是expr,那么方法就是def expr(self),该方法会返回ExprContext的对象。在创建{GrammarName}Parser对象时需要传递antlr4.TokenStream作为参数,antlr4.TokenStream可以理解为词法分析的单词流,解析器就是对单词流进行分析。
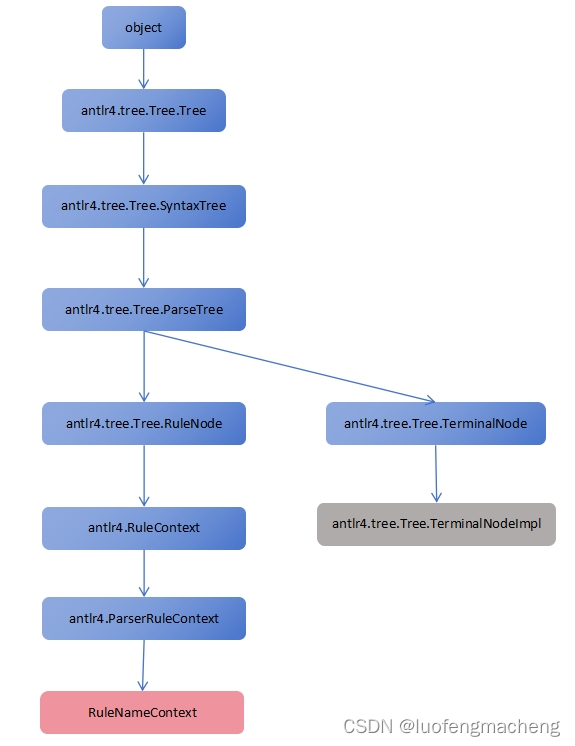
在创建{GrammarName}Parser解析器对象后,就可以通过第一条规则的规则名作为方法名得到语法分析树的根节点,接下来就可以通过Listener或者Visitor机制遍历该语法分析树。语法分析树的每个节点对应一条规则,都是继承自antlr4.ParserRuleContext的对象,而叶子节点则是词法分析的单词,类型是TerminalNodeImpl。
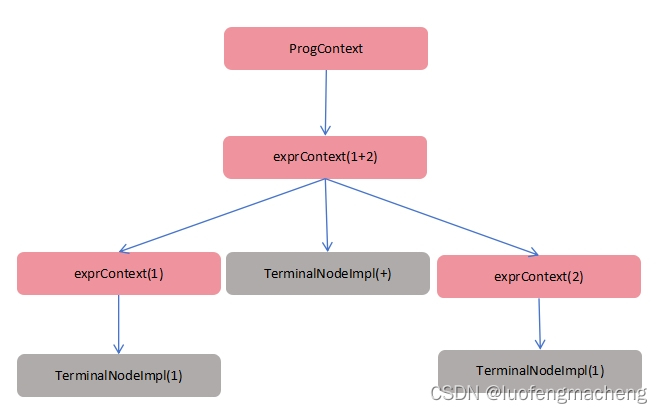
因此,在实际的开发者解析语法分析树的主函数代码通常是:
# 使用输入的字符串创建输入流,然后将输入流给到词法分析器
# 使用词法分析器就得到TokenStream对象
input_stream = InputStream("10+1+1+2\n")
lexer = exprLexer(input_stream)
token_stream = CommonTokenStream(lexer)# 使用TokenStream对象创建antlr4为我们生成的解析器对象
parser = exprParser(token_stream)# prog就是g4语法规则文件的第一条规则
# 因此,调用解析器的prog方法得到语法分析树的根节点
# 在其他程序中也需要使用第一条规则的规则名进行调用
tree = parser.prog()# 此处使用Listenser的方式遍历得到的语法分析树
listener = Listener()
walker = ParseTreeWalker()
walker.walk(listener, tree)
3.1 Listener
Listener的基本思想是给树的节点定义回调函数,当访问语法分析树时自动调用定义的回调函数,实现树的自动访问。
在使用antlr4工具生成对应语言的程序时,会默认生成{GrammarName}Listener.py的代码文件(这里以python为例)。
在{GrammarName}Listener.py的文件中会生成一个继承自antlr4.tree.Tree.ParseTreeListener的{GrammarName}Listener类,该类中会每条规则定义了两个方法:
- enter{RuleName}()方法:例如,规则名为expr,则方法名为enterExpr,参数为
{GrammarName}Parser.ExprContext - exit{RuleName}()方法:例如,规则名为expr,则方法名为exitExpr,参数为
{GrammarName}Parser.ExprContext
看方法名可以知道,enterExpr()就是在访问到expr这个规则的子树时调用的方法,函数的参数就是子树的树根,exitExpr()就是在访问完expr这个子树时调用的方法,函数的参数就是子树的树根。
一般情况下,开发者不会去修改antlr4生成的Listener文件,而是重新继承{GrammarName}Listener,然后在其中重写enter/exit方法。
在enter/exit方法中,参数是当前遍历的节点,因此,可以使用继承自antlr4.ParserRuleContext的方法访问当前节点的属性和数据:
- getChild(i):获取第i个子节点
- getChildren():获取所有孩子节点
- getChildCount():获取孩子节点的个数
- getText():获取节点的字符串,通常只会在叶子节点才会调用,中间节点调用得到的就是本条规则匹配的字符串
- getParent():获取父节点,只有叶子节点才能调用
- depth():获取当前节点在树中的深度
由于参数是当前节点,并且没有返回值,无法将当前节点的处理后得到的数据往上传递,因此,如果在遍历语法分析树时需要进行数据的传递,需要使用额外的数据结构,例如第一篇文章中的计算器程序,在得到当前节点计算的值后将数据保存到字典中,在处理上层节点时再从字典中读取。
对于Listener,需要使用antlr4.tree.Tree.ParseTreeWalker进行遍历,首先创建一个ParseTreeWalker的对象,然后调用对象的walk()函数遍历,函数的参数是ParseTreeListener和ParseTree,在每个节点类型的ParserRuleContext的派生类{RuleName}Context中,都会有定义两个函数enterRule和exitRule,在调用walk()时其实就会用深度优先遍历的方式遍历每个节点,然后在开始遍历孩子节点前执行enterRule,在遍历完成孩子节点后执行exitRule:
