微服务项目收获和总结---第2,3天(分库分表思想,文章业务)
①分库分表思想
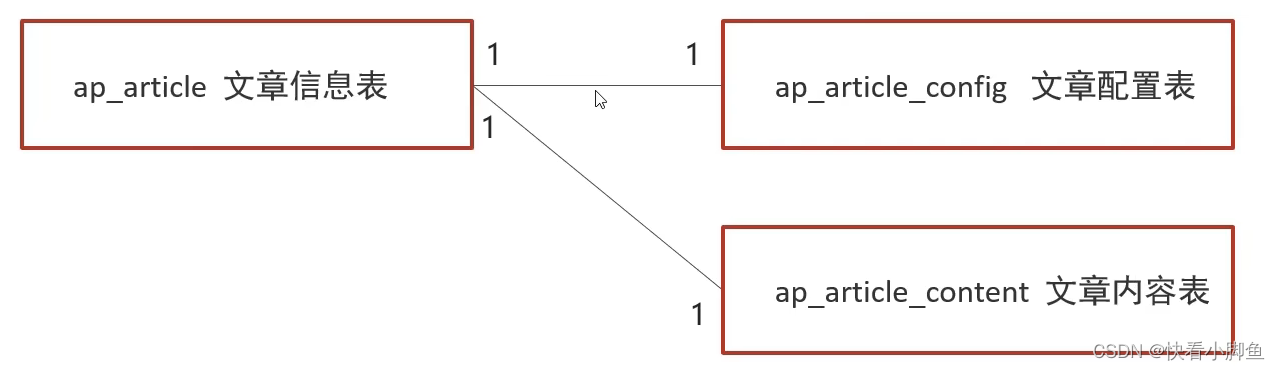
文章表一对一为什么要拆分?因为文章的内容会非常大,查询效率会很低,我们经常操作文章的基本信息,不会很经常查询文章内容。充分发挥高频数据的操作效率。

②freemarker和minIO
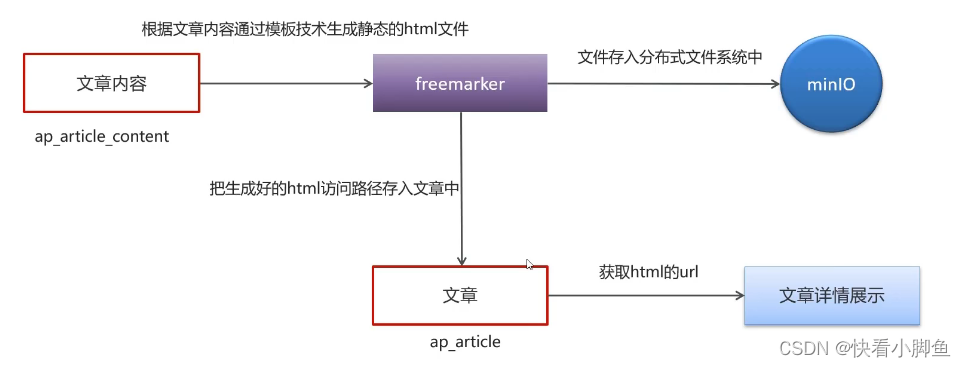
由于文章内容数据量过大,我们通过freemarker创建出静态页面并且上传到minIO中存储,前端访问时直接访问静态页面。
③自媒体素材管理
数据库表:

素材表:创作者可上传素材到其中,并且可以设置收藏与否
文章表:创作者所发布的文章的表,包括每一篇文章的用户ID,标题,内容,封面格式,频道,当前状态
文章素材关系表:文章与素材引用的关系表格
业务逻辑:!!!!非常重要要捋清楚
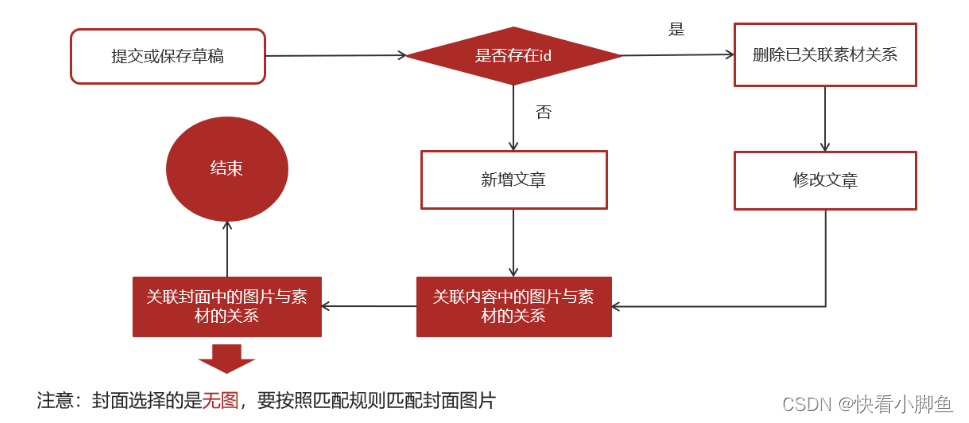
①你写一篇文章,可以选择保存草稿或者直接发布。
②如果你是保存草稿,先要判断该文章是否已经存在,疑问点:为什么草稿也要判断是否已经存在,因为还有编辑草稿的操作,当你把之前的草稿进行重新编辑时提交就要判断是否存在。如果是新增草稿,就新增一篇文章,并把内容中的图片与素材的关系表添加数据进行绑定,而且也要把封面的图片与素材进行绑定。然后就可以结束。
③如果是发布文章,因为文章也有编辑发布和直接发布操作。所以也是要判断是否已经存在该文章。如果是直接发布文章,则不会存在ID,然后把内容和封面的图片与素材的绑定关系添加到数据库的文章素材关系表中即可。但是如果是把已经发布的文章进行编辑然后再发布,首先也是要判断是否存在当然这一步判断肯定是存在的,然后就需要把旧版本的文章内容和封面所绑定的图片进行删除,然后再更新新的绑定关系。
代码实现:
首先要熟悉前端传过来的参数:

代码:
public class WmNewsServiceImpl extends ServiceImpl<WmNewsMapper,WmNews> implements WmNewsService {@Overridepublic ResponseResult findList(WmNewsPageReqDto dto) {//检查参数dto.checkParam();//分页查询IPage page =new Page(dto.getPage(),dto.getSize());LambdaQueryWrapper<WmNews> lambdaQueryWrapper = new LambdaQueryWrapper();//状态精确查询if(dto.getStatus() != null){lambdaQueryWrapper.eq(WmNews::getStatus,dto.getStatus());}//频道精确查询if(dto.getChannelId() != null){lambdaQueryWrapper.eq(WmNews::getChannelId,dto.getChannelId());}//时间范围查询if(dto.getBeginPubDate() != null && dto.getEndPubDate() != null){lambdaQueryWrapper.between(WmNews::getPublishTime,dto.getBeginPubDate(),dto.getEndPubDate());}//关键字模糊查询if (StringUtils.isNotBlank(dto.getKeyword())){lambdaQueryWrapper.like(WmNews::getTitle,dto.getKeyword());}//查询当前登录人的文章lambdaQueryWrapper.eq(WmNews::getUserId, WmThreadLocalUtil.getUser().getId());//按照发布时间倒序查询lambdaQueryWrapper.orderByDesc(WmNews::getPublishTime);//查询page = page(page, lambdaQueryWrapper);ResponseResult responseResult = new PageResponseResult(dto.getPage(), dto.getSize(), (int) page.getTotal());responseResult.setData(page.getRecords());//结果返回return responseResult;}@Overridepublic ResponseResult submitNews(WmNewsDto dto) {//条件判断,判断前端穿过来的值不为空if(dto == null || dto.getContent() == null){return ResponseResult.errorResult(AppHttpCodeEnum.PARAM_INVALID);}//保存或者修改文章,把基本信息保存到News文章对象中WmNews wmNews = new WmNews();BeanUtils.copyProperties(dto,wmNews);//图片的类型转换,把字符串中的封面图片路径提取出来,保存到Nes对象中if(dto.getImages() != null && dto.getImages().size()>0){String imgesStr = StringUtils.join(dto.getImages(), ",");wmNews.setImages(imgesStr);}//如果封面类型为自动,先把封面类型设置为空if(dto.getType().equals(WemediaConstants.WM_NEWS_TYPE_AUTO)){wmNews.setType(null);}//直接保存到数据库中,并且把图片和素材的关系删除saveOrUpdateNews(wmNews);//判断是否为草稿就可以直接返回,如果是,结束方法if(dto.getStatus().equals(WmNews.Status.NORMAL.getCode())){return ResponseResult.okResult(AppHttpCodeEnum.SUCCESS);}//不是草稿,保存文章内容图片与素材的关系//获取到内容中的图片信息List<String> materials = ectractUrlInfo(dto.getContent());//将正文中的图片信息+文章的ID,即正文图片与素材的绑定关系保存到数据库中saveRelativeInfoForContent(materials,wmNews.getId());//保存文章封面图片与素材的关系saveRelativeInfoForCover(dto,wmNews,materials);return ResponseResult.okResult(AppHttpCodeEnum.SUCCESS);}/*** 根据封面规则去存储* @param dto* @param wmNews* @param materials*///内容图片等于1 小于3 单图 type 1//大于3 多图 type 3//没图 无图 type 0//保存封面与素材的关系@Autowiredprivate WmMaterialMapper wmMaterialMapper;@Autowiredprivate WmNewsMaterialMapper wmNewsMaterialMapper;//保存或修改文章private void saveOrUpdateNews(WmNews wmNews) {//补全属性wmNews.setUserId(WmThreadLocalUtil.getUser().getId());wmNews.setCreatedTime(new Date());wmNews.setSubmitedTime(new Date());wmNews.setEnable((short) 1); //默认为上架if(wmNews.getId() == null){//保存save(wmNews);}else{//修改//删除文章图片与素材的关系wmNewsMaterialMapper.delete(Wrappers.