大模型日报|今日必读的 13 篇大模型论文

大家好,今日必读的大模型论文来啦!
1.MIT新研究:并非所有语言模型特征都是线性的
最近的研究提出了线性表征假说:语言模型通过操作激活空间中概念(“特征”)的一维表征来执行计算。与此相反,来自麻省理工学院(MIT)的研究团队探讨了某些语言模型表征是否可能本质上是多维的。
他们首先为不可还原的多维特征下了一个严格的定义,该定义基于这些特征是否可以分解为独立或不共存的低维特征。受这些定义的启发,他们设计了一种可扩展的方法,利用稀疏自动编码器自动发现 GPT-2 和 Mistral 7B 中的多维特征。这些自动发现的特征包括可解释示例,例如代表星期和月份的 circular 特征。他们确定了一些任务,在这些任务中,这些精确的 circular 被用来解决涉及一周中的天数和一年中的月份的模块运算问题。最后,通过对 Mistral 7B 和 Llama 3 8B 的干预实验,他们证明这些 circular 特征确实是这些任务中的基本计算单元。
论文链接:
https://arxiv.org/abs/2405.14860
GitHub 地址:
https://github.com/JoshEngels/MultiDimensionalFeatures
2.Google DeepMind 推出图像条件扩散模型 Semantica
Google DeepMind 团队研究了在不进行微调的情况下将图像生成模型适应不同数据集的任务。为此,他们提出了一种图像条件扩散模型——Semantica,其能够根据条件图像的语义生成图像。Semantica 完全是在网络规模的图像对上进行训练的,也就是说,它接收网页中的随机图像作为条件输入,并对同一网页中的另一张随机图像进行建模。他们的实验凸显了预训练图像编码器的表现力,以及基于语义的数据过滤对实现高质量图像生成的必要性。一旦经过训练,只需使用数据集中的图像作为输入,它就能自适应地从该数据集中生成新图像。
论文链接:
https://arxiv.org/abs/2405.14857
3.Visual Echoes:用于音频-视觉生成的简单统一 Transformer
近年来,随着逼真的生成结果和广泛的个性化应用,基于扩散的生成模型在视觉和音频生成领域都获得了极大的关注。与文本-图像生成或文本-音频生成的巨大进步相比,音频-视觉生成或视觉-音频生成的研究相对缓慢。近期的音频-视觉生成方法通常采用大型语言模型或可组合扩散模型。
在这项工作中,来自索尼的研究团队没有为音频-视觉生成设计另一个大型模型,而是退后一步,展示了一个在多模态生成中尚未得到充分研究的简单轻量级生成 Transformer,可以在图像-音频生成中取得优异的效果。Transformer 在离散的音频和视觉矢量量化 GAN 空间中运行,并以掩码去噪方式进行训练。训练完成后,无需额外的训练或修改,即可部署现成的无分类器引导,从而获得更好的性能。由于 Transformer 模型是模态对称的,因此也可直接用于音频-图像生成和协同生成。在实验中,他们发现这一简单方法超越了最近的图像-音频生成方法。
论文链接:
https://arxiv.org/abs/2405.14598
4.大型语言模型的分布式推测
加速大型语言模型(LLM)的推理是人工智能领域的一项重要挑战。
来自魏茨曼科学研究所、英特尔和麻省理工学院(MIT)的研究团队提出了一种新颖的分布式推理算法——分布式推测推理(DSI),与推测推理(SI)和传统的自回归推理(non-SI)相比,其推理速度更快。与其他自回归推理算法一样,DSI 在冻结的 LLM 上工作,不需要训练或架构修改,并能保留目标分布。
之前关于 SI 的研究表明,与 non-SI 相比,DSI 算法的经验速度有所提高,但这需要快速、准确的起草 LLM。在实践中,现成的 LLM 通常不具备足够快速和准确的匹配起草器。他们发现:当使用速度较慢或准确度较低的起草员时,SI 的速度会比非 SI 慢。他们通过证明 DSI 在使用任何起草器的情况下都比 SI 和 non-SI 更快,弥补了这一差距。通过协调目标和起草器的多个实例,DSI 不仅比 SI 更快,而且还支持 SI 无法加速的 LLM。
