基于Scala开发Spark ML的ALS推荐模型实战
推荐系统,广泛应用到电商,营销行业。本文通过Scala,开发Spark ML的ALS算法训练推荐模型,用于电影评分预测推荐。
算法简介
ALS算法是Spark ML中实现协同过滤的矩阵分解方法。
ALS,即交替最小二乘法(Alternating Least Squares),是协同过滤技术中的一种经典算法。它通过对用户和物品的潜在特征进行建模,来预测用户对未知物品的评分或偏好。具体介绍如下:
- 矩阵分解模型:在推荐系统中,我们通常有一个用户-物品的评分矩阵,其中行表示用户,列表示物品,矩阵中的值代表用户对物品的评分。然而,这个矩阵通常是非常稀疏的,因为用户只给少数物品评分。ALS算法就是在这样的不完整评分矩阵上操作,通过矩阵分解来补全缺失值,进而产生推荐。
- 算法原理:ALS算法的核心思想是通过迭代过程更新用户和物品的潜在因子向量。在每次迭代中,一个评分被建模为用户潜在特征向量和物品潜在特征向量的点积,加上一个偏差项。通过最小化实际评分和预测评分之间的差异来不断优化这些潜在特征向量。
- Spark ML实现:在Spark ML库中,ALS算法被用于处理大规模的数据集,并提供了多种参数以适应不同的数据特性和需求。例如,可以设置潜在因子的数量、正则化参数、迭代次数等。此外,Spark ML的ALS还支持隐式反馈数据的变体,这对于无法获取明确评分的数据非常有用。
总的来说,ALS是一种强大的推荐系统算法,尤其适用于处理大规模稀疏数据集。通过合理地选择和调整参数,可以在保持高效计算的同时获得良好的推荐质量。
代码实战
pom.xml文件更新,加入相关依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>org.example</groupId><artifactId>sparkGNU2023</artifactId><version>1.0-SNAPSHOT</version><properties><maven.compiler.source>8</maven.compiler.source><maven.compiler.target>8</maven.compiler.target><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><scala.version>2.13</scala.version><spark.version>3.4.1</spark.version><log4j.version>1.2.17</log4j.version><slf4j.version>1.7.22</slf4j.version></properties><dependencies><!--日志相关依赖--><dependency><groupId>org.slf4j</groupId><artifactId>jcl-over-slf4j</artifactId><version>${slf4j.version}</version></dependency><dependency><groupId>org.slf4j</groupId><artifactId>slf4j-api</artifactId><version>${slf4j.version}</version></dependency><dependency><groupId>org.slf4j</groupId><artifactId>slf4j-log4j12</artifactId><version>${slf4j.version}</version></dependency><dependency><groupId>log4j</groupId><artifactId>log4j</artifactId><version>${log4j.version}</version></dependency><dependency><groupId>com.thoughtworks.paranamer</groupId><artifactId>paranamer</artifactId><version>2.8</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-core_2.13</artifactId><version>3.4.1</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-sql_2.13</artifactId><version>${spark.version}</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-streaming_2.13</artifactId><version>${spark.version}</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-hive_2.13</artifactId><version>${spark.version}</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-streaming-kafka-0-10_2.13</artifactId><version>3.4.1</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-mllib_2.13</artifactId><version>${spark.version}</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-streaming-kafka-0-8_2.11</artifactId><version>2.4.8</version></dependency><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>8.0.30</version></dependency><dependency><groupId>org.apache.flume.flume-ng-clients</groupId><artifactId>flume-ng-log4jappender</artifactId><version>1.11.0</version></dependency><!-- flume 拦截器相关依赖--><dependency><groupId>org.apache.flume</groupId><artifactId>flume-ng-core</artifactId><version>1.9.0</version><scope>provided</scope></dependency><dependency><groupId>com.alibaba</groupId><artifactId>fastjson</artifactId><version>1.2.62</version></dependency></dependencies><build><plugins><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-compiler-plugin</artifactId><version>3.8.1</version><configuration><source>1.8</source><target>1.8</target></configuration></plugin><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-assembly-plugin</artifactId><version>3.6.0</version><configuration><descriptorRefs><descriptorRef>jar-with-dependencies</descriptorRef></descriptorRefs></configuration><executions><execution><id>make-assembly</id><phase>package</phase><goals><goal>single</goal></goals></execution></executions></plugin></plugins></build></project>训练ALS模型
基于scala训练ALS模型
package base.charpter10import breeze.linalg.sum
import org.apache.spark.ml.evaluation.RegressionEvaluator
