yolov8推理由avi改为mp4
修改\ultralytics-main\ultralytics\engine\predictor.py,即可
# Ultralytics YOLO 🚀, AGPL-3.0 license
"""
Run prediction on images, videos, directories, globs, YouTube, webcam, streams, etc.Usage - sources:$ yolo mode=predict model=yolov8n.pt source=0 # webcamimg.jpg # imagevid.mp4 # videoscreen # screenshotpath/ # directorylist.txt # list of imageslist.streams # list of streams'path/*.jpg' # glob'https://youtu.be/LNwODJXcvt4' # YouTube'rtsp://example.com/media.mp4' # RTSP, RTMP, HTTP, TCP streamUsage - formats:$ yolo mode=predict model=yolov8n.pt # PyTorchyolov8n.torchscript # TorchScriptyolov8n.onnx # ONNX Runtime or OpenCV DNN with dnn=Trueyolov8n_openvino_model # OpenVINOyolov8n.engine # TensorRTyolov8n.mlpackage # CoreML (macOS-only)yolov8n_saved_model # TensorFlow SavedModelyolov8n.pb # TensorFlow GraphDefyolov8n.tflite # TensorFlow Liteyolov8n_edgetpu.tflite # TensorFlow Edge TPUyolov8n_paddle_model # PaddlePaddleyolov8n_ncnn_model # NCNN
"""import platform
import re
import threading
from pathlib import Pathimport cv2
import numpy as np
import torchfrom ultralytics.cfg import get_cfg, get_save_dir
from ultralytics.data import load_inference_source
from ultralytics.data.augment import LetterBox, classify_transforms
from ultralytics.nn.autobackend import AutoBackend
from ultralytics.utils import DEFAULT_CFG, LOGGER, MACOS, WINDOWS, callbacks, colorstr, ops
from ultralytics.utils.checks import check_imgsz, check_imshow
from ultralytics.utils.files import increment_path
from ultralytics.utils.torch_utils import select_device, smart_inference_modeSTREAM_WARNING = """
WARNING ⚠️ inference results will accumulate in RAM unless `stream=True` is passed, causing potential out-of-memory
errors for large sources or long-running streams and videos. See https://docs.ultralytics.com/modes/predict/ for help.Example:results = model(source=..., stream=True) # generator of Results objectsfor r in results:boxes = r.boxes # Boxes object for bbox outputsmasks = r.masks # Masks object for segment masks outputsprobs = r.probs # Class probabilities for classification outputs
"""class BasePredictor:"""BasePredictor.A base class for creating predictors.Attributes:args (SimpleNamespace): Configuration for the predictor.save_dir (Path): Directory to save results.done_warmup (bool): Whether the predictor has finished setup.model (nn.Module): Model used for prediction.data (dict): Data configuration.device (torch.device): Device used for prediction.dataset (Dataset): Dataset used for prediction.vid_writer (dict): Dictionary of {save_path: video_writer, ...} writer for saving video output."""def __init__(self, cfg=DEFAULT_CFG, overrides=None, _callbacks=None):"""Initializes the BasePredictor class.Args:cfg (str, optional): Path to a configuration file. Defaults to DEFAULT_CFG.overrides (dict, optional): Configuration overrides. Defaults to None."""self.args = get_cfg(cfg, overrides)self.save_dir = get_save_dir(self.args)if self.args.conf is None:self.args.conf = 0.25 # default conf=0.25self.done_warmup = Falseif self.args.show:self.args.show = check_imshow(warn=True)# Usable if setup is doneself.model = Noneself.data = self.args.data # data_dictself.imgsz = Noneself.device = Noneself.dataset = Noneself.vid_writer = {} # dict of {save_path: video_writer, ...}self.plotted_img = Noneself.source_type = Noneself.seen = 0self.windows = []self.batch = Noneself.results = Noneself.transforms = Noneself.callbacks = _callbacks or callbacks.get_default_callbacks()self.txt_path = Noneself._lock = threading.Lock() # for automatic thread-safe inferencecallbacks.add_integration_callbacks(self)def preprocess(self, im):"""Prepares input image before inference.Args:im (torch.Tensor | List(np.ndarray)): BCHW for tensor, [(HWC) x B] for list."""not_tensor = not isinstance(im, torch.Tensor)if not_tensor:im = np.stack(self.pre_transform(im))im = im[..., ::-1].transpose((0, 3, 1, 2)) # BGR to RGB, BHWC to BCHW, (n, 3, h, w)im = np.ascontiguousarray(im) # contiguousim = torch.from_numpy(im)im = im.to(self.device)im = im.half() if self.model.fp16 else im.float() # uint8 to fp16/32if not_tensor:im /= 255 # 