【机器学习】基于机器学习的分类算法对比实验



摘要
基于机器学习的分类算法对比实验
本论文旨在对常见的分类算法进行综合比较和评估,并探索它们在机器学习分类领域的应用。实验结果显示,随机森林模型在CIFAR-10数据集上的精确度为0.4654,CatBoost模型为0.4916,XGBoost模型为0.5425,LightGBM模型为0.5311,BP神经网络模型为0.4907,而经过100次迭代的深度学习模型达到了0.6308的精确度。相对于随机森林模型,CatBoost和XGBoost模型表现出更好的性能,而深度学习模型在CIFAR-10数据集上展现出卓越的性能。
关键字:随机森林;CatBoost;XGBoost;LightGBM;BP神经网络;深度学习
A Comparative Experimental Study of Machine
Learning Classification Algorithms
Abstract:This paper aims to comprehensively compare and evaluate common classification algorithms and explore their applications in the field of machine learning classification. The experimental results show that the accuracy of the random forest model on the CIFAR-10 dataset is 0.4654, the CatBoost model is 0.4916, the XGBoost model is 0.5425, the LightGBM model is 0.5311, the BP neural network model is 0.4907, and the deep learning model with 100 iterations achieves an accuracy of 0.6308. Compared to the random forest model, the CatBoost and XGBoost models demonstrate better performance, while the deep learning model exhibits outstanding performance on the CIFAR-10 dataset.
Keywords: Random Forest; CatBoost; XGBoost; LightGBM; BP Neural Network; Deep Learning
实验项目地址:https://colab.research.google.com/drive/17ZhwA8J0EoBoUg4eJOniVWLJSWJYRTJQ#scrollTo=_2An7ZsbV8i-&uniqifier=3
目录
摘要
1 数据集
2 分类算法
2.1 随机森林
2.2 CatBoost
2.3 XGBoost
2.4 LightGBM
2.5 BP神经网络
2.6 深度学习
3 实验分析
4 参考文献
1 数据集
本研究使用了CIFAR-10数据集[1],该数据集是由加拿大高级研究所创建的常用计算机视觉数据集。CIFAR-10数据集包含10个类别的彩色图像,每个类别有6000张图像,总计60000张图像,图像尺寸为32x32像素。数据集划分为训练集(50000张图像)和测试集(10000张图像)。
为了确保数据质量和实验需求,对CIFAR-10数据集进行了归一化处理、图像增强、数据扩充和标签编码。归一化将像素值缩放到[0, 1]范围内,以适应模型训练。图像增强和数据扩充通过随机变换增加数据多样性,提升模型泛化能力。标签编码采用独热编码表示类别标签。
引用CIFAR-10数据集时,遵循科研规范,明确提及数据集来源、特征和预处理步骤,以确保数据可靠性和可复现性。
2 分类算法
2.1 随机森林
随机森林是一种基于集成学习的算法,其核心思想是构建多个相互独立的决策树,并将它们的分类结果进行综合。由于其大量的数据样本,随机森林能够有效地容忍异常值,减少过拟合的风险,并具有较高的预测精度,适用范围广[2]。在传统的随机森林方法中,决策树的数量是一个超参数,需要通过观察模型在测试集上的表现来选择最优的决策树数量,然而这个过程的效率较低。相对于其他机器学习算法而言,随机森林在分类问题上表现出色。随机森林的构建过程包括Bootstrap抽样、决策树生成和分类结果投票。具体步骤如下:
- Bootstrap抽样:采用有放回的随机抽样方法,从样本集中有放回的抽取θ组数据,N次抽样后得到N个包含 θ 组数据的训练集。
- 构建决策树:使用CART等决策树算法构建N棵决策树。
- 分类结果:根据所有决策树的分类结果,采用多数投票原则进行统计,得出随机森林算法的最终分类结果。决策树 i 对测试样本A的分类结果可表示为:

则随机森林分类模型的输出为:

式中: ![]() 表示决策树基分类器;lab表示决策树对样本A的分类结果,lab=1表示辨识结果为正常,lab=2表示辨识结果为异常;
表示决策树基分类器;lab表示决策树对样本A的分类结果,lab=1表示辨识结果为正常,lab=2表示辨识结果为异常; ![]() 为随机森林的分类;N表示随机森林中决策树的数量[3]。
为随机森林的分类;N表示随机森林中决策树的数量[3]。
2.2 CatBoost
CatBoost是一种基于梯度提升决策树原理的算法,通过迭代训练决策树模型,并利用梯度提升方法优化预测性能。其在特征处理方面具有独特创新,能自动处理类别型特征,无需手动编码或独热编码,采用有序目标编码技术,将类别型特征值映射为对应目标变量的平均值,更有效地处理类别型特征[4]。此外,CatBoost引入自适应学习率自动调整每个决策树的学习率。通过根据树的复杂度和梯度大小动态调整学习率,提高决策树模型的训练效果和性能。
第一,自动处理类别特征。假设数据集![]() ,其中:
,其中:![]() 是一个包含m个特征的向量,
是一个包含m个特征的向量,![]() 是标签的值。在处理类别型特征时,一般用整个数据集的标签值的均值来表示,即
是标签的值。在处理类别型特征时,一般用整个数据集的标签值的均值来表示,即

