【Flink网络数据传输(4)】RecordWriter(下)封装数据并发送到网络的过程
文章目录
- 一. RecordWriter封装数据并发送到网络
- 1. 数据发送到网络的具体流程
- 2. 源码层面
- 2.1. Serializer的实现逻辑
- a. SpanningRecordSerializer的实现
- b. SpanningRecordSerializer中如何对数据元素进行序列化
- 2.2. 将ByteBuffer中间数据写入BufferBuilder
- 二. BufferBuilder申请资源并创建
- 1. ChannelSelectorRecordWriter创建BufferBuilder
- 2. BroadcastRecordWriter创建BufferBuilder
一. RecordWriter封装数据并发送到网络
1. 数据发送到网络的具体流程
RecordWriter对接入的StreamRecord数据进行序列化并等待下游任务消费的过程,整个过程细节如下。
StreamRecord通过RecordWriterOutput写入RecordWriter,并在RecordWriter中通过RecordSerializer组件将StreamRecord序列化为ByteBuffer数据格式。
RecordWriter
向ResultPartition申请BufferBuilder对象,用于构建BufferConsumer对象,将序列化后的二进制数据存储在申请到的Buffer中。ResultPartition会向LocalBufferPool申请MemorySegment内存块,用于存储Buffer数据。BufferBuilder中会不断接入ByteBuffer数据,
直到将BufferBuilder中的Buffer空间占满,此时会申请新的BufferBuilder继续构建BufferConsumer数据集。Buffer构建完成后,会调用flushTargetPartition()方法,
让ResultPartition向下游输出数据,此时会通知NetworkSequenceViewReader组件开始消费ResultSubPartition中的BufferConsumer对象。当BufferConsumer中Buffer数据被
推送到网络后,回收BufferConsumer中的MemorySegment内存空间,继续用于后续的消息处理。