class ParseTreeWalker(object):DEFAULT = Nonedef walk(self, listener:ParseTreeListener, t:ParseTree):"""对树执行深度优先遍历,在遍历当前节点的孩子节点之前,先判断当前节点是否是叶子节点,这里分为错误节点和正确的叶子节点,分别调用listener的visitErrorNode和visitTerminal,因此,可以在我们自己的Listener中增加visitErrorNode和visitTerminal,用于处理叶子节点在遍历孩子节点之前,先执行enterRule,在遍历完所有孩子节点后执行exitRule"""if isinstance(t, ErrorNode):listener.visitErrorNode(t)returnelif isinstance(t, TerminalNode):listener.visitTerminal(t)returnself.enterRule(listener, t)for child in t.getChildren():self.walk(listener, child)self.exitRule(listener, t)def enterRule(self, listener:ParseTreeListener, r:RuleNode):"""执行当前节点的enterRule"""ctx = r.getRuleContext()listener.enterEveryRule(ctx)ctx.enterRule(listener)def exitRule(self, listener:ParseTreeListener, r:RuleNode):"""执行当前节点的exitRule"""ctx = r.getRuleContext()ctx.exitRule(listener)listener.exitEveryRule(ctx)
可以看到,使用这种方式的好处是,开发者只需要编写遍历节点的回调函数,即可自动实现树的遍历,但是没办法控制遍历过程以及实现值的传递。
3.2 Visitor
将g4文件使用命令antlr4 -Dlanguage=Python3 -visitor -no-listener expr.g4就可以得到只有Visitor的代码,生成的代码与Listener的区别就是有一个exprVisitor.py的文件。
exprVisitor.py中是默认生成的vistor:exprVisitor,exprVisitor继承自antlr4.tree.Tree.ParseTreeVisitor。exprVisitor中对于每条规则会生成一个visitor{RuleName}()方法,参数还是{RuleName}Context。
与Listener有所不同,Visitor模式下{RuleName}Context中没有定义enter/exit方法,而是定义了accept(ParseTreeVisitor)方法:
def accept(self, visitor:ParseTreeVisitor):if hasattr( visitor, "visitProg" ):return visitor.visitProg(self)else:return visitor.visitChildren(self)
在accept(ParseTreeVisitor)中,如果ParseTreeVisitor中有visit{RuleName}方法,就会调用visit{RuleName},否则,就会访问孩子节点。
class ParseTreeVisitor(object):# 提供给外部调用的函数# 参数就是树的根节点def visit(self, tree):# 调用的就是节点的accept()函数return tree.accept(self)# 访问孩子节点def visitChildren(self, node):result = self.defaultResult()n = node.getChildCount()for i in range(n):if not self.shouldVisitNextChild(node, result):return resultc = node.getChild(i)childResult = c.accept(self)result = self.aggregateResult(result, childResult)return resultdef visitTerminal(self, node):return self.defaultResult()def visitErrorNode(self, node):return self.defaultResult()def defaultResult(self):return Nonedef aggregateResult(self, aggregate, nextResult):return nextResultdef shouldVisitNextChild(self, node, currentResult):return True
开发者需要基于exprVisitor创建自己的Visitor,重写里面的visitor{RuleName}()方法,在主逻辑中就可以调用Visitor.visit()访问语法分析树:
# 使用输入的字符串创建输入流,然后将输入流给到词法分析器
# 使用词法分析器就得到TokenStream对象
input_stream = InputStream("10+1+1+2\n")
lexer = exprLexer(input_stream)
token_stream = CommonTokenStream(lexer)# 使用TokenStream对象创建antlr4为我们生成的解析器对象
parser = exprParser(token_stream)# prog就是g4语法规则文件的第一条规则
# 因此,调用解析器的prog方法得到语法分析树的根节点
# 在其他程序中也需要使用第一条规则的规则名进行调用
tree = parser.prog()# 创建Visitor,并调用visit访问tree
visitor = Visitor()
print(visitor.visit(tree))
下面是一个简易的计算器程序的Visitor,visitExpr就是访问表达式,如果这个表达式只有一个孩子节点,说明它的孩子节点应该是个叶子节点,也就是经过词法分析匹配得到的操作数,则直接返回该操作数即可,如果这个表达式有3个节点,说明当前子树是个需要计算的表达式,访问第1个孩子,获取操作符左边的值,访问第3个孩子,获取操作符右边的值,然后根据第2个孩子的值进行对应的计算并返回。最后,在主逻辑中打印visitor.visit(tree)就可以得到表达式最终的结果。
class Visitor(exprVisitor):def visitProg(self, ctx:exprParser.ProgContext):if ctx.getChildCount() == 2:return self.visit(ctx.getChild(0))return self.visitChildren(ctx)def visitExpr(self, ctx:exprParser.ExprContext):if ctx.getChildCount() == 1:return ctx.getChild(0).getText()elif ctx.getChildCount() == 3:left = self.visit(ctx.getChild(0))right = self.visit(ctx.getChild(2))if ctx.getChild(1).getText() == "+":return int(left) + int(right)elif ctx.getChild(1).getText() == "-":return int(left) - int(right)elif ctx.getChild(1).getText() == "*":return int(left) * int(right)elif ctx.getChild(1).getText() == "/":return int(left) / int(right)return self.visitChildren(ctx)
可以看到跟Listener的区别在于,使用Visitor的方式可以自己控制是否访问子树,并且可以得到子树的值。
4 总结
- 定义好词法和语法规则,就可以对提供的输入串进行词法分析和语法分析,得到语法分析树
- 语法分析树的非叶子节点的类型是
{RuleName}Context,叶子节点的类型为TerminalNodeImpl,然后使用解析器的第一条规则名作为函数得到树的根节点 - antlr4提供了Listener和Visitor两种机制遍历语法分析树
- Listener中生成的
{RuleName}Context中会增加enterRule()和exitRule()方法,它们分别调用listener中定义的enter{RuleName}和exit{RuleName}方法,ParseTreeWalker.walk(ParseTreeListener, ParseTree)使用深度优先搜索遍历树的根节点,在遍历当前节点的孩子节点之前会调用当前节点的enterRule()方法,在遍历完当前节点的孩子节点后会调用当前节点的exitRule()方法,从而来调用listener中定义的enter{RuleName}和exit{RuleName}方法。这种方式适合不需要传递值的场景,例如,语法检查 - Visitor中生成的
{RuleName}Context中会增加accept(ParseTreeVisitor),在使用ParseTreeVisitor.visit(ParseTree)遍历语法分析树时,就会访问根节点的accept方法,从而访问Visitor中的visit{RuleName}方法,开发人员在重写visit{RuleName}方法时可以使用visit方法得到子树的值,这种方式适合需要在子树和父节点传递值的场景
相关文章:
ANTLR4规则解析生成器(三):遍历语法分析树
文章目录 1 词法分析2 语法分析3 遍历语法分析树3.1 Listener3.2 Visitor 4 总结 1 词法分析 词法分析就是对给定的字符串进行分割,提取出其中的单词。 在antlr4中,词法规则的名称的首字母需要大写,右侧必须是终结符,通常将词法…...

