MySQL开窗函数
测试环境:mysql8.0.18
官方文档:https://dev.mysql.com/doc/refman/8.0/en/window-functions.html
- 一、窗口函数介绍
- 二、语法结构
- 三、自定义窗口
- 1.rows(重点)
- 2.range
- 3.默认窗口
- 四、常用窗口函数示例
- 1.row_number & rank & dense_rank
- 2.lead & lag
- 3.first_value & last_value & nth_value
- 4.ntile
- 5.cume_dist & percent_rank(了解)
一、窗口函数介绍
开窗函数是mysql8.0中的新特性,用于实现和group by分组函数类似的分组聚合功能。区别在于:
- 分组函数:对一个集合输出一个标量结果,改变了数据的粒度,且丢失了非分组字段及非聚合字段的信息。
- 开窗函数:分别以每一行为当前行,与当前行相关的所有行为窗口,对同一个窗口内的数据进行聚合等类似操作,结果附加到当前行的后面,不改变原始数据粒度,不丢失原始数据信息。
二、语法结构
开窗函数|聚合函数 over([分组函数] [排序函数] [自定义窗口]) ,over是进行开窗,里面的分组函数、排序函数、自定义窗口都可以省略。
开窗函数|聚合函数:不可省略,用于对窗口范围内的所有数据行进行某种指定操作。可以是只适用于开窗函数的非聚合函数(https://dev.mysql.com/doc/refman/8.0/en/window-functions-usage.html),也可以是适用于group by的聚合函数(https://dev.mysql.com/doc/refman/8.0/en/aggregate-functions.html)。
分组函数:partition by ...,根据指定的字段对表分组,分组字段可以有多个。省略时表示整个表为一组。
排序函数:order by ...,排序字段也可以有多个,当排序字段为多个时表示先按照第一个字段排序,当第一个字段相等确定不了顺序时再按照第二个字段排序,以此类推…
三、自定义窗口
这部分可以直接查看文档https://dev.mysql.com/doc/refman/8.0/en/window-functions-frames.html,个人觉得这部分算是开窗函数里最重要的了,弄明白了各种情况下窗口的大小,其他的就没啥容易混淆的点了。
mysql中的窗口类型有两种:rows和range。rows是以物理行距离为基准通过计算与当前行的物理距离计算窗口大小,range是以当前行的值为基准通过计算与当前行值的差值计算窗口大小。
窗口大小可通过between 上界 and 下界来指定,其中,窗口的上下界分别有下面几种取值:
unbounded preceding:包含当前行及当前行之前的所有记录。n preceding:包含当前行及当前行之前的n-1行,实际窗口大小n。current row:仅包含当前行。unbounded following:包含当前行及当前行之后的所有记录。n following:包含当前行及当前行之后的n-1行,实际窗口大小n。
当窗口下界为current row时,可以不使用between and,也就是下面几种情况可简写:
1)between unbounded preceding and current row --> unbounded preceding
2)between n preceding and current row --> n preceding
3)between current row and current row --> current row
而following的情况不支持简写,原因可以参考下怎么理解mysql开窗函数 unbounded following这种简写形式不支持 而unbounded preceding支持,觉得有些道理。
1.rows(重点)
物理范围窗口,窗口大小只与当前行的物理距离有关。下面造点测试数据:
create table test_rows_range as
select 1 as id, '2020-10-03' as trans_date, 349 as sales
union all
select 2 as id, '2020-10-01' as trans_date, 563 as sales
union all
select 3 as id, '2020-10-02' as trans_date, 716 as sales
union all
select 4 as id, '2020-10-05' as trans_date, 628 as sales
union all
select 5 as id, '2020-10-02' as trans_date, 412 as sales
union all
select 6 as id, '2020-10-02' as trans_date, 857 as sales
union all
select 7 as id, '2020-10-08' as trans_date, 201 as sales
union all
select 8 as id, '2020-10-05' as trans_date, 191 as sales
union all
select 9 as id, '2020-10-06' as trans_date, 675 as sales
union all
select 10 as id, '2020-10-08' as trans_date, 941 as sales;

