ElasticSearch学习篇10_Lucene数据存储之BKD动态磁盘树
前言
基础的数据结构如二叉树衍生的的平衡二叉搜索树通过左旋右旋调整树的平衡维护数据,靠着二分算法能满足一维度数据的logN时间复杂度的近似搜索。对于大规模多维度数据近似搜索,Lucene采用一种BKD结构,该结构能很好的空间利用率和性能。
本片博客主要学习常见的多维数据搜索数据结构、KD-Tree的构建、搜索过程以针对高维度数据容灾的优化的BBF算法,以及BKD结构原理。
感受 算法之美 结构之道 吧~
目录
- 多维数据空间搜索结构
- KD-Tree
- BSP树和四叉树的关系
- KD-Tree和BSP的关系
- KD-Tree的原理
- KD-Tree搜索算法优化之BBF算法
- KD-B-Tree
- KD-Tree
- BKD-Tree
一、多维数据空间搜索结构
BKD-Tree是基于KD-B-Tree改进而来,而KD-B-Tree又是KD-Tree和B+Tree的结合体,KD-Tree又是我们最熟悉的二叉查找树BST(Binary Search Tree)在多维数据的自然扩展,它是BSP(Binary Space Partitioning)的一种。B+Tree又是对B-Tree的扩展。以下对这几种树的特点简要描述。
1、KD-Tree
kd是K-Dimensional的所写,k值表示维度,KD-Tree表示能处理K维数据的树结构,当K为1的时候,就转化为了BST结构
维基百科:在计算机科学里,k-d树(k-维树的缩写)是在k维欧几里德空间组织点的数据结构。k-d树可以使用在多种应用场合,如多维键值搜索(例:范围搜寻及最邻近搜索)。k-d树是空间二分算法(binary space partitioning)的一种特殊情况。
首先看BSP,Binary space partitioning(BSP)是一种使用超平面递归划分空间到凸集的一种方法。使用该方法划分空间可以得到表示空间中对象的一个树形数据结构。这个树形数据结构被我们叫做BSP树。
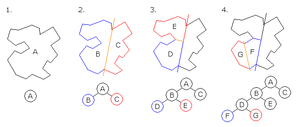
可以分为轴对齐、多边形对齐BSP,这两种方式就是选择超平面的方式不一样,已轴对齐BSP通过构建过程简单理解,就是选择一个超平面,这个超平面是跟选取的轴垂直的一个平面,通过超平面将空间分为两个子空间,然后递归划分子空间。
空间划分思想可以转化为坐标点划分,一般可以应用在游戏中如物体定位等,比如二维空间的四叉树和三维空间的八叉树都是参考BSP划分算法。
1.1、BSP树和四叉树的关系
BSP算法和四叉树的关系
- BSP树:BSP树使用平面进行递归的二分划分,将空间划分为两个子空间。每个节点要么是叶子节点(包含实际对象),要么是内部节点(包含一个分割平面)。分割平面通常由空间中的一条直线表示。
- 四叉树:四叉树将空间划分为四个象限,每个象限都是父节点的子节点。每个节点要么是叶子节点(包含实际对象),要么是内部节点(包含四个子节点)。
四叉树又分为点四叉树和边四叉树,以边四叉树为例,具体的实现源码参考:空间搜索优化算法之——四叉树 - 掘金

