如何运行大模型
简介
要想了解一个模型的效果,对模型进行一些评测,或去评估是否能解决业务问题时,首要任务是如何将模型跑起来。目前有较多方式运行模型,提供client或者http能力。
名词解释
浮点数表示法
一个浮点数通常由三部分组成:符号位、指数部分和尾数部分(也称为小数部分或 mantissa)。
- 符号位:决定了数的正负。在大多数浮点数格式中,符号位通常占1位,0表示正数,1表示负数。
- 指数部分(Exponent):表示数值的大小或缩放因子。在浮点数中,指数部分采用偏移码(bias encoding)来表示,以确保0的特殊处理和指数的正负表示。例如,在IEEE 754标准的单精度(float32)中,指数部分实际占8位,但由于偏移码(通常偏移127),实际的指数范围是从-126到127。
- 尾数部分(Mantissa或Fraction):代表小数部分,它是一个小于1的正数,用来精确表示数值的非整数部分。在标准的浮点数表示中,尾数部分总是以1开头(这个1是隐含的,不占用实际的位),然后是若干位来表示其余的数字。例如,在float32中,尾数部分实际有23位(因为隐含了一个1),这提供了很高的精度。
以一个具体的例子来说明,假设我们有一个二进制浮点数,格式为1位符号位,8位指数部分,23位尾数部分。一个浮点数的值计算方式大致为:(-1)^符号位 × 1.尾数部分 × 2^(指数部分 - 偏移值)。
torch_dtype
在PyTorch中,torch_dtype参数是一个用于指定张量(tensor)数据类型的选项,通常可用以下取值:
- auto:自动判断,读取模型目录的config.json中配置的torch_dtype值,如果是bfloat16且当前硬件支持bfloat16,则优先使用这种;判断是否支持float16,不支持才使用float32。
- torch.bfloat16:1位符号位、8位指数部分、7位尾数,此种类型牺牲了一些精度,但保持了与单精度float32相同的指数范围,这在处理大范围数值和保持动态范围方面非常有利。
- torch.float16:标准的16位浮点数格式,由1位符号位、5位指数部分、10位小数部分组成。与bfloat16相比,它有更精细的尾数精度,但在指数范围上较窄,这意味着它在处理非常大或非常小的数值时可能不够稳定。
- torch.float32:单精度浮点数,由1位符号位、8位指数部分(使用偏移编码,偏移值为127)和23位尾数部分组成。
- torch.float64:由1位符号位、11位指数部分(使用偏移编码,偏移值为1023)和52位尾数部分组成。
- 其它:torch.int8, unit8, int32, int64等类型。
chat template
基础模型只提供了completion能力,在大模型发展的过程中,很多公司都推出了针对聊天的chat模型,这类模型将用户分为了system, user, assistant角色,将不同角色的输入内容用特定的token分隔开,使得模型能够更好的理解上下文,给出更精确的答复。
此外,模型在训练的时候,就提供了一些数据集,使得system中提供的消息优先级高于user,多模型的安全性也有一定的帮助(避免用户在user message中改变system message对于模型的一些设置)
transformers框架已经原生支持了这一模式,通过执行以下代码帮助拼接prompt
from transformers import AutoModelForCausalLM, AutoTokenizertokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen1.5-7B-Chat")
prompt = "Give me a short introduction to large language model."
