大数据 - Spark系列《十四》- spark集群部署模式
Spark系列文章:
大数据 - Spark系列《一》- 从Hadoop到Spark:大数据计算引擎的演进-CSDN博客
大数据 - Spark系列《二》- 关于Spark在Idea中的一些常用配置-CSDN博客
大数据 - Spark系列《三》- 加载各种数据源创建RDD-CSDN博客
大数据 - Spark系列《四》- Spark分布式运行原理-CSDN博客
大数据 - Spark系列《五》- Spark常用算子-CSDN博客
大数据 - Spark系列《六》- RDD详解-CSDN博客
大数据 - Spark系列《七》- 分区器详解-CSDN博客
大数据 - Spark系列《八》- 闭包引用-CSDN博客
大数据 - Spark系列《九》- 广播变量-CSDN博客
大数据 - Spark系列《十》- rdd缓存详解-CSDN博客
大数据 - Spark系列《十一》- Spark累加器详解-CSDN博客
大数据 - Spark系列《十二》- 名词术语理解-CSDN博客
大数据 - Spark系列《十三》- spark调度流程(运行过程)-CSDN博客
目录
Spark 程序分布式运行模式
14.1.1 🥙本地测试模式
14.1.2 StandAlone模式
集群安装步骤
spark-submit脚本方式提交
14.1.3 Yarn 模式:client vs cluster模式
1. 简介
2. 🥙 client模式
🍠Cluster和client模式的区别
14.1.4 Mesos/k8s
Mesos模式:
Kubernetes模式:
Spark 程序分布式运行模式
当运行 Spark 程序时,可以选择不同的部署模式,具体取决于集群管理系统和资源调度器。以下是常见的 Spark 程序分布式运行模式:
-
本地测试模式
-
Standalone模式(Client/cluster): spark内置的运行集群
-
Yarn 模式(Client/cluster):在yarn上运行
-
Mesos/k8s : 在mesos集群或者k8s集群上运行
14.1.1 🥙本地测试模式
Idea中
val conf = new SparkConf().setAppName("doe").setMaster("local[*]")虚拟机环境中 (安装包解压即可)
[root@doe01 bin]# ./spark-shell
Welcome to____ __/ __/__ ___ _____/ /___\ \/ _ \/ _ `/ __/ '_//___/ .__/\_,_/_/ /_/\_\ version 3.3.2/_/scala> val rdd = sc.makeRDD(List(1,2,3,4,5,6) , 2)
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at makeRDD at <console>:2314.1.2 StandAlone模式
Spark standalone是一个类似于yarn的资源调度集群,属于spark自己的集群管理 , 规模小, 不通用 ;它构建一个基于 Master+Slaves 的资源调度集群,Spark 任务提交给 Master运行。生产中一般不使用.
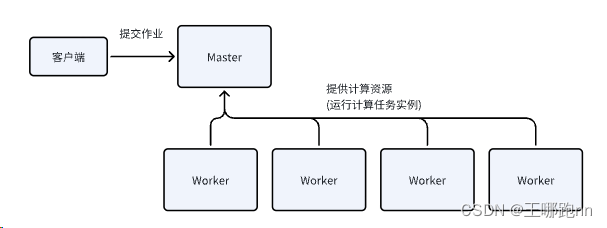
集群安装步骤
1. 上传安装包解压
2. 修改conf下的spark-env.sh
export JAVA_HOME=/opt/apps/jdk1.8
export HADOOP_CONF_DIR=/opt/apps/hadoop-3.1.1/
export YARN_CONF_DIR=/opt/apps/hadoop-3.1.1/ 
3. 修改conf下的workers文件,添加worker节点
hadoop01
hadoop02
hadoop03 
4. 将安装包分发到其他节点
Scp -r 5. 修改系统环境变量
vi /etc/profileexport SPARK_HOME=/opt/apps/spark-3.3.2-bin-hadoop3
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HIVE_HOME/bin:$FLUME_HOME/bi
n:$SQOOP_HOME/bin:$HBASE_HOME/bin:$SPARK_HOME/bin:$SPARK_HOME/sbin
source /etc/profile6. 修改sbin下的指令名
sbin目录下的start-all.sh和stop-all.sh和Hadoop的指令冲突
修改成start-spark.sh stop-spark.sh