1.2、KD-Tree和BSP树的关系
KD-Tree是一种特殊的BSP树,它的特点有:
- 每一层都是一种划分维度,而BSP划分的维度为轴划分、边划分,是同一维度的划分。
- 每个节点代表垂直于当前维度的超平面,将空间划分为两部分
- k维空间,按树的每一层循环选取,当前节点为i维,下一层节点为(i+1)%k维
KD 树(KD-tree)和 BSP 树(Binary Space Partitioning tree)都是用于空间划分的数据结构,但它们有一些关键的区别,这也是为什么 KD 树被认为是 BSP 树的一种特殊情况的原因之一。
- 维度划分方式不同:
- KD 树:KD 树是针对 k 维空间的树形数据结构,它在每个节点上通过轮流选择一个维度来划分空间,例如在二维空间中,它可能在 x 轴上进行一次划分,在 y 轴上进行下一次划分,以此类推。因此,KD 树在每一层都会选择一个维度进行划分。
- BSP 树:BSP 树是一种二叉树,每个节点都代表一个超平面(hyperplane),用于将空间划分为两个子空间。BSP 树的划分方式不一定是轮流选择维度,而是根据一些准则(如最佳平面)选择划分的超平面。
- 节点类型不同:
- KD 树:KD 树的节点可以是叶节点,也可以是非叶节点。非叶节点表示一个划分超平面,叶节点表示一个数据点。
- BSP 树:BSP 树的每个节点都是一个划分超平面,它没有叶节点来表示数据点。
- 适用场景不同:
- KD 树:KD 树主要用于 k 维空间中的最近邻搜索等问题,由于它在每个节点上都选择一个维度进行划分,因此在高维空间中可能会出现维度灾难(curse of dimensionality)的问题。
- BSP 树:BSP 树更通用,可以用于任何维度的空间划分,常用于图形学中的空间分区和碰撞检测等问题。
因此,虽然 KD 树和 BSP 树都是空间划分的数据结构,但由于它们的设计和应用场景有所不同,KD 树被认为是 BSP 树的一种特殊情况。
下面是一个2维度的KD-tree,类似BST,只不过BST是一维的
先KD-Tree适宜处理多维数据,查询效率较高。不难知道一个静态多维数据集合建成KD-Tree后查询时间复杂度是O(lgN)。所有节点都存储了数据本身,导致索引数据的内存利用不够紧凑,相应地数据磁盘存储的空间利用不够充分。
此外KD-Tree不适宜处理海量数据的动态更新。原因和B树不适宜处理多维数据的动态更新的分析差不多,因为KD-Tree的分层划分是依维度依次轮替进行的,动态更新后调整某个中间节点时,变更的当前维度也同样需要调整其全部子孙节点中的当前维度值,导致对树节点的访问和操作增多,操作耗时增大。可见,KD-Tree更适宜处理的是静态场景的多维海量数据的查询操作。
1.3、KD-Tree和KNN算法的联系
KNN算法的实现就可以采KD-Tree:https://blog.csdn.net/v_july_v/article/details/8203674,这篇博客写的很详细,KNN算法简单理解就是给定一个测试元素,根据最靠近的K个元素判断测试元素的分类,当K=1的时候,就转化成了最紧邻算法,KD-Tree结构是支持最紧邻搜索的。
1.4、KD-Tree的原理
学习KD-Tree是如何构建、查询、删除元素的,使用Java实现一个简单二维的KD-Tree结构,实现寻找最近的n个点。
package org.example.kdtree;import java.util.ArrayList;
import java.util.List;/*** @author sichaolong* @createdate 2024/3/14 14:19*/class KDNode {int[] point;KDNode left;KDNode right;public KDNode(int[] point) {this.point = point;this.left = null;this.right = null;}
}public class SimpleKDTreeDemo {private KDNode root;public SimpleKDTreeDemo() {this.root = null;}public void insert(int[] point) {this.root = insertNode(this.root, point, 0);}private KDNode insertNode(KDNode node, int[] point, int depth) {if (node == null) {return new KDNode(point);}int k = point.length;// 选定切割轴int axis = depth % k;if (point[axis] < node.point[axis]) {node.left = insertNode(node.left, point, depth + 1);} else {node.right = insertNode(node.right, point, depth + 1);}return node;}public List<int[]> search(int[] target, int n) {List<int[]> result = new ArrayList<>();searchNode(this.root, target, 0, n, result);return result;}private void searchNode(KDNode node, int[] target, int depth, int k, List<int[]> result) {if (node == null) {return;}// 确定当前层的切割维度int axis = depth % k;if (target[axis] < node.point[axis]) {searchNode(node.left, target, depth + 1, k, result);} else {searchNode(node.right, target, depth + 1, k, result);}// 还没找够n个,就直接添加if (result.size() < k) {result.add(node.point);} else {// 上一个最近的点int[] farthestPoint = result.get(result.size() - 1);// 如果当前点距离更近,就替换if (distance(target, node.point) < distance(target, farthestPoint)) {result.remove(result.size() - 1);result.add(node.point);}}// 如果切割轴距离更近,就添加int[] farthestPoint = result.get(result.size() - 1);// 切割轴距离double splitDistance = Math.abs(target[axis] - node.point[axis]);// 切割轴距离更近if (splitDistance < distance(target, farthestPoint)) {if (target[axis] < node.point[axis]) {searchNode(node.right, target, depth + 1, k, result);} else {searchNode(node.left, target, depth + 1, k, result);}}}// 欧式距离private double distance(int[] point1, int[] point2) {int k = point1.length;double sum = 0;for (int i = 0; i < k; i++) {sum += Math.pow(point1[i] - point2[i], 2);}return Math.sqrt(sum);}public static void main(String[] args) {SimpleKDTreeDemo kdTree = new SimpleKDTreeDemo();int[][] points = {{2, 3}, {5, 4}, {9, 6}, {4, 7}, {8, 1}, {7, 2}};for (int[] point : points) {kdTree.insert(point);}int[] target = {6, 3};int n = 2;// 找出最近的n个点List<int[]> result = kdTree.search(target, n);System.out.println("The " + n + " nearest neighbors to the target point " + java.util.Arrays.toString(target) + " are:");for (int[] point : result) {System.out.println(java.util.Arrays.toString(point));}}
}
构建
树的构建就是依靠递归,对于KD-Tree的构建步骤
- 根据元素各个维度的方差,确定split域作为划分左、右子树的边界
- 确定当前层的根结点,一般是取中间值
- 划分左右子树
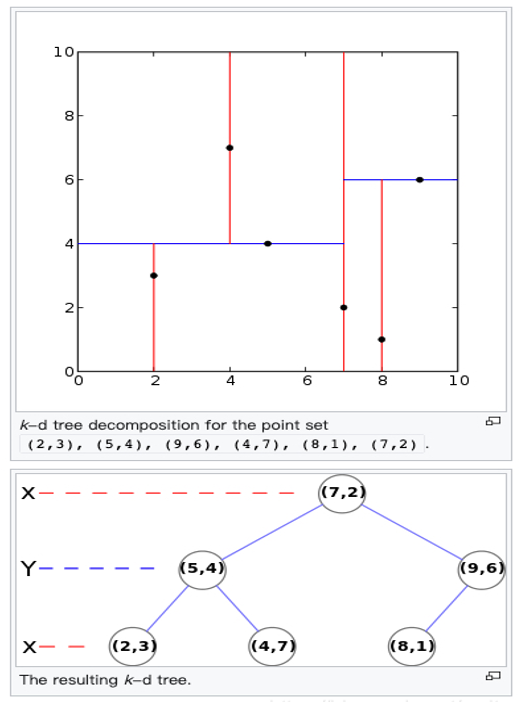
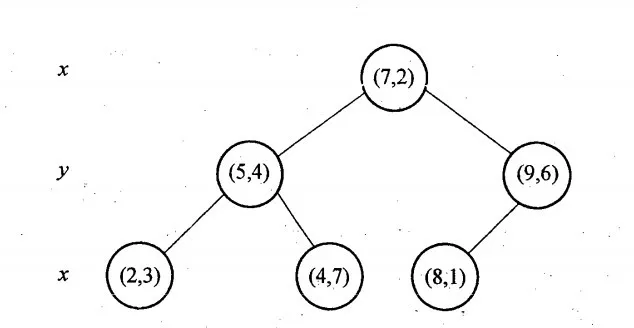