messages = [{"role": "system", "content": "You are a helpful assistant."},{"role": "user", "content": prompt}
]
# 这样不进行tokenize测试下效果(直接输出拼接后的string)
# 如果想直接进行tokenize,需要传递参数:tokenize=True(默认就是), return_tensors='pt'
text = tokenizer.apply_chat_template(messages,tokenize=False,add_generation_prompt=True
)
以上代码会去加载模型目录的tokenizer_config.json文件,读取需要的信息,这里以qwen1.5模型为例,需要读取json中的以下字段:
{"chat_template": "{% for message in messages %}{% if loop.first and messages[0]['role'] != 'system' %}{{ '<|im_start|>system\nYou are a helpful assistant.<|im_end|>\n' }}{% endif %}{{'<|im_start|>' + message['role'] + '\n' + message['content'] + '<|im_end|>' + '\n'}}{% endfor %}{% if add_generation_prompt %}{{ '<|im_start|>assistant\n' }}{% endif %}",
}
由于指定了add_generation_prompt=True,生成的拼接后的字符串如下:
<|im_start|>system
You are a helpful assistant.<|im_end|>
<|im_start|>user
Give me a short introduction to large language model.<|im_end|>
<|im_start|>assistant
CUDA_VISIBLE_DEVICES
在 PyTorch 中,你可以使用 CUDA_VISIBLE_DEVICES 环境变量来指定可见的 GPU 设备。这个环境变量的值是一个以逗号分隔的 GPU 设备索引列表,可以是单个索引,也可以是多个索引组成的列表。
export CUDA_VISIBLE_DEVICES=0,1 # 只使用 GPU 0 和 GPU 1
export CUDA_VISIBLE_DEVICES=0 # 只使用 GPU 0
# 不使用任何 GPU(将模型运行在 CPU 上)
export CUDA_VISIBLE_DEVICES=
export CUDA_VISIBLE_DEVICES=""
device_map
device_map 参数是 Hugging Face transformers 库中一种用于控制模型在多个设备上分配的参数。它可以让你明确指定模型的哪些部分应该分配到哪个设备上,以优化模型的性能和内存使用。可以取以下值:
auto:自动选择合适的设备来分配模型,根据系统的可用资源和模型的大小智能选择设备。目前auto和balanced效果一样,但后续可能会修改。balanced:均匀地将模型分配到所有可用设备上,以平衡内存使用。balanced_low_0:将模型均匀地分配到除第一个 GPU 外的所有 GPU 上,并且只将不能放入其他 GPU 的部分放在 GPU 0 上。sequential:将模型层按顺序分配到多个设备上,模型的第一层分配给第一个设备,第二层分配给第二个设备,依此类推。当模型层数超过可用设备数量时,会循环回到第一个设备再次分配模型层。- 自定义映射:你还可以提供一个字典,明确指定每个模型层应该分配到哪个设备上。
查看设备分配的情况
# 查看主设备
model = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto")
print(model.device)# 查看每一层所在的设备
model = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto")
for name, param in model.named_parameters():print(name, param.device)
max_memory
当模型在多个设备上运行时,max_memory 参数可以帮助你限制每个设备上模型的内存使用,以防止内存溢出或超出系统资源限制。你可以提供一个字典,将设备名称(例如 "cuda:0"、"cuda:1" 或 "cpu")映射到相应的最大内存使用量(例如 "10GB"、"20GB" 或 "10240MB")
max_memory = {0:'5GB', 1:'13GB'}
model = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto", max_memory=max_memory)
查看每个卡的gpu使用情况和能分配的最大内存
# 这里的gpu_id是基于CUDA_VISIBLE_DEVICES可见设备,不是实际的卡位置
num_gpus = torch.cuda.device_count()
for gpu_id in range(num_gpus):torch.cuda.set_device(gpu_id)allocated_memory = torch.cuda.memory_allocated(gpu_id)max_memory_allocated = torch.cuda.max_memory_allocated(gpu_id)print(f"GPU {gpu_id}: Allocated Memory: {allocated_memory / 1024**3:.2f} GB, Max Allocated Memory: {max_memory_allocated / 1024**3:.2f} GB")
下载模型
驱动下载:https://www.nvidia.com/Download/index.aspx?lang=en-us
可以通过以下网站搜索模型:
-
https://huggingface.co (基于transformers架构模型的官方地址,一般新模型这里第一时间商家,可能需要翻墙)
-
https://hf-mirror.com (huggingface的镜像站)
-
https://www.modelscope.cn (阿里云推出的一个模型开放平台,国内下载速度较快,但是更新可能不是太及时)
设置pip镜像站:export PIP_INDEX_URL=https://pypi.tuna.tsinghua.edu.cn/simple
运行模型的时候,如果模型不存在会自动去下载模型,你也可以提前通过以下方式将模型下载好:
通过hugging face下载
pip install huggingface_hub
# 设置镜像站
export HF_ENDPOINT=https://hf-mirror.com
# 修改模型下载的目录(可选,默认是:~/.cache/huggingface/hub)
export HF_HUB_CACHE=/data/modelscope
# 需要授权的仓库需要登录(可选:https://huggingface.co/settings/tokens)
huggingface-cli login --token <your hugging face token>
# 下载qwen1.5-7b-chat模型
huggingface-cli download --resume-download Qwen/Qwen1.5-7B-Chat
通过modelscope下载
pip install modelscope
# 修改模型下载的目录(可选,默认是:~/.modelscope)
export MODELSCOPE_CACHE=/data/modelscope# python3
from modelscope import snapshot_download
model_dir = snapshot_download('qwen/Qwen1.5-7B-Chat')
运行模型
为了支持模型的版本控制、快速下载和增量更新,huggingface下载的模型结构blobs、refs和snapshot几个目录:
-
blobs: 这个目录存储了模型的实际权重数据和其他二进制文件。这些文件通常很大,包含了模型训练得到的参数。每个blob可以看作是一个独立的数据块,这样设计有利于分块下载和缓存,特别是在更新模型时,如果只有少量更改,用户只需下载变化的部分。