7. 启动standalone集群
sbin/start-spark.sh
Jps 可观察到Master worker 进程在浏览器上访问 : http://hadoop02:8080

此界面是standalone集群的监控界面
而每一个application都有一个自己的监控页面
spark-submit脚本方式提交
将自己的程序打包

注意代码中不用指定运行模式和appName
// conf.setAppName("").setMaster()
上传到虚拟机 , 然后将程序提交到 spark自己的集群上
./spark-submit --master spark://hadoop02:7077 \--name test_cf \--executor-cores 2 \--executor-memory 2G \--class com.doit.day0201.CommonFriend_HDFS \/opt/testDemo/Spark_module-1.0-SNAPSHOT.jar 
14.1.3 Yarn 模式:client vs cluster模式
1. 简介
YARN(Yet Another Resource Negotiator)是Apache Hadoop的资源管理器,Spark可以作为YARN应用程序在Hadoop集群上运行。在YARN模式下,Spark应用程序可以以两种方式运行:
-
Client模式:Driver程序运行在提交作业的客户端机器上。
-
Cluster模式:Driver程序运行在YARN集群中的一个容器内,由YARN资源管理器负责资源调度和任务执行。
2. 🥙 client模式
如果部署模式为 client,程序jar包可以放在本地磁盘, 程序初始化是在本地的SparkSubmit中的Driver中进行的
# cluster模式完整示例
# Usage: spark-submit [options] <app jar | python file | R file> [app arguments]
# 注意,cluster模式时,spark-submit先请求standalone获取资源启动driver,然后driver要请求standalone获取资源启动executor(需要jar包)
# 要提前将jar包放到hdfs
bin/spark-submit --master spark://doit01:7077 \
--deploy-mode cluster \
--class cn.doitedu.spark.WordCount \
--name "帅无边男人的帅无边程序" \
--driver-memory 1G \
--executor-memory 2G \
--executor-cores 2 \
--total-executor-cores 6 \
hdfs://doit01:8020/sparkjars/sparktest.jar hdfs://doit01:8020/sparktest/wordcount/input hdfs://doit01:8020/sparktest/wordcount/output3运行起来后,集群中会出现如下独立的进程:

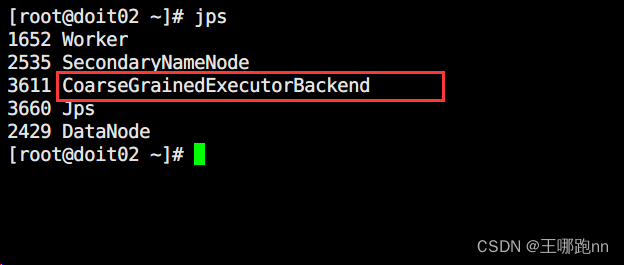
如果部署模式是cluster,DriverWrapper是在某个Worker节点上运行的!所以不使用提交作业机器的内存来做程序的初始化!
🍠Cluster和client模式的区别
区别在于Driver端创建的位置不同。工作过程中用cluster模式
14.1.4 Mesos/k8s
-
Mesos模式:
在Mesos模式下,Mesos作为资源管理器分配资源给Spark应用程序。Mesos负责在集群中启动和管理Executor容器,并分配资源给这些Executor容器以执行Spark任务。
-
Kubernetes模式:
在Kubernetes模式下,Kubernetes作为容器编排平台管理Spark应用程序的资源。Kubernetes启动和管理Executor容器,并根据Spark应用程序的需求动态调整资源。与Mesos模式类似,Kubernetes模式也提供了一种灵活且可扩展的方式来运行Spark作业。
相关文章:
大数据 - Spark系列《十四》- spark集群部署模式
Spark系列文章: 大数据 - Spark系列《一》- 从Hadoop到Spark:大数据计算引擎的演进-CSDN博客 大数据 - Spark系列《二》- 关于Spark在Idea中的一些常用配置-CSDN博客 大数据 - Spark系列《三》- 加载各种数据源创建RDD-CSDN博客 大数据 - Spark系列《…...

