大数据开发面试题【Spark篇】
115、Spark的任务执行流程
driver和executor,结构式一主多从模式,
driver:spark的驱动节点,用于执行spark任务中的main方法,负责实际代码的执行工作;主要负责:将代码逻辑转换为任务、在executor之间调度任务、跟踪executor的执行情况。
Executor:spark的执行节点,是jvm的一个进程,负责在spark作业中运行具体的任务,任务之间相互独立,spark应用启动时候,executor节点被同时启动,伴随整个spark应用的生命周期而存在;
主要功能:负责运行组成spark应用的任务,并将结果返回给驱动进程、
在任务提交之后,都先启动driver,然后driver向集群管理中注册应用程序,根据任务的配置文件分配executor并启动,然后driver等待资源满足,执行main函数;spark为懒加载,当执行到action算子时候才开始真正执行,开始反向推算,根据宽依赖进行stage的划分,随后每一个stage对应一个个taskset,一个taskset中有多个task,task会被指定到executor中执行,
116、Spark提交job的流程
117、Spark的阶段划分
spark的阶段划分分为两个阶段:转换阶段和动作阶段,分别对应转换算子和行动算子
每遇到一个宽依赖就划分一个stage
在一个stage内部会有很多task被执行,同一个stage中所有的task结束之后才能根据DAG依赖执行下一个stage中的task
阶段:划分stage的依据就是RDD之间的宽窄依赖,遇到宽依赖就划分stage,每个stage包含一个或者多个task任务,stage是由一组并行的task组成;切割规则:遇到宽依赖就切割stage(遇到一个shuffle就转为一个新的阶段)
阶段的划分等于shuffle依赖的数量+1
根据行动算子划分job、根据shuffle划分stage、根据RDD的分区数划分Task(Job>stage>task,一个job中可以有多个stage,一个stage中可以多个task)
118、Sparkjoin的分类
根据join操作方式进行分类,分为shuffle join和broadcastjoin
Shuffle join:spark将参与join操作的数据集按照join的条件进行分区,并将具有相同键的数据分发到同一个节点上进行join操作
Broadcast join:spark将一个较小的数据集复制到每一个节点的内存中,然后将参与join操作的大数据集分发到各个节点上进行join操作(通常进行大表join小表)
119、spark mapjoin的实现原理
Map join在内存中将两个数据集进行连接,从而避免磁盘io的开销
1、数据划分:spark将两个数据集划分为多个分区,每个分区的数据流尽可能均匀
2、数据广播:spark将其中一个较小的数据集广播到每一个节点的内存中
3、分区处理:每个节点接收到广播的数据后,将其本地的另一个数据集进行联接操作
4、结果汇总:每个节点将自己的结果发送到驱动节点,由驱动节点进行最终的节点汇总(map join适用于,两个数据集至少有一个可以完全放入内存中)
120、spark shuffle以及优点
可以用于在数据分区过程中重新分配和重组数据,在spark执行对数据进行重分区或者聚合操作时候,将数据重新发送到不同的节点上,进行下一步的计算
优点:
数据本地性:shuffle可以在节点之间移动数据,以便在计算过程中最大限度地利用数据本地性,减少数据传输过程中的开销
分布式计算:shuffle运行spark在多个节点之间执行计算的时候,从而实现了分布式计算的能力
补充:Spark的shuffle怎么了解?能讲讲Spark的shuffle的过程吗?
121、什么时候会产生shuffle
数据重分区:需要将数据重新分区进行后续的数据处理操作时候
聚合操作:当需要对数据进行聚合操作时候,会使用到shuffle操作
排序操作:需要对数据进行排序的时候,使用shuffle
122、spark为什么适合迭代处理
spark是基于内存计算的,存储的数据在内存中,而不是在磁盘上,从而提高了数据处理的速度
可以保留中间结果:RDD可以内存中保留中间结果,对于迭代处理来说,每次迭代都是可以重用中间结果,而不是重新计算基于DAG执行引擎:
123、Spark为什么快?
1、spark是基于内存计算,MR是基于磁盘计算
2、spark中具有DAG有向无环图,在此过程中减少了shuffle以及落地磁盘的次数
3、spark是粗粒度的资源申请,也就是当提交了spark application时候,application会将所有资源申请完毕,task在执行的时候就不需要申请资源,task执行快,当最后一个task执行完之后才会被释放;MR是细粒度的资源申请,task需要自己申请资源并释放,故application执行比较缓慢;
124、Spark数据倾斜问题,如何定位,解决方案?
spark中数据倾斜主要是指shuffle过程中出现的数据倾斜问题,不同的key对应的数据量不同导致不同的task处理的数据量不同的问题
数据倾斜是指少数的task被分配了极大量的数据,少数task运行缓慢
解决方案:
增加分区:如果数据分布不均匀,可以增加分区数,使得数据能够更加均匀地分配到不同的分区中
重新分桶/哈希:对于键值对冲突的情况,尝试重新分桶或者通过哈希函数重新计算键值,使得数据分布均匀
增加缓存:对于某些数据,可以将其缓存到内存中,减少重复计算
随机前缀/后缀:对于简直冲突的情况,增加键的前缀或者后缀,降低冲突
倾斜数据单独处理:
补充:美团梳理spark解决数据倾斜的问题
数据倾斜原理简单:在进行shuffle的时候,必须将各个节点上相同的key拉取到某个节点上的一个task来进行处理,如果某一个key对应的数据量特别大的话,就会发生数据倾斜,大部分key对应10条数据,个别key对应的100W条数据,导致运行task结束事件不同,因此,整个saprk作业的运行进度是由运行时间最长的那个task决定的。
了解了spark的stage划分原理,有助于快速定位数据倾斜发生的位置查看导致数据倾斜的key的数据分布情况:
1、如果是spark SQL中的group by、join语句导致的数据倾斜,那么就查询一下SQL中使用的表的key的分布情况。
2、如果是对SparkRDD执行的shuffle算子导致的数据倾斜,那么可以在Spark作业中加入查看key分布的代码,比如RDD.countByKey()。然后对统计出来的各个key出现的次数,collect/take到客户端打印一下,就可以看到key的分布情况。
解决方案
