巨细!Python爬虫详解
爬虫(又称为网页蜘蛛,网络机器人,在 FOAF 社区中间,更经常的称为网页追逐者);它是一种按照一定的规则,自动地抓取网络信息的程序或者脚本。
如果我们把互联网比作一张大的蜘蛛网,那一台计算机上的数据便是蜘蛛网上的一个猎物,而爬虫程序就是一只小蜘蛛,他们沿着蜘蛛网抓取自己想要的猎物/数据。
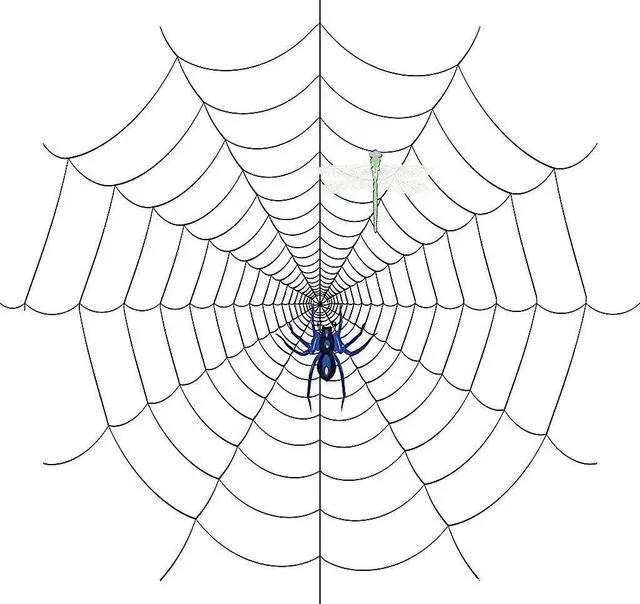
爬虫的基本流程