import org.apache.spark.ml.recommendation.ALS
import org.apache.spark.sql.functions.{col, count, explode, when}
import org.apache.spark.sql.{DataFrame, SparkSession}/*** @projectName sparkGNU2023 * @package base.charpter10 * @className base.charpter10.MovieRecommender * @description ${description} * @author pblh123* @date 2024/3/29 15:18* @version 1.0**/object MovieRecommender {def main(args: Array[String]): Unit = {// 创建Spark会话val spark = SparkSession.builder().appName("MovieRecommender").master("local[*]").getOrCreate()import spark.implicits._// 假设我们有一个用户-物品评分数据集,格式为(userId, itemId, rating)/*** UserID,MovieID,Rating,Timestamp* 1,1193,5,978300760* 1,661,3,978302109*/// 指定CSV文件的路径,以及解析选项val csvFilePath = "data/ratings.csv"val csvOptions = Map("header" -> "true", // 是否有列名头"inferSchema" -> "true", // 是否自动推断数据类型"encoding" -> "UTF-8", // 如果有特定的编码格式,例如对于包含中文的CSV文件:)// 读取CSV文件并创建DataFrameval ratingsDF = spark.read.format("csv").options(csvOptions).load(csvFilePath)// 显示DataFrame的前几行以验证数据是否正确加载println("查看原始据数据样例:")ratingsDF.show(5)val ratings: DataFrame = ratingsDF.select("UserID", "MovieID", "Rating").withColumnRenamed("UserID", "userId").withColumnRenamed("MovieID", "itemId").withColumnRenamed("Rating", "rating")// 将数据集分割为训练集和测试集val Array(training, test) = ratings.randomSplit(Array(0.8, 0.2))println("查看训练集数据")training.show(5)println("查看测试集数据")test.show(5)// 设置ALS参数// 创建一个ALS实例并配置参数val als = new ALS().setMaxIter(10) // 设置最大迭代次数为5,10,本地测试时,设置过大,会报错.setRegParam(0.01) // 设置正则化参数为0.01.setUserCol("userId") // 设置用户列名为"userId".setItemCol("itemId") // 设置物品列名为"itemId".setRatingCol("rating") // 设置评分列名为"rating"/*** ALS(Alternating Least Squares)是一种基于矩阵分解的协同过滤算法,用于处理用户和物品之间的评分数据。各参数说明如下:* setMaxIter: 设置最大迭代次数,决定模型训练的精细程度。迭代次数越多,模型通常越精确,但训练时间也可能更长。* setRegParam: 设置正则化参数,用于控制模型的复杂度和过拟合程度。较小的正则化参数值可能导致模型过复杂,容易过拟合;较大的值则可能导致模型过于简单,欠拟合。* setUserCol, setItemCol, setRatingCol: 分别设置用户ID列、物品ID列和评分列的名称。这些列名根据实际的数据结构来确定,用于告诉ALS算法在哪些列中查找用户、物品和评分信息。*/// 训练ALS模型println("开始训练模型")val model = als.fit(training)// 对测试集进行预测val predictions = model.transform(test)predictions.show()predictions.filter($"rating".isNotNull && $"prediction".isNotNull).count() // 确认有非空的评分和预测值// 评估模型val evaluator = new RegressionEvaluator().setMetricName("rmse").setLabelCol("rating").setPredictionCol("prediction")val rmse = evaluator.evaluate(predictions)println(s"Root-mean-square error = $rmse")// 为用户生成推荐// 该函数是基于一个模型(model)为所有用户推荐项目的函数。它将为每个用户推荐5个项目/*** +------+--------------------------------------------------------------------------------------------+* |userId|recommendations[{itemid,pred_rating},{itemid,pred_rating},...] |* +------+--------------------------------------------------------------------------------------------+* |12 |[{1864, 9.721167}, {2964, 8.815781}, {3867, 8.480173}, {1539, 7.8904114}, {563, 7.8829007}] |* |22 |[{2964, 6.090676}, {3215, 5.6165895}, {1534, 5.4731245}, {718, 5.462125}, {2632, 5.4482727}]|*/val userRecs = model.recommendForAllUsers(5)userRecs.show(5,false)println("保存预测结果")
// userRecs.write.mode("overwrite").parquet("models/recomALSmodel") // 保存为parquet格式,一般用于集群中
// userRecs是一个DataFrame,其中"recommendations"列是数组类型val explodedUserRecs = userRecs.withColumn("recommendations", explode($"recommendations")).select($"userId", $"recommendations.itemId".as("itemId"), $"recommendations.rating".as("PredRating"))explodedUserRecs.write.mode("overwrite").format("csv").save("predictRes/recomALS") // PC 调试使用// 保存模型到指定路径val modelPath = "models/recomALSmodel"model.write.overwrite().save(modelPath)println(s"Model saved to $modelPath")// 停止Spark会话spark.stop()/*当程序试图停止Spark会话时,可能会触发清理临时文件的操作,从而导致出现NoSuchFileException异常。通常情况下,这不是代码逻辑的问题,而是Spark内部在清理资源时可能出现的问题。可以尝试重启Spark环境或者适当增大Spark的临时目录空间来避免此类问题。*/}}
运行代码,效果图如下
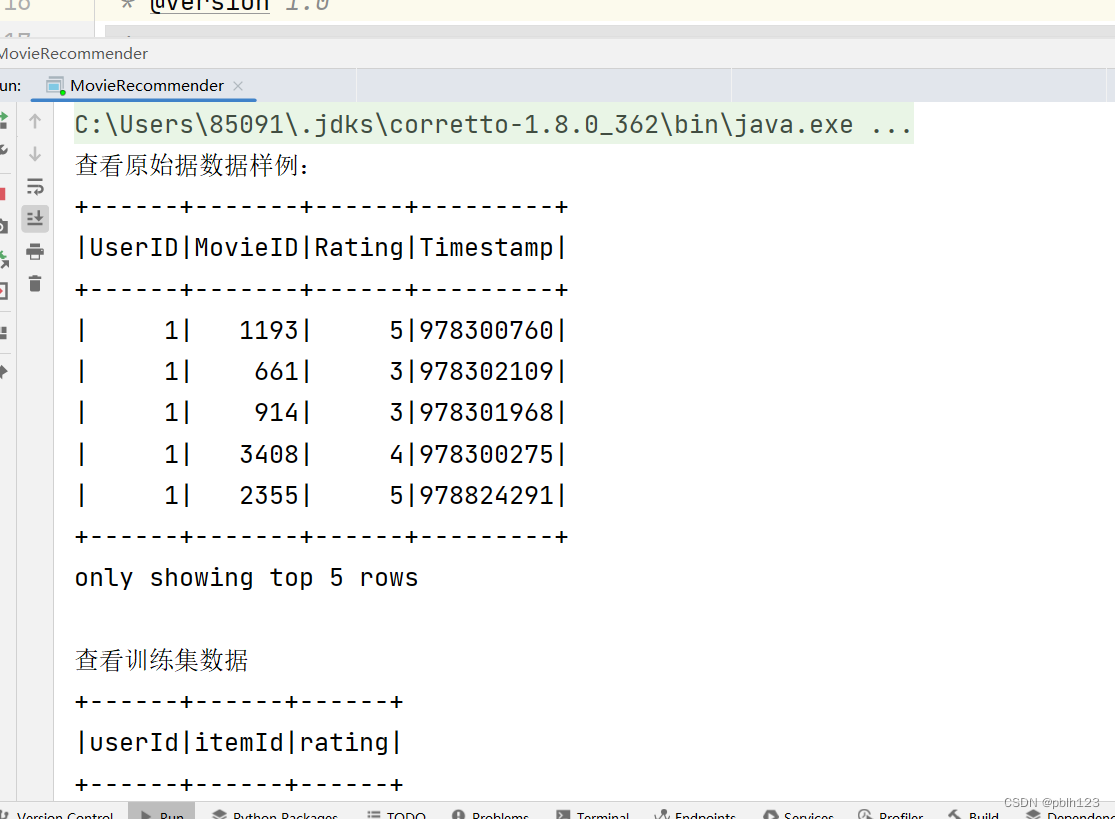