1、使用hive
ETL预处理数据:评估是否可以通过hive进行数据预处理,从根源上解决了数据倾斜问题,彻底避免了spark中执行的shuffle类算子,我们只是把数据倾斜提升到了hive中,避免了spark中发生数据倾斜。2、过滤少数导致倾斜的key:如果发现倾斜的key就少数几个,并且对计算本身的影响不大,就可以直接过滤少数几个key;如果每次执行作业时候,动态判定哪些key的数据量最多然后再进行过滤,可以使用sample算子对RDD进行采样,计算每个key的数量,取数据量最多的key过滤即可。
3、提高shuffle操作的并行度:这是最简单的一种方案,对RDD执行shuffle算子时候,给shuffle传入一个参数,该参数就设置了shuffle算子执行时候的reduce
task数量;在实际时候治标不治本,无法彻底解决数据倾斜的问题。
4、局部聚合和全局聚合:第一次是局部聚合,先给每个key都打上一个随机数,然后对打上随机数后的数据执行reducebykey的操作,进行局部聚合,然后将各个key的前缀去掉,再进行全局聚合操作;对于聚合类的shuffle操作导致的数据倾斜,效果很好,可以大幅度甚至解决数据倾斜问题。
5、将reduce join转换为map
join:不使用join算子进行连接操作,而使用Broadcast变量与map类算子实现join操作,进而完全规避掉shuffle类的操作,彻底避免数据倾斜的发生和出现。将较小RDD中的数据直接通过collect算子拉取到Driver端的内存中来,然后对其创建一个Broadcast变量;接着对另外一个RDD执行map类算子,在算子函数内,从Broadcast变量中获取较小RDD的全量数据,与当前RDD的每一条数据按照连接key进行比对,如果连接key相同的话,那么就将两个RDD的数据用你需要的方式连接起来;普通的join是会走shuffle过程的,而一旦shuffle,就相当于会将相同key的数据拉取到一个shuffle
read task中再进行join,此时就是reduce
join。但是如果一个RDD是比较小的,则可以采用广播小RDD全量数据+map算子来实现与join同样的效果,也就是map
join,此时就不会发生shuffle操作,也就不会发生数据倾斜。 6、采样倾斜key并分拆join操作
7、随机前缀和扩容RDD进行join
125、spark中的宽窄依赖
两个相邻的RDD之间的依赖关系(宽、窄依赖是根据上下游RDD的分区而言的)
宽依赖:上游一个RDD的partition可以被下游RDD的多个partition依赖
窄依赖:上游一个RDD的partition可以被下游RDD的多个partition依赖
RDD不会保存数据,只会保存血缘关系。提高容错性,将RDD之间的关系恢复重新进行读取
126、spark join在什么情况下会变成窄依赖
当两个RDD进行join时候,分区方式以及分区数目相同,并且每个分区中的数据量也相当,这样就将每个分区数据进行一对一匹配,形成窄依赖
当进行shuffle操作的key值较少时候,通过增大分区来减少每个分区中数据量,使得每个分区的数据量相对较少,
127、spark的内存模型
spark是基于分布式内存计算的,由dirver和executor
spark内存分为堆内内存和堆外内存,堆内内存基于JVM内存模型,堆外内存则通过调用底层JDK unsafeAPI
1、堆内内存
其大小由spark应用程序启动时候的-executor-momery参数配置,executor运行的并发任务共享JVM堆内内存,该任务在缓存RDD数据和广播数据时占用的内存被规划为存储内存(Storage),这些任务在执行shuffle时占用的内存被规划为执行内存(Execution)
2、堆外内存
可以直接在工作节点的系统内存中开辟空间,spark可以直接操作堆外内存,减少了不必要的内存开销和频繁的垃圾扫描,默认情况下不开启
128、为什么要划分宽窄依赖
目的在于执行计算中进行优化。spark通过识别窄依赖来执行一些优化,在同一个节点上对多个窄依赖的转化操作进行合并,从而减少网络传输的开销。对于宽依赖,spakr会根据分区的数量和大小来据欸的那个是否进行数据重分区。
129、spark中的转换算子和行动算子的区分
转换算子得到的是一个新的RDD,但不会立即执行计算,只是记录下当前的操作,
行动算子是指触发RDD进行计算的操作,(所以spark中作业的划分是根据行动算子来确定的)
130、Spark的哪些算子会有shuffle过程?
groupByKey:将具有相同键的键值对分组到一起,必须进行shuffle以重新分配数据到不同的分区。
reduceByKey:对具有相同键的键值对进行聚合操作,需要将具有相同键的数据重新分配到不同的分区。
sortByKey:按照键对数据进行排序,需要将数据重新分区以进行排序。
join:将两个具有相同键的数据集进行连接操作,需要将具有相同键的数据重新分配到不同的分区。
distinct:去除数据集中的重复元素,需要对元素进行重新分区以进行重复元素的合并。
cogroup:将具有相同键的数据集进行分组,需要将具有相同键的数据重新分配到不同的分区。
131、Spark有了RDD,为什么还要有Dataform和DataSet?
引入DF和DS是为了实现更高级的数据处理和优化
RDD是强类型的,它在编译时候无法检查数据类型的准确性,如果在运行过程中类型不匹配,只能在运行时抛出。DF和DS是基于RDD的抽象,提供了更加攻击的类型安全性,允许编译器在编译时候检查数据类型的准确性
RDD是基于函数式编程的,需要手动编写复杂的转换和操作逻辑。DF和DS提供了基于SQL的高级抽象,可以使用sql语句进行数据操作
132、Spark的RDD、DataFrame、DataSet、DataStream区别?
RDD式弹性分布式数据集,是基于分区进行操作,通过转换算子和行动算子来进行数据处理
DF是一种以结构化数据为中心的数据抽象概念,DF是一个分布式数据,具有类似关系型数据库表的结构
DS式DF的扩展,提供类型安全和更高级的API,强类型的数据集合
补充:spark中dataframe表格的类型
createGlobalTempView:全局临时视图,spark中sql的临时视图是session级别的,会随着session的消失而消失,如果希望一个临时视图跨session而存在,可以建立一个全局临时视图,全局临时视图存在于系统数据库global_temp中,必须加上库名引用它;
createOrReplaceGlobalTempView:创建一个可替换的全局视图,
createTempView:临时视图