仿真显示,在现实环境中,现成的 LLMs 的速度都有所提高:DSI 比 SI 快 1.29-1.92 倍。
论文链接:
https://arxiv.org/abs/2405.14105
5.改进分布匹配蒸馏,实现快速图像合成
最近的一些方法表明,将扩散模型提炼成高效的一步生成器大有可为。其中,分布匹配蒸馏法(DMD)可以生成在分布上与其“教师”模型相匹配的一步生成器,而无需强制与“教师”的采样轨迹一一对应。然而,为了确保稳定的训练,DMD 需要额外的回归损耗,该损耗是使用由“教师”通过多步确定性采样器生成的大量噪声图像对计算得出的。这对于大规模文本到图像的合成来说成本很高,而且限制了“学生”模型的质量,使其与“教师”的原始采样路径过于紧密地联系在一起。
来自麻省理工学院(MIT)和 Adobe 的研究团队提出了一套能解除这一限制并改进 DMD 训练的技术——DMD2。首先,他们消除了回归损失和昂贵的数据集构建需求。他们证明了由此产生的不稳定性是由于假批评家没有准确估计生成样本的分布,并提出了一种双时间尺度更新规则作为补救措施。其次,他们将 GAN 损失集成到蒸馏过程中,以区分生成样本和真实图像。这样,他们就能在真实数据上训练“学生”模型,减轻“教师”模型对真实分数估计的不完美,提高质量。最后,他们修改了训练程序,以实现多步采样。在这种情况下,他们通过在训练期间模拟推理时间生成器采样,发现并解决了训练-推理输入不匹配的问题。
综合来看,他们的改进为一步图像生成设定了新的基准,在 ImageNet-64x64 上的 FID 分数为 1.28,在零样本 COCO 2014 上的 FID 分数为 8.35,尽管推理成本降低了 500 倍,但仍超过了原来的“教师”。此外,他们还展示了这一方法可以通过提炼 SDXL 生成百万像素图像,在几步法中展示了卓越的视觉质量。
论文链接:
https://arxiv.org/abs/2405.14867
项目地址:
https://tianweiy.github.io/dmd/
6.ReVideo:通过运动和内容控制重塑视频
尽管在利用扩散模型生成和编辑视频方面取得了重大进展,但实现精确的本地化视频编辑仍是一项巨大挑战。此外,现有的大多数视频编辑方法主要集中在改变视觉内容上,对动作编辑的研究十分有限。
在这项研究中,来自北京大学和腾讯的研究团队及其合作者,提出了一种新颖的“重塑视频”(ReVideo)尝试,通过指定内容和动作,在特定区域进行精确的视频编辑。内容编辑通过修改第一帧来实现,而基于轨迹的运动控制则提供了直观的用户交互体验。ReVideo 解决了内容和运动控制之间的耦合和训练不平衡问题。为了解决这个问题,他们开发了一种三阶段训练策略,从粗到细逐步解耦这两个方面。此外,他们还提出了一个时空自适应融合模块,以整合不同采样步骤和空间位置的内容和运动控制。
广泛的实验证明,ReVideo 在几种精确的视频编辑应用中具有良好的性能,即:1)局部改变视频内容,同时保持运动不变;2)保持内容不变,同时定制新的运动轨迹;3)同时修改内容和运动轨迹。该方法还可以无缝地将这些应用扩展到多区域编辑,而无需特定的训练,这证明了它的灵活性和鲁棒性。
论文链接:
https://arxiv.org/abs/2405.13865
项目地址:
https://mc-e.github.io/project/ReVideo/
7.360智脑技术报告
360智脑团队提出的 360Zhinao 模型具有 7B 参数大小和包括 4K、32K 和 360K 的上下文长度。为了实现预训练的快速发展,他们建立了一个稳定而灵敏的消融环境,以最小的模型规模对实验运行进行评估和比较。在这样的指导下,他们完善了数据清洗和合成策略,在 3.4T token 上对 360Zhinao-7B-Base 进行预训练。他们还主要强调对齐过程中的数据,通过过滤和重新格式化,努力平衡数量和质量。有了量身定制的数据,360Zhinao-7B 的上下文窗口很容易扩展到 32K 和 360K。RM 和 RLHF 根据 SFT 进行训练,并可靠地应用于特定任务。所有这些贡献使得 360Zhinao-7B 的性能在类似规模的模型中具有竞争力。
