拆解Spring boot:Springboot为什么如此丝滑而简单?源码剖析解读自动装配

🎉🎉欢迎光临,终于等到你啦🎉🎉
🏅我是苏泽,一位对技术充满热情的探索者和分享者。🚀🚀
🌟持续更新的专栏《Spring 狂野之旅:从入门到入魔》 🚀
本专栏带你从Spring入门到入魔
这是苏泽的个人主页可以看到我其他的内容哦👇👇
努力的苏泽![]() http://suzee.blog.csdn.net/
http://suzee.blog.csdn.net/
springboot帮我们做了什么
一个字--自动!
通常搭建一个基于spring的web应用,我们需要做以下工作:
1、pom文件中引入相关jar包,包括spring、springmvc、redis、mybaits、log4j、mysql-connector-java 等等相关jar ...
2、配置web.xml,Listener配置、Filter配置、Servlet配置、log4j配置、error配置 ...
3、配置数据库连接、配置spring事务
4、配置视图解析器
5、开启注解、自动扫描功能
6、配置完成后部署tomcat、启动调试
......
这些都是Spring boot在背后默默为我们做的工作
那 有没有想过为什么?
本文给大家来解读Spring的源码 拆解他的自动配置 一步一步解释为什么Springboot为何那么强大
进入他的细节源码之前 首先关注 ---架构
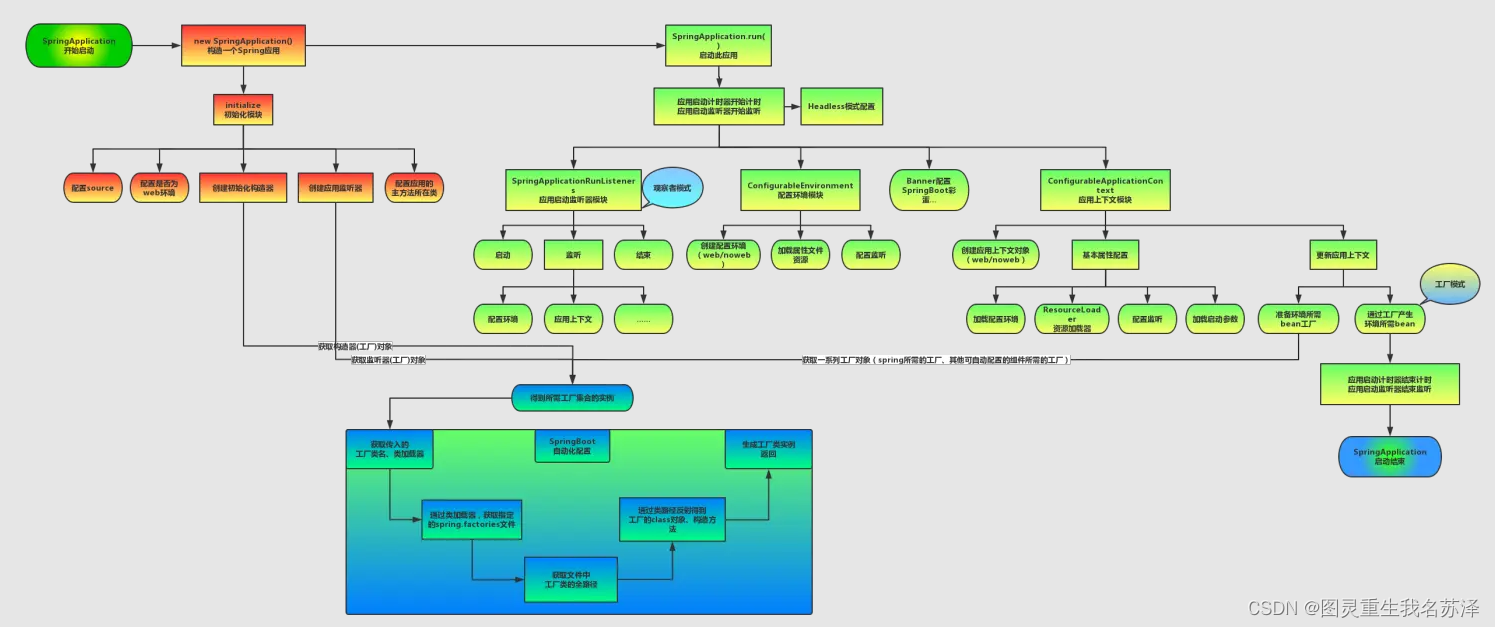
解读SpringBootApplication
@Target(ElementType.TYPE) // 注解的适用范围,其中TYPE用于描述类、接口(包括包注解类型)或enum声明
@Retention(RetentionPolicy.RUNTIME) // 注解的生命周期,保留到class文件中(三个生命周期)
@Documented // 表明这个注解应该被javadoc记录
@Inherited // 子类可以继承该注解
@SpringBootConfiguration // 继承了Configuration,表示当前是注解类
@EnableAutoConfiguration // 开启springboot的注解功能,springboot的四大神器之一,其借助@import的帮助
@ComponentScan(excludeFilters = { // 扫描路径设置(具体使用待确认)@Filter(type = FilterType.CUSTOM, classes = TypeExcludeFilter.class),@Filter(type = FilterType.CUSTOM, classes = AutoConfigurationExcludeFilter.class) })
public @interface SpringBootApplication {
...
}
@Configuration
这里的@Configuration 对我们来说不陌生,它就是 JavaConfig 形式的 Spring Ioc 容器的配置类使用的那个@Configuration,SpringBoot 社区推荐使用基于 JavaConfig 的配置形式,所以,这里的启动类标注了@Configuration 之后,本身其实也是一个 IoC 容器的配置类。 举几个简单例子回顾下,XML 跟 config 配置方式的区别:
表达形式层面 基于 XML 配置的方式是这样:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-3.0.xsd"default-lazy-init="true"><!--bean定义-->
</beans>
而基于 JavaConfig 的配置方式是这样:
@Configuration
public class MockConfiguration{//bean定义
}
任何一个标注了@Configuration 的 Java 类定义都是一个 JavaConfig 配置类。
注册 bean 定义层面 基于 XML 的配置形式是这样:
<bean id="mockService" class="..MockServiceImpl">...
</bean>
而基于 JavaConfig 的配置形式是这样的:
@Configuration
public class MockConfiguration{@Beanpublic MockService mockService(){return new MockServiceImpl();}
}
任何一个标注了@Bean 的方法,其返回值将作为一个 bean 定义注册到 Spring 的 IoC 容器,方法名将默认成该 bean 定义的 id。
表达依赖注入关系层面 为了表达 bean 与 bean 之间的依赖关系,在 XML 形式中一般是这样:
<bean id="mockService" class="..MockServiceImpl"><propery name ="dependencyService" ref="dependencyService" />
</bean><bean id="dependencyService" class="DependencyServiceImpl"></bean>
而基于 JavaConfig 的配置形式是这样的:
@Configuration
public class MockConfiguration{@Beanpublic MockService mockService(){return new MockServiceImpl(dependencyService());}@Beanpublic DependencyService dependencyService(){return new DependencyServiceImpl();}
}
@ComponentScan:
@ComponentScan注解用于指定Spring容器扫描组件的基础包路径。它会自动扫描指定包及其子包下的类,并将被@Component及其派生注解标注的类识别为Spring的组件,将其实例化并纳入容器管理。
// 在包com.example中定义了两个被@Component注解标记的类:UserService和UserRepository// UserService.java
package com.example;import org.springframework.stereotype.Component;@Component
public class UserService {// ...
}// UserRepository.java
package com.example;import org.springframework.stereotype.Component;@Component
public class UserRepository {// ...
}// AppConfig.java
package com.example;import org.springframework.context.annotation.ComponentScan;
import org.springframework.context.annotation.Configuration;@Configuration
@ComponentScan("com.example") // 指定扫描的基础包路径
public class AppConfig {// 配置其他的Bean
}@ComponentScan的原理可以从源代码的角度来解释。在Spring的源代码中,@ComponentScan注解被解析为一个Bean扫描器。当Spring容器启动时,扫描器会根据指定的包路径,将带有@Component及其派生注解的类解析为BeanDefinition对象,并注册到BeanFactory中。这样,Spring容器就知道这些类是组件,并可以对其进行实例化和管理。
@EnableAutoConfiguration:
@EnableAutoConfiguration注解用于启用Spring Boot的自动配置功能。它会根据项目的依赖和配置,自动加载和配置一系列的Spring Bean,简化了项目的配置过程。
@EnableAutoConfiguration的原理可以从源代码的角度来解释。在Spring Boot的源代码中,@EnableAutoConfiguration注解被解析为一个自动配置处理器。当Spring Boot应用启动时,处理器会根据classpath下的META-INF/spring.factories文件中的配置,加载并执行一系列的自动配置类。这些自动配置类根据约定和条件,自动创建和配置相应的Bean对象,完成项目的自动化配置。
Import(AutoConfigurationImportSelector.class)注解:
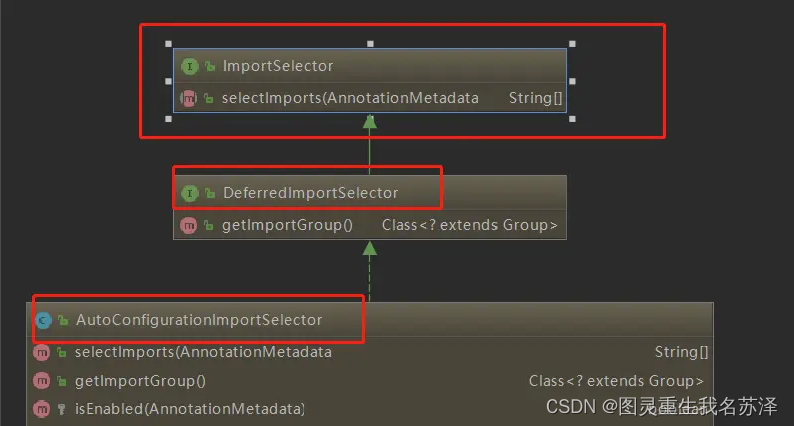
图中看出 AutoConfigurationImportSelector 继承了 DeferredImportSelector 继承了 ImportSelector
ImportSelector有一个方法为:selectImports。
