Spark项目实训(一)
目录
实验任务一:计算级数
idea步骤分步:
完整代码:
linux步骤分布:
实验任务二:统计学生成绩
idea步骤分布:
完整代码:
linux步骤分步:
实验任务一:计算级数
请用脚本的方式编程计算并输出下列级数的前 n 项之和 Sn,直到 Sn 刚好大于或等于 q 为止,其中 q 为大于 0 的整数,其值通过键盘输 入。
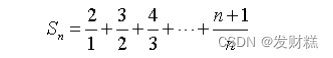
例如,若 q 的值为 50.0,则输出应为:Sn=50.416695。请将源文件 保存为 exercise2-1.scala,在 REPL 模式下测试运行,测试样例: q=1 时,Sn=2;q=30 时,Sn=30.891459;q=50 时,Sn=50.416695。
idea步骤分步:
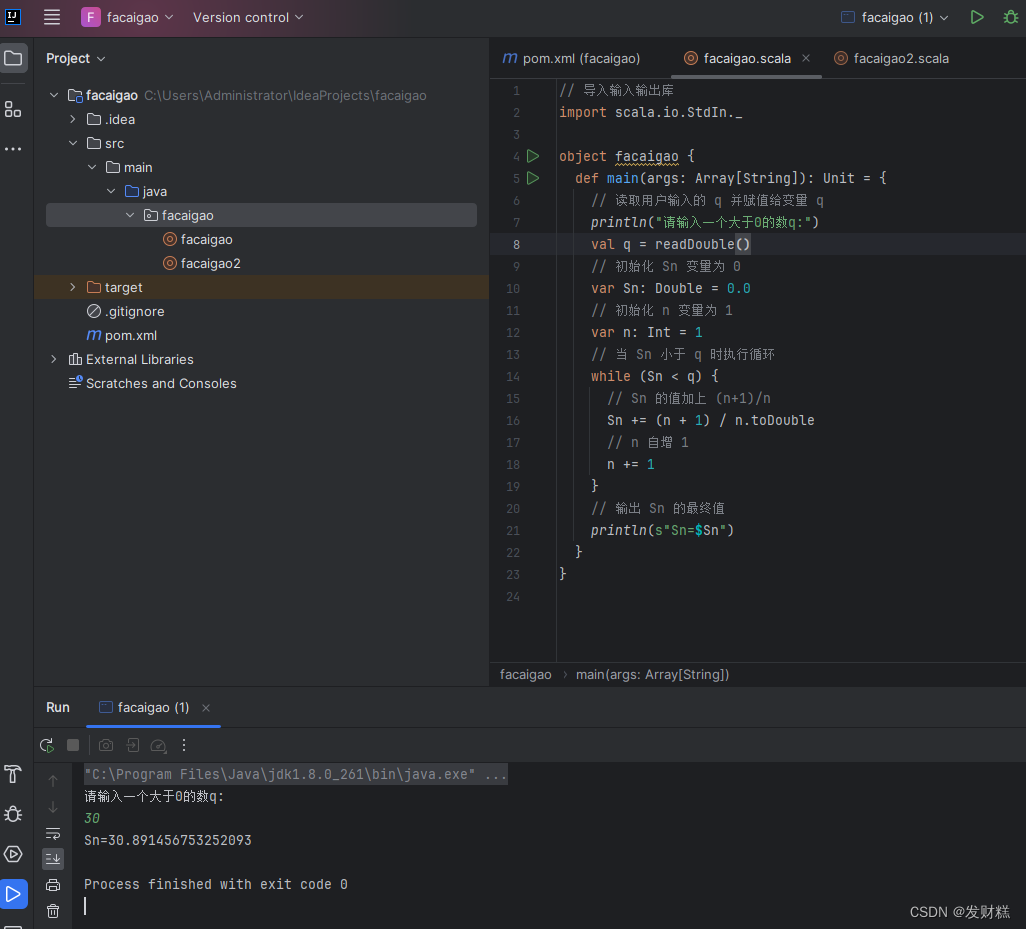
// 导入输入输出库
import scala.io.StdIn._
// 导入输入输出库
import scala.io.StdIn._// 初始化 Sn 变量为 0
// 初始化 Sn 变量为 0
var Sn: Double = 0.0// 初始化 n 变量为 1
![]()
// 读取用户输入的 q 并赋值给变量 q
val q = StdIn.readInt()
// 读取用户输入的 q 并赋值给变量 qprintln("请输入一个大于0的数q:")val q = readDouble()// 当 Sn 小于 q 时执行循环
// 当 Sn 小于 q 时执行循环while (Sn < q) {}// Sn 的值加上(n+1)/n
// Sn 的值加上 (n+1)/nSn += (n + 1) / n.toDouble// n 自增 1
// n 自增 1n += 1// 输出 Sn 的最终值
// 输出 Sn 的最终值println(s"Sn=$Sn")完整代码:
// 导入输入输出库
import scala.io.StdIn._object facaigao {def main(args: Array[String]): Unit = {// 读取用户输入的 q 并赋值给变量 qprintln("请输入一个大于0的数q:")val q = readDouble()// 初始化 Sn 变量为 0var Sn: Double = 0.0// 初始化 n 变量为 1var n: Int = 1// 当 Sn 小于 q 时执行循环while (Sn < q) {// Sn 的值加上 (n+1)/nSn += (n + 1) / n.toDouble// n 自增 1n += 1}// 输出 Sn 的最终值println(s"Sn=$Sn")}
}
linux步骤分布:
1、开启 scala 命令行:
[root@master ~]# su - hadoop
[hadoop@master ~]$ cd /usr/local/src/scala/bin
[hadoop@master bin]$ ./scala
2、执行下面的代码:
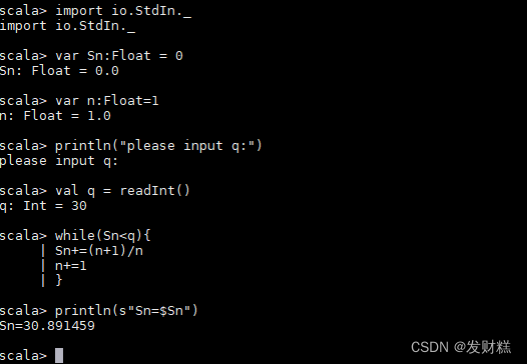
// 导入输入输出库
scala> import io.StdIn._
// 初始化 Sn 变量为 0
scala> var Sn:Float = 0
// 初始化 n 变量为 1
scala> var n:Float=1
// 输出提示信息让用户输入 q
scala> println("please input q:")
// 读取用户输入的 q 并赋值给变量 q
scala> val q = readInt()
// 当 Sn 小于 q 时执行循环
scala> while(Sn<q){
| Sn+=(n+1)/n // Sn 的值加上(n+1)/n
| n+=1 // n 自增 1
| }
// 输出 Sn 的最终值
scala> println(s"Sn=$Sn")
其中 val q = readInt()表示在 linux shell 终端输入 q 的 值,执行代码之后会一直监听窗口,等待键盘输入 q 的值,这里设 置了 q=30。
最后输入 :q 退出 scala shell
实验任务二:统计学生成绩
