在项目中数据库如何优化?【MySQL主从复制(创建一个从节点复制备份数据)】【数据库读写分离ShardingJDBC(主库写,从库读)】
MySQL主从复制
- MySQL主从复制
- 介绍
- MySQL复制过程分成三步:
- 1). MySQL master 将数据变更写入二进制日志( binary log)
- 2). slave将master的binary log拷贝到它的中继日志(relay log)
- 3). slave重做中继日志中的事件,将数据变更反映它自己的数据
- 搭建
- 主库配置
- 从库配置
- 测试
- 读写分离案例
- 背景介绍
- ShardingJDBC介绍
- 数据库环境
- 初始工程导入
- 读写分离配置
- 测试
- 1). 保存数据
- 2). 修改数据
- 3). 查询数据
- 4). 删除数据
MySQL主从复制
MySQL数据库默认是支持主从复制的,不需要借助于其他的技术,我们只需要在数据库中简单的配置即可。接下来,我们就从以下的几个方面,来介绍一下主从复制:
介绍
MySQL主从复制是一个异步的复制过程,底层是基于Mysql数据库自带的 二进制日志 功能。就是一台或多台MySQL数据库(slave,即从库)从另一台MySQL数据库(master,即主库)进行日志的复制,然后再解析日志并应用到自身,最终实现 从库 的数据和 主库 的数据保持一致。MySQL主从复制是MySQL数据库自带功能,无需借助第三方工具。
二进制日志:
二进制日志(BINLOG)记录了所有的 DDL(数据定义语言)语句和 DML(数据操纵语言)语句,但是不包括数据查询语句。此日志对于灾难时的数据恢复起着极其重要的作用,MySQL的主从复制, 就是通过该binlog实现的。默认MySQL是未开启该日志的。
MySQL的主从复制原理如下:

MySQL复制过程分成三步:
1). MySQL master 将数据变更写入二进制日志( binary log)
2). slave将master的binary log拷贝到它的中继日志(relay log)
3). slave重做中继日志中的事件,将数据变更反映它自己的数据
搭建
提前准备两台服务器,并且在服务器中安装MySQL,服务器的信息如下:

并在两台服务器上做如下准备工作:
1). 防火墙开放3306端口号
firewall-cmd --zone=public --add-port=3306/tcp --permanentfirewall-cmd --zone=public --list-ports

2). 并将两台数据库服务器启动起来:
systemctl start mysqld
登录MySQL,验证是否正常启动

主库配置
服务器: 192.168.200.200
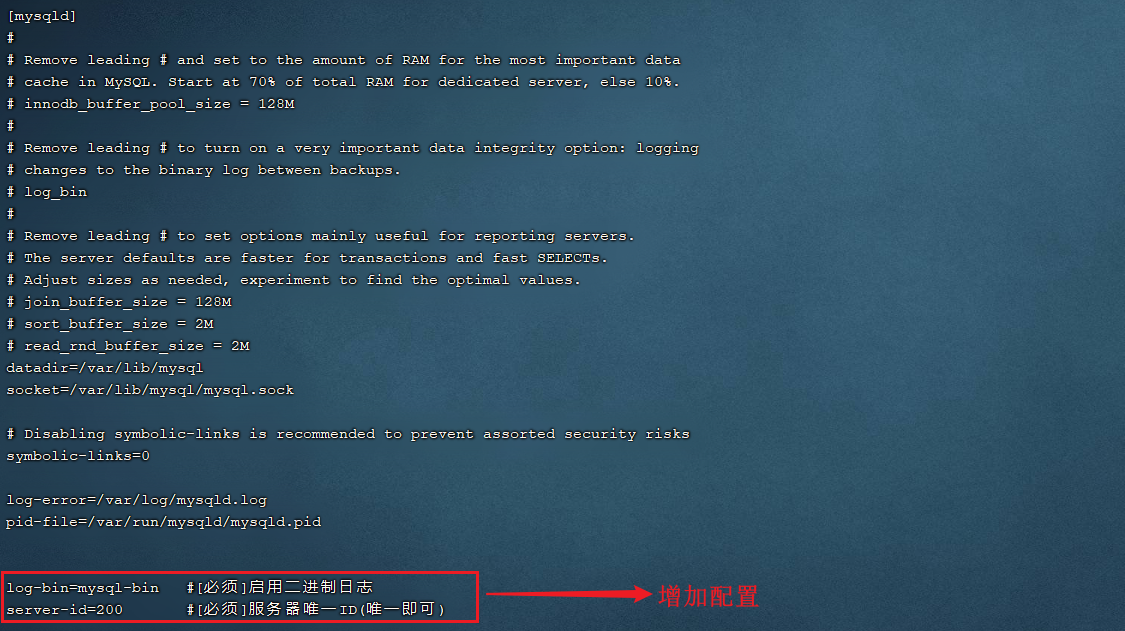
1). 修改Mysql数据库的配置文件/etc/my.cnf
在最下面增加配置:
log-bin=mysql-bin #[必须]启用二进制日志
server-id=200 #[必须]服务器唯一ID(唯一即可)
2). 重启Mysql服务
执行指令:
systemctl restart mysqld