@Overridepublic String[] selectImports(AnnotationMetadata annotationMetadata) {if (!isEnabled(annotationMetadata)) {return NO_IMPORTS;}AutoConfigurationMetadata autoConfigurationMetadata = AutoConfigurationMetadataLoader.loadMetadata(this.beanClassLoader);AnnotationAttributes attributes = getAttributes(annotationMetadata);List<String> configurations = getCandidateConfigurations(annotationMetadata,attributes);configurations = removeDuplicates(configurations);Set<String> exclusions = getExclusions(annotationMetadata, attributes);checkExcludedClasses(configurations, exclusions);configurations.removeAll(exclusions);configurations = filter(configurations, autoConfigurationMetadata);fireAutoConfigurationImportEvents(configurations, exclusions);return StringUtils.toStringArray(configurations);}AutoConfigurationImportSelector是Spring Boot内部的一个选择器类,它会根据项目的依赖和配置,选择要自动配置的类。该选择过程是基于条件注解(如@ConditionalOnClass、@ConditionalOnProperty等)进行的,只有满足条件的自动配置类才会被选择。
@AutoConfigurationPackage
// 在包com.example中定义了一个主配置类ApplicationConfig// ApplicationConfig.java
package com.example;import org.springframework.boot.autoconfigure.AutoConfigurationPackage;
import org.springframework.boot.autoconfigure.SpringBootApplication;@SpringBootApplication
@AutoConfigurationPackage // 标注了@AutoConfigurationPackage注解
public class ApplicationConfig {// 主配置类的内容// ...
}当Spring Boot启动时,它会扫描并解析主配置类ApplicationConfig。在解析过程中,Spring Boot会检测到@AutoConfigurationPackage注解,并执行相应的处理。
@AutoConfigurationPackage注解被解析为一个特殊的Bean定义处理器。处理器会读取主配置类ApplicationConfig的包路径(com.example),并将该包路径注册到Spring的BeanFactory中。
注册完成后,Spring容器会将com.example包及其子包作为组件扫描的范围。这意味着Spring会扫描该包下的所有类,并根据条件注解(如@ConditionalOnClass、@ConditionalOnMissingBean等)来决定是否自动配置相应的Bean。
通过将主配置类所在的包及其子包作为自动配置的包,我们可以确保自动配置类能够正确地扫描和应用到我们的应用程序中。
相关文章:
拆解Spring boot:Springboot为什么如此丝滑而简单?源码剖析解读自动装配
🎉🎉欢迎光临,终于等到你啦🎉🎉 🏅我是苏泽,一位对技术充满热情的探索者和分享者。🚀🚀 🌟持续更新的专栏《Spring 狂野之旅:从入门到入魔》 &a…...
中国银行信息系统应用架构发展历程
概述: 从 20 世纪 80 年代开始至今,我国银行业信息化历程已 有四十年历史。虽然相对于发达国家来讲,我国银行业务信 息化起步较晚,但发展速度很快, 目前我国一些大型商业银行的信息化程度已经处于全球领先水平。 “银行…...
)
掌握Go语言:探索Go语言指针,解锁高效内存操作与动态数据结构的奥秘(19)
指针是一个变量,它存储了另一个变量的地址。在Go语言中,指针提供了直接访问内存地址的能力,允许程序直接操作内存,这在某些场景下非常有用。 Go语言指针的详细使用方法 声明指针 可以使用*符号来声明指针变量,例如&…...
大数据面试题 —— Zookeeper
目录 ZooKeeper 的定义ZooKeeper 的特点ZooKeeper 的应用场景你觉得Zookeeper比较重要的功能ZooKeeper 的选举机制 ***zookeeper主节点故障,如何重新选举?ZooKeeper 的监听原理 ***zookeeper集群的节点数为什么建议奇数台 ***ZooKeeper 的部署方式有哪几…...