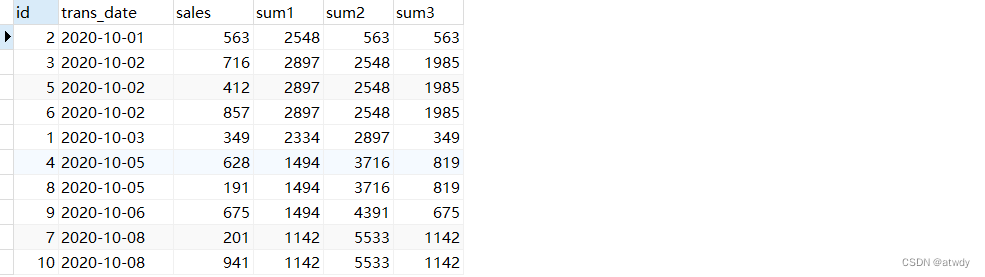
select *,sum(sales) over(order by trans_date rows between 1 preceding and 1 following) as sum1, -- 当前行的前一行、后一行、及当前行共3行作为一个窗口sum(sales) over(order by trans_date rows unbounded preceding) as sum2, -- 当前行及当前行之前的所有行为窗口sum(sales) over(order by trans_date rows current row) as sum3 -- 仅取当前行为窗口
from test_rows_range;
output:

2.range
逻辑范围窗口,业务中一般都会和order by连用,否则使用range窗口没啥实际意义。range类型窗口的上下界依然可以沿用rows类型窗口的上下界,规则是以当前行order by字段的值为基准,对值按照指定的上下界范围进行加减操作以确定逻辑窗口上下界的值。例如当前行的值为3,自定义窗口大小为range between 2 preceding and 1 following,那么此时逻辑窗口的临界值为[3-2, 3+1] -> [1, 4],所有order by字段值在该范围内的行都属于当前行窗口中的记录。
这里有两个小细节:
1)因为range是以行的值为基准,按照指定的上下界对值进行加减操作以确定窗口上下临界值的范围,因此range窗口的order by排序字段只能是数值型或日期时间类型这样支持逻辑意义上加减的字段类型,否则像varchar这种类型就会报下面这个错误:
> 3587 - Window '<unnamed window>' with RANGE N PRECEDING/FOLLOWING frame requires exactly one ORDER BY expression, of numeric or temporal type
2)当排序字段为数值型时,自定义窗口的格式可以直接沿用rows中列举的上下界,例如range n preceding,这时窗口的上界值为当前行的值-n。但是如果为时间日期类型时对于n preceding这样的上界就不能使用了,因为mysql不知道是在这个时间日期的基础上-n day?还是-n hour?,因此需要用range between interval 1 day preceding and interval 1 day following这种语法格式明确一下,否则会报下面异常:
> 3588 - Window '<unnamed window>' with RANGE frame has ORDER BY expression of datetime type. Only INTERVAL bound value allowed.
但是,对于unbounded preceding这样的上界,就不用interval的形式指定,很好理解,这种上界包括了所有小于当前行的值的记录,此时是- day还是- hour已经不重要了。
-- 修改trans_date字段类型为date
alter table test_rows_range modify trans_date date;select *,sum(sales) over(order by trans_date range between interval 1 day preceding and interval 1 day following) as sum1, -- 当前行的日期&前一天的日期&后一天的日期 的所有行作为一个窗口sum(sales) over(order by trans_date range unbounded preceding) as sum2, -- 所有小于等于当前行日期的行作为窗口sum(sales) over(order by trans_date range current row) as sum3 -- 仅取和当前行日期相等的行作为窗口
from test_rows_range;
output:
3.默认窗口
如果不显式指定窗口大小,则默认窗口大小主要分为over()中有没有order by子句两种情况:
- 没有
order by子句:默认窗口为每个组内的全部行。 - 有
order by子句:默认窗口为range unbounded preceding。
select *,sum(sales) over() as sum1, -- 无order by,窗口范围为全部行sum(sales) over(order by trans_date) as sum2 -- 有order by,窗口范围为当前行及之前的所有行
from test_rows_range;
output:

四、常用窗口函数示例
这部分可以直接查看文档https://dev.mysql.com/doc/refman/8.0/en/window-function-descriptions.html
1.row_number & rank & dense_rank
这三个都是排序函数,区别在于:
- row_number():序号不重复,不间断。
- rank():序号可重复,可间断。
- dense_rank(),序号可重复,不间断。
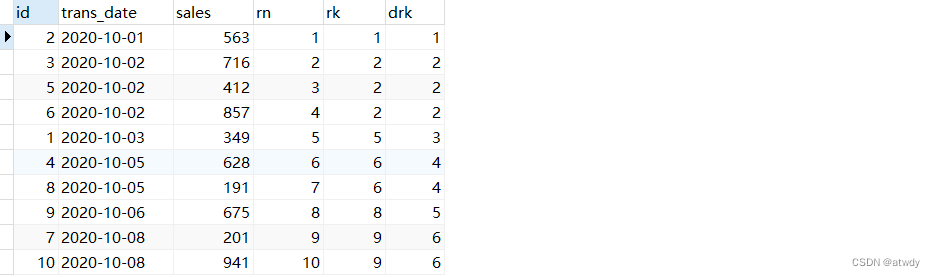
select *,row_number() over(order by trans_date) as rn,rank() over(order by trans_date) as rk, dense_rank() over(order by trans_date) as drk
from test_rows_range;
output:
2.lead & lag
对指定字段整体上移(lead)或者下移(lag)。
- lead(col, n, default):上移。参数col表示移动的字段,不可缺省;参数n表示移动的距离,可缺省,缺省值默认值为1;参数default表示当出现空值时用来填充的默认值,可缺省,缺省时用null填充。
- lag(col, n, default):下移,参数含义同上。
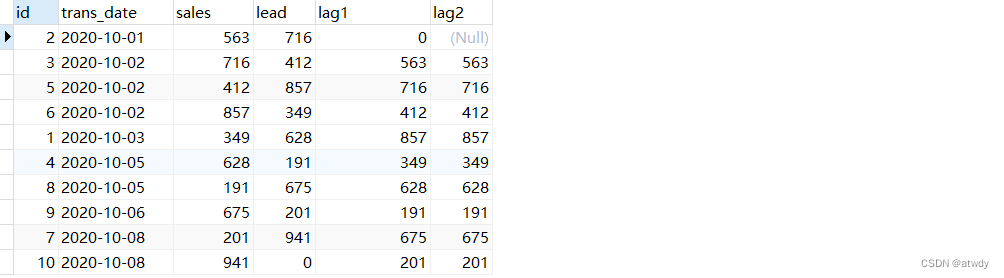
select *,lead(sales,1,0) over(order by trans_date) as `lead`, -- 将sales字段值整体上移1位,空值用0填充lag(sales,1,0) over(order by trans_date) as lag1, -- 将sales字段值整体下移1位,空值用0填充lag(sales) over(order by trans_date) as lag2 -- 将sales字段值整体下移1位,空值不处理
from test_rows_range;
output:
3.first_value & last_value & nth_value
下面几个函数的作用是取窗口中指定顺序的字段值。
- first_value(col):取窗口中字段col的第一个值。
- last_value(col):取窗口中字段col的最后一个值。
- nth_value(col, n):取窗口中第n顺序的值。
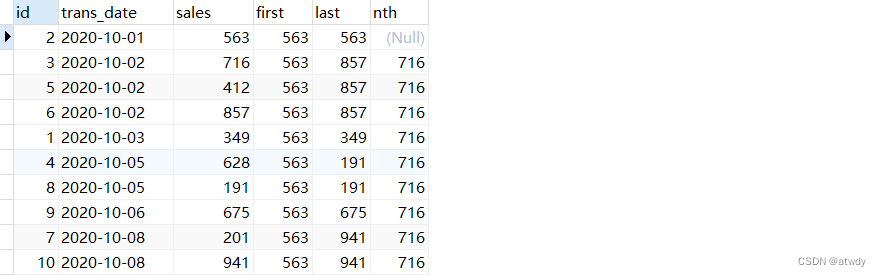
select *,first_value(sales) over(order by trans_date) as `first`, -- 取每个窗口第一个值last_value(sales) over(order by trans_date) as last, -- 取每个窗口最后一个值nth_value(sales,2) over(order by trans_date) as nth -- 取每个窗口第二个值
from test_rows_range;
output:
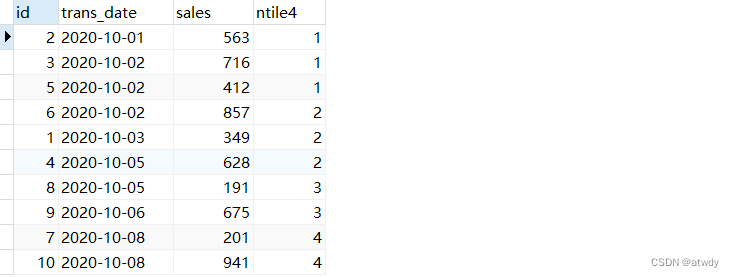
4.ntile
将数据分组。
- ntile(n):n是指定的组数。分组逻辑是从小到后为每条数据打上一个组号的标签,尽可能使每组内的数据相对均匀,当每组内的数据不能完全一样时,多余的数据优先给组号较小的分组。
select *,ntile(4) over(order by trans_date) as ntile4 -- 数据均匀分为4组
from test_rows_range;
output:
5.cume_dist & percent_rank(了解)
这两个函数基本不用,了解即可,下面是两个函数的官方描述。