考研C语言复习进阶(2)
目录 1. 字符指针 2. 指针数组 3. 数组指针 3.1 数组指针的定义 3.2 &数组名VS数组名 4. 函数指针 5. 函数指针数组 6. 指向函数指针数组的指针 7. 回调函数 8.三步辗转法 9. 指针和数组笔试题解析 10. 指针笔试题 指针的主题,我们在初级阶段的《指…...

设计模式学习笔记 - 设计原则与思想总结:1.总结回顾面向对象、设计原则、编程规范、重构技巧等知识点
概述 对前面的内容的回顾,温故而知新,包括:面向对象、设计原则、规范与重构三个模块的内容。 1.代码质量评判标准 如何评价代码质量的高低? 代码质量的评价具有很强的主观性,描述代码质量的词汇也有很多,…...
WPF图表库LiveCharts的使用
这个LiveCharts非常考究版本,它有非常多个版本,.net6对应的是LiveChart2 我这里的wpf项目是.net6,所以安装的是这三个,搜索的时候要将按钮“包括愈发行版”打勾 git:https://github.com/beto-rodriguez/LiveCharts2?…...

第十三届蓝桥杯省赛C++ C组《全题目+题解》
填空题一般都是找规律题目,耐下心来慢慢分析即可。 第一题《排列字母》 【问题描述】 小蓝要把一个字符串中的字母按其在字母表中的顺序排列。 例如,LANQIAO 排列后为AAILNOQ。 又如,GOODGOODSTUDYDAYDAYUP 排列后为AADDDDDGGOOOOPSTUUYYY。…...