0 - 255 to 0.0 - 1.0return imdef inference(self, im, *args, **kwargs):"""Runs inference on a given image using the specified model and arguments."""visualize = (increment_path(self.save_dir / Path(self.batch[0][0]).stem, mkdir=True)if self.args.visualize and (not self.source_type.tensor)else False)return self.model(im, augment=self.args.augment, visualize=visualize, embed=self.args.embed, *args, **kwargs)def pre_transform(self, im):"""Pre-transform input image before inference.Args:im (List(np.ndarray)): (N, 3, h, w) for tensor, [(h, w, 3) x N] for list.Returns:(list): A list of transformed images."""same_shapes = len({x.shape for x in im}) == 1letterbox = LetterBox(self.imgsz, auto=same_shapes and self.model.pt, stride=self.model.stride)return [letterbox(image=x) for x in im]def postprocess(self, preds, img, orig_imgs):"""Post-processes predictions for an image and returns them."""return predsdef __call__(self, source=None, model=None, stream=False, *args, **kwargs):"""Performs inference on an image or stream."""self.stream = streamif stream:return self.stream_inference(source, model, *args, **kwargs)else:return list(self.stream_inference(source, model, *args, **kwargs)) # merge list of Result into onedef predict_cli(self, source=None, model=None):"""Method used for CLI prediction.It uses always generator as outputs as not required by CLI mode."""gen = self.stream_inference(source, model)for _ in gen: # noqa, running CLI inference without accumulating any outputs (do not modify)passdef setup_source(self, source):"""Sets up source and inference mode."""self.imgsz = check_imgsz(self.args.imgsz, stride=self.model.stride, min_dim=2) # check image sizeself.transforms = (getattr(self.model.model,"transforms",classify_transforms(self.imgsz[0], crop_fraction=self.args.crop_fraction),)if self.args.task == "classify"else None)self.dataset = load_inference_source(source=source,batch=self.args.batch,vid_stride=self.args.vid_stride,buffer=self.args.stream_buffer,)self.source_type = self.dataset.source_typeif not getattr(self, "stream", True) and (self.source_type.streamor self.source_type.screenshotor len(self.dataset) > 1000 # many imagesor any(getattr(self.dataset, "video_flag", [False]))): # videosLOGGER.warning(STREAM_WARNING)self.vid_writer = {}@smart_inference_mode()def stream_inference(self, source=None, model=None, *args, **kwargs):"""Streams real-time inference on camera feed and saves results to file."""if self.args.verbose:LOGGER.info("")# Setup modelif not self.model:self.setup_model(model)with self._lock: # for thread-safe inference# Setup source every time predict is calledself.setup_source(source if source is not None else self.args.source)# Check if save_dir/ label file existsif self.args.save or self.args.save_txt:(self.save_dir / "labels" if self.args.save_txt else self.save_dir).mkdir(parents=True, exist_ok=True)# Warmup modelif not self.done_warmup:self.model.warmup(imgsz=(1 if self.model.pt or self.model.triton else self.dataset.bs, 3, *self.imgsz))self.done_warmup = Trueself.seen, self.windows, self.batch = 0, [], Noneprofilers = (ops.Profile(device=self.device),ops.Profile(device=self.device),ops.Profile(device=self.device),)self.run_callbacks("on_predict_start")for self.batch in self.dataset:self.run_callbacks("on_predict_batch_start")paths, im0s, s = self.batch# Preprocesswith profilers[0]:im = self.preprocess(im0s)# Inferencewith profilers[1]:preds = self.inference(im, *args, **kwargs)if self.args.embed:yield from [preds] if isinstance(preds, torch.Tensor) else preds # yield embedding tensorscontinue# Postprocesswith profilers[2]:self.results = self.postprocess(preds, im, im0s)self.run_callbacks("on_predict_postprocess_end")# Visualize, save, write resultsn = len(im0s)for i in range(n):self.seen += 1self.results[i].speed = {"preprocess": profilers[0].dt * 1e3 / n,"inference": profilers[1].dt * 1e3 / n,"postprocess": profilers[2].dt * 1e3 / n,}if self.args.verbose or self.args.save or self.args.save_txt or self.args.show:s[i] += self.write_results(i, Path(paths[i]), im, s)# Print batch resultsif self.args.verbose:LOGGER.info("\n".join(s))self.run_callbacks("on_predict_batch_end")yield