createOrReplaceTempView:创建一个临时视图,如果该视图已经存在,则替换它,session级别的
补充:RDD的弹性体现在哪些方面
-
自动进行内存和磁盘切换
-
基于lineage(血缘关系)的高效容错(出错时候可以进行恢复)task如果失败会特定次数的重试
-
stage如果失败会自动进行特定次数的重试,而且只会计算失败的分片
-
checkpoint:每次对RDD操作都会产生新的RDD,如果链条比较长,就算笨重,就把数据放在磁盘中
-
persist:内存或磁盘中对数据进行复用
133、Spark的Spark Application、Job、Stage、Task分别介绍下,如何划分?
application(应用):一个独立的spark作业是由一系列的tasks组成的,一个application通常包含多个任务,每个作业由一个或者多个RDD转换和操作组成。提交一个任务就是一个application
Job(作业):job是一组相互依赖的RDD转化和动作操作的有向无环图,一个job代表了一个完整的作业执行流程(一个action算子就会生成一个job)
Stage(阶段):stage是job的划分,一个job可以由多个stage组成,stage是根据RDD之间的宽窄依赖划分的,一个stage中的所有任务都可以并行执行,不同的stage之间的任务需要等待前一个stage的任务完成
Task(任务):task是最小的作业单元,每个stage包含多个任务,每个任务负责处理一个RDD分区的数据(一个stage中,最后一个RDD的分区个数就是task的个数)
Job代表一个完整的作业执行过程,Stage是Job的划分,根据RDD之间的宽依赖关系划分,Task是Stage的执行单元,负责对RDD进行实际的操作和计算
注意:Application->Job->Stage->Task每一层都是1对n的关系。
134、Stage的内部逻辑
stage是由一个具有相同宽依赖关系的RDD组成的,一个stage可以看作一个逻辑的划分
内部逻辑:
1、DAG生成:在stage内部,spark会根据RDD之间的依赖关系生成一个有向无环图
2、任务划分:会将每个stage划分为多个task,每个task对应的RDD的分区
3、任务调度:spark会将task调度到集群中的执行器上执行
4、任务执行
5、数据传输
135、spark为什么要划分stage
划分satge的目的是为了优化任务的执行过程,提高计算性能和效率
136、stage的数量等于什么
stage的数量等于宽依赖的个数+1
137、Spark容错机制?
138、RDD的容错机制
RDD的容错性是指其发射发生故障能够自动恢复,并且不会丢失任何数据
容错实现方式:
1、数据复制:RDD将数据划分为多个分区,并将每个分区的数据复制到集群的多个节点上
139、Spark广播变量的实现和原理?
广播变量是一种分布式共享变量,允许开发者在每个节点上缓存一个只读变量,而不是将其复制到每个任务中,用于在每个节点上缓存一个较大的数据集,方便在执行任务期间共享数据
在多个并行操作中使用同一个变量,但是 Spark 会为每个任务分别发送。
140、转换算子
1、map
将处理的数据逐条进行映射转换,可以是类型的转换,也可以是值的转换。不会减少或者增多数据
2、mapPartitions
将待处理的数据以分区为单位发送到计算节点上进行处理,可以减少或者增多数据
Map 算子是分区内一个数据一个数据的执行,类似于串行操作。而 mapPartitions 算子 是以分区为单位进行批处理操作。
比如,将RDD中的所有数据通过JDBC连接写入数据库,如果使用map函数,可能要为每一个元素都创建一个connection,这样开销很大,如果使用mapPartitions,那么只需要针对每一个分区建立一个connection
3、mapPartitionsWithIndex
将待处理的数据以分区为单位发送到计算节点进行处理,并且可以获取当前分区索引
4、flatmap
将待处理的数据进行扁平化后再映射
5、glom
将RDD中的分区数据直接转换为相同类型的RDD,分区不变 将每一个分区形成一个数组,形成新的RDD类型时RDD[Array[T]]
6、Groupby
根据指定的规则进行分组,分区默认不变,数据会被打乱重新组合,一个组的数据在一个分区中,涉及shuffle
7、filter
根据指定规则进行筛选过滤,符合规则的数据保留,不符合的数据丢弃
8、sample
- 从数据集中抽取数据,采样从大规模数据中抽取数据
- 第一个参数:抽取数据后是否将数据放回
- 第二个参数:数据源中每条数据被抽取的概率(如果抽取不放回,表示数据源中每条数据被抽取的概率)(如果抽取放回的场合:表示数据源中每条数据被抽取的可能次数)
- 第三个参数:表示随机算法的种子
![[图片]](https://img-blog.csdnimg.cn/direct/3ab6f86beb0e438485b4a5a1add5a1f8.png)
9、distinct
数据去重。
10、coalesce
缩减分区,用于大数据集过滤以后,提高小数据集的执行效率
11、repartition
扩大分区,内部还是执行的coalesce算子,只是默认执行shuffle操作,没有shuffle操作的话,就没有意义
12、sortBy算子
按照一定的规则进行排序
13、交集并集差集拉链
intersection、union、subtract、zip都是针对两个value类型的
在交集、并集、补集、差集中,数据类型必须一致
在zip中,数据类型可以不一致,但是数据的个数一定要一样
14、partitionBy
15、reduceByKey
(a,1)(a,1)(b,1)(b,1)(b,1)(b,1)
按照指定的键,对value做聚合(a,2),(b,3)
支持分区内预聚合,可以有效减少shuffle时落盘的数据量
分区内和分区间计算规则是相同的
16、groupByKey
按照指定的键,将value聚合成一个迭代器 (a,(1,2,3))
类比groupBy,(a,((a,1), (a,2), (a,3)))
reduceByKey对比groupByKey
都存在shuffle的操作,但是reduceByKey可以在shuffle前对分区内的数据进行预聚合,这样会减少落盘的数据量。
groupByKey只是进行分组,不存在数据量减少的问题
reduceByKey性能高
reduceByKey包含分组和聚合的功能,GroupByKey只能分组,不能聚合
17、aggregateByKey
分区内计算和分区间的计算规则可以不同,自己定义
第一个参数:表示计算的初始值
第二个参数列表:
分区内的计算规则
分区间的计算规则
18、foldByKey
如果分区内和分区间的计算规则相同了,那么就是用foldByKey算子
19、combinByKey
是一个通用的聚合操作,
reduceByKey、foldByKey、aggregateByKey、combineByKey 的区别?
行动算子
count、countbykey、countbyvalue
![[图片]](https://img-blog.csdnimg.cn/direct/6e95ea33b8554e77804fbde8c9d0e303.png)
141、reduceByKey和groupByKey的区别和作用?
reducebykey将具有相同的键的值进行聚合,并返回一个新的键值RDD,
groupbykey将具有相同的键的所有值分组,并返回一个新的键值对RDD
从shuffle的角度:两者都存在shuffle操作,但是reducebykey可以在shuffle前对分区内相同的key的数据进行预聚合,减少落盘的数量,groupbykey只是进行分组,不存在数据量减少的问题,前者性能较高
功能角度:reducebykey只包含了分组和聚合的功能,后者只能分组
142、reducebykey和reduce的区别
两者都是进行聚合操作的方法
reducebykey是转换算子,将RDD中具有相同键的元素进行聚合,返回一个新的RDD,并将结果作为新的键
reduce是一个行动算子,它将RDD中所有元素进行聚合,并返回一个单个的结果
reduceByKey适用于对键值对RDD进行聚合操作,返回一个新的键值对RDD,而reduce操作适用于对整个RDD进行聚合,返回一个单一结果。
reduceByKey可以在分区上并行地进行聚合操作,而reduce操作是在整个RDD上进行的。
reduceByKey需要指定一个聚合函数来合并具有相同键的元素,而reduce操作只需要指定一个聚合函数即可。
143、使用reduceByKey出现数据倾斜怎么办?
144、Spark SQL的执行原理?
和RDD不同,sparksql的DS和sql并不是直接生成计划交给集群执行,而是经过了一个叫Catalyst的优化器,帮助开发者优化代码
回答:
1、首先SparkSQL底层解析成RDD,通过两个阶段RBO和CBO
2、RBO就是通过逻辑执行计划通过常见的优化达到逻辑执行计划
3、CBO就是从优化后的逻辑计划到物理执行计划
145、Spark SQL的优化?
1、catalyst优化器:自动推断查询计划的最优执行方式
2、列式存储;采用列式存储的方式来存储和处理数据
3、数据划分和分区:可以将大规模的数据集划分成多个小块进行处理
4、数据裁剪和推测执行:数据裁剪可以根据查询条件不想不关的数据过滤掉,减少数据的传输和处理量
5、并行执行和动态分配资源
146、Spark RDD持久化
checkpoint
用于将spark应用程序的中间数据保存到持久存储中,以便在发生故障或者重启时候恢复应用程序的状态,当用户启动checkpoint后,spark会将DAG的中间数据保存到可靠的存储系统中,即使发生故障也可以从checkpoint中恢复数据,执行方法:
sparkcontext.setCheckpointDir(" ")
Cache缓存
RDD通过cache或者persist方法将前面的计算结果缓存,默认情况下会把数据以缓存在JVM的堆内存中,
缓存和检查点区别
cache只是将数据保存起来,不切断血缘依赖,checkpoint检查点切断血缘依赖
cache缓存的数据通常在磁盘,内存地方,checkpoint数据通常存储在hdfs
145、DF和DS的创建
补充:RDD、DF、DS三者之间的转换
1、DF和DS——>RDD,只需要调用.rdd()就能实现
2、RDD——>DS,将RDD的每一行封装成样例类,再调用toDS()
3、RDD——>DF,调用.toDF()
3、DF——>DS,DF就是DS的特例,是可以相互转换,使用.as()
4、DS——>DF,使用.toDF()
146、HashPartitioner和RangePartitioner的实现
两者都是spark的分区函数,继承于partitioner
HashPartitioner:哈希分区,对于给定的key,计算其hashCode,并除于分区的个数取余,会后返回的余数就是这个key所属的分区ID
RangePartitioner:将一定范围内的数据映射到一个分区中,尽量保证每个分区的数据均匀,而且分区间有序,也就是说一个分区中的元素肯定都是比另一个分区内的元素小或者大,但是分区内的元素是不能保证顺序的
147、为什么spark比MR快
1、内存计算
spark将数据存储在内存中进行计算和处理,而hadoop则将数据存储在磁盘上,速度更慢
2、DAG执行引擎
spark使用DAG执行引擎,通过将任务划分为多个阶段进行优化,可以有效地减少任务之间的数据传输和磁盘读写
3、运行模式
spark支持多种运行模式,本地、yarn。独立模式更,根据需求进行选择
4、缓存机制
spark具有强大的缓存机制,可以将结果存储在内存中,避免了重复计算和磁盘读写操作
5、数据流水线
spark可以将多个数据处理操作连接成一个数据流水线,减少了中间数据的存储的传输
6、资源调度
spark是粗粒度的资源申请,也就是当提交了spark application时候,application会将所有资源申请完毕,task在执行的时候就不需要申请资源,task执行快,当会后一个task执行完之后才会被释放;MR是细粒度的资源申请,task需要自己申请资源并释放,故application执行比较缓慢。
补充:Hive On Spark 和 Spark SQL的区别
Hive on spark:
将spark作为hive的计算引擎,通过将hive的查询作为spark任务提交到spark集群上进行计算,
继承了hive的数据仓库功能,包括元数据管理,数据存储,查询优化等,还支持UDF函数和存储过程
sparkSQL:是spark项目的一部分,用于处理结构化的数据,基于Dataframe,
sparkSQL可以更直接利用spark引擎的优化器和执行引擎,可以更紧密地集成到spark生态系统中,更好利用集群资源(优化器和执行引擎、数据格式和存储、内存计算、执行计划)
相关文章:
大数据开发面试题【Spark篇】
115、Spark的任务执行流程 driver和executor,结构式一主多从模式, driver:spark的驱动节点,用于执行spark任务中的main方法,负责实际代码的执行工作;主要负责:将代码逻辑转换为任务、在executo…...

