2024电工杯B题保姆级分析完整思路+代码+数据教学
2024电工杯B题保姆级分析完整思路+代码+数据教学
B题题目:大学生平衡膳食食谱的优化设计及评价
接下来我们将按照题目总体分析-背景分析-各小问分析的形式来
总体分析:
题目要求对两份一日膳食食谱进行营养分析和调整,然后设计优化的平衡膳食食谱,并进行评价。具体步骤如下:
问题 1:膳食食谱的营养分析评价及调整
1.1 膳食营养评价
首先我们需要对附件1和附件2中的男、女大学生的膳食进行全面的营养评价。根据附件4的标准,评价内容包括能量、主要营养素含量(蛋白质、脂肪、碳水化合物等)、非产能营养素(钙、铁、锌、维生素等)及氨基酸评分等。
1.2 调整改进
基于附件3提供的食堂主要食物信息,对男、女大学生的膳食进行适当调整,使其更符合营养需求,然后再进行营养评价。
问题 2:基于附件3的日平衡膳食食谱的优化设计
2.1 目标一:蛋白质氨基酸评分最大化
建立优化模型,设计男、女大学生的日食谱,并进行膳食营养评价。
2.2 目标二:用餐费用最经济
建立优化模型,设计男、女大学生的日食谱,并进行膳食营养评价。
2.3 目标三:兼顾蛋白质氨基酸评分及经济性
建立综合优化模型,设计男、女大学生的日食谱,并进行膳食营养评价。
2.4 比较分析
对上述三种优化方案进行比较分析,找出最优方案。
问题 3:基于附件3的周平衡膳食食谱的优化设计
在问题2的基础上,分别以蛋白质氨基酸评分最大、用餐费用最经济、兼顾蛋白质氨基酸评分及经济性为目标,设计男、女大学生的周食谱,并进行评价及比较分析。
问题 4:健康饮食、平衡膳食的倡议书
基于以上分析和设计,针对大学生饮食结构及习惯,写一份健康饮食、平衡膳食的倡议书。
背景分析:
大学时代是学知识、长身体的重要阶段,这一时期的年轻人需要充足的能量和营养素来支持身体发育、脑力劳动和体育锻炼。然而,目前大学生饮食结构不合理、不良饮食习惯突出,如不吃早餐、经常食用外卖快餐等,导致营养不良或过度肥胖。解决这些问题对于大学生的生长发育和健康至关重要。
可以看到研究的对象是一名男大学生和一名女大学生,他们分别记录了一日三餐的食物摄入情况。并且还有某高校学生食堂提供的一日三餐主要食物信息。
数据文件包括3个数据集,在拆解后,我们的目标主要有以下几个:
-
营养分析和评价:
-
对男、女大学生的膳食进行全面的营养分析和评价。
-
基于高校食堂的食物信息,对膳食进行调整改进,并重新进行评价。
-
优化设计:
-
建立优化模型,设计男、女大学生的日食谱,目标分别为蛋白质氨基酸评分最大、用餐费用最经济、兼顾评分和经济性。
-
在日食谱基础上,设计周食谱,并进行评价和比较分析。
-
健康倡议书:
-
针对大学生的饮食结构及习惯,撰写一份健康饮食、平衡膳食的倡议书。
现在就先对数据集进行预处理分析,我们以附件1为例,做数据预处理和探索性数据分析(EDA)
数据读取和展示:
import pandas as pd
# 读取数据
male_diet = pd.read_excel('/mnt/data/附件1:1名男大学生的一日食谱.xlsx')
# 展示前10行数据
male_diet_head = male_diet.head(10)
male_diet_head
数据预处理
预处理步骤包括:
-
检查数据的完整性,处理缺失值。
-
转换数据类型,确保所有数据类型正确。
-
计算每种食物的总量及其对应的营养素含量。
代码:
# 检查数据的基本信息
male_diet.info()
# 检查数据的描述性统计
male_diet.describe()
# 检查是否有缺失值
missing_values = male_diet.isnull().sum()
missing_values
数据处理和计算
根据每种食物的量和其营养成分表,计算总的营养素含量。
假设数据表中包括以下列:食物名称、数量(g)、蛋白质含量(g/100g)、脂肪含量(g/100g)、碳水化合物含量(g/100g)等。
# 假设有以下列
# 食物名称、数量(g)、蛋白质含量(g/100g)、脂肪含量(g/100g)、碳水化合物含量(g/100g)
# 添加总蛋白质、总脂肪、总碳水化合物列
male_diet['总蛋白质 (g)'] = male_diet['数量 (g)'] * male_diet['蛋白质含量 (g/100g)'] / 100
male_diet['总脂肪 (g)'] = male_diet['数量 (g)'] * male_diet['脂肪含量 (g/100g)'] / 100
male_diet['总碳水化合物 (g)'] = male_diet['数量 (g)'] * male_diet['碳水化合物含量 (g/100g)'] / 100
# 计算总的营养素含量
total_protein = male_diet['总蛋白质 (g)'].sum()