3). 创建数据同步的用户并授权
登录mysql,并执行如下指令,创建用户并授权:
GRANT REPLICATION SLAVE ON *.* to 'xiaoming'@'%' identified by 'Root@123456';
注:上面SQL的作用是创建一个用户 xiaoming ,密码为 Root@123456 ,并且给xiaoming用户授予REPLICATION SLAVE权限。常用于建立复制时所需要用到的用户权限,也就是slave必须被master授权具有该权限的用户,才能通过该用户复制。
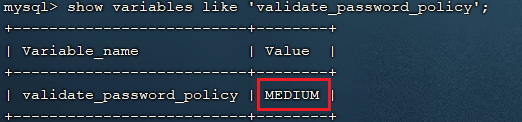
MySQL密码复杂程度说明:
目前mysql5.7默认密码校验策略等级为 MEDIUM , 该等级要求密码组成为: 数字、小写字母、大写字母 、特殊字符、长度至少8位
4). 登录Mysql数据库,查看master同步状态
执行下面SQL,记录下结果中File和Position的值
show master status;

注:上面SQL的作用是查看Master的状态,执行完此SQL后不要再执行任何操作
从库配置
服务器: 192.168.200.201
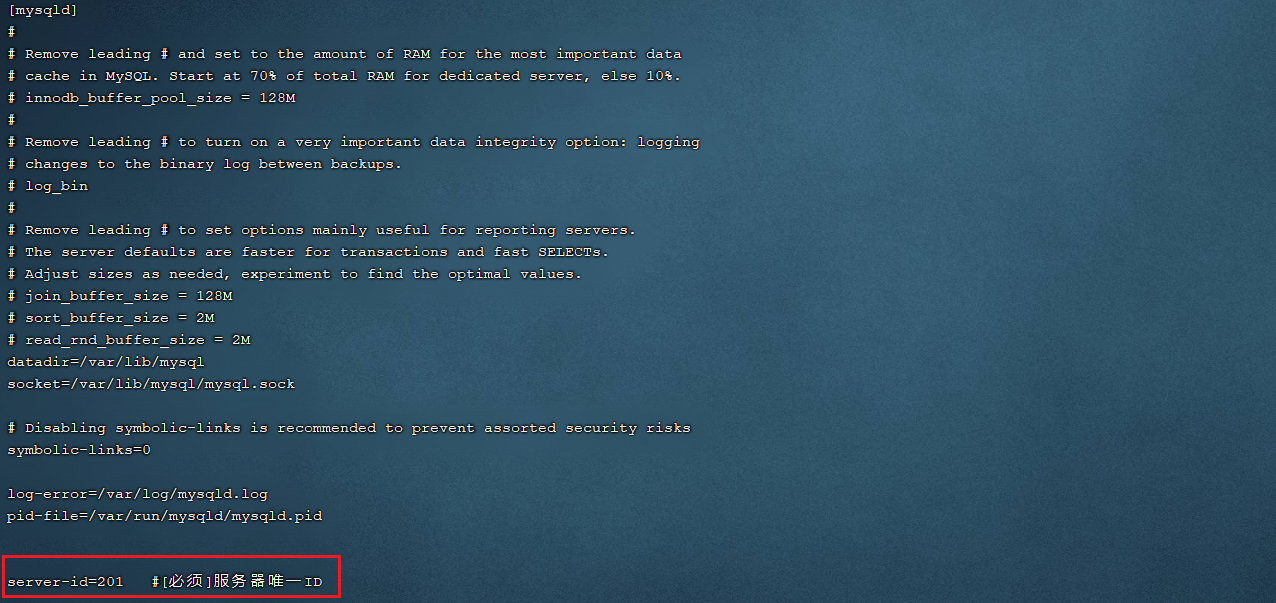
1). 修改Mysql数据库的配置文件/etc/my.cnf
server-id=201 #[必须]服务器唯一ID
2). 重启Mysql服务
systemctl restart mysqld
3). 登录Mysql数据库,设置主库地址及同步位置
change master to master_host='192.168.200.200',master_user='xiaoming',master_password='Root@123456',master_log_file='mysql-bin.000001',master_log_pos=154;start slave;
参数说明:
A. master_host : 主库的IP地址
B. master_user : 访问主库进行主从复制的用户名(上面在主库创建的)
C. master_password : 访问主库进行主从复制的用户名对应的密码
D. master_log_file : 从哪个日志文件开始同步(上述查询master状态中展示的有)
E. master_log_pos : 从指定日志文件的哪个位置开始同步(上述查询master状态中展示的有)
4). 查看从数据库的状态
show slave status;
然后通过状态信息中的 Slave_IO_running 和 Slave_SQL_running 可以看出主从同步是否就绪,如果这两个参数全为Yes,表示主从同步已经配置完成。