<WmNewsMaterial>lambdaQuery().eq(WmNewsMaterial::getNewsId,wmNews.getId()));updateById(wmNews);}}//提取文章内容的图片信息private List<String> ectractUrlInfo(String content) {List<String> materials = new ArrayList<>();List<Map> maps = JSON.parseArray(content, Map.class);for (Map map : maps) {if(map.get("type").equals("image")){String imgUrl = (String) map.get("value");materials.add(imgUrl);}}return materials;}//处理文章内容图片与素材的关系private void saveRelativeInfoForContent(List<String> materials, Integer newsId) {saveRelativeInfo(materials,newsId, WemediaConstants.WM_CONTENT_REFERENCE);}//保存文章内容图片和素材的关系到数据库中private void saveRelativeInfo(List<String> materials, Integer newsId, Short type) {if(materials != null && !materials.isEmpty()){//通过图片查询素材的idList<WmMaterial> dbMaterials = wmMaterialMapper.selectList(Wrappers.<WmMaterial>lambdaQuery().in(WmMaterial::getUrl, materials));//判断素材是否有效if(dbMaterials == null || dbMaterials.size() == 0){//手动抛异常throw new CustomException(AppHttpCodeEnum.MATERIAL_REFERENCE_FALL);}if(materials.size() != dbMaterials.size()){throw new CustomException(AppHttpCodeEnum.MATERIAL_REFERENCE_FALL);}List<Integer> idList = dbMaterials.stream().map(WmMaterial::getId).collect(Collectors.toList());//批量保存wmNewsMaterialMapper.saveRelations(idList,newsId,type);}}//保存封面图片和素材的关系到数据库中private void saveRelativeInfoForCover(WmNewsDto dto, WmNews wmNews, List<String> materials) {List<String> images = dto.getImages();if(dto.getType().equals(WemediaConstants.WM_NEWS_TYPE_AUTO)){//多图if(materials.size() >= 3){wmNews.setType(WemediaConstants.WM_NEWS_MANY_IMAGE);images = materials.stream().limit(3).collect(Collectors.toList());}else if(materials.size() >1 && materials.size() <3){//单图wmNews.setType(WemediaConstants.WM_NEWS_SINGLE_IMAGE);images = materials.stream().limit(1).collect(Collectors.toList());}else{//无图wmNews.setType(WemediaConstants.WM_NEWS_NONE_IMAGE);}//修改文章if(images != null && images.size() > 0){wmNews.setImages(StringUtils.join(images,","));}updateById(wmNews);}if(images != null && images.size() > 0){saveRelativeInfo(images,wmNews.getId(),WemediaConstants.WM_COVER_REFERENCE);}}}
相关文章:
微服务项目收获和总结---第2,3天(分库分表思想,文章业务)
①分库分表思想 文章表一对一为什么要拆分?因为文章的内容会非常大,查询效率会很低,我们经常操作文章的基本信息,不会很经常查询文章内容。充分发挥高频数据的操作效率。 ②freemarker和minIO 由于文章内容数据量过大,…...
【全网最全】2024电工杯数学建模A题21页初步参考论文+py代码+保奖思路等(后续会更新)
您的点赞收藏是我继续更新的最大动力! 一定要点击如下的卡片链接,那是获取资料的入口! 【全网最全】2024电工杯数学建模A题21页初步参考论文py代码保奖思路等(后续会更新成品论文)「首先来看看目前已有的资料&#x…...
)
怎么通过OpenAI API调用其多模态大模型(GPT-4o)
现在只要有额度,大家都可以调用OpenAI的多模态大模型了,例如GPT-4o和GPT-4 Turbo,我一年多前总结过一些OpenAI API的用法,发现现在稍微更新了一下。主要参考了这里:https://platform.openai.com/docs/guides/vision 其…...
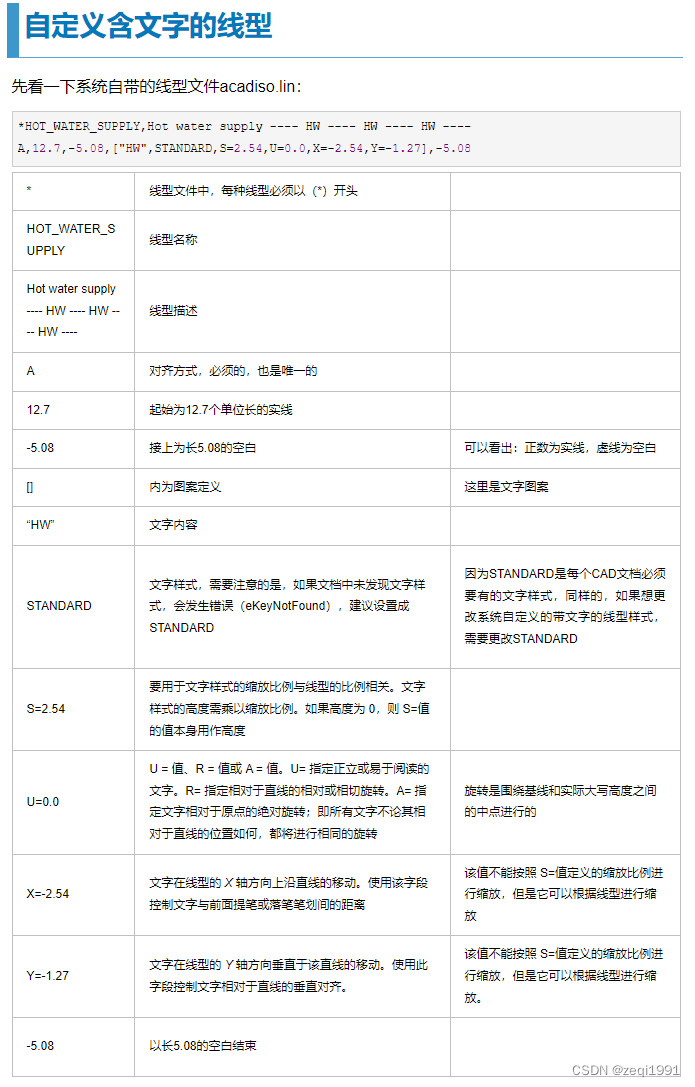
自定义文字线性
...