from self.results# Release assetsfor v in self.vid_writer.values():if isinstance(v, cv2.VideoWriter):v.release()# Print final resultsif self.args.verbose and self.seen:t = tuple(x.t / self.seen * 1e3 for x in profilers) # speeds per imageLOGGER.info(f"Speed: %.1fms preprocess, %.1fms inference, %.1fms postprocess per image at shape "f"{(min(self.args.batch, self.seen), 3, *im.shape[2:])}" % t)if self.args.save or self.args.save_txt or self.args.save_crop:nl = len(list(self.save_dir.glob("labels/*.txt"))) # number of labelss = f"\n{nl} label{'s' * (nl > 1)} saved to {self.save_dir / 'labels'}" if self.args.save_txt else ""LOGGER.info(f"Results saved to {colorstr('bold', self.save_dir)}{s}")self.run_callbacks("on_predict_end")def setup_model(self, model, verbose=True):"""Initialize YOLO model with given parameters and set it to evaluation mode."""self.model = AutoBackend(weights=model or self.args.model,device=select_device(self.args.device, verbose=verbose),dnn=self.args.dnn,data=self.args.data,fp16=self.args.half,batch=self.args.batch,fuse=True,verbose=verbose,)self.device = self.model.device # update deviceself.args.half = self.model.fp16 # update halfself.model.eval()def write_results(self, i, p, im, s):"""Write inference results to a file or directory."""string = "" # print stringif len(im.shape) == 3:im = im[None] # expand for batch dimif self.source_type.stream or self.source_type.from_img or self.source_type.tensor: # batch_size >= 1string += f"{i}: "frame = self.dataset.countelse:match = re.search(r"frame (\d+)/", s[i])frame = int(match.group(1)) if match else None # 0 if frame undeterminedself.txt_path = self.save_dir / "labels" / (p.stem + ("" if self.dataset.mode == "image" else f"_{frame}"))string += "%gx%g " % im.shape[2:]result = self.results[i]result.save_dir = self.save_dir.__str__() # used in other locationsstring += result.verbose() + f"{result.speed['inference']:.1f}ms"# Add predictions to imageif self.args.save or self.args.show:self.plotted_img = result.plot(line_width=self.args.line_width,boxes=self.args.show_boxes,conf=self.args.show_conf,labels=self.args.show_labels,im_gpu=None if self.args.retina_masks else im[i],)# Save resultsif self.args.save_txt:result.save_txt(f"{self.txt_path}.txt", save_conf=self.args.save_conf)if self.args.save_crop:result.save_crop(save_dir=self.save_dir / "crops", file_name=self.txt_path.stem)if self.args.show:self.show(str(p))if self.args.save:self.save_predicted_images(str(self.save_dir / p.name), frame)return stringdef save_predicted_images(self, save_path="", frame=0):"""Save video predictions as mp4 at specified path."""im = self.plotted_img# Save videos and streamsif self.dataset.mode in {"stream", "video"}:fps = self.dataset.fps if self.dataset.mode == "video" else 30frames_path = f'{save_path.split(".", 1)[0]}_frames/'if save_path not in self.vid_writer: # new videoif self.args.save_frames:Path(frames_path).mkdir(parents=True, exist_ok=True)# Always save as MP4 regardless of OSsuffix, fourcc = (".mp4", "avc1")self.vid_writer[save_path] = cv2.VideoWriter(filename=str(Path(save_path).with_suffix(suffix)),fourcc=cv2.VideoWriter_fourcc(*fourcc),fps=fps, # integer required, floats produce error in MP4 codecframeSize=(im.shape[1], im.shape[0]), # (width, height))# Save videoself.vid_writer[save_path].write(im)if self.args.save_frames:cv2.imwrite(f"{frames_path}{frame}.jpg", im)# Save imageselse:cv2.imwrite(save_path, im)def show(self, p=""):"""Display an image in a window using OpenCV imshow()."""im = self.plotted_imgif platform.system() == "Linux" and p not in self.windows:self.windows.append(p)cv2.namedWindow(p, cv2.WINDOW_NORMAL | cv2.WINDOW_KEEPRATIO) # allow window resize (Linux)cv2.resizeWindow(p, im.shape[1], im.shape[0]) # (width, height)cv2.imshow(p, im)cv2.waitKey(300 if self.dataset.mode == "image" else 1) # 1 milliseconddef run_callbacks(self, event: str):"""Runs all registered callbacks for a specific event."""for callback in self.callbacks.get(event, []):callback(self)def add_callback(self, event: str, func):"""Add callback."""self.callbacks[event].append(func)
相关文章:

yolov8推理由avi改为mp4
修改\ultralytics-main\ultralytics\engine\predictor.py,即可 # Ultralytics YOLO 🚀, AGPL-3.0 license """ Run prediction on images, videos, directories, globs, YouTube, webcam, streams, etc.Usage - sources:$ yolo modepred…...

Vue3设置缓存:storage.ts
在vue文件使用: import { Local,Session } from //utils/storage; // Local if (!Local.get(字段名)) Local.set(字段名, 字段的值);// Session Session.getToken()storage.ts文件: import Cookies from js-cookie;/*** window.localStorage 浏览器永…...

如何用AI工具提升日常工作效率,帮我们提速增效减负
昨天,coze海外版支持了GPT4o, 立马体验了下,速度杠杠的。 https://www.coze.com 支持chatGP和gemini模型,需要科学上网。国内 https://www.coze.cn支持语雀、KIMI模型。 这里回到正题, 如何用AI工具提升日常工作效率…...

C++: 优先级队列的模拟实现和deque
目录 一、优先级队列 1.1优先级队列 priority_queue介绍 1.2优先级队列的使用 1.3priority_queue的模拟实现 二、deque 2.1deque介绍 2.2deque的优缺点 2.3为什么选择deque作为stack和queue的底层默认容器 一、优先级队列 1.1优先级队列 priority_queue介绍 1.11 优先级队…...