MySQL命令行技巧:
\G : 在MySQL的sql语句后加上\G,表示将查询结果进行按列打印,可以使每个字段打印到单独的行。即将查到的结构旋转90度变成纵向;
测试
主从复制的环境,已经搭建好了,接下来,我们可以通过Navicat连接上两台MySQL服务器,进行测试。测试时,我们只需要在主库Master执行操作,查看从库Slave中是否将数据同步过去即可。
1). 在master中创建数据库itcast, 刷新slave查看是否可以同步过去
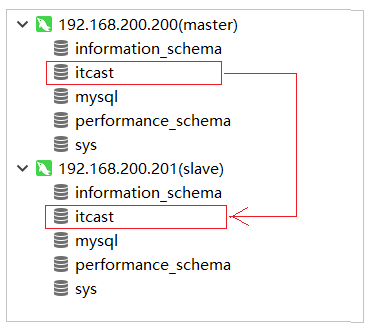
2). 在master的itcast数据下创建user表, 刷新slave查看是否可以同步过去

3). 在master的user表中插入一条数据, 刷新slave查看是否可以同步过去

读写分离案例
背景介绍
面对日益增加的系统访问量,数据库的吞吐量面临着巨大瓶颈。 对于同一时刻有大量并发读操作和较少写操作类型的应用系统来说,将数据库拆分为主库和从库,主库负责处理事务性的增删改操作,从库负责处理查询操作,能够有效的避免由数据更新导致的行锁,使得整个系统的查询性能得到极大的改善。
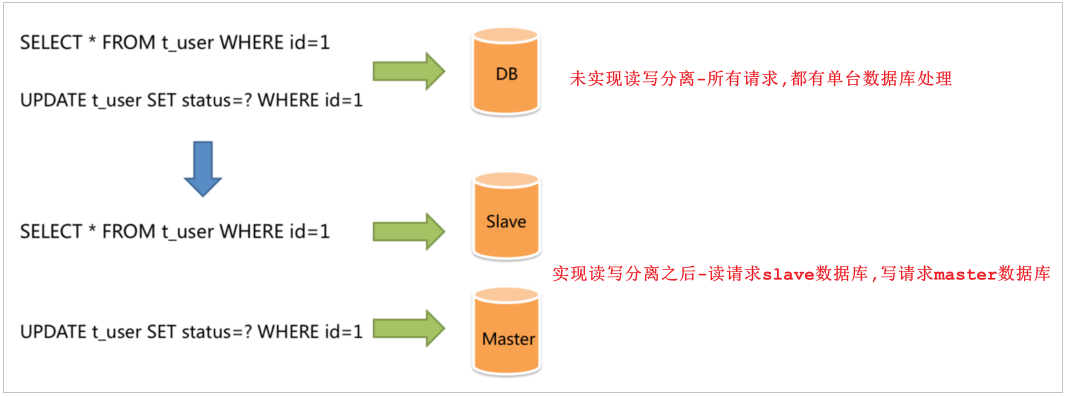
通过读写分离,就可以降低单台数据库的访问压力, 提高访问效率,也可以避免单机故障。
主从复制的结构,我们在第一节已经完成了,那么我们在项目中,如何通过java代码来完成读写分离呢,如何在执行select的时候查询从库,而在执行insert、update、delete的时候,操作主库呢?这个时候,我们就需要介绍一个新的技术 ShardingJDBC。
ShardingJDBC介绍
Sharding-JDBC定位为轻量级Java框架,在Java的JDBC层提供的额外服务。 它使用客户端直连数据库,以jar包形式提供服务,无需额外部署和依赖,可理解为增强版的JDBC驱动,完全兼容JDBC和各种ORM框架。
使用Sharding-JDBC可以在程序中轻松的实现数据库读写分离。
Sharding-JDBC具有以下几个特点:
1). 适用于任何基于JDBC的ORM框架,如:JPA, Hibernate, Mybatis, Spring JDBC Template或直接使用JDBC。
2). 支持任何第三方的数据库连接池,如:DBCP, C3P0, BoneCP, Druid, HikariCP等。
3). 支持任意实现JDBC规范的数据库。目前支持MySQL,Oracle,SQLServer,PostgreSQL以及任何遵循SQL92标准的数据库。
依赖:
<dependency><groupId>org.apache.shardingsphere</groupId><artifactId>sharding-jdbc-spring-boot-starter</artifactId><version>4.0.0-RC1</version>
</dependency>
数据库环境
在主库中创建一个数据库rw, 并且创建一张表, 该数据库及表结构创建完毕后会自动同步至从数据库,SQL语句如下:
create database rw default charset utf8mb4;use rw;CREATE TABLE `user` (`id` int(11) NOT NULL AUTO_INCREMENT,`name` varchar(255) DEFAULT NULL,`age` int(11) DEFAULT NULL,`address` varchar(255) DEFAULT NULL,PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
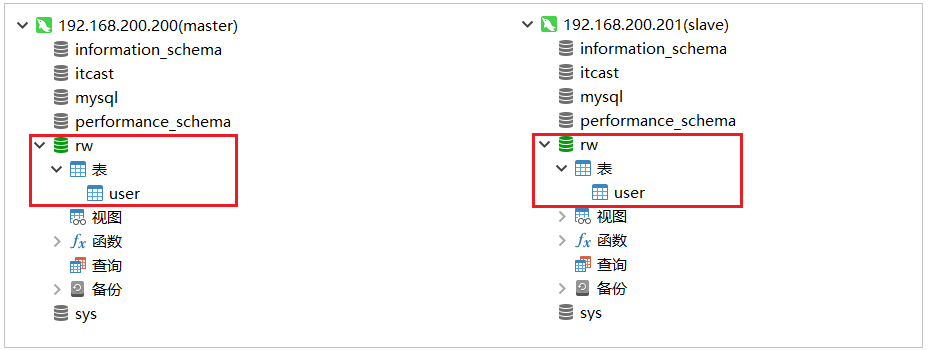
初始工程导入