学生的成绩清单格式如下所示,第一行为表头,各字段意思分别为 学号、性别、课程名 1、课程名 2 等,后面每一行代表一个学生的 信息,各字段之间用空白符隔开, 给定任何一个如上格式的清单(不同清单里课程数量可能不一样), 要求尽可能采用函数式编程,统计出各门课程的平均成绩,最低成 绩,和最高成绩;另外还需按男女同学
Id gender Math English Physics Science
301610 male 72 39 74 93
301611 male 75 85 93 26
301612 female 85 79 91 57
301613 female 63 89 61 62
301614 male 72 63 58 64
301615 male 99 82 70 31
301616 female 100 81 63 72
301617 male 74 100 81 59
301618 female 68 72 63 100
301619 male 63 39 59 87
301620 female 84 88 48 48
301621 male 71 88 92 46
301622 male 82 49 66 78
301623 male 63 80 83 88
301624 female 86 80 56 69
301625 male 76 69 86 49
301626 male 91 59 93 51
301627 female 92 76 79 100
301628 male 79 89 78 57
301629 male 85 74 78 80分开,分别统计各门课程的 平均成绩,最低成绩,和最高成绩。
桌面创建数据文件名字为1.txt
Id gender Math English Physics
301610 male 80 64 78
301611 female 65 87 58
301612 female 44 71 77
301613 female 66 71 91
301614 female 70 71 100
301615 male 72 77 72
301616 female 73 81 75
301617 female 69 77 75
301618 male 73 61 65
301619 male 74 69 68
301620 male 76 62 76
301621 male 73 69 91
301622 male 55 69 61
301623 male 50 58 75
301624 female 63 83 93
301625 male 72 54 100
301626 male 76 66 73
301627 male 82 87 79
301628 female 62 80 54
301629 male 89 77 72桌面创建数据文件名字为2.txt
idea步骤分布:
// 从文件中读取数据
val inputFile = scala.io.Source.fromFile("C:\\Users\\Administrator\\Desktop\\1.txt")
val originalData =inputFile.getLines.map{_.split("\\s+")}.toList// 获取课程名和学生数据
val courseNames = originalData.head.drop(2) // 将第一行数据中//前两列去除,其余作为课程名
val allStudents = originalData.tail // 剩余行数据为所有学生数据val courseNum = courseNames.length // 课程数量// 定义统计函数
def statistc(lines: List[Array[String]]) = {// 遍历每门课程,计算总分、最低分和最高分(for (i <- 2 to courseNum+1) yield {val temp = lines map { elem => elem(i).toDouble } //获取每门课程的成绩数据(temp.sum, temp.min, temp.max) // 计算总分、最低分和最高分}) map { case (total, min, max) => (total / lines.length,min, max) } // 计算平均分}// 输出结果函数