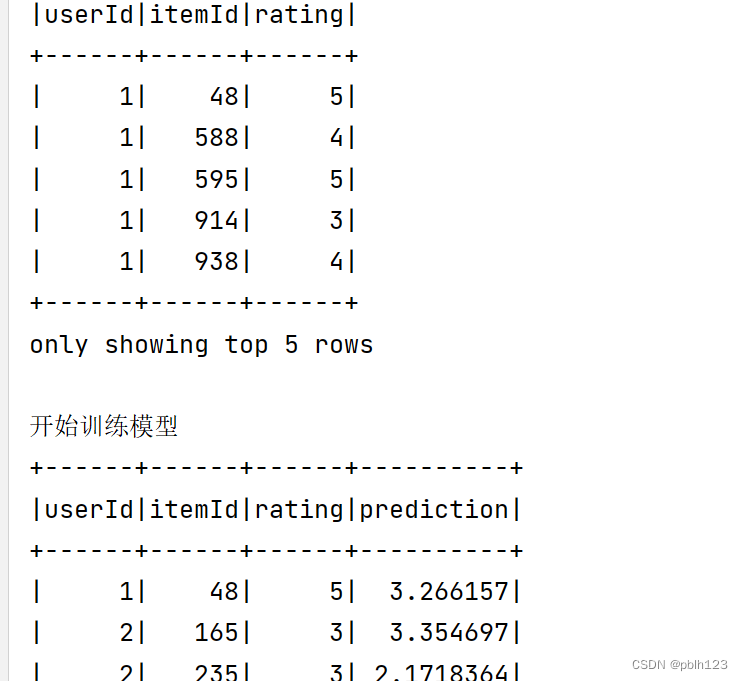
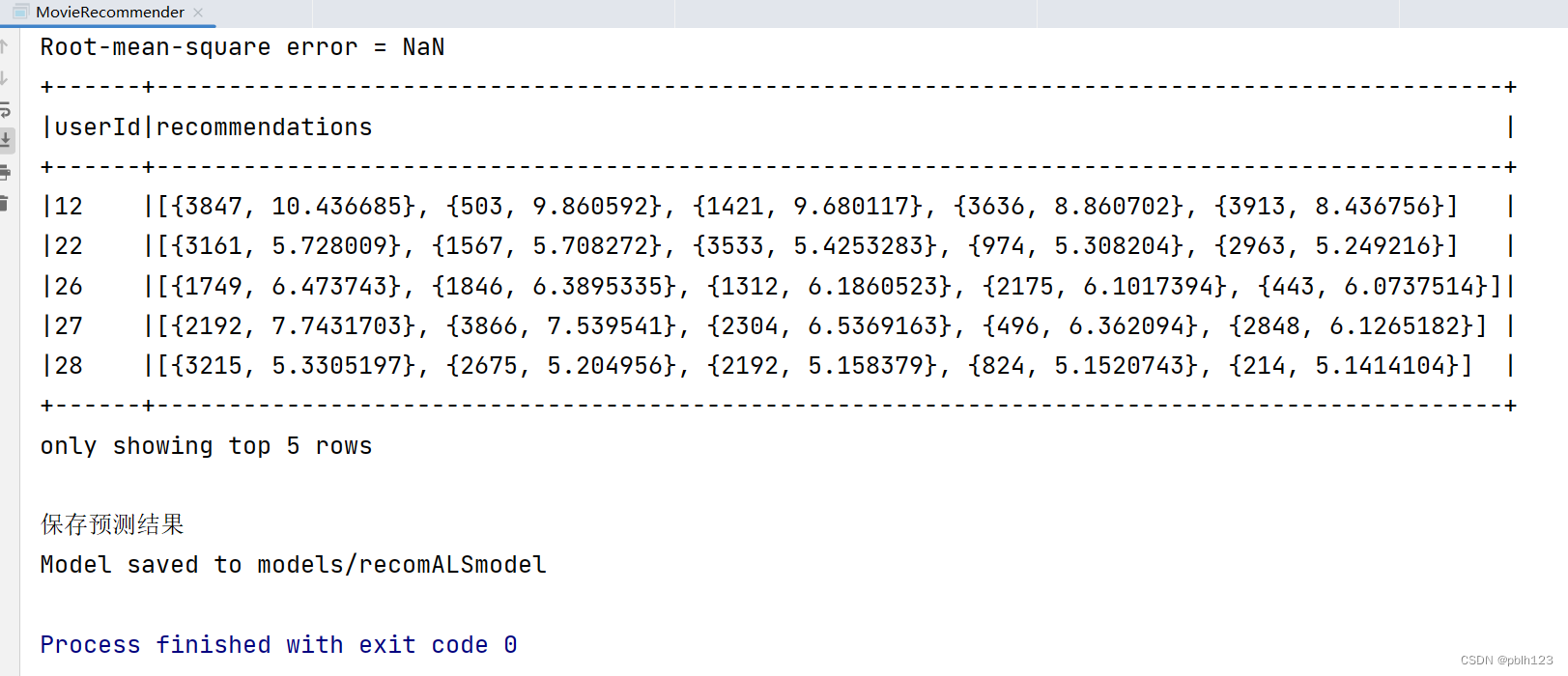
TodoList:目前RMSE计算出问题,原数据清洗没有做,模型参数还可以调整。后期调整更新后,再发一篇文章。
使用训练的模型预测新数据
scala开发应用模型demo代码
package base.charpter10import org.apache.spark.ml.recommendation.ALSModel
import org.apache.spark.sql.SparkSession/*** @projectName sparkGNU2023 * @package base.charpter10 * @className base.charpter10.RecommendationModelLoadDemo * @description ${description} * @author pblh123* @date 2024/3/29 15:36* @version 1.0**/object RecommendationModelLoadDemo {def main(args: Array[String]): Unit = {// 创建Spark会话val spark = SparkSession.builder().master("local[*]").appName("RecommendationModelUsageDemo").getOrCreate()import spark.implicits._// 加载之前保存的ALS模型val modelPath = "models/recomALSmodel"val loadedModel: ALSModel = ALSModel.load(modelPath)// 假设我们有一些新的用户-物品对,我们想要预测它们的评分val userItemPairs = Seq((1, 4), // 用户1对物品4的评分预测(2, 2) // 用户2对物品2的评分预测).toDF("userId", "itemId")// 使用模型进行评分预测val predictions = loadedModel.transform(userItemPairs)predictions.show()// 现在,假设我们想要为用户1生成前N个推荐物品val numRecommendations = 5 // 为用户推荐的物品数量val userRecs = loadedModel.recommendForAllUsers(numRecommendations)userRecs.show(5,false)// 停止Spark会话spark.stop()}}
运行效果如下
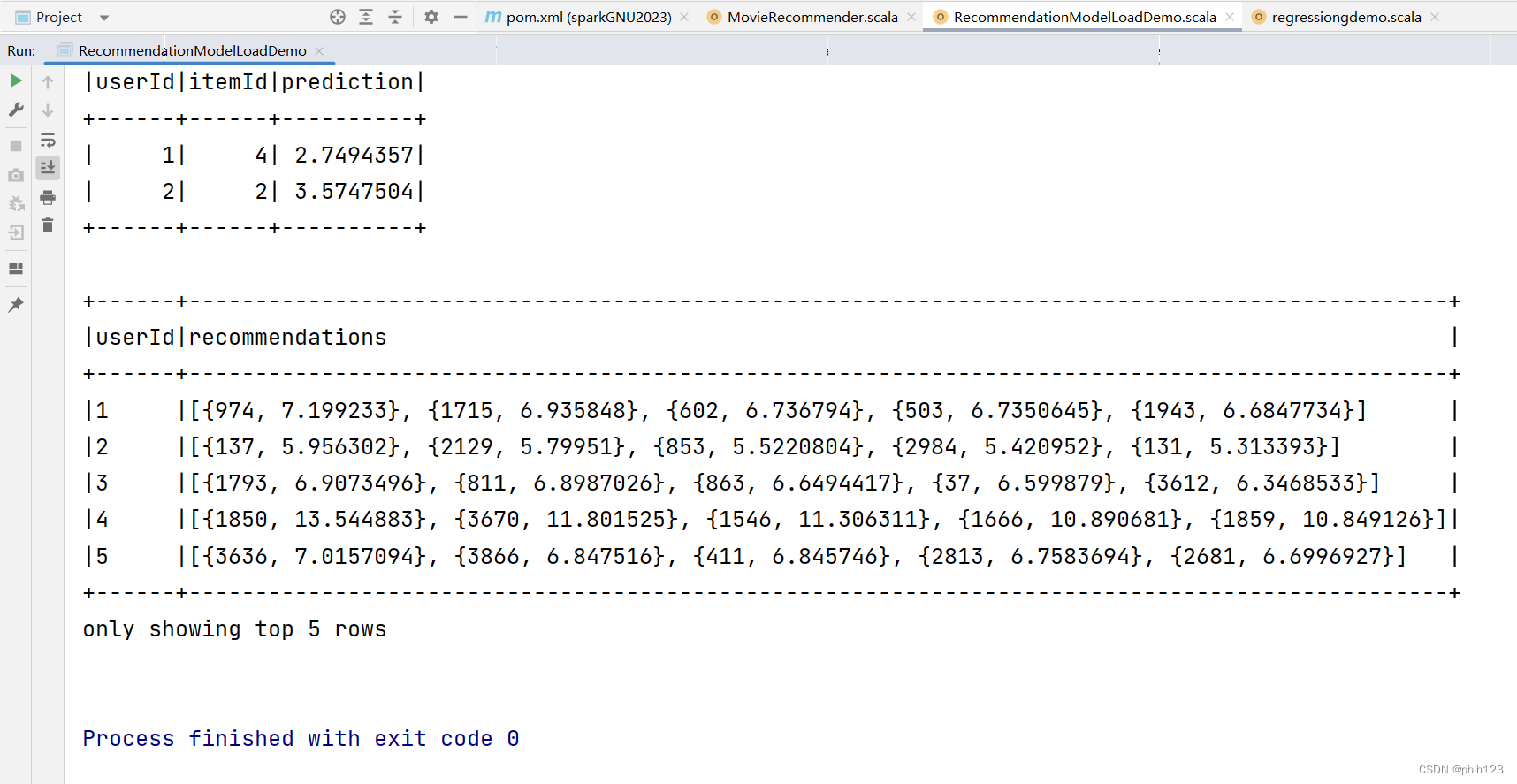
评估效果说明:目前的预测评分不合理,是因为模型没有经过精挑,优化,预测的记过会依据预测评分高低排序,选取得分高的前5个结果返回。后期模型调优后,结果就正常了。
相关文章:
基于Scala开发Spark ML的ALS推荐模型实战
推荐系统,广泛应用到电商,营销行业。本文通过Scala,开发Spark ML的ALS算法训练推荐模型,用于电影评分预测推荐。 算法简介 ALS算法是Spark ML中实现协同过滤的矩阵分解方法。 ALS,即交替最小二乘法(Alte…...