robosuite导入自定义机器人
目录 目的:案例一:成果展示具体步骤:URDF文件准备xml文件生成xml修改机器人构建 目的: 实现其他标准/非标准机器人的构建 案例一: 成果展示 添加机器人JAKA ZU 7 这个模型 具体步骤: URDF文件准备 从…...
四天学会JS高阶(学好vue的关键)——构造函数数据常用函数(理论+实战)(第二天)
一、对象创建引发构造函数产生 1.1 创建对象三种方式: 利用对象字面量创建对象 const obj {name: 佩奇}注:对象字面量的由来:即它是直接由字面形式(由源代码直接)创建出来的对象,而不是通过构造函数或者…...
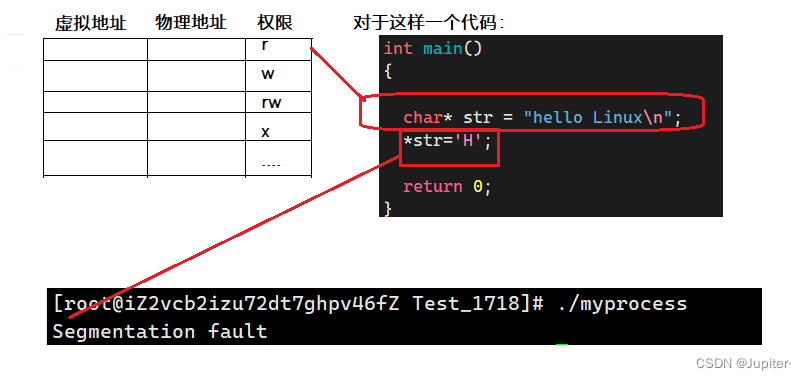
【Linux学习】进程地址空间与写时拷贝
文章目录 Linux进程内存布局图:内存布局的验证 进程地址空间写时拷贝 Linux进程内存布局图: 地址空间的范围,在32位机器上是2^32比特位,也就是[0,4G]。 内存布局的验证 代码验证内存布局: 验证代码: #include<s…...