def printResult(theresult: Seq[(Double, Double, Double)]) {// 将课程名和结果对应输出(courseNames zip theresult) foreach {case (course, result) => println(f"${course + ":"}%-10s${result._1}%5.2f${result._2}%8.2f${result._3}%8.2f")}}// 统计全体学生数据并输出结果
val allResult = statistc(allStudents)println("course average min max")printResult(allResult)// 按性别划分数据
val (maleLines, femaleLines) = allStudents partition { _(1)== "male" }
// 统计男学生数据并输出结果
val maleResult = statistc(maleLines)// 统计女学生数据并输出结果
val femaleResult = statistc(femaleLines)println("course average min max")printResult(femaleResult)完整代码:
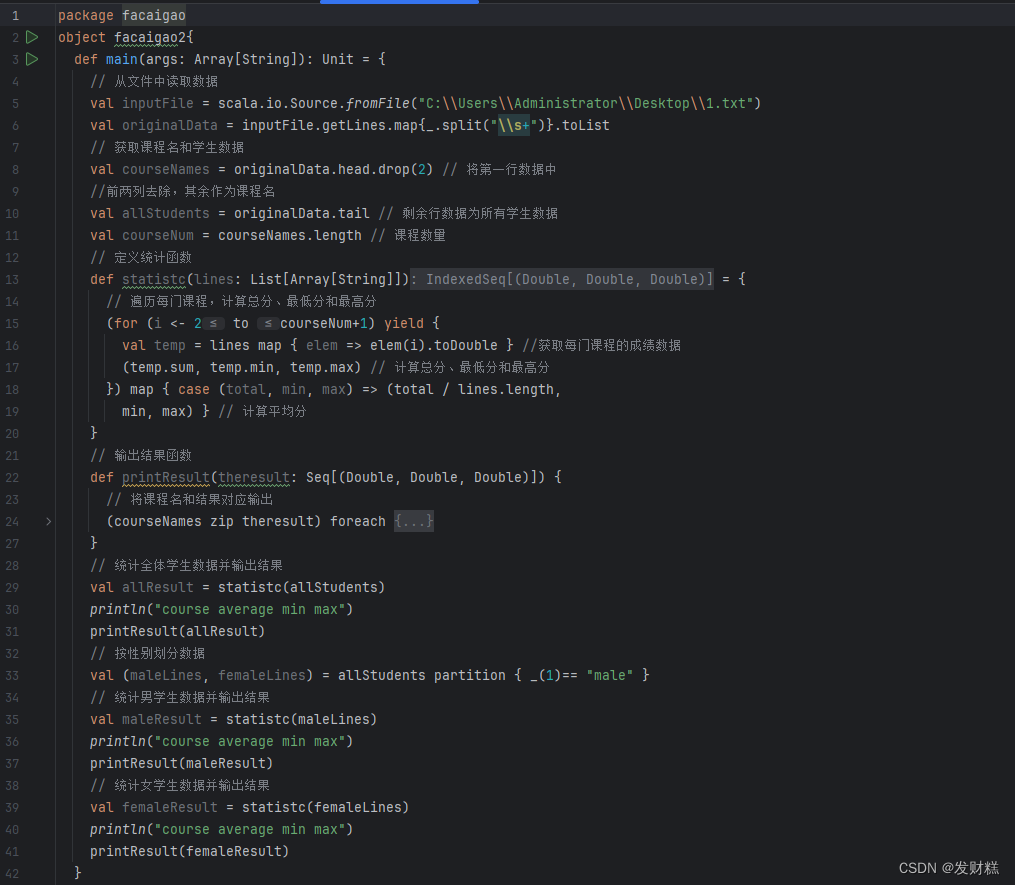
package facaigaoobject facaigao2{def main(args: Array[String]): Unit = {// 从文件中读取数据val inputFile = scala.io.Source.fromFile("C:\\Users\\Administrator\\Desktop\\1.txt")val originalData = inputFile.getLines.map{_.split("\\s+")}.toList// 获取课程名和学生数据val courseNames = originalData.head.drop(2) // 将第一行数据中//前两列去除,其余作为课程名val allStudents = originalData.tail // 剩余行数据为所有学生数据val courseNum = courseNames.length // 课程数量// 定义统计函数def statistc(lines: List[Array[String]]) = {// 遍历每门课程,计算总分、最低分和最高分(for (i <- 2 to courseNum+1) yield {val temp = lines map { elem => elem(i).toDouble } //获取每门课程的成绩数据(temp.sum, temp.min, temp.max) // 计算总分、最低分和最高分}) map { case (total, min, max) => (total / lines.length,min, max) } // 计算平均分}// 输出结果函数def printResult(theresult: Seq[(Double, Double, Double)]) {// 将课程名和结果对应输出(courseNames zip theresult) foreach {case (course, result) => println(f"${course + ":"}%-10s${result._1}%5.2f${result._2}%8.2f${result._3}%8.2f")}}// 统计全体学生数据并输出结果val allResult = statistc(allStudents)println("course average min max")printResult(allResult)// 按性别划分数据val (maleLines, femaleLines) = allStudents partition { _(1)== "male" }// 统计男学生数据并输出结果val maleResult = statistc(maleLines)println("course average min max")printResult(maleResult)// 统计女学生数据并输出结果val femaleResult = statistc(femaleLines)println("course average min max")printResult(femaleResult)}
} 