举例KD-Tree的构建过程, 6个二维数据点{(2,3),(5,4),(9,6),(4,7),(8,1),(7,2)}构建kd树的具体步骤为:
- 计算x维度的方差为1.24,y维度的方差为0.83,选定split域为x维度,方差的计算公式
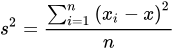
- 确定当前层的根结点为(7,2),经过该点垂直于split域的平面为 分割超平面
- 左子树为(2,3)、(5,4)、(4,7),右子树为(9,6)、(8,1)
然后递归的交替使用x、y维度继续构建左、右子树,最终的结果,奇数层split域为x,偶数层为y。
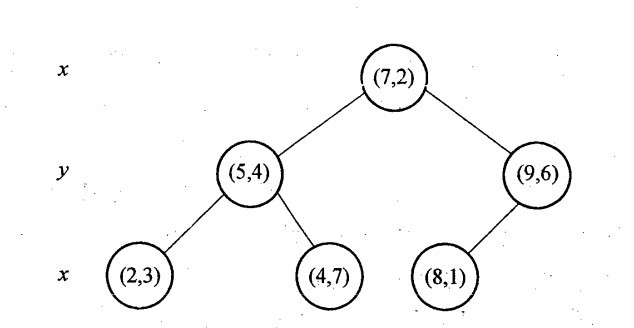
使用x、y坐标轴表示KD-Tree
ps:上面的代码并没第一步,首次插入的节点被定为根节点
搜索
查询最紧邻的点,二维KD-Tree不像BST那样,因为按照维度分层,找到的叶子节点不一定是最紧邻的点,需要回溯,回溯到上一层父节点,查找父节点的其他子空间(分割平面划分的另外一个空间)是否可能有更近的点,依据就是以当前点为圆心,最近的距离为半径画圆,判断是否可能有其他点在圆内(判断的依据就是圆是否触达分割平面,是否包含其他点),距离度量同样使用欧式距离。
搜索过程,如果点是随机分布的,那么搜索的时间复杂度为O(lgN),巧妙的地方就是回溯直接取栈元素就行
- 从根节点递归的向下搜索,各维度交替向左、右子树搜索。
- 找到叶子节点,计算距离,记录为临时最近距离以及临时最近节点target point,因为叶子节点不一定是最紧邻的点。
- 回溯
- 回溯的父节点到搜索节点距离是否小于 临时最近距离,如果小于,更新临时target point。
- 临时最近节点target point为圆点,临时最近距离为r画圆,圆是否和其他维度域分割平面相交,如果相交,需要搜索其他维度区域(假如当前进入的是root的左子树,本来不应该搜索右子树的,但是圆和其他维度空间相交就又可能其他空间有更近的点,需要搜索计算距离和临时最近点比较)
- 回溯到根节点,找到最邻近节点。
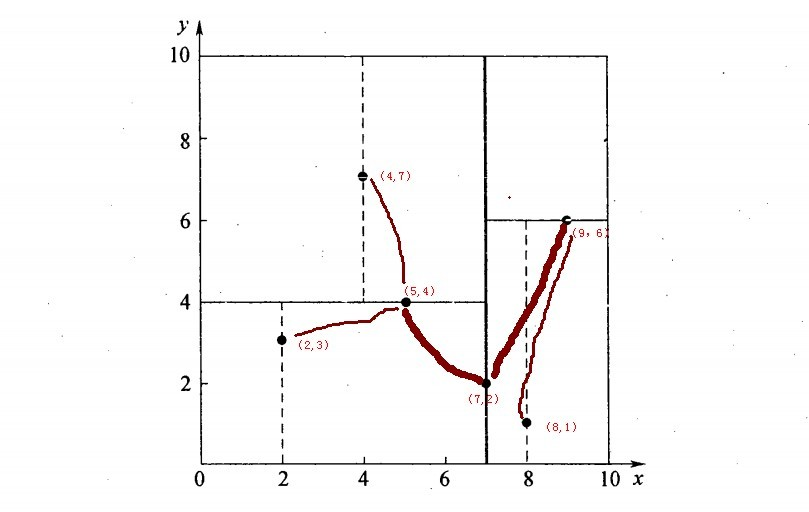
举例,搜索(2.2,3.2)最紧邻的点
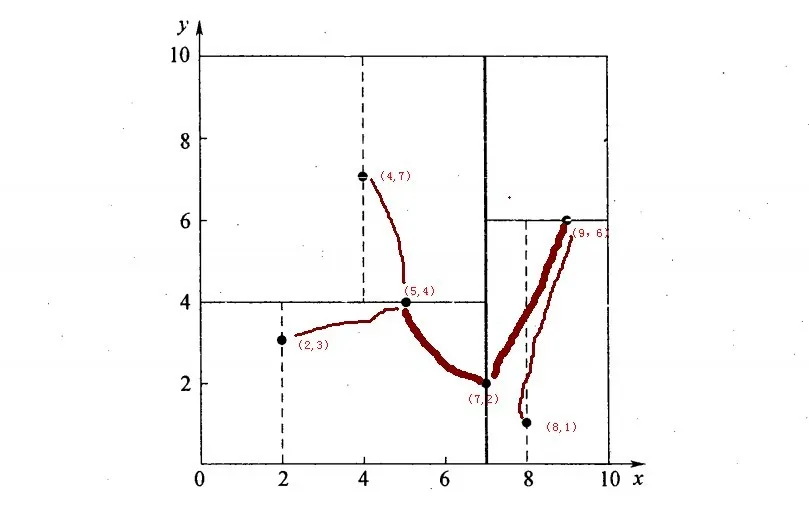
- 首先从根结点(7,2)出发搜索,首先按照x维度为split域,进入左子树(5,4)
- 接着按照y维度为split域名,进入左子树(2,3),找到了叶子节点(2,3),计算欧式距离为0.1414,计算父节点(5,4)距离为2.91 > 0.1414,因此目前target点(2,3)最近距离为0.1414。
- 回溯判断
- 回溯到(5,4)按照(2.1,3.1)以0.1414为半径画圆,发现和y = 4这条分割域平面无交点,继续回溯,
- 回溯到(7,2)按照(2.1,3.1)以0.1414为半径画圆,发现和x = 7这条分割域平面无交点,至此回溯结束。
- 找到最邻近的点为(2,3),最近距离为0.1414
举例,搜索(2,4.5)最紧邻的点
- 首先从根结点(7,2)出发搜索,首先按照x维度为split域,进入左子树(5,4)
- 接着按照y维度为split域名,进入右子树(4,7),找到了叶子节点(4,7),计算欧式距离为3.202,计算父节点(5,4)距离为3.04 < 3.202,因此目前target点(5,4)最近距离为3.04。
- 回溯判断
- 回溯到(5,4)按照(2,4.5)以3.04为半径画圆,发现与y = 4这条分割域平面有交交点,所以需要搜索(5,4)的左空间(2,3),计算(2,3)距离(2,4.5)为1.5 < 3.04,因此目前target点(2,3)最近距离为1.5。
- 回溯到(7,2)按照(2,4.5)以半径1.5画圆,发现不和x = 7 这条分割域平面有交交点,至此回溯结束。
- 找到最邻近的点(2,3),最近距离为1.5。
上面两个demo证明叶子节点不一定是最紧邻的target节点,需要以当前叶子节点(temp target节点) 和 搜素节点 的欧式距离为r画圆,看圆是否和某个split域平面相交,如果相交,还需要去相交域接着找是否存在更紧邻的点,下面就是递归,直到圆和域切割面不在相交,最紧邻的target才找到。
一般来说,叶子节点只需要找几个即可
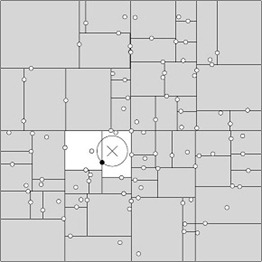
但是当点分布的比较糟糕,就需要递归查找很多域,因此当维数比较多的时候,KD-Tree树的性能会迅速下降,一般数据规模 N >> K平方 才能发挥比较不错的性能,比如100个2维度的点,其中 100 远远大于 2*2;实验结果表明当特征空间的维数超过20 的时候容易线形灾难。
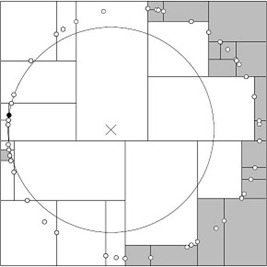
1.5、KD-Tree搜索算法优化之BBF算法
BBF(Best-Bin-First)查询算法,它是由发明sift算法的David Lowe在1997的一篇文章中针对高维数据提出的一种近似算法,此算法能确保优先检索包含最近邻点可能性较高的空间,此外,BBF机制还设置了一个运行超时限定。采用了BBF查询机制后,kd树便可以有效的扩展到高维数据集上。
上述的KD-Tree搜索过程得知,搜索回溯是有查询路径决定的,查询的路径并没有考虑到数据本身的一些性质,减少回溯到其他区域空间的次数,就能一定程度降低搜索计算次数,一个改进的思路就是对数据做一些处理,便于搜素的路径可控,如按各自分割超平面(也称bin)与查询点的距离排序,也就是说,回溯检查总是从优先级最高(Best Bin)的树结点开始。
对于BBF算法,就是把回溯的栈换成了有序的优先队列,然后按照优先队列里面的子树进行递归。
- 首先是为每一层的节点排个优先级,也就是各个节点到当前层计算维度轴的距离,记为abs(q[i]-v),i为当前所选维度,v为到维度轴的距离。
- 搜索节点的时候,使用优先队列记录那些同层未被选择的兄弟节点,或者表兄弟节点。只有搜索到叶子节点才会回溯,才从优先队列取节点,回溯的时候直接从优先队列找,此时找到的基本上是理论最近点。然后递归更新找到的最紧邻的点,直到优先队列为空。
- 找到最紧邻的点。
举例,还是以上面搜索(2,4.5)最紧邻的点
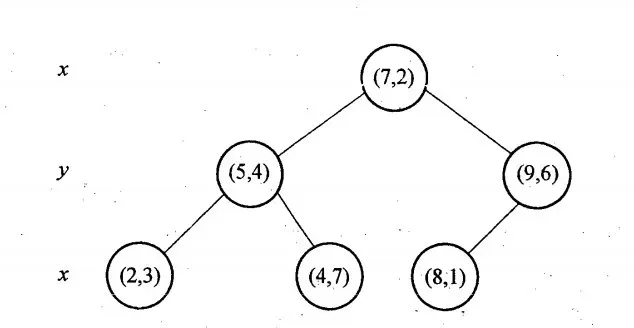
- 首先将根节点放入优先队列。
- 首先从根结点(7,2)出发搜索,首先按照x维度为split域,进入左子树(5,4),此时把右子树根节点(9,6)放入优先队列,此时队列顶元素为(7,2)
- 接着按照y维度为split域名,进入右子树(4,7),将左子树根节点(2,3)放入优先队列,此时队列元素有{(2,3)、(7,2),(5,4)},优先队列队顶元素为(5,4)。找到了叶子节点(4,7),计算欧式距离为3.202,计算父节点(5,4)距离为3.04 < 3.202,因此目前target点(5,4)最近距离为3.04。
- 回溯判断:提取优先队列队顶元素(2,3),重复步骤2,直到优先队列为空。
- 找到最邻近的点(2,3),最近距离为1.5。
ps:针对KD-Tree结构存在的问题,还有很多优化的数据结构如球树、R树、VP树、MVP树。
球树简单理解就是不在像KD-Tree使用split域将整个空间分割成一个个矩形,而是分成了一个个圆形,这样可以很好的处理KD-Tree不能很好的处理位于举矩形空间角落的点。
VP树又叫至高树,而在vpt中,首先从节点中选择一个数据点(可随机选)作为制高点(vp),然后算出其它点到vp的距离大小,最后根据该距离大小将数据点均分为二,递归建树。
R树:https://zh.wikipedia.org/wiki/R%E6%A0%91
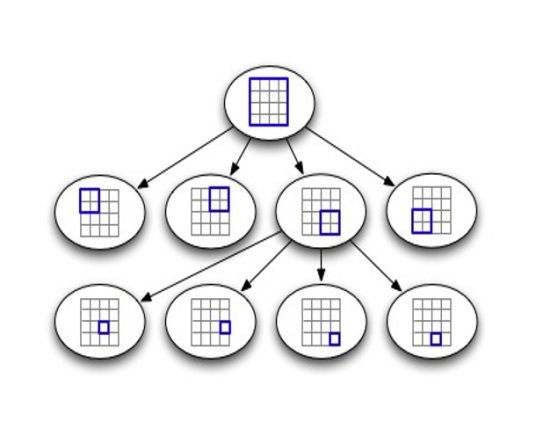
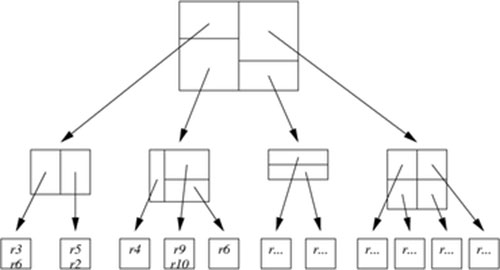
2、KD-B-Tree
KD-B-Tree(K-Dimension-Balanced-Tree)顾名思义,结合了KD-Tree和B+Tree。它主要解决了KD-Tree的二叉树形式树高较高,对磁盘IO不够友好的缺点,引入了B+树的多叉树形式,不仅降低了树高,而且全部数据都存储在叶子节点,增加了磁盘空间存储利用率。一个KD-B-Tree结构的示意图如下。它同样不适宜多维数据的动态更新场景,原因同KD-Tree一样。
二、BKD-Tree
BKD-Tree(或BK-D-Tree,全称是Block-K-Dimension-Tree )
在本文中,我们提出了一种新的索引结构,称为Bkd-tree,用于索引大型多维点数据集。 Bkdtree 是一种基于 kd-tree 的 I/O 高效动态数据结构。我们提出了一项广泛的实验研究的结果,表明与之前将 kd-tree 的外部版本动态化的尝试不同,Bkd-tree 保持了其高空间利用率和出色的性能。查询和更新性能与对其执行的更新数量无关。
// TODO
参考
- kd-tree-维基百科
- 论文 Bkd-Tree: A Dynamic Scalable kd-Tree
- K-D树、K-D-B树、B-K-D树
- 空间索引技术在58搜索中的落地实践 – BKD技术原理深入剖析_ITPUB博客
- 从K近邻算法、距离度量谈到KD树、SIFT+BBF算法
相关文章:
ElasticSearch学习篇10_Lucene数据存储之BKD动态磁盘树
前言 基础的数据结构如二叉树衍生的的平衡二叉搜索树通过左旋右旋调整树的平衡维护数据,靠着二分算法能满足一维度数据的logN时间复杂度的近似搜索。对于大规模多维度数据近似搜索,Lucene采用一种BKD结构,该结构能很好的空间利用率和性能。 …...