深入分析 Android Activity (六)
文章目录 深入分析 Android Activity (六)1. Activity 的权限管理1.1 在 Manifest 文件中声明权限1.2 运行时请求权限1.3 处理权限请求结果1.4 处理权限的最佳实践 2. Activity 的数据传递2.1 使用 Intent 传递数据2.2 使用 Bundle 传递复杂数据 3. Activity 的动画和过渡效果3…...

火箭升空AR虚拟三维仿真演示满足客户的多样化场景需求
在航空工业的协同研发领域,航空AR工业装配系统公司凭借前沿的AR增强现实技术,正引领一场革新。通过将虚拟信息无缝融入实际环境中,我们为工程师、设计师和技术专家提供了前所未有的共享和审查三维模型的能力,极大地提升了研发效率…...

LeetCode 279 —— 完全平方数
阅读目录 1. 题目2. 解题思路3. 代码实现 1. 题目 2. 解题思路 此图利用动态规划进行求解,首先,我们求出小于 n n n 的所有完全平方数,存放在数组 squareNums 中。 定义 dp[n] 为和为 n n n 的完全平方数的最小数量,那么有状态…...

PHP发票真假API、医疗电子票据查验、发票识别接口开发示例
“营”“增”两种税是主流的流转税种,是两个独立而不能交叉的税种。也就是说交增值税的话就不交营业税,而交了营业税就不需要交增值税。而且,两者在征收的对象、征税范围、计税的依据、税目、税率以及征收管理等都有所不同,增值税…...

Python库之`lxml`的高级用法深度解析
Python库之lxml的高级用法深度解析 简介 lxml是一个功能强大的第三方库,它提供了对XML和HTML文档的高效处理能力。除了基本的解析和创建功能外,lxml还包含了一些高级用法,这些用法可以帮助开发者在处理复杂文档时更加得心应手。 高级解析技…...

参数的本质:详解 JavaScript 函数的参数
文章导读:AI 辅助学习前端,包含入门、进阶、高级部分前端系列内容,当前是 JavaScript 的部分,瑶琴会持续更新,适合零基础的朋友,已有前端工作经验的可以不看,也可以当作基础知识回顾。 上篇文章…...