Git远程控制
文章目录 1. 创建仓库1.1 Readme1.2 Issue1.3 Pull request 2. 远程仓库克隆3. 推送远程仓库4. 拉取远程仓库5. 配置Git.gitignore配置别名 使用GitHub可以,采用Gitee也行 1. 创建仓库 1.1 Readme Readme文件相当于这个仓库的说明书,gitee会初始化2两份…...
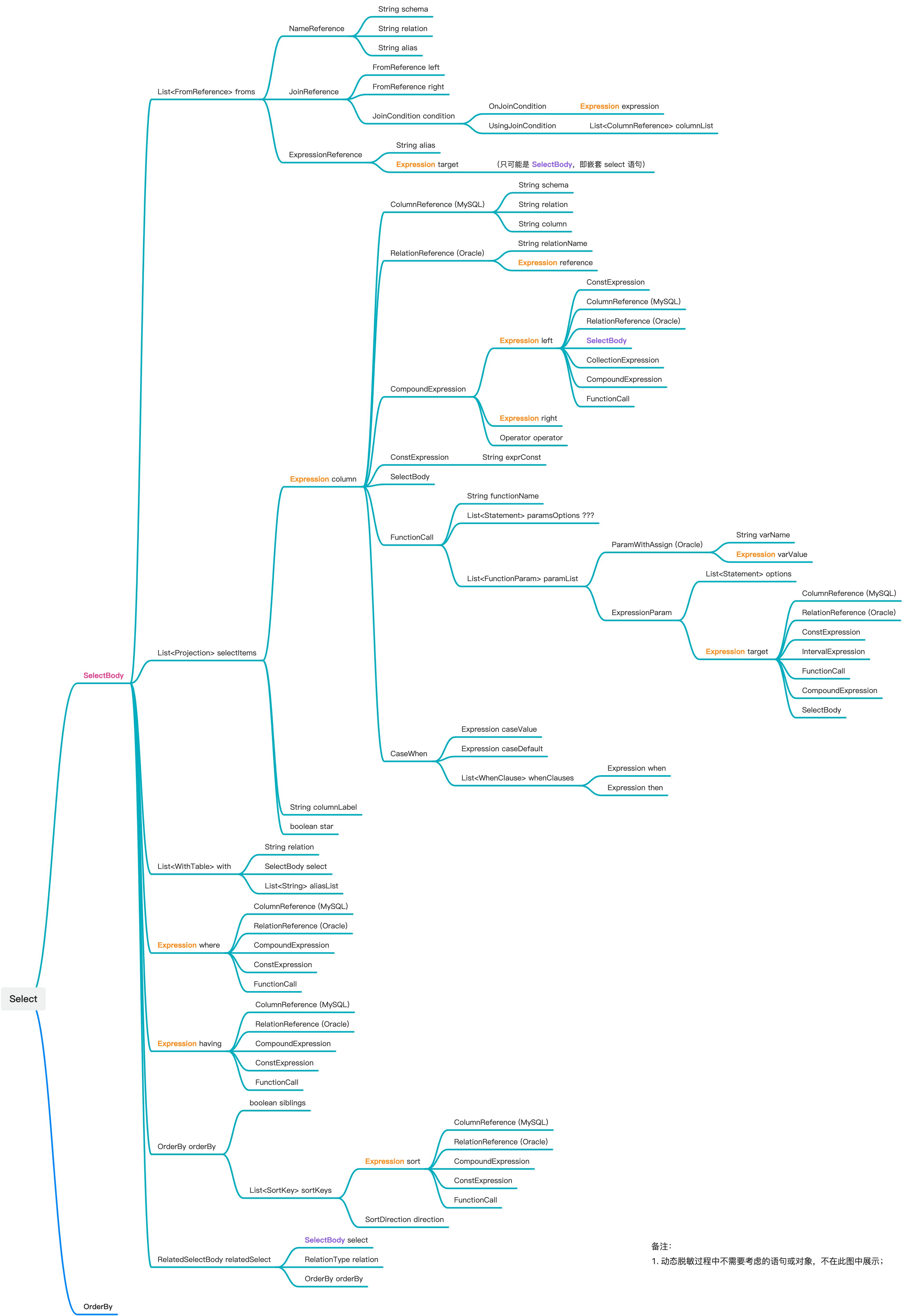
怎样从SQL中分析和提取访问的字段信息?| OceanBase实践
当执行任意一条SELECT SQL语句时,我们如何能够分析出所访问的字段信息,并进一步判断结果集中的每一列数据具体来自于哪些数据库、表以及表中的哪些字段呢?本文将会详细阐述针对此问题的技术解决方案。 应用场景 从 SQL 中解析访问的原始字段…...
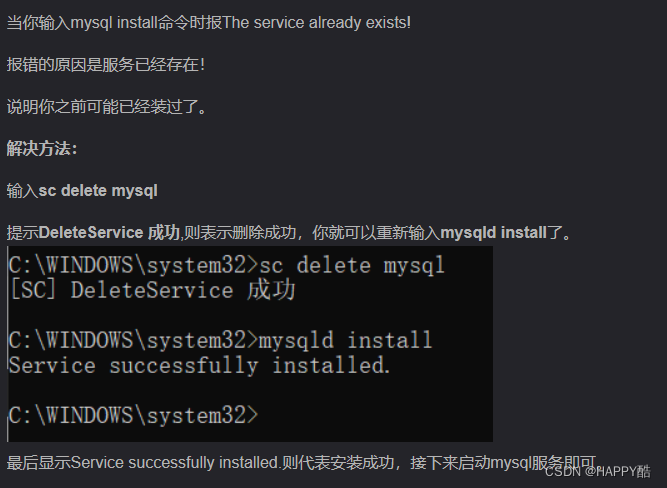
MySQL 服务无法启动
常见原因: 检查端口占用: 使用命令行工具(如netstat)来检查3306端口是否已被其他程序占用,输入netstat -ano(Windows)或netstat -tulnp | grep 3306(Linux/Mac)来查找3306端口的占用情况。如果…...