运维实习生 - 面经 - 游族网络
2024.3.5 Boss投递 2024.3.6 回复 2024.3.8过初筛 2024.3.13面试 确认候选人姓名 自我介绍 我看你更多是做数据分析的? 你是实习的时候才接触Linux? 软件工程不应该是往开发方面发展的吗? 你最近有做运维方面的工作吗,技术…...
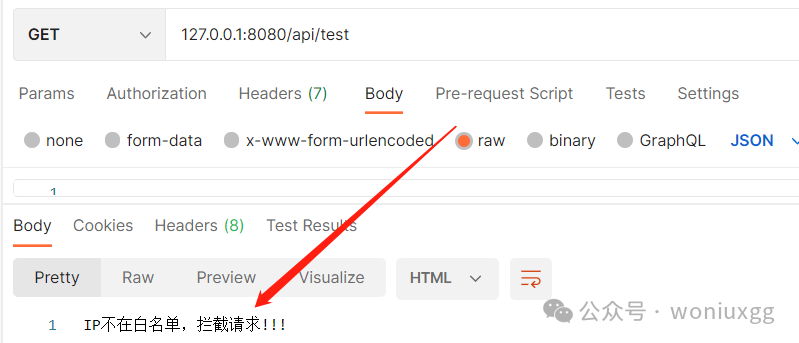
SpringBoot接口添加IP白名单限制
实现流程: 自定义拦截器——注入拦截器——获取请求IP——对比IP是否一致——请求返回 文章背景: 接口添加IP白名单限制,只有规定的IP可以访问项目。 实现思路: 添加拦截器,拦截项目所有的请求,获取请求的…...
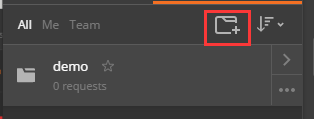
用postman进行web端自动化测试
前言 概括说一下,web接口自动化测试就是模拟人的操作来进行功能自动化,主要用来跑通业务流程。 主要有两种请求方式:post和get,get请求一般用来查看网页信息;post请求一般用来更改请求参数,查看结果是否正…...
基于Java+SpringBoot+vue+element疫情物资捐赠分配系统设计和实现
基于JavaSpringBootvueelement疫情物资捐赠分配系统设计和实现 🍅 作者主页 央顺技术团队 🍅 欢迎点赞 👍 收藏 ⭐留言 📝 🍅 文末获取源码联系方式 📝 文章目录 基于JavaSpringBootvueelement疫情物资捐赠…...
胡桃爱原石)
(差分)胡桃爱原石
琴团长带领着一群胡桃准备出征,进攻丘丘人,出征前,琴团长根据不同胡桃的战力,发放原石作为军饷,琴团长分批次发放,每批次会给连续的几个胡桃发放相同的原石,琴团长最后想知道给每个胡桃发放了多…...
)
二级Java程序题--01基础操作:源码大全(all)
目录 1.基本操作(源代码): 1.1 1.2 1.3 1.4 1.5 1.6 1.7 1.8 1.9 1.10 1.11 1.12 1.13 1.14 1.15 1.16 1.17 1.18 1.19 1.20 1.21 1.22 1.23 1.24 1.25 1.26 1.27 1.28 1.29 1.30 1.31 1.32 1.33 1.34 1.…...
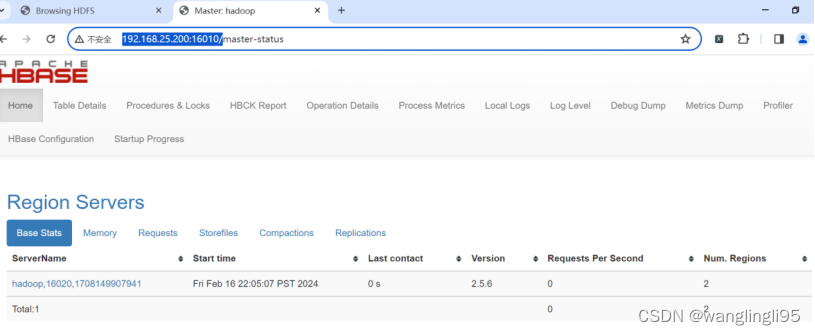
伪分布HBase的安装与部署
1.实训目标 (1)熟悉掌握使用在Linux下安装伪分布式HBase。 (2)熟悉掌握使用在HBase伪分布式下使用自带Zookeeper。 2.实训环境 环境 版本 说明 Windows 10系统 64位 操作电脑配置 VMware 15 用于搭建所需虚拟机Linux系统 …...