读写分离配置
1). 在pom.xml中增加shardingJdbc的maven坐标
<dependency><groupId>org.apache.shardingsphere</groupId><artifactId>sharding-jdbc-spring-boot-starter</artifactId><version>4.0.0-RC1</version>
</dependency>
2). 在application.yml中增加数据源的配置
spring:shardingsphere:datasource:names:master,slave# 主数据源master:type: com.alibaba.druid.pool.DruidDataSourcedriver-class-name: com.mysql.cj.jdbc.Driverurl: jdbc:mysql://192.168.200.200:3306/rw?characterEncoding=utf-8username: rootpassword: root# 从数据源slave:type: com.alibaba.druid.pool.DruidDataSourcedriver-class-name: com.mysql.cj.jdbc.Driverurl: jdbc:mysql://192.168.200.201:3306/rw?characterEncoding=utf-8username: rootpassword: rootmasterslave:# 读写分离配置load-balance-algorithm-type: round_robin #轮询# 最终的数据源名称name: dataSource# 主库数据源名称master-data-source-name: master# 从库数据源名称列表,多个逗号分隔slave-data-source-names: slaveprops:sql:show: true #开启SQL显示,默认false
配置解析:

3). 在application.yml中增加配置
spring: main:allow-bean-definition-overriding: true
该配置项的目的,就是如果当前项目中存在同名的bean,后定义的bean会覆盖先定义的。
如果不配置该项,项目启动之后将会报错:

报错信息表明,在声明 org.apache.shardingsphere.shardingjdbc.spring.boot 包下的SpringBootConfiguration中的dataSource这个bean时出错, 原因是有一个同名的 dataSource 的bean在com.alibaba.druid.spring.boot.autoconfigure包下的DruidDataSourceAutoConfigure类加载时已经声明了。


而我们需要用到的是 shardingjdbc包下的dataSource,所以我们需要配置上述属性,让后加载的覆盖先加载的。
测试
我们使用shardingjdbc来实现读写分离,直接通过上述简单的配置就可以了。配置完毕之后,我们就可以重启服务,通过postman来访问controller的方法,来完成用户信息的增删改查,我们可以通过debug及日志的方式来查看每一次执行增删改查操作,使用的是哪个数据源,连接的是哪个数据库。
1). 保存数据

控制台输出日志,可以看到操作master主库:

2). 修改数据

控制台输出日志,可以看到操作master主库:

3). 查询数据

控制台输出日志,可以看到操作slave主库:

4). 删除数据

控制台输出日志,可以看到操作master主库:

相关文章:
在项目中数据库如何优化?【MySQL主从复制(创建一个从节点复制备份数据)】【数据库读写分离ShardingJDBC(主库写,从库读)】
MySQL主从复制 MySQL主从复制介绍MySQL复制过程分成三步:1). MySQL master 将数据变更写入二进制日志( binary log)2). slave将master的binary log拷贝到它的中继日志(relay log)3). slave重做中继日志中的事件,将数据变更反映它自…...
Fragment 与 ViewPager的联合应用(2)
5.创建底部布局bottom_layout <LinearLayout xmlns:android"http://schemas.android.com/apk/res/android"android:orientation"horizontal"android:layout_width"match_parent"android:layout_height"55dp"android:background&qu…...