2. 源码层面
接下来我们从源码的角度了解RecordWriter具体处理数据的逻辑。在RecordWriterOutput中调用pushToRecordWriter方法将数据写出。
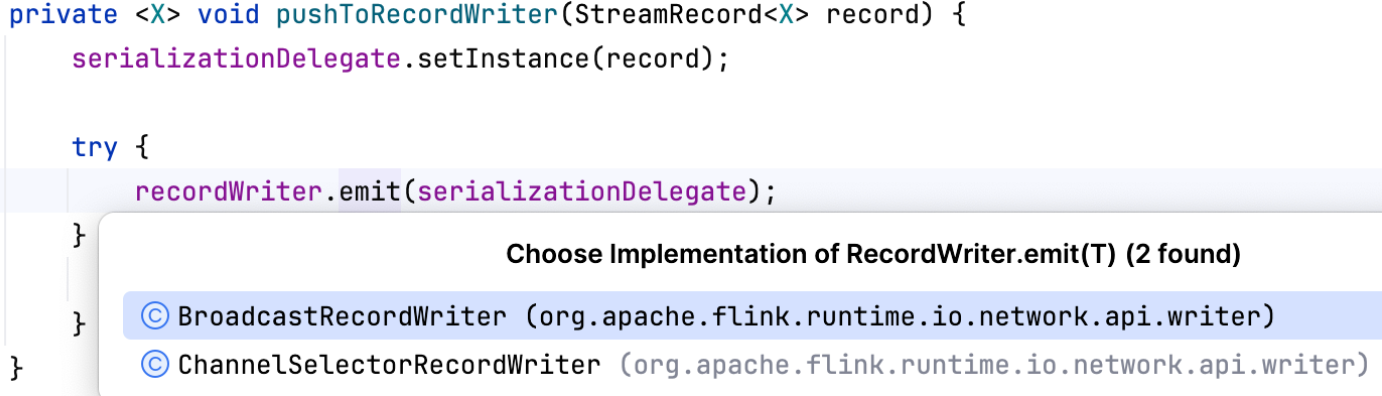
通过recordWriter.emit(serializationDelegate)方法,将数据元素发送到RecordWriter中进行处理。主要逻辑如下
- 序列化数据为ByteBuffer二进制数据,并缓存在SpanningRecordSerializer.serializationBuffer对象中。
- 将序列化器生成的中间数据复制到指定分区中,实际上就是将ByteBuffer数据复制到BufferBuiler对象中。
- 如果BufferBuiler中存储了完整的数据元素,就会清空序列化器的中间数据,因为序列化器中累积的数据不宜过大。
protected void emit(T record, int targetSubpartition) throws IOException { checkErroneous(); targetPartition.emitRecord(serializeRecord(serializer, record), targetSubpartition); if (flushAlways) { targetPartition.flush(targetSubpartition); }
}protected void emit(T record, int targetChannel) throws IOException, InterruptedException {checkErroneous();// 数据序列化serializer.serializeRecord(record);// 将序列化器中的数据复制到指定分区中if (copyFromSerializerToTargetChannel(targetChannel)) {// 清空序列化器serializer.prune();}
}
2.1. Serializer的实现逻辑
接着了解如何将序列化器中的数据转换成Buffer并存储到ResultPartiton中,最终将数据发送到下游。
a. SpanningRecordSerializer的实现
SpanningRecordSerializer实现将序列化后的BytesBuffer数据写入BufferBuilder。
SpanningRecordSerializer对象主要包含了DataOutputSerializer serializationBuffer和ByteBuffer dataBuffer两个成员变量。
- DataOutputSerializer可以将数据转换成二进制格式并存储在byte[]数组中。在serialization中会调用serializationBuffer.wrapAsByteBuffer()方法,将serializationBuffer中生成的byte[]数组转换成ByteBuffer数据结构,并赋值给dataBuffer对象。
- ByteBuffer是Java NIO中用于对二进制数据进行操作的Buffer接口,底层有DirectByteBuffer和HeapByteBuffer等实现,通过ByteBuffer提供的方法,可以轻松实现对二进制数据的操作。
b. SpanningRecordSerializer中如何对数据元素进行序列化
SpanningRecordSerializer.serializeRecord()方法主要逻辑如下。
1)清理serializationBuffer的中间数据,实际上就是将byte[]数组的position参数置为0。
2)设定serialization buffer的初始容量,默认不小于4。
3)将数据元素写入serializationBuffer的bytes[]数组。(所有数据元素都实现了IOReadableWritable接口,可以直接将数据对象转换为二进制格式)
4)获取serializationBuffer的长度信息,并写入serializationBuffer。
5)将serializationBuffer中的byte[]数据封装为java.io.ByteBuffer数据结构,最终赋值到dataBuffer的中间结果中。
public void serializeRecord(T record) throws IOException {if (CHECKED) {if (dataBuffer.hasRemaining()) {throw new IllegalStateException("Pending serialization of previous record.");}}// 首先清理serializationBuffer中的数据serializationBuffer.clear();// 设定serialization buffer数量serializationBuffer.skipBytesToWrite(4);// 将record数据写入serializationBufferrecord.write(serializationBuffer);// 获取serializationBuffer的长度信息并记录到serializationBuffer对象中int len = serializationBuffer.length() - 4;serializationBuffer.setPosition(0);serializationBuffer.writeInt(len);serializationBuffer.skipBytesToWrite(len);// 对serializationBuffer进行wrapp处理,转换成ByteBuffer数据结构dataBuffer = serializationBuffer.wrapAsByteBuffer();
}
Flink 1.12版本中RecordWriter就提供了serializeRecord的能力,没有单拎出来实现。
2.2. 将ByteBuffer中间数据写入BufferBuilder
首先BufferBuilder用于构建完整的Buffer数据。在copyFromSerializerToTargetChannel()方法中实现了将RecordSerializer中的ByteBuffer中间数据写入BufferBuilder的逻辑:
- 对序列化器进行Reset操作,重置初始化位置。
- 将序列化器的ByteBuffer中间数据写入BufferBuilder。
- 判断当前BufferBuilder是否构建了完整的Buffer数据,完成BufferBuilder中Buffer的构建。
- 判断SerializationResult中是否具有完整的数据元素,如果是则将pruneTriggered置为True,然后清空当前的BufferBuilder,并跳出循环。
- 创建新的bufferBuilder,继续从序列化器中将中间数据复制到BufferBuilder中。
- 指定flushAlways参数为True,
调用flushTargetPartition()方法将数据写入ResultPartition。为防止过度频繁地将数据写入ResultPartiton,在RecordWriter中会有独立的outputFlusher线程(在构造器中),周期性地将构建出来的Buffer数据推送到ResultPartiton本地队列中存储,默认延迟为100ms。