-
refs: 这部分涉及到版本控制。它存储了指向特定模型版本的引用,包括提交哈希(commit hashes)或者其他版本标识符。这使得用户可以明确地指定使用模型的哪个版本,同时也方便开发者维护模型的历史变更。
-
snapshot: 这个目录通常包含了一个模型版本的快照,它是一个特定时间点模型的状态。快照通常包含了指向
blobs中具体权重文件的指针,确保了模型的完整下载和加载。以commit id作为文件夹。
modelscope下载下来的模型文件并没有按照这个规则,它直接存储的是模型的检查点(checkpoint,包含权重文件、状态、配置等),加载modelscope下载的模型,需要导入modelscope相应的包,如:
# huggingface 风格
from transformers import AutoModelForCausalLM, AutoTokenizer# modelscope 风格
from modelscope import AutoModelForCausalLM, AutoTokenizer
也可以直接将模型的目录作为checkpoint_path参数传入,这样huggingface就会作为checkpoint去加载模型,而不是去下载。
import os
from transformers import AutoModelForCausalLM, AutoTokenizer# modelscope下载模型的存储目录,这里以qwen1.5-7b-chat作为示例
checkpoint_path = os.getenv('MODELSCOPE_CACHE') + "/qwen/Qwen1___5-7B-Chat"
model = AutoModelForCausalLM.from_pretrained(checkpoint_path, torch_dtype="auto", device_map="auto").eval()
tokenizer = AutoTokenizer.from_pretrained(checkpoint_path)
阻塞运行模型
模型下载页面一般提供了运行模型的测试代码,有些在github仓库中提供了运行示例。
from transformers import AutoModelForCausalLM, AutoTokenizer
device = "cuda" # the device to load the model ontocheckpoint_path = "Qwen/Qwen1.5-7B-Chat"
model = AutoModelForCausalLM.from_pretrained(checkpoint_path,torch_dtype="auto",device_map="auto"
).eval()
tokenizer = AutoTokenizer.from_pretrained(checkpoint_path)prompt = "Give me a short introduction to large language model."
messages = [{"role": "system", "content": "You are a helpful assistant."},{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(messages,tokenize=False,add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(device)generated_ids = model.generate(model_inputs.input_ids,max_new_tokens=512
)
generated_ids = [output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(response)流式运行模型
from transformers import AutoModelForCausalLM, AutoTokenizer, TextIteratorStreamer
from threading import Thread
device = "cuda" # the device to load the model ontocheckpoint_path = "Qwen/Qwen1.5-7B-Chat"
model = AutoModelForCausalLM.from_pretrained(checkpoint_path,torch_dtype="auto",device_map="auto"
).eval()
tokenizer = AutoTokenizer.from_pretrained(checkpoint_path)prompt = "Give me a short introduction to large language model."
messages = [{"role": "system", "content": "You are a helpful assistant."},{"role": "user", "content": prompt}
]
input_ids = tokenizer.apply_chat_template(messages, add_generation_prompt=True, return_tensors='pt').to(device)
streamer = TextIteratorStreamer(tokenizer=tokenizer, skip_prompt=True, timeout=60.0, skip_special_tokens=True)generation_kwargs = dict(input_ids=input_ids, streamer=streamer, max_new_tokens=20)
thread = Thread(target=model.generate, kwargs=generation_kwargs)
thread.start()for new_text in streamer:print(new_text, end='', flush=True)并行推理
通过并行计算来利用多GPU资源分为两种场景:
- torch.nn.DataParallel:多个GPU上并行处理数据批次(data batches)来加速训练。它在单个节点上工作,自动将输入数据分割成多个部分,每个部分在不同的GPU上进行前向传播,然后将结果合并。它通常通过模型的复制来实现并行计算,每个GPU上都有一个模型副本。
- model.parallelize:它不仅在数据层面并行,还在模型层面并行,利用了NCCL等库来协调多GPU间通信,可以对模型的不同层进行并行计算。适用于大型模型的训练,尤其是那些单个GPU内存无法容纳的模型,或者需要在多节点多GPU环境下进行分布式训练的情况。
数据批次并行
import osimport torch
from transformers import AutoModelForCausalLM, AutoTokenizer, TextIteratorStreamer
from threading import Threaddevice = "cuda" # the device to load the model onto
checkpoint_path = os.getenv('MODELSCOPE_CACHE') + "/qwen/Qwen1___5-7B-Chat"
model = AutoModelForCausalLM.from_pretrained(checkpoint_path,torch_dtype="auto",device_map="auto"
).eval()
if torch.cuda.is_available():num_gpus = torch.cuda.device_count()if num_gpus > 1:print(f"Found {num_gpus} GPUs, model is now parallelized.")model = torch.nn.DataParallel(model)tokenizer = AutoTokenizer.from_pretrained(checkpoint_path)prompt = "Give me a short introduction to large language model."