论文链接:
https://arxiv.org/abs/2405.13386
GitHub 地址:
https://github.com/Qihoo360/360zhinao
8.GameVLM:基于视觉语言模型和零和博弈的机器人任务规划决策框架
GPT-4V 等预训练视觉语言模型(VLM)具有突出的场景理解和推理能力,因此在机器人任务规划中受到越来越多的关注。与传统的任务规划策略相比,视觉语言模型在多模态信息解析和代码生成方面具有很强的优势,并显示出显著的效率。虽然 VLM 在机器人任务规划中展现出巨大潜力,但它也面临着幻觉、语义复杂性和上下文有限等挑战。
为了解决这些问题,来自复旦大学的研究团队提出了一种多智能体框架——GameVLM,从而增强机器人任务规划中的决策过程。该研究提出了基于 VLM 的决策智能体和专家智能体来执行任务规划。具体来说,决策智能体用于规划任务,专家智能体用于评估这些任务计划。研究引入了零和博弈理论来解决不同智能体之间的不一致性,并确定最佳解决方案。在真实机器人上进行的实验结果表明,所提出的框架非常有效,平均成功率高达 83.3%。
论文链接:
https://arxiv.org/abs/2405.13751
9.AlignGPT:具有自适应对齐功能的多模态大型语言模型
多模态大型语言模型(MLLM)被广泛认为是探索通用人工智能(AGI)的关键。MLLM 的核心在于其实现跨模态对齐的能力。为了实现这一目标,目前的 MLLM 通常采用两阶段训练模式:预训练阶段和指令微调阶段。
尽管这些模型取得了成功,但在对齐能力建模方面仍存在不足。首先,在预训练阶段,模型通常假定所有图像-文本对都是统一对齐的,但实际上不同图像-文本对之间的对齐程度并不一致。其次,目前用于微调的指令包含多种任务,不同任务的指令通常需要不同程度的对齐能力,但以往的 MLLM 忽视了这些差异化的对齐需求。
为了解决这些问题,来自南京大学的研究团队提出了一种新的多模态大型语言模型——AlignGPT。在预训练阶段,他们并不是对所有图像-文本对一视同仁,而是为不同的图像-文本对分配不同级别的对齐能力。然后,在指令微调阶段,他们自适应地组合这些不同级别的对齐能力,以满足不同指令的动态对齐需求。广泛的实验结果表明,AlignGPT 在 12 个基准测试中取得了具有竞争力的性能。
论文链接:
https://arxiv.org/abs/2405.14129
项目地址:
https://aligngpt-vl.github.io/
10.JiuZhang3.0:通过训练小型数据合成模型有效提高数学推理能力
数学推理是大型语言模型(LLMs)在实际应用中的一项重要能力。为了增强这一能力,现有的工作要么是收集大规模数学相关文本进行预训练,要么是依靠更强大的 LLM(如 GPT-4)来合成大规模数学问题。这两类工作通常都会导致训练或合成方面的巨大成本。
为了降低成本,来自中国人民大学的研究团队及其合作者,提出了一种基于开源文本的高效方法,即训练一个小型 LLM 来合成数学问题,从而有效地生成足够的高质量预训练数据。
为此,他们使用 GPT-4 创建了一个数据集,将其数据合成能力提炼到小型 LLM 中。具体来说,他们根据人类教育阶段精心设计了一套提示语,引导 GPT-4 归纳出涵盖不同数学知识和难度水平的问题。此外,让他们还采用了基于梯度的影响估计方法来选择最有价值的数学相关文本。这两者都被输入到 GPT-4 中,用于创建知识提炼数据集,训练小型 LLM。他们利用它合成了 600 万个数学问题,用于预训练 JiuZhang3.0 模型,该模型只需调用 GPT-4 API 9.3k 次,并在 4.6B 数据上进行预训练。实验结果表明,在自然语言推理和工具操作设置下,JiuZhang3.0 在多个数学推理数据集上都取得了 SOTA。
论文链接:
https://arxiv.org/abs/2405.14365
11.DeepSeek-Prover:通过大规模合成数据推进 LLM 中的定理证明