protected boolean copyFromSerializerToTargetChannel(int targetChannel) throws IOException, InterruptedException {// 对序列化器进行Reset操作,初始化initial positionserializer.reset();// 创建BufferBuilderboolean pruneTriggered = false;BufferBuilder bufferBuilder = getBufferBuilder(targetChannel);// 调用序列化器将数据写入bufferBuilderSerializationResult result = serializer.copyToBufferBuilder(bufferBuilder);// 如果SerializationResult是完整Bufferwhile (result.isFullBuffer()) {// 则完成创建Buffer数据的操作finishBufferBuilder(bufferBuilder);// 如果是完整记录,则将pruneTriggered置为Trueif (result.isFullRecord()) {pruneTriggered = true;emptyCurrentBufferBuilder(targetChannel);break;}// 创建新的bufferBuilder,继续复制序列化器中的数据到BufferBuilder中bufferBuilder = requestNewBufferBuilder(targetChannel);result = serializer.copyToBufferBuilder(bufferBuilder);}checkState(!serializer.hasSerializedData(), "All data should be written at once");// 如果指定的flushAlways,则直接调用flushTargetPartition将数据写入ResultPartitionif (flushAlways) {flushTargetPartition(targetChannel);}return pruneTriggered;
}
二. BufferBuilder申请资源并创建
1. ChannelSelectorRecordWriter创建BufferBuilder
在ChannelSelectorRecordWriter.getBufferBuilder()方法中定义了BufferBuilder的创建过程。
//1. targetChannel确认数据写入的分区,ID与下游InputGate中的InputChannelID是对应的
//2.
public BufferBuilder getBufferBuilder(int targetChannel) throws IOException, InterruptedException {//在ChannelSelectorRecordWriter中维护了//bufferBuilders[]数组,用于存储创建好的BufferBuilder对象if (bufferBuilders[targetChannel] != null) {return bufferBuilders[targetChannel];} else {//只有在无法从bufferBuilders[]中获取BufferBuilder时,//才会调用requestNewBufferBuilder()方法创建新的BufferBuilder对象。return requestNewBufferBuilder(targetChannel);}
}
requestNewBufferBuilder()方法逻辑如下
- 检查bufferBuilders[]的状态,确保bufferBuilders[targetChannel]为空或者bufferBuilders[targetChannel].isFinished()方法返回值为True。
- 调用targetPartition.getBufferBuilder()方法获取新的BufferBuilder,这里的targetPartition就是前面提到的ResultPartition。
在ResultPartition中会向LocalBufferPool申请Buffer内存空间,用于存储序列化后的ByteBuffer数据。- 向targetPartition添加通过bufferBuilder构建的BufferConsumer对象,bufferBuilder和BufferConsumer内部维护了同一个Buffer数据。BufferConsumer会被存储到ResultSubpartition的BufferConsumer队列中。
- 将创建好的bufferBuilder添加至数组,用于下次直接获取和构建BufferConsumer对象。
public BufferBuilder requestNewBufferBuilder(int targetChannel) throws IOException, InterruptedException {checkState(bufferBuilders[targetChannel] == null || bufferBuilders[targetChannel].isFinished());// 调用targetPartition获取BufferBuilderBufferBuilder bufferBuilder = targetPartition.getBufferBuilder();// 向targetPartition中添加BufferConsumertargetPartition.addBufferConsumer(bufferBuilder.createBufferConsumer(),targetChannel);// 将创建好的bufferBuilder添加至数组bufferBuilders[targetChannel] = bufferBuilder;return bufferBuilder;
}
2. BroadcastRecordWriter创建BufferBuilder
在BroadcastRecordWriter内部创建BufferBuilder的过程中,会将创建的bufferConsumer对象添加到所有的ResultSubPartition中,实现将Buffer数据下发至所有InputChannel,如下代码:
public BufferBuilder requestNewBufferBuilder(int targetChannel) throws IOException, InterruptedException {checkState(bufferBuilder == null || bufferBuilder.isFinished());BufferBuilder builder = targetPartition.getBufferBuilder();if (randomTriggered) {targetPartition.addBufferConsumer(builder.createBufferConsumer(), targetChannel);} else {try (BufferConsumer bufferConsumer = builder.createBufferConsumer()) {for (int channel = 0; channel < numberOfChannels; channel++) {targetPartition.addBufferConsumer(bufferConsumer.copy(), channel);}}}bufferBuilder = builder;return builder;
}
以上步骤就是在RecordWriter组件中将数据元素序列化成二进制格式,然后通过BufferBuilder构建成Buffer类型数据,最终存储在ResultPartition的ResultSubPartition中。
这是从Task的层面了解数据网络传输过程,下篇了解在TaskManager中如何构建底层的网络传输通道。
相关文章:
【Flink网络数据传输(4)】RecordWriter(下)封装数据并发送到网络的过程
文章目录 一. RecordWriter封装数据并发送到网络1. 数据发送到网络的具体流程2. 源码层面2.1. Serializer的实现逻辑a. SpanningRecordSerializer的实现b. SpanningRecordSerializer中如何对数据元素进行序列化 2.2. 将ByteBuffer中间数据写入BufferBuilder 二. BufferBuilder申…...