为防止过拟合,首先,它对数据集进行随机排列,生成一个随机排列序列![]() ,接着,对于每个样本的类别型特征取值并转换,转换的方法是取该样本之前标签值的均值,再结合先验值P和先验值的权重
,接着,对于每个样本的类别型特征取值并转换,转换的方法是取该样本之前标签值的均值,再结合先验值P和先验值的权重![]() ,即
,即
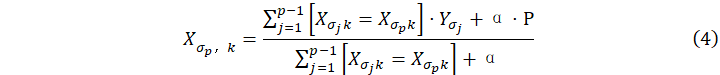
特征组合处理是CatBoost算法的一个重要特点。在生成树的初次分裂时,CatBoost算法并不对特征进行任何处理。然而,在二次分裂时,它会将树中的所有类别型特征与数据集中的所有类别型特征进行组合,从而生成新的特征,以增强模型的表达能力。
CatBoost算法生成的树都是对称树的设计,这种设计能够有效避免过拟合,并提高CatBoost的运行效率和预测性能。这种对称树的特性使得模型更加稳定和鲁棒,有助于提升算法在实际应用中的效果。
2.3 XGBoost
XGBoost是基于改进GBDT的算法。该算法采用目标函数的二阶泰勒展开,并引入惩罚项来防止过拟合。XGBoost是一种高效可扩展的机器学习算法,基于梯度提升框架,通过集成多个弱学习器(通常是决策树)逐步优化损失函数,提升整体模型性能[5]。在分类、回归、排序和推荐系统等许多机器学习任务中,XGBoost取得了显著成果。其卓越性能和广泛应用使其成为科研和实践领域中重要的算法之一。
![]()
泰勒展开如下:
![]()
此时目标函数近似为:
![]()
其中:
![]()
![]()
而![]() ,
,![]() 表示预测值,
表示预测值,![]() 表示第i个样本所属的类别,t表示生成树的数量,
表示第i个样本所属的类别,t表示生成树的数量,![]() 表示第t棵树模型,T表示叶子结点的数量,
表示第t棵树模型,T表示叶子结点的数量,![]() 表示叶子结点向量的模,
表示叶子结点向量的模,![]() 和
和![]() 表示系数,constant表示常数。
表示系数,constant表示常数。
目标函数由两个主要部分组成:损失函数和正则项。损失函数用于评估模型的拟合效果,而正则项用于降低过拟合的风险。正则化项中的![]() 通过控制叶子节点的数目及其权重来控制树的复杂度,观察目标函数,发现
通过控制叶子节点的数目及其权重来控制树的复杂度,观察目标函数,发现![]() 为常数,常数项不影响模型优化可删,并将
为常数,常数项不影响模型优化可删,并将![]() 表达式代入公式,此时目标函数为
表达式代入公式,此时目标函数为
![]()
目标函数由损失和正则化两部分组成。损失部分对训练样本集进行累加,其中所有样本的输入映射到CART树的叶子节点。因此从叶子节点出发,对所有叶子节点进行累加,得

令![]() ,
,![]() ,其中
,其中![]() 表示的是对映射为第j个叶子节点的所有输入样本的一阶导数求和,
表示的是对映射为第j个叶子节点的所有输入样本的一阶导数求和,![]() 表示的是对其二阶导数求和。因为各个叶子节点之间都相互独立,且
表示的是对其二阶导数求和。因为各个叶子节点之间都相互独立,且![]() 和
和![]() 都是确定量,最小化公式(10)的目标函数可得
都是确定量,最小化公式(10)的目标函数可得
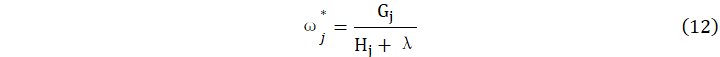
其目标函数是
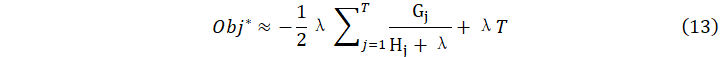
![]() 的值越小,代表数的结构越好。
的值越小,代表数的结构越好。
2.4 LightGBM
LightGBM是微软于2017年提出的一种创新的训练算法。它在GBDT算法的基础上进行改进,具有快速训练、低内存消耗和高准确率的优势[6]。LightGBM引入了两个新技术:基于梯度的单边采样和互斥特征捆绑。这些技术通过减少大样本总量和降低特征维度的优化来解决大规模统计实例和大样本特征之间的相关性问题。
Gradient Boosting是一种基于迭代的机器学习方法,通过逐步增加子模型来最小化损失函数。其模型表示如下:
![]()
损失函数是在增加一个子模型时,用于衡量模型预测与实际观测之间差异的一种函数。当增加一个子模型时,损失函数的梯度将朝着信息量次高的变量方向下降,这一过程可用以下数学表达式表示:
![]()
LightGBM采用了一种按叶子分裂的决策树子模型,以减少计算开销。为了避免过拟合,需要控制树的深度和叶子节点的最小数据量。该模型采用基于直方图的决策树算法,将特征值划分为多个小的"桶",通过在这些"桶"上进行分裂,从而降低计算和存储成本。此外,LightGBM还对类别特征进行了处理,进一步提高了算法的性能。
2.5 BP神经网络
BP神经网络是一种被广泛应用于科研领域的模型,由多层神经元组成,包括输入层、输出层和隐含层[7]。隐含层位于输入层和输出层之间,尽管不直接与
外界相连,但其状态对输入和输出之间的关系具有重要影响。
本研究中的文本分类器采用了三层前馈型BP神经网络,包括输入层、隐含层和输出层。在这个网络中,输入层接收原始文本数据,将其转换为特征向量表示。隐含层是网络的核心部分,它通过对输入层的特征进行非线性变换和组合,提取出更高级的语义特征。输出层接收隐含层的输出,根据学习到的权值和偏置,将文本映射到不同的分类类别上。
在BP神经网络中,权值是经过训练数据进行调整而得到的系数。这些经过调整的权值起着至关重要的作用,它们决定了输入向量和输出向量之间的相关性,进而决定了文本在不同类别上的分类结果。通过训练和优化过程,BP神经网络能够学习到合适的权值,以提高分类准确性并适应各种不同的输入数据。这种权值调整的过程是神经网络学习和适应的关键,使得网络能够处理复杂的文本分类任务。
假设神经网络有m层,其中输入层为样本X。对于第k层的第i个神经元,其输入总和表示为![]() ,而
,而![]() 表示该神经元的输出。权值之和从第k-1层的第j个神经元到第i个神经元用
表示该神经元的输出。权值之和从第k-1层的第j个神经元到第i个神经元用表示。假设每个神经元都具有激活函数f。可以用以下数学式来描述这些变量之间的关系:

反向传播(Backpropagation)算法是一种基于最速下降法的权值更新方法。它通过根据误差的负梯度方向对权值进行调整,以达到最小化误差函数的目的。误差函数e衡量了期望输出与实际输出之间的差异,通常以差的平方作为标准来度量误差的大小:
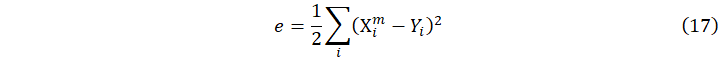
其中![]() 是实际输出,
是实际输出,![]() 是输出单元的期望值。因为BP算法按误差函数负梯度方向修改权值,故权值
是输出单元的期望值。因为BP算法按误差函数负梯度方向修改权值,故权值![]() 的修改量
的修改量![]() 与e的关系如下:
与e的关系如下:

η为学习率,按照BP神经网络的原理,最终完成![]() 的计算。
的计算。
2.6 深度学习
深度学习是一种基于人工神经网络的概念,旨在通过模拟人脑的神经网络结构和工作方式来解决复杂的模式识别和决策问题[8],通过建立多层神经元之间的信息传递从而学习样本特征。其核心思想是通过多层次的非线性变换来学习和提取数据的高层次抽象表示。
3 实验分析
混淆矩阵是分类问题中常用的评估分类器性能的工具,用于比较分类器预测结果与实际标签之间的一致性。混淆矩阵包含四个主要条目。基于混淆矩阵,可以计算出准确率、精确率、召回率和F1值等一系列分类性能指标。以下是六种分类算法在混淆矩阵实验中的结果:
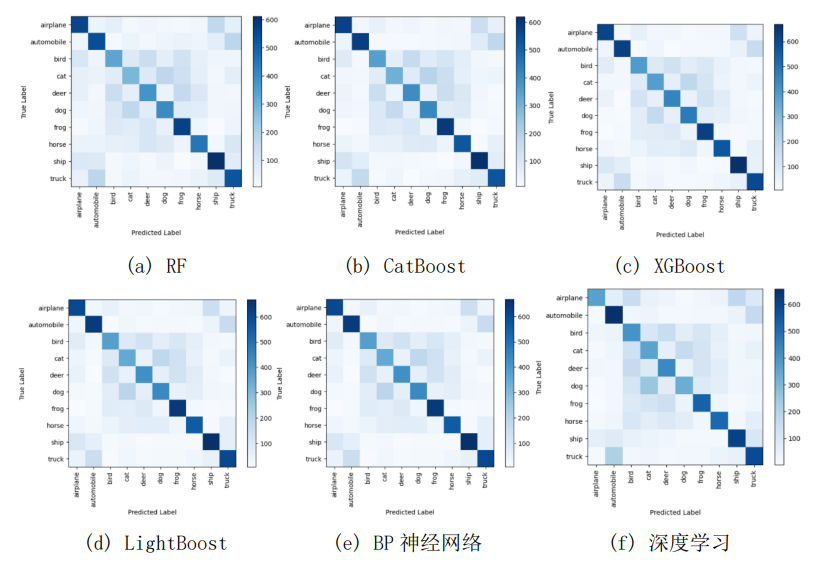
图1 混淆矩阵