悲痛都会过去,唯有当下值得珍惜
在生活的长河中,我们都会经历各种各样的悲痛与挫折,无论是来自原生家庭的困扰,婚姻中的曲折,还是小时候的创伤、男女关系中的纠葛、校园时期的霸凌。然而,当我们回首过去,曾经以为无法逾越的痛苦࿰…...

第三方软件测试机构进行代码审计需要哪些专业的知识?
代码审计 进行代码审计需要专业的知识,包括编程语言、操作系统、数据库、网络知识以及安全知识等。 1.编程语言知识是进行代码审计的基础,因为你需要理解代码的语法和结构。对于不同的应用程序,你需要了解其所使用的编程语言的特点和语法规…...
Modal.method() 不显示头部的问题
ant-design中的Modal组件有两种用法: 第一种是用标签:<a-modal></a-modal> 第二种是用Api:Modal.info、Modal.warning、Modal.confirm...... 一开始项目中这两种用法是混用的,后面UI改造,需要统一样式&…...

Java中的内部类及其用途
一、技术难点 在Java中,内部类是一个定义在另一个类内部的类。这种嵌套的结构带来了一些技术上的难点和挑战: 访问控制:内部类可以直接访问外部类的所有成员(包括私有成员),但外部类不能直接访问内部类的…...

堆(建堆算法,堆排序)
目录 一.什么是堆? 1.堆 2.堆的储存 二.堆结构的创建 1.头文件的声明: 2.向上调整 3.向下调整 4.源码: 三.建堆算法 1.向上建堆法 2.向下建堆法 四.堆排序 五.在文件中Top出最小的K个数 一.什么是堆? 1.堆 堆就…...
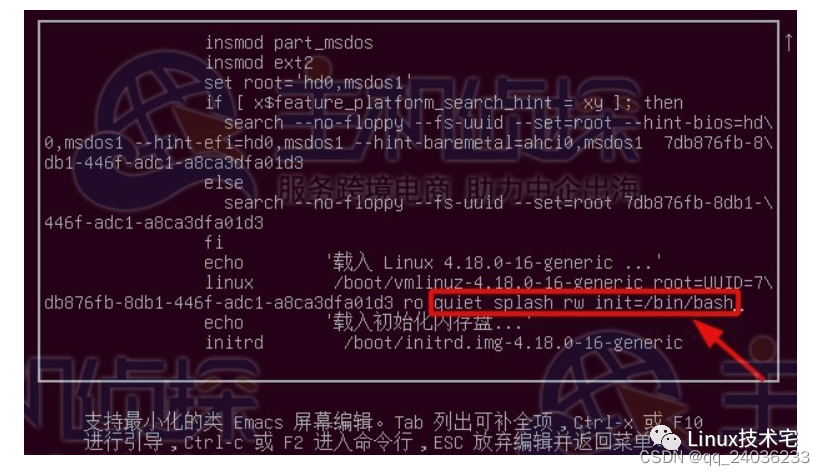
Linux内核重置root密码
Ubuntu 首先重新启动Ubuntu系统,然后快速按下shift键,以调出grub启动菜单在这里我们选择第二个(Ubuntu高级选项),选中后按下Enter键 选择最高的Linux内核版本所对应的recovery mode模式,按e键编辑启动项 在…...
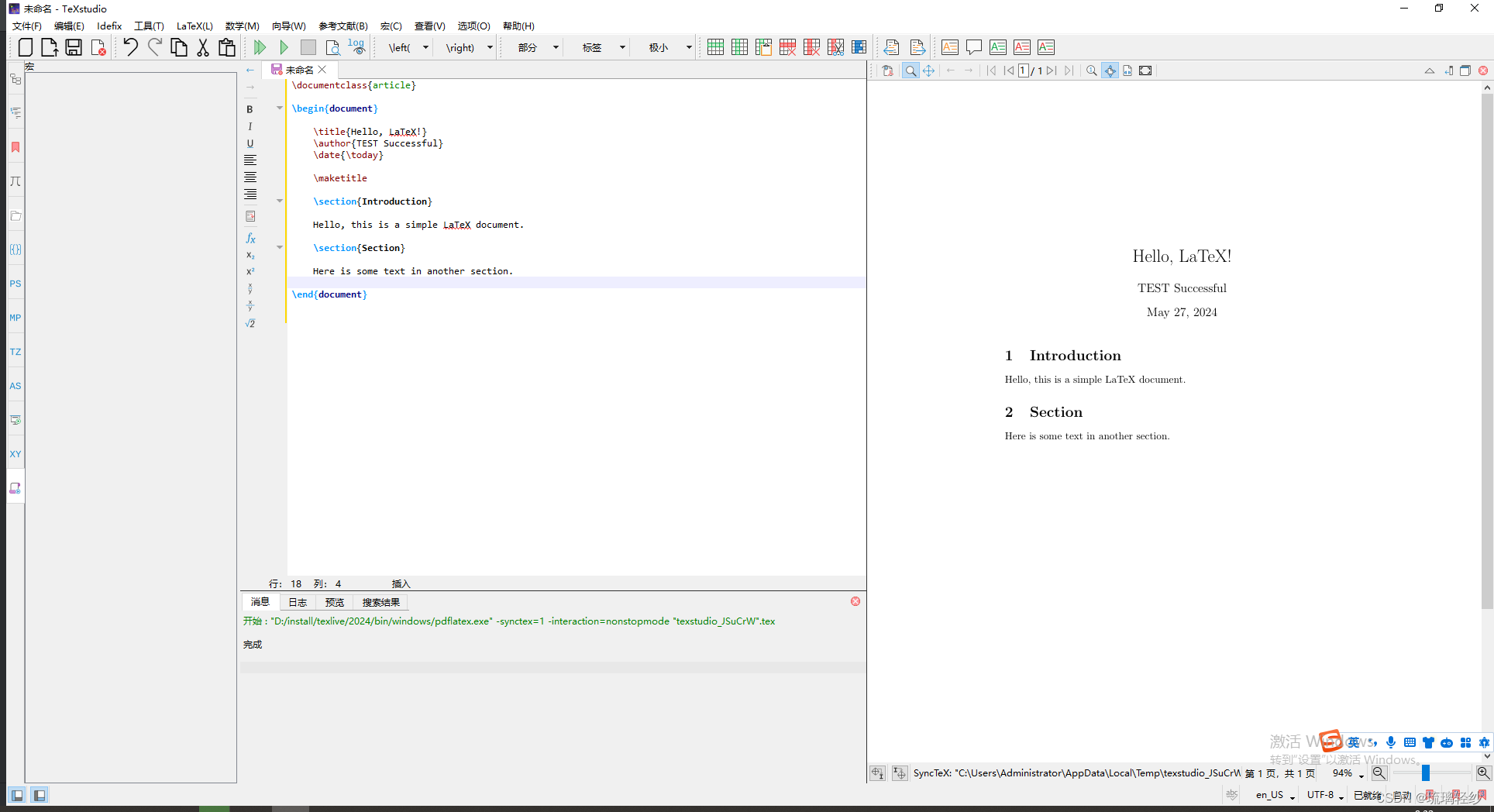
LaTex安装及配置(Windows)
LaTex安装及配置(Windows) 安装环境安装texlive下载texlive安装 编辑器安装texstudio下载texstudio安装 环境配置 使用第一个LaTex文档新建文件编程查看results 安装 环境安装 texlive下载 镜像清华源下载地址:https://mirrors.tuna.tsing…...
这才是满分毕业答辩PPT!
这才是满分毕业答辩PPT! 2024年 毕业答辩论文指南 创新 正式 高效 正值毕业季,是不是很多同学,非常头疼如何进行论文答辩? 要想导师满意,顺利毕业,那么手里必须有份优秀的答辩PPT。这将是你的秘密武器&…...

