Feature Pyramid Networks for object detection
FPN
- 总述
- 1.引言
- 2.相关工作
- 3. Feature Pyramid Networks
- Bottom-up pathway
- Top-down pathway and lateral connections
- 4. 应用
- 用于 RPN
- 用于 Fast R-CNN
- 核心代码复现
- FPN网络结构
- ResNet Bottleneck
- 完整代码
总述
下图中,蓝色边框表示的是特征图,边框越粗表示该特征图的语义信息越丰富,即在特征层次结构中位置越高。 这四个子图展示了如何在不同层级上提取和融合特征,以便于在不同尺度上进行有效的对象检测。
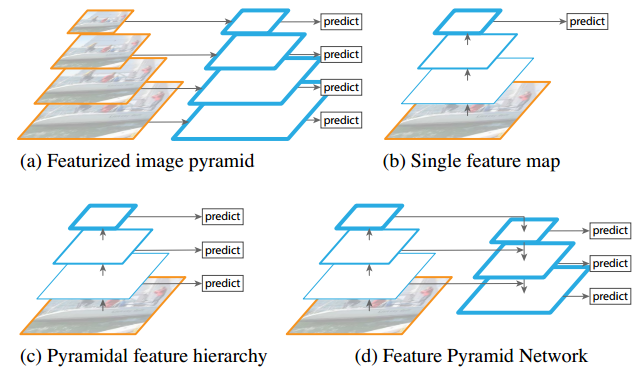
- a) Featurized image pyramid (特征化图像金字塔):
这是传统方法,通过对不同尺度的图像分别计算出一个特征图来构建一个特征金字塔,从而能在多个尺度上进行对象检测。这种方法计算量大,速度慢,因为每个尺度都需要独立计算特征。
- b) Single feature map (单一特征图):
为了提高检测速度,一些现代的检测系统选择只在一个单一的尺度上计算特征并进行预测,避免了特征化图像金字塔的复杂计算过程。但这种方法可能会牺牲对小尺度对象的检测准确性。
- c) Pyramidal feature hierarchy (金字塔特征层级):
这是另一种方法,利用卷积神经网络(ConvNet)内部计算的金字塔特征层级来进行对象检测。它尝试像特征化图像金字塔那样使用这些特征,但并不需要对每个图像尺度独立计算特征,从而可以更快地进行。(卷积神经网络不同卷积层输出的特征图天然有金字塔的特点,就是直接将不同卷积层输出的特征图用于预测)
- d) Feature Pyramid Network (FPN, 特征金字塔网络):
这是本文提出的方法。与单一特征图和金字塔特征层级一样快速,但提供了更高的准确性。FPN通过 自顶向下的路径(Top-down pathway) 和 横向连接(lateral connection) 整合了不同层级的特征,从而在每个层级上都能得到语义较强的特征,用于进行更准确的预测。
1.引言
对图像金字塔的每个级别进行特征化的主要优点是,它产生了一个多尺度特征表示,其中所有级别在语义上都很强,包括高分辨率级别。
然而,图像金字塔并非计算多尺度特征表示的唯一方法。深度卷积神经网络一层一层地计算特征层次结构,通过子采样层,特征层次结构具有固有的多尺度金字塔形状。这种网络内特征层次产生了不同空间分辨率的特征图,但由于深度不同,引入了很大的语义差距。高分辨率的特征图(网络的较浅层)具有低级特征,这损害了它们对目标识别的表示能力。
本文的目标是利用卷积神经网络自然地特征层次的金字塔形状,同时创建一个在所有尺度上都具有强语义的特征金字塔。为了实现这一目标,作者依赖于一种架构,该架构通过自上而下的途径和横向连接将低分辨率、语义强的特征与高分辨率、语义弱的特征结合起来(图1(d))。结果是一个特征金字塔,在所有级别上都具有丰富的语义,并且可以从单个输入图像规模快速构建。换句话说,作者展示了如何在不牺牲表示能力、速度或内存的情况下创建可用于替换特征图像金字塔的 in-network feature pyramids。
作者提出的模型,既适用于 Bounding Box Proposals ,也可以扩展到 Masked Proposals。
此外,作者提出的 FPN 结构可以在所有尺度上进行端对端训练,并在训练/测试时一致使用,这对于传统的图像金字塔来说是不可行的。
2.相关工作
这张图2展示了两种不同的深度学习架构,用于对象检测任务中的特征提取和预测过程。
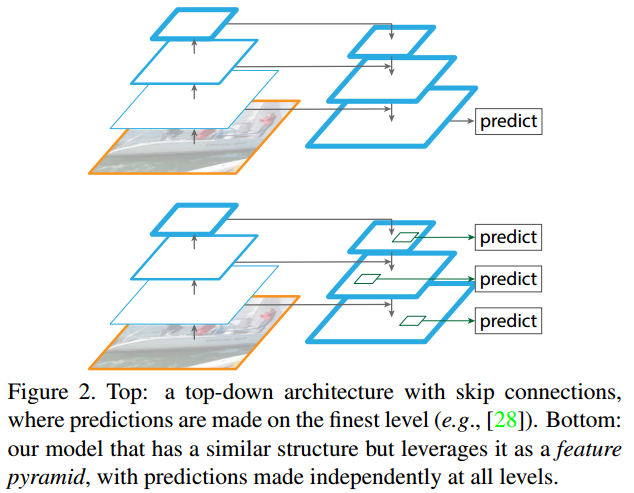
顶部图(Top)显示的是一种自顶向下的架构,该架构带有跳过连接(skip connections)。在这种架构中,预测仅在最细的层级(即空间分辨率最高的特征图)上进行。这样做的一个例子是文献 [28] 中的方法。这种方式 通过自顶向下的路径传递信息,同时利用跳过连接保留细节信息,这对于图像分割任务非常有用。但对于对象检测,尤其是在需要检测不同尺寸的对象时,可能不够有效。
底部图(Bottom)展示的是论文提出的特征金字塔网络(FPN)。它具有与顶部图相似的结构,但它是作为一个特征金字塔(feature pyramid)使用,其中在所有层级上都独立进行预测。这意味着FPN不仅利用自顶向下的结构来提取强语义的特征,并且通过横向连接将这些特征与来自卷积网络低层次的高分辨率特征结合起来。因此,FPN能够在每个层级上都生成具有丰富语义信息的特征图,这使得在不同尺度上的对象检测更加准确和有效。
这张图清楚地说明了FPN的核心优势,即能够结合来自不同深度层次的特征,从而在多尺度对象检测任务中取得好的效果。它避免了仅在单个尺度上进行预测的限制,同时又不需要像传统的特征化图像金字塔那样繁琐地计算每个尺度上的特征。
3. Feature Pyramid Networks
在本文中,作者重点关注滑动窗口提议器(区域提议网络,简称RPN)和基于区域的检测器(Fast R-CNN)
作者的方法采用任意大小的单尺度图像作为输入,并在多个级别输出按比例大小的特征图,以一种完全卷积的方式。
在本文中,作者展示了使用ResNets的结果。作者的金字塔结构包括自下而上的途径,自上而下的途径和横向连接,如下所述。
Bottom-up pathway
自底向上路径是卷积神经网络 backbone 的前馈计算,计算由多个尺度的特征图组成的特征层次结构,缩放步长为 2。通常有许多层产生相同大小的输出图,称这些层处于相同的网络阶段 (stage)。
对于作者提出的特征金字塔,为每个阶段定义一个金字塔级别。选择每个阶段最后一层的输出作为特征图的参考集,将对其进行丰富以创建金字塔。这种选择是很自然的,因为每个阶段的最深层应该拥有最强大的功能。
具体而言,对于 ResNets \text{ResNets} ResNets,作者使用每个阶段最后一个残差块输出的特征激活。对于 conv2, conv3, conv4 \text{conv2, conv3, conv4} conv2, conv3, conv4 和 conv5 \text{conv5} conv5 ,将这些最后的残差块的输出表示为 C 2 , C 3 , C 4 , C 5 {C_2, C_3, C_4, C_5} C2,C3,C4,C5,注意到它们相对于输入图像的步长为 4 , 8 , 16 , 32 {4,8,16,32} 4,8,16,32 像素。作者并没有将 conv1 \text{conv1} conv1 包含在金字塔中,因为它占用了大量内存。
Top-down pathway and lateral connections
自上而下的路径通过对来自更高金字塔级别的空间上更粗糙但语义上更强的特征图进行上采样来产生更高分辨率的特征。然后,这些特征通过横向连接通过自下而上通路的特征得到增强。每个横向连接都合并了自底向上路径和自顶向下路径中相同空间大小的特征图。自底向上的特征图具有较低级的语义,但它的激活定位更准确,因为它的子采样次数更少。
图3显示了构建自顶向下特征图的构建块。对于较粗分辨率的特征图,作者将空间分辨率上采样2倍 (为了简单起见,使用最近邻上采样)。
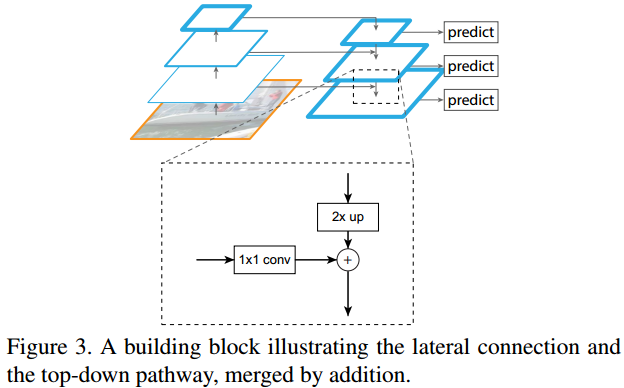
上采样后的特征图然后通过元素级加法 ( element-wise addition \text{element-wise addition} element-wise addition) 与相应的自下而上特征图合并(该特征图经过 1 × 1 1×1 1×1卷积层以减少通道维度)。这个过程反复进行,直到生成最精细的分辨率特征图。
为了开始迭代,作者简单地在 C 5 C_5 C5上附加一个 1 × 1 1×1 1×1 卷积层来生成最粗略的分辨率特征图。最后,在每个合并的特征图上附加 3 × 3 3×3 3×3 卷积来生成最终的特征图,这是为了减少上采样的混叠效应。最后一组特征图称为 P 2 , P 3 , P 4 , P 5 {P_2, P_3, P_4, P_5} P2,P3,P4,P5,分别对应具有相同空间大小的 C 2 , C 3 , C 4 , C 5 {C_2, C_3, C_4, C_5} C2,C3,C4,C5
由于金字塔的所有层次都像传统的特征图像金字塔一样使用共享的分类器/回归器,因此作者固定了所有特征图中的特征维度(通道数,记为 d d d)。作者在本文中设置 d = 256 d = 256 d=256,因此所有额外的卷积层都有 256 256 256 通道输出。在这些额外的层中没有非线性,作者的经验发现这些非线性的影响很小。
简单是作者设计的核心,作者发现其模型对于许多设计选择都是健壮的。作者已经尝试了更复杂的块(例如,使用多层残差块作为连接),并观察到稍微更好的结果。设计更好的连接模块不是本文的重点,因此作者选择了上面描述的简单设计。
4. 应用
用于 RPN
用于 Fast R-CNN
核心代码复现
FPN网络结构
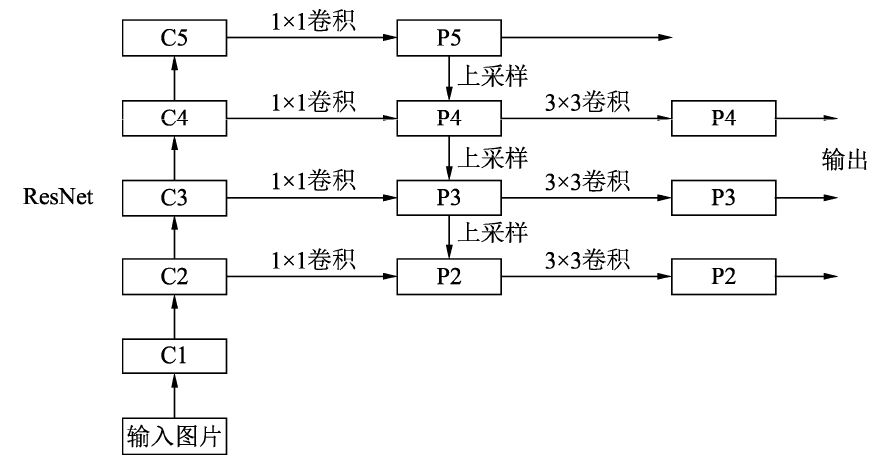
ResNet Bottleneck
在残差网络中,主路径和残差路径的输出必须具有相同的尺寸和通道数,才能进行element-wise相加 !!
可以看到,第一个卷积层和第三个卷积层之间,通道数的变化是倍增 4,所以 expansion = 4 \text{expansion = 4} expansion = 4
64,64和256表示的是对应卷积层的输出通道数
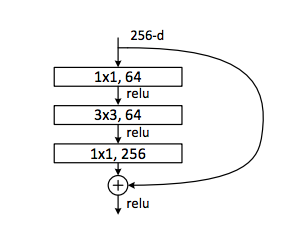
- 第一个1x1卷积层将输入通道数减少到64,这是一个降维操作,它的目的是减少参数数量和计算量。
- 然后是一个3x3的卷积层,它在64个通道上进行操作,这是
Bottleneck的核心部分,用于提取特征。 - 最后一个1x1卷积层再次将通道数增加,这次增加到256,这是一个升维操作,为后续的层提供更多的特征信息。
在此结构中,残差连接(也就是图中的弯曲箭头)直接连接输入和最后一个1x1卷积层的输出。如果输入的通道数不是256,残差连接上通常会有一个1x1卷积用于匹配通道数,这样才能将输入和输出相加。ReLU激活函数应用于每个卷积层之后,以及最终的相加操作之后。
class Bottleneck(nn.Module):# 输出通道倍增数expansion = 4def __init__(self, inchannels, outchannels, stride=1, downsample=None):super(Bottleneck, self).__init__()self.bottleneck = nn.Sequential(# 第一个1*1卷积核降低通道维度nn.Conv2d(inchannels, outchannels, kernel_size=1, bias=False),nn.BatchNorm2d(outchannels),nn.ReLU(inplace=True),# 第二个3*3卷积核特征提取nn.Conv2d(outchannels, outchannels, kernel_size=3, stride=stride, padding=1, bias=False),nn.BatchNorm2d(outchannels),nn.ReLU(inplace=True),# 第三个1*1卷积核升高通道维度nn.Conv2d(outchannels, self.expansion * outchannels, kernel_size=1, bias=False),nn.BatchNorm2d(self.expansion * outchannels))self.relu = nn.ReLU(inplace=True)self.downsample = downsampledef forward(self, x):identity = xout = self.bottleneck(x)if self.downsample is not None:identity = self.downsample(x)out += identityout = self.relu(out)return out