样例1运行结果
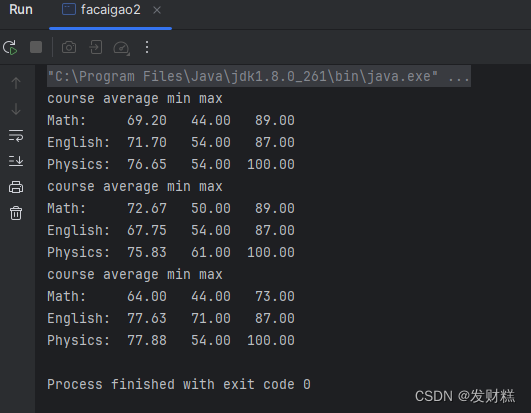
样例2运行结果:

linux步骤分步:
创建代码文件夹
[hadoop@master myscalacode]$ cd /
[hadoop@master /]$ sudo mkdir myscalacode2创建数据源文件
[hadoop@master /]$ cd myscalacode2
[hadoop@master myscalacode2]$ sudo vim test.txt按 i 进入编辑模式,输入以下测试样例 1或者测试样例 2 的数据 (这里以测试样例 1 举例)
样例1
Id gender Math English Physics
301610 male 80 64 78
301611 female 65 87 58
301612 female 44 71 77
301613 female 66 71 91
301614 female 70 71 100
301615 male 72 77 72
301616 female 73 81 75
301617 female 69 77 75
301618 male 73 61 65
301619 male 74 69 68
301620 male 76 62 76
301621 male 73 69 91
301622 male 55 69 61
301623 male 50 58 75
301624 female 63 83 93
301625 male 72 54 100
301626 male 76 66 73
301627 male 82 87 79
301628 female 62 80 54
301629 male 89 77 72样例2
Id gender Math English Physics Science
301610 male 72 39 74 93
301611 male 75 85 93 26
301612 female 85 79 91 57
301613 female 63 89 61 62
301614 male 72 63 58 64
301615 male 99 82 70 31
301616 female 100 81 63 72
301617 male 74 100 81 59
301618 female 68 72 63 100
301619 male 63 39 59 87
301620 female 84 88 48 48
301621 male 71 88 92 46
301622 male 82 49 66 78
301623 male 63 80 83 88
301624 female 86 80 56 69
301625 male 76 69 86 49
301626 male 91 59 93 51
301627 female 92 76 79 100
301628 male 79 89 78 57
301629 male 85 74 78 80
添加完毕之后按 Esc 键退出编辑模式,输入“:wq”保存退出
新建 scala 文件并编写代码
[hadoop@master myscalacode2]$ sudo vim scoreReport.scalai 进入编辑模式,编写以下代码
object scoreReport {def main(args: Array[String]) {// 从文件中读取数据val inputFile = scala.io.Source.fromFile("test.txt")val originalData =
inputFile.getLines.map{_.split("\\s+")}.toList// 获取课程名和学生数据val courseNames = originalData.head.drop(2) // 将第一行数据中
前两列去除,其余作为课程名val allStudents = originalData.tail // 剩余行数据为所有学生数
据val courseNum = courseNames.length // 课程数量// 定义统计函数def statistc(lines: List[Array[String]]) = {// 遍历每门课程,计算总分、最低分和最高分(for (i <- 2 to courseNum+1) yield {val temp = lines map { elem => elem(i).toDouble } //
获取每门课程的成绩数据(temp.sum, temp.min, temp.max) // 计算总分、最低分和
最高分}) map { case (total, min, max) => (total / lines.length,
min, max) } // 计算平均分}// 输出结果函数def printResult(theresult: Seq[(Double, Double, Double)]) {// 将课程名和结果对应输出(courseNames zip theresult) foreach {case (course, result) => println(f"${course + ":"}%-
10s${result._1}%5.2f${result._2}%8.2f${result._3}%8.2f")}}// 统计全体学生数据并输出结果val allResult = statistc(allStudents)println("course average min max")printResult(allResult)// 按性别划分数据val (maleLines, femaleLines) = allStudents partition { _(1)
== "male" }// 统计男学生数据并输出结果val maleResult = statistc(maleLines)println("course average min max")printResult(maleResult)// 统计女学生数据并输出结果val femaleResult = statistc(femaleLines)println("course average min max")printResult(femaleResult)}
}编译并运行程序
[hadoop@master myscalacode2]$ sudo /usr/local/src/scala/bin/scalac
scoreReport.scala
[hadoop@master myscalacode2]$ ls[hadoop@master myscalacode2]$ sudo /usr/local/src/scala/bin/scala
scoreReport样例 1 的统计结果输出为:
course average min max
Math: 69.20 44.00 89.00
English: 71.70 54.00 87.00
Physics: 76.65 54.00 100.00
course average min max (males)
Math: 72.67 50.00 89.00
English: 67.75 54.00 87.00
Physics: 75.83 61.00 100.00
course average min max (females)
Math: 64.00 44.00 73.00
English: 77.63 71.00 87.00
Physics: 77.88 54.00 100.00样例 2 的统计结果为:
course average min max
Math: 79.00 63.00 100.00
English: 74.05 39.00 100.00
Physics: 73.60 48.00 93.00
Science: 65.85 26.00 100.00
course average min max
Math: 77.08 63.00 99.00
English: 70.46 39.00 100.00
Physics: 77.77 58.00 93.00
Science: 62.23 26.00 93.00
course average min max
Math: 82.57 63.00 100.00
English: 80.71 72.00 89.00
Physics: 65.86 48.00 91.00
Science: 72.57 48.00 100.00相关文章:
Spark项目实训(一)
目录 实验任务一:计算级数 idea步骤分步: 完整代码: linux步骤分布: 实验任务二:统计学生成绩 idea步骤分布: 完整代码: linux步骤分步: 实验任务一:计算级数 请…...
爬虫基础1
一、爬虫的基本概念 1.什么是爬虫? 请求网站并提取数据的自动化程序 2.爬虫的分类 2.1 通用爬虫(大而全) 功能强大,采集面广,通常用于搜索引擎:百度,360,谷歌 2.2 聚焦爬虫&#x…...
vlan综合实验
1、实验拓扑 2、实验要求 1、pc1和pc3所在接口为access;属于vlan 2; pc2/pc4/pc5/pc6处于同一网段;其中pc2可以访问pc4/pc5/pc6; pc4可以访问pc6;pc5不能访问pc6; 2、pc1/pc3与pc2/pc4/pc5/pc6不在同一网段; 3、所有pc通过DHC…...