messages = [{"role": "system", "content": "You are a helpful assistant."},{"role": "user", "content": prompt}
]
input_ids = tokenizer.apply_chat_template(messages, add_generation_prompt=True, return_tensors='pt').to(device)
streamer = TextIteratorStreamer(tokenizer=tokenizer, skip_prompt=True, timeout=60.0, skip_special_tokens=True)generation_kwargs = dict(input_ids=input_ids, streamer=streamer, max_new_tokens=512)
thread = Thread(target=model.generate, kwargs=generation_kwargs)
thread.start()for new_text in streamer:print(new_text, end='', flush=True)模型&数据批次并行
并不是所有的模型都支持这种方式
import osimport torch
from transformers import AutoModelForCausalLM, AutoTokenizer, TextIteratorStreamer
from threading import Threaddevice = "cuda" # the device to load the model onto
checkpoint_path = os.getenv('MODELSCOPE_CACHE') + "/qwen/Qwen1___5-7B-Chat"
model = AutoModelForCausalLM.from_pretrained(checkpoint_path,torch_dtype="auto",device_map="auto"
).eval()
if torch.cuda.is_available():num_gpus = torch.cuda.device_count()if num_gpus > 1:print(f"Found {num_gpus} GPUs, model is now parallelized.")model.parallelize()tokenizer = AutoTokenizer.from_pretrained(checkpoint_path)prompt = "Give me a short introduction to large language model."
messages = [{"role": "system", "content": "You are a helpful assistant."},{"role": "user", "content": prompt}
]
input_ids = tokenizer.apply_chat_template(messages, add_generation_prompt=True, return_tensors='pt').to(device)
streamer = TextIteratorStreamer(tokenizer=tokenizer, skip_prompt=True, timeout=60.0, skip_special_tokens=True)generation_kwargs = dict(input_ids=input_ids, streamer=streamer, max_new_tokens=512)
thread = Thread(target=model.generate, kwargs=generation_kwargs)
thread.start()for new_text in streamer:print(new_text, end='', flush=True)相关文章:

如何运行大模型
简介 要想了解一个模型的效果,对模型进行一些评测,或去评估是否能解决业务问题时,首要任务是如何将模型跑起来。目前有较多方式运行模型,提供client或者http能力。 名词解释 浮点数表示法 一个浮点数通常由三部分组成…...

基于FPGA实现LED的闪烁——HLS
基于FPGA实现LED的闪烁——HLS 引言: 随着电子技术的飞速发展,硬件设计和开发的速度与效率成为了衡量一个项目成功与否的关键因素。在传统的硬件开发流程中,工程师通常需要使用VHDL或Verilog等硬件描述语言来编写底层的硬件逻辑࿰…...

平常心看待已发生的事
本篇主要记录自己在阅读此篇文章(文章链接: 这才是扼杀员工积极性的真正原因(管理者必读) )和这两天京东的东哥“凡是长期业绩不好,从来不拼搏的人,不是我的兄弟”观点后的一些想法。 自己在微…...
