K8s技术全景:架构、应用与优化

一、介绍

Kubernetes的历史和演进
Kubernetes(简称K8s)是一个开源的容器编排系统,用于自动化应用程序的部署、扩展和管理。它最初是由Google内部的Borg系统启发并设计的,于2014年作为开源项目首次亮相。
初始阶段
Kubernetes的诞生源于Google内部对大规模容器管理的需求。早在2014年之前,Google已经在其内部系统Borg上积累了大量关于容器编排和管理的经验。这些经验和技术最终孕育出Kubernetes。
发展阶段
随着云计算和微服务架构的兴起,Kubernetes迅速成为行业标准。它的设计哲学、可扩展性和社区支持是其成功的关键因素。2015年,Cloud Native Computing Foundation(CNCF)成立,并接管了Kubernetes的发展。在CNCF的支持下,Kubernetes经历了快速发展,吸引了一大批贡献者和用户。
演进阶段
Kubernetes不断演进,增加了对多种云平台的支持,改进了网络和存储功能,增强了安全性。其社区也不断扩大,衍生出众多相关项目和工具,形成了一个庞大的生态系统。
K8s的核心概念和设计理念
核心概念
-
Pods:Pod是Kubernetes的基本运行单位,代表了在集群中运行的一个或多个容器的组合。
-
Services:Service是对一组提供相同功能的Pods的抽象,它提供了一个稳定的网络接口。
-
Deployments:Deployment提供了对Pods和ReplicaSets(副本集)的声明式更新能力。
设计理念
-
声明式配置:Kubernetes使用声明式配置(而非命令式),用户定义期望状态,系统负责实现这一状态。
-
自我修复:系统能够自动替换、重启、复制和扩展集群中的节点。
-
可扩展性:Kubernetes设计了一套强大的APIs,允许在其上构建更复杂的系统。
-
负载均衡和服务发现:Kubernetes能够自动分配IP地址和DNS名,以及平衡网络流量,以实现高效的服务发现和负载均衡。
-
多维度资源调度:它支持基于CPU、内存等多种资源类型的调度决策。
Kubernetes的这些概念和设计理念共同构成了其强大的容器编排和管理能力,使其成为当今云原生应用和微服务架构的首选平台。
二、K8s架构深入解析
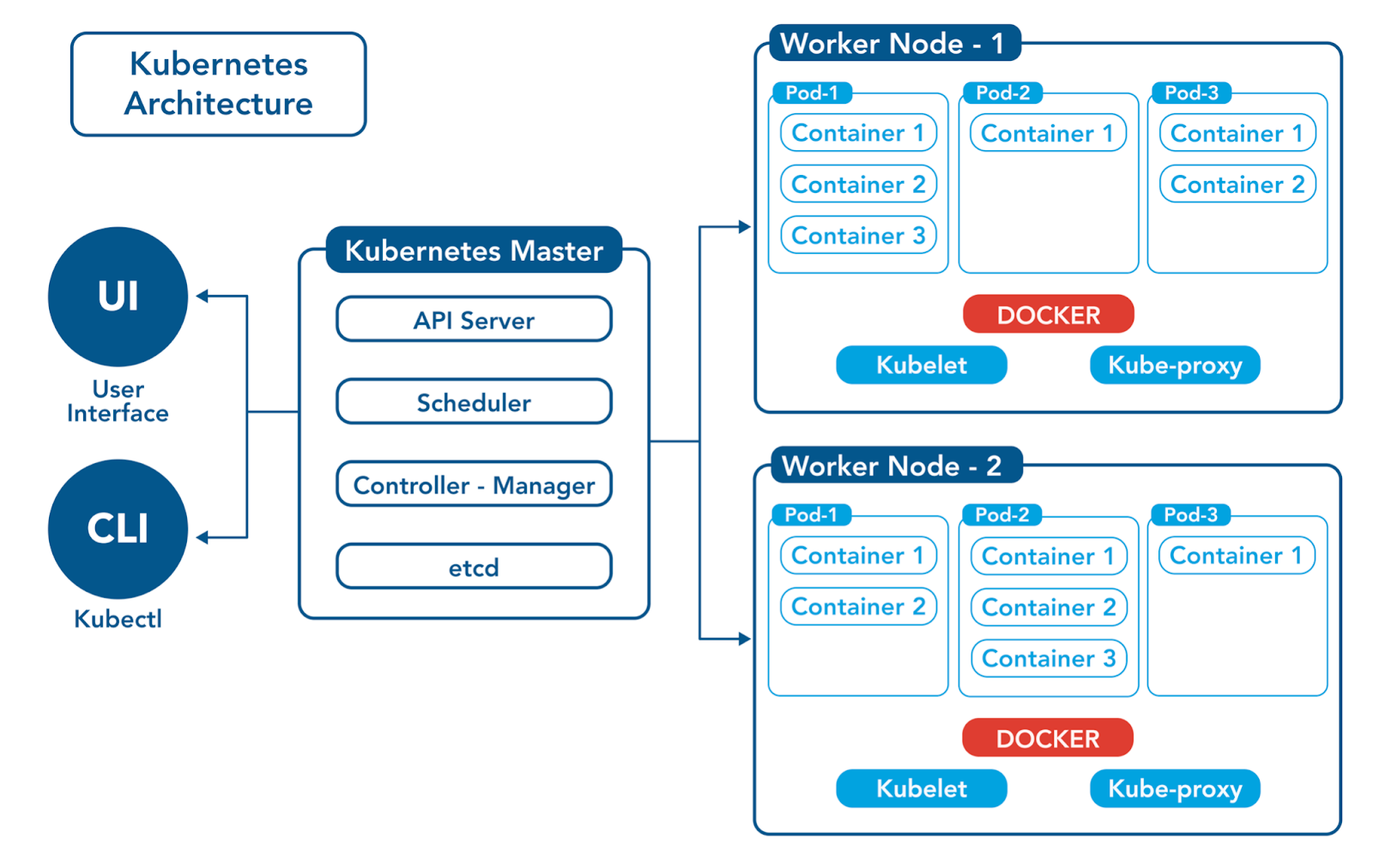
架构、应用与优化Kubernetes的架构设计旨在提供一个分布式、可扩展且高度可用的容器编排平台。它由多个组件构成,协同工作以管理集群的生命周期和操作。
主要组件和节点类型
1. 控制平面(Master节点)
控制平面是Kubernetes的大脑,负责整个集群的管理和协调。它包含几个关键组件:
-
API服务器(kube-apiserver):作为集群的前端,处理REST请求,是所有通信的枢纽。
-
集群数据存储(etcd):一个轻量级、高可用的键值存储,用于保存所有集群数据。
-
控制器管理器(kube-controller-manager):运行控制器进程,这些控制器包括节点控制器、副本控制器等。
-
调度器(kube-scheduler):负责决定将新创建的Pod分配给哪个节点。
2. 工作节点(Worker节点)
工作节点是运行应用程序容器的物理服务器或虚拟机。它们包括:
-
Kubelet:确保容器在Pod中运行,并向控制平面汇报节点的状态。
-
Kube-Proxy:负责节点上的网络代理,实现服务发现和负载均衡。
-
容器运行时:负责运行容器,例如Docker或containerd。
控制平面和数据平面的工作原理
控制平面
控制平面维护着集群的全局状态,如调度决策、响应Pod生命周期事件、控制器的逻辑等。它确保集群始终处于用户定义的期望状态。
数据平面
数据平面包括所有工作节点,负责实际运行用户的应用程序。它通过Kubelet和Kube-Proxy来维护Pod的生命周期和网络规则。
集群状态管理和调度算法
集群状态管理
Kubernetes通过etcd来维护集群状态。所有组件都通过API服务器与etcd交互,获取或更改集群的状态信息。