如何使用ffmpeg 实现10种特效
相关特效的名字 特效id 特效名 1 向上移动 2 向左移动 3 向下移动 4 颤抖 5 摇摆 6 雨刷 7 弹入 8 弹簧 9 轻微跳动 10 跳动 特效展示(同时汇总相关命令) pad背景显示 pad背景透明 相关命令(一会再讲这些命令,先往下看) # 合成特效语音 ffmpeg -y -loglevel erro…...

C语言如果变量全部在全局内存空间会怎么样
结论先行 应该根据内存使用的生命周期,选择合适的内存空间应该尽量使用连续内存如果不想在设计封装性上付出太多代价,全部放入全局空间也比较可取 空间类型特点全局空间生命周期最久,空间连续,变量分配紧致,但存在浪…...
)
【YOLO改进】换遍MMPretrain主干网络之ConvNeXt-Tiny(基于MMYOLO)
ConvNeXt-Tiny ConvNeXt-Tiny 是一种改进的卷积神经网络架构,其设计目的是在保持传统卷积神经网络优势的同时,借鉴了一些Transformer架构的成功经验。 ConvNeXt-Tiny 的优点 架构优化: ConvNeXt-Tiny 对经典ResNet架构进行了多种优化&#…...
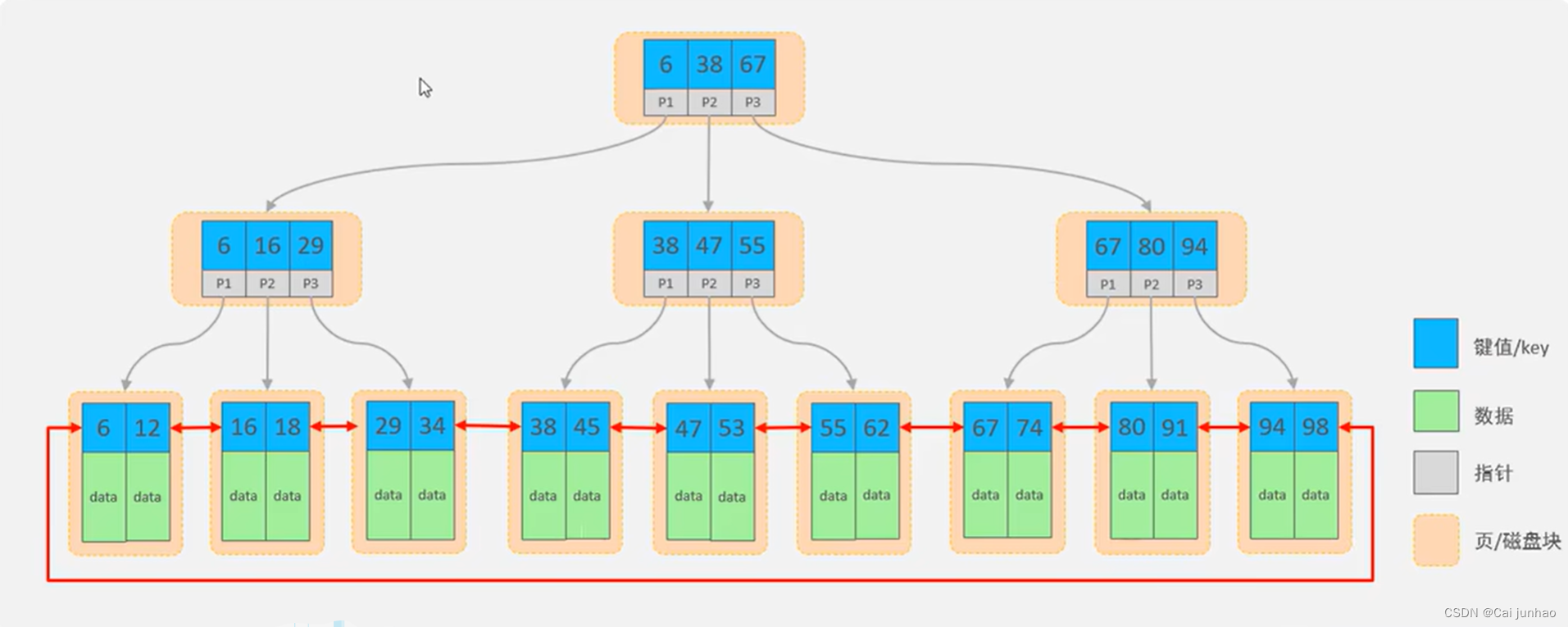
【数据库】MySQL
文章目录 概述DDL数据库操作查询使用创建删除 表操作创建约束MySqL数据类型数值类型字符串类型日期类型 查询修改删除 DMLinsertupdatedelete DQL基本查询条件查询分组查询分组查询排序查询分页查询 多表设计一对多一对一多对多设计步骤 多表查询概述内连接外连接 子查询标量子…...