Python贪心算法
贪心算法(Greedy Algorithm)是一种常见的算法设计策略,它在每一步选择当前最优解,希望通过局部最优解最终得到全局最优解。贪心算法通常适用于满足一些特定条件的问题,例如货币找零、活动选择、任务调度等。贪心算法的…...

牛客网刷题 | BC85 牛牛学数列3
目前主要分为三个专栏,后续还会添加: 专栏如下: C语言刷题解析 C语言系列文章 我的成长经历 感谢阅读! 初来乍到,如有错误请指出,感谢! 描述 牛牛准备继续进阶&…...
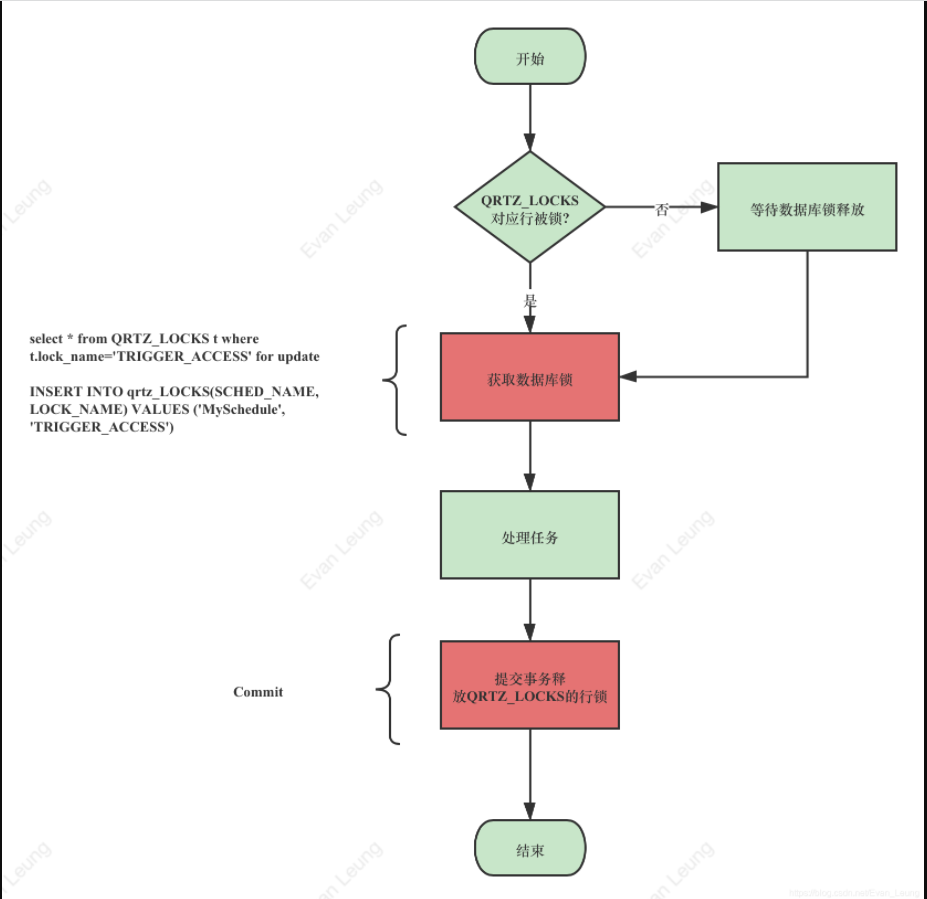
quartz定时任务
Quartz 数据结构 quartz采用完全二叉树:除了最后一层每一层节点都是满的,而且最后一层靠左排列。 二叉树节点个数规则:每层从左开始,第一层只有一个,就是2的0次幂,第二层两个就是2的1次幂,第三…...
——选择结构与循环结构)
Python基础学习笔记(五)——选择结构与循环结构
目录 程序的组织结构条件选择结构1. 单分支结构2. 双分支结构3. 多分支结构4. 嵌套(分支)结构5. 无内容执行6. 条件表达式 循环结构1. 可迭代对象2. range()函数3. for循环语句4. while循环语句5. 结束语句 程序的组织结构 程序的组织结构主要有以下三种…...