Lean 等证明助手彻底改变了数学证明验证,确保了高准确性和可靠性。尽管大型语言模型(LLM)在数学推理中大有可为,但由于缺乏训练数据,它们在形式定理证明中的发展受到了阻碍。
为了解决这个问题,来自 DeepSeek 和中山大学的研究团队及其合作者,提出了一种从高中和本科生水平的数学竞赛题中生成大量 Lean 4 证明数据的方法。这种方法包括将自然语言问题转化为形式化语句,过滤掉低质量语句,并生成证明以创建合成数据。
DeepSeekMath 7B 模型由 800 万条带有证明的形式化语句组成,在该合成数据集上对该模型进行微调后,模型在 Lean 4 miniF2F 测试中的整体证明生成准确率在 64 个样本中达到了 46.3%,累计达到了 52%,超过了基线 GPT-4 在 64 个样本中的 23.0%,以及树搜索强化学习方法的 41.0%。此外,模型还成功证明了 Lean 4 形式化国际数学奥林匹克(FIMO)基准测试 148 个问题中的 5 个问题,而 GPT-4 则未能证明任何问题。
这些结果证明了利用大规模合成数据提高 LLM 中定理证明能力的潜力。
论文链接:
https://arxiv.org/abs/2405.14333
12.将具身多智能体协作与高效 LLM 结合
由于物理世界的复杂性,将大型语言模型(LLMs)的推理能力与具身任务相结合是具有挑战性的。特别是多机器人协作的 LLM 规划需要机器人之间的交流或信用分配作为反馈,从而重新调整所提出的计划并实现有效协调。然而,现有方法过度依赖物理验证或自我反思,导致对 LLM 的查询过多且效率低下。
在这项工作中,来自清华大学、上海 AI Lab 和西北工业大学的研究团队及其合作者,提出了一种新颖的多机器人协作框架,该框架结合了强化优势反馈(ReAd)来实现计划的高效自我完善。具体来说,他们通过批判回归从 LLM 计划的数据中学习顺序优势函数,然后将 LLM 计划器视为优化器,生成优势函数最大化的行动。它赋予了 LLM 判断行动是否有助于完成最终任务的前瞻性。他们通过将强化学习中的优势加权回归扩展到多智能体系统,提供了理论分析。
在 Overcooked-AI 和 RoCoBench 的一个高难度变体上进行的实验表明,ReAd 在成功率上超过了基线,而且还显著减少了智能体的交互步骤和LLM的查询轮数,证明了它在为LLM打基础方面的高效率。
论文链接:
https://arxiv.org/abs/2405.14314
项目地址:
https://read-llm.github.io/
13.HippoRAG:神经生物学启发的大型语言模型长期记忆法
为了在恶劣和不断变化的自然环境中茁壮成长,哺乳动物的大脑在进化过程中存储了大量有关世界的知识,并不断整合新信息,同时避免灾难性遗忘。尽管取得了令人瞩目的成就,但大型语言模型(LLMs)即使采用了检索增强生成(RAG)技术,仍难以在预训练后高效地整合大量新经验。
在这项工作中,来自俄亥俄州立大学和斯坦福大学的研究团队提出了一种新颖的检索框架——HippoRAG,其灵感来自于人类长期记忆的海马索引理论,能够对新经验进行更深入、更高效的知识整合。HippoRAG 协同协调了 LLM、知识图谱和个性化 PageRank 算法,从而模拟新皮层和海马体在人类记忆中的不同作用。
他们将 HippoRAG 与现有的多跳问题解答 RAG 方法进行了比较,结果表明,这一方法明显优于其他方法,最高可达 20%。与 IRCoT 等迭代检索法相比,使用 HippoRAG 的单步检索法取得了相当或更好的性能,同时成本降低了 10-30 倍,速度提高了 6-13 倍。最后,他们展示了这一方法可以解决现有方法无法解决的新型场景。
论文链接:
https://arxiv.org/abs/2405.14831
GitHub 地址:
https://github.com/OSU-NLP-Group/HippoRAG
相关文章:
大模型日报|今日必读的 13 篇大模型论文
大家好,今日必读的大模型论文来啦! 1.MIT新研究:并非所有语言模型特征都是线性的 最近的研究提出了线性表征假说:语言模型通过操作激活空间中概念(“特征”)的一维表征来执行计算。与此相反,来…...