Go语言和Java编程语言的主要区别
目录 1.设计理念: 2.语法: 3.性能: 4.并发性: 5.内存管理: 6.标准库: 7.社区和支持: 8.应用领域: Go(也称为Golang)和Java是两种不同的编程语言&…...

【TypeScript系列】与其它构建工具整合
与其它构建工具整合 构建工具 BabelBrowserifyDuoGruntGulpJspmWebpackMSBuildNuGet Babel 安装 npm install babel/cli babel/core babel/preset-typescript --save-dev.babelrc {"presets": ["babel/preset-typescript"] }使用命令行工具 ./node_…...

Java | Leetcode Java题解之第12题整数转罗马数字
题解: 题解: class Solution {String[] thousands {"", "M", "MM", "MMM"};String[] hundreds {"", "C", "CC", "CCC", "CD", "D", "DC…...
哈佛大学商业评论 --- 第五篇:智能眼镜之战
AR将全面融入公司发展战略! AR将成为人类和机器之间的新接口! AR将成为人类的关键技术之一! 请将此文转发给您的老板! --- 专题作者:Michael E.Porter和James E.Heppelmann 虽然物理世界是三维的,但大多…...
paddlepaddle模型转换onnx指导文档
一、检查本机cuda版本 1、右键找到invdia控制面板 2、找到系统信息 3、点开“组件”选项卡, 可以看到cuda版本,我们这里是cuda11.7 cuda驱动版本为516.94 二、安装paddlepaddle环境 1、获取pip安装命令 ,我们到paddlepaddle官网ÿ…...