C++ socket epoll IO多路复用
IO多路复用通常用于处理单进程高并发,在Linux中,一切皆文件,一个socket连接会对应一个文件描述符,在监听多个文件描述符的状态应用中epoll相对于select和poll效率更高 epoll本质是系统在内核维护了一颗红黑树,监听的文…...
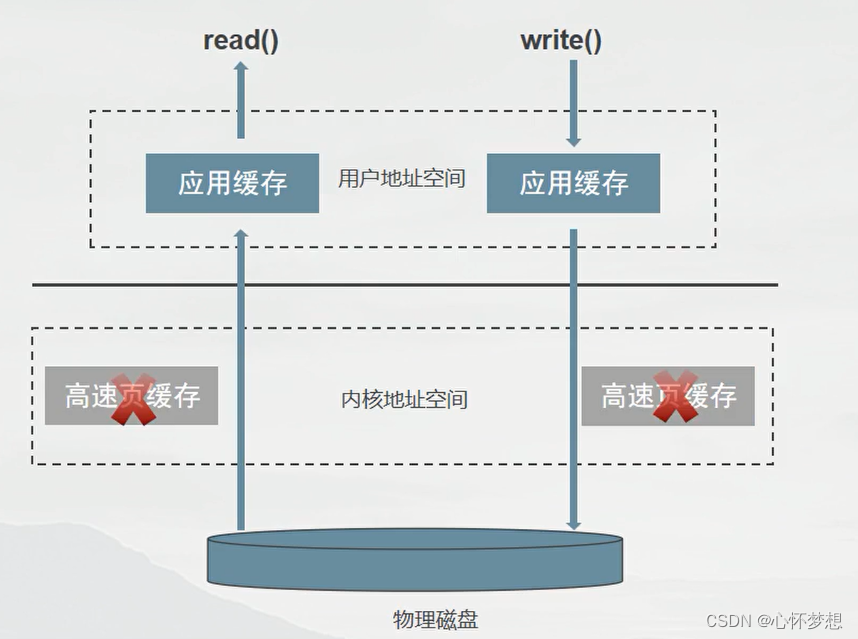
缓存IO与直接IO
IO类型 缓存 I/O 缓存 I/O 又被称作标准 I/O,大多数文件系统的默认 I/O 操作都是缓存 I/O。在 Linux 的缓存 I/O 机制中,数据先从磁盘复制到内核空间的缓冲区,然后从内核空间缓冲区复制到应用程序的地址空间(用户空间࿰…...
输入输出(3)——C++的标准输入流
目录 一、cin 流 二、成员函数 get 获取一个字符 (一)无参数的get函数。 (二)有一个参数的get函数。 (三)有3个参数的get函数 (四)用成员函数 getline 函数读取一行字符 (五)用成员函数 read 读取一串字符 (六)istream 类…...

[力扣题解] 344. 反转字符串
题目:344. 反转字符串 思路 双指针法 代码 class Solution { public:void reverseString(vector<char>& s) {int i, j, temp;for(i 0, j s.size()-1; i < j; i, j--){temp s[j];s[j] s[i];s[i] temp;}} };...

找不到msvcr110.dll无法继续执行代码的原因分析及解决方法
在计算机使用过程中,我们经常会遇到一些错误提示,其中之一就是找不到msvcr110.dll文件。这个错误通常发生在运行某些程序或游戏时,系统无法找到所需的动态链接库文件。为了解决这个问题,下面我将介绍5种常见的解决方法。 一&#…...
数据技术篇之日志采集)
深入理解数仓开发(一)数据技术篇之日志采集
前言 今天开始重新回顾电商数仓项目,结合《阿里巴巴大数据之路》和尚硅谷的《剑指大数据——企业级电商数据仓库项目实战 精华版》来进行第二次深入理解学习。之前第一次学习数仓,虽然尽量放慢速度力求深入理解,但是不可能一遍掌握࿰…...

Edge浏览器:重新定义现代网页浏览
引言 - Edge的起源与重生 Edge浏览器,作为Microsoft Windows标志性的互联网窗口,源起于1995年的Internet Explorer。在网络发展的浪潮中,IE曾是无可争议的霸主,但随着技术革新与用户需求的演变,它面临的竞争日益激烈。…...