【安全类书籍-6】僵尸网络:网络程序杀手
目录 内容 用处 下载链接 内容 这本书着重探讨以下几个主题: 1. 僵尸网络基础:介绍僵尸网络的基本构成、运作机制以及在全球网络空间中的影响和威胁程度。 2. 僵尸网络技术剖析:详细分析僵尸网络的组件,如命令控制中心(C&C)、恶意软件传播途径、感染节点的招募和…...

文件的创建与删除
文件的创建 使用File类创建一个文件对象,例如:File filenew File("c:\\myletter" , "letter.txt"); public boolean createNewFile();/*如果c:\myletter目录中没 有名字为letter.txt文件,文件对象file调用createNewFil…...
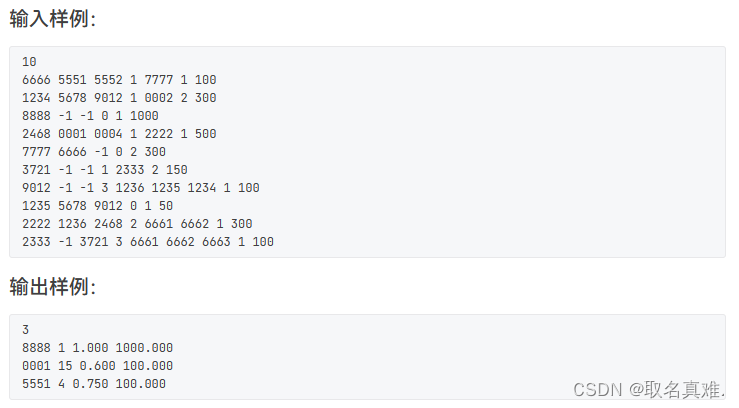
图论题目集一(代码 注解)
目录 题目一: 题目二: 题目三: 题目四: 题目五: 题目六: 题目七: 题目一: #include<iostream> #include<queue> #include<cstring> using namespace st…...