OriginBot智能机器人开源套件
详情可参见:OriginBot智能机器人开源套件——支持ROS2/TogetherROS,算力强劲,配套古月居定制课程 (guyuehome.com) OriginBot智能机器人开源套件 最新消息:OriginBot V2.1.0版本正式发布,新增车牌识别,点击…...
Java Web-Maven
Maven是apache旗下的一个开源项目,是一款用于管理和构建java项目的工具 Maven的作用 1.依赖管理:方便快捷的管理项目依赖资源(jar包),避免版本冲突问题 我们有的项目需要大量的jar包,采用手动导包的方式非常繁琐,并且版本升级也…...

.Net 异步委托
委托的 BeginInvoke 方法和 EndInvoke 方法可以实现异步执行委托方法。这允许委托的方法在后台线程中执行,而不会阻塞当前线程。小编在之前的webform开发中遇到下载进度条卡死的问题就是用它解决的。 案例: namespace ConsoleApplication1 {class Progr…...
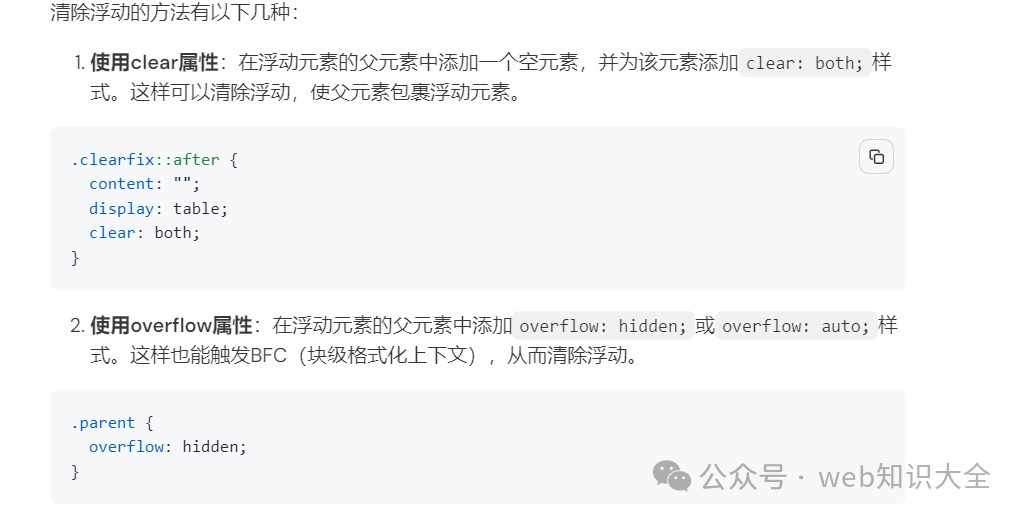
web前端面试题---->HTML、CSS
一.居中方法 block元素如何居中 margin:0 auto;position: absolute; top: 50%; left: 50%; transform: translate(-50%, -50%);flex布局: 对父元素操作 : justify-content:center; al…...