网页的请求与响应
网页的请求和响应方式是 Request 和 Response
Request:用户将自己的信息通过浏览器(socket client)发送给服务器(socket server)
Response:服务器接收请求,分析用户发来的请求信息,收到请求信息后返回数据(返回的数据中可能包含其他链接,如:image、js、css等)
浏览器在接收 Response 后,会解析其内容来显示给用户,而爬虫程序在模拟浏览器发送请求然后接收 Response 后,是要提取其中的有用数据。
发起请求:Request
请求的发起是使用 http 库向目标站点发起请求,即发送一个Request
Request对象的作用是与客户端交互,收集客户端的 Form、Cookies、超链接,或者收集服务器端的环境变量。
Request 对象是从客户端向服务器发出请求,包括用户提交的信息以及客户端的一些信息。客户端可通过 HTML 表单或在网页地址后面提供参数的方法提交数据。
然后服务器通过 request 对象的相关方法来获取这些数据。request 的各种方法主要用来处理客户端浏览器提交的请求中的各项参数和选项。
Request 包含:请求 URL、请求头、请求体等
Request 请求方式: GET/POST
请求url: url全称统一资源定位符,一个网页文档、一张图片、 一个视频等都可以用url唯一来确定
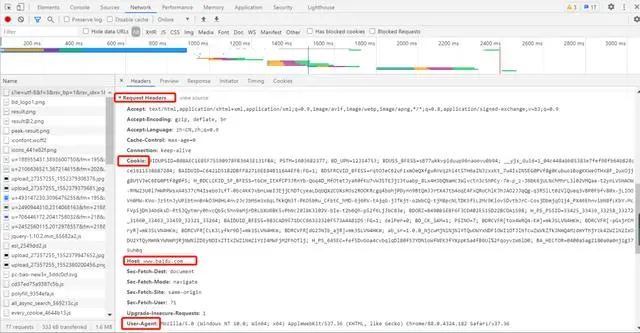
请求头: User-agent:请求头中如果没有 user-agent 客户端配置,服务端可能将你当做一个非法用户;
cookies: cookie 用来保存登录信息
一般做爬虫都会加上请求头
例如:抓取百度网址的数据请求信息如下:
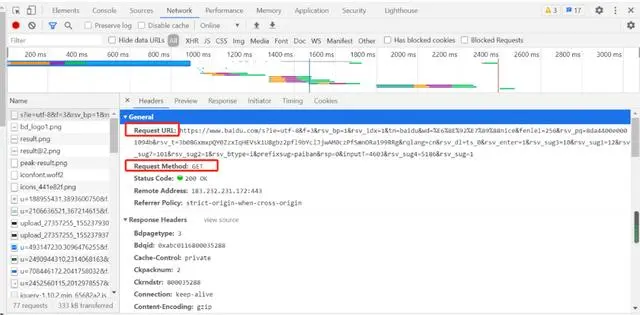
获取响应内容
爬虫程序在发送请求后,如果服务器能正常响应,则会得到一个Response,即响应;
Response 信息包含:html、json、图片、视频等,如果没报错则能看到网页的基本信息。例如:一个的获取网页响应内容程序如下:
import requests
request_headers={
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Cookie': 'BIDUPSID=088AEC1E85F75590978FB3643E131FBA; PSTM=1603682377; BD_UPN=12314753; BDUSS_BFESS=s877ukkvpiduup96naoovu0b94; __yjs_duid=1_04c448abb85383e7fef98fb64b828cce1611538687284; BAIDUID=C6421D51B2DBFF82716EE84B116A4EF8:FG=1; BDSFRCVID_BFESS=rqtOJeC62uF1xmOeQXfguRnVq2hi4t5TH6aINJzxxKt_7w4IsZNSEG0PVf8g0Kubuo1BogKKWeOTHx8F_2uxOjjg8UtVJeC6EG0Ptf8g0f5; H_BDCLCKID_SF_BFESS=tbCH_ItXfCP3JRnYb-Qoq4D_MfOtetJyaR0fKU7vWJ5TEJjz3tuabp_8Lx4H3bQNaHc3Wlvctn3cShPCy-7m-p_z-J6bK6jULNchMhrL3l02VMQae-t2ynLV5HAOW-RMW23U0l7mWPPWsxA45J7cM4IseboJLfT-0bc4KKJxbnLWeIJEjjChDTcyeaLDqbQX2COXsROs2ROOKRcgq4bohjPDynn9BtQmJJrtX4Jtb4oqE4FxQRoChlKJhJAO2JJqQg-q3R5lLt02VlQueq3vBP0Fbfv80x-jLIOOVn0MW-KVo-Jz5tnJyUPibtnnBnkO3H8HL4nv2JcJbM5m3x6qLTKkQN3T-PKO5bRu_CFbtC_hMD-6j6RV-tAjqG-jJTkjt-o2WbCQ-tjM8pcNLTDK5f5L2Mc9Klov5DvtbJrC-CosjDbmjqO1j4_PX46EhnvibN8fLKbY-McFVp5jDh34b6ksD-Rt5JQytmry0hvcQb5cShn9eMjrDRLbXU6BK5vPbNcZ0l8K3l02V-bIe-t2b6Qh-p52f6LjJbC83e; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; H_PS_PSSID=33425_33439_33258_33272_31660_33463_33459_33321_33264; BAIDUID_BFESS=983CAD9571DCC96332320F573A4A81D5:FG=1; delPer=0; BD_CK_SAM=1; PSINO=7; BDRCVFR[tox4WRQ4-Km]=mk3SLVN4HKm; BDRCVFR[-pGxjrCMryR]=mk3SLVN4HKm; BDRCVFR[CLK3Lyfkr9D]=mk3SLVN4HKm; BDRCVFR[dG2JNJb_ajR]=mk3SLVN4HKm; BD_HOME=1; H_PS_645EC=0c49V2LWy0d6V4FbFplBYiy6xyUu88szhVpw2raoJDgdtE3AL0TxHMUUFPM; BA_HECTOR=0l05812h21248584dc1g38qhn0r; COOKIE_SESSION=1_0_8_3_3_9_0_0_7_3_0_1_5365_0_3_0_1614047800_0_1614047797%7C9%23418111_17_1611988660%7C5; BDSVRTM=1',
'Host':'www.baidu.com',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.182 Safari/537.36'}
response = requests.get('https://www.baidu.com/s',params={'wd':'帅哥'},headers=request_headers) #params内部就是调用urlencode
print(response.text)
以上内容输出的就是网页的基本信息,它包含 html、json、图片、视频等,如下图所示:
Response 响应后会返回一些响应信息,例下:
1、响应状态
- 200:代表成功
- 301:代表跳转
- 404:文件不存在
- 403:权限
- 502:服务器错误
2、Respone header
- set-cookie:可能有多个,是来告诉浏览器,把cookie保存下来
3、preview 是网页源代码
- 最主要的部分,包含了请求资源的内容,如网页html、图片、二进制数据等
4、解析内容
解析 html 数据:解析 html 数据方法有使用正则表达式、第三方解析库如 Beautifulsoup,pyquery 等
解析 json 数据:解析 json数据可使用 json 模块
解析二进制数据:以 b 的方式写入文件
5、保存数据
爬取的数据以文件的形式保存在本地或者直接将抓取的内容保存在数据库中,数据库可以是 MySQL、Mongdb、Redis、Oracle 等……
写在最后
爬虫的总流程可以理解为:蜘蛛要抓某个猎物–>沿着蛛丝找到猎物–>吃到猎物;即爬取–>解析–>存储;
在爬取数据过程中所需参考工具如下:
爬虫框架:Scrapy
请求库:requests、selenium
解析库:正则、beautifulsoup、pyquery
存储库:文件、MySQL、Mongodb、Redis……
总结
今天的文章是对爬虫的原理做一个详解,希望对大家有帮助,同时也在后面的工作中奠定基础!