调度算法
Kubernetes调度器采用多步骤的过程来选择最佳节点:
-
过滤:基于资源需求、策略限制、亲和性规则等过滤掉不适合的节点。
-
评分:对于剩余节点,基于资源使用率、网络拓扑等因素计算评分。
-
选择:选择得分最高的节点来部署Pod。
此过程确保了有效的资源分配和负载平衡,同时满足用户对部署位置的具体要求。
Kubernetes架构的每个组成部分都被精心设计以提高效率、可靠性和可扩展性,确保其能够应对各种规模和复杂度的应用需求。
三、容器编排和管理
容器编排是Kubernetes的核心功能,它负责管理容器的生命周期、维护应用的健康和确保服务的可用性。在这一部分,我们将深入探讨Kubernetes在容器编排和管理方面的机制和组件。
Pod生命周期管理
1. Pod的创建
-
定义:Pod是Kubernetes中最小的部署单元,通常包含一个或多个容器。
-
配置:通过YAML或JSON文件定义Pod的规格,包括容器镜像、端口、环境变量等。
2. Pod的状态
-
Pending:Pod已被Kubernetes接受,但有一个或多个容器尚未创建。
-
Running:Pod已被绑定到一个节点,所有容器都已创建,至少有一个正在运行。
-
Succeeded:Pod中的所有容器都正常运行并已退出,不会重启。
-
Failed:Pod中的所有容器都已终止,且至少有一个因故障终止。
-
Unknown:Pod的状态无法确定。
3. Pod的生命周期钩子
-
PostStart:在容器创建后立即执行的操作。
-
PreStop:在容器终止之前执行的操作。
控制器模式
1. Deployment
-
用途:管理无状态的应用。
-
功能:确保指定数量的Pod副本始终运行,支持滚动更新和回滚。
2. StatefulSet
-
用途:管理有状态的应用。
-
功能:为每个副本维护一个持久的标识符和存储。
3. DaemonSet
-
用途:在集群的每个节点上运行一份Pod副本。
-
功能:用于运行日志收集器、监控代理等集群范围的服务。
4. Job和CronJob
-
用途:执行一次性或定时任务。
-
功能:Job用于执行批处理任务,CronJob用于定时任务。
服务发现和负载均衡
1. Service
-
定义:一种抽象,定义了访问一组Pod的方式。
-
类型:ClusterIP:在集群内部提供一个内部IP。NodePort:在每个节点的指定端口上提供访问。LoadBalancer:使用外部负载均衡器提供访问。ExternalName:通过DNS名映射到外部服务。
2. Ingress
-
定义:管理外部访问集群服务的规则。
-
功能:提供URL路由、负载均衡、SSL终端和名称基础的虚拟主机。
容器编排和管理是Kubernetes的核心强项,它通过一系列精密设计的机制和组件,确保容器化应用的高效、可靠运行。这些功能的深度和灵活性使Kubernetes成为当今企业级容器管理的首选平台。
四、网络和存储
在Kubernetes中,网络和存储的管理对于保证容器化应用的高效运行至关重要。这部分将深入探讨Kubernetes在这两个关键领域的实现机制。
网络模型与策略
1. 网络模型
Kubernetes采用的是扁平化网络模型,要求每个Pod都有一个独一无二的IP地址。这意味着在整个集群内,每个Pod都应该能够直接访问其他Pod,而无需NAT。
-
Pod-to-Pod Communication:Pod之间可以直接通信,无需通过NAT。
-
Pod-to-Service Communication:Service作为Pods的抽象,提供了一个稳定的接口供Pods间通信。
2. 网络策略
Kubernetes允许使用网络策略来控制Pod间的流量。这些策略基于标签和命名空间,允许定义复杂的规则集,以确定Pods间的通信权限。
-
入口和出口规则:定义哪些类型的流量可以进入或离开Pod。
-
基于标签的隔离:通过标签来标识Pods和服务,实现细粒度的网络隔离。
持久化存储和Volume管理
1. Volume