移动端Web笔记day03
移动 Web 第三题 01-移动 Web 基础 谷歌模拟器 模拟移动设备,方便查看页面效果,移动端的效果是当手机屏幕发生了变化,页面和页面中的元素也要跟着等比例变化。 屏幕分辨率 分类: 硬件分辨路 -> 物理分辨率:硬件…...
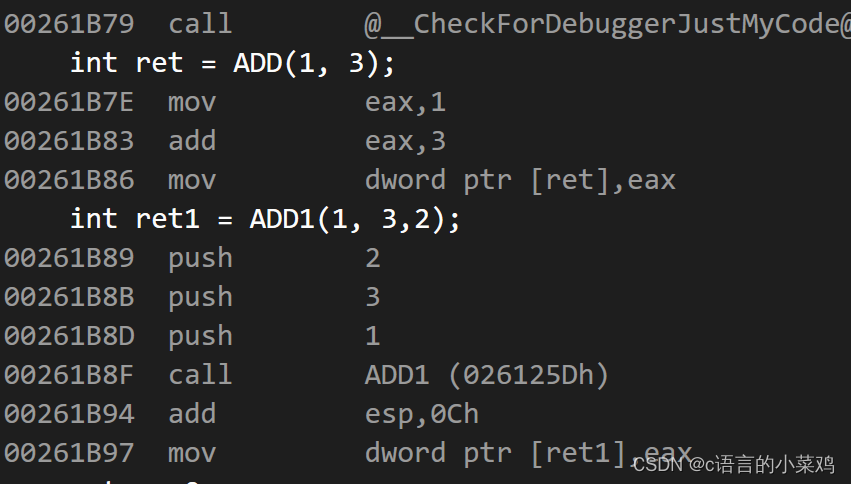
c++的学习之路:3、入门(2)
一、引用 1、引用的概念 引用不是新定义一个变量,而是给已存在变量取了一个别名,编译器不会为引用变量开辟内存空 间,它和它引用的变量共用同一块内存空间。 怎么说呢,简单点理解就是你的小名,家里人叫你小名&#…...
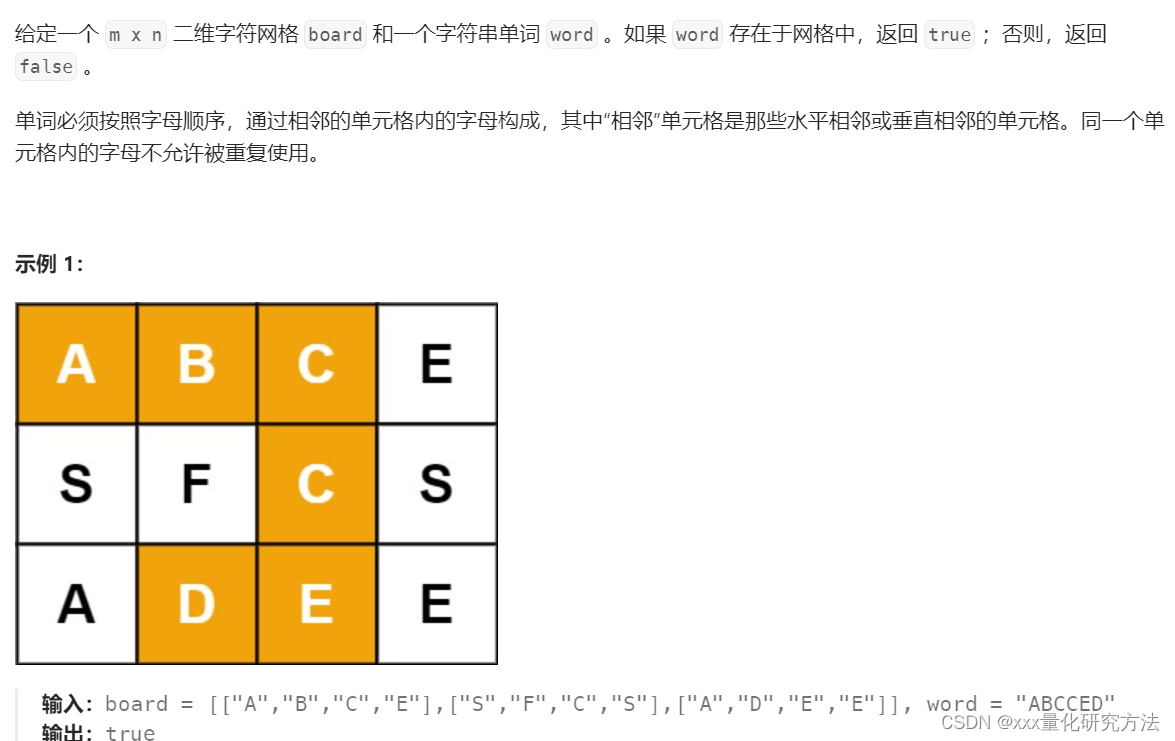
面试经典150题【91-100】
文章目录 面试经典150题【91-100】70.爬楼梯198.打家劫舍139.单词拆分322.零钱兑换300.递增最长子序列77.组合46.全排列39.组合总和(※)22.括号生成79.单词搜索 面试经典150题【91-100】 五道一维dp题五道回溯题。 70.爬楼梯 从递归到动态规划 public …...

在 nginx 中使用 JavaScript
前些日子尝试了在 nginx 中写 JavaScript 的效果。考虑到 JavaScript 作为编程语言不是强需求,在nginx生态上还是 lua 独大,并且还有 openresty 这样一直强力输血,大部分应用场景都能找到参考的解决方案。 插件生态来说,github 上…...

【pytorch】安装合集
使用conda或者pip安装的指令 https://pytorch.org/get-started/previous-versions/ 测试pytorch_gpu是否可用的代码 # 测试pytorch是否安装成功 import torch print(torch.__version__) print(torch.cuda.is_available())...

【教程】PLSQL查看表属性乱码解决方法
一、前言 PL/SQL是Oracle数据库的编程语言,用于编写存储过程、触发器、函数等。 今天用plsql想查看表的属性,看看各个字段的注释,可是打开一看,居然是乱码的,如下面这样 如果在使用PL/SQL查看表属性时出现乱码&…...

新书速览|Django 5企业级Web应用开发实战:视频教学版
掌握Django框架开发技能,实战投票应用系统和内容管理系统 本书内容 《Django 5企业级Web应用开发实战:视频教学版》精选当前简单、实用和流行的Django实例代码,帮助读者学习和掌握Django 5框架及其相关技术栈的开发知识。本书系统全面、内容…...

excel创建和部分使用
一.excel导出是在开发中经常操作的内容,对于excel的导出也是有各种成熟的api组件 这里是最近的项目有通过ts处理,这里的内容通过ts ①引入const XlsxPopulate require("xlsx-populate"); const XLSXChart require("xlsx-chart"); 通过命令行操作, pnp…...