相关文章:
巨细!Python爬虫详解
爬虫(又称为网页蜘蛛,网络机器人,在 FOAF 社区中间,更经常的称为网页追逐者);它是一种按照一定的规则,自动地抓取网络信息的程序或者脚本。 如果我们把互联网比作一张大的蜘蛛网,那…...
项目中如何进行限流(限流的算法、实现方法详解)
❤ 作者主页:李奕赫揍小邰的博客 ❀ 个人介绍:大家好,我是李奕赫!( ̄▽ ̄)~* 🍊 记得点赞、收藏、评论⭐️⭐️⭐️ 📣 认真学习!!!🎉🎉 文章目录 限流的算法漏…...

https在win7的环境下如何配置
https在win7的环境下如何配置?在Windows7环境下配置https,需要完成以下步骤: 1)安装Web服务器软件 可以选择安装常用的Web服务器软件,如Apache、Nginx或IIS,这些服务器软件都支持https。 2)获…...

Day69:WEB攻防-Java安全JWT攻防Swagger自动化算法签名密匙Druid泄漏
目录 Java安全-Druid监控-未授权访问&信息泄漏 黑盒发现 白盒发现 攻击点 Java安全-Swagger接口-导入&联动批量测试 黑盒发现 白盒发现 自动化发包测试 自动化漏洞测试 Java安全-JWT令牌-空算法&未签名&密匙提取 识别 JWT 方式一:人工识…...

Python Windows系统 虚拟环境使用
目录 1、安装 2、激活 3、停止 1、安装 1)为项目新建一个目录(比如:目录命名为learning_log) 2)在终端中切换到这个目录 3)执行命令:python -m venv ll_env,即可创建一个名为ll…...

栈和队列的学习
存储方式分两类:顺序存储和链式存储 栈:只允许从一端进行数据插入和删除的线性表:先进后出 FILO 队列:只允许从一端进行数据插入,另一端进行数据删除的线性表:先进先出 FIFO 栈 创建空栈,创建…...

【机器学习】基于机器学习的分类算法对比实验
摘要 基于机器学习的分类算法对比实验 本论文旨在对常见的分类算法进行综合比较和评估,并探索它们在机器学习分类领域的应用。实验结果显示,随机森林模型在CIFAR-10数据集上的精确度为0.4654,CatBoost模型为0.4916,XGBoost模型为…...

