Raylib 绘制自定义字体的一种套路
Raylib 绘制自定义字体是真的难搞。我的需求是程序可以加载多种自定义字体,英文中文的都有。
我调试了很久成功了!
很有用的参考,建议先看一遍:
瞿华:raylib绘制中文内容
个人笔记|Raylib 的字体使用 - bilibili
再放一下第一篇文章的可用示例代码:
#include <raylib.h>int main() {InitWindow(800,600,"世界你好");Image img=GenImageColor(800,600,WHITE);//读取字体文件unsigned int fileSize;unsigned char *fontFileData = LoadFileData("c:\\windows\\fonts\\simhei.ttf", &fileSize);//ImageDrawCircleEx(&img, 400,300,200,10,BLACK);SetTraceLogLevel(LOG_WARNING);SetTargetFPS(120);while (!WindowShouldClose()) {//将要输出的内容放到字符串中(必须是utf8编码)char text[]="世界,你好!";// 将字符串中的字符逐一转换成Unicode码点,得到码点表int codepointsCount;int *codepoints=LoadCodepoints(text,&codepointsCount);// 读取仅码点表中各字符的字体Font font = LoadFontFromMemory(".ttf",fontFileData,fileSize,32,codepoints,codepointsCount);// 释放码点表UnloadCodepoints(codepoints);BeginDrawing();ClearBackground(WHITE);DrawTextEx(font,text,(Vector2){50,50},32,5,RED);EndDrawing();//释放字体UnloadFont(font);}UnloadImage(img);//释放字体文件内容UnloadFileData(fontFileData);return 0;
}
(是的,图片img好像没有用)
关键步骤概括为:
- LoadFileData 读取字体文件
- (while 主循环)
- 准备好要输出的文本
- LoadCodepoints 用准备的文本加载码点
- LoadFontFromMemory 得到含需要输出的文本的字符的字体
- UnloadCodepoints 卸载码点
- BeginDrawing 开始绘制 使用刚刚的字体绘制文本
- EndDrawing 结束绘制
- UnloadFont
- (循环结束)
- UnloadFileData 卸载字体文件
注意每一轮循环都用指定文本的码点加载了新的字体,绘制好后才卸载该字体。
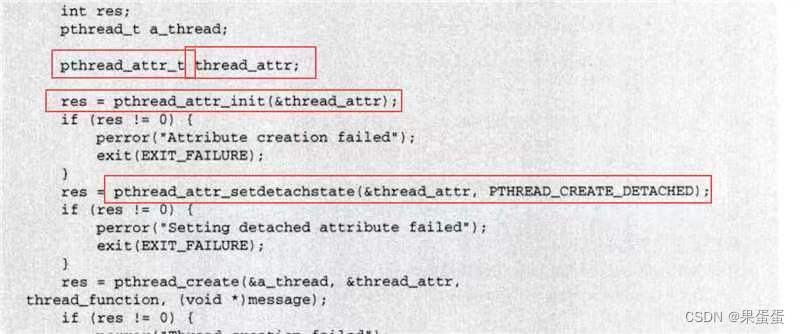
我试图将这一系列操作封装成函数DrawTextPlus,发现UnloadFont必须要在EndDrawing后面执行,不然会输出失败。
下面这张图更离谱了,大错特错!!

但是如果在一帧内调用多次BeginDrawing和EndDrawing,还是会出事。。出事代码如下
还是错误的代码,别复制
void DrawTextPlus(const string& s, int x, int y, int fs = 32)
{BeginDrawing();// 将字符串中的字符逐一转换成Unicode码点,得到码点表int codepointsCount;int *codepoints=LoadCodepoints(s.c_str(),&codepointsCount);// 读取仅码点表中各字符的字体Font font = LoadFontFromMemory(".ttf", fontFileData, fileSize, 32, codepoints, codepointsCount);// 释放码点表UnloadCodepoints(codepoints);DrawTextEx(font,s.c_str(),(Vector2){x,y},fs,0,RED);EndDrawing();//释放字体UnloadFont(font);
}