完整代码
import torch
import torch.nn as nn
import torch.nn.functional as F
import math
from torchsummary import summaryclass Bottleneck(nn.Module):# 输出通道倍增数expansion = 4def __init__(self, inchannels, outchannels, stride=1, downsample=None):super(Bottleneck, self).__init__()self.bottleneck = nn.Sequential(# 第一个1*1卷积核降低通道维度nn.Conv2d(inchannels, outchannels, kernel_size=1, bias=False),nn.BatchNorm2d(outchannels),nn.ReLU(inplace=True),# 第二个3*3卷积核特征提取nn.Conv2d(outchannels, outchannels, kernel_size=3, stride=stride, padding=1, bias=False),nn.BatchNorm2d(outchannels),nn.ReLU(inplace=True),# 第三个1*1卷积核升高通道维度nn.Conv2d(outchannels, self.expansion * outchannels, kernel_size=1, bias=False),nn.BatchNorm2d(self.expansion * outchannels))self.relu = nn.ReLU(inplace=True)self.downsample = downsampledef forward(self, x):identity = xout = self.bottleneck(x)# stride!=1 或者输入通道和输出通道数不一致时,downsample不为空if self.downsample is not None:identity = self.downsample(x)# 在残差网络中,主路径和残差路径的输出必须具有相同的尺寸和通道数,才能进行element-wise相加!!# 如果不对x进行下采样,那identity的空间尺寸或通道数是和out不一致的out += identityout = self.relu(out)return outclass FPN(nn.Module):#接收的参数layers是一个列表,每个元素数值代表不同阶段bottleneck块的数量def __init__(self, layers):super(FPN, self).__init__()self.inplanes = 64# 处理C1模块,如果输入空间尺寸是224*224,经过conv1之后尺寸变为112*112self.conv1 = nn.Conv2d(in_channels=3, out_channels=64, kernel_size=7, stride=2, padding=3, bias=False)self.bn1 = nn.BatchNorm2d(64)self.relu = nn.ReLU(inplace=True)# maxpool将特征图大小改变为 56*56self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)# 搭建自底向上的C2,C3,C4,C5模块#resnet50 中 layers[0] = 3,layers[1] = 4,layers[2] = 6,layers[3] = 3,# layers[i]代表各个阶段Bottleneck块的数量# 64,128,256,512 是输出通道数,_make_layers会返回各个阶段包含的一系列Bottleneck块,#conv2_x的输入通道64,conv3_x的输入通道128,conv4_x的输入通道256,conv5_x的输入通道512self.layer1 = self._make_layers(64, layers[0]) #构建C2self.layer2 = self._make_layers(128, layers[1], stride=2) #构建C3self.layer3 = self._make_layers(256, layers[2], stride=2) #构建C4self.layer4 = self._make_layers(512, layers[3], stride=2) #构建C5# 定义toplayer层,用于后面对C5降低输出通道数,得到P5,#这里输入通道是2048是因为resnet50及以上的模型经过conv5_x之后输出的通道数是2048self.toplayer = nn.Conv2d(in_channels=2048, out_channels=256, kernel_size=1, stride=1, padding=0)# 3*3卷积融合,目的是消除上采样过程带来的重叠效应,以生成最终的特征图self.smooth1 = nn.Conv2d(in_channels=256, out_channels=256, kernel_size=3, stride=1, padding=1)self.smooth2 = nn.Conv2d(in_channels=256, out_channels=256, kernel_size=3, stride=1, padding=1)self.smooth3 = nn.Conv2d(in_channels=256, out_channels=256, kernel_size=3, stride=1, padding=1)# 横向连接self.latlayer1 = nn.Conv2d(in_channels=1024, out_channels=256, kernel_size=1, stride=1, padding=0)self.latlayer2 = nn.Conv2d(in_channels=512, out_channels=256, kernel_size=1, stride=1, padding=0)self.latlayer3 = nn.Conv2d(in_channels=256, out_channels=256, kernel_size=1, stride=1, padding=0)# blocks参数代表各个阶段Bottleneck块的数量,来自于layers列表中的元素# stride参数在第一个Bottleneck块中使用,用于控制特征图的空间尺寸是否减半。# 如果stride等于2,各个阶段第一个Bottleneck块将会使特征图的高度和宽度减半。def _make_layers(self, inchannels, blocks, stride=1):downsample = None# stride!=1时需要对特征图进行下采样,# 输入通道数和输出通道数不等时,需要使用1*1卷积核进行通道数调整。#在残差网络中,主路径和残差路径的输出必须具有相同的尺寸和通道数,才能进行element-wise相加!!if stride != 1 or self.inplanes != Bottleneck.expansion * inchannels:downsample = nn.Sequential(nn.Conv2d(self.inplanes, Bottleneck.expansion * inchannels, kernel_size=1, stride=stride, bias = False),nn.BatchNorm2d(Bottleneck.expansion * inchannels))# layers是一个Python列表,它用于存储一系列的Bottleneck块。# 这些Bottleneck块在一起构成了ResNet的一个阶段(stage),其中每个阶段的输出特征图大小可能会减半,而通道数可能会增加# 这里的layers和上面的layers不一样,layers = []layers.append(Bottleneck(self.inplanes, inchannels, stride, downsample))# 因为经过第一个Bottleneck之后,第二个Bottleneck块的输入通道数是第一个Bottleneck块的输出通道数,# 所以需要通道倍增self.inplanes = inchannels * Bottleneck.expansionfor i in range(1, blocks):# 这里没有指定stride=stride,所以是默认的stride=1layers.append(Bottleneck(self.inplanes, inchannels))return nn.Sequential(*layers)def _upsample_and_add(self, x, y):_,_,H,W = y.shape# x是较高层的特征图,上采样到和较低层y一样的空间尺寸后,和y进行元素级加法return F.upsample(x, size=(H,W), mode='bilinear') + ydef forward(self, x):# 自下而上c1 = self.maxpool(self.relu(self.bn1(self.conv1(x))))#c2是conv2_x阶段经过一些列bottleneck块的输出,输出通道数为256c2 = self.layer1(c1)#c3是conv3_x阶段经过一些列bottleneck块的输出,输出通道数为512c3 = self.layer2(c2)#c4是conv4_x阶段经过一些列bottleneck块的输出,输出通道数为1024c4 = self.layer3(c3)#c5是conv5_x阶段经过一些列bottleneck块的输出,输出通道数为2048c5 = self.layer4(c4)# 自顶向下和横向连接# toplayer使用1*1卷积核调整通道数为256,latlayer1,2,3的通道数都是256p5 = self.toplayer(c5)#c4输出的通道数是1024,所以latlayer1的输入通道数是1024,同理latlayer2,3也是p4 = self._upsample_and_add(p5, self.latlayer1(c4))p3 = self._upsample_and_add(p4, self.latlayer2(c3))p2 = self._upsample_and_add(p3, self.latlayer3(c2))# 卷积融合,平滑处理p4 = self.smooth1(p4)p3 = self.smooth2(p3)p2 = self.smooth3(p2)return p2, p3, p4, p5if __name__ == '__main__':fpn = FPN([3, 4, 6, 3]).cuda()summary(fpn, (3, 224, 224))'''