民航电子数据库:mysql与cae建表语法差异
目录 一、场景二、语法差异 一、场景 1、使用CAEMigrator-1.0.exe将mysql数据库迁移至cae数据库时,迁移速度非常慢,而且容易卡死(可能是部署cae数据库的服务器资源不足导致) 2、所以将mysql数据库导出为sql脚本,通过…...
(学习日记)2024.03.15:UCOSIII第十七节:任务的挂起和恢复
写在前面: 由于时间的不足与学习的碎片化,写博客变得有些奢侈。 但是对于记录学习(忘了以后能快速复习)的渴望一天天变得强烈。 既然如此 不如以天为单位,以时间为顺序,仅仅将博客当做一个知识学习的目录&a…...
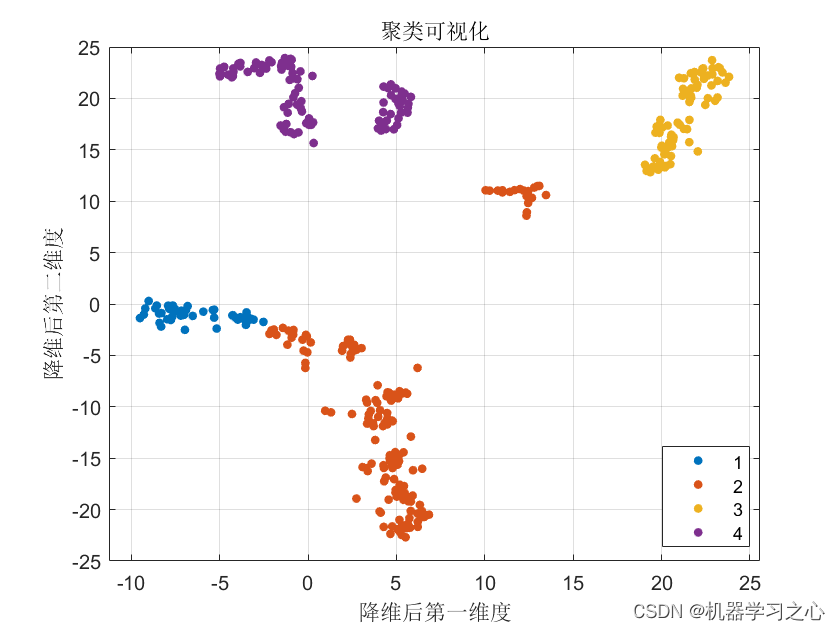
聚类分析 | Matlab实现基于NNMF+DBO+K-Medoids的数据聚类可视化
聚类分析 | Matlab实现基于NNMFDBOK-Medoids的数据聚类可视化 目录 聚类分析 | Matlab实现基于NNMFDBOK-Medoids的数据聚类可视化效果一览基本介绍程序设计参考资料 效果一览 基本介绍 NNMFDBOK-Medoids聚类,蜣螂优化算法DBO优化K-Medoids 非负矩阵分解(…...
Unity类银河恶魔城学习记录11-3 p105 Inventory UI源代码
Alex教程每一P的教程原代码加上我自己的理解初步理解写的注释,可供学习Alex教程的人参考 此代码仅为较上一P有所改变的代码 【Unity教程】从0编程制作类银河恶魔城游戏_哔哩哔哩_bilibili UI_itemSlot.cs using System.Collections; using System.Collections.Gen…...

Vue3 + Vite + ts引入本地图片
Vue3 Vite ts引入本地图片 单张图片导入 单个图片导入,不过多阐述,通过 import 导入需要使用的图片。 import imgName from /assets/img/imgName.png 多张图片导入 new URL() import.meta.url import.meta.url 是一个 ESM 的原生功能࿰…...
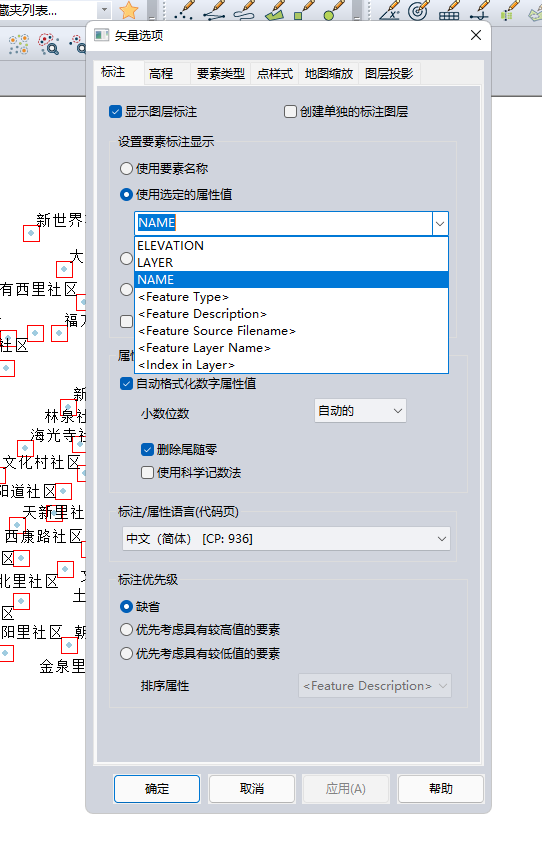
图斑或者道路如何单独显示名称在图斑上或者道路上
0序: 遇到过多个测绘、工程、林业相关业务的客户,在加载一些图斑数据,线路数据时,希望能够单独的把图斑的名称,显示到图斑上,或者路网上面。 之前多数推荐的办法: 1.shp可以直接在图新地球中…...