【牛客】VL74 异步复位同步释放
描述 题目描述: 请使用异步复位同步释放来将输入数据a存储到寄存器中,并画图说明异步复位同步释放的机制原理 信号示意图: clk为时钟 rst_n为低电平复位 d信号输入 dout信号输出 波形示意图: 输入描述: clk为时…...

CSS3笔记
1.相同优先级的样式以写在后面的为主。 2.交集选择器,并且 条件挨在一起 p.rich{...} /*p元素class有rich的元素*/ 3.并集选择器,或者 逗号隔开 .class1,class2{...}/*满足其中一个类名都会使用该样式*/ 4.后代选择器 空格 隔开 所有符合的包括孙子及…...
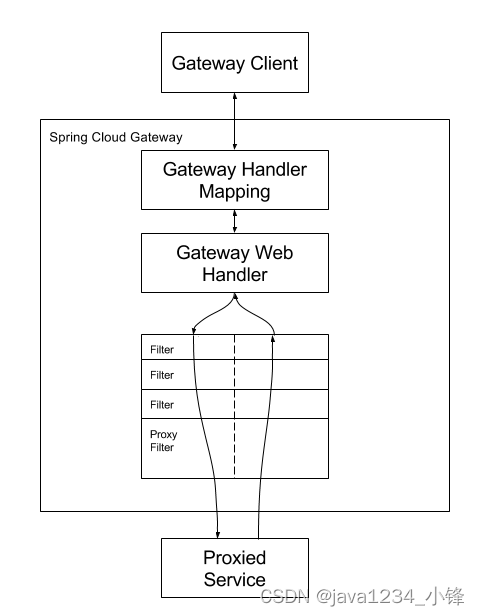
两天学会微服务网关Gateway-Gateway工作原理
锋哥原创的微服务网关Gateway视频教程: Gateway微服务网关视频教程(无废话版)_哔哩哔哩_bilibiliGateway微服务网关视频教程(无废话版)共计17条视频,包括:1_Gateway简介、2_Gateway工作原理、3…...
备忘 clang diagnostic 类的应用示例 ubuntu 22.04
系统的ncurses环境有些问题 通过源码安装了ncurses6.3后,才可以在 llvmort-18.1.rc4中编译通过示例: 1,折腾环境 ncurses-6.3$ ./configure ncurses-6.3$ make -j ncurses-6.3$ sudo make install sudo apt install libtinfo5 sudo…...
Git小册-笔记迁移
Git简介 Git是目前世界上最先进的分布式版本控制系统(没有之一)。 所有的版本控制系统,其实只能跟踪文本文件的改动,比如TXT文件,网页,所有的程序代码等等,Git也不例外。版本控制系统可以告诉…...