JVM运行时内存:垃圾回收器(Serial ParNew Parallel )详解
文章目录 1. 查看默认GC2. Serial GC : 串行回收3. ParNew GC:并行回收4. Parallel GC:吞吐量优先 1. 查看默认GC -XX:PrintCommandLineFlags:查看命令行相关参数(包含使用的垃圾收集器)使用命令行指令:ji…...
The Missing Semester of Your CS Education(计算机教育中缺失的一课)
Shell 工具和脚本(Shell Tools and Scripting) 一、shell脚本 1.1、变量赋值 在bash中为变量赋值的语法是foobar,访问变量中存储的数值,其语法为 $foo。 需要注意的是,foo bar (使用空格隔开)是不能正确工作的&…...

如何为ChatGPT编写有效的提示词:软件开发者的指南
作为一名软件开发者,特别是使用Vue进行开发的开发者,与ChatGPT等AI助手高效互动,可以极大地提升你的开发效率。本文将深入探讨如何编写有效的提示词,以便从ChatGPT中获取有用的信息和帮助。 1. 明确目标 在编写提示词之前&#…...

angular插值语法与属性绑定
在 Angular 中,您提供的两种写法都是用来设置 HTML 元素的 title 属性,但它们的工作方式有所不同: 插值语法 (Interpolation) <h1 title"{{ name }}">我的名字</h1> 属性绑定 (Property Binding) <h1 [title]&q…...

Python ❀ 使用代码解决今天中午吃什么的重大生存问题
1. 环境安装 安装Python代码环境参考文档 2. 代码块 import random# 准备一下你想吃的东西 hot ["兰州拉面", "爆肚面", "黄焖鸡", "麻辣香锅", "米线", "麻食", "羊肉泡馍", "肚丝/羊血汤&qu…...
做抖音小店需要清楚的5个核心点!
大家好,我是喷火龙。 不管你是在做抖音小店,还是在做其他的电商平台,如果已经做了一段时间了,但还是没有拿到什么结果,我所指的结果不是什么大结果,而是连温饱都解决不了,甚至说还在亏钱。 有…...

文件流下载优化:由表单提交方式修改为Ajax请求
如果想直接看怎么写的可以跳转到 解决方法 节! 需求描述 目前我们系统导出文件时,都是通过表单提交后,接收文件流自动下载。但由于在表单提交时没有相关调用前和调用后的回调函数,所以我们存在的问题,假如导出数据需…...