Python语言基础与应用-北京大学-陈斌-P40-39-基本扩展模块/上机练习:计时和文件处理-给算法计时-上机代码
Python语言基础与应用-北京大学-陈斌-P40-39-基本扩展模块/上机练习:计时和文件处理-给算法计时-上机代码 上机代码: # 基本扩展模块训练 给算法计时 def factorial(number): # 自定义一个计算阶乘的函数i 1result 1 # 变量 result 用来存储每个数的阶…...
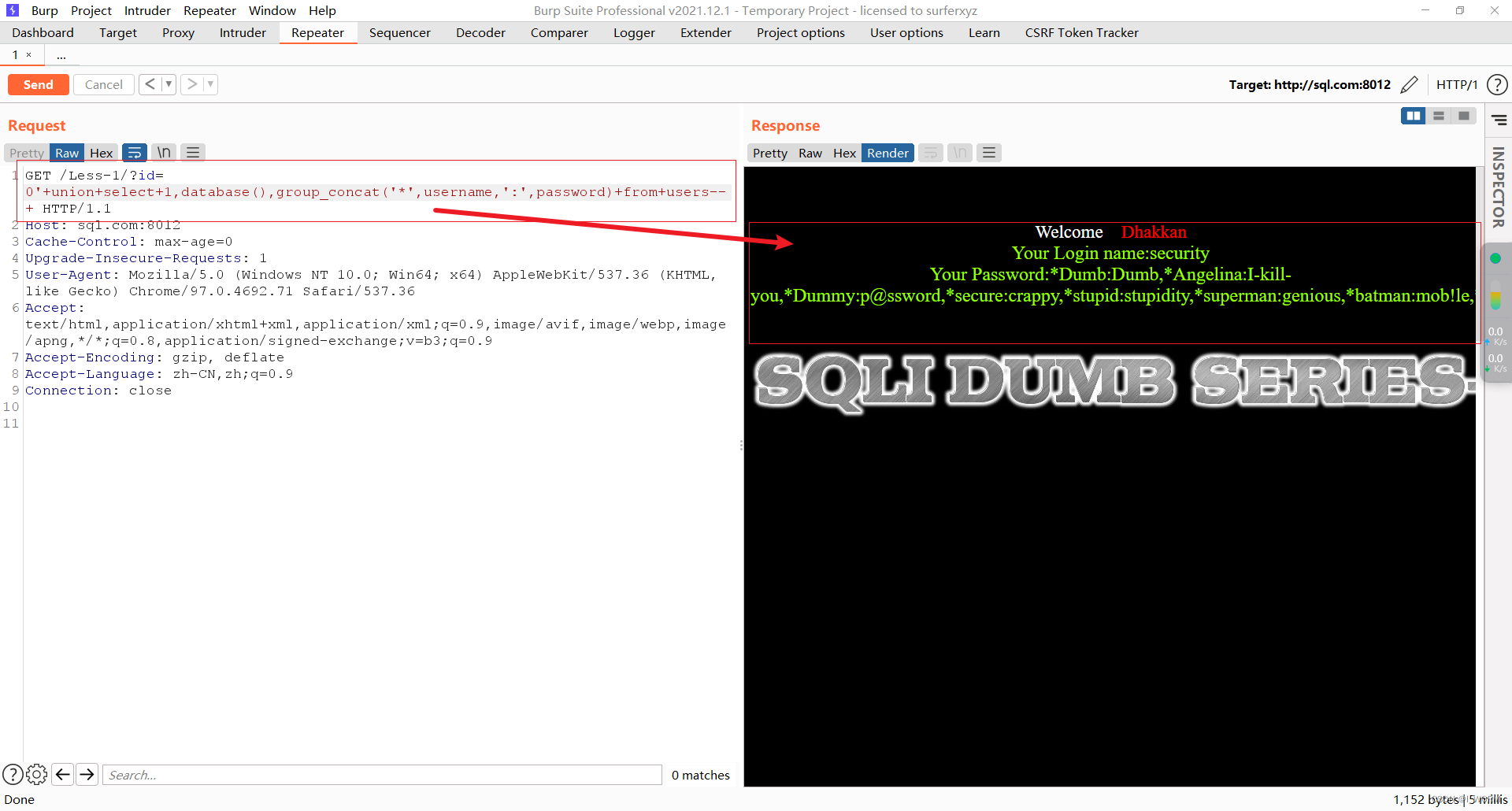
Sqllab第一关通关笔记
知识点: 明白数值注入和字符注入的区别 数值注入:通过数字运算判断,1/0 1/1 字符注入:通过引号进行判断,奇数个和偶数个单引号进行识别 联合查询:union 或者 union all 需要满足字段数一致&…...