从文档中可以看到这两个函数都应该与order by放在一起使用,返回的结果也都和order by字段的值有关。
cume_dist:返回的是窗口中所有小于等于当前行order by字段的值的总行数 / 窗口所在的分组内的总行数。percent_rank:返回的是窗口中所有小于当前行order by字段的值的总行数 / 窗口所在的分组内的总行数-1。
select *,cume_dist() over(order by trans_date) as `cume_dist`,percent_rank() over(order by trans_date) as `percent_rank`
from test_rows_range;
output:
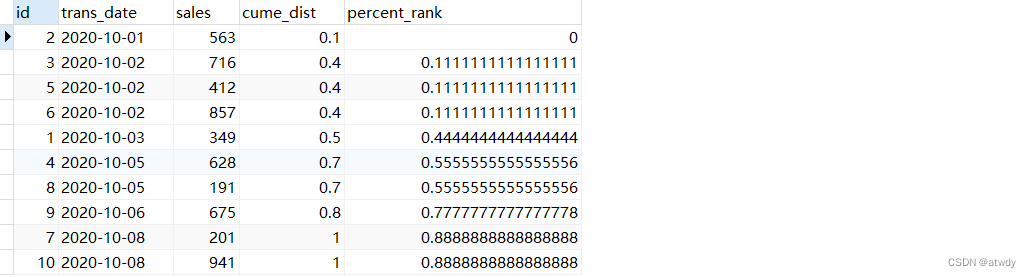
解释一下这个输出结果,默认窗口range unbounded preceding,对于cume_dist列,第一行trans_date为’2020-10-01’时,窗口内小于等于这一行的总行数为1,而这个窗口所在的分组也就是整个表总行数为10,因此第一行结果为0.1;而对于后面3个连续的0.4,是因为窗口类型为range,小于等于第二行值’2020-10-02’的总行数为4,所以结果为0.4。
对于percent_rank列,窗口所在的分组也就是整个表总行数为10,所以分母都为10-1=9。窗口内小于第一行’2020-10-01’的总行数为0,所以该列第一个值为0,后面以此类推…
PS
文档中没看到直接的描述,但在测试中发现了这两个函数有一些特点:
1)只适用于range类型窗口,这并不是说显式指定rows会报错,而是mysql忽略指定,输出的结果和range类型一致。
2)窗口范围自定义无效,也就是只能为默认窗口range unbounded preceding,像是修改为range between interval 1 day preceding and interval 1 day preceding无效。
select *,cume_dist() over(order by trans_date) as dist_range,cume_dist() over(order by trans_date rows unbounded preceding) as dist_rows,percent_rank() over(order by trans_date) as percent_range,percent_rank() over(order by trans_date rows unbounded preceding) as percent_rows,percent_rank() over(order by trans_date range between interval 1 day preceding and interval 1 day preceding) as percent_range1 -- 自定义窗口无效,不影响输出
from test_rows_range;
output:
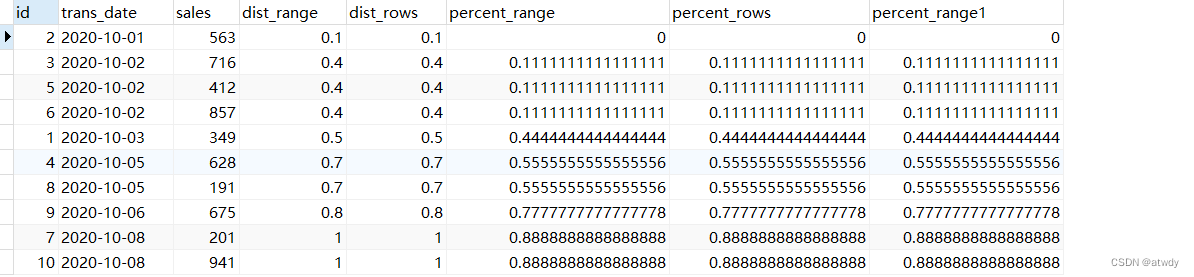
可以看到结果均无变化,我的理解是这两个函数都是用来计算某行记录在排序后的总体分布情况,因此rows类型的窗口因为忽略了重复值的影响所以不合适。而在此需求中更没必要让用户可以自定义指定窗口,因为这两个需求的总体思路都是按照当前行值在所有数据中的相对位置 / 所有记录数这样的思路来计算。
相关文章:
MySQL开窗函数
测试环境:mysql8.0.18 官方文档:https://dev.mysql.com/doc/refman/8.0/en/window-functions.html 一、窗口函数介绍二、语法结构三、自定义窗口1.rows(重点)2.range3.默认窗口 四、常用窗口函数示例1.row_number & rank &…...