OpenCV实现目标追踪
目录 准备工作 语言: 软件包: 效果演示 代码解读 (1)导入OpenCV库 (2)使用 cv2.VideoCapture 打开指定路径的视频文件 (3)使用 vid.read() 读取视频的第一帧,ret…...

【剑指offer--C/C++】JZ6 从尾到头打印链表
一、题目 二、本人思路及代码 直接在链表里进行翻转不太方便操作,但是数组就可以通过下标进行操作,于是, 思路1、 先遍历链表,以此存到vector中,然后再从后往前遍历这vector,存入到一个新的vector,就完成…...

算法-买卖股票的最佳时机
1、题目来源 121. 买卖股票的最佳时机 - 力扣(LeetCode) 2、题目描述 给定一个数组 prices ,它的第 i 个元素 prices[i] 表示一支给定股票第 i 天的价格。 你只能选择 某一天 买入这只股票,并选择在 未来的某一个不同的日子 卖…...
:EXPLAIN、USE、LOAD、SET、SQL Hints)
【大数据】Flink SQL 语法篇(十):EXPLAIN、USE、LOAD、SET、SQL Hints
《Flink SQL 语法篇》系列,共包含以下 10 篇文章: Flink SQL 语法篇(一):CREATEFlink SQL 语法篇(二):WITH、SELECT & WHERE、SELECT DISTINCTFlink SQL 语法篇(三&…...

Java中List接口常见的实现类
目录 ArrayList实现类 数据存储 构造器 成员方法:CRUD Vector实现类 数据存储 构造器方法 成员方法 LinkedList实现类 数据存储 构造器方法 成员方法CRUD List总结 ArrayList:数组实现,随机访问速度快,增删慢&#x…...

SPI通信
SPI通信: 四根通信线:SCK,MOSI,MISO,SS(从机选择线) 同步时钟,全双工 支持总线挂载多个设备,一主多从 SPI相对IIC传输更快,最简单,最快速 SPI没有接收和应答机制,发送就发…...

【动态规划】【数论】【区间合并】3041. 修改数组后最大化数组中的连续元素数目
作者推荐 视频算法专题 本文涉及知识点 动态规划汇总 数论 区间合并 LeetCode3041. 修改数组后最大化数组中的连续元素数目 给你一个下标从 0 开始只包含 正 整数的数组 nums 。 一开始,你可以将数组中 任意数量 元素增加 至多 1 。 修改后,你可以从…...