docker 修改默认存储位置
一般系统下系统盘可能磁盘空间有限,需要将docker的存储目录改到其他位置 docker info 查看docker的版本 低版本docker在配置json中增加"graph":"/var/lib/docker" 高版本docker在配置json中增加"data-root":"/var/lib/docker&q…...
Springboot+vue的医疗挂号管理系统+数据库+报告+免费远程调试
效果介绍: Springbootvue的医疗挂号管理系统,Javaee项目,springboot vue前后端分离项目 本文设计了一个基于Springbootvue的前后端分离的医疗挂号管理系统,采用M(model)V(view)C(con…...

【Effective C++】39 明智而审慎地使用private继承
在之前论证过c如何将public 继承视为 is-a 关系。在哪个例子里,class Student 以 public 形式继承class Person, 于是编译器在必要时刻将Students暗自转化为Person.如果此时我们以 private 继承替换 public继承。 class Person {...}; class Student: p…...
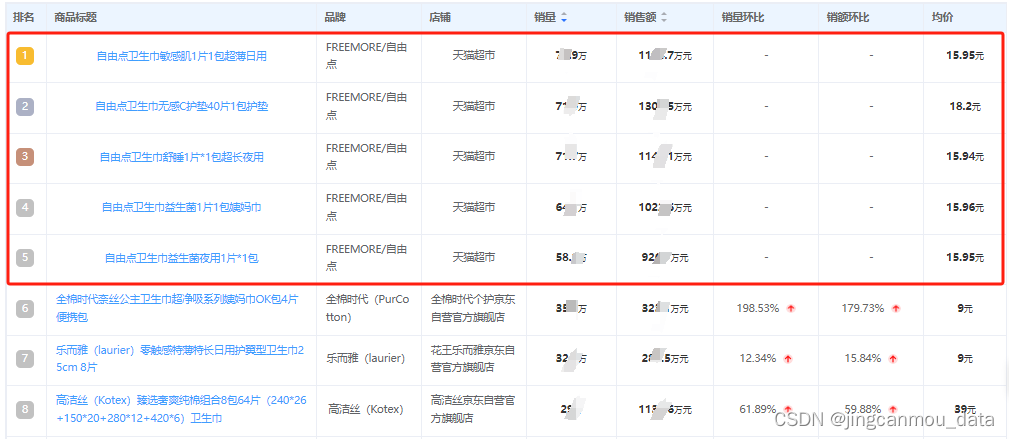
2024年卫生巾行业市场分析报告(京东天猫淘宝线上卫生巾品类电商数据查询)
最近,相关部门辟谣了一则“十大致癌卫生巾黑名单”的消息。这个榜单是部分博主AI撰写,为博眼球、蹭热度的结果。此次事件势必会对卫生巾行业产生一定影响,加剧行业竞争。 根据鲸参谋电商数据平台显示,2024年1月至2月线上电商平台…...

MySQL之表的记录操作
前言 存数据不是目的,目的是能够将存起来的数据取出来或者查出来,并且能够对数据进行增删改查操作,本文将详细介绍表中记录的增删改查操作。对记录的操作属于DML数据库操作语言,可以通过SQL实现对数据的操作,包括实现…...

一种动态联动的实现方法
安防领域中的联动规则 有安防领域相关的开发经历的人知道,IPCamera可以配置使能“侦测”功能,并且指定仅针对图像传感器的某个区载进行侦测。除了基本的“移动侦测"外,侦测的功能点还有细化的类别,如人员侦测、车辆侦测、烟…...
kotlin中使用ViewBinding绑定控件
kotlin中使用ViewBinding绑定控件 什么是ViewBinding? View Binding是Android Studio 3.6推出的新特性,主要用于减少findViewById的冗余代码,但内部实现还是通过使用findViewById。通过ViewBinding,可以更轻松地编写可与视图交互…...