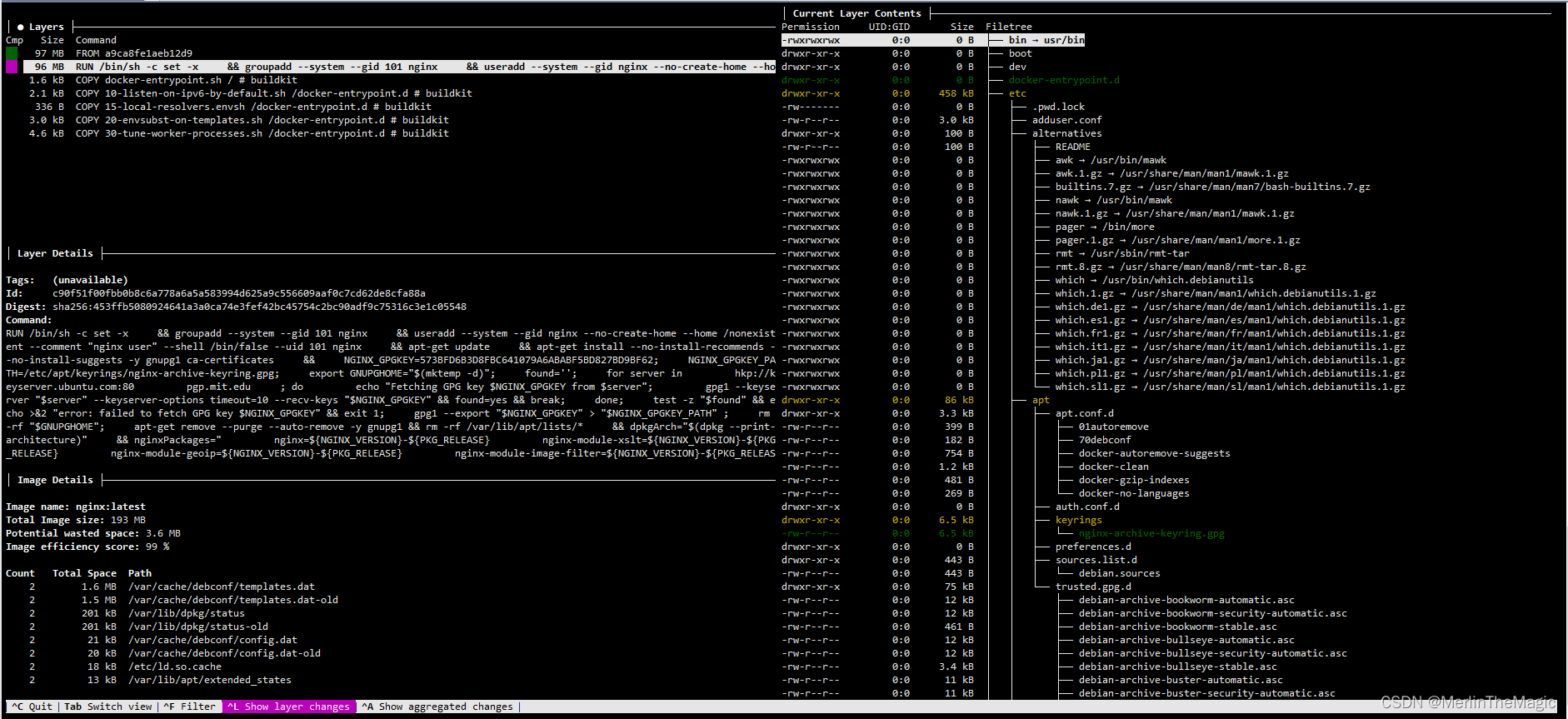
docker image分析利器之dive
dive是一个用于研究 Docker 镜像、层内容以及发现缩小 Docker/OCI 镜像大小方法的开源工具. 开源地址: dive github 为了有个直观的印象, 可以先看一下repo文档中的gif图: 安装 在Ubuntu/Debian系统下,可以使用deb包安装: DIVE_VERSION$(curl -sL "https:/…...

java组合设计模式Composite Pattern
组合设计模式(Composite Pattern)是一种结构型设计模式,它允许你将对象组合成树形结构来表示“部分-整体”的层次结构。组合模式使得客户端对单个对象和组合对象的使用具有一致性。 // Component - 图形接口 interface Graphic {void draw()…...
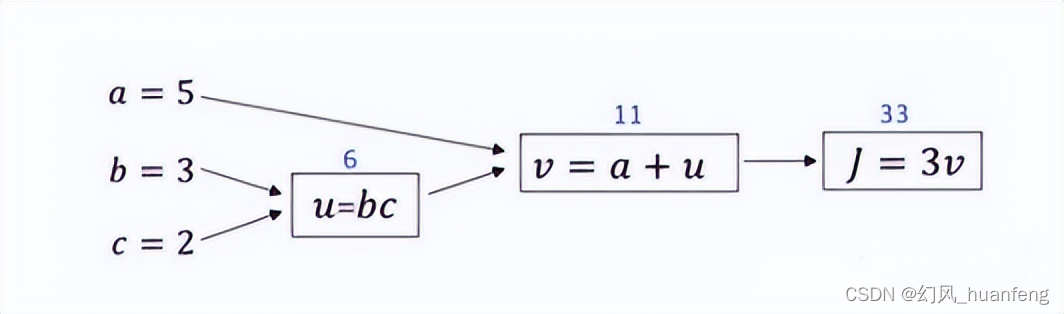
每天五分钟深度学习:如何使用计算图来反向计算参数的导数?