Java学习笔记(23)
多线程 并发 并行 多线程实现方式 1.继承Thread类 自己创建一个类extends thread类 Start方法开启线程,自动执行重写之后的run方法 2.实现runable接口 自己创建一个类implements runnable Myrun不能直接使用getname方法,因为这个方法是thread类的方法…...
nodejs下载安装以及npm、yarn安装及配置教程
1、nodejs下载安装 1.1、使用nodejs版本管理工具下载安装,可一键安装、切换不同nodejs版本, nvm-setup.zip:安装版,推荐使用 本次演示的是安装版。 1、双击安装文件 nvm-setup.exe 选择nvm安装路径 例如:E:\Soft…...
方法执行JavaScript 表达式)
Playwright库page.evaluate()方法执行JavaScript 表达式
page.evaluate() 方法是 Playwright 中常用的方法之一,用于在页面上下文中执行 JavaScript 代码。它允许在浏览器环境中执行各种操作,如操作 DOM 元素、获取页面数据、执行复杂的计算等,并将结果返回到 Node.js 或 Python 代码中。 在 Playw…...
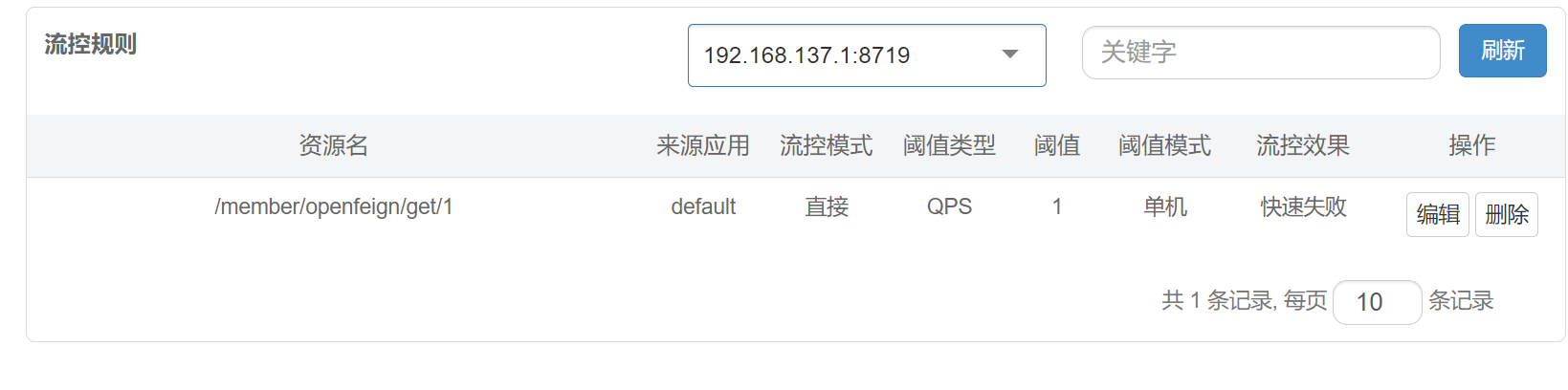
【微服务】OpenFeign+Sentinel集中处理远程调用异常
文章目录 1.微服务基本环境调整1.对10004模块的application.yml调整2.启动nacos以及一个消费者两个提供者3.测试1.输入http://localhost:8848/nacos/index.html 来查看注册情况2.浏览器访问 http://localhost:81/member/nacos/consumer/get/13.结果 2.使用OpenFeign实现微服务模…...