图2 RF

图3 CatBoost

图4 XGBoost

图5 LightGBM

图6 BP神经网络

图7 深度学习
XGBoost模型的精确度为0.5425,即能够正确分类约54.25%的样本。相较于之前提到的随机森林模型和CatBoost模型,XGBoost模型的性能进一步提升,这表明XGBoost在CIFAR-10数据集上对图像分类任务的性能更好。除了精确度指标,还可以对其他评价指标进行分析。例如,可以计算模型的召回率、准确率和F1值等,以获得更全面的性能评估结果。
LightGBM模型的精确度为0.5311,即能够正确分类约53.11%的样本。从精确度来看,0.5311的结果略高于随机森林模型的0.4654,但相对于CatBoost模型的0.4916和XGBoost模型的0.5425,略低一些。然而,仅凭精确度无法全面评价模型的性能,因为不同的算法可能在不同的数据集上表现出不同的特点和优势。
BP神经网络模型在CIFAR-10数据集上的精确度为0.4907,即能够正确分类约49.07%的样本。从精确度来看,0.4907的结果表明BP神经网络在CIFAR-10数据集上的性能有一定局限性。这可能是因为BP神经网络的训练过程容易受到局部最小值、梯度消失或梯度爆炸等问题的影响。为了提高BP神经网络的性能,可以尝试调整网络结构、使用更优化的激活函数和优化算法,或者采用其他更适合处理图像数据的深度学习模型。
深度学习模型在CIFAR-10数据集上经过100次迭代的精确度为0.6308,即能够正确分类约63.08%的样本。从精确度来看,0.6308的结果相对较高,反映深度学习的训练效果更好,但其训练和调整过程相对复杂。深度学习模型的训练需要大量的计算资源和时间,以及对超参数的精细调整。此外,过拟合问题也需要引起关注,因为深度学习模型具有较高的参数数量和复杂度,容易在训练集上获得较好的性能,但在测试集上表现不佳。
综上所述,深度学习模型在CIFAR-10数据集上表现良好,达到了0.6308的精确度,深度学习模型通过逐层学习特征表示,可以自动发现数据中的抽象特征和复杂模式,由于深度学习模型的复杂结构和大规模数据集的使用所致,并且需要进行大量的迭代过程通过不断的降低损失和反向传播从而实现较好的效果,虽然效果与之机器学习更优,但耗费的时间成本和算力都是很昂贵的,因此实际应用中需要综合考虑多方因素确定使用的方法,做到方法的实用性。
表2
| 深度学习 | 迭代10次 | 迭代20次 | 迭代100次 | |
|---|---|---|---|---|
| 精确度 | 0.4796 | 0.5337 | 0.6308 | |
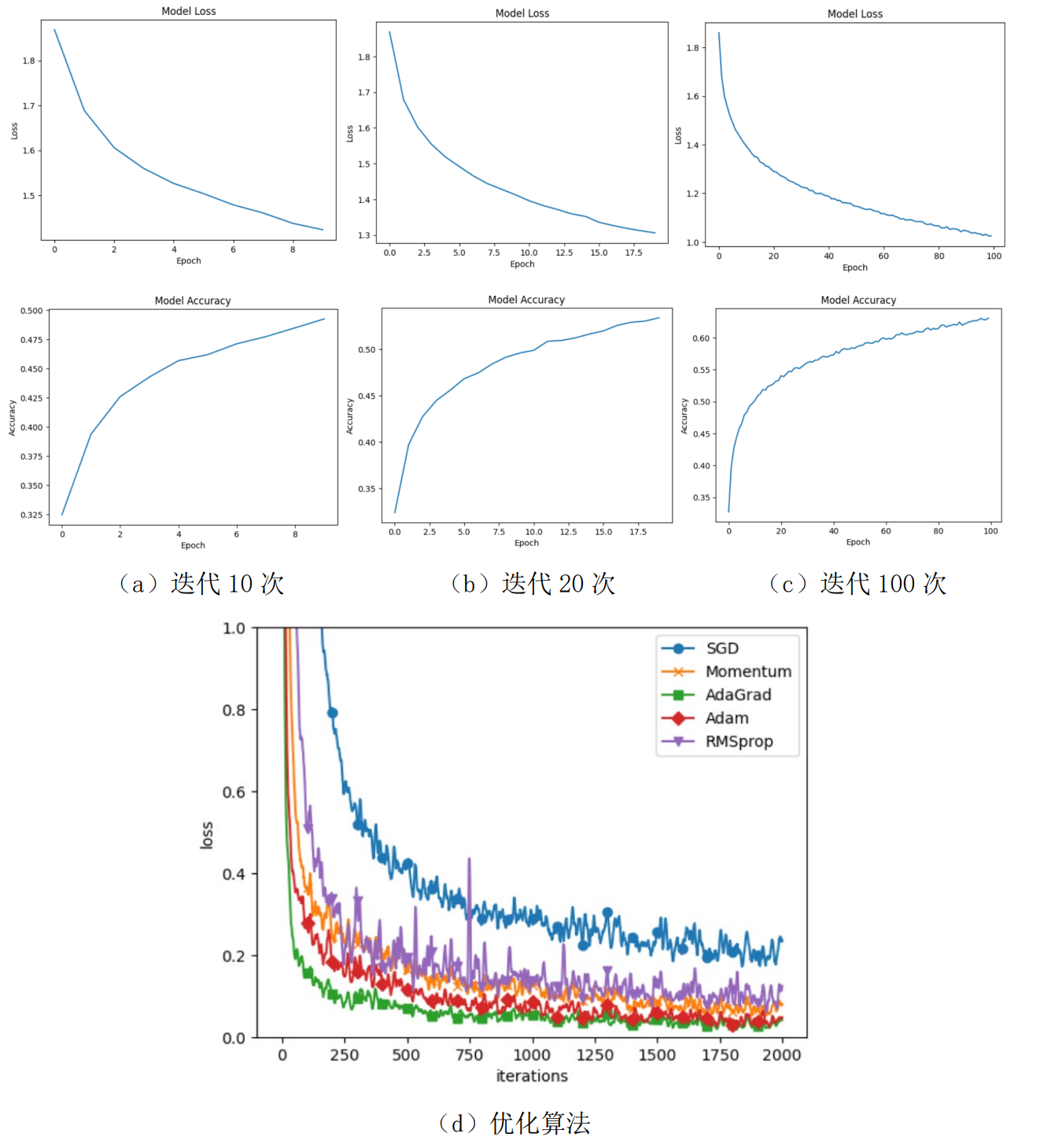
(d)优化算法
图8 深度学习
在迭代10次的实验结果显示,深度学习模型在 CIFAR-10 数据集上的精确度为 0.4796。这意味着模型能够正确分类约 47.96% 的样本。从精确度指标来看,这个结果相对较低,表明模型的性能还有提升的空间如图8。
迭代20次的实验结果显示,深度学习模型在 CIFAR-10 数据集上的精确度为 0.5337。这表示模型能够正确分类约 53.37% 的样本。相对于迭代10次的结果,精确度有所提高。随着迭代次数的增加,模型的损失逐渐降低,同时精确度也逐步提高。
迭代100次的实验结果显示,深度学习模型在 CIFAR-10 数据集上的精确度为 0.6308。这意味着模型能够正确分类约 63.08% 的样本,随着迭代次数的持续增加,可以明显观察到模型的性能得到了显著的改善和提升。
随着迭代次数的增加,模型性能明显提升。随着训练的进行,模型逐渐学习到更准确的特征和模式,从而使得精确度不断增加。这表明在深度学习模型中,较多的迭代次数可以帮助模型更好地适应数据集,提高其分类能力和泛化能力。在收集实验结果和进行分析时,通过对比使用不同优化算法和传统梯度下降算法的实验结果,发现AdaGrad算法在加速收敛和提高性能方面表现出色。
4 参考文献
[1] A. Krizhevsky, V. Nair, and G. Hinton. CIFAR-10 (Canadian Institute for Advanced Research). Technical Report, 2009.
[2] L. Breiman. Random Forests. Machine Learning, 2001, 45(1): 5-32.
[3] T. K. Ho. The Random Subspace Method for Constructing Decision Forests. IEEE Transactions on Pattern Analysis and Machine Intelligence, 1998, 20(8): 832-844.
[4] A. I. Ignatiev, G. Gusev, and M. Y. Khachay. CatBoost: Gradient Boosting with Categorical Features Support. Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS), 2017, 6638-6648.
[5] T. Chen and C. Guestrin. XGBoost: A Scalable Tree Boosting System. Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 2016, 785-794.
[6] G. Ke, Q. Meng, T. Finley, et al. LightGBM: A Highly Efficient Gradient Boosting Decision Tree. Journal of Machine Learning Research, 2018, 19(1): 1-6.
[7] D. E. Rumelhart, G. E. Hinton, and R. J. Williams. Learning Representations by Back-Propagating Errors. Nature, 1986, 323(6088): 533-536.
[8] Y. LeCun, Y. Bengio, and G. Hinton. Deep Learning. Nature, 2015, 521(7553): 436-444.