Python 魂斗罗的音效和动漫效果
一、实现游戏音效 音效是游戏中不可或缺的一部分,它可以为游戏增添氛围和趣味性。在 Pygame 中,我们可以使用 pygame.mixer 模块来播放音效。下面是一个简单的示例代码,演示如何在游戏中播放音效: import pygamepygame.mixer.init…...

Raylib 绘制自定义字体的一种套路
Raylib 绘制自定义字体是真的难搞。我的需求是程序可以加载多种自定义字体,英文中文的都有。 我调试了很久成功了! 很有用的参考,建议先看一遍: 瞿华:raylib绘制中文内容 个人笔记|Raylib 的字体使用 - …...

C++学习笔记(21)——继承
目录 1. 继承的概念及定义1.1 继承的概念1.2 继承定义1.2.1 定义格式1.2.2 继承关系和访问限定符1.2.3 继承基类成员访问方式的变化 继承的概念总结: 2. 基类和派生类对象赋值转换3.继承中的作用域4.派生类的默认成员函数知识点:派生类中6个默认成员函数…...

DOS学习-目录与文件应用操作经典案例-more
新书上架~👇全国包邮奥~ python实用小工具开发教程http://pythontoolsteach.com/3 欢迎关注我👆,收藏下次不迷路┗|`O′|┛ 嗷~~ 目录 一.前言 二.使用 三.案例 一.前言 DOS系统的more命令是一个用于查看文本文件内容的工具。…...

android 在 Activity 的 onCreate 中获取View 的宽高
view 的 post 执行时,首先会判断view 的 mAttatchInfo 是否为空,如果不为空,则将Runnable 添加到mAttachInfo.handler 的 UI线程MessageQueue 中;如果为空,则先将Runnable 暂存在view 的类为HandlerActionQueue的mRunQ…...

Pod进阶——资源限制以及探针检查
目录 一、资源限制 1、资源限制定义: 2、资源限制request和limit资源约束 3、Pod和容器的资源请求和限制 4、官方文档示例 5、CPU资源单位 6、内存资源单位 7、资源限制实例 ①编写yaml资源配置清单 ②释放内存(node节点,以node01为…...
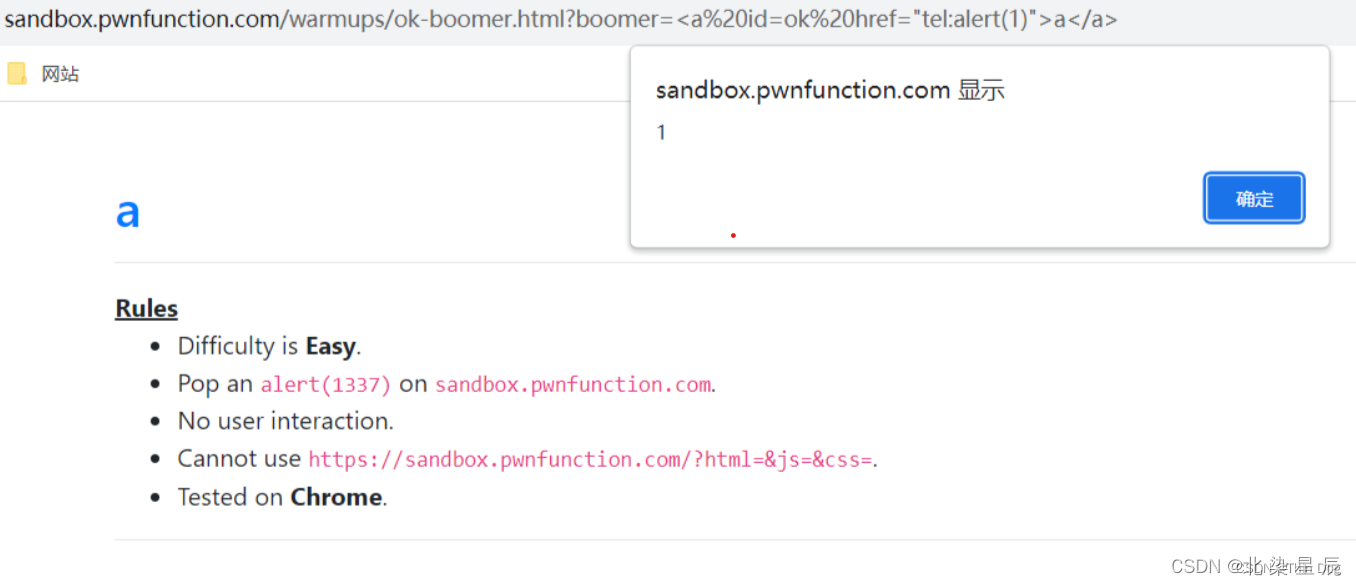
XSS---DOM破坏
文章目录 前言一、pandas是什么?二、使用步骤 1.引入库2.读入数据总结 一.什么是DOM破坏 在HTML中,如果使用一些特定的属性名(如id或name)给DOM元素命名,这些属性会在全局作用域中创建同名的全局变量,指向对…...