出现了闪烁现象:

所以一帧还只能调用一次BeginDrawing,EndDrawing。那只能采取其他措施了。
如果真的不封装,需要在同一帧输出不同文本的话,以下代码可以正常运行:
#include <raylib.h>
#include <string>int main() {InitWindow(800,600,"世界你好");//读取字体文件unsigned int fileSize;unsigned char *fontFileData = LoadFileData("c:\\windows\\fonts\\simhei.ttf", &fileSize);SetTraceLogLevel(LOG_WARNING);SetTargetFPS(120);//将要输出的内容放到字符串中(必须是utf8编码)ssize_t scnt = 4;const std::string strings[] {"DarkVoxel", "Battle of Phantom", "Poemaze", "TerraSurvivor"};while (!WindowShouldClose()) {std::string total_texts{""};for (size_t i {0}; i < scnt; ++i)total_texts += strings[i];// 将字符串中的字符逐一转换成Unicode码点,得到码点表int codepointsCount;int *codepoints=LoadCodepoints(total_texts.c_str(),&codepointsCount);// 读取仅码点表中各字符的字体Font font = LoadFontFromMemory(".ttf",fontFileData,fileSize,32,codepoints,codepointsCount);// 释放码点表UnloadCodepoints(codepoints);BeginDrawing();ClearBackground(WHITE);//可以按需要输出了,只要total_texts中有该字符就可以正常输出for (size_t i {0}; i < scnt; ++i)DrawTextEx(font,strings[i].c_str(),Vector2{50.0f, 50.0f * i}, 32.0f, 5.0f, RED);EndDrawing();//释放字体UnloadFont(font);}//释放字体文件内容UnloadFileData(fontFileData);return 0;
}
可以发现有好几个地方值得注意以及一点想法:
1.字体整个文件的读取还是在循环前(也就是在程序的载入阶段可以一口气把所有的字体文件读完放进一个容器中)
2.需要输出的文本得提前准备好(如果真的在项目中这样,未免太难受了)
3.在准备码点的时候,可以把需要输出的文本合并在一起(当然可以进行一个字符去重以提高效率)
4.绘制文本的时候只要字符在合并好的文本之中,就可以正常输出
5.每帧都进行了加载和卸载字体的操作(还是变慢了)
6.最后程序退出前卸载时要释放所有的字体文件内容。(释放容器)
小项目就上面这样的写法应该可以接受。但是中大项目就不一样了,动不动就要输出一大堆文本,不可能搞一堆string存在那里,看的都烦;而且每帧都要重新准备字体效率低下。
经过进一步思考,我形成了另一种思路。我在上面的代码中添加了一些【伪代码】:
#include <raylib.h>
#include <string>
#include <map>
#include <vector>【
容器,存储所有词汇std::string LSTR(const std::string输出内容ID)
{//在我的项目中,支持多语言,我弄一个CSV,专门存储每种语言的词汇,//那么这个输出内容ID就可以是中文,方便我阅读代码。返回真实的输出内容
}
】int main()
{InitWindow(800,600,"世界你不好");//读取读取你的CSV文件并存储到一个容器中,以供上面的LSTR函数使用map<std::string, pair <std::string, unsigned char*>> 所有需要用到的字体名称以及路径、数据;{{..., {..., nullptr}},{..., {..., nullptr}},};】【for (const auto& fdt : ...){unsigned int fileSize;unsigned char *fontFileData = LoadFileData(字体文件路径, &fileSize);把fontFileData存进去string 整合串= 去重后的把CSV文件所有内容拼接在一起的字符串;// 将字符串中的字符逐一转换成Unicode码点,得到码点表int codepointsCount;int *codepoints=LoadCodepoints(整合串.c_str(), &codepointsCount);// 读取仅码点表中各字符的字体Font font = LoadFontFromMemory(取字体路径扩展名, 字体文件内容fontFileData,fileSize, 200, codepoints, codepointsCount);把字体装进去// 释放码点表UnloadCodepoints(codepoints);}】SetTraceLogLevel(LOG_WARNING);SetTargetFPS(120);//将要输出的内容放到字符串中(必须是utf8编码)while (!WindowShouldClose()) {BeginDrawing();ClearBackground(WHITE);//可以按需要输出了,只要total_texts中有该字符就可以正常输出
//CUR_FONT 是一个宏,获取当前字体DrawTextEx(CUR_FONT,LSTR("CSV中"),Vector2{50.0f, 50.0f}, 80.0f, 5.0f, BLACK);DrawTextEx(CUR_FONT,LSTR("包含的内容"),Vector2{50.0f, 130.0f}, 80.0f, 5.0f, BLACK);DrawTextEx(CUR_FONT,LSTR("都可以写"),Vector2{50.0f, 210.0f}, 80.0f, 5.0f, BLACK);EndDrawing();}【for (auto& fdt : ...){UnloadFileData(字体文件内容指针);}】return 0;