if __name__ == '__main__':model = FPN([3, 4, 6, 3])print(model)input = torch.randn(1, 3, 224, 224)out = model(input)# 遍历输出tuple中的每个元素,并打印其尺寸信息for i, feature_map in enumerate(out):print(f"Feature map {i} size: {feature_map.size()}")
'''
执行之后的打印信息:
----------------------------------------------------------------Layer (type) Output Shape Param #
================================================================Conv2d-1 [-1, 64, 112, 112] 9,408BatchNorm2d-2 [-1, 64, 112, 112] 128ReLU-3 [-1, 64, 112, 112] 0MaxPool2d-4 [-1, 64, 56, 56] 0Conv2d-5 [-1, 64, 56, 56] 4,096BatchNorm2d-6 [-1, 64, 56, 56] 128ReLU-7 [-1, 64, 56, 56] 0Conv2d-8 [-1, 64, 56, 56] 36,864BatchNorm2d-9 [-1, 64, 56, 56] 128ReLU-10 [-1, 64, 56, 56] 0Conv2d-11 [-1, 256, 56, 56] 16,384BatchNorm2d-12 [-1, 256, 56, 56] 512Conv2d-13 [-1, 256, 56, 56] 16,384BatchNorm2d-14 [-1, 256, 56, 56] 512ReLU-15 [-1, 256, 56, 56] 0Bottleneck-16 [-1, 256, 56, 56] 0Conv2d-17 [-1, 64, 56, 56] 16,384BatchNorm2d-18 [-1, 64, 56, 56] 128ReLU-19 [-1, 64, 56, 56] 0Conv2d-20 [-1, 64, 56, 56] 36,864BatchNorm2d-21 [-1, 64, 56, 56] 128ReLU-22 [-1, 64, 56, 56] 0Conv2d-23 [-1, 256, 56, 56] 16,384BatchNorm2d-24 [-1, 256, 56, 56] 512ReLU-25 [-1, 256, 56, 56] 0Bottleneck-26 [-1, 256, 56, 56] 0Conv2d-27 [-1, 64, 56, 56] 16,384BatchNorm2d-28 [-1, 64, 56, 56] 128ReLU-29 [-1, 64, 56, 56] 0Conv2d-30 [-1, 64, 56, 56] 36,864BatchNorm2d-31 [-1, 64, 56, 56] 128ReLU-32 [-1, 64, 56, 56] 0Conv2d-33 [-1, 256, 56, 56] 16,384BatchNorm2d-34 [-1, 256, 56, 56] 512ReLU-35 [-1, 256, 56, 56] 0Bottleneck-36 [-1, 256, 56, 56] 0Conv2d-37 [-1, 128, 56, 56] 32,768BatchNorm2d-38 [-1, 128, 56, 56] 256ReLU-39 [-1, 128, 56, 56] 0Conv2d-40 [-1, 128, 28, 28] 147,456BatchNorm2d-41 [-1, 128, 28, 28] 256ReLU-42 [-1, 128, 28, 28] 0Conv2d-43 [-1, 512, 28, 28] 65,536BatchNorm2d-44 [-1, 512, 28, 28] 1,024Conv2d-45 [-1, 512, 28, 28] 131,072BatchNorm2d-46 [-1, 512, 28, 28] 1,024ReLU-47 [-1, 512, 28, 28] 0Bottleneck-48 [-1, 512, 28, 28] 0Conv2d-49 [-1, 128, 28, 28] 65,536BatchNorm2d-50 [-1, 128, 28, 28] 256ReLU-51 [-1, 128, 28, 28] 0Conv2d-52 [-1, 128, 28, 28] 147,456BatchNorm2d-53 [-1, 128, 28, 28] 256ReLU-54 [-1, 128, 28, 28] 0Conv2d-55 [-1, 512, 28, 28] 65,536BatchNorm2d-56 [-1, 512, 28, 28] 1,024ReLU-57 [-1, 512, 28, 28] 0Bottleneck-58 [-1, 512, 28, 28] 0Conv2d-59 [-1, 128, 28, 28] 65,536BatchNorm2d-60 [-1, 128, 28, 28] 256ReLU-61 [-1, 128, 28, 28] 0Conv2d-62 [-1, 128, 28, 28] 147,456BatchNorm2d-63 [-1, 128, 28, 28] 256ReLU-64 [-1, 128, 28, 28] 0Conv2d-65 [-1, 512, 28, 28] 65,536BatchNorm2d-66 [-1, 512, 28, 28] 1,024ReLU-67 [-1, 512, 28, 28] 0Bottleneck-68 [-1, 512, 28, 28] 0Conv2d-69 [-1, 128, 28, 28] 65,536BatchNorm2d-70 [-1, 128, 28, 28] 256ReLU-71 [-1, 128, 28, 28] 0Conv2d-72 [-1, 128, 28, 28] 147,456BatchNorm2d-73 [-1, 128, 28, 28] 256ReLU-74 [-1, 128, 28, 28] 0Conv2d-75 [-1, 512, 28, 28] 65,536BatchNorm2d-76 [-1, 512, 28, 28] 1,024ReLU-77 [-1, 512, 28, 28] 0Bottleneck-78 [-1, 512, 28, 28] 0Conv2d-79 [-1, 256, 28, 28] 131,072BatchNorm2d-80 [-1, 256, 28, 28] 512ReLU-81 [-1, 256, 28, 28] 0Conv2d-82 [-1, 256, 14, 14] 589,824BatchNorm2d-83 [-1, 256, 14, 14] 512ReLU-84 [-1, 256, 14, 14] 0Conv2d-85 [-1, 1024, 14, 14] 262,144BatchNorm2d-86 [-1, 1024, 14, 14] 2,048Conv2d-87 [-1, 1024, 14, 14] 524,288BatchNorm2d-88 [-1, 1024, 14, 14] 2,048ReLU-89 [-1, 1024, 14, 14] 0Bottleneck-90 [-1, 1024, 14, 14] 0Conv2d-91 [-1, 256, 14, 14] 262,144BatchNorm2d-92 [-1, 256, 14, 14] 512ReLU-93 [-1, 256, 14, 14] 0Conv2d-94 [-1, 256, 14, 14] 589,824BatchNorm2d-95 [-1, 256, 14, 14] 512ReLU-96 [-1, 256, 14, 14] 0Conv2d-97 [-1, 1024, 14, 14] 262,144BatchNorm2d-98 [-1, 1024, 14, 14] 2,048ReLU-99 [-1, 1024, 14, 14] 0Bottleneck-100 [-1, 1024, 14, 14] 0Conv2d-101 [-1, 256, 14, 14] 262,144BatchNorm2d-102 [-1, 256, 14, 14] 512ReLU-103 [-1, 256, 14, 14] 0Conv2d-104 [-1, 256, 14, 14] 589,824BatchNorm2d-105 [-1, 256, 14, 14] 512ReLU-106 [-1, 256, 14, 14] 0Conv2d-107 [-1, 1024, 14, 14] 262,144BatchNorm2d-108 [-1, 1024, 14, 14] 2,048ReLU-109 [-1, 1024, 14, 14] 0Bottleneck-110 [-1, 1024, 14, 14] 0Conv2d-111 [-1, 256, 14, 14] 262,144BatchNorm2d-112 [-1, 256, 14, 14] 512ReLU-113 [-1, 256, 14, 14] 0Conv2d-114 [-1, 256, 14, 14] 589,824BatchNorm2d-115 [-1, 256, 14, 14] 512ReLU-116 [-1, 256, 14, 14] 0Conv2d-117 [-1, 1024, 14, 14] 262,144BatchNorm2d-118 [-1, 1024, 14, 14] 2,048ReLU-119 [-1, 1024, 14, 14] 0Bottleneck-120 [-1, 1024, 14, 14] 0Conv2d-121 [-1, 256, 14, 14] 262,144BatchNorm2d-122 [-1, 256, 14, 14] 512ReLU-123 [-1, 256, 14, 14] 0Conv2d-124 [-1, 256, 14, 14] 589,824BatchNorm2d-125 [-1, 256, 14, 14] 512ReLU-126 [-1, 256, 14, 14] 0Conv2d-127 [-1, 1024, 14, 14] 262,144BatchNorm2d-128 [-1, 1024, 14, 14] 2,048ReLU-129 [-1, 1024, 14, 14] 0Bottleneck-130 [-1, 1024, 14, 14] 0Conv2d-131 [-1, 256, 14, 14] 262,144BatchNorm2d-132 [-1, 256, 14, 14] 512ReLU-133 [-1, 256, 14, 14] 0Conv2d-134 [-1, 256, 14, 14] 589,824BatchNorm2d-135 [-1, 256, 14, 14] 512ReLU-136 [-1, 256, 14, 14] 0Conv2d-137 [-1, 1024, 14, 14] 262,144BatchNorm2d-138 [-1, 1024, 14, 14] 2,048ReLU-139 [-1, 1024, 14, 14] 0Bottleneck-140 [-1, 1024, 14, 14] 0Conv2d-141 [-1, 512, 14, 14] 524,288BatchNorm2d-142 [-1, 512, 14, 14] 1,024ReLU-143 [-1, 512, 14, 14] 0Conv2d-144 [-1, 512, 7, 7] 2,359,296BatchNorm2d-145 [-1, 512, 7, 7] 1,024ReLU-146 [-1, 512, 7, 7] 0Conv2d-147 [-1, 2048, 7, 7] 1,048,576BatchNorm2d-148 [-1, 2048, 7, 7] 4,096Conv2d-149 [-1, 2048, 7, 7] 2,097,152BatchNorm2d-150 [-1, 2048, 7, 7] 4,096ReLU-151 [-1, 2048, 7, 7] 0Bottleneck-152 [-1, 2048, 7, 7] 0Conv2d-153 [-1, 512, 7, 7] 1,048,576BatchNorm2d-154 [-1, 512, 7, 7] 1,024ReLU-155 [-1, 512, 7, 7] 0Conv2d-156 [-1, 512, 7, 7] 2,359,296BatchNorm2d-157 [-1, 512, 7, 7] 1,024ReLU-158 [-1, 512, 7, 7] 0Conv2d-159 [-1, 2048, 7, 7] 1,048,576BatchNorm2d-160 [-1, 2048, 7, 7] 4,096ReLU-161 [-1, 2048, 7, 7] 0Bottleneck-162 [-1, 2048, 7, 7] 0Conv2d-163 [-1, 512, 7, 7] 1,048,576BatchNorm2d-164 [-1, 512, 7, 7] 1,024ReLU-165 [-1, 512, 7, 7] 0Conv2d-166 [-1, 512, 7, 7] 2,359,296BatchNorm2d-167 [-1, 512, 7, 7] 1,024ReLU-168 [-1, 512, 7, 7] 0Conv2d-169 [-1, 2048, 7, 7] 1,048,576BatchNorm2d-170 [-1, 2048, 7, 7] 4,096ReLU-171 [-1, 2048, 7, 7] 0Bottleneck-172 [-1, 2048, 7, 7] 0Conv2d-173 [-1, 256, 7, 7] 524,544Conv2d-174 [-1, 256, 14, 14] 262,400Conv2d-175 [-1, 256, 28, 28] 131,328Conv2d-176 [-1, 256, 56, 56] 65,792Conv2d-177 [-1, 256, 14, 14] 590,080Conv2d-178 [-1, 256, 28, 28] 590,080Conv2d-179 [-1, 256, 56, 56] 590,080
================================================================
Total params: 26,262,336
Trainable params: 26,262,336
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.57
Forward/backward pass size (MB): 302.71
Params size (MB): 100.18
Estimated Total Size (MB): 403.47
----------------------------------------------------------------
查看FPN模型信息
if __name__ == '__main__':model = FPN([3, 4, 6, 3])print(model)input = torch.randn(1, 3, 224, 224)out = model(input)# 遍历输出tuple中的每个元素,并打印其尺寸信息for i, feature_map in enumerate(out):print(f"Feature map {i} size: {feature_map.size()}")
打印信息如下:
FPN((conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True)(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)(layer1): Sequential((0): Bottleneck((bottleneck): Sequential((0): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True)(3): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(4): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(5): ReLU(inplace=True)(6): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(7): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True))(relu): ReLU(inplace=True)(downsample): Sequential((0): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)))(1): Bottleneck((bottleneck): Sequential((0): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True)(3): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(4): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(5): ReLU(inplace=True)(6): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(7): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True))(relu): ReLU(inplace=True))(2): Bottleneck((bottleneck): Sequential((0): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True)(3): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(4): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(5): ReLU(inplace=True)(6): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(7): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True))(relu): ReLU(inplace=True)))(layer2): Sequential((0): Bottleneck((bottleneck): Sequential((0): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True)(3): Conv2d(128, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)(4): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(5): ReLU(inplace=True)(6): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)(7): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True))(relu): ReLU(inplace=True)(downsample): Sequential((0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)))(1): Bottleneck((bottleneck): Sequential((0): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True)(3): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(4): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(5): ReLU(inplace=True)(6): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)(7): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True))(relu): ReLU(inplace=True))(2): Bottleneck((bottleneck): Sequential((0): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True)(3): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(4): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(5): ReLU(inplace=True)(6): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)(7): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True))(relu): ReLU(inplace=True))(3): Bottleneck((bottleneck): Sequential((0): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True)(3): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(4): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(5): ReLU(inplace=True)(6): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)(7): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True))(relu): ReLU(inplace=True)))(layer3): Sequential((0): Bottleneck((bottleneck): Sequential((0): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True)(3): Conv2d(256, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)(4): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(5): ReLU(inplace=True)(6): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)(7): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True))(relu): ReLU(inplace=True)(downsample): Sequential((0): Conv2d(512, 