Linux——线程池
目录 线程池的概念 线程池的优点 线程池的实现 【注意】 线程池的线程安全 日志文件的实现 线程池的概念 线程池也是一种池化技术,可以预先申请一批线程,当我们后续有任务的时候就可以直接用,这本质上是一种空间换时间的策略。 如果有任…...
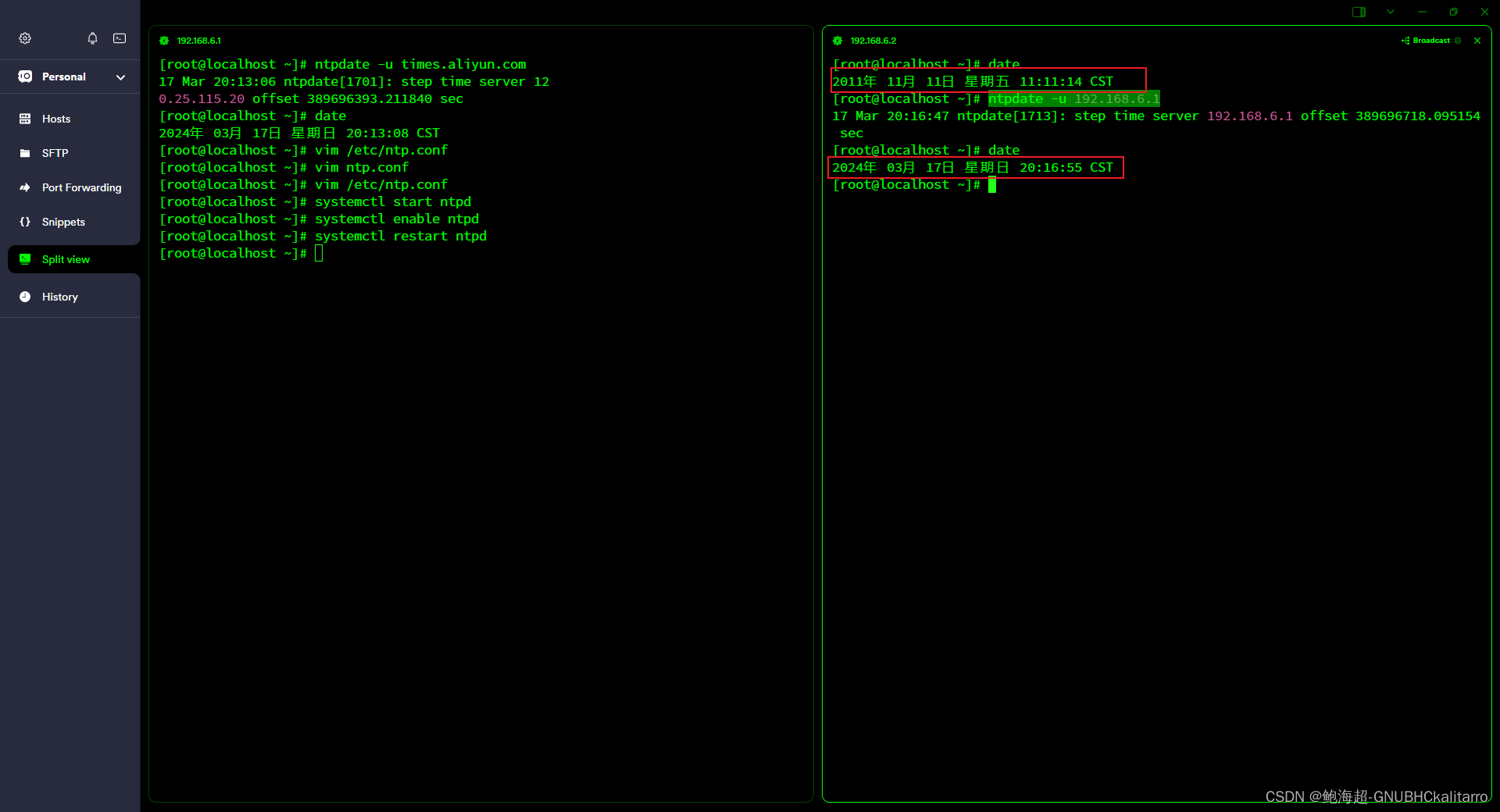
Linux:搭建ntp服务器
我准备两个centos7服务器 一个为主服务器连接着外网,并且搭建了ntp服务给其他主机同步 另外一个没有连接外网,通过第一台设备去同步时间 首先两个服务器都要安装ntp软件 yum -y install ntp 再把他俩的时间都改成别的 左侧的是主服务器,主…...
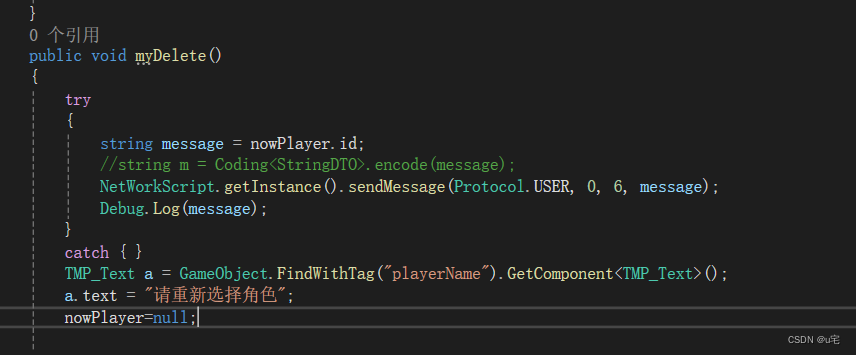
unity学习(57)——选择角色界面--删除角色2
1.客户端添加点击按钮所触发的事件,在selectMenu界面中增加myDelete函数,当点击“删除角色”按钮时触发该函数的内容。 public void myDelete() {string message nowPlayer.id;//string m Coding<StringDTO>.encode(message);NetWorkScript.get…...

Flutter:构建美观应用的跨平台方案
🤍 前端开发工程师、技术日更博主、已过CET6 🍨 阿珊和她的猫_CSDN博客专家、23年度博客之星前端领域TOP1 🕠 牛客高级专题作者、打造专栏《前端面试必备》 、《2024面试高频手撕题》 🍚 蓝桥云课签约作者、上架课程《Vue.js 和 E…...