HDFS,HBase,MySQL,Elasticsearch ,MongoDB分别适合存储什么特征的数据?
HDFS(Hadoop Distributed File System)通常用于存储大规模数据,适合存储结构化和非结构化数据,例如文本文件、日志数据、图像和视频等。 HBase是基于Hadoop的分布式数据库,适合存储大量非结构化和半结构化的数据&…...

ArcGIS中离线发布路径分析服务,并实现小车根据路径进行运动
ArcGIS中离线发布路径分析服务,您可以按照以下步骤操作: 准备ArcMap项目: 打开ArcMap并加载包含网络分析图层的项目。在ArcMap中,使用 Network Analyst Toolbar 或 Catalog 创建网络数据集(Network Dataset)…...

时政|医疗结果互认
背景(存在的问题) 看同一种病,换一家医院甚至换一个院区、换一个科室,检查检验还得再来一遍,费钱又费时。开展检查检验结果互认,可以明显减轻患者就医负担。患者不用做重复检查,也可节约就医时…...
华为OD机试【找出通过车辆最多颜色】(java)(100分)
1、题目描述 在一个狭小的路口,每秒只能通过一辆车,假设车辆的颜色只有 3 种,找出 N 秒内经过的最多颜色的车辆数量。 三种颜色编号为0 ,1 ,2。 2、输入描述 第一行输入的是通过的车辆颜色信息[0,1,1,2] ࿰…...

hyperf 多对多关联模型
这里使用到三张表,一张是用户(users),一张是角色(roles),一张是用户角色关联表(users_roles), 首先创建用户模型、角色模型 php bin/hyperf.php gen:model users php bin/hyperf.php gen:model rolesusers…...
)
每日力扣刷题day03(从零开始版)
文章目录 2024.5.24(5题)2828.判别首字母缩略词题解一题解二 1365.有多少小于当前数字的数字题解一题解二题解三 2469.温度转换题解一题解二 1502.判断能否形成等差数列题解一题解二 2351.第一个出现两次的字母题解一题解二 2024.5.24(5题&am…...

误差反向传播简介与实现
误差反向传播 导语计算图反向传播链式法则 反向传播结构加法节点乘法节点 实现简单层加法乘法 激活函数层实现ReLUSigmoid Affine/Softmax层实现Affine基础版批版本 Softmax-with-Loss 误差反向传播实现梯度确认总结参考文献 导语 书上在前一章介绍了随机梯度下降法进行参数与…...
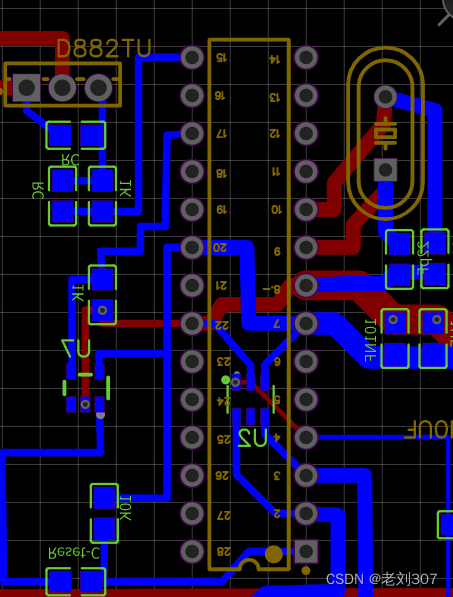
ATmega328P加硬件看门狗MAX824L看门狗
void Reversewdt(){ //硬件喂狗,11PIN接MAX824L芯片WDIif (digitalRead(11) HIGH) {digitalWrite(11, LOW); //低电平} else {digitalWrite(11, HIGH); //高电平 }loop增加喂狗调用 void loop() { …… Reversewdt();//喂狗 }...
)
Goframe项目实战:从数据库表到API接口的全链路开发指南(含避坑点)
Goframe项目实战:从数据库表到API接口的全链路开发指南(含避坑点)在当今微服务架构盛行的时代,Go语言因其高性能和并发优势成为后端开发的热门选择。而Goframe作为一款企业级的Go应用开发框架,提供了从数据库操作到API…...
)
从STM32迁移到普冉PY32F003:UART代码移植保姆级教程(附HAL库对比)
从STM32到普冉PY32F003的UART代码迁移实战指南 1. 国产MCU替代浪潮下的技术选择 近年来,半导体行业的供应链波动促使更多工程师将目光投向国产MCU解决方案。普冉PY32F003系列作为Cortex-M0内核的代表产品,以48MHz主频、64KB Flash和8KB RAM的配置&#x…...