Kubernetes中的Volume是一个存储在Pod中的目录,可以是本地的目录,也可以是远程存储或其他高级存储设备。
-
生命周期:Volume的生命周期与Pod相同,它在Pod启动时创建,在Pod退出时销毁。
-
类型:支持多种类型的Volume,如emptyDir、hostPath、NFS、PersistentVolume等。
2. PersistentVolume (PV) 和 PersistentVolumeClaim (PVC)
-
PersistentVolume (PV):集群资源,代表一块存储空间。PV是独立于Pod的,可以在Pod间共享。
-
PersistentVolumeClaim (PVC):用户对存储的请求。PVC消费PV资源,PVC与PV之间的关系类似于Pod与Node。
3. 存储类 (StorageClass)
-
定义:描述不同类型存储的方法。
-
功能:允许管理员为不同的存储后端提供和配置类别,用户可以基于这些类别创建PVC。
4. StatefulSet的存储管理
StatefulSet是管理有状态应用的控制器,它可以确保每个Pod都能够绑定到特定的PersistentVolume,这对于数据库和其他需要持久化存储的应用至关重要。
Kubernetes在网络和存储方面提供了高度的灵活性和可扩展性,能够适应不同的应用场景和需求。这些特性是Kubernetes支持复杂企业级应用的关键因素之一。
五、安全和合规
在Kubernetes环境中,确保集群安全和遵守合规标准是至关重要的。这一部分详细探讨Kubernetes中的安全机制,包括认证、授权、访问控制以及最佳安全实践。
认证、授权与访问控制
1. 认证 (Authentication)
-
机制:Kubernetes支持多种认证机制,如X.509证书、Bearer Tokens、OpenID Connect Tokens等。
-
Kubeconfig:用于存储API服务器的访问凭证和连接信息。
-
Service Accounts:专门为Pod中运行的应用程序创建的账户,由Kubernetes自动管理。
2. 授权 (Authorization)
-
RBAC (Role-Based Access Control):基于角色的访问控制,通过角色和角色绑定来控制用户对Kubernetes资源的访问。
-
ABAC (Attribute-Based Access Control):基于属性的访问控制,定义复杂的访问规则。
-
Node Authorization:专门控制节点(kubelet)对API的访问。
3. 准入控制 (Admission Control)
-
定义:用于拦截(在认证和授权之后)对API的请求。
-
常用控制器:包括PodSecurityPolicies、ResourceQuotas、NamespaceLifecycle等。
安全最佳实践与策略
1. 集群安全
-
API服务器安全配置:使用HTTPS、开启RBAC、限制访问来源等。
-
节点安全:保证kubelet的安全,限制对kubelet API的访问。
-
网络策略:使用网络策略隔离Pod和服务,防止未授权的跨服务访问。
2. Pod安全
-
Pod安全策略:定义一组条件,Pod需要满足这些条件才能运行。
-
安全上下文:为Pod和容器配置权限和访问控制设置。
-
最小权限原则:只授予Pod运行所必需的权限。
3. 密钥和敏感数据管理
-
Secrets:用于存储和管理敏感信息,如密码、OAuth令牌和SSH密钥。
-
加密-at-Rest:确保持久化存储的数据被加密。
4. 审计日志
-
审计:跟踪和记录集群中的活动,对安全事件进行分析。
-
策略:定义审核日志策略,决定记录哪些事件以及如何保留日志。
通过这些机制和最佳实践,Kubernetes提供了强大的工具来保护集群和应用程序免受未授权访问和攻击,同时确保了合规性和数据保密性。
六、高可用和灾难恢复
在Kubernetes集群管理中,实现高可用性和灾难恢复策略是至关重要的。这些机制确保在硬件故障、软件错误、网络问题等不可预测情况下,集群和应用能够持续运行或快速恢复。
集群的高可用配置