total_fat = male_diet['总脂肪 (g)'].sum()
total_carbs = male_diet['总碳水化合物 (g)'].sum()
# 展示总营养素含量
total_nutrients = {
'总蛋白质 (g)': total_protein,
'总脂肪 (g)': total_fat,
'总碳水化合物 (g)': total_carbs
}
total_nutrients
探索性数据分析(EDA)
-
食物种类和数量分布:
-
统计不同类别食物的数量分布情况。
-
营养素分布:
-
分析蛋白质、脂肪、碳水化合物在整个食谱中的分布。
import matplotlib.pyplot as plt
# 食物种类和数量分布
food_types = male_diet['食物名称'].value_counts()
food_types.plot(kind='bar', title='食物种类分布')
plt.xlabel('食物名称')
plt.ylabel('数量')
plt.show()
# 营养素分布
nutrients = male_diet[['总蛋白质 (g)', '总脂肪 (g)', '总碳水化合物 (g)']]
nutrients.sum().plot(kind='bar', title='营养素分布')
plt.xlabel('营养素')
plt.ylabel('总量 (g)')
plt.show()
通过以上步骤,我们可以获得男大学生一日食谱的基本情况及其营养素分布,为后续的营养评价和优化设计打下基础。附件2类似方法可以做。下面来看问题1的分析过程
问题一分析:
针对问题一,它分为两个小问,包括对两份食谱做出全面的膳食营养评价,以及加上附件3后的调整。首先,先来解决第一小问。
膳食营养评价
我们需要对男大学生的一日膳食进行全面的营养分析评价,评价内容包括:
l 食物结构分析:检查食物种类是否齐全,是否多样化。
l 能量和主要营养素计算:计算总能量及蛋白质、脂肪、碳水化合物的摄入量。
l 非产能营养素计算:计算钙、铁、锌、维生素A、维生素B1、维生素B2、维生素C的摄入量。
l 营养素供能比分析:评价蛋白质、脂肪、碳水化合物的供能占比。
l 氨基酸评分分析:计算食谱中蛋白质的氨基酸评分。
数据预处理
首先读取数据,并检查数据的完整性和类型:
Python代码:
import pandas as pd
# 读取数据
male_diet = pd.read_excel('/mnt/data/附件1:1名男大学生的一日食谱.xlsx')
# 展示前10行数据
male_diet_head = male_diet.head(10)
print(male_diet_head)
# 检查数据的基本信息
male_diet.info()
# 检查数据的描述性统计
male_diet.describe()
# 检查是否有缺失值
missing_values = male_diet.isnull().sum()
print(missing_values)
食物结构分析
根据《中国居民膳食指南》的要求,检查食物种类是否多样化:
python
# 统计食物种类
food_types = male_diet['食物名称'].nunique()
print(f"食物种类数量: {food_types}")
# 分析食物类别是否齐全
food_categories = ['谷类', '蔬菜', '水果', '肉类', '奶类', '豆类', '油脂']
food_categories_count = male_diet['类别'].value_counts()
print(food_categories_count)
下面给大家如何用灰色综合评价法来做的示例,推荐大家使用此算法:
灰色综合评价法步骤
-
确定评价指标体系:
-
选择评价膳食营养的关键指标,如总能量、蛋白质、脂肪、碳水化合物、钙、铁、锌、维生素A、维生素B1、维生素B2、维生素C等。
-
数据标准化:
-
对各指标数据进行无量纲化处理(标准化),以消除不同指标间量纲的影响。
-
计算灰关联度:
-
计算每个评价对象(食谱)与理想参考值之间的灰色关联度。
-
计算综合关联度:
-
根据各指标的权重,计算各评价对象的综合关联度。
-
综合评价:
-
根据综合关联度对各评价对象进行排序,得出综合评价结果。
实现步骤 1. 确定评价指标体系 选择男大学生膳食的关键评价指标如下:
-
总能量 (kcal)
-
总蛋白质 (g)
-
总脂肪 (g)
-
总碳水化合物 (g)
-
钙 (mg)
-
铁 (mg)
-
锌 (mg)
-
维生素A (μg)
-
维生素B1 (mg)
-
维生素B2 (mg)
-
维生素C (mg)
2. 数据标准化 标准化处理可以采用极差标准化方法:

添加图片注释,不超过 140 字(可选)
假设数据已经在前面的步骤中计算完成,以下代码将实现数据标准化:
python
复制代码
import numpy as np
# 假设 total_nutrients 和 total_non_energy_nutrients 是已计算的营养素总量
data = {
'总能量 (kcal)': total_energy,
'总蛋白质 (g)': total_protein,
'总脂肪 (g)': total_fat,
'总碳水化合物 (g)': total_carbs,
'钙 (mg)': total_calcium,
'铁 (mg)': total_iron,
'锌 (mg)': total_zinc,
'维生素A (μg)': total_vitamin_a,
'维生素B1 (mg)': total_vitamin_b1,
'维生素B2 (mg)': total_vitamin_b2,
'维生素C (mg)': total_vitamin_c
}
# 转换为DataFrame
df = pd.DataFrame([data])
# 定义理想参考值,可以参考膳食指南的推荐摄入量
ideal_values = {
'总能量 (kcal)': 2400,
'总蛋白质 (g)': 90,
'总脂肪 (g)': 80,
'总碳水化合物 (g)': 300,
'钙 (mg)': 800,
'铁 (mg)': 12,
'锌 (mg)': 12.5,
'维生素A (μg)': 800,
'维生素B1 (mg)': 1.4,
'维生素B2 (mg)': 1.4,
'维生素C (mg)': 100
}
# 标准化处理
df_normalized = (df - df.min()) / (df.max() - df.min())
ideal_normalized = (pd.DataFrame([ideal_values]) - df.min()) / (df.max() - df.min())
print(df_normalized)
print(ideal_normalized)
然后需要计算灰色关联度:

添加图片注释,不超过 140 字(可选)
代码:
# 定义分辨系数
rho = 0.5
# 计算差异
diff = np.abs(df_normalized - ideal_normalized)
delta_min = diff.min().min()
delta_max = diff.max().max()
# 计算灰关联度
gray_relation = (delta_min + rho * delta_max) / (diff + rho * delta_max)
gray_relation_scores = gray_relation.mean(axis=1)
print(gray_relation_scores)
4. 计算综合关联度
综合关联度可以根据各指标的权重进行计算,这里假设所有指标权重相等:
# 假设所有指标权重相等
weights = np.ones(len(data.keys())) / len(data.keys())
# 计算综合关联度
comprehensive_relation_score = (gray_relation * weights).sum(axis=1)
print(comprehensive_relation_score)
5. 综合评价
根据综合关联度对膳食进行排序,得出综合评价结果:‘
# 综合评价
evaluation_result = comprehensive_relation_score.sort_values(ascending=False)
print(evaluation_result)
下面就是第一问的第二小问分析过程:
根据第一小问的营养评价结果,确定哪些营养素不足或过剩,具体包括:
-
总能量:是否满足推荐的每日能量摄入标准。
-
宏量营养素:蛋白质、脂肪、碳水化合物的供能占比是否合理。
-
非产能营养素:钙、铁、锌、维生素A、维生素B1、维生素B2、维生素C的摄入量是否达标。
-
氨基酸评分:蛋白质的氨基酸组成是否合理。
然后调整方案,可以通过以下方式进行调整:
-
增加或减少食物种类:
-
增加:对于不足的营养素,通过增加相应食物种类来补充。例如,钙不足可以增加奶制品,维生素C不足可以增加水果。
-
减少:对于过剩的营养素,通过减少相应食物种类来控制。例如,脂肪过多可以减少油脂和高脂食物的摄入。
-
优化食物搭配:
-
多样化:确保每天摄入的食物种类大于12种,每周摄入的食物种类大于25种,覆盖五大类食物(谷类、蔬菜、水果、肉类、奶类、豆类、油脂)。
-
合理搭配:合理搭配不同种类的食物,以提高膳食的整体营养价值。例如,谷类和豆类搭配可以提高蛋白质的氨基酸评分。
-
调整餐次比:
-
能量分配:合理分配早餐、中餐和晚餐的能量摄入,推荐早餐占30%,中餐和晚餐各占35%。
具体可以用以下方式进行调整:
-
总能量调整:
-
如果总能量不足:增加能量密集型食物,如全谷类、坚果、油脂等。
-
如果总能量过多:减少高能量食物的摄入,增加低能量密度的蔬菜和水果。
-
宏量营养素调整:
-
蛋白质不足:增加富含蛋白质的食物,如鱼类、禽肉、豆制品。
-
脂肪过多:减少油炸食品、肥肉,增加鱼类、坚果等优质脂肪来源。
-
碳水化合物不足:增加全谷类食品,如燕麦、糙米。
-
非产能营养素调整:
-
钙不足:增加奶制品、豆制品、绿叶蔬菜。
-
铁不足:增加红肉、肝脏、深色绿叶蔬菜,搭配维生素C丰富的食物以促进铁吸收。
-
锌不足:增加海产品、肉类、坚果。
-
维生素不足:增加水果、蔬菜,特别是富含维生素A、B、C的食物。
最后,通过调整食谱,重新进行膳食营养评价,确认各项营养素是否达到推荐摄入量,能量供给是否合理,氨基酸评分是否提高。
2-4问后续更新