集合嵌套,Collections,斗地主案例,日志框架
文章目录 集合嵌套List嵌套ListList嵌套MapMap嵌套Map Collections类方法排序 sort 乱序 shuffle 斗地主案例需求思路代码 日志框架介绍优势体系结构Logback概述快速入门配置详解 集合嵌套 List嵌套List public static void main(String[] args){//一个年级有许多班级…...

maven pom relativePath属性的作用
maven pom relativePath属性的作用 文章目录 maven pom relativePath属性的作用一、relativePath出现的地方二、relativePath默认值三、四、<relativePath>一个pom路径 一、relativePath出现的地方 搭建maven项目,子模块指定父模块试,经常会在par…...

【STM32 HAL库SPI/QSPI协议学习,基于外部Flash读取。】
1、SPI协议 简介 SPI 协议是由摩托罗拉公司提出的通讯协议 (Serial Peripheral Interface),即串行外围设备接口,是 一种高速全双工的通信总线。它被广泛地使用在 ADC、LCD 等设备与 MCU 间,要求通讯速率 较高的场合。 SPI 物理层 SPI 通讯…...

Nginx入门--初识Nginx的架构
一、概述 Nginx的架构设计旨在高效处理并发的网络请求。它采用了事件驱动的、非阻塞的IO模型,可以同时处理成千上万个并发连接,而不会消耗太多的系统资源。 二、主要组件 Nginx的主要组件包括: Master Process(主进程…...

网络性能提升10%,ZStack Edge 云原生超融合基于第四代英特尔®至强®可扩展处理器解决方案发布
随着业务模式的逐渐转变、业务架构逐渐变得复杂,同时容器技术的兴起和逐渐成熟,使得Kubernetes、微服务等新潮技术逐步应用于业务应用系统上。 为了充分释放性能、为业务系统提供更高效的运行环境,ZStack Edge 云原生超融合采用了第四代英特尔…...

双非计算机考研目标211,选11408还是22408更稳?
求稳得话,11408比22408要稳! 很多同学只知道,11408和22408在考察的科目上有区别,比如: 11408考的是考研数学一和英语一,22408考察的是考研数学二和英语二: 考研数学一和考研数学二的区别大吗…...
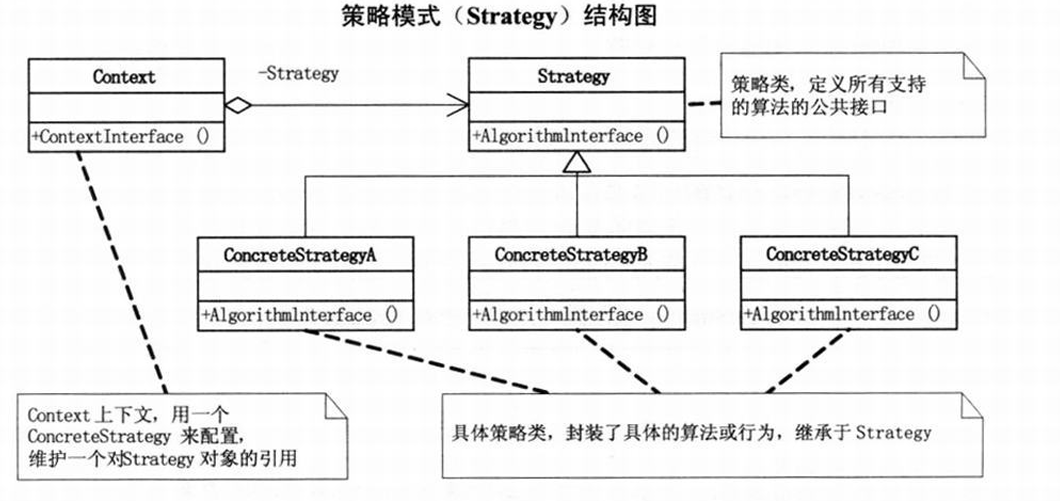
简单了解策略模式
什么是策略模式? 策略模式提供生成某一种产品的不同方式 Strategy策略类定义了某个各种算法的公共方法,不同的算法类通过继承Strategy策略类,实现自己的算法 Context的作用是减少客户端和Strategy策略类之间的耦合,客户端只需要…...