解释MVC和MVVM架构模式
一、解释MVC和MVVM架构模式 MVC和MVVM都是常见的前端架构模式,用于抽象分离并解决特定问题。这两种模式在结构上具有一定的相似性,但在细节和数据处理方式上存在一些差异。 MVC,即Model-View-Controller,是一种用于应用程序分层…...

OLLAMA:如何像云端一样运行本地大语言模型
简介:揭开 OLLAMA 本地大语言模型的神秘面纱 您是否曾发现自己被云端语言模型的网络所缠绕,渴望获得更本地化、更具成本效益的解决方案?那么,您的探索到此结束。欢迎来到 OLLAMA 的世界,这个平台将彻底改变我们与大型…...

React全家桶及原理解析-lesson4-Redux
lesson4-react全家桶及原理解析.mov React全家桶及原理解析 React全家桶及原理解析 课堂⽬标资源起步Reducer 什么是reducer什么是reduceRedux 上⼿ 安装reduxredux上⼿检查点react-redux 异步代码抽取Redux拓展 redux原理 核⼼实现中间件实现redux-thunk原理react-redux原理 实…...

电商api数据接口技术开发来赞达lazada通过商品ID抓取商品详情信息item_get请求key接入演示
要获取Lazada的商品详情,你需要使用item_get请求。首先,你需要注册一个开发者账号并获取API密钥(App Key和App Secret)。然后,你可以使用以下Python代码示例来获取商品详情: # coding:utf-8 ""&…...
-音频焦点2)
零基础入门多媒体音频(2)-音频焦点2
说实话,android的代码是越来越难以阅读。业务函数里面狗皮膏药似的补丁与日俱增。继上篇简要介绍音频焦点的文章,这篇文章的主要内容是分析audiofocus的实现。看了一下午的相关代码都没找到做audiofocus策略的核心逻辑。目前能看懂的大概包含下面两个逻辑…...
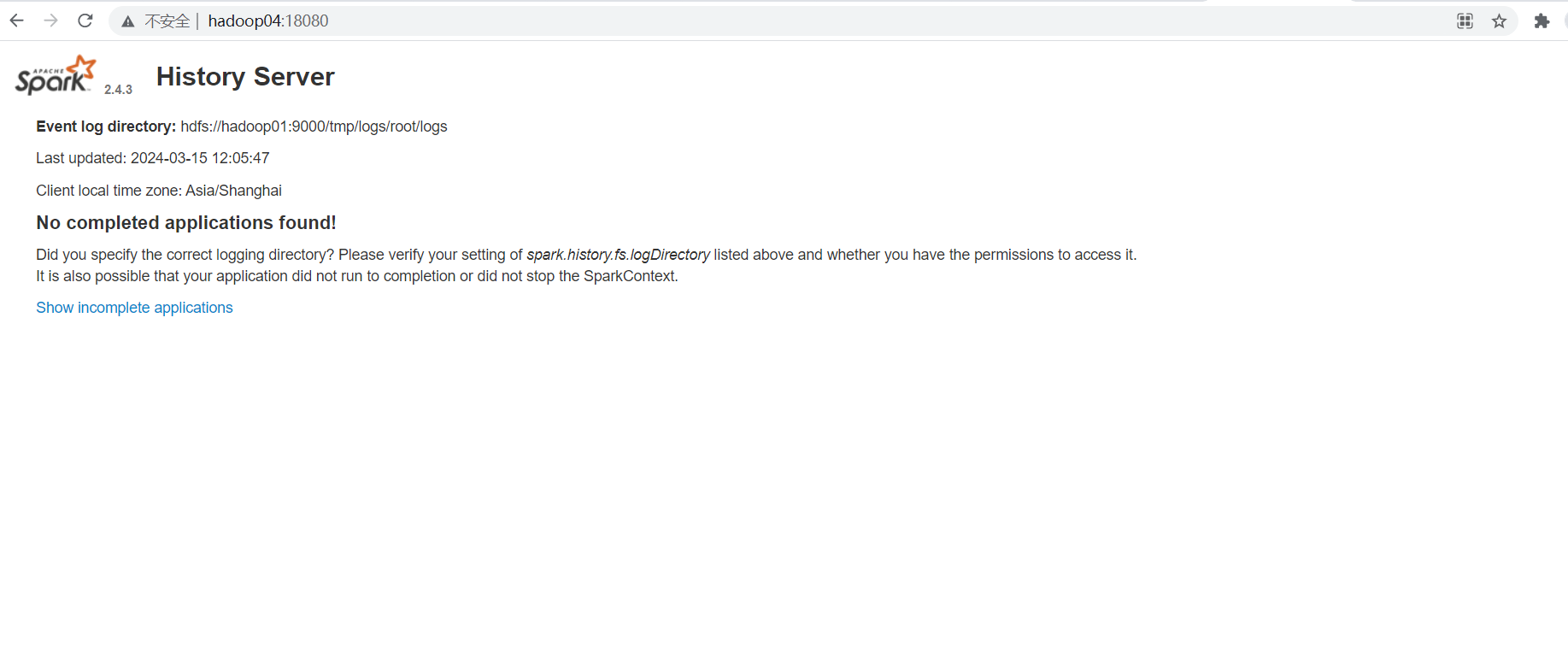
Spark杂谈
文章目录 什么是Spark对比HadoopSpark应用场景Spark数据处理流程什么是RDDSpark架构相关进程入门案例:统计单词数量Spark开启historyServer 什么是Spark Spark是一个用于大规模数据处理的统一计算引擎Spark一个重要的特性就是基于内存计算,从而它的速度…...