DIY复刻经典:Texar Audio Prism动态处理器克隆套件全攻略
1. 项目概述:Texar Audio Prism 克隆套件如果你在专业音频圈子里混过一段时间,尤其是对上世纪八九十年代那些经典的、带点“魔法”色彩的外置动态处理器感兴趣,那么“Texar Audio Prism”这个名字你大概率不会陌生。它不是最常见的1176或者LA…...

【DeepSeek测试用例生成实战指南】:20年QA专家亲授5大高覆盖率生成模式与3个避坑红线
更多请点击: https://codechina.net 第一章:DeepSeek测试用例生成的核心价值与适用边界 DeepSeek系列大模型在代码理解与生成任务中展现出显著的上下文建模能力,其测试用例生成功能并非通用“黑盒测试器”,而是聚焦于**单元级、函…...
Transient、QuickEye、VerifyEye傻傻分不清?一文讲透Ansys里三种眼图仿真方法的适用场景与避坑指南
Transient、QuickEye、VerifyEye深度解析:Ansys眼图仿真技术选型实战指南 在高速数字系统设计中,眼图分析是评估信号完整性的黄金标准。面对Ansys工具链中三种截然不同的眼图生成方法,工程师常常陷入选择困境——是追求精确度的传统瞬态分析&…...

LizzieYzy:你的智能围棋教练,让AI分析变得简单有趣 [特殊字符]
LizzieYzy:你的智能围棋教练,让AI分析变得简单有趣 🎯 【免费下载链接】lizzieyzy LizzieYzy - GUI for Game of Go 项目地址: https://gitcode.com/gh_mirrors/li/lizzieyzy 还在为复盘找不到关键点而烦恼吗?想提升棋力却…...

Hindsight API参考:REST接口完整文档
Hindsight API参考:REST接口完整文档 【免费下载链接】hindsight Hindsight: Agent Memory That Learns 项目地址: https://gitcode.com/GitHub_Trending/hindsight2/hindsight Hindsight是一个强大的Agent Memory系统,提供了全面的REST API接口&…...

终极指南:用D2DX让《暗黑破坏神2》在现代电脑上焕发新生
终极指南:用D2DX让《暗黑破坏神2》在现代电脑上焕发新生 【免费下载链接】d2dx D2DX is a complete solution to make Diablo II run well on modern PCs, with high fps and better resolutions. 项目地址: https://gitcode.com/gh_mirrors/d2/d2dx 还在为经…...

告别坐标点击!用Poco精准定位UI控件,让你的Airtest安卓自动化脚本更稳定
告别坐标点击!用Poco精准定位UI控件,让你的Airtest安卓自动化脚本更稳定每次UI微调就导致脚本大面积失效?分辨率变化让精心编写的自动化测试瞬间崩溃?作为从坐标点击转型到控件识别的实践者,我深刻理解这种挫败感。三年…...

如何优化 MySQL 千万级数据分页查询的性能?
它的本质是:**传统 LIMIT offset, size 在大数据量下性能急剧下降,是因为 MySQL 必须 扫描并丢弃 前 offset 行数据。当 offset 很大时(如 LIMIT 1000000, 10),MySQL 需要读取 1,000,010 行记录,执行 1,000…...