1. 控制平面的高可用
-
多节点控制平面:部署多个控制平面节点,以避免单点故障。
-
负载均衡器:在控制平面节点前设置负载均衡器,以分散请求。
-
etcd集群:运行多个etcd实例,形成一个高可用的键值存储集群。
2. 工作节点的高可用
-
自动扩展和自愈:使用集群自动扩展器和自动修复策略确保足够的工作节点数量和健康状态。
-
跨区域部署:在不同的地理位置或云区域部署节点,以抵御区域性故障。
备份与恢复策略
1. 数据备份
-
etcd备份:定期备份etcd数据,这对于恢复集群状态至关重要。
-
持久卷备份:对PersistentVolumes进行定期备份,以保证数据安全。
2. 集群资源备份
-
Kubernetes资源备份:使用工具如Velero备份Kubernetes资源和配置,包括Deployments、Services等。
3. 灾难恢复
-
恢复计划:制定详细的灾难恢复计划,包括如何快速恢复集群和应用。
-
演练:定期进行灾难恢复演练,以验证和改进恢复流程。
4. 容灾策略
-
多集群部署:部署多个Kubernetes集群,作为彼此的备份,以保证至少有一个集群始终可用。
-
数据复制:跨集群复制关键数据和配置,以确保在主集群不可用时能够快速切换。
通过这些高可用和灾难恢复策略,Kubernetes能够最大限度地减少系统停机时间,保证业务连续性和数据完整性。这些策略对于运行关键业务应用的企业来说尤为重要。
七、监控和日志
监控和日志管理是Kubernetes集群管理中不可或缺的一部分,它们帮助管理员了解集群的健康状况,诊断问题,并确保集群的高效运行。这部分将深入探讨Kubernetes中的监控和日志系统。
集群监控工具和技巧
1. 资源和性能监控
-
Prometheus:一个开源的监控和告警工具,广泛用于Kubernetes的资源和性能监控。
-
Grafana:与Prometheus集成,提供了丰富的数据可视化选项。
-
Heapster:(已废弃)曾经是Kubernetes的默认监控工具,现已被Metrics Server所替代。
-
Metrics Server:用于收集集群中节点和Pod的资源使用数据。
2. 监控策略
-
基于阈值的告警:设置资源使用率等的阈值,当达到阈值时发送告警。
-
自定义监控和告警规则:利用Prometheus的强大查询语言和告警规则来定制监控策略。
日志管理和分析
1. 日志收集
-
Elasticsearch、Fluentd和Kibana(EFK堆栈):一套流行的日志收集、存储和分析解决方案。
-
Loki:一个更轻量级的日志聚合系统,专为Kubernetes设计,与Grafana紧密集成。
2. 日志策略
-
集中式日志收集:将所有节点和Pod的日志汇总到一个中心位置,便于分析和存储。
-
日志轮转和保留:自动删除旧日志,以管理存储空间和满足合规要求。
3. 日志分析
-
实时日志分析:提供实时的日志数据流,帮助快速定位问题。
-
日志查询和可视化:使用Kibana或Grafana对日志数据进行查询和可视化展示。
4. 审计日志
-
Kubernetes审计:记录对Kubernetes API的请求,包括谁、什么时候、什么操作以及操作是否成功等信息。
通过这些监控和日志管理工具,Kubernetes管理员能够有效地监控集群状态,识别和解决问题,从而保证集群的稳定性和效率。这些系统对于维护大规模、复杂的Kubernetes集群至关重要。
文章转载自:techlead_krischang
原文链接:https://www.cnblogs.com/xfuture/p/18119480
体验地址:引迈 - JNPF快速开发平台_低代码开发平台_零代码开发平台_流程设计器_表单引擎_工作流引擎_软件架构
相关文章:
K8s技术全景:架构、应用与优化
一、介绍 Kubernetes的历史和演进 Kubernetes(简称K8s)是一个开源的容器编排系统,用于自动化应用程序的部署、扩展和管理。它最初是由Google内部的Borg系统启发并设计的,于2014年作为开源项目首次亮相。 初始阶段 Kubernetes的诞生…...