添加图片注释,不超过 140 字(可选)

其中更详细的思路、各题目思路、代码、讲解视频、成品论文及其他相关内容,可以点击下方名片获取哦!
相关文章:
2024电工杯B题保姆级分析完整思路+代码+数据教学
2024电工杯B题保姆级分析完整思路代码数据教学 B题题目:大学生平衡膳食食谱的优化设计及评价 接下来我们将按照题目总体分析-背景分析-各小问分析的形式来 总体分析: 题目要求对两份一日膳食食谱进行营养分析和调整,然后设计优化的平衡膳…...

基于svm的水果识别
1、程序界面介绍 该程序GUI界面包括待检测水果图片加载、检测结果输出、清空可视化框等。其中包括训练模型、加载图片、重置、识别检测按钮。 程序GUI界面 识别玉米识别西瓜 分类器识别水果基本原理: 由于每种水果的外形存在很大差异,比如西瓜与玉米&…...

【DevOps】深入理解 Nginx Location 块:配置示例与应用场景详解
目录 一、location 块的基本概念 二、location 块的语法 三、location 块的匹配方式 四、location 块的优先级 五、location 块的应用场景 六、location 块的嵌套 七、location 块的指令 八、示例配置 Nginx 是一个高性能的 Web 服务器和反向代理服务器,它广…...
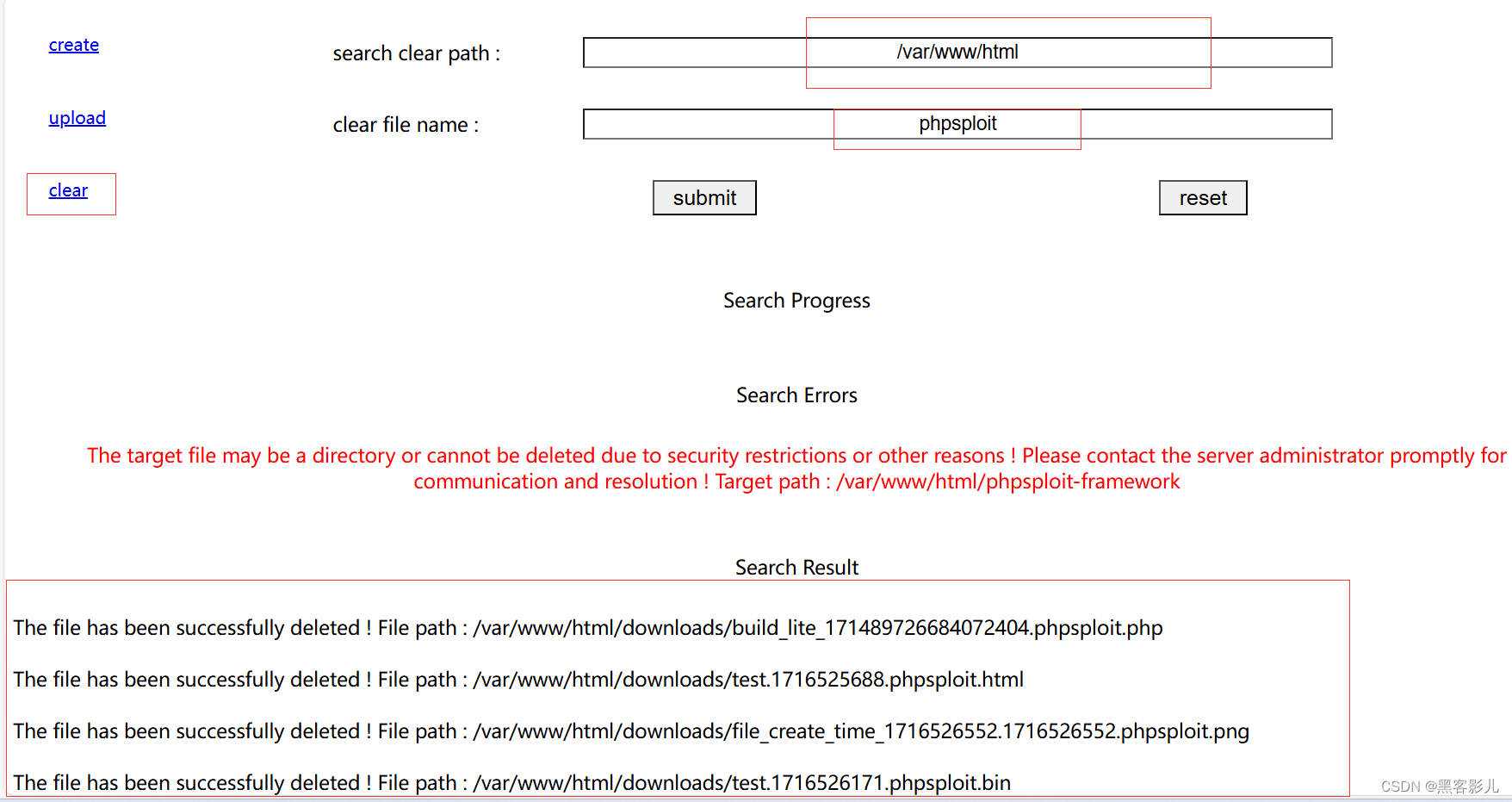
专业渗透测试 Phpsploit-Framework(PSF)框架软件小白入门教程(十一)
本系列课程,将重点讲解Phpsploit-Framework框架软件的基础使用! 本文章仅提供学习,切勿将其用于不法手段! 接上一篇文章内容,讲述如何进行Phpsploit-Framework软件的基础使用和二次开发。 我们,继续讲一…...

未来机器人的发展方向
未来机器人的发展方向是多元化且充满潜力的。以下是一些主要的发展方向: 人工智能与机器学习的集成:随着人工智能(AI)和机器学习(ML)技术的不断进步,机器人将变得更加智能化和自主化。这些技术将…...

美国硅谷高防服务器有哪些优势
美国硅谷高防服务器是位于美国硅谷的,具备高级防护能力的服务器。这种服务器针对网络安全威胁提供了增强的保护措施,以确保数据的安全和业务的连续性。Rak部落小编为您整理发布美国硅谷高防服务器有哪些优势。 具体介绍如下: 1. 安全性&#…...
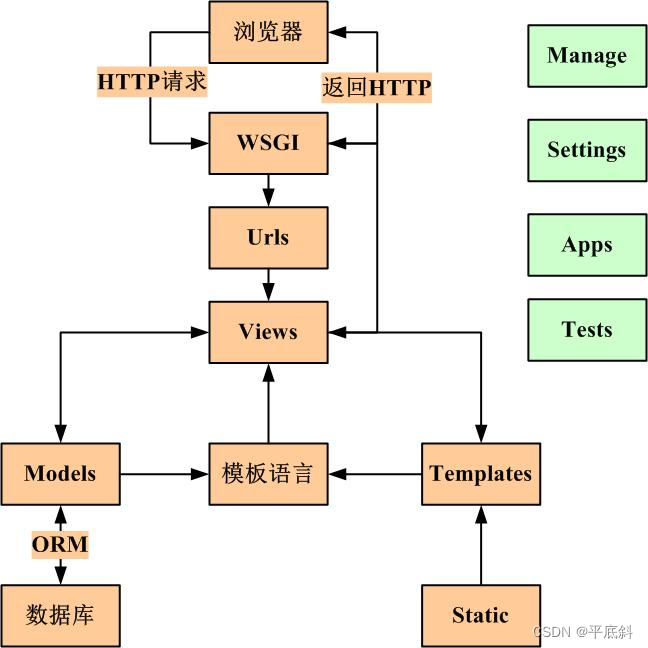
Django介绍:探索Python最受欢迎的Web框架
文章目录 Django是什么Django的核心特性1. MTV架构2. 自带的Admin后台管理系统3. ORM(对象关系映射)4. 强大的表单处理5. 完善的文档和活跃的社区 快速入门:使用Django创建一个简单的Web应用步骤1:安装Django步骤2:创建…...