}
注意你需要准备一个文件(例如CSV格式的),每行存储一个你需要的字符串,然后LSTR函数的参数就是你访问任意一个字符串的索引(可以是数字【我觉得挺烦的,还要查】,可以是字符串【本身】)。正如我注释中写的,我的程序支持多语言,因此可以每行一个中文,逗号,一个英文,然后用中文索引,特别方便。
这样的结构虽然很难搞,但是大大简化了中间绘制文本的代码,只需要加个LSTR这样的函数即可,无需手动准备一堆string来搞临时的字体再输出。
如果你不想撰写新的文件存储所要用的字符串,还有几种偷懒的方法(仅供参考):
(1)写一个辅助的程序,在要编译前运行它,提取你的源文件中的字符串然后整合在一起,再把字符串写进去然后编译(雾)。
(2)把所有字符(例如汉字)加载进去(日常试试可以,实际运用肯定不现实,内存都要爆了)
上面的伪代码可能看的不是很明白,我也不可能全部帮你补全,只能提供一些我跑成功的项目的代码或是截图,希望对你有帮助:
语言、词汇处理
enum LangID
{Chinese = 0,English = 1,
};
#define LANG_CNT 2//下标宏
#define LID_LANG 0 //各语言名称
#define LID_GAME_NAME 1vector<vector<string>> lang_words;bool ReadLanguage();constexpr const char* PunctAndNumberString(void)
{return "0123456789,.?/<>()~`[]{}\\|\"\':;!@#$%^&*-=_+ ";
}
constexpr const char* PunctAndNumberStringIncludingChinese(void)
{return " 0123456789,.?/<>()~`[]{}\\|\"\':;!@#$%^&*-=_+,。?!、()【】“”‘’;:《》·…—";
}
string ObtainNormalEnglish(const string& s)
{string res;bool wordbeg{ true };for (char ch : s){if (wordbeg && isalpha(ch)){res += islower(ch) ? toupper(ch) : ch;wordbeg = false;}else if (isalpha(ch)){res += ch;}else if (ch == '_' || ch == ' '){res += ' ';wordbeg = true;}}return res;
}
string AssembleTotalChineseString(void);
string AssembleTotalEnglishString(void)
{string res;for (char ch = 'A'; ch <= 'Z'; ++ch)res += str(ch);for (char ch = 'a'; ch <= 'z'; ++ch)res += str(ch);res += PunctAndNumberString();return res;
}
string UniqueChinese(const string& s) {string result;unordered_set<int> chineseChars;for (size_t i = 0; i < s.length(); i++) {// 检查当前字符是否是中文字符if ((s[i] & 0xE0) == 0xE0) {int codePoint = ((s[i] & 0x0F) << 12) | ((s[i + 1] & 0x3F) << 6) | (s[i + 2] & 0x3F);// 如果当前中文字符不在哈希集合中,则将其添加到结果字符串和哈希集合中if (chineseChars.find(codePoint) == chineseChars.end()) {result += s.substr(i, 3);chineseChars.insert(codePoint);}// 由于中文字符占用3个字节,因此增加索引i的值i += 2;}else {result += s[i];}}return result;
}bool ReadLanguage()
{string path = g.data_dir + "Language.csv";if (!ExistFile(path)){ErrorLogTip(nullptr, "Cannot Find the Language File :(\n" + path, "ReadLanguage");return false;}DebugLog("读取语言...");vector<string> lines = ReadFileLines(path);int i{ 1 };while (i < lines.size()){string line = lines.at(i);if (line.empty()){++i;continue;}line = strrpc(line, " ", "$");line = strrpc(line, ",", " ");stringstream ss;string tmp;ss << line;vector<string> langs;for (int i = 0; i < LANG_CNT; ++i){ss >> tmp;tmp = strrpc(tmp, "$", " ");tmp = strrpc(tmp, "^", ",");langs.push_back(tmp);}// DebugLog(str(langs));lang_words.push_back(langs);++i;}for (const auto& idt : itemdata)lang_words.push_back(vector{ idt.cn_name, ObtainNormalEnglish(idt.en_name) });for (const auto& edt : entitydata)lang_words.push_back(vector{ edt.cn_name, ObtainNormalEnglish(edt.en_name) });for (const auto& bdt : buffdata)lang_words.push_back(vector{ bdt.cn_name, ObtainNormalEnglish(bdt.en_name) });for (const auto& pdt : placeabledata)lang_words.push_back(vector{ pdt.cn_name, ObtainNormalEnglish(pdt.en_name) });for (const auto& rdt : random_tips)lang_words.push_back(rdt.versions);DebugLog("共计", lang_words.size(), "个词汇,支持", LANG_CNT, "门语言");return true;