【PyTorch】进阶学习:一文详细介绍 torch.save() 的应用场景、实战代码示例
【PyTorch】进阶学习:一文详细介绍 torch.save() 的应用场景、实战代码示例 🌈 个人主页:高斯小哥 🔥 高质量专栏:Matplotlib之旅:零基础精通数据可视化、Python基础【高质量合集】、PyTorch零基础入门教程…...

私域流量运营的关键要素和基本步骤
解锁增长的四大关键: 关键要素一:精准营销 精准营销是私域流量运营的核心所在。通过精细化运营和个性化服务,企业可以将普通用户转化为忠实粉丝,提高用户的粘性和转化率。采用数据驱动的精准营销策略,深度挖掘用户需求…...

k8s部署hadoop
(作者:陈玓玏) 配置和模板参考helm仓库:https://artifacthub.io/packages/helm/apache-hadoop-helm/hadoop 先通过以下命令生成yaml文件: helm template hadoop pfisterer-hadoop/hadoop > hadoop.yaml用kube…...
卡住)
deepspeed分布式训练在pytorch 扩展(PyTorch extensions)卡住
错误展示: Using /root/.cache/torch_extensions/py310_cu121 as PyTorch extensions root... Using /root/.cache/torch_extensions/py310_cu121 as PyTorch extensions root... 错误表现: 出现在多卡训练过程的pytorch 扩展,deepspee…...