基础3 探索JAVA图形编程桌面:逻辑图形组件实现
在一个宽敞明亮的培训教室里,阳光透过窗户柔和地洒在地上,教室里摆放着整齐的桌椅。卧龙站在讲台上,面带微笑,手里拿着激光笔,他的眼神中充满了热情和期待。他的声音清晰而洪亮,传遍了整个教室:…...
前后端部署笔记
windows版: 如果傻呗公司让用win电脑部署,类似于我们使用笔记本做局域网服务器,社内使用。 1.安装win版的nginx、mysql、node、jdk等 2.nginx开机自启参考Nginx配置及开机自启动(Windows环境)_nginx开机自启动 wind…...
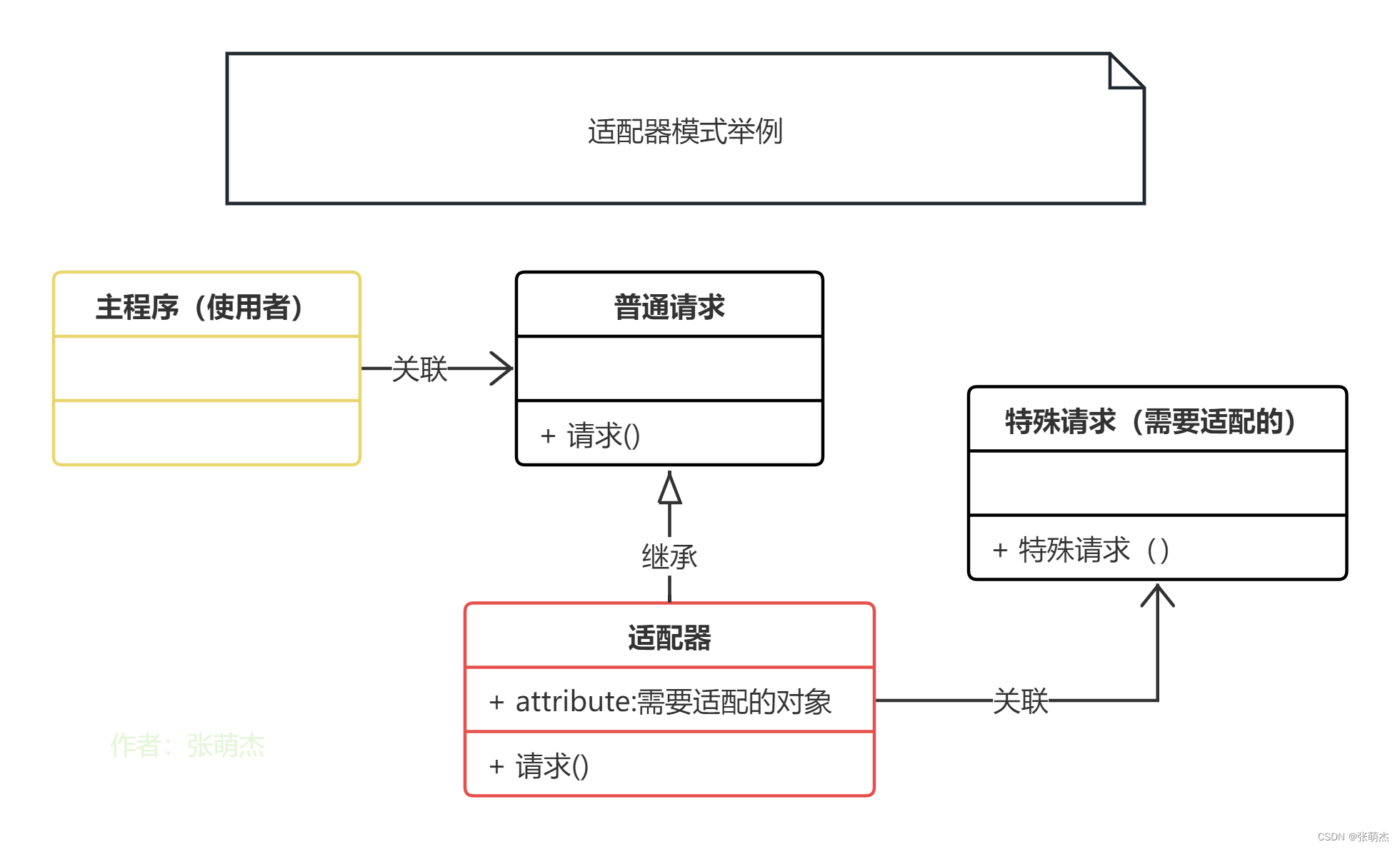
设计模式9——适配器模式
写文章的初心主要是用来帮助自己快速的回忆这个模式该怎么用,主要是下面的UML图可以起到大作用,在你学习过一遍以后可能会遗忘,忘记了不要紧,只要看一眼UML图就能想起来了。同时也请大家多多指教。 适配器模式(Adapte…...

一文了解基于ITIL的运维管理体系框架
本文来自腾讯蓝鲸智云社区用户:CanWay ITIL(Information Technology Infrastructure Library)是全球最广泛使用的 IT 服务管理方法,旨在帮助组织充分利用其技术基础设施和云服务来实现增长和转型。优化IT运维,作为企业…...