字节后端实习 一面凉经
心脏和字节永远都在跳动 深圳还有没有大厂招后端日常实习生啊,求捞~(boss小公司也不理我) 很纠结要不要干脆直接面暑期实习,又怕因为没有后端实习经历,面不到大厂实习。死锁了...

倒计时37天
复习1001. 马走日问题: 1.P1002 [NOIP2002 普及组] 过河卒 - 洛谷 | 计算机科学教育新生态 (luogu.com.cn) //日常碎碎念:谁懂啊,dev突然不能用了,也不知道是哪里出了问题下了五六次都不能用,,,找远程安…...
【计算机考研】考408,还是不考408性价比高?
首先综合考虑,如果其他科目并不是很优秀,需要我们花一定的时间去复习,408的性价比就不高,各个科目的时间互相挤压,如果备考时间不充裕,考虑其他专业课也未尝不可。 复习408本来就是费力不讨好的事情 不同…...

测试入门篇
测试: 这里写目录标题 测试:基础概念:BUG:创建一个合理的bug:bug 的级别:跟开发争执如何解决: 测试用例:编写测试用例的万能公式:案例: 登录功能的测试:设计测试用例的方法: 进阶篇(主要介绍测试方法):自动化测试:自动化测试的分类:selenium( web 自动化测试工具 )环境部署:什么…...

b站小土堆pytorch学习记录—— P25-P26 网络模型的使用和修改、保存和读取
文章目录 一、修改1.方法2.代码 二、保存和读取1.方法2.代码(1)保存(2)加载 3.陷阱 一、修改 1.方法 add_module(name: str, module: Module) -> None name 是要添加的子模块的名称。 module 是要添加的子模块。 调用 add_m…...
[数据结构]OJ用队列实现栈
225. 用队列实现栈 - 力扣(LeetCode) 官方题解:https://leetcode.cn/problems/implement-stack-using-queues/solutions/432204/yong-dui-lie-shi-xian-zhan-by-leetcode-solution/ 首先我们要知道 栈是一种后进先出的数据结构,…...

「优选算法刷题」:最长回文子串
一、题目 给你一个字符串 s,找到 s 中最长的回文子串。 如果字符串的反序与原始字符串相同,则该字符串称为回文字符串。 示例 1: 输入:s "babad" 输出:"bab" 解释:"aba"…...
Java项目:41 springboot大学生入学审核系统的设计与实现010
作者主页:舒克日记 简介:Java领域优质创作者、Java项目、学习资料、技术互助 文中获取源码 项目介绍 本大学生入学审核系统管理员和学生。 管理员功能有个人中心,学生管理,学籍信息管理,入学办理管理等。 学生功能有…...

【数据结构与算法】常见排序算法(Sorting Algorithm)
文章目录 相关概念1. 冒泡排序(Bubble Sort)2. 直接插入排序(Insertion Sort)3. 希尔排序(Shell Sort)4. 直接选择排序(Selection Sort)5. 堆排序(Heap Sort)…...

Unity3D学习之XLua实践——背包系统
文章目录 1 前言2 新建工程导入必要资源2.1 AB包设置2.2 C# 脚本2.3 VSCode 的环境搭建 3 面板拼凑3.1 主面板拼凑3.2 背包面板拼凑3.3 格子复合组件拼凑3.4 常用类别名准备3.5 数据准备3.5.1 图集准备3.5.2 json3.5.3 打AB包 4 Lua读取json表及准备玩家数据5 主面板逻辑6 背包…...

前端技术研究越深入,越觉得技术不是决定录用唯一条件。
一、拒绝抬杠 我说技能不是唯一条件,不是说技能不重要,招聘前端条件是1X,其中1是技能,X是其他条件。 如果X条件很优秀,1这个条件可以降格为0.8、0.5,甚至更低。 有人就抬杠,那为啥不招聘清洁工来干前端&…...

vue组件的重新渲染的问题
目录 1.方式1 2.方式2 1.方式1 修改组件上的key属性 Vue是通过diffing算法比较虚拟DOM和真实DOM,来判断新旧 DOM 的变化。key是虚拟DOM对象的标识,在更新显示时key表示着DOM的唯一性。 DOM是否变化的核心是通过判断新旧DOM的key值是否变化,…...