2024电工杯数学建模B 题:大学生平衡膳食食谱的优化设计
背景: 大学时代是学知识长身体的重要阶段, 同时也是良好饮食习惯形成的重要时期。这一特 定年龄段的年轻人, 不仅身体发育需要有充足的能量和各种营养素, 而且繁重的脑力劳动和 较大量的体育锻炼也需要消耗大量的能源物质。 大学生…...
)
LeetCode 1542.找出最长的超赞子字符串:前缀异或和(位运算)
【LetMeFly】1542.找出最长的超赞子字符串:前缀异或和(位运算) 力扣题目链接:https://leetcode.cn/problems/find-longest-awesome-substring/ 给你一个字符串 s 。请返回 s 中最长的 超赞子字符串 的长度。 「超赞子字符串」需…...

LLM企业应用落地场景中的问题概览
三个问题 AI思维快速工具:需要对接LLM的API、控制幻觉、管理知识库。POC验证四个难点 私有化部署的环境:包括网络和服务器环境。交互友好意想不到的情况方向选择:让客户做目标和方向的选择问题 一、RAG 多跳问题 通常发生在报告编写的数据整理环节,比如要从一堆报表中找…...
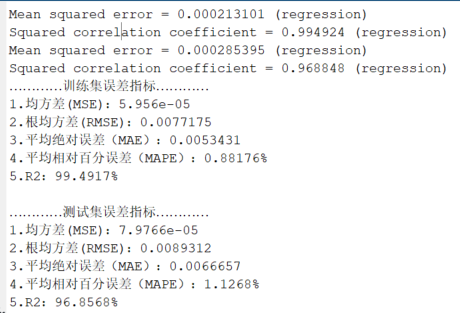
基于灰狼优化算法优化支持向量机(GWO-SVM)时序预测
代码原理及流程 基于灰狼优化算法优化支持向量机(GWO-SVM)的时序预测代码的原理和流程如下: 1. **数据准备**:准备时序预测的数据集,将数据集按照时间顺序划分为训练集和测试集。 2. **初始化灰狼群体和SVM模型参数…...

C++中获取int最大与最小值
不知道大家有没有遇到过这种要求:“返回值必须是int,如果整数数超过 32 位有符号整数范围 [−2^31, 2^31 − 1] ,需要截断这个整数,使其保持在这个范围内。例如,小于 −2^31 的整数应该被固定为 −2^31 ,大…...
学习通高分免费刷课实操教程
文章目录 概要整体架构流程详细步骤云上全平台登录步骤小结 概要 我之前提到过一个通过浏览器的三个脚本就可以免费高分刷课的文章,由于不方便拍视频进行实操演示,然后写下了这个实操教程,之前的三个脚本划到文章末尾 整体架构流程 整体大…...

缓存降级
当Redis缓存出现问题或者无法正常工作时,需要有一种应对措施,避免直接访问数据库而导致整个系统瘫痪。缓存降级就是这样一种机制。 主要的缓存降级策略包括: 本地缓存降级 当Redis缓存不可用时,可以先尝试使用本地进程内缓存,如Guava Cache或Caffeine等。这样可以减少对Redis…...
PyQt6--Python桌面开发(32.QMenuBar菜单栏控件)
QMenuBar菜单栏控件 选择Main Window...

golang创建式设计模式---工厂模式
创建式设计模式—工厂模式 目录导航 创建式设计模式---工厂模式1)什么是工厂模式2)使用场景3)实现方式4)实践案例5)优缺点分析 1)什么是工厂模式 工厂模式(Factory Method Pattern)是一种设计模式,旨在创建对象时,将对象的创建与使用进行分离。通过定义…...