Rust 的 HashMap
在 Rust 中,HashMap 是一个从键(key)映射到值(value)的数据结构。它允许你以 O(1) 的平均时间复杂度存储、检索和删除键值对。HashMap 实现了 std::collections::HashMap 结构体,通常通过 use std::collect…...
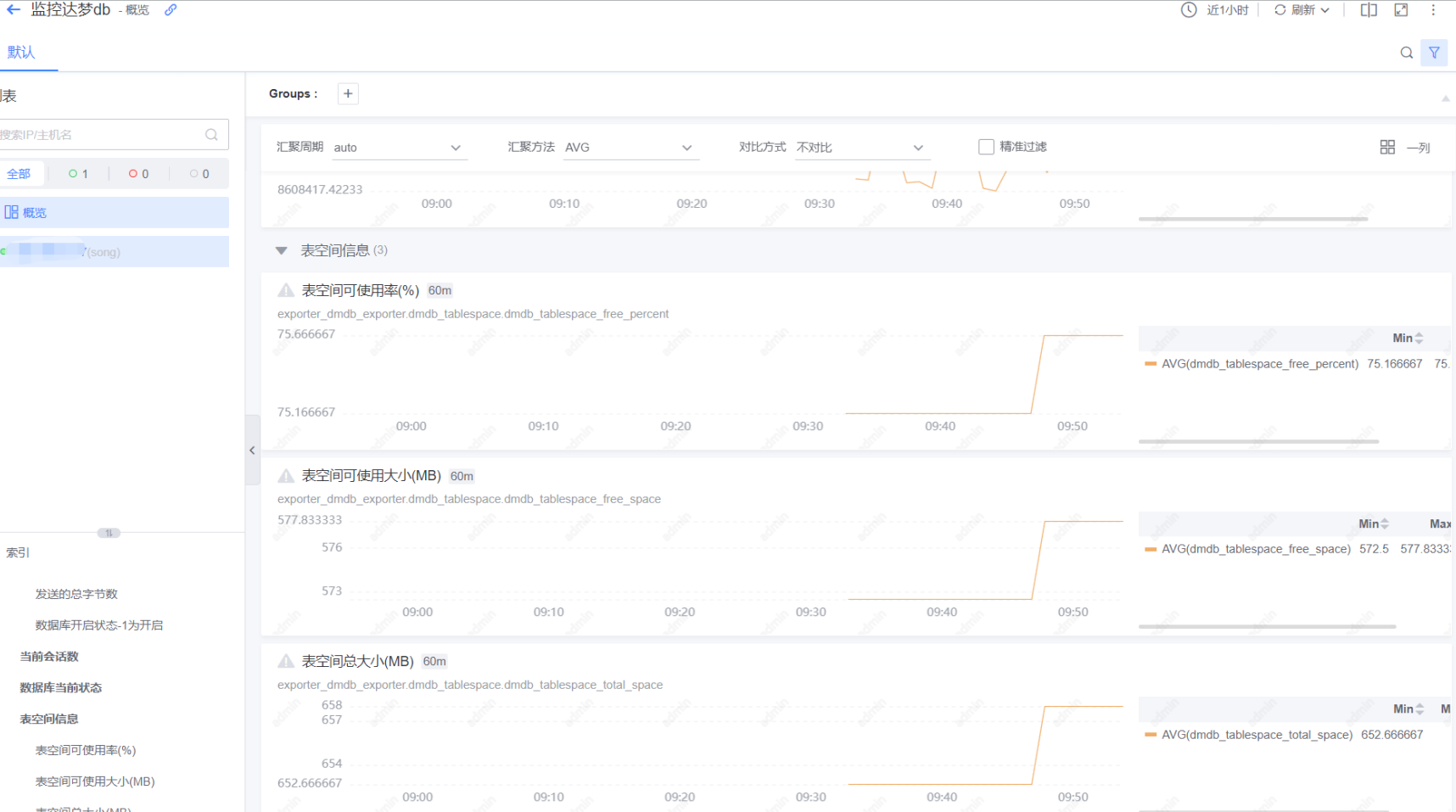
exporter方式监控达梦数据库
蓝鲸监控 随着国产化和信创的深入,开始普遍使用国产化数据库–如达梦数据库,蓝鲸平台默认没有对其进行监控,但是平台了提供监控告警的能力。比如脚本采集,脚本的是一种灵活和快速的监控采集方式,不同层的监控对象都可…...
供应链安全之被忽略的软件质量管理平台安全
背景 随着我国信息化进程加速,网络安全问题更加凸显。关键信息基础设施和企业单位在满足等保合规的基础上,如何提升网络安全防御能力,降低安全事件发生概率?默安玄甲实验室针对SonarQube供应链安全事件进行分析,强调供…...