1024, kernel_size=(1, 1), stride=(2, 2), bias=False)(1): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)))(1): Bottleneck((bottleneck): Sequential((0): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True)(3): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(4): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(5): ReLU(inplace=True)(6): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)(7): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True))(relu): ReLU(inplace=True))(2): Bottleneck((bottleneck): Sequential((0): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True)(3): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(4): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(5): ReLU(inplace=True)(6): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)(7): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True))(relu): ReLU(inplace=True))(3): Bottleneck((bottleneck): Sequential((0): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True)(3): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(4): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(5): ReLU(inplace=True)(6): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)(7): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True))(relu): ReLU(inplace=True))(4): Bottleneck((bottleneck): Sequential((0): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True)(3): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(4): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(5): ReLU(inplace=True)(6): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)(7): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True))(relu): ReLU(inplace=True))(5): Bottleneck((bottleneck): Sequential((0): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True)(3): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(4): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(5): ReLU(inplace=True)(6): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)(7): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True))(relu): ReLU(inplace=True)))(layer4): Sequential((0): Bottleneck((bottleneck): Sequential((0): Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True)(3): Conv2d(512, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)(4): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(5): ReLU(inplace=True)(6): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)(7): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True))(relu): ReLU(inplace=True)(downsample): Sequential((0): Conv2d(1024, 2048, kernel_size=(1, 1), stride=(2, 2), bias=False)(1): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)))(1): Bottleneck((bottleneck): Sequential((0): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True)(3): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(4): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(5): ReLU(inplace=True)(6): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)(7): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True))(relu): ReLU(inplace=True))(2): Bottleneck((bottleneck): Sequential((0): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True)(3): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(4): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(5): ReLU(inplace=True)(6): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)(7): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True))(relu): ReLU(inplace=True)))(toplayer): Conv2d(2048, 256, kernel_size=(1, 1), stride=(1, 1))(smooth1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(smooth2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(smooth3): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(latlayer1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1))(latlayer2): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1))(latlayer3): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1))
)
D:\Miniconda\envs\SINet_01\lib\site-packages\torch\nn\functional.py:3769: UserWarning: nn.functional.upsample is deprecated. Use nn.functional.interpolate instead.warnings.warn("nn.functional.upsample is deprecated. Use nn.functional.interpolate instead.")
Feature map 0 size: torch.Size([1, 256, 56, 56])
Feature map 1 size: torch.Size([1, 256, 28, 28])
Feature map 2 size: torch.Size([1, 256, 14, 14])
Feature map 3 size: torch.Size([1, 256, 7, 7])
相关文章:
Feature Pyramid Networks for object detection
FPN 总述1.引言2.相关工作3. Feature Pyramid NetworksBottom-up pathwayTop-down pathway and lateral connections 4. 应用用于 RPN用于 Fast R-CNN 核心代码复现FPN网络结构ResNet Bottleneck完整代码 总述 下图中,蓝色边框表示的是特征图,边框越粗表…...