算法——运动模型
智能驾驶中常用的速度计算算法包括基于GPS的速度计算、惯性测量单元(IMU)的速度计算、雷达测距的速度计算、视觉测距的速度计算等。这些算法可以单独使用或者结合使用,以提高速度计算的准确性和稳定性。 智能驾驶中常用的加速度计算算法包括…...
基于R语言lavaan结构方程模型(SEM)技术应用
结构方程模型(Sructural Equation Modeling,SEM)是分析系统内变量间的相互关系的利器,可通过图形化方式清晰展示系统中多变量因果关系网,具有强大的数据分析功能和广泛的适用性,是近年来生态、进化、环境、…...

本地虚拟机服务器修改站点根目录并使用域名访问的简单示例
说明:本文提及效果是使用vmware虚拟机,镜像文件是Rocky8.6 一、配置文件路径 1. /etc/httpd/conf/httpd.conf #主配置文件 2. /etc/httpd/conf.d/*.conf #调用配置文件 调用配置文件的使用: vim /etc/httpd/conf.d/webpage.conf 因为在主配…...
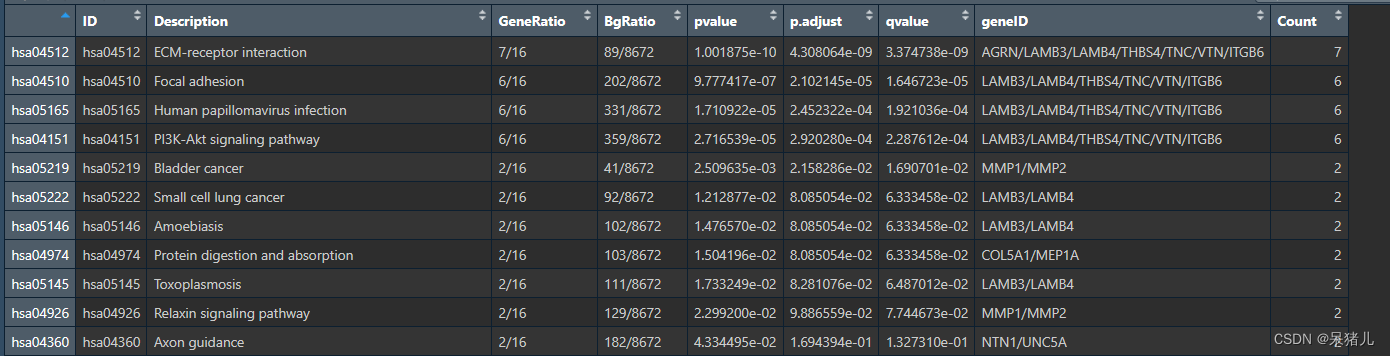
生信数据分析——GO+KEGG富集分析
生信数据分析——GOKEGG富集分析 目录 生信数据分析——GOKEGG富集分析1. 富集分析基础知识2. GO富集分析(Rstudio)3. KEGG富集分析(Rstudio) 1. 富集分析基础知识 1.1 为什么要做功能富集分析? 转录组学数据得到的基…...

微服务(基础篇-007-RabbitMQ)
目录 初识MQ(1) 同步通讯(1.1) 异步通讯(1.2) MQ常见框架(1.3) RabbitMQ快速入门(2) RabbitMQ概述和安装(2.1) 常见消息模型(2.2) 快速入门ÿ…...

汇总:五个开源的Three.js项目
Three.js 是一个基于 WebGL 的 JavaScript 库,它提供了一套易于使用的 API 用来在浏览器中创建和显示 3D 图形。通过抽象和简化 WebGL 的复杂性,Three.js 使开发者无需深入了解 WebGL 的详细技术就能够轻松构建和渲染3D场景、模型、动画、粒子系统等。 T…...

JavaScript(一)---【js的两种导入方式、全局作用域、函数作用域、块作用域】
一.JavaScript介绍 1.1什么是JavaScript JavaScript简称“js”,js与java没有任何关系。 js是一种“轻量级、解释型、面向对象的脚本语言”。 二.JavaScript的两种导入方式 2.1内联式 在HTML文档中使用<script>标签直接引用。 <script>console.log…...