【深度学习模型移植】用torch普通算子组合替代torch.einsum方法
首先不得不佩服大模型的强大之处,在算法移植过程中遇到einsum算子在ONNX中不支持,因此需要使用普通算子替代。参考TensorRT - 使用torch普通算子组合替代torch.einsum爱因斯坦求和约定算子的一般性方法。可以写出简单的替换方法,但是该方法会…...
鸿蒙 Harmony 初体验
前言 看现在网上传得沸沸扬扬的鸿蒙,打算弄个 hello world 玩一下, 不然就跟不上时代的发展了 环境安装 我的环境 Windows 11 家庭中文版HarmonyOS SDK (API 9)DevEco Studio (3.1.1 Release)Node.js (16.19.1) 开发IDE下载 官方下载链接 配置 nodejs 这里帮…...
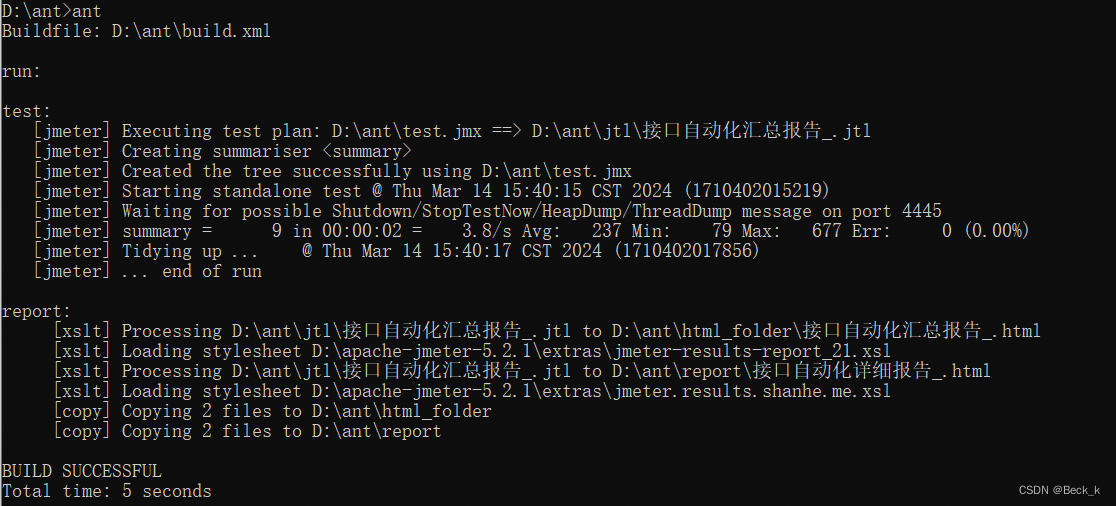
Jmeter+ant,ant安装与配置
1.ant含义 ant:Ant翻译过来是蚂蚁的意思,在我们做接口测试的时候,是可以用来做JMeter接口测试生成测试报告的工具 2.ant下载 下载地址:Apache Ant - Ant Manual Distributions download中选择ant 下载安装最新版zip文件 3.…...

【MySQL基础】MySQL基础操作三
文章目录 🍉1.联合查询🥝笛卡尔积 🍉2.内连接🥝查询单个数据🥝查询多个数据 🍉3.外连接🍉4.自连接🍉5.合并查询 🍉1.联合查询 🥝笛卡尔积 实际开发中往往数…...

【K8s】肿么办??Kubernetes Secrets并不是Secret哟!!
【K8s】肿么办??Kubernetes Secrets并不是Secret哟!! 目录 【K8s】肿么办??Kubernetes Secrets并不是Secret哟!!Kubernetes Secrets为什么不认为 Base64 编码是密文?问题出现了以下是几种加密 K8s Secrets 的选项。Bitnami Sealed Secrets 介绍Bitnami Sealed Secrets…...