计算机毕业设计springboot基于java技术的计算机实训室管理系统的设计与实现 基于SpringBoot框架的高校实训室资源预约与信息化管理平台的设计与实现 实验室智能调度与实训过程管理系统
计算机毕业设计springboot基于java技术的计算机实训室管理系统的设计与实现k8svdqb1 (配套有源码 程序 mysql数据库 论文) 本套源码可以在文本联xi,先看具体系统功能演示视频领取,可分享源码参考。随着高校信息化建设的深入推进,传…...

MyBatis 中 CDATA 的实战应用与避坑指南
1. 为什么MyBatis需要CDATA 在MyBatis的日常开发中,我们经常需要在XML映射文件中编写SQL语句。但XML本身对特殊字符有着严格的限制,比如小于号(<)、大于号(>)、和号(&)等字符在XML中都有特殊含义。这就导致了一个很现实的问题:当我…...

网页在线编辑 Office 实现|软航控件集成入门实战①
在 OA、ERP、管理系统开发中,网页在线编辑 Office、在线预览 Word/Excel/PPT/PDF是高频刚需。自己从零开发兼容性差、周期长,集成成熟控件是最快、最稳的方案。本文以软航 Office 文档控件为例,从零到一教你完成 Windows 端集成,新…...
:RAG检索与重排序算法精研|从原理到参数调优,彻底攻克检索瓶颈)
Day25(高阶篇):RAG检索与重排序算法精研|从原理到参数调优,彻底攻克检索瓶颈
Day25(高阶篇):RAG检索与重排序算法精研|从原理到参数调优,彻底攻克检索瓶颈 引言: 进阶篇我们搞定了RAG系统的生产级落地,能满足常规项目的精准问答需求,但如果想让系统达到极致准确…...

新能源企业数字化转型:从“卖设备“到“卖服务“的服务管理实践
在"双碳"目标驱动下,新能源产业正经历从"投建"到"运营服务"的战略转型。光伏、风电、储能等设备遍布全国各地,售后服务与运维效率直接关系到发电收益与品牌口碑。 然而,很多新能源企业面临一个共同的困境&…...

做了十几年财务,我用RPA把最累的工作交给了“机器人”
在财务这行摸爬滚打了十几年,算是一路看着这个行业慢慢“进化”过来的:从最早拿计算器对数据,到后来用电脑做账,从手工账本过渡到ERP系统,再到这两年铺天盖地的“数智化转型”。中间也确实尝试过不少所谓的“黑科技”。…...

百川2-13B-4bits量化版对比测试:OpenClaw日常任务执行效率报告
百川2-13B-4bits量化版对比测试:OpenClaw日常任务执行效率报告 1. 测试背景与动机 最近在折腾OpenClaw自动化工作流时,发现一个棘手问题:当任务链条较长时,本地部署的大模型显存占用会飙升到16GB以上,导致我的RTX 30…...

LCDWIKI SPI图形库:嵌入式TFT-LCD驱动核心架构与实战
1. LCDWIKI SPI 图形库深度解析:面向嵌入式显示驱动的底层架构与工程实践LCDWIKI SPI Library 是一款专为基于 SPI 接口的 TFT-LCD 显示模块设计的轻量级、高兼容性图形驱动核心库。它并非孤立的显示驱动,而是整个 LCDWIKI 显示生态系统的“基石类”&…...

【adb端口5555】烽火hg680系列安卓9线刷全攻略:告别强制升级与花屏困扰
1. 烽火HG680系列机顶盒的痛点与解决方案 最近在折腾烽火HG680-GY和HG680-GC这两款机顶盒的朋友应该都深有体会,官方系统用着用着就会弹出强制升级提示,有时候还会莫名其妙出现花屏问题。作为一个折腾过不下20台烽火盒子的老玩家,我太理解这种…...

2026微软SDE LeetCode高频题:208道,按频度排序,含备考建议
2026微软SDE LeetCode高频题:208道,按频度排序,含备考建议 微软SDE的LeetCode面试题,第一名不是反转链表,不是LRU缓存,而是—— 215. 数组中的第K个最大元素,出现14次。 我整理了基于真实面经…...