部署云原生边缘计算平台kubeedge
文章目录 1、kubeedge架构2、基础服务提供 负载均衡器 metallb2.1、开启ipvc模式中的strictARP2.2、部署metalb2.2.1、创建IP地址池2.2.2、开启二层转发,实现在k8s集群节点外访问2.2.3、测试 3、部署cloudcore3.1、部署cloudcore3.2、修改cloudcore的网络类型 4、部…...

Open UI5 源代码解析之1378:DestinationField.js
源代码仓库: https://github.com/SAP/openui5 源代码位置:src\sap.ui.integration\src\sap\ui\integration\editor\fields\DestinationField.js DestinationField.js 文件分析 文件定位与整体判断 DestinationField.js 是 sap.ui.integration 编辑器体系中的一个专用字段…...

Modbus RTU 与 Modbus TCP 深入指南-附录:快速参考表
十五、附录:快速参考表 15.1 Modbus RTU 帧示例速查 操作请求帧(十六进制)响应帧示例读线圈(1个)01 01 00 00 00 01 CRC01 01 01 01 CRC读离散输入01 02 00 00 00 01 CRC01 02 01 00 CRC读保持寄存器(1个…...

基于MCP协议构建Jira Tempo工时管理AI助手:从原理到实践
1. 项目概述:一个专为Jira Tempo设计的MCP服务器 如果你和我一样,每天都要在Jira里手动填写Tempo工时,然后对着那些重复的、琐碎的操作感到厌倦,那么这个项目可能就是你的“救星”。 ivelin-web/tempo-mcp-server 是一个基于Mo…...

BookGet:一键下载全球50+图书馆古籍资源的智能工具指南
BookGet:一键下载全球50图书馆古籍资源的智能工具指南 【免费下载链接】bookget bookget 数字古籍图书下载工具。 项目地址: https://gitcode.com/gh_mirrors/bo/bookget 你是否曾为查找古籍资料而奔波于各大数字图书馆?是否因为复杂的下载流程而…...

深度解析VMDE:Windows系统虚拟机检测的终极武器
深度解析VMDE:Windows系统虚拟机检测的终极武器 【免费下载链接】VMDE Source from VMDE paper, adapted to 2015 项目地址: https://gitcode.com/gh_mirrors/vm/VMDE 在网络安全研究的世界里,有一个永恒的问题困扰着分析师们:"我…...

LoRa模块信号弱?可能是你的“射频快递”堵车了:深入Sx1262前端电路的信号处理流水线
LoRa模块信号弱?可能是你的“射频快递”堵车了:深入Sx1262前端电路的信号处理流水线 想象一下,你精心打包的快递包裹在运输途中被随意堆放、地址模糊不清,最终导致收件人无法正常签收——这正是许多LoRa模块信号问题的真实写照。当…...

Windows系统清理神器:DriverStore Explorer深度使用教程
Windows系统清理神器:DriverStore Explorer深度使用教程 【免费下载链接】DriverStoreExplorer Driver Store Explorer 项目地址: https://gitcode.com/gh_mirrors/dr/DriverStoreExplorer 你是否曾经遇到过Windows系统盘空间莫名减少的情况?是否…...

开发预告:关于改造Hermes-agent这件事,我想说的比上一篇多得多
先声明一点:这不是什么技术布道,更不是产品软文。这篇文章里写的东西,要么是我花了真金白银和睡眠时间换来的,要么是我接下来要去踩的坑。你要觉得哪里不对,直接怼。你要觉得哪里说到你心坎里了,欢迎一起搞…...

解决 Claude Code 频繁封号问题之转向 Taotoken 稳定服务
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 解决 Claude Code 频繁封号问题之转向 Taotoken 稳定服务 对于依赖 Claude Code 进行开发的工程师而言,账号访问权限的…...

FILCO架构:动态可重构DNN加速器设计解析
1. FILCO架构设计背景与核心挑战深度神经网络(DNN)加速器设计正面临一个根本性矛盾:专用架构在特定负载下能达到峰值效率,但实际应用中工作负载的多样性日益增长。以自动驾驶系统为例,单个任务流程可能同时包含MLP分类器、Transformer视觉模型…...