数星星 刷题笔记 (树状数组)
依题意 要求每个点 x, y 的左下方有多少个星星 又因为 是按照y从小到大 给出的 所以 我们在计算个数的时候是按照y一层层变大来遍历的 因此我们在处理每一个点的时候 只需要看一下 当前的点有多少个点的x值比当前点小即可 树状数组的 操作模板 P3374 【模板】树…...
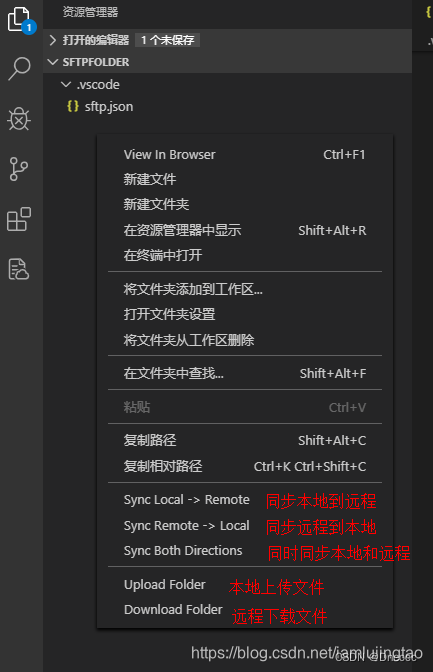
Windows→Linux,本地同步到服务器
适用背景: 用自己电脑修改代码,使用实验室/公司的服务器炼丹的朋友 优势: 本地 <--> 服务器,实时同步,省去文件传输的步骤 本地改 -> 自动同步到服务器 -> 服务器跑代码 -> 一键同步回本地ÿ…...
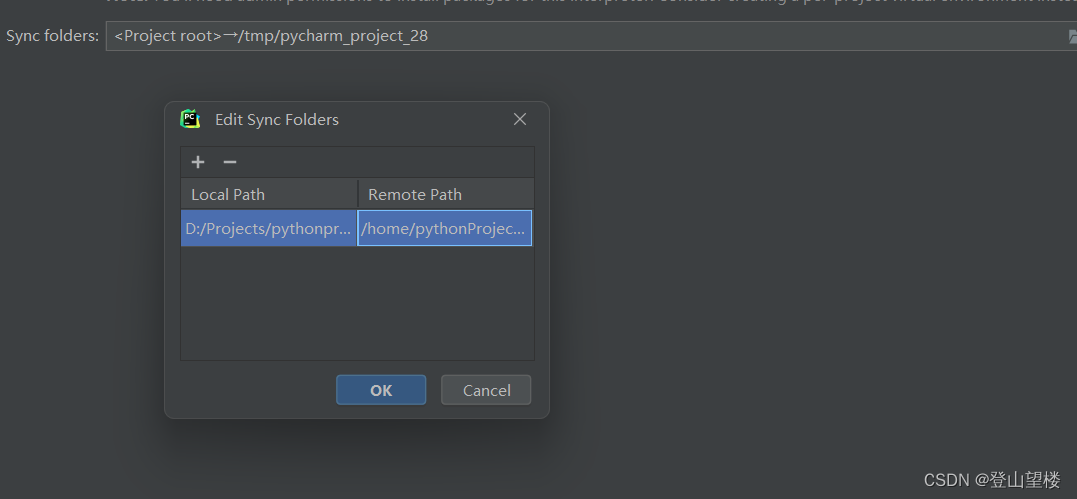
Pycharm连接远程服务器Anoconda中的虚拟环境
在配置远程解释器时,踩过一些坑,现在记录一下配置过程: 步骤1: 打开pycharm的File里面的Settings 里面的Project:你的项目名称目录下的Python Interpreter。 步骤二: 点击右上角的“add interpreter”,选择…...
无人机自动返航算法实现与优化
一、引言 随着无人机技术的快速发展,其在航拍、农业、救援等领域的应用越来越广泛。在这些应用中,无人机的自动返航功能显得尤为重要。一旦无人机失去控制或与遥控器失去连接,自动返航算法能够确保无人机安全返回起飞点,避免损失和…...
切面条-蓝桥杯?-Lua 中文代码解题第1题
切面条-蓝桥杯?-Lua 中文代码解题第1题 一根高筋拉面,中间切一刀,可以得到2根面条。 如果先对折1次,中间切一刀,可以得到3根面条。 如果连续对折2次,中间切一刀,可以得到5根面条。 那么…...
WebRTC:真正了解 RTP 和 RTCP
介绍 近年来,通过互联网进行实时通信变得越来越流行,而 WebRTC 已成为通过网络实现实时通信的领先技术之一。WebRTC 使用多种协议,包括实时传输协议 (RTP) 和实时控制协议 (RTCP)。 RTP负责通过网络传输音频和视频数据,而RTCP负责…...
)
Veo 2提示词效能跃迁实战(工业级Prompt链构建全图谱)
更多请点击: https://codechina.net 第一章:Veo 2提示词编写的核心范式演进 Veo 2作为新一代视频生成模型,其提示词(prompt)工程已从早期的“关键词堆叠”转向结构化、语义分层与意图对齐的复合范式。这一演进并非简…...