图像处理与视觉感知---期末复习重点(6)
文章目录 一、图像分割二、间断检测2.1 概述2.2 点检测2.3 线检测2.4 边缘检测 三、边缘连接3.1 概述3.2 Hough变换3.3 例子3.4 Hough变换的具体步骤3.5 Hough变换的法线表示形式3.6 Hough变换的扩展 四、阈值处理4.1 概述4.2 计算基本全局阈值算法4.3 自适应阈值 五、基于区域…...

git 如何删除本地和远程分支
删除本地分支 确认当前分支:首先,确保你没有在要删除的分支上。你可以通过运行git branch命令来查看当前的分支。 切换分支:如果你在要删除的分支上,需要先切换到另一个分支。例如,切换到main分支,可以使用…...

Kong基于QPS、IP限流
Rate Limiting限流插件 https://docs.konghq.com/hub/kong-inc/rate-limiting/ 它可以针对consumer ,credential ,ip ,service,path,header 等多种维度来进行限流.流量控制的精准度也有多种方式可以参考,比如可以做到秒级,分钟级,小时级等限流控制. 基于IP限流 源码地址&…...
基于springboot实现甘肃非物质文化网站系统项目【项目源码+论文说明】
摘要 现代经济快节奏发展以及不断完善升级的信息化技术,让传统数据信息的管理升级为软件存储,归纳,集中处理数据信息的管理方式。本甘肃非物质文化网站就是在这样的大环境下诞生,其可以帮助管理者在短时间内处理完毕庞大的数据信…...
【瑞萨RA6M3】1. 基于 vscode 搭建开发环境
基于 vscode 搭建开发环境 1. 准备2. 安装2.1. 安装瑞萨软件包2.2. 安装编译器2.3. 安装 cmake2.4. 安装 openocd2.5. 安装 ninja2.6. 安装 make 3. 生成初始代码4. 修改 cmake 脚本5. 调试准备6. 仿真 1. 准备 需要瑞萨仓库中的两个软件: MDK_Device_Packs.zipse…...

使用pip install替代conda install将packet下载到anaconda虚拟环境
问题描述 使用conda install 下载 stable_baseline3出现问题 一番搜索下是Anaconda.org缺少源 解决方法 首先使用管理员权限打开 anaconda prompt 然后激活目标环境:conda activate env_name 接着使用:conda env list查看目标env的位置 如D:\anacon…...

【HTML】常用CSS属性
文章目录 前言1、字体和文本属性2、边距和填充3、border边框4、列表属性 前言 上一篇我们学习了CSS扩展选择器以及它的继承性,对于页面元素样式设置相信大家都不陌生了。 这一篇我们就来看看具体都有哪些样式可以设置?又该如何设置? 喜欢的【…...
具体用法)
python中的print(f‘‘)具体用法
在Python中,print(f) 是格式化字符串(f-string)的语法,它允许你在字符串中嵌入表达式,这些表达式在运行时会被其值所替换。f 或 F 前缀表示这是一个格式化字符串字面量。 在 f 或 F 中的大括号 {} 内,你可…...

《青少年成长管理2024》022 “成长七要素之三:文化”4/5
《青少年成长管理2024》022 “成长七要素之三:文化”4/5 七、物质文化(一)什么是物质文化(二)物质文化的分类(三)人类物质文化最新成果有哪些(四)青少年了解物质文化的途…...
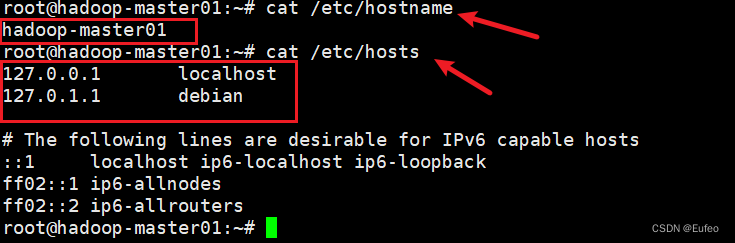
Linux(05) Debian 系统修改主机名
查看主机名 方法1:hostname hostname 方法2:cat etc/hostname cat /etc/hostname 如果在创建Linux系统的时候忘记修改主机名,可以采用以下的方式来修改主机名称。 修改主机名 注意,在linux中下划线“_”可能是无效的字符&…...

之前翻硬币问题胡思乱想的完善
题目背景 小明正在玩一个“翻硬币”的游戏。 题目描述 桌上放着排成一排的若干硬币。我们用 * 表示正面,用 o 表示反面(是小写字母,不是零),比如可能情形是 **oo***oooo,如果同时翻转左边的两个硬币&#x…...