相关文章:
【机器学习】基于机器学习的分类算法对比实验
摘要 基于机器学习的分类算法对比实验 本论文旨在对常见的分类算法进行综合比较和评估,并探索它们在机器学习分类领域的应用。实验结果显示,随机森林模型在CIFAR-10数据集上的精确度为0.4654,CatBoost模型为0.4916,XGBoost模型为…...

民航电子数据库:mysql与cae建表语法差异
目录 一、场景二、语法差异 一、场景 1、使用CAEMigrator-1.0.exe将mysql数据库迁移至cae数据库时,迁移速度非常慢,而且容易卡死(可能是部署cae数据库的服务器资源不足导致) 2、所以将mysql数据库导出为sql脚本,通过…...
(学习日记)2024.03.15:UCOSIII第十七节:任务的挂起和恢复
写在前面: 由于时间的不足与学习的碎片化,写博客变得有些奢侈。 但是对于记录学习(忘了以后能快速复习)的渴望一天天变得强烈。 既然如此 不如以天为单位,以时间为顺序,仅仅将博客当做一个知识学习的目录&a…...
聚类分析 | Matlab实现基于NNMF+DBO+K-Medoids的数据聚类可视化
聚类分析 | Matlab实现基于NNMFDBOK-Medoids的数据聚类可视化 目录 聚类分析 | Matlab实现基于NNMFDBOK-Medoids的数据聚类可视化效果一览基本介绍程序设计参考资料 效果一览 基本介绍 NNMFDBOK-Medoids聚类,蜣螂优化算法DBO优化K-Medoids 非负矩阵分解(…...
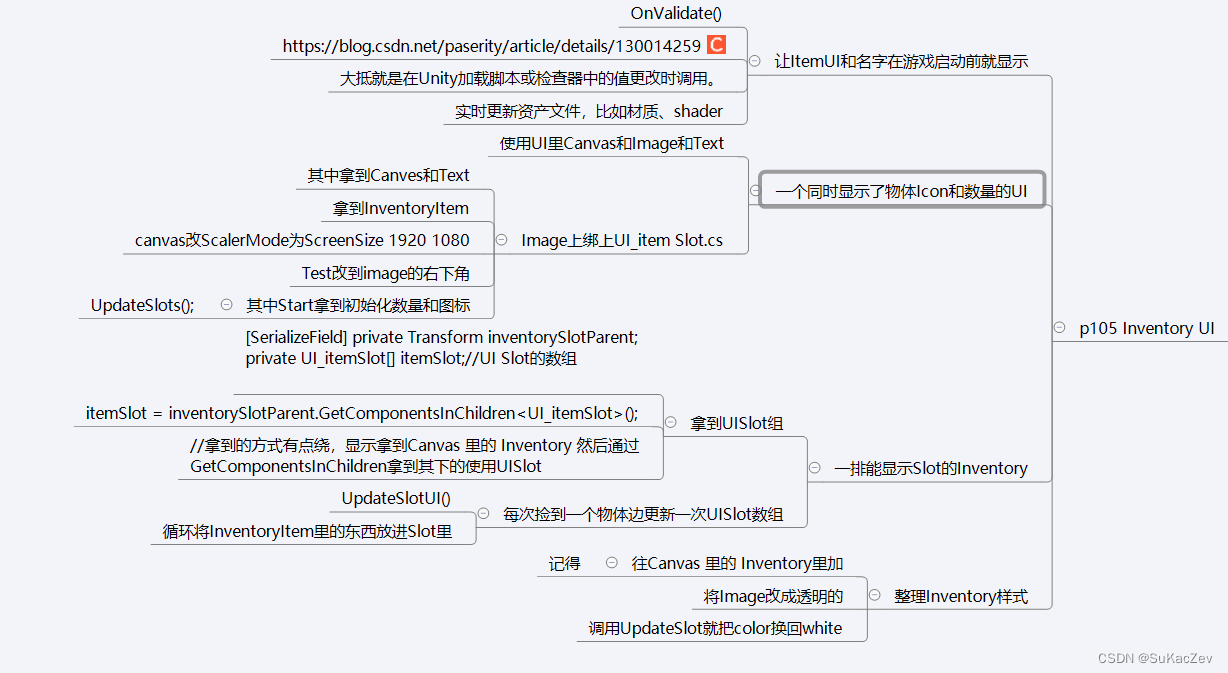
Unity类银河恶魔城学习记录11-3 p105 Inventory UI源代码
Alex教程每一P的教程原代码加上我自己的理解初步理解写的注释,可供学习Alex教程的人参考 此代码仅为较上一P有所改变的代码 【Unity教程】从0编程制作类银河恶魔城游戏_哔哩哔哩_bilibili UI_itemSlot.cs using System.Collections; using System.Collections.Gen…...