艾尔登法环帧率解锁终极指南:告别卡顿,畅享丝滑游戏体验
艾尔登法环帧率解锁终极指南:告别卡顿,畅享丝滑游戏体验 【免费下载链接】EldenRingFpsUnlockAndMore A small utility to remove frame rate limit, change FOV, add widescreen support and more for Elden Ring 项目地址: https://gitcode.com/gh_m…...

[智能体-81]:工程化智能体 = 模型做脑力拆解 + 框架做流程落地。前者是决策者,后者是管理者,tools/function call是内部员工;mcp server是外部资源;
一、全角色人设 & 对应技术组件角色定位对应技术模块核心职责决策者(脑力大脑)大模型 LLM理解目标、任务拆解、逻辑判断、分支决策、内容生成,负责 “想方案、定步骤”管理者(流程总管)智能体编排框架(…...

2026年一键生成论文工具对比实测:5款神器从选题到格式全流程护航
写论文的焦虑,是每个科研人和学生都心照不宣的“隐形压力”。选题无从下手,文献检索耗时费力,逻辑框架反复推翻,格式排版让人抓狂,查重降重更是像在和系统玩“猫鼠游戏”。2026年的AI工具早已不是过去那种“打字机”&a…...
)
别再死磕USB HID了!用ESP32的Arduino框架手把手教你实现蓝牙鼠标键盘(附完整代码)
ESP32蓝牙HID实战:零基础打造自定义键盘鼠标 手里那块吃灰的ESP32开发板终于能派上用场了!上周我用它做了个无线演示控制器,在会议室里走着就能翻PPT,同事们都问是怎么实现的。其实秘诀就在于ESP32的蓝牙HID功能——不需要任何USB…...
)
Unity3D深度纹理实战:手把手教你实现可交互的激光雷达扫描特效(附完整C#/Shader代码)
Unity3D深度纹理实战:手把手教你实现可交互的激光雷达扫描特效(附完整C#/Shader代码)在科幻题材的游戏开发中,激光雷达扫描特效是营造科技感的经典元素。从《赛博朋克2077》的战术目镜到《看门狗》的环境扫描,这种动态…...

避坑指南:Unity中AABB碰撞检测失效的5种常见原因及解决方法
Unity中AABB碰撞检测失效的深度排查与解决方案在Unity开发中,AABB(轴对齐包围盒)碰撞检测是基础但容易出问题的环节。许多开发者都遇到过这样的情况:明明逻辑正确,测试时却出现物体穿透、碰撞时有时无等诡异现象。本文…...

ROS机器人仿真架构解析:基于wpr_simulation的移动操作机器人技术实现
ROS机器人仿真架构解析:基于wpr_simulation的移动操作机器人技术实现 【免费下载链接】wpr_simulation 项目地址: https://gitcode.com/gh_mirrors/wp/wpr_simulation 在机器人操作系统(ROS)开发领域,硬件依赖和测试成本一直是制约算法迭代效率的…...

自动加字幕软件推荐:口播视频如何批量加字幕过
口播视频加字幕,为什么越做越累?一位知识类博主连续两周日更3条口播视频,每条12–18分钟,需手动校对字幕、拆分金句切片、补气口停顿、匹配背景音乐——最后一条视频发布时,字幕错漏率达17%,平台审核未过。…...

基于ESP8266与RGBDigit的Wi-Fi网络时钟:硬件设计、物联网集成与DIY实践
1. 项目概述:一个能感知环境的网络时钟如果你和我一样,对复古又带点科技感的显示设备没有抵抗力,同时又是个喜欢动手折腾的极客,那么这个项目绝对能让你在工作室或家里多一个既实用又炫酷的玩意儿。我说的就是这款基于RGBDigit数码…...