前端与后端协同:实现Excel导入导出功能
🌟 前言 欢迎来到我的技术小宇宙!🌌 这里不仅是我记录技术点滴的后花园,也是我分享学习心得和项目经验的乐园。📚 无论你是技术小白还是资深大牛,这里总有一些内容能触动你的好奇心。🔍 &#x…...
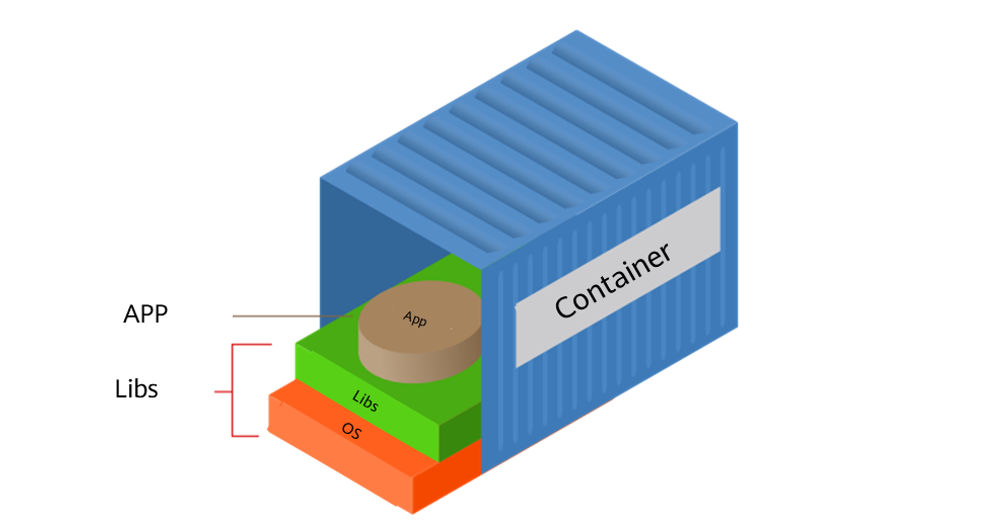
Docker:探索容器化技术,重塑云计算时代应用交付与管理
一,引言 在云计算时代,随着开发者逐步将应用迁移至云端以减轻硬件管理负担,软件配置与环境一致性问题日益凸显。Docker的横空出世,恰好为软件开发者带来了全新的解决方案,它革新了软件的打包、分发和管理方式ÿ…...
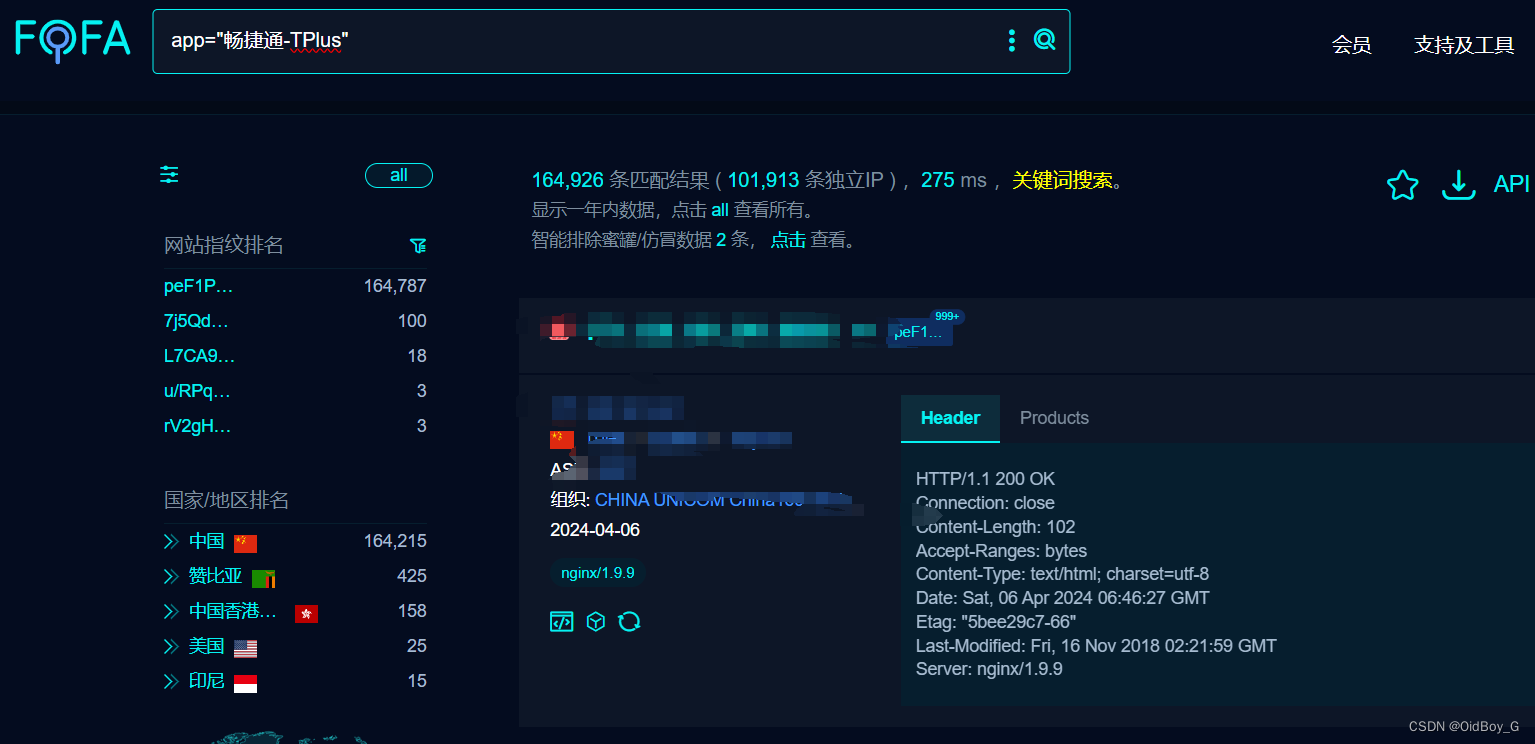
畅捷通T+ KeyInfoList.aspx SQL漏洞复现
0x01 产品简介 畅捷通 T+ 是一款灵动,智慧,时尚的基于互联网时代开发的管理软件,主要针对中小型工贸与商贸企业,尤其适合有异地多组织机构(多工厂,多仓库,多办事处,多经销商)的企业,涵盖了财务,业务,生产等领域的应用,产品应用功能包括:采购管理、库存管理、销售…...