【你也能从零基础学会网站开发】Web建站之HTML+CSS入门篇 传统布局和Web标准布局的区别
🚀 个人主页 极客小俊 ✍🏻 作者简介:web开发者、设计师、技术分享 🐋 希望大家多多支持, 我们一起学习和进步! 🏅 欢迎评论 ❤️点赞💬评论 📂收藏 📂加关注 传统布局与…...

005-事件捕获、冒泡事件委托
事件捕获、冒泡&事件委托 1、事件捕获与冒泡2、事件冒泡示例3、阻止事件冒泡4、阻止事件默认行为5、事件委托6、事件委托优点 1、事件捕获与冒泡 2、事件冒泡示例 <!DOCTYPE html> <html lang"en"><head><meta charset"UTF-8" /…...

SpringBoot快速入门(介绍,创建的3种方式,Web分析)
目录 一、SpringBoot介绍 二、SpringBootWeb快速入门 创建 定义请求处理类 运行测试 三、Web分析 一、SpringBoot介绍 我们可以打开Spring的官网(Spring | Home),去看一下Spring的简介:Spring makes Java simple。 Spring发展到今天已经形成了一种…...
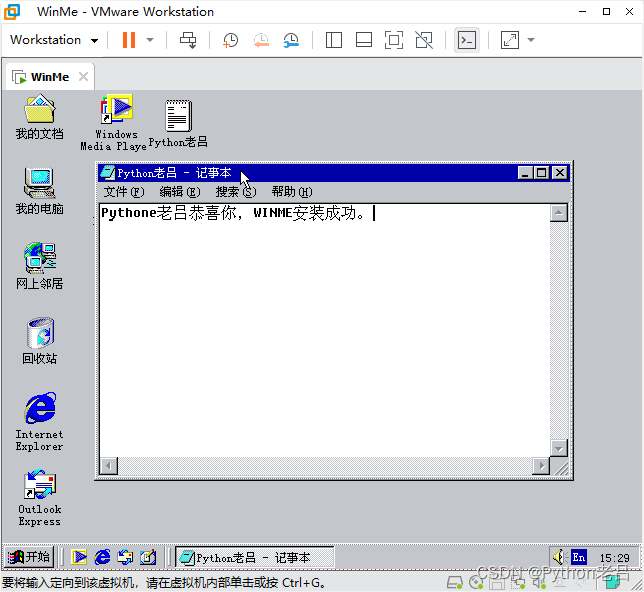
VMwareWorkstation17.0虚拟机搭建WindowsME虚拟机(完整安装步骤详细图文教程)
VMwareWorkstation17.0虚拟机搭建WindowsME虚拟机(完整安装步骤详细图文教程) 一、Windows ME安装准备工作3.1 Windows ME下载地址3.2 DOS软盘版下载地址3.3 UltraISO 4.用VMware虚拟模仿当年的电脑配置4.1 新建虚拟机4.2 类型配置4.3 类型配置4.4 选择版…...
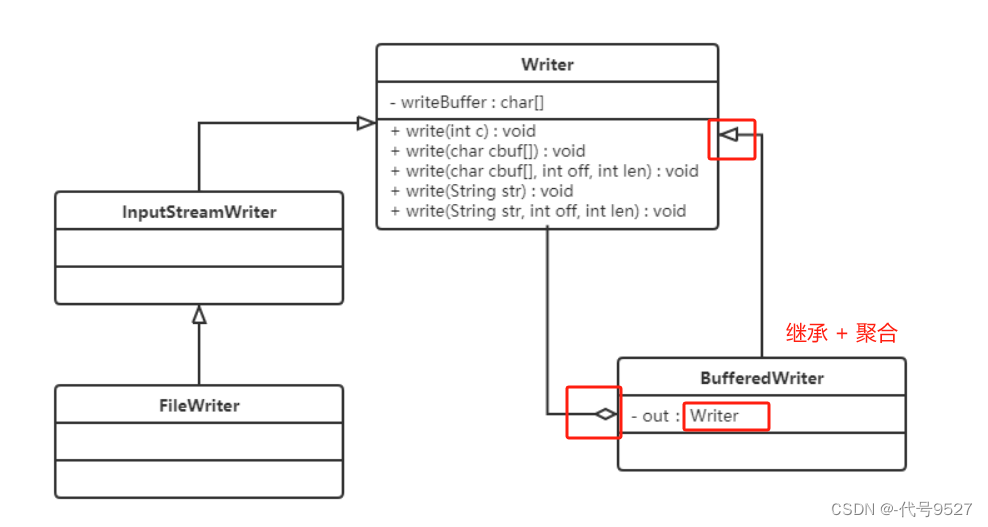
【Java设计模式】八、装饰者模式
文章目录 0、背景1、装饰者模式2、案例3、使用场景4、源码中的实际应用 0、背景 有个快餐店,里面的快餐有炒饭FriedRice 和 炒面FriedNoodles,且加配菜后总价不一样,计算麻烦。如果单独使用继承,那就是: 类爆炸不说&a…...