}
string AssembleTotalChineseString(void)
{string res;//英文也要for (char ch = 'A'; ch <= 'Z'; ++ch)res += str(ch);for (char ch = 'a'; ch <= 'z'; ++ch)res += str(ch);//然后是中文for (const auto& pr : lang_words)res += pr.at(Chinese);res += PunctAndNumberStringIncludingChinese();res = UniqueChinese(res);return res;
}
#define CHN_FONTNAME "Sthginkra Italic"map<LangID, string> lang_font_names
{{Chinese, CHN_FONTNAME},{English, "Andy Bold"},
};#define CUR_FONTNAME (g.lang_font_names[g.lang].c_str())
#define CENTER_TITLE_CHN_FONTNAME "钉钉进步体"map<string, pair<string, LangID>> used_fonts
{{"Andy Bold", {"ANDYB.TTF", English}},{CHN_FONTNAME, {"ZhouFangRiMingTiXieTi-2.otf", Chinese}}, //我不是舟批{CENTER_TITLE_CHN_FONTNAME, {"DingTalk JinBuTi.ttf", Chinese}},
};DebugLog("安装", used_fonts.size() - 1, "个字体...");unsigned char* pFileData{ nullptr };auto iter = used_fonts.begin();
for (;iter != used_fonts.end(); ++iter)
{if (iter->second.second == English)continue;auto pr = make_pair(iter->first,make_pair(ProduceMemoryFont(iter->second.first, iter->second.second, &pFileData),pFileData)); //见下文cout << iter->second.first << " " << iter->second.second << " " << pr.first << " " << pr.second.first.glyphCount << '\n';g.fonts.insert(pr);
}DebugLog("加载 " + str(g.fonts.size()) + " 个字体完毕");
Font ProduceMemoryFont(const string& filename, LangID lid, unsigned char** pFileData)
{string s;switch (lid){case Chinese:s = AssembleTotalChineseString();break;case English:s = AssembleTotalEnglishString();break;default:return GetFontDefault();}Font font;unsigned int fileSize{ 0U };unsigned char* fontFileData = LoadFileData((g.font_dir + filename).c_str(), &fileSize);*pFileData = fontFileData;if (fontFileData == nullptr){DebugLog("ERROR: fontFileData is empty");}int codepointsCount;cout << "LoadCodepoints...\n";cout << "s=" << s << '\n';int* codepoints = LoadCodepoints(s.c_str(), &codepointsCount);if (!codepoints){cout << "ERROR: LoadCodePoints failed\n";}cout << "CodepointsCount=" << codepointsCount << '\n';cout << "FileSize=" << fileSize << '\n';string ext = GetFileExtension(filename.c_str());cout << "Ext=" << ext << '\n';// 读取仅码点表中各字符的字体cout << "LoadFontFromMemory...\n";font = LoadFontFromMemory(ext.c_str(), fontFileData,fileSize, 200, codepoints, codepointsCount); //200挺合适的// 释放码点表cout << "UnloadCodepoints...\n";UnloadCodepoints(codepoints);return font;
}
DebugLog("卸载", used_fonts.size(), "个字体...");
for (const auto& fn : used_fonts)
{UnloadFont(g.fonts[fn.first].first);UnloadFileData(g.fonts[fn.first].second);
}
控制台输出截图(非中文字符去重我好像没做):