构建可靠AI编码代理:OpenClaw-Build工作流详解与实战
1. 项目概述:一个能“闭环”的AI编码代理工作流如果你用过市面上那些号称能自动编程的AI代理,大概率经历过这样的挫败感:你满怀期待地丢给它一个需求,它吭哧吭哧干了两三个任务,然后要么开始“神游”,写出来…...
)
别再手动写Prompt了!Lovable原生AI编排引擎深度解析(附12个已验证行业工作流)
更多请点击: https://intelliparadigm.com 第一章:Lovable无代码AI应用构建指南 Lovable 是一款面向业务人员与开发者的低门槛 AI 应用构建平台,它通过可视化编排、预置模型组件和自然语言驱动逻辑,实现无需编写代码即可部署可运…...

基于Azure AI Search与OpenAI构建企业级智能问答系统实战指南
1. 项目概述:当企业级搜索遇上生成式AI 如果你正在为如何让公司内部的知识库、产品文档或客服系统变得更“聪明”而头疼,那么你很可能已经听说过或将接触到这个项目: Azure-Samples/azure-search-openai-demo 。这不仅仅是一个简单的代码示…...

终极指南:如何快速筛选高质量免费股票资源的5大核心标准
终极指南:如何快速筛选高质量免费股票资源的5大核心标准 【免费下载链接】awesome-stock-resources :city_sunrise: A collection of links for free stock photography, video and Illustration websites 项目地址: https://gitcode.com/gh_mirrors/aw/awesome-s…...
)
Python还是Java?小白程序员必备!收藏这份6个月大模型应用开发学习路线图(附实战项目)
本文针对大模型应用开发,为初学者提供Python/Java语言选择建议,并推出分阶段学习路线图。通过6-8个月学习,涵盖大模型基础、RAG、Agent开发、微调与部署等核心技能。强调实战项目驱动,推荐资源库,最后总结学习建议。适…...

【必收藏】2026年大模型学习全指南|小白程序员入门捷径,抓住百万年薪红利
2026年的AI行业,机遇早已从风口走向实锤——应用层依旧是那片肉眼可见的黄金赛道!从大厂技术布局到招聘市场风向标,所有信号都在一致指向:大模型应用开发,已然成为程序员突破职业瓶颈、实现薪资跃升的核心赛道。 字节跳…...

告别AT指令!用nRF52832的BLE NUS服务,5分钟搞定手机与开发板的双向通信
用nRF52832的BLE NUS服务实现高效蓝牙串口通信 在嵌入式开发中,设备与移动端的双向通信一直是个痛点。传统AT指令虽然简单,但效率低下、扩展性差,每次通信都需要复杂的握手流程。而基于nRF52832的BLE NUS(Nordic UART Service&…...

告别数据焦虑:WeChatExporter如何重塑你的数字记忆管理体验
告别数据焦虑:WeChatExporter如何重塑你的数字记忆管理体验 【免费下载链接】WeChatExporter 一个可以快速导出、查看你的微信聊天记录的工具 项目地址: https://gitcode.com/gh_mirrors/wec/WeChatExporter 当你深夜翻看三年前的聊天记录,却发现…...

死锁四大必要条件解析
好的,针对“死锁考点与高频面试题”,我将直接进行核心内容解构与推演,并生成符合规范的答案。死锁是多线程并发编程中的核心难点与高频考点,其核心围绕定义、条件、场景、检测、预防与避免展开。一、 死锁核心定义与必要条件死锁是…...

OnmyojiAutoScript:阴阳师自动化脚本终极指南,20+日常任务一键托管解放双手
OnmyojiAutoScript:阴阳师自动化脚本终极指南,20日常任务一键托管解放双手 【免费下载链接】OnmyojiAutoScript Onmyoji Auto Script | 阴阳师脚本 项目地址: https://gitcode.com/gh_mirrors/on/OnmyojiAutoScript 还在为阴阳师中重复繁琐的日常…...