高精度定位平板主要应用在哪些领域
高精度定位平板是一种集成了高精度定位技术和强大计算能力的设备,能够提供亚米级甚至厘米级的定位精度。其应用领域广泛,涵盖测绘、精准农业、工程建设、地理信息系统(GIS)、公共安全等多个方面。这种设备凭借其高精度和耐用性&am…...

conda使用常用命令
Conda是一个非常常用的Python包管理器,也是Anaconda Python发行版的一部分。它可以帮助用户安装、更新、卸载Python包,以及管理Python虚拟环境。在这篇博客中,我们将总结一些常用的Conda命令及其用法。 安装和更新Conda 在使用Conda之前&…...
22-LINUX--多线程and多进程TCP连接
一.TCP连接基础知识 1.套接字 所谓套接字(Socket),就是对网络中不同主机上的应用进程之间进行双向通信的端点的抽象。一个套接字就是网络上进程通信的一端,提供了应用层进程利用网络协议交换数据的机制。从所处的地位来讲,套接字上联应用进程…...

ZYNQ平台开源EtherCAT主站部署与实时运动控制优化实践
1. 项目概述与核心价值最近在做一个基于ZYNQ的工业运动控制项目,客户对多轴同步的实时性和抖动要求非常高,传统的脉冲或总线方案在复杂轨迹规划下显得有些力不从心。经过一番调研和选型,最终决定上马EtherCAT总线。作为工业以太网领域的“性能…...

【芯片测试】:自定义波形与条件波形
第四篇:进阶篇(上)—— 用户自定义波形与条件波形 系列:《VCDSTIL 实战:从仿真波形到 ATE 测试向量》第 4 篇(共 5 篇) 前言 前三篇介绍的都是 VCDSTIL 的"自动提取"模式:…...

Miro致力弥合AI潜力与组织现实之间的鸿沟
Miro在Canvas 26上将其AI平台建设成为现代AI生态系统的连接层 — 汇聚团队、智能体以及已经使用的工具,将个体AI生产率变为整个组织的转型 Miro是一个面向团队的人工智能(AI)创新工作空间。该公司宣布推出多项AI平台创新,强化了其…...

Go 内存优化骚操作
1. 零内存占位符:struct{}{}原理:struct{} 是空结构体,Go 编译器对其做了特殊处理,它在内存中不占任何空间(大小为 0 字节)。场景 A:实现集合 (Set)map[string]struct{}。比起 map[string]bool&…...

大学生零基础打CTF比赛全攻略:要学啥、怎么学,看完就能参赛
大学生零基础打CTF比赛全攻略:要学啥、怎么学,看完就能参赛(干货版) 摘要:对大学生来说,CTF(Capture The Flag,夺旗赛)不仅是网络安全领域最具实战性的竞赛,…...
)
【MATLAB】人脸表情识别与情感分析程序(工程实操版)
【MATLAB】人脸表情识别与情感分析程序(工程实操版) 摘要:人脸表情是人类情感表达的核心载体,人脸表情识别与情感分析技术融合了计算机视觉、图像处理、模式识别等多领域知识,广泛应用于人机交互、心理评估、智能安防、教育教学等场景。传统表情识别依赖人工判断,存在主…...

Prism Launcher:重新定义你的Minecraft启动体验
Prism Launcher:重新定义你的Minecraft启动体验 【免费下载链接】PrismLauncher A custom launcher for Minecraft that allows you to easily manage multiple installations of Minecraft at once (Fork of MultiMC) 项目地址: https://gitcode.com/gh_mirrors/…...
)
别再傻傻重启了!用JRebel插件实现Spring Boot项目秒级热更新(附2024最新激活与配置避坑指南)
解锁Spring Boot开发新姿势:JRebel热更新实战全攻略 每次修改完代码后,那个漫长的等待重启进度条的过程,是不是让你忍不住想砸键盘?作为经历过数百次Spring Boot项目重启的老司机,我完全理解这种抓狂感。直到遇见了JR…...

终极指南:免费实现Zwift离线骑行模拟的完整方案
终极指南:免费实现Zwift离线骑行模拟的完整方案 【免费下载链接】zwift-offline Use Zwift offline 项目地址: https://gitcode.com/gh_mirrors/zw/zwift-offline 想要在没有网络连接的情况下享受Zwift专业骑行训练吗?Zwift-Offline开源项目为你提…...

实战指南:高效部署企业级网络监控系统ElastiFlow的完整方案
实战指南:高效部署企业级网络监控系统ElastiFlow的完整方案 【免费下载链接】elastiflow Network flow analytics (Netflow, sFlow and IPFIX) with the Elastic Stack 项目地址: https://gitcode.com/gh_mirrors/el/elastiflow ElastiFlow是一款基于Elastic…...