【字典树(前缀树) 字符串】2416. 字符串的前缀分数和
本文涉及知识点 字典树(前缀树) 字符串 LeetCode 2416. 字符串的前缀分数和 给你一个长度为 n 的数组 words ,该数组由 非空 字符串组成。 定义字符串 word 的 分数 等于以 word 作为 前缀 的 words[i] 的数目。 例如,如果 words [“a”,…...

X-CSV-Reader:一个使用Rust实现CSV命令行读取器
🎈效果演示 ⚡️快速上手 依赖导入: cargo add csv读取实现: use std::error::Error; use std::fs::File; use std::path::Path;fn read_csv<P: AsRef<Path>>(filename: P) -> Result<(), Box<dyn Error>> {le…...

集成ECharts到若依框架:原理与使用方法详解
ECharts 是一个强大的开源数据可视化库,基于 JavaScript,能够创建丰富多彩的图表和交互数据展示。结合若依框架(RuoYi),我们可以非常方便地将 ECharts 集成到系统中,实现数据的可视化展示。本文将详细介绍 …...
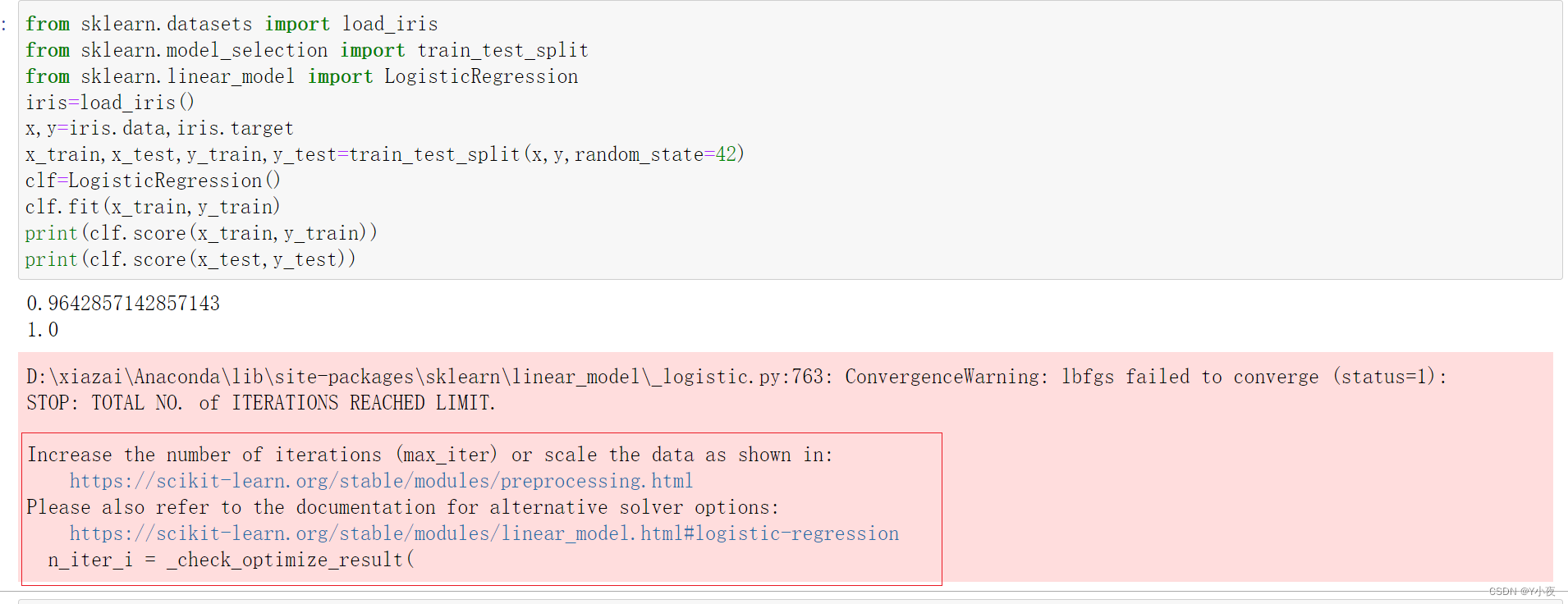
【机器学习】——线性模型
💻博主现有专栏: C51单片机(STC89C516),c语言,c,离散数学,算法设计与分析,数据结构,Python,Java基础,MySQL,linux…...