Web前端开发技术-格式化文本 Web页面初步设计
目录 Web页面初步设计 标题字标记 基本语法: 语法说明: 添加空格与特殊符号 基本语法: 语法说明: 特殊字符对应的代码: 代码解释: 格式化文本标记 文本修饰标记 计算机输出标记 字体font标记 基本语法: 属…...
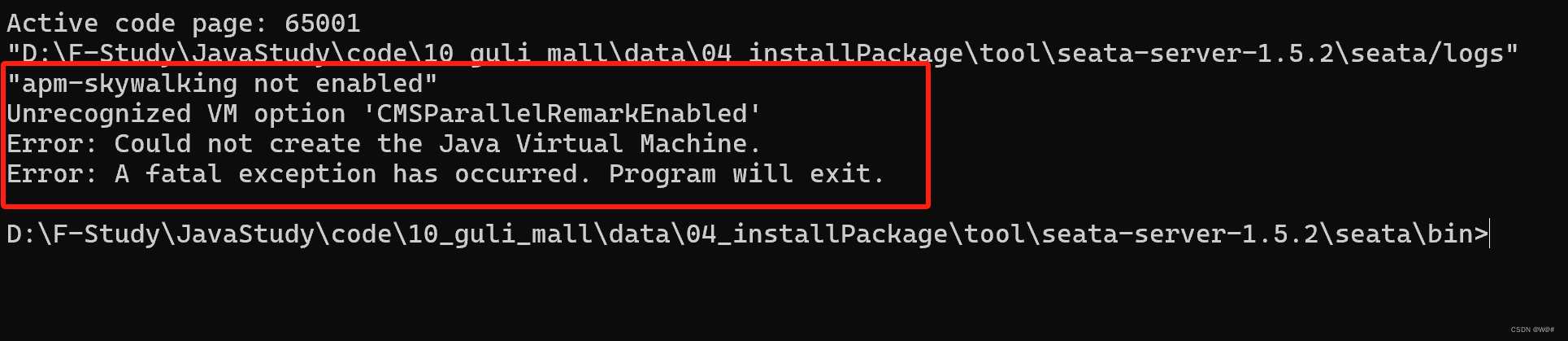
Windows下部署Seata1.5.2,解决Seata无法启动问题
目录 1. 版本说明 2. Windows下部署Seata1.5.2 2.1 创建回滚日志表undo_log 2.2 创建Seata服务端需要的四张表 2.3 在nacos创建seata命名空间,添加seataServer.yml配置 2.4 修改本地D:/tool/seata-server-1.5.2/seata/conf/applicaltion.yml文件 2.5 启动Seat…...

观察Taotoken在多模型聚合调用下的月度账单明细
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 观察Taotoken在多模型聚合调用下的月度账单明细 对于个人开发者或项目组而言,在项目中集成多个大语言模型(…...

深入解析Linux内核sk_buff:网络数据包的内存布局与核心操作
1. 项目概述:从“数据包”到“sk_buff”的认知跃迁在网络编程或者内核开发领域,无论你是刚入门的新手,还是已经写过几个驱动模块的开发者,迟早都会与一个名为sk_buff的数据结构狭路相逢。这个名字听起来有点古怪,它是“…...

ViGEmBus虚拟游戏控制器驱动:Windows游戏输入终极解决方案
ViGEmBus虚拟游戏控制器驱动:Windows游戏输入终极解决方案 【免费下载链接】ViGEmBus Windows kernel-mode driver emulating well-known USB game controllers. 项目地址: https://gitcode.com/gh_mirrors/vi/ViGEmBus 想要在Windows系统上获得完美的游戏控…...

4.7 Spark SQL函数分类与应用
本次实战涵盖了三大核心内容:内置函数、自定义函数(UDF)和开窗函数。 内置函数是数据处理的基础,包括字符串、日期、数学、聚合等10大类,可通过DataFrame API或SQL语句两种方式调用,满足多样化的数据转换需…...

formality
get_app_var verification_set_undriven_signalsset_app_var verification_set_undriven_signals binary 0ref的port是undriven,会说original undriven,并且给出0的cut_net激励,得到的值为0。这里的值给的是0而不是x,所以会特意说…...

MulimgViewer终极指南:如何用一个界面管理多张图片,告别繁琐切换
MulimgViewer终极指南:如何用一个界面管理多张图片,告别繁琐切换 【免费下载链接】MulimgViewer MulimgViewer is a multi-image viewer that can open multiple images in one interface, which is convenient for image comparison and image stitchin…...

深入理解Istio架构:控制平面与数据平面核心组件全解析
深入理解Istio架构:控制平面与数据平面核心组件全解析 【免费下载链接】istio-handbook Istio服务网格进阶实战 项目地址: https://gitcode.com/gh_mirrors/is/istio-handbook Istio作为新一代服务网格(Service Mesh)的领航者…...

CANN/asc-devkit RTC运行时编译指南
RTC 【免费下载链接】asc-devkit 本项目是CANN 推出的昇腾AI处理器专用的算子程序开发语言,原生支持C和C标准规范,主要由类库和语言扩展层构成,提供多层级API,满足多维场景算子开发诉求。 项目地址: https://gitcode.com/cann/a…...

Python金融数据引擎:重构通达信数据获取的技术范式
Python金融数据引擎:重构通达信数据获取的技术范式 【免费下载链接】mootdx 通达信数据读取的一个简便使用封装 项目地址: https://gitcode.com/GitHub_Trending/mo/mootdx 在量化投资和金融数据分析领域,数据获取一直是开发者面临的首要挑战。传…...

8. Python 模块与包 深度解析
Python 模块与包 深度解析 目录 模块与包的概念模块基础 2.1 模块即 .py 文件2.2 import 语句与 from ... import2.3 模块搜索路径 sys.path 模块的编译与缓存包 4.1 常规包与 __init__.py4.2 命名空间包4.3 相对导入与绝对导入 __name__ 与 "__main__"模块与包的组…...