Linux下docker运行python
前言 本机开发环境众多,python版本都好多个,虽然可以通过conda管理多个虚拟环境,但还是不能像容器那样进行进程间的隔离。于是打算试下docker下运行python,而且生产环境很多时候也是用容器来跑应用,环境统一、方便扩容…...

MacOS下载和安装HomeBrew的详细教程
在MacOS上安装Homebrew的详细教程如下:(参考官网:macOS(或 Linux)缺失的软件包的管理器 — Homebrew) 步骤1:检查系统要求 确保你的MacOS版本至少为macOS Monterey (12) (or higher) 或更高版本…...

AI技术在金融领域/银行业的应用和风险
前言 随着科技的不断发展,人工智能(AI)技术已经在各行各业得到了广泛的应用,其中包括银行业。银行业作为经济的重要组成部分,一直在不断地探索和应用新技术,以提升服务效率、风险管理和客户体验。然而&…...
每日OJ题_两个数组dp⑤_力扣10. 正则表达式匹配
目录 力扣10. 正则表达式匹配 解析代码 力扣10. 正则表达式匹配 10. 正则表达式匹配 难度 困难 给你一个字符串 s 和一个字符规律 p,请你来实现一个支持 . 和 * 的正则表达式匹配。 . 匹配任意单个字符* 匹配零个或多个前面的那一个元素 所谓匹配,…...
开源区块链系统/技术 总结(欢迎补充,最新)
一、联盟链 1. FISCO BCOS FISCO BCOS 2.0 技术文档 — FISCO BCOS 2.0 v2.9.0 文档https://fisco-bcos-documentation.readthedocs.io/ 2. ChainMaker(长安链) 文档导航 — chainmaker-docs v2.3.2 documentationhttps://docs.chainmaker.org.cn/v2…...