最全的Redis常用命令
Redis是一个开源的内存数据结构存储系统,用作数据库、缓存和消息代理。它支持多种类型的数据结构,如字符串(strings)、哈希(hashes)、列表(lists)、集合(sets)…...

百度网盘直链解析:终极免费提速解决方案
百度网盘直链解析:终极免费提速解决方案 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 还在为百度网盘非会员的龟速下载而烦恼吗?今天我要向你介绍一个…...

如何用嘎嘎降AI处理会计学论文:会计学研究生毕业论文降AI4.8元完整操作教程
如何用嘎嘎降AI处理会计学论文:会计学研究生毕业论文降AI4.8元完整操作教程 关于会计学论文降AI教程,有几个细节提前知道能少走很多弯路。 核心用嘎嘎降AI(www.aigcleaner.com),4.8元,达标率99.26%。这篇…...

OBS高级计时器插件:6种专业模式让你的直播时间管理轻松自如
OBS高级计时器插件:6种专业模式让你的直播时间管理轻松自如 【免费下载链接】obs-advanced-timer 项目地址: https://gitcode.com/gh_mirrors/ob/obs-advanced-timer 还在为直播时间控制而烦恼吗?OBS Advanced Timer计时器插件是你的直播时间管理…...

AI智能体:从概念到现实的技术演进与应用前景
AI智能体正渐渐从科幻概念转变成现实应用里的关键角色,这是随着人工智能技术的快速发展而出现的情况。按照2024年发布的报告来看,全球已经存在超过67%的企业其正在规划或者早已经部署了和AI智能体相关的项目,预计到2026年的时候,这…...

Axure RP 多版本本地化引擎:高性能界面翻译架构解析与部署指南
Axure RP 多版本本地化引擎:高性能界面翻译架构解析与部署指南 【免费下载链接】axure-cn Chinese language file for Axure RP. Axure RP 简体中文语言包。支持 Axure 11、10、9。不定期更新。 项目地址: https://gitcode.com/gh_mirrors/ax/axure-cn Axure…...

如何免费将PPTX转为HTML?纯JavaScript终极解决方案完整指南
如何免费将PPTX转为HTML?纯JavaScript终极解决方案完整指南 【免费下载链接】PPTX2HTML Convert pptx file to HTML by using pure javascript 项目地址: https://gitcode.com/gh_mirrors/pp/PPTX2HTML 在数字化办公和在线教育的时代,你是否经常需…...

终极免费方案:如何5分钟搞定Axure RP全界面中文汉化
终极免费方案:如何5分钟搞定Axure RP全界面中文汉化 【免费下载链接】axure-cn Chinese language file for Axure RP. Axure RP 简体中文语言包。支持 Axure 11、10、9。不定期更新。 项目地址: https://gitcode.com/gh_mirrors/ax/axure-cn 还在为Axure RP的…...

AI教材生成新突破!低查重AI写教材工具,快速打造专业教材书稿!
写教材的过程,总能遇到“慢节奏”带来的各种困扰。虽然框架和材料已经准备好,但内容撰写却常常陷入瓶颈——一句话反复推敲半小时,总觉得不够完美;章节之间的衔接过渡,总是费尽脑筋也找不到合适的表述,创作…...
)
ChatGPT提示工程进阶实战(故事化表达失效的7大隐形陷阱)
更多请点击: https://kaifayun.com 第一章:故事化表达失效的底层认知重构 当工程师在技术文档中反复使用“用户点击按钮后,系统就像一位耐心的向导,带他走过三步旅程”这类修辞时,信息熵并未降低——反而因隐喻失准而…...

颠覆性GIF处理终极方案:Gifsicle深度解密
颠覆性GIF处理终极方案:Gifsicle深度解密 【免费下载链接】giflossy Merged into Gifsicle! 项目地址: https://gitcode.com/gh_mirrors/gi/giflossy 你是否曾为网站上的GIF动画加载缓慢而烦恼?是否在处理大量GIF素材时感到力不从心?今…...