怎么样,有思路了吗?
大概就是把要输出的字符串提前收集好,然后装载字体一次就行,后面就随心所欲输出就行了。
还有几点:
1.装载字体时的字号选 200 是挺合适的值,如果太低就马赛克了,太高会出问题
2.CSV文件可能是这样的:

相关文章:
Raylib 绘制自定义字体的一种套路
Raylib 绘制自定义字体是真的难搞。我的需求是程序可以加载多种自定义字体,英文中文的都有。 我调试了很久成功了! 很有用的参考,建议先看一遍: 瞿华:raylib绘制中文内容 个人笔记|Raylib 的字体使用 - …...

C++学习笔记(21)——继承
目录 1. 继承的概念及定义1.1 继承的概念1.2 继承定义1.2.1 定义格式1.2.2 继承关系和访问限定符1.2.3 继承基类成员访问方式的变化 继承的概念总结: 2. 基类和派生类对象赋值转换3.继承中的作用域4.派生类的默认成员函数知识点:派生类中6个默认成员函数…...

DOS学习-目录与文件应用操作经典案例-more
新书上架~👇全国包邮奥~ python实用小工具开发教程http://pythontoolsteach.com/3 欢迎关注我👆,收藏下次不迷路┗|`O′|┛ 嗷~~ 目录 一.前言 二.使用 三.案例 一.前言 DOS系统的more命令是一个用于查看文本文件内容的工具。…...

android 在 Activity 的 onCreate 中获取View 的宽高
view 的 post 执行时,首先会判断view 的 mAttatchInfo 是否为空,如果不为空,则将Runnable 添加到mAttachInfo.handler 的 UI线程MessageQueue 中;如果为空,则先将Runnable 暂存在view 的类为HandlerActionQueue的mRunQ…...