python INI文件操作与configparser内置库
目录 INI文件 configparser内置库 类与方法 操作实例 导入INI 查询所有节的列表 判断某个节是否存在 查询某个节的所有键的列表 判断节下是否存在某个键 增加节点 删除节点 增加节点的键 修改键值 保存修改结果 获取键值 获取节点所有键值 INI文件 即Initiali…...

软考笔记--软件系统质量属性
一.软件系统质量属性的概念 软件系统的质量就是“软件系统与明确地和隐含的定义的需求相一致的程度”。更具体地说,软件系统质量就是软件与明确地叙述的功能和性能需求文档中明确描述的开发标准以及任何专业开发的软件产品都应该具有的隐含特征相一致的程度。从管理…...
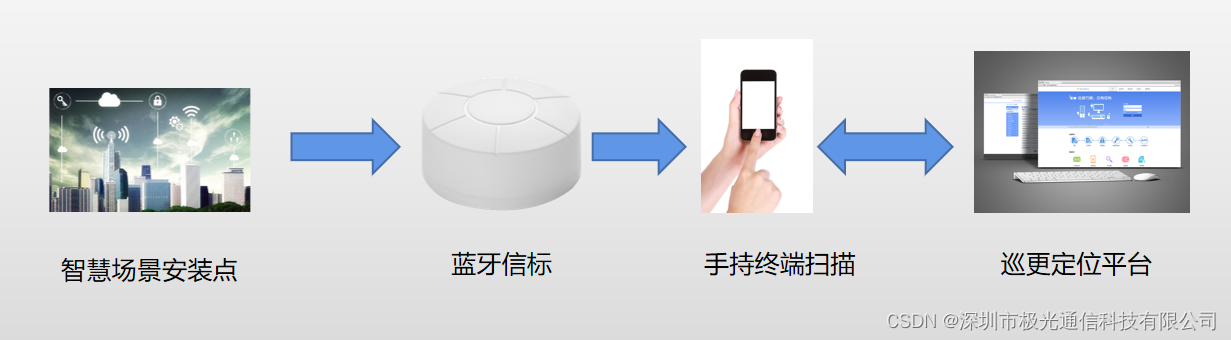
新型设备巡检方案-手机云巡检
随着科技的不断发展,设备巡检工作也在逐步向智能化、高效化方向转变。传统的巡检方式往往需要人工逐个设备检查,耗时耗力,效率低下,同时还容易漏检和误检。而新型设备巡检应用—手机蓝牙云巡检的出现,则为设备巡检工作…...