ESP32硬件IIC驱动SHT30:从零构建温湿度监测组件
1. ESP32与SHT30传感器入门指南 第一次接触ESP32和SHT30温湿度传感器时,我完全被各种专业术语搞晕了。后来在实际项目中摸爬滚打才发现,这套组合其实特别适合物联网开发新手。ESP32就像个全能型选手,自带Wi-Fi和蓝牙,而SHT30则是瑞…...

Windows平台QT BLE开发避坑指南:从环境搭建到稳定通信
1. Windows平台QT BLE开发环境搭建 在Windows平台上使用QT进行BLE开发,首先需要确保开发环境正确配置。我遇到过不少开发者因为环境问题卡在第一步,白白浪费好几天时间。这里分享几个关键点: 编译器选择是第一个坑。实测发现必须使用MSVC编译…...
Translumo:5分钟掌握Windows实时屏幕翻译终极指南
Translumo:5分钟掌握Windows实时屏幕翻译终极指南 【免费下载链接】Translumo Advanced real-time screen translator for games, hardcoded subtitles in videos, static text and etc. 项目地址: https://gitcode.com/gh_mirrors/tr/Translumo 你是否在玩外…...

在线Graphviz图表编辑器:3步创建专业技术流程图
在线Graphviz图表编辑器:3步创建专业技术流程图 【免费下载链接】GraphvizOnline Lets Graphviz it online 项目地址: https://gitcode.com/gh_mirrors/gr/GraphvizOnline 还在为复杂的技术图表绘制而烦恼吗?GraphvizOnline作为一款革命性的在线G…...

并行LLM推理技术:Hogwild! Inference原理与应用
1. 并行LLM推理的技术背景与挑战在传统Transformer架构中,语言模型的推理过程本质上是顺序执行的——每个新token的生成都严格依赖于之前所有token的注意力计算结果。这种串行特性导致两个显著瓶颈:首先,硬件计算资源利用率低下,特…...

All in Token,三个运营商建Token工厂,中国移动跟进Token经营 三大运营商争夺AI阵地
随着Token(词元)经营战略的密集落地,三大运营商在AI领域的竞争愈发激烈。在日前举行的2026移动云大会上,中国移动正式发布了Token运营生态体系与移动模型服务平台MoMA,宣布接入超300款模型,并通过Token集约…...

Windows Cleaner终极指南:3分钟彻底解决C盘爆红问题!
Windows Cleaner终极指南:3分钟彻底解决C盘爆红问题! 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner 还在为Windows系统越用越慢而烦恼吗&…...

Unity游戏开发集成MCP协议:AI助手自动化操作指南
1. 项目概述:Unity游戏开发中的MCP革命如果你是一名Unity开发者,最近可能已经注意到一个名为“CoderGamester/mcp-unity”的项目在GitHub上悄然走红。这不仅仅是一个普通的插件或工具包,它代表了一种全新的工作流范式,旨在将大型语…...

终极指南:3步实现PotPlayer实时字幕翻译,外语视频无障碍观看
终极指南:3步实现PotPlayer实时字幕翻译,外语视频无障碍观看 【免费下载链接】PotPlayer_Subtitle_Translate_Baidu PotPlayer 字幕在线翻译插件 - 百度平台 项目地址: https://gitcode.com/gh_mirrors/po/PotPlayer_Subtitle_Translate_Baidu 还…...

Iris API错误处理机制与嵌入式系统优化实践
1. Iris API错误处理机制解析在嵌入式系统开发中,API的健壮性直接影响整个系统的稳定性。Iris框架作为ARM架构下的核心组件,其错误处理机制基于JSON-RPC 2.0规范进行了深度定制,特别适合资源受限的嵌入式环境。与通用Web API不同,…...