【Golang星辰图】图像和多媒体处理的创新之路:Go语言的无限潜能
图像处理、音视频编辑,Go语言不再局限:揭秘opencv和goav的威力 前言: 在当今的数字时代,图像处理和多媒体技术在各个领域中的应用越来越广泛。无论是计算机视觉、图像处理还是音视频处理,选择合适的库和工具至关重要。本文将介绍…...

MES管理系统中电子看板都有哪些类型?
随着工业信息化和智能制造的不断发展,MES管理系统已经成为现代制造业不可或缺的重要工具。MES管理系统通过集成和优化生产过程中的各个环节,实现对生产过程的实时监控、调度和管理,提高生产效率和质量。 在生产制造过程中,看板管…...
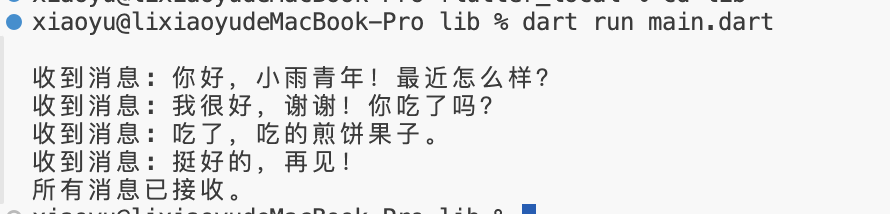
【Flutter 面试题】await for 如何使用?
【Flutter 面试题】await for 如何使用? 文章目录 写在前面解答补充说明完整代码示例运行结果详细说明 写在前面 🙋 关于我 ,小雨青年 👉 CSDN博客专家,GitChat专栏作者,阿里云社区专家博主,51…...

MongoDB聚合运算符:$dayOfWeek
$dayOfWeek返回日期中“星期”的部分,值的范围1-7,即Sunday~Saturday。 语法 { $dayOfWeek: <dateExpression> }参数说明: <dateExpression>为可被解析为Date、Timestamp或ObjectID的表达式<dateExpression>也可以是一个…...