node.js 下 mysql2 的 CURD 功能极简封装
此封装适合于使用 SQL 直接操作数据库的小型后端项目,更多功能请查阅MySQL2官网 // 代码保存到单独的 js 文件const mysql require(mysql2/promise)const debug true let conn/*** 执行 SQL 语句* param {String} sql* param {*} params* returns {Array}*/ const…...
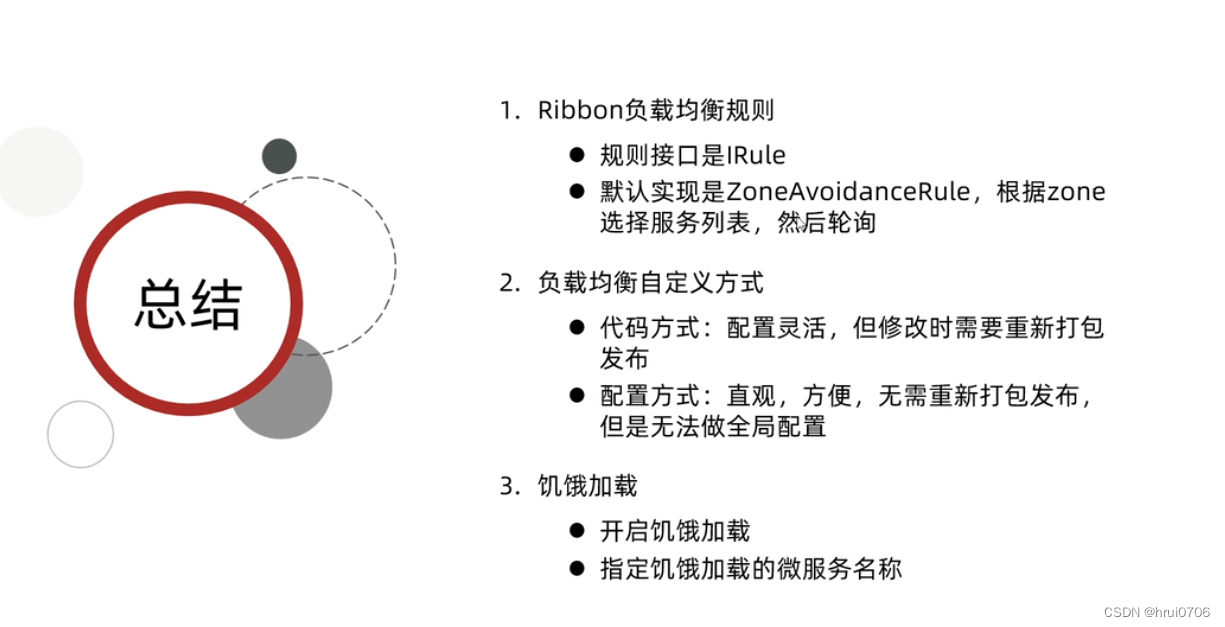
Cloud-Eureka服务治理-Ribbon负载均衡
构建Cloud父工程 父工程只做依赖版本管理 不引入依赖 pom.xml <packaging>pom</packaging><parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>2.3.9.RELEA…...
Northwestern University-844计算机科学与技术/软件工程-机试指南【考研复习】
本文提到的西北大学是位于密歇根湖泊畔的西北大学。西北大学(英语:Northwestern University,简称:NU)是美国的一所著名私立研究型大学。它由九人于1851年创立,目标是建立一所为西北领地地区的人服务的大学。…...

【Linux的网络编程】
1、OSI的七层网络模型有哪些,每一层有什么作用? 答:(1)应用层:负责处理不同应用程序之间的通信,需要满足提供的协议,确保数据发送方和接收方的正确。 (2)表…...

vue-seamless-scroll 点击事件不生效
问题:在使用此插件时发现,列表内容前几行还是能正常点击的,但是从第二次出现的列表开始就没有点击事件了 原因:因为html元素是复制出来的(滚动组件是将后面的复制出来一份,进行填铺页面,方便滚动…...

前端工程部署步骤小记
安装mqtt: “mqtt”: “^4.3.7”, npm install git panjiacheng 后台demo下载zip 1、npm install --registryhttps://registry.npmmirror.com 2、npm run dev 前端demo创建 1、安装npm 2、npm install vuenext 3、npm install -g vue/cli 查看版本 vue --version 4、更新插件…...