Java的异常机制
异常机制 三种类型 检查型异常:程序员无法预见的运行时异常:在编译时会被忽略错误ERROR:错误在代码中被忽略,在编译时检查不到 异常处理机制 抛出异常捕获异常异常处理的五个关键字:try,catchÿ…...
考虑预同步的虚拟同步机T型三电平逆变器并离网MATLAB仿真模型
微❤关注“电气仔推送”获得资料(专享优惠) 模型简介 三相 T 型三电平逆变器电路如图所示,逆变器主回路由三个单相 T 型逆变器组成。 直流侧输入电压为 UPV,直流侧中点电位 O 设为零电位,交流侧输出侧是三相三线制连…...

记一次k8s取证检材过期的恢复
复盘盘古石k8s的时候碰到了证书过期的问题,在此记录解决方法 报错信息:192.168.91.171:6443 was refused - did you specify the right host or port? 查看证书是否过期 kubeadm alpha certs check-expiration或 openssl x509 -in /etc/kubernetes/…...
【网站项目】自助购药小程序
🙊作者简介:拥有多年开发工作经验,分享技术代码帮助学生学习,独立完成自己的项目或者毕业设计。 代码可以私聊博主获取。🌹赠送计算机毕业设计600个选题excel文件,帮助大学选题。赠送开题报告模板ÿ…...

Ubuntu22.04修改默认窗口系统为X11
Ubuntu22.04安装默认窗口系统为Wayland(通过设置->关于可以看到)。 一、用Ubuntu on Xorg会话登录 用户登录时,点“未列出”,输入用户名后,在登录界面底部的齿轮图标中,选择 "Ubuntu on Xorg&quo…...

延时队列实现实战:如何利用 RabbitMQ 实现延时队列,以满足特定延迟处理需求
实现延时队列,可以通过RabbitMQ的死信队列(Dead-letter queue)特性,“死信队列”是当消息过期,或者队列达到最大长度时,未消费的消息会被加入到死信队列。然后,我们可以对死信队列中的消息进行消…...