pycharm使用远程服务器的jupyter环境
1、确保服务器上安装了jupyter,如果没有,执行下面命令安装 pip install jupyter2、启动jupyter notebook服务 jupyter notebook --no-browser --port8888 --ip0.0.0.0 --allow-root表明在服务器的8888 端口上启动 Jupyter Notebook,并允许从任何 IP 地…...
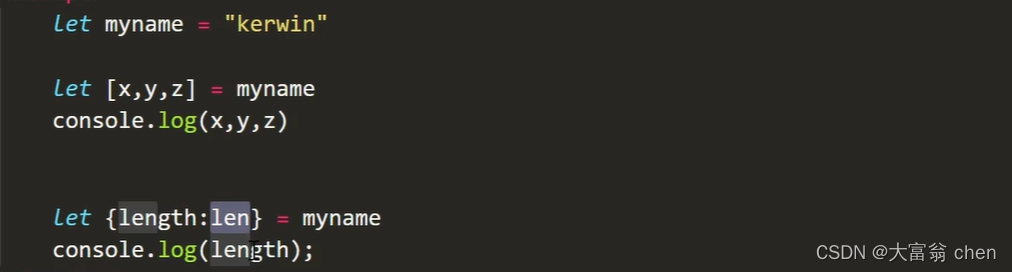
ES6 基础
文章目录 1. 初识 ES62. let 声明变量3. const 声明常量4. 解构赋值 1. 初识 ES6 ECMAScript6.0(以下简称ES6)是JavaScript语言的下一代标准,已经在2015年6月正式发布了。它的目标,是使得」JavaScript语言可以用来编写复杂的大型应用程序,成为…...

【双指针】Leetcode 有效三角形的个数
题目解析 611. 有效三角形的个数 算法讲解 回顾知识:任意两数之和大于第三数就可以构成三角形 算法 1:暴力枚举 int triangleNumber(vector<int>& nums) {// 1. 排序sort(nums.begin(), nums.end());int n nums.size(), ret 0;// 2. 从…...

python项目练习——4.手写数字识别
使用Python和Scikit-learn库进行机器学习模型训练的项目——手写数字识别。 项目分析: 数据准备:使用公开数据集(如MNIST)作为训练和测试数据。数据预处理:对图像数据进行归一化、展平等操作,以便输入到机…...

【目标检测】NMS算法的理论讲解
将NMS就必须先讲IOU, IOU就是交并比,两个检测框的交集除以两个检测框的并集就是IOU 为什么要做NMS操作,因为要去除同一个物体的多的冗余检测框 那么NMS算法是如何做的呢? 以上是算法的流程图 下面讲解算法的流程 首先输入是预…...
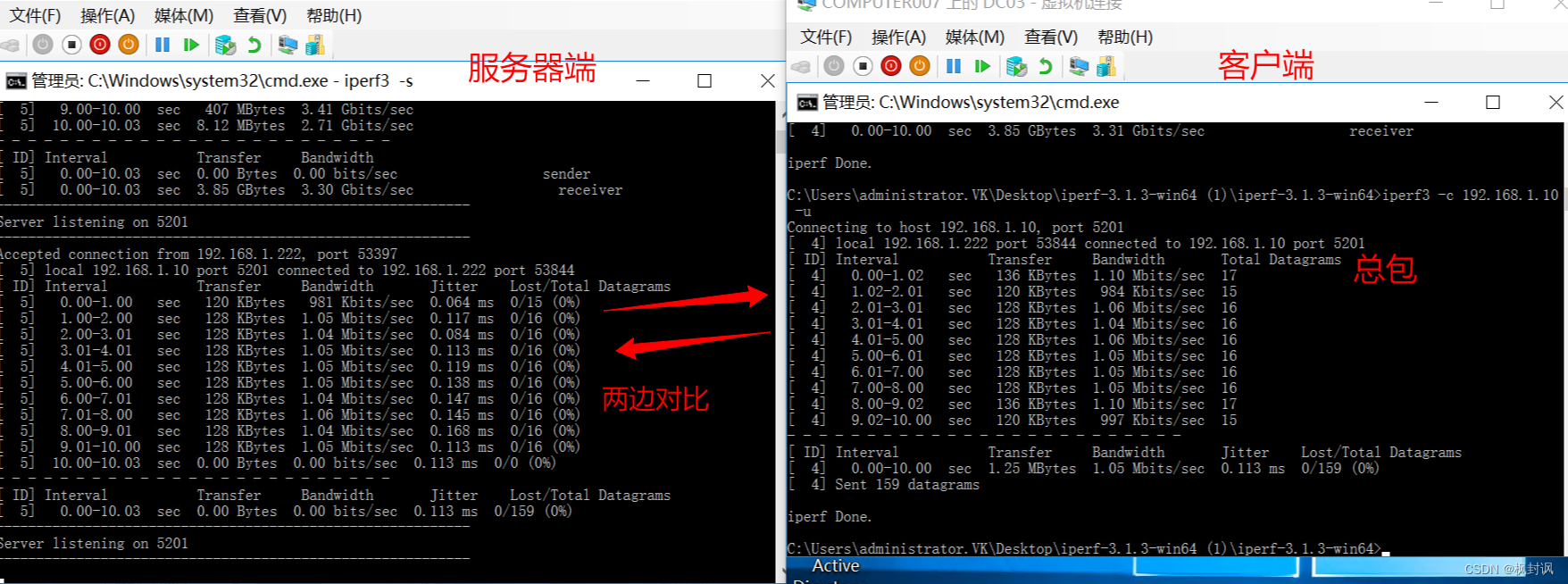
3-iperf3 使用什么工具可以检测网络带宽、延迟和数据包丢失率等网络性能参数呢?
(1)iperf3简介 1.iperf3简介 2.用途(特点) 3.下载iperf3地址 (2)实战 1.iperf3参数 (1)通用参数(客户端和服务器端都是适用的) (2)客户端参数 实验1&…...