Visual Studio单步调试中监视窗口变灰的问题
在vs调试中,写了这样一条语句 while((nfread(buf, sizeof(float), N, pf))>0) 然而,在调试中,只要一执行while这条语句,监视窗口中的变量全部变为灰色,不能查看,是程序本身并没有报错,能够继…...
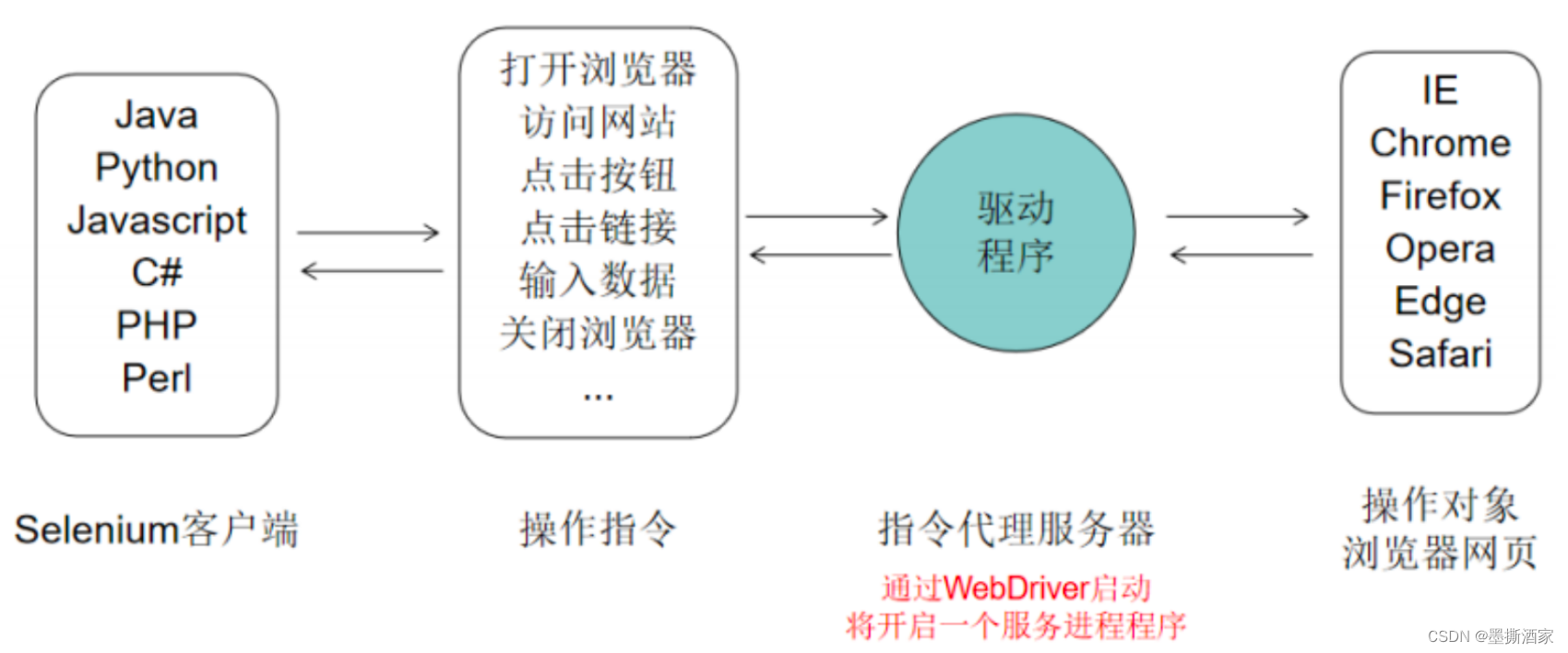
【Selenium】selenium介绍及工作原理
一、Selenium介绍 用于Web应用程序测试的工具,Selenium是开源并且免费的,覆盖IE、Chrome、FireFox、Safari等主流浏览器,通过在不同浏览器中运行自动化测试。支持Java、Python、Net、Perl等编程语言进行自动化测试脚本编写。 官网地址&…...
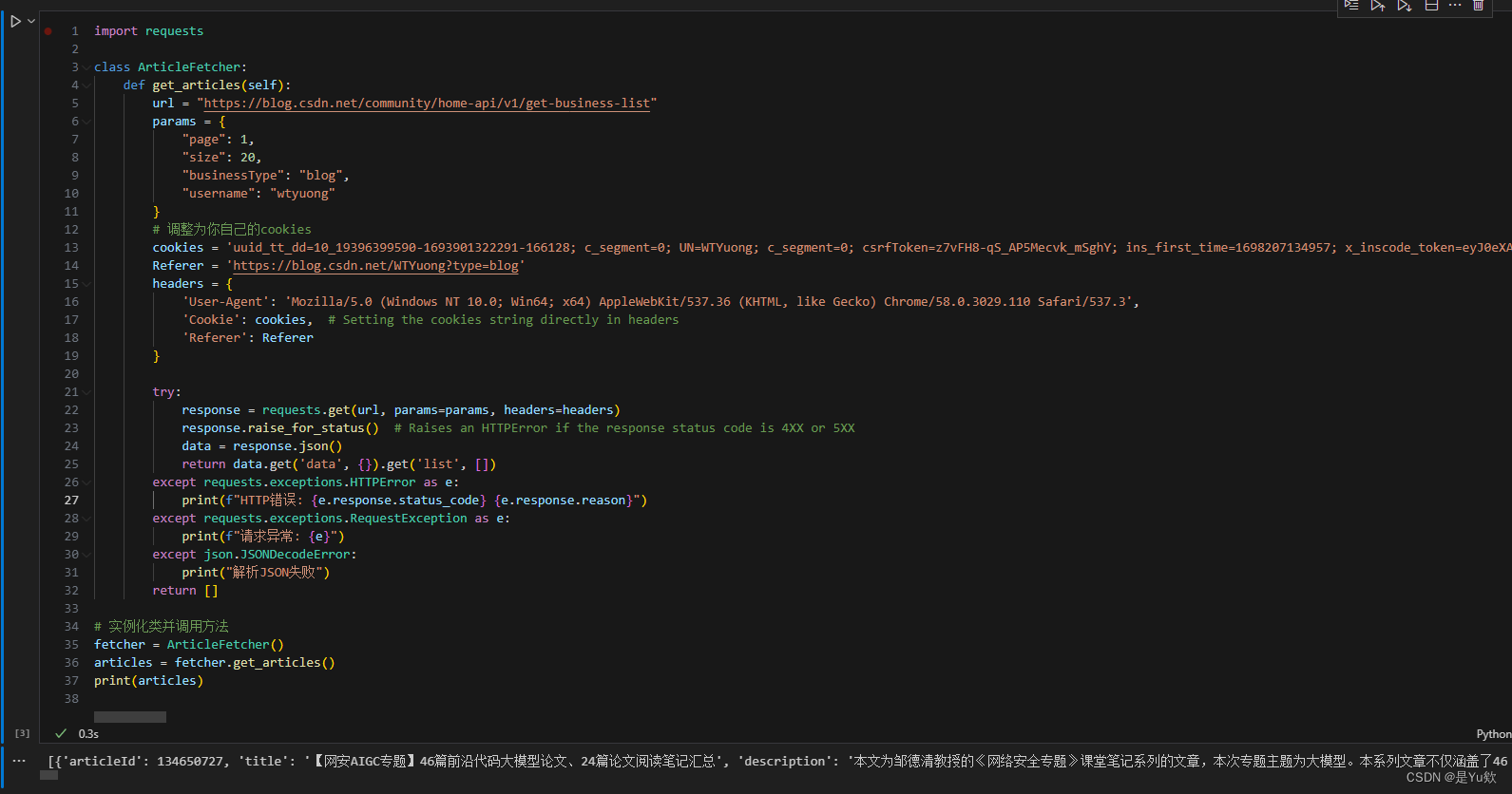
【2024-完整版】python爬虫 批量查询自己所有CSDN文章的质量分:附整个实现流程
【2024】批量查询CSDN文章质量分 写在最前面一、分析获取步骤二、获取文章列表1. 前期准备2. 获取文章的接口3. 接口测试(更新重点) 三、查询质量分1. 前期准备2. 获取文章的接口3. 接口测试 四、python代码实现1. 分步实现2. 批量获取文章信息3. 从exce…...