关于在Ubuntu上配置mysql踩的一些坑
最近准备换工作了,回顾了下学校时期做的那个webserver,又在linux下mysql踩了一些坑,特此记录下来 程序编译错误mysql.h: No such file or directory 云服务器缺少mysql必要的运行组件,安装: sudo apt-get install l…...
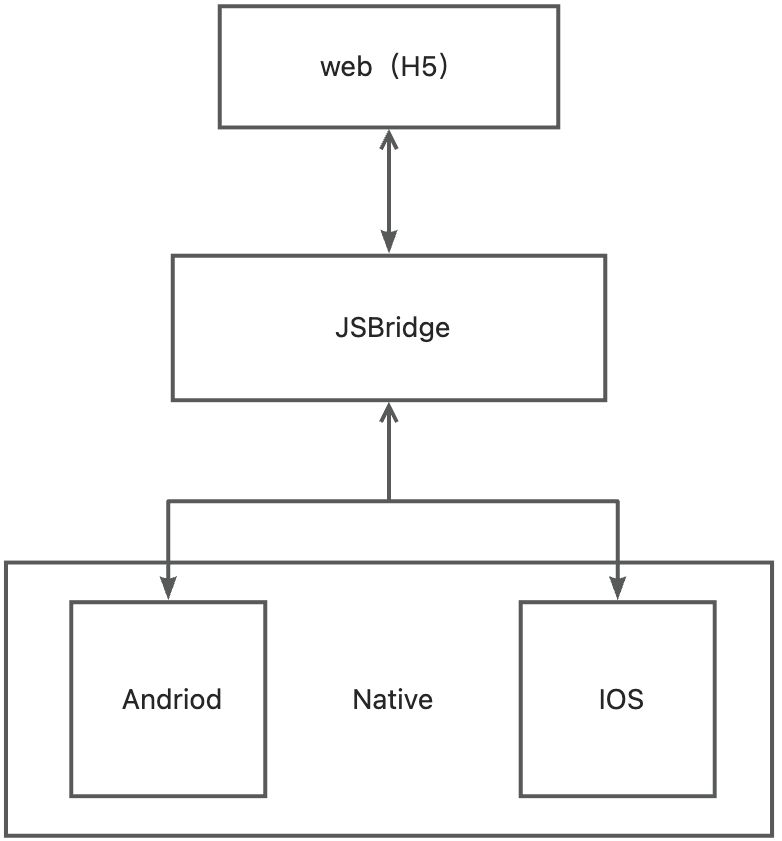
JSBridge原理 - 前端H5与客户端Native交互
1. 概述: 在混合应用开发中,一种常见且成熟的技术方案是将原生应用与 WebView 结合,使得复杂的业务逻辑可以通过网页技术实现。实现这种类型的混合应用时,就需要解决H5与Native之间的双向通信。JSBridge 是一种在混合应用中实现 …...

【Java EE】Spring请求如何传递参数详解
文章目录 🎍传递单个参数🌴传递多个参数🍀传递对象🎄后端参数重命名(后端参数映射)🌲传递数组🎍传递集合🌴传递JSON数据🌸JSON概念🌸JSON的语法&a…...