【Unity Shader入门精要 第9章】更复杂的光照(四)
1. 透明度测试物体的阴影 对于物体有片元丢弃的情况,比如透明度测试或者后边会讲到的消融效果,使用默认的 ShadowCaster Pass 会产生问题,这是因为该Pass在生成阴影映射纹理时,没有考虑被丢弃的片元,而是使用完整的模…...

【软件工程】【23.10】p2
关键字: 软件复用技术、过程途径、特定需求是文档核心、数据字典条目、高内聚低耦合独立性、数据流图映射模块结构图、UML依赖、用例图关系、RUB迭代、程序规格说明等价类划分、有效性测试的目标、喷泉模型面向对象、软件验证过程、CMMI...

WPF--几种常用定时器Timer汇总
1.WPF中常用4种Timer: System.Windows.Threading.DispatcherTimer(UI操作线程) 这是一个基于WPF Dispatcher的计时器。它可以在指定的时间间隔内触发Tick事件,并在UI线程上执行回调函数,方便进行UI更新操作。 System.Timers.Timer 这是一个基…...

在vue中实现下载文件功能
实际操作为,在表格中 我们可以获取到文件的id,通过插槽就可以实现 <template #default"scope"><el-button type"text" click"handleDown(scope.row)"><span>下载</span></el-button> </…...
文件中海量数据的排序
文件中海量数据的排序 题目: 跟之前堆排序可以解决TopK问题一样,我们来看看归并排序会用来解决什么问题? 思路: 我们说归并排序是外排序。其实就是将数据分成一个个小段,在内存中进行排序,再拿出内存&am…...

java项目之视频网站系统源码(springboot+vue+mysql)
风定落花生,歌声逐流水,大家好我是风歌,混迹在java圈的辛苦码农。今天要和大家聊的是一款基于springboot的视频网站系统。项目源码以及部署相关请联系风歌,文末附上联系信息 。 项目简介: 视频网站系统的主要使用者管…...
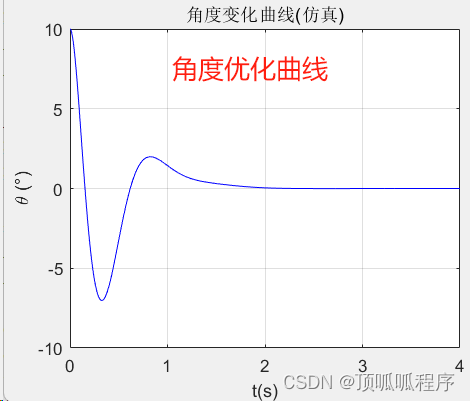
262 基于matlab的一级倒立摆仿真
基于matlab的一级倒立摆仿真,在对一级倒立摆进行数学建模的基础上,对模型进行线性化,得到其状态空间模型,利用二次型最优控制方法得出控制率。输出角度和位置优化曲线。程序已调通,可直接运行。 262 一级倒立摆仿真 状…...
智能无网远控再升级 向日葵Q2Pro升级版发布
无网或者内网设备也想要进行远程控制,是不是听上去有些天方夜谭了?其实这类特种设备的远程控制需求是非常强的,比如医疗/工控设备的远程运维、使用指导教学等等。 实际上,只要这类设备有屏幕,支持可视化的桌面操作&am…...