Pod进阶——资源限制以及探针检查
目录 一、资源限制 1、资源限制定义: 2、资源限制request和limit资源约束 3、Pod和容器的资源请求和限制 4、官方文档示例 5、CPU资源单位 6、内存资源单位 7、资源限制实例 ①编写yaml资源配置清单 ②释放内存(node节点,以node01为…...
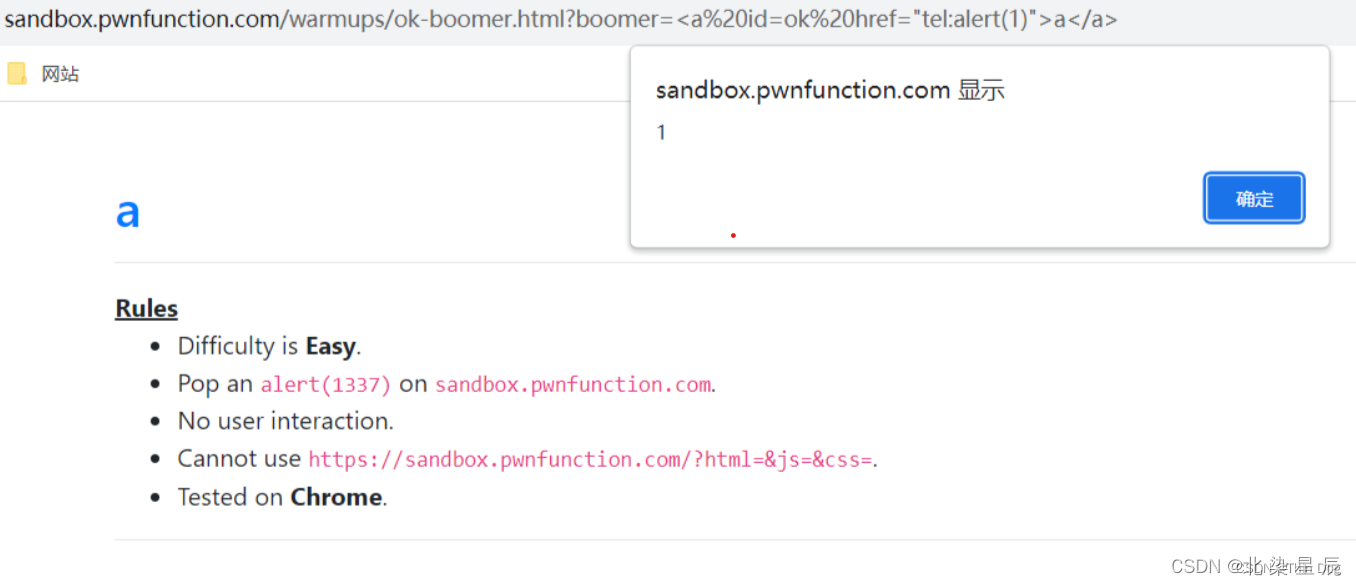
XSS---DOM破坏
文章目录 前言一、pandas是什么?二、使用步骤 1.引入库2.读入数据总结 一.什么是DOM破坏 在HTML中,如果使用一些特定的属性名(如id或name)给DOM元素命名,这些属性会在全局作用域中创建同名的全局变量,指向对…...

2024电工杯数学建模B 题:大学生平衡膳食食谱的优化设计
背景: 大学时代是学知识长身体的重要阶段, 同时也是良好饮食习惯形成的重要时期。这一特 定年龄段的年轻人, 不仅身体发育需要有充足的能量和各种营养素, 而且繁重的脑力劳动和 较大量的体育锻炼也需要消耗大量的能源物质。 大学生…...
)
LeetCode 1542.找出最长的超赞子字符串:前缀异或和(位运算)
【LetMeFly】1542.找出最长的超赞子字符串:前缀异或和(位运算) 力扣题目链接:https://leetcode.cn/problems/find-longest-awesome-substring/ 给你一个字符串 s 。请返回 s 中最长的 超赞子字符串 的长度。 「超赞子字符串」需…...

LLM企业应用落地场景中的问题概览
三个问题 AI思维快速工具:需要对接LLM的API、控制幻觉、管理知识库。POC验证四个难点 私有化部署的环境:包括网络和服务器环境。交互友好意想不到的情况方向选择:让客户做目标和方向的选择问题 一、RAG 多跳问题 通常发生在报告编写的数据整理环节,比如要从一堆报表中找…...
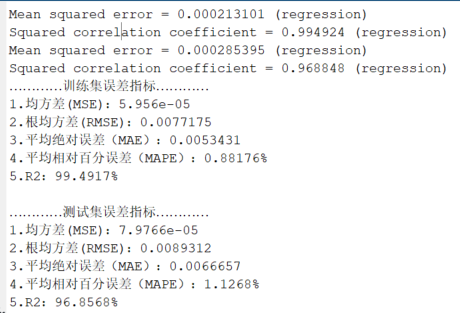
基于灰狼优化算法优化支持向量机(GWO-SVM)时序预测
代码原理及流程 基于灰狼优化算法优化支持向量机(GWO-SVM)的时序预测代码的原理和流程如下: 1. **数据准备**:准备时序预测的数据集,将数据集按照时间顺序划分为训练集和测试集。 2. **初始化灰狼群体和SVM模型参数…...