Nuxt3: useFetch使用过程常见一种报错
一、问题描述 先看一段代码: <script setup> const fetchData async () > {const { data, error } await useFetch(https://api.publicapis.org/entries);const { data: data2, error: error2 } await useFetch(https://api.publicapis.org/entries);…...

当代计算机语言占比分析
在当今快速发展的科技领域,计算机语言作为程序员的工具之一,扮演着至关重要的角色。随着技术的不断演进,各种编程语言层出不穷,但在实际开发中,哪些计算机语言占据主导地位?本文将对当代计算机语言的占比进…...
基于大模型和向量数据库的 RAG 示例
1 RAG 介绍 RAG是一种先进的自然语言处理方法,它结合了信息检索和文本生成技术,用于提高问答系统、聊天机器人等应用的性能。 2 RAG 的工作流程 文档加载(Document Loading) 从各种来源加载大量文档数据。这些文档…...

BFloat16与SME2指令集在AI加速中的应用
1. BFloat16浮点格式解析BFloat16(Brain Floating Point 16)是专为机器学习设计的16位浮点格式,它在保持与32位单精度浮点(FP32)相同指数位宽(8位)的同时,将尾数位从23位缩减到7位。…...

AI给组内同事的脚本能力价值打了1折!
以前一个做了七八年前端设计的工程师,遇到一个简单的VCD波形解析需求,第一反应可能是是找工具组的人或者脚本能力强的人帮忙。这个场景挺普遍的,只是大家都不太好意思说出来。现在有个概念叫 Vibe Coding,核心是借助AI工具&#x…...

从0到1:如何打造一块高精度的工业级隔离数据采集卡?
http://www.z-linear.com 在工业自动化与智能制造的浪潮中,数据采集卡(DAQ)就像是系统的“感官神经”,负责将现实世界的温度、压力、电压、电流等物理量转化为数字世界的数据。然而,在复杂的工业现场,强电…...

uWSGI目录穿越漏洞CVE-2018-7490深度利用与防御
1. 这不是“文件读取”那么简单:uWSGI目录穿越漏洞的真实杀伤半径你可能在Vulfocus靶场里点开CVE-2018-7490这个靶机,输入/..%2f..%2f..%2fetc%2fpasswd,页面返回了一堆用户名,然后就关掉了——觉得“哦,能读文件&…...

Bi-LSTM vs CNN-BiLSTM:实战对比哪个模型更适合你的时间序列预测任务?
Bi-LSTM与CNN-BiLSTM实战抉择:时间序列预测的黄金选择法则当面对时间序列预测任务时,选择正确的模型架构往往能决定项目的成败。Bi-LSTM和CNN-BiLSTM作为两种主流的深度学习模型,各自在特定场景下展现出独特优势。本文将带您深入剖析这两种模…...

Unity2022数字孪生变电站工程包:URP优化+IEC104直连+Win11深度适配
1. 这不是个“能跑就行”的Demo,而是一套可交付的数字孪生工程基线“Unity源码:数字孪生变电站场景,支持Unity2022与Win11运行,完整包”——看到这个标题,我第一反应不是点开下载,而是下意识翻了翻发布者主…...

拆解:我们为宁步建设做南京办公室装修GEO的完整步骤与底层思考
很多南京工装老板现在都有一个共同困惑:网站有、文章发、排名有,就是没有精准咨询。本质原因很简单:传统SEO只“做排名”,而现在的AI搜索GEO是“做答案”。用户现在搜【南京1000平办公室装修】【南京产业园工装公司】,…...

基于Simulink的四开关buck-boost变换器闭环仿真模型
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 🎁…...
(回溯的使用))
今日算法(组合问题III)(回溯的使用)
题目描述找出所有相加之和为 n 的 k 个数的组合,且满足下列条件:只使用数字 1 到 9每个数字 最多使用一次返回所有可能的有效组合的列表,列表不能包含相同的组合两次,组合可以以任何顺序返回核心思路:带双重剪枝的回溯…...

MySQL JSON 类型操作:从入门到不踩坑
开场白 MySQL 5.7 加了 JSON 类型之后,很多人觉得终于可以在关系型数据库里存 JSON 了,不用再拆表了。但说实话,我一开始用 JSON 类型的时候也没少踩坑——查询语法记不住、索引不会建、JSON 路径表达式写错……后来用多了才发现,…...