2024电工杯A题详细思路代码分析数学建模:园区微电网风光储协调优化配置
题目分析:园区微电网风光储协调优化配置 我们会先给出三个问题总体的分析,最后会详细分析问题一的建模和详细内容。 背景: 园区微电网由风光发电和主电网联合为负荷供电,为了尽量提高风光电量的负荷占比,需配置较高比…...
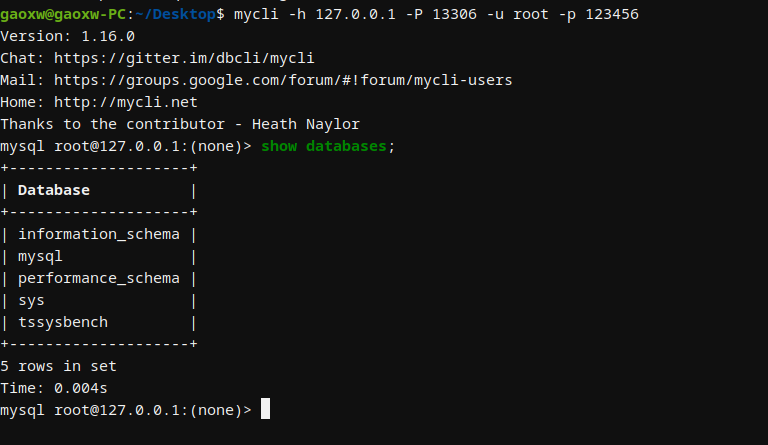
Docker搭建mysql性能测试环境
OpenEuler使用Docker搭建mysql性能测试环境 一、安装Docker二、docker安装mysql三、测试mysql连接 一、安装Docker 建立源文件vim /etc/yum.repos.d/docker-ce.repo增加内容[docker-ce-stable] nameDocker CE Stable - $basearch baseurlhttps://repo.huaweicloud.com/docker…...
关于开启直连v2rayn代理Fiddler Charles bp抓包失败问题
Fiddler 使用插件:proxy switchyomega 配置代理8888端口为fiddler && charles的监听端口 此时fiddler提示代理已更改点击变更捕获,这时不需要进行点击只需要开启上述插件即可抓到包并且国外代理,如果点击的话回自动更新为原来的ip 即…...

Python 爬虫编写入门
一、爬虫概述 网络爬虫(Web Crawler)或称为网络蜘蛛(Web Spider),是一种按照一定规则,自动抓取互联网信息的程序或者脚本。它们可以自动化地浏览网络中的信息,通过解析网页内容,提取…...
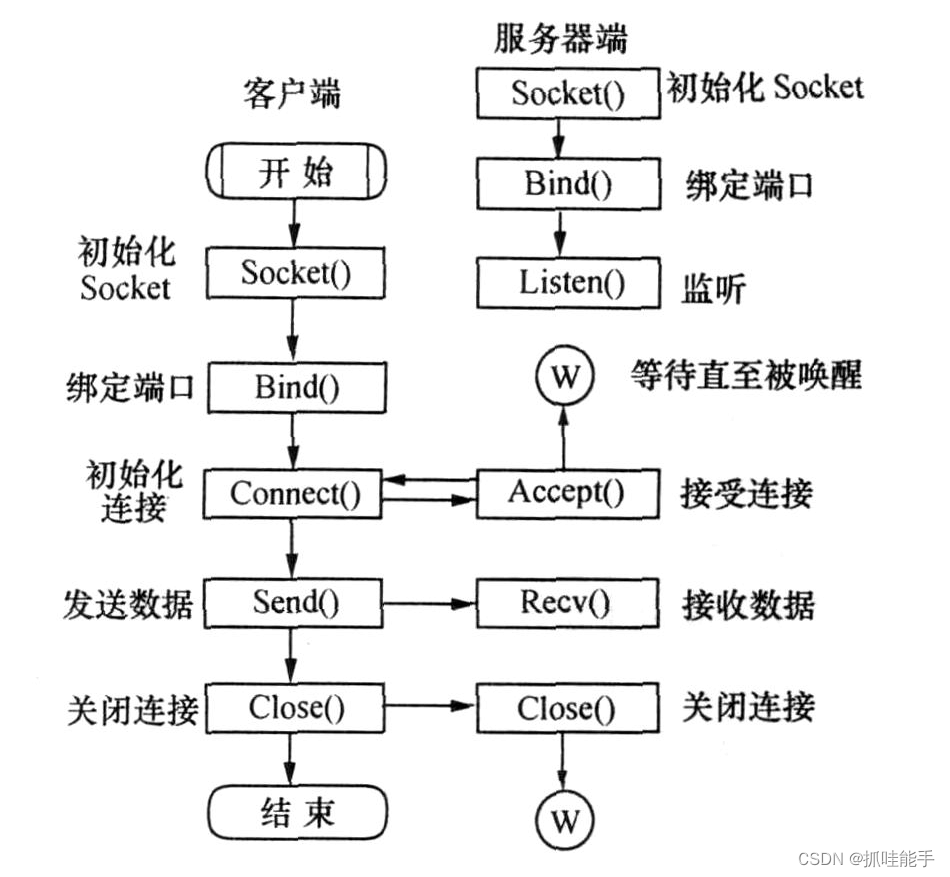
Linux网络编程(socket)
1. 概念 局域网和广域网 局域网:局域网将一定区域内的各种计算机、外部设备和数据库连接起来形成计算机通信的私有网络。广域网:又称广域网、外网、公网。是连接不同地区局域网或城域网计算机通信的远程公共网络。 IP(Internet Protocol&a…...