C++中获取int最大与最小值
不知道大家有没有遇到过这种要求:“返回值必须是int,如果整数数超过 32 位有符号整数范围 [−2^31, 2^31 − 1] ,需要截断这个整数,使其保持在这个范围内。例如,小于 −2^31 的整数应该被固定为 −2^31 ,大…...
学习通高分免费刷课实操教程
文章目录 概要整体架构流程详细步骤云上全平台登录步骤小结 概要 我之前提到过一个通过浏览器的三个脚本就可以免费高分刷课的文章,由于不方便拍视频进行实操演示,然后写下了这个实操教程,之前的三个脚本划到文章末尾 整体架构流程 整体大…...

缓存降级
当Redis缓存出现问题或者无法正常工作时,需要有一种应对措施,避免直接访问数据库而导致整个系统瘫痪。缓存降级就是这样一种机制。 主要的缓存降级策略包括: 本地缓存降级 当Redis缓存不可用时,可以先尝试使用本地进程内缓存,如Guava Cache或Caffeine等。这样可以减少对Redis…...
PyQt6--Python桌面开发(32.QMenuBar菜单栏控件)
QMenuBar菜单栏控件 选择Main Window...

golang创建式设计模式---工厂模式
创建式设计模式—工厂模式 目录导航 创建式设计模式---工厂模式1)什么是工厂模式2)使用场景3)实现方式4)实践案例5)优缺点分析 1)什么是工厂模式 工厂模式(Factory Method Pattern)是一种设计模式,旨在创建对象时,将对象的创建与使用进行分离。通过定义…...

高精度定位平板主要应用在哪些领域
高精度定位平板是一种集成了高精度定位技术和强大计算能力的设备,能够提供亚米级甚至厘米级的定位精度。其应用领域广泛,涵盖测绘、精准农业、工程建设、地理信息系统(GIS)、公共安全等多个方面。这种设备凭借其高精度和耐用性&am…...

conda使用常用命令
Conda是一个非常常用的Python包管理器,也是Anaconda Python发行版的一部分。它可以帮助用户安装、更新、卸载Python包,以及管理Python虚拟环境。在这篇博客中,我们将总结一些常用的Conda命令及其用法。 安装和更新Conda 在使用Conda之前&…...
22-LINUX--多线程and多进程TCP连接
一.TCP连接基础知识 1.套接字 所谓套接字(Socket),就是对网络中不同主机上的应用进程之间进行双向通信的端点的抽象。一个套接字就是网络上进程通信的一端,提供了应用层进程利用网络协议交换数据的机制。从所处的地位来讲,套接字上联应用进程…...

像素级创意:深入浅出PixelCNN图像合成技术
参考 https://arxiv.org/pdf/1601.06759 https://blog.csdn.net/zcyzcyjava/article/details/126559327 需要熟悉熵的一些理论、和极大释然估计等价于最小化交叉熵等知识 1. pixelcnn建模方法 pixelcnn做生成模型的想必都有耳闻。它是一种自回归模型,什么是自回归…...

MyBatisPlus使用流程
引入依赖 <dependency><groupId>com.baomidou</groupId><artifactId>mybatis-plus-boot-starter</artifactId><version>3.5.4</version> </dependency> 版本号根据需要选取 在实体类上加注解声明,表信息 根据数…...