Vue3 + Vite + ts引入本地图片
Vue3 Vite ts引入本地图片 单张图片导入 单个图片导入,不过多阐述,通过 import 导入需要使用的图片。 import imgName from /assets/img/imgName.png 多张图片导入 new URL() import.meta.url import.meta.url 是一个 ESM 的原生功能࿰…...
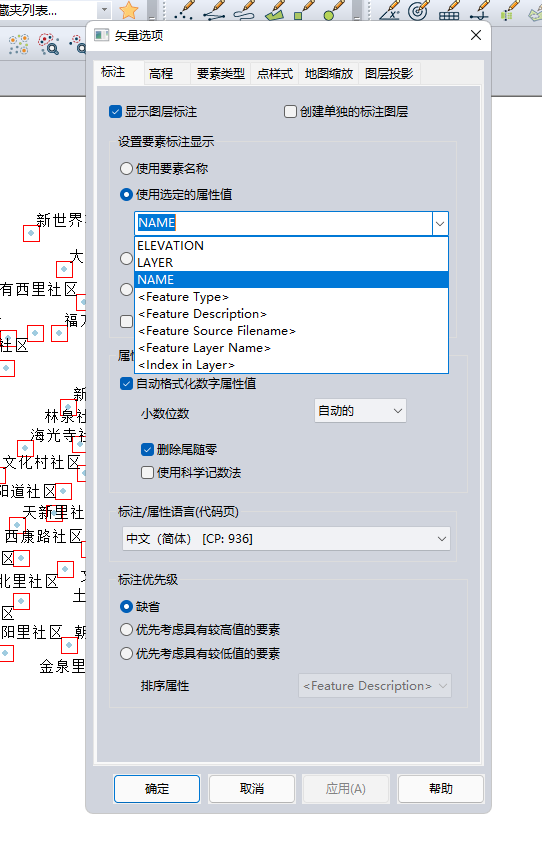
图斑或者道路如何单独显示名称在图斑上或者道路上
0序: 遇到过多个测绘、工程、林业相关业务的客户,在加载一些图斑数据,线路数据时,希望能够单独的把图斑的名称,显示到图斑上,或者路网上面。 之前多数推荐的办法: 1.shp可以直接在图新地球中…...

docker 修改默认存储位置
一般系统下系统盘可能磁盘空间有限,需要将docker的存储目录改到其他位置 docker info 查看docker的版本 低版本docker在配置json中增加"graph":"/var/lib/docker" 高版本docker在配置json中增加"data-root":"/var/lib/docker&q…...
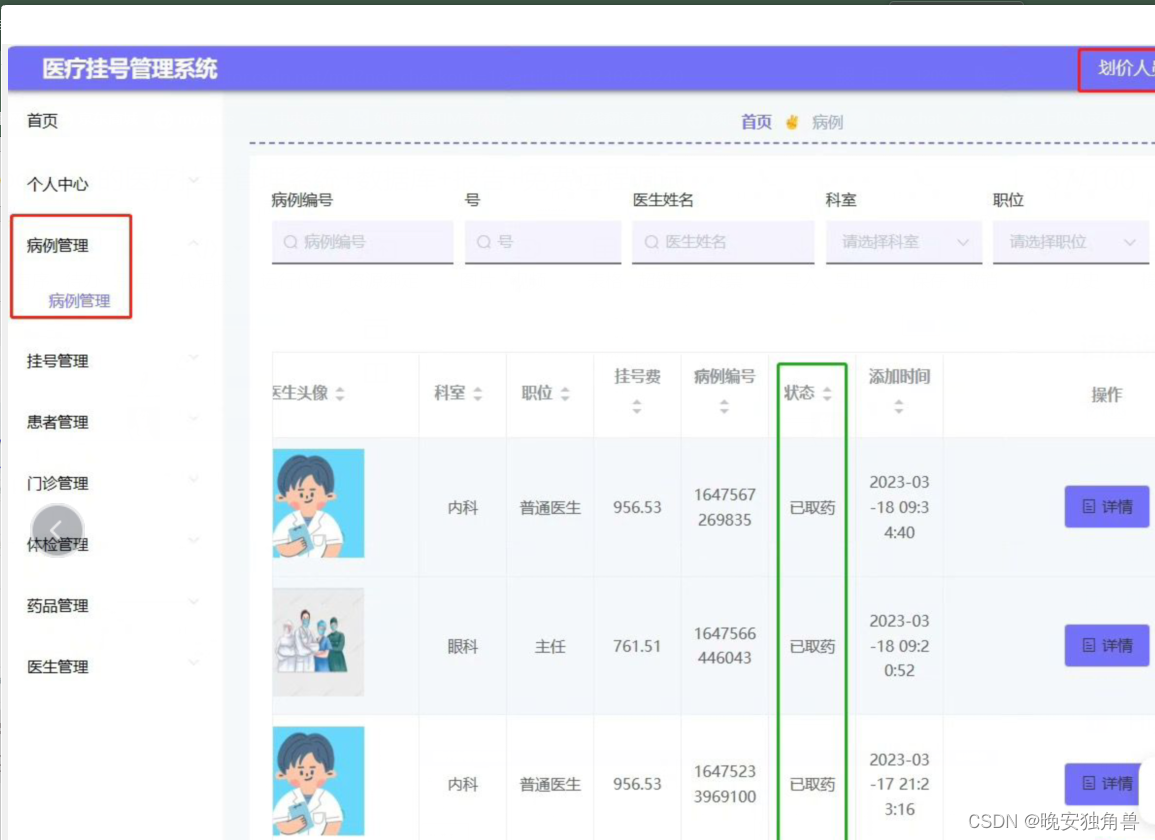
Springboot+vue的医疗挂号管理系统+数据库+报告+免费远程调试
效果介绍: Springbootvue的医疗挂号管理系统,Javaee项目,springboot vue前后端分离项目 本文设计了一个基于Springbootvue的前后端分离的医疗挂号管理系统,采用M(model)V(view)C(con…...