LeetCode 994—— 腐烂的橘子
阅读目录 1. 题目2. 解题思路3. 代码实现 1. 题目 2. 解题思路 1.记录下初始新鲜橘子的位置到 notRotting,我们按照行把二维数组拉成一维,所以,一个vector 就可以实现了;2.如果没有新鲜橘子,那么第 0 分钟所有橘子已经…...

向上向下采样
在数字图像处理中,向上采样(upsampling)和向下采样(downsampling)是两种常见的操作,用于改变图像的分辨率。 向上采样(Upsampling): 向上采样是指增加图像的分辨率&…...

Leetcode面试经典150_Q169多数元素
题目: 给定一个大小为 n 的数组 nums ,返回其中的多数元素。多数元素是指在数组中出现次数 大于 ⌊n/2⌋ 的元素。 你可以假设数组是非空的,并且给定的数组总是存在多数元素。 解题思路: 1. 注意“大于 ⌊n/2⌋”,…...

Spring Cloud微服务入门(五)
Sentinel的安装与使用 安装部署Sentinel 下载Sentinel: https://github.com/alibaba/Sentinel/releases Sentinel控制台 https://localhost:8080 用户和密码为sentinel 使用Sentinel 加依赖: 写配置: 输入: java -Dserver.po…...

负荷预测 | Matlab基于TCN-GRU-Attention单输入单输出时间序列多步预测
目录 效果一览基本介绍程序设计参考资料 效果一览 基本介绍 1.Matlab基于TCN-GRU-Attention单输入单输出时间序列多步预测; 2.单变量时间序列数据集,采用前12个时刻预测未来96个时刻的数据; 3.excel数据方便替换,运行环境matlab20…...

SpringBoot整合Spring Data JPA
✅作者简介:大家好,我是Leo,热爱Java后端开发者,一个想要与大家共同进步的男人😉😉🍎个人主页:Leo的博客💞当前专栏: 循序渐进学SpringBoot ✨特色专栏: MySQL学习 🥭本文内容: SpringBoot整合Spring Data JPA 📚个人知识库: Leo知识库,欢迎大家访问 1.…...

机器学习(五) -- 监督学习(2) -- k近邻
系列文章目录及链接 目录 前言 一、K近邻通俗理解及定义 二、原理理解及公式 1、距离度量 四、接口实现 1、鸢尾花数据集介绍 2、API 3、流程 3.1、获取数据 3.2、数据预处理 3.3、特征工程 3.4、knn模型训练 3.5、模型评估 3.6、结果预测 4、超参数搜索-网格搜…...