Vue插槽solt如何传递具名插槽的数据给子组件?
在Vue中,你可以通过作用域插槽(scoped slots)来传递数据给子组件。这同样适用于具名插槽。首先,你需要在子组件中定义一个具名插槽,并通过v-slot指令传递数据。例如: 子组件(ChildComponent.vu…...
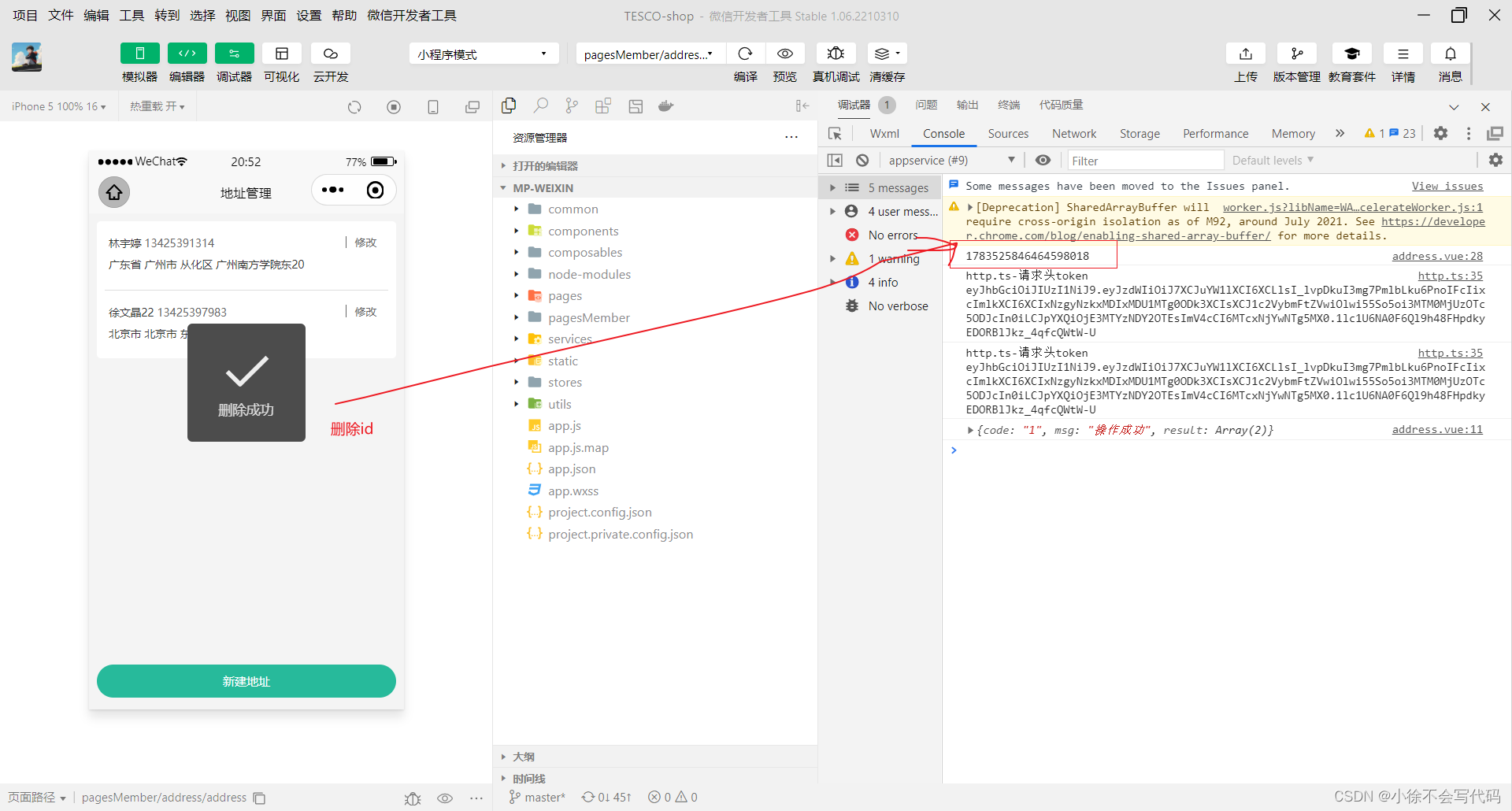
小程序-收货地址管理模块实现
页面结构代码: address-form.vue --->新建地址和修改地址页面 <template><view class"content"><form><!-- 表单内容 --><view class"form-item"><text class"label">收货人</text>…...
)
【星海随笔】微信小程序(三)
网络数据请求 1.小程序中网络数据请求的限制 出于安全性方面的考虑,小程序官方对 数据接口的请求 做出了如下 两个限制: ① 只能请求 HTTPS 类型的接口 ② 必须将 接口的域名 添加到 信任列表 中 微信小程序只能请求 https 类型的接口 且需要请求的域名必须提前进行设置后,才可…...
pip(包管理器) for Python
pip是什么 pip是Python的包安装程序,即python包管理器。您可以使用 pip 从Python包索引和其他索引安装包。 1. pip 安装 python 包 pip install 包名 例如:pip install pymssql : 使用pip安装数据库驱动包 pymssql 2.pip 卸载 python 包 pi…...