Topit:macOS窗口置顶神器,让多任务处理效率翻倍
Topit:macOS窗口置顶神器,让多任务处理效率翻倍 【免费下载链接】Topit Pin any window to the top of your screen / 在Mac上将你的任何窗口强制置顶 项目地址: https://gitcode.com/gh_mirrors/to/Topit 你是否经常在macOS上同时处理多个任务时…...

AMLP框架实战:基于MACE构建高精度机器学习势函数
1. 项目概述:当机器学习势函数遇上自动化管道在计算化学和材料科学领域,我们长久以来面临着一个核心矛盾:精度与效率的权衡。密度泛函理论(DFT)能提供接近实验的精度,但计算成本高昂,通常只能处…...

D3KeyHelper:暗黑3玩家的智能按键助手,告别重复操作疲劳
D3KeyHelper:暗黑3玩家的智能按键助手,告别重复操作疲劳 【免费下载链接】D3keyHelper D3KeyHelper是一个有图形界面,可自定义配置的暗黑3鼠标宏工具。 项目地址: https://gitcode.com/gh_mirrors/d3/D3keyHelper 你是否曾在《暗黑破坏…...
:数组排序、去重、查找)
数组专项(一):数组排序、去重、查找
大家好,欢迎来到《算法面试60讲(2026最新版全真题带解析)》第19篇!上一篇我们彻底吃透了字符串专项的核心难点——BF暴力匹配与KMP高效匹配算法,搞定了字符串模块面试最难的算法考点。从本节课开始,我们正式进入算法面试第一高频模块:数组专项。 在算法面试中,数组是出…...

CUDA并行计算与FSR框架优化实践
1. CUDA并行计算与FSR框架概述在GPU加速计算领域,CUDA(Compute Unified Device Architecture)作为NVIDIA推出的并行计算平台和编程模型,已经成为高性能计算的事实标准。其核心设计理念是将计算任务分解为网格(Grid&…...

3分钟快速安装BetterNCM插件管理器,让你的网易云音乐功能翻倍
3分钟快速安装BetterNCM插件管理器,让你的网易云音乐功能翻倍 【免费下载链接】BetterNCM-Installer 一键安装 Better 系软件 项目地址: https://gitcode.com/gh_mirrors/be/BetterNCM-Installer 还在为网易云音乐功能单一而烦恼吗?想要解锁更多个…...

Lovable电商网站搭建:如何用不到3人技术团队,72小时内上线PCI-DSS合规MVP版本?
更多请点击: https://codechina.net 第一章:Lovable电商网站搭建 Lovable 是一个面向中小商户的轻量级电商解决方案,采用现代 Web 技术栈构建,强调可扩展性、用户体验与快速部署能力。本章将指导你从零开始搭建一个具备商品展示、…...
)
DeepSeek安全测试辅助Prompt工程白皮书(含17个CVE靶场验证指令模板)
更多请点击: https://intelliparadigm.com 第一章:DeepSeek安全测试辅助 DeepSeek系列大模型在代码生成、漏洞模式识别与安全上下文理解方面展现出独特优势,可作为安全测试工程师的智能协作者。其对OWASP Top 10、CWE分类体系及常见PoC结构具…...

量子机器学习与傅里叶分析:革新期权定价的混合计算范式
1. 项目概述:当量子机器学习遇见金融定价在金融工程的核心地带,期权定价一直是个计算密集型的硬骨头。传统的蒙特卡洛模拟虽然通用,但为了达到足够的精度,动辄需要百万甚至千万次的路径模拟,计算成本高昂。近年来&…...

qobuz-dl终极实战指南:专业无损音乐下载工具架构解析与高效应用
qobuz-dl终极实战指南:专业无损音乐下载工具架构解析与高效应用 【免费下载链接】qobuz-dl A complete Lossless and Hi-Res music downloader for Qobuz 项目地址: https://gitcode.com/gh_mirrors/qo/qobuz-dl 在数字音乐时代,追求极致音质的音…...