【Effective C++】39 明智而审慎地使用private继承
在之前论证过c如何将public 继承视为 is-a 关系。在哪个例子里,class Student 以 public 形式继承class Person, 于是编译器在必要时刻将Students暗自转化为Person.如果此时我们以 private 继承替换 public继承。 class Person {...}; class Student: p…...
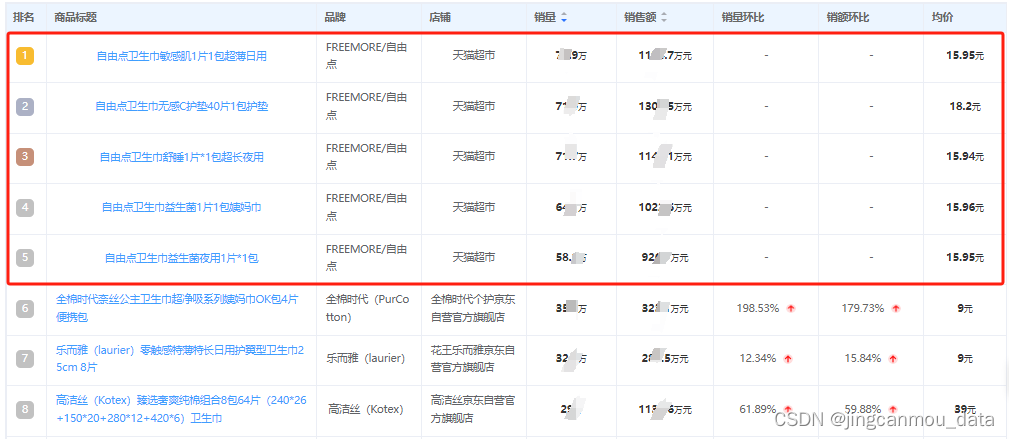
2024年卫生巾行业市场分析报告(京东天猫淘宝线上卫生巾品类电商数据查询)
最近,相关部门辟谣了一则“十大致癌卫生巾黑名单”的消息。这个榜单是部分博主AI撰写,为博眼球、蹭热度的结果。此次事件势必会对卫生巾行业产生一定影响,加剧行业竞争。 根据鲸参谋电商数据平台显示,2024年1月至2月线上电商平台…...

MySQL之表的记录操作
前言 存数据不是目的,目的是能够将存起来的数据取出来或者查出来,并且能够对数据进行增删改查操作,本文将详细介绍表中记录的增删改查操作。对记录的操作属于DML数据库操作语言,可以通过SQL实现对数据的操作,包括实现…...

一种动态联动的实现方法
安防领域中的联动规则 有安防领域相关的开发经历的人知道,IPCamera可以配置使能“侦测”功能,并且指定仅针对图像传感器的某个区载进行侦测。除了基本的“移动侦测"外,侦测的功能点还有细化的类别,如人员侦测、车辆侦测、烟…...
kotlin中使用ViewBinding绑定控件
kotlin中使用ViewBinding绑定控件 什么是ViewBinding? View Binding是Android Studio 3.6推出的新特性,主要用于减少findViewById的冗余代码,但内部实现还是通过使用findViewById。通过ViewBinding,可以更轻松地编写可与视图交互…...

知识积累(五):Transformer 家族的学习笔记
文章目录 1. RNN1.1 缺点 2. Transformer2.1 组成2.2 Encoder2.2.1 Input Embedding(嵌入层)2.2.2 位置编码2.2.3 多头注意力2.2.4 Add & Norm 2.3 Decoder2.3.1 概览2.3.2 Masked multi-head attention 2.4 Transformer 模型的训练和推理2.4.1 训练…...

[Java、Android面试]_13_map、set和list的区别
本人今年参加了很多面试,也有幸拿到了一些大厂的offer,整理了众多面试资料,后续还会分享众多面试资料。 整理成了面试系列,由于时间有限,每天整理一点,后续会陆续分享出来,感兴趣的朋友可关注收…...

Linux进程管理:(六)SMP负载均衡
文章说明: Linux内核版本:5.0 架构:ARM64 参考资料及图片来源:《奔跑吧Linux内核》 Linux 5.0内核源码注释仓库地址: zhangzihengya/LinuxSourceCode_v5.0_study (github.com) 1. 前置知识 1.1 CPU管理位图 内核…...

计算机专业学生的成长之路:超越课堂的自我提升策略
🌟 前言 欢迎来到我的技术小宇宙!🌌 这里不仅是我记录技术点滴的后花园,也是我分享学习心得和项目经验的乐园。📚 无论你是技术小白还是资深大牛,这里总有一些内容能触动你的好奇心。🔍 &#x…...
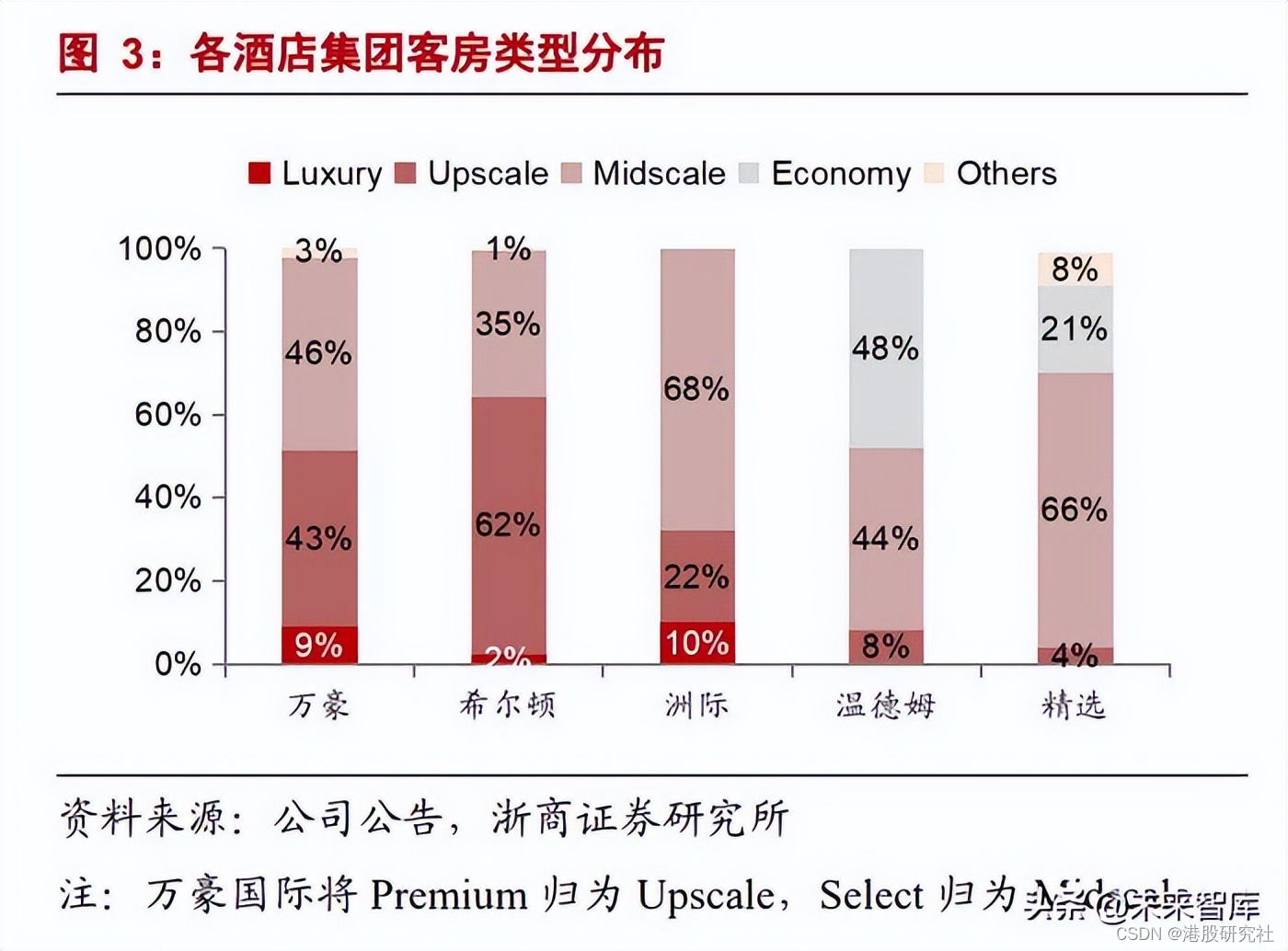
财报解读:“高端化”告一段落,华住开始“全球化”?
2023年旅游业快速复苏,全球酒店业直接受益,总体运营指标大放异彩,多数酒店企业都实现了营收上的明显增长,身为国内龙头的华住也不例外。 3月20日晚,华住集团发布2023年四季度及全年财报。整体实现扭亏为盈,…...