菜鸟笔记-Numpy常用函数用法汇总
NumPy(Numerical Python的简称)是Python中用于处理数组和矩阵的库,提供了大量的数学函数来操作这些数组。通过前面的学习,慢慢也能发现一些规律,以下是NumPy的一些常用函数及其用法汇总: 数组创建 numpy.a…...
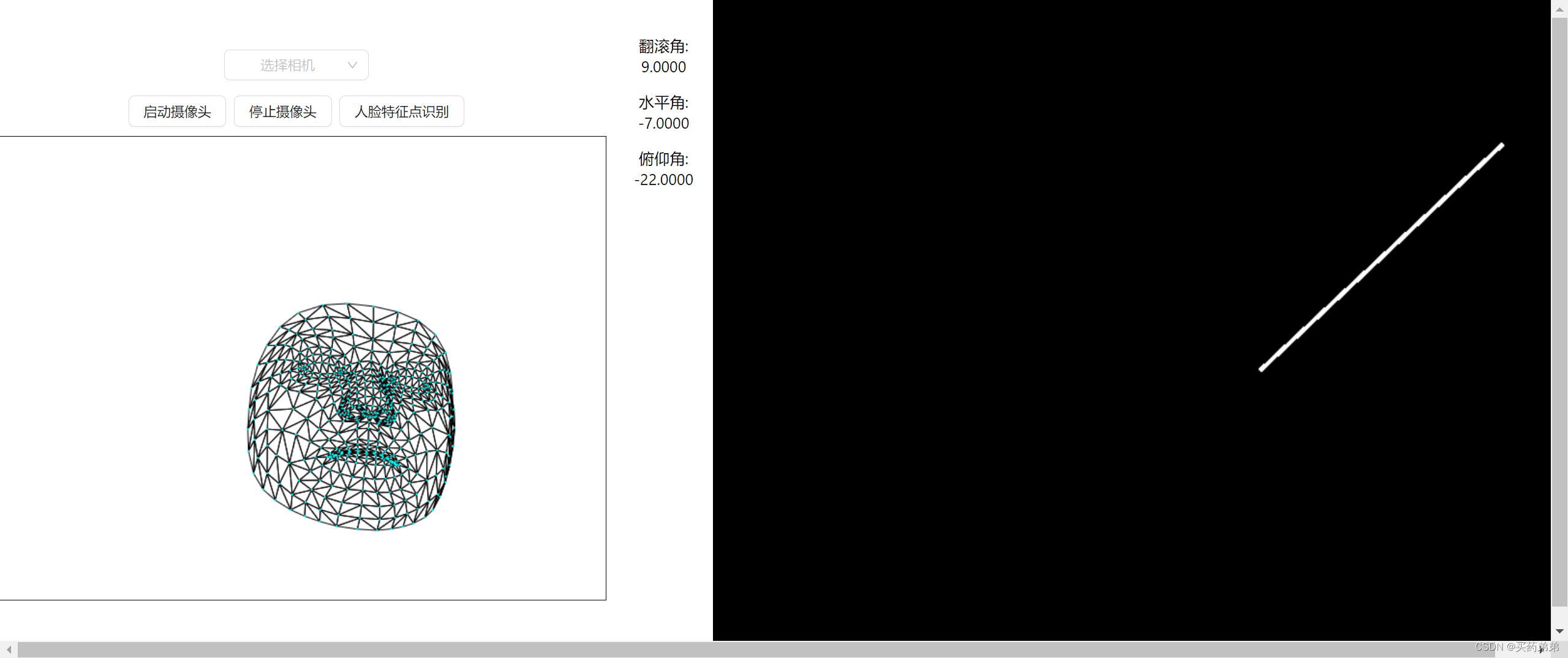
tensorflow.js 如何使用opencv.js通过面部特征点估算脸部姿态并绘制示意图
文章目录 前言一、实现步骤1. 获取所需特征点的索引2. 使用opencv.js 计算俯仰角、水平角和翻滚角cv.solvePnP介绍cv.solvePnP原理运行代码查看效果 3.绘制姿态示意直线添加canvas元素计算姿态直线坐标并绘制 总结 前言 在计算机视觉领域,估算脸部姿态是一项具有挑…...
)
Linux命令-dpkg-divert命令(Debian Linux中创建并管理一个转向列表)
说明 dpkg-divert命令 是Debian Linux中创建并管理一个转向(diversion)列表,其使得安装文件的默认位置失效的工具。 语法 dpkg-divert(选项)(参数)选项 --add:添加一个转移文件; --remove:删除一个转移…...

flex: 1 是哪些属性的缩写?
flex:1是哪些属性的缩写? flex:1 是 flex-grow: 1, flex-shrink: 1,flex-basis: 0% 的缩写; 解释下flex-grow flex-grow是将剩余的空间,根据flex-grow的值平分,然后加到flex-basis上 <!doctype html> <htm…...

python基于opencv实现数籽粒
千粒重是一个重要的农艺性状,通过对其的测量和研究,我们可以更好地理解作物的生长状况,优化农业生产,提高作物产量和品质。但数籽粒数目是一个很繁琐和痛苦的过程,我们现在用一个简单的python程序来数水稻籽粒。代码的…...

OpenCV图像处理——基于OpenCV的ORB算法实现目标追踪
概述 ORB(Oriented FAST and Rotated BRIEF)算法是高效的关键点检测和描述方法。它结合了FAST(Features from Accelerated Segment Test)算法的快速关键点检测能力和BRIEF(Binary Robust Independent Elementary Feat…...

13.JavaWeb XML:构建结构化数据的重要工具
目录 导语: 一、XML概念 (1)可拓展 (2)功能-存储数据 (3)xml与html的区别 二、XML内容 三、XML用途 四、案例:使用XML构建在线书店的书籍数据库 结语: 导语&…...

鸿蒙OS实战开发:【多设备自适应服务卡片】
介绍 服务卡片的布局和使用,其中卡片内容显示使用了一次开发,多端部署的能力实现多设备自适应。 用到了卡片扩展模块接口,[ohos.app.form.FormExtensionAbility] 。 卡片信息和状态等相关类型和枚举接口,[ohos.app.form.formInf…...
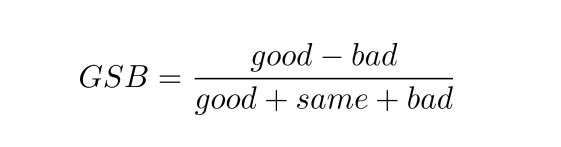
深度学习基础之一:机器学习
文章目录 深度学习基本概念(Basic concepts of deep learning)机器学习典型任务机器学习分类 模型训练的基本概念基本名词机器学习任务流程模型训练详细流程正、反向传播学习率Batch size激活函数激活函数 sigmoid 损失函数MSE & M交叉熵损失 优化器优化器 — 梯度下降优化…...