别再手动画图了!用Mermaid+Markdown在VSCode里5分钟搞定UML设计文档
用文本驱动设计:现代开发者的UML高效实践指南 在技术文档中清晰表达系统设计是每个开发者的必修课。传统UML工具往往需要频繁切换鼠标键盘,拖拽调整元素位置,保存后再手动插入文档——这种工作流不仅低效,更让设计文档与代码库脱节…...

Vue-antd样式系统深度解析:从主题定制到组件样式覆盖的完整指南
Vue-antd样式系统深度解析:从主题定制到组件样式覆盖的完整指南 【免费下载链接】vue-antd Vue UI Component & Ant.Design 项目地址: https://gitcode.com/gh_mirrors/vu/vue-antd Vue-antd作为Ant Design的Vue实现,提供了一个强大而灵活的样…...

KaTrain围棋AI:5步开启专业级围棋训练新时代 [特殊字符]
KaTrain围棋AI:5步开启专业级围棋训练新时代 🎯 【免费下载链接】katrain Improve your Baduk skills by training with KataGo! 项目地址: https://gitcode.com/gh_mirrors/ka/katrain 你是否渴望提升围棋水平,却苦于缺乏专业指导&am…...

5分钟快速生成专业README文件:readme-md-generator完全指南
5分钟快速生成专业README文件:readme-md-generator完全指南 【免费下载链接】readme-md-generator 📄 CLI that generates beautiful README.md files 项目地址: https://gitcode.com/gh_mirrors/re/readme-md-generator 在开源项目开发中&#x…...

如何在Linux系统上安装Realtek RTL8125 2.5GbE网卡驱动:完整配置指南
如何在Linux系统上安装Realtek RTL8125 2.5GbE网卡驱动:完整配置指南 【免费下载链接】realtek-r8125-dkms A DKMS package for easy use of Realtek r8125 driver, which supports 2.5 GbE. 项目地址: https://gitcode.com/gh_mirrors/re/realtek-r8125-dkms …...
终极Emu模型架构解析:深入理解370亿参数的多模态Transformer
终极Emu模型架构解析:深入理解370亿参数的多模态Transformer 【免费下载链接】Emu Emu Series: Generative Multimodal Models from BAAI 项目地址: https://gitcode.com/gh_mirrors/emu/Emu Emu是由BAAI开发的革命性多模态生成模型系列,通过融合…...

鸿蒙备考题库页面构建:错题本、小组榜单与备考提示模块详解
鸿蒙备考题库页面构建:错题本、小组榜单与备考提示模块详解 前言 在 HarmonyOS 6.0 应用开发中,教育类应用的错题管理、学习排行榜和系统提示是提升用户粘性的关键功能模块。本文将以“备考题库”应用中的“错题本”高频错题列表、“小组榜单”学习排名和…...

6.解决 99% 刷机故障|GPT 分区修复 + SEP 兼容检测 + 全分区备份,工程师实战手册
摘要 本文面向具备基础Linux命令行操作能力的维修工程师与高级发烧友,系统阐述主流品牌手机刷机与维修的底层逻辑与标准化操作流程。内容覆盖高通、联发科、苹果A系列三大芯片平台的刷机协议差异,提供完整的刷机工具链搭建脚本、分区备份恢复脚本、以及底层驱动级故障诊断代…...

Sunshine自托管游戏串流终极指南:打造跨平台家庭游戏云的完整解决方案
Sunshine自托管游戏串流终极指南:打造跨平台家庭游戏云的完整解决方案 【免费下载链接】Sunshine Self-hosted game stream host for Moonlight. 项目地址: https://gitcode.com/GitHub_Trending/su/Sunshine 想象一下这样的场景:您坐在客厅沙发上…...

运放电源端串联磁珠
在运放电源端串联磁珠,是一种常见的高频噪声抑制设计手段,但需结合具体应用场景谨慎使用。以下是关键要点:---作用与目的 - 抑制高频噪声:磁珠对高频信号(通常 >10 MHz)呈现高阻抗,将电源线上…...