深度解析DeepMIMO:毫米波大规模MIMO信道建模的5个架构设计决策
深度解析DeepMIMO:毫米波大规模MIMO信道建模的5个架构设计决策 【免费下载链接】DeepMIMO-matlab DeepMIMO dataset and codes for mmWave and massive MIMO applications 项目地址: https://gitcode.com/gh_mirrors/de/DeepMIMO-matlab 在5G/6G通信系统演进…...

技术难题攻克指南:Retrieval-based-Voice-Conversion-WebUI常见问题全景解析
技术难题攻克指南:Retrieval-based-Voice-Conversion-WebUI常见问题全景解析 【免费下载链接】Retrieval-based-Voice-Conversion-WebUI Easily train a good VC model with voice data < 10 mins! 项目地址: https://gitcode.com/GitHub_Trending/re/Retrieva…...

NAssistant上位机实战:从TOFSense数据解析到固件升级全流程
1. NAssistant上位机初识:连接TOFSense的起点 第一次打开NAssistant上位机时,那个简洁的灰色界面可能会让你觉得无从下手。别担心,我刚开始用的时候也是这样。这个由Nooploop开发的工具其实设计得非常直观,只是需要一点时间来熟悉…...

Legacy iOS Kit终极指南:解锁旧iOS设备的完整控制权
Legacy iOS Kit终极指南:解锁旧iOS设备的完整控制权 【免费下载链接】Legacy-iOS-Kit An all-in-one tool to restore/downgrade, save SHSH blobs, jailbreak legacy iOS devices, and more 项目地址: https://gitcode.com/gh_mirrors/le/Legacy-iOS-Kit 在…...

如何验证Qwen3-4B部署效果?MMLU基准测试实战指南
如何验证Qwen3-4B部署效果?MMLU基准测试实战指南 1. 为什么需要验证模型效果? 当你成功部署了Qwen3-4B模型后,最关心的问题肯定是:这个模型到底表现如何?能不能满足我的需求?这时候就需要一个客观的评估方…...

3步掌握PinWin效率工具:让窗口置顶操作效率提升10倍
3步掌握PinWin效率工具:让窗口置顶操作效率提升10倍 【免费下载链接】PinWin Pin any window to be always on top of the screen 项目地址: https://gitcode.com/gh_mirrors/pin/PinWin 你是否曾在视频会议时手忙脚乱地寻找被覆盖的会议窗口?在多…...

合规刚需下,游戏行业适合的内网通讯软件怎么选
一、背景 2026年,游戏行业在合规监管、信创推进与降本增效三重驱动下,内部协作与数据安全需求持续升级。《数据安全法》《网络安全法》对游戏企业研发代码、运营数据、用户信息的存储与传输提出明确合规要求,数据泄露、权限失控、协作低效等…...

3分钟掌握英雄联盟身份定制:LeaguePrank终极使用指南
3分钟掌握英雄联盟身份定制:LeaguePrank终极使用指南 【免费下载链接】LeaguePrank 项目地址: https://gitcode.com/gh_mirrors/le/LeaguePrank 还在为千篇一律的游戏界面感到乏味吗?想在不违反游戏规则的前提下展示个性风格?LeagueP…...

告别手动记录:清音听真语音识别系统快速部署,中英文混合转录一键搞定
告别手动记录:清音听真语音识别系统快速部署,中英文混合转录一键搞定 1. 系统概述与核心优势 清音听真语音识别系统搭载了Qwen3-ASR-1.7B旗舰引擎,是专为复杂语音场景设计的高精度转录解决方案。相比前代0.6B版本,1.7B参数模型在…...

Serverless时代Java开发者必学的3种函数封装范式:POJO/Function/Consumer,第2种正在被淘汰!
第一章:Serverless时代Java函数计算的演进与定位Serverless 架构正深刻重塑 Java 应用的部署范式。传统 Java 应用依赖长生命周期的 JVM 进程与复杂中间件栈,而函数计算(Function-as-a-Service, FaaS)将执行单元收敛为无状态、事件…...