Ubuntu上安装Maven
在Ubuntu上安装Maven的步骤如下: 更新包索引: sudo apt update 安装Maven: sudo apt install maven 验证安装是否成功: mvn -version 以上步骤将会安装Maven并添加到系统路径中,你可以通过运行mvn -version来验…...
java中使用svnkit实现文件的版本管理
java中使用svnkit实现文件的版本管理 一、引入svnKit依赖二、初始化仓库工厂类二、使用svnkit创建本地存储仓库三、svn基本原子操作四、通过原子方法实现简单svn相应操作 一、引入svnKit依赖 <dependency><groupId>org.tmatesoft.svnkit</groupId><artifa…...

免费开源AMD Ryzen调试工具终极指南:从零掌握SMUDebugTool完整使用教程
免费开源AMD Ryzen调试工具终极指南:从零掌握SMUDebugTool完整使用教程 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目…...

Unlock Music Electron:终极开源音乐解密解决方案,打破平台枷锁
Unlock Music Electron:终极开源音乐解密解决方案,打破平台枷锁 【免费下载链接】unlock-music-electron Unlock Music Project - Electron Edition 在Electron构建的桌面应用中解锁各种加密的音乐文件 项目地址: https://gitcode.com/gh_mirrors/un/u…...

SystemVerilog驱动强度详解:从概念到工程实践
1. 项目概述:为什么需要关注驱动强度?在数字电路设计和验证领域,SystemVerilog 是我们描述硬件行为、构建测试平台的核心语言。很多工程师,尤其是刚入行的朋友,往往把精力集中在always块、interface、UVM这些“大件”上…...

项目管理专题会议圆满举办丨AI+数据驱动:重塑项目管理全链路
2026 年 5 月 20 日,由深圳市软件行业协会、易趋 、腾讯TAPD主办的第十四期项目管理专题活动 ——AI 如何重塑项目管理全链路主题沙龙在深圳圆满举行。来自IT、制造、金融等领域的PMO、项目管理专家、技术实践者,以及CIO/CTO等高层决策者共同探讨 AI 时代…...

RTX166任务调度:K_IVL与K_TMO事件机制详解
1. RTX166任务调度中的K_IVL与K_TMO事件机制解析在RTX166实时操作系统中,os_wait函数提供的K_IVL和K_TMO事件是任务调度的核心机制。这两个看似相似的延时控制参数,在实际应用中却有着截然不同的行为模式。作为深耕嵌入式领域十余年的开发者,…...

工业IoT实战:边缘计算+AI在电机预测性维护中的系统架构设计
前言工业物联网(IIoT)场景下,预测性维护(Predictive Maintenance)是AI技术落地价值最明确的方向之一。本文以杭州沃伦森(WARENSEN)电气的AIESA电机智能安康系统为案例,分析其在边缘计…...

NotebookLM关键词提取结果不一致?权威测试报告揭示模型版本、文档编码、上下文窗口三重耦合陷阱
更多请点击: https://kaifayun.com 第一章:NotebookLM关键词提取 NotebookLM 是 Google 推出的基于用户文档构建的 AI 助手,其核心能力之一是自动从上传的文本中识别并提取关键语义单元——即关键词(Keywords)。这些关…...

Linux下BepInEx Mod部署原理与实战指南
1. 为什么Linux玩家总在Mod部署上卡住?——BepInEx不是“装上就能用”的玩具 BepInEx、Unity、Linux、Mod框架——这四个词凑在一起,对很多刚从Windows转战Linux的玩家或Mod开发者来说,几乎等于一道默认关闭的门。我第一次在Ubuntu 22.04上尝…...
线上服务卡顿?从一次ES写入超时故障,复盘我是如何调整`refresh_interval`和`translog`参数的
线上服务卡顿?一次Elasticsearch写入超时故障的深度调优实战 凌晨三点,监控系统突然告警——核心服务的API响应时间突破5秒阈值。快速排查发现,所有慢请求都卡在了日志写入环节。作为运维负责人,我立即意识到这又是一次Elasticsea…...

3步解锁安全镜像烧录:Balena Etcher让系统部署零风险
3步解锁安全镜像烧录:Balena Etcher让系统部署零风险 【免费下载链接】etcher Flash OS images to SD cards & USB drives, safely and easily. 项目地址: https://gitcode.com/GitHub_Trending/et/etcher 还在为制作系统启动盘而烦恼吗?你是…...