Python 基于 OpenCV 视觉图像处理实战 之 OpenCV 简单视频处理实战案例 之五 简单指定视频某片段重复播放效果
Python 基于 OpenCV 视觉图像处理实战 之 OpenCV 简单视频处理实战案例 之五 简单指定视频某片段重复播放效果 目录 Python 基于 OpenCV 视觉图像处理实战 之 OpenCV 简单视频处理实战案例 之五 简单指定视频某片段重复播放效果 一、简单介绍 二、简单指定视频某片段重复播放…...
)
从‘密码长度’到‘任意代码执行’:手把手复现攻防世界int_overflow靶场(附Python3 EXP)
从密码长度到系统控制:整数溢出漏洞实战攻防全解析 在网络安全领域,整数溢出漏洞往往因其隐蔽性而被开发者忽视,却可能成为攻击者打开系统大门的金钥匙。本文将带您深入一个典型场景:如何通过精心构造的密码输入,从简单…...
)
NotebookLM赋能电影学研究(2024年唯一经实证验证的学术工作流)
更多请点击: https://codechina.net 第一章:NotebookLM赋能电影学研究(2024年唯一经实证验证的学术工作流) NotebookLM 是 Google 推出的基于用户上传文档进行语义理解与推理的 AI 助手,其“引用溯源”与“片段锚定”…...

AI 说错了怎么办——给生成性 Agent 装上 Self-RAG 自审循环
AI 说错了怎么办——给生成性 Agent 装上 Self-RAG 自审循环Agent 早就跑通了,但有一条横切线一直没单独写过:深度阅读那种动辄一千多字的输出,怎么知道 LLM 是不是在自圆其说。这周回过头来补这一篇,顺便把本周做的几个小改动一并…...

别再被Nginx的rewrite循环搞懵了!一个真实Vue项目部署的500错误排查实录
从Nginx重定向死循环到优雅解决:Vue项目部署的深度排错指南 凌晨三点,服务器监控突然告警——刚上线的Vue企业门户网站出现大面积500错误。查看日志时,那个令人窒息的rewrite or internal redirection cycle错误信息让整个运维团队陷入沉思。…...

失落大陆建模:亚特兰蒂斯数字重建的结构验证
一、项目背景与目标设定在数字孪生与虚拟考古技术飞速发展的当下,亚特兰蒂斯这一传说中失落大陆的数字重建,不仅是对古老神话的技术致敬,更是对复杂场景建模与结构验证能力的极致考验。本项目旨在依托Blender等3D建模工具,结合最新…...

基于SpringBoot的民宿预订与评价系统毕业设计
博主介绍:✌ 专注于Java,python,✌关注✌私信我✌具体的问题,我会尽力帮助你。一、研究目的本研究旨在构建一个基于Spring Boot与Vue框架的民宿预订与评价系统以解决当前旅游住宿服务领域存在的信息不对称问题用户体验碎片化问题以及数据管理分散化问题该…...

Spring Boot Microservices故障排查:10个常见问题及解决方案
Spring Boot Microservices故障排查:10个常见问题及解决方案 【免费下载链接】spring-boot-microservices Spring Boot Template for Micro services Architecture - Show cases how to use Zuul for API Gateway, Spring OAuth 2.0 as Auth Server, Multiple Resou…...

如何用OpenWebRTC实现音视频通话:完整开发教程
如何用OpenWebRTC实现音视频通话:完整开发教程 【免费下载链接】openwebrtc A cross-platform WebRTC client framework based on GStreamer 项目地址: https://gitcode.com/gh_mirrors/op/openwebrtc OpenWebRTC是一个基于GStreamer的跨平台WebRTC客户端框架…...

基于RAG架构构建私有知识库智能问答系统:从原理到部署实战
1. 项目概述:一个基于内容的智能对话机器人最近在GitHub上看到一个挺有意思的项目,叫mpaepper/content-chatbot。乍一看名字,你可能会觉得这又是一个基于大语言模型(LLM)的聊天机器人,市面上已经多如牛毛了…...

创业团队如何利用多模型聚合平台优化产品开发流程
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 创业团队如何利用多模型聚合平台优化产品开发流程 对于小型创业团队而言,在快速迭代产品的过程中,大模型能…...