Wifi环境下Unity开发iOS应用启动后HTTPS请求未弹出是否允许无线数据使用数据的弹窗
情况说明 笔者项目在首次启动,登录界面点击登录按钮会先HTTPS请求创建帐号,但是在WIFI网络下,请求后一直提示网络连接失败。但是切换到流量包后,则会弹出"无线数据"使用数据的弹窗,选择允许后则可顺利进入。…...

小米MIMO最新邀请码
欢迎使用,各得10元体验金...

政企数据安全:危机与出路
随着数字化转型的浪潮席卷全球,公共部门积累的数据量呈爆炸式增长。从公民个人信息到公共服务记录,从财政预算到基础设施管理数据——这些宝贵资源在提升政府治理效率的同时,也悄然成为网络犯罪分子的“新猎物”。当公共数据逐渐成为数字时代…...

为什么92%的DeepSeek二次开发团队在6个月内遭遇交付延迟?——基于17个真实项目的技术债务归因分析
更多请点击: https://intelliparadigm.com 第一章:为什么92%的DeepSeek二次开发团队在6个月内遭遇交付延迟?——基于17个真实项目的技术债务归因分析 在对17个采用DeepSeek-R1/VL模型开展定制化开发的工业级项目进行回溯审计后,我…...

通过curl命令快速测试Taotoken大模型API的连通性与返回格式
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过curl命令快速测试Taotoken大模型API的连通性与返回格式 在集成大模型能力到应用时,开发者通常需要一种快速、轻量的…...

脉冲神经网络加速器设计与边缘计算优化
1. 脉冲神经网络加速器的设计挑战与突破在边缘计算领域,脉冲神经网络(SNN)正以其独特的生物启发特性引发新一轮技术变革。与传统人工神经网络(ANN)相比,SNN通过离散的脉冲信号传递信息,模拟生物神经元的工作机制,理论上可实现超低…...
)
DeepSeek代码风格检查避坑指南(内部审计报告首次披露:37个被忽略的合规红线)
更多请点击: https://intelliparadigm.com 第一章:DeepSeek代码风格检查的合规性本质与审计背景 DeepSeek代码风格检查并非单纯的技术偏好约束,而是嵌入研发治理链条中的合规性控制节点。其本质是将编程实践与组织级安全策略、行业监管要求&…...

操作符从浅入深的讲解
1. 操作符的分类 2. ⼆进制和进制转换 3. 原码、反码、补码 4. 移位操作符 5. 位操作符:&、|、^、~ 6. 单⽬操作符 7. 逗号表达式 8. 下标访问[]、函数调⽤() 9. 结构成员访问操作符 10. 操作符的属性:优先级、结合性 11. 表达式求值1.操作符的分类以…...
 指针的常见操作)
C语言(12) 指针的常见操作
指针的常见操作指针变量,有两方面的意思:一个指针指向的内容(数据值,一级)指针变量本身存储的数据 (地址值)#include <stdio.h>int main() {int a 10;int b 0 ;int c 50;int *p NULL;int *q NULL;p &a; // 对指针变量本身进行修改// 对指…...

【C++】零基础入门 · 第 6 节:数组
上一节我们学习了函数,知道了如何把代码封装起来方便复用。但在实际编程中,你很快就会遇到一个问题:如果要存储 100 个学生的成绩,难道要定义 100 个变量吗?这显然不现实。数组就是 C++ 给出的答案——它让我们能用一个变量名管理一组相同类型的数据。 1. 为什么需要数组…...

WarcraftHelper:让经典魔兽争霸3完美适配现代电脑的终极解决方案
WarcraftHelper:让经典魔兽争霸3完美适配现代电脑的终极解决方案 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 还在为魔兽争霸3在现代操…...