掌握SRA Tools:3步轻松处理高通量测序数据的高效工具
掌握SRA Tools:3步轻松处理高通量测序数据的高效工具 【免费下载链接】sra-tools SRA Tools 项目地址: https://gitcode.com/gh_mirrors/sr/sra-tools SRA Tools是处理NCBI Sequence Read Archive数据的核心工具集,让你可以轻松地下载、转换和分析…...

如何在macOS上轻松运行Windows应用:Whisky终极使用指南
如何在macOS上轻松运行Windows应用:Whisky终极使用指南 【免费下载链接】Whisky A modern Wine wrapper for macOS built with SwiftUI 项目地址: https://gitcode.com/gh_mirrors/wh/Whisky 想在Apple Silicon Mac上运行Windows软件,又不想安装笨…...

Win11Debloat:彻底解放Windows性能的智能优化革命
Win11Debloat:彻底解放Windows性能的智能优化革命 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes to declutter and custom…...

终极指南:如何用Word Checker轻松实现中英文拼写自动纠正
终极指南:如何用Word Checker轻松实现中英文拼写自动纠正 【免费下载链接】word-checker 🇨🇳🇬🇧Chinese and English word spelling corrector.(中文易错别字检测,中文拼写检测纠正。英文单词拼写校验工具…...

从霍金难题到MESI协议:原子操作性能瓶颈的硬件根源与优化实践
1. 项目概述:从霍金的难题到现代CPU的协同困境 如果你写过并发程序,或者研究过Linux内核的同步机制,你一定对“原子操作”和“缓存一致性”这两个词不陌生。我们常常被告知,原子操作是昂贵的,因为它需要“锁总线”或者…...

Desktop Postflop v0.2.7:高性能德州扑克GTO求解器架构设计与实现原理深度解析
Desktop Postflop v0.2.7:高性能德州扑克GTO求解器架构设计与实现原理深度解析 【免费下载链接】desktop-postflop [Development suspended] Advanced open-source Texas Holdem GTO solver with optimized performance 项目地址: https://gitcode.com/gh_mirrors…...

GD32F303外部中断实战:从按键消抖到中断优先级配置,一个例程全搞定
GD32F303外部中断实战:从按键消抖到中断优先级配置 第一次接触嵌入式开发时,最让我困惑的就是中断系统。记得当时用按键控制LED,明明代码逻辑没问题,LED却总是莫名其妙地闪烁。后来才发现是按键抖动导致多次触发中断。今天我们就以…...

Pydantic序列化避坑指南:model_dump vs dict、exclude/include高级用法与SerializeAsAny解析
Pydantic序列化避坑指南:model_dump vs dict、exclude/include高级用法与SerializeAsAny解析 在Python生态中,Pydantic已经成为数据验证和序列化的标杆工具。但许多开发者在实际使用中,常常会遇到一些看似简单却容易踩坑的序列化问题。本文将…...
)
TI C2000 DSP开发笔记:除了IQMath,F28377D的定点计算还有这些隐藏技巧(含FFT/FIR函数初探)
TI C2000 DSP开发笔记:F28377D定点计算高阶技巧与FFT/FIR实战解析 在嵌入式信号处理领域,定点计算一直是平衡性能与精度的关键选择。TMS320F28377D作为TI C2000系列中的高性能DSP控制器,其IQMath库提供的定点计算能力远超基础算术运算范畴。本…...

Android多媒体开发避坑:深入理解DMABUF机制与RK3588上的常见泄漏点
Android多媒体开发中的DMABUF机制解析与RK3588内存泄漏实战指南 在RK3588这类高性能芯片上开发视频编解码、相机等多媒体应用时,追求零拷贝性能优化往往会引入DMABUF的使用。然而,这种看似完美的解决方案背后隐藏着复杂的内存管理陷阱。本文将带您深入理…...