【.NET全栈】ZedGraph图表库的介绍和应用
文章目录 一、ZedGraph介绍ZedGraph的特点ZedGraph的缺点使用注意事项 二、ZedGraph官网三、ZedGraph的应用四、ZedGraph的高端应用五、、总结 一、ZedGraph介绍 ZedGraph 是一个用于绘制图表和图形的开源.NET图表库。它提供了丰富的功能和灵活性,可以用于创建各种…...

vivado 设计调试
设计调试 对 FPGA 或 ACAP 设计进行调试是一个多步骤迭代式流程。与大多数复杂问题的处理方式一样 , 最好先将 FPGA 或 ACAP 设计调试流程细分为多个小部分 , 以便集中精力使设计中的每一小部分能逐一正常运行 , 而不是尝试一次性让整 个…...

Python3 replace()函数使用详解:字符串的艺术转换
博主猫头虎的技术世界 🌟 欢迎来到猫头虎的博客 — 探索技术的无限可能! 专栏链接: 🔗 精选专栏: 《面试题大全》 — 面试准备的宝典!《IDEA开发秘籍》 — 提升你的IDEA技能!《100天精通鸿蒙》 …...

【C++】用红黑树封装map和set
我们之前学的map和set在stl源码中都是用红黑树封装实现的,当然,我们也可以模拟来实现一下。在实现之前,我们也可以看一下stl源码是如何实现的。我们上篇博客写的红黑树里面只是一个pair对象,这对于set来说显然是不合适的ÿ…...

一些好玩的东西
这里写目录标题 递归1.递归打印数组和链表?代码实现原理讲解二叉树的 前 中 后 序位置 参考文章 递归 1.递归打印数组和链表? 平常我们打印数组和链表都是 迭代 就好了今天学到一个新思路–>不仅可以轻松正着打印数组和链表 , 还能轻松倒着打印(用的是二叉树的前中后序遍…...

微电网优化:基于巨型犰狳优化算法(Giant Armadillo Optimization,GAO)的微电网优化(提供MATLAB代码)
一、微电网优化模型 微电网是一个相对独立的本地化电力单元,用户现场的分布式发电可以支持用电需求。为此,您的微电网将接入、监控、预测和控制您本地的分布式能源系统,同时强化供电系统的弹性,保障您的用电更经济。您可以在连接…...

java锁
乐观锁 乐观锁是一种乐观思想,即认为读多写少,遇到并发写的可能性低,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,采取在写时先读出…...

ArcSWAT建模踩坑记:你的土壤数据库参数算对了吗?聊聊SPAW的那些默认值和单位陷阱
ArcSWAT土壤参数校准实战:避开SPAW计算中的5个致命误区 当水文模拟结果与实测数据出现系统性偏差时,经验丰富的建模者会首先检查土壤参数——这个隐藏在界面背后的"沉默变量"往往是误差的最大来源。SPAW作为ArcSWAT推荐的土壤参数计算工具&…...
)
用Python和OpenCV手把手教你搞定自动驾驶图像坐标系转换(附NuScenes数据集实战代码)
用Python和OpenCV手把手教你搞定自动驾驶图像坐标系转换(附NuScenes数据集实战代码) 自动驾驶技术的核心在于让车辆"看懂"周围环境,而坐标系转换正是连接物理世界与数字世界的桥梁。想象一下,当一辆自动驾驶汽车行驶在…...

终极D2DX宽屏补丁:让经典暗黑破坏神2在现代PC上完美重生
终极D2DX宽屏补丁:让经典暗黑破坏神2在现代PC上完美重生 【免费下载链接】d2dx D2DX is a complete solution to make Diablo II run well on modern PCs, with high fps and better resolutions. 项目地址: https://gitcode.com/gh_mirrors/d2/d2dx 你是否还…...

别再死记硬背了!用这5个真实项目案例,彻底搞懂Python函数参数与返回值
别再死记硬背了!用这5个真实项目案例,彻底搞懂Python函数参数与返回值 函数是Python编程的基石,但很多初学者在学完基础语法后,面对实际项目依然无从下手。本文将通过5个真实开发场景,带你从"会用"到"懂…...

多模态AI应用开发实战:GPT与图像生成的集成架构与优化
1. 项目概述与核心价值最近在折腾AI图像生成和智能对话的整合应用时,发现了一个挺有意思的仓库:bubblesslayyer-cmd/Awesome-GPT-Image-2-OpenAi。这个项目名字乍一看有点长,但拆解一下就能明白它的核心——“Awesome”系列通常代表精选资源集…...

暗黑3鼠标宏终极指南:D3KeyHelper 5步配置法快速上手
暗黑3鼠标宏终极指南:D3KeyHelper 5步配置法快速上手 【免费下载链接】D3keyHelper D3KeyHelper是一个有图形界面,可自定义配置的暗黑3鼠标宏工具。 项目地址: https://gitcode.com/gh_mirrors/d3/D3keyHelper D3KeyHelper是一款专为暗黑破坏神3玩…...

基于Arduino与TSL2561的光照度测量系统:从硬件连接到软件调试
1. 项目概述:从园艺需求到嵌入式光测量方案最近在折腾一个园艺相关的项目,需要量化评估不同覆盖材料(比如遮阳网、塑料薄膜)对光线透射率的影响。说白了,就是想精确知道,盖上一层材料后,底下还能…...

XHS-Downloader:小红书内容采集与管理的全栈解决方案
XHS-Downloader:小红书内容采集与管理的全栈解决方案 【免费下载链接】XHS-Downloader 小红书(XiaoHongShu、RedNote)链接提取/作品采集工具:提取账号发布、收藏、点赞、专辑作品链接;提取搜索结果作品、用户链接&…...

避坑指南:在Unity 2022 LTS中配置XCharts插件时遇到的3个常见问题及解决方法
Unity 2022 LTS中XCharts插件实战避坑手册 当数据可视化成为现代应用的核心需求时,Unity开发者常会选择XCharts这类开源图表插件来快速实现专业级图表展示。但在实际项目落地过程中,版本兼容性、环境配置和平台适配等问题往往会让开发进程意外卡壳。本文…...
)
【仅剩217份】《Midjourney后印象派风格白皮书》V2.3——含17位艺术家专属LoRA适配建议、32组跨文化色彩映射表及实时风格强度校准工具(2024.06内部封测版)
更多请点击: https://intelliparadigm.com 第一章:后印象派风格的视觉基因与Midjourney语义解码 后印象派并非对自然的模仿,而是对色彩、结构与主观情绪的系统性重构——梵高旋转的星云、塞尚凝固的苹果、高更平面化的塔希提图腾,…...