混合精度递归Cholesky分解:算法优化与硬件加速实践
1. 混合精度递归Cholesky分解的技术背景在科学计算领域,对称正定(SPD)线性系统的求解是一个基础而关键的问题。这类问题广泛存在于计算流体动力学、气候建模、金融风险分析等实际应用中。以气候建模为例,全球大气环流模型需要求解的线性系统矩阵规模可达…...
)
Hackbar收费了怎么办?手把手教你配置Tampermonkey脚本实现类似功能(附常用脚本分享)
Hackbar收费后的完美替代方案:Tampermonkey脚本实战指南 当Hackbar从免费转向收费模式时,许多安全研究人员和开发者都感到措手不及。这款曾经被誉为"渗透测试瑞士军刀"的浏览器插件突然变成了付费墙后的工具,让不少用户开始寻找替…...

如何快速配置大麦抢票自动化工具:5个步骤实现高效网络诊断与抓包分析
如何快速配置大麦抢票自动化工具:5个步骤实现高效网络诊断与抓包分析 【免费下载链接】ticket-purchase 大麦自动抢票,支持人员、城市、日期场次、价格选择 项目地址: https://gitcode.com/GitHub_Trending/ti/ticket-purchase 你是否曾因大麦网抢…...
、 小模型(小脑、肌肉记忆、条件反射)功能的差别,会导致模型在结构和训练等维度上哪些差别?!!)
[具身智能-857]:大模型(大脑、知识记忆、反复推演)、 小模型(小脑、肌肉记忆、条件反射)功能的差别,会导致模型在结构和训练等维度上哪些差别?!!
大脑大模型 VS 小脑小模型:功能差异→结构差异→训练差异 全维度对比一、核心功能差异(根源)大脑大模型:负责认知理解、语义交互、多轮逻辑推演、长时序任务规划、经验归纳、知识推理,先思后行,全局预判&am…...

Taotoken控制台的用量看板与账单追溯功能如何助力团队成本管理
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken控制台的用量看板与账单追溯功能如何助力团队成本管理 对于团队管理者或项目负责人而言,将大模型能力整合进业…...

Unity 2D基础:2D相机Orthographic的参数调节
Unity 2D基础:2D相机Orthographic的参数调节📚 本章学习目标:深入理解2D相机Orthographic的参数调节的核心概念与实践方法,掌握关键技术要点,了解实际应用场景与最佳实践。本文属于《Unity工程师成长之路教程》Unity 2…...

从账单视角看 Taotoken Token Plan 套餐带来的月度成本优化
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 从账单视角看 Taotoken Token Plan 套餐带来的月度成本优化 效果展示类,通过分享一个中型项目在采用 Taotoken 按 toke…...

ComfyUI-Custom-Scripts自动完成终极指南:如何快速提升AI绘画提示词效率
ComfyUI-Custom-Scripts自动完成终极指南:如何快速提升AI绘画提示词效率 【免费下载链接】ComfyUI-Custom-Scripts Enhancements & experiments for ComfyUI, mostly focusing on UI features 项目地址: https://gitcode.com/gh_mirrors/co/ComfyUI-Custom-Sc…...

8051单片机中断向量号计算与配置详解
1. C51中断向量号计算方法解析在8051单片机开发中,中断处理是最核心的功能之一。作为一名长期使用Keil C51工具链的嵌入式开发者,我经常遇到新手询问如何正确计算中断向量号的问题。这个看似简单的数字背后,其实隐藏着8051架构的设计哲学。1.…...
)
告别Bowtie2!用Minimap2搞定FASTQ到BAM的保姆级流程(含最新参数详解)
告别Bowtie2!用Minimap2搞定FASTQ到BAM的保姆级流程(含最新参数详解) 在生物信息学领域,测序数据的比对分析一直是核心工作流程之一。随着测序技术的快速发展,传统的比对工具如Bowtie2在处理长读长测序数据时逐渐显现出…...