本文重点 在上一个课程中,我们使用一个例子来计算函数J,也就相当于前向传播的过程,本节课程我们将学习如何使用计算图计算函数J的导数。相当于反向传播的过程。 计算J对v的导数,dJ/dv3 计算J对a的导数,dJ/da…...
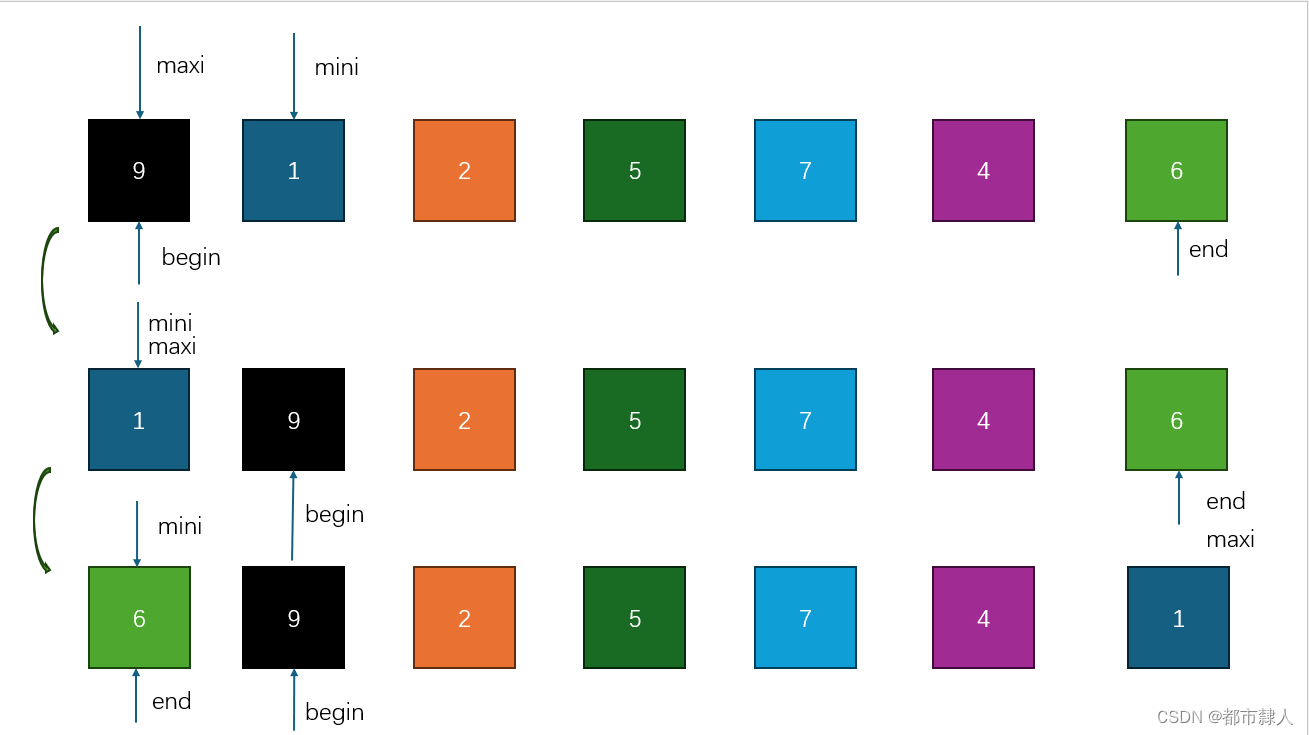
常见排序算法之选择排序
目录 一、选择排序 1.1 什么是选择排序? 1.2 思路 1.2.1 思路一 1.2.2 优化思路 1.3 C语言源码 1.3.1 思路一 1.3.2 优化思路 二、堆排序 2.1 调整算法 2.1.2 向上调整算法 2.1.3 向下调整算法 2.2 建堆排序 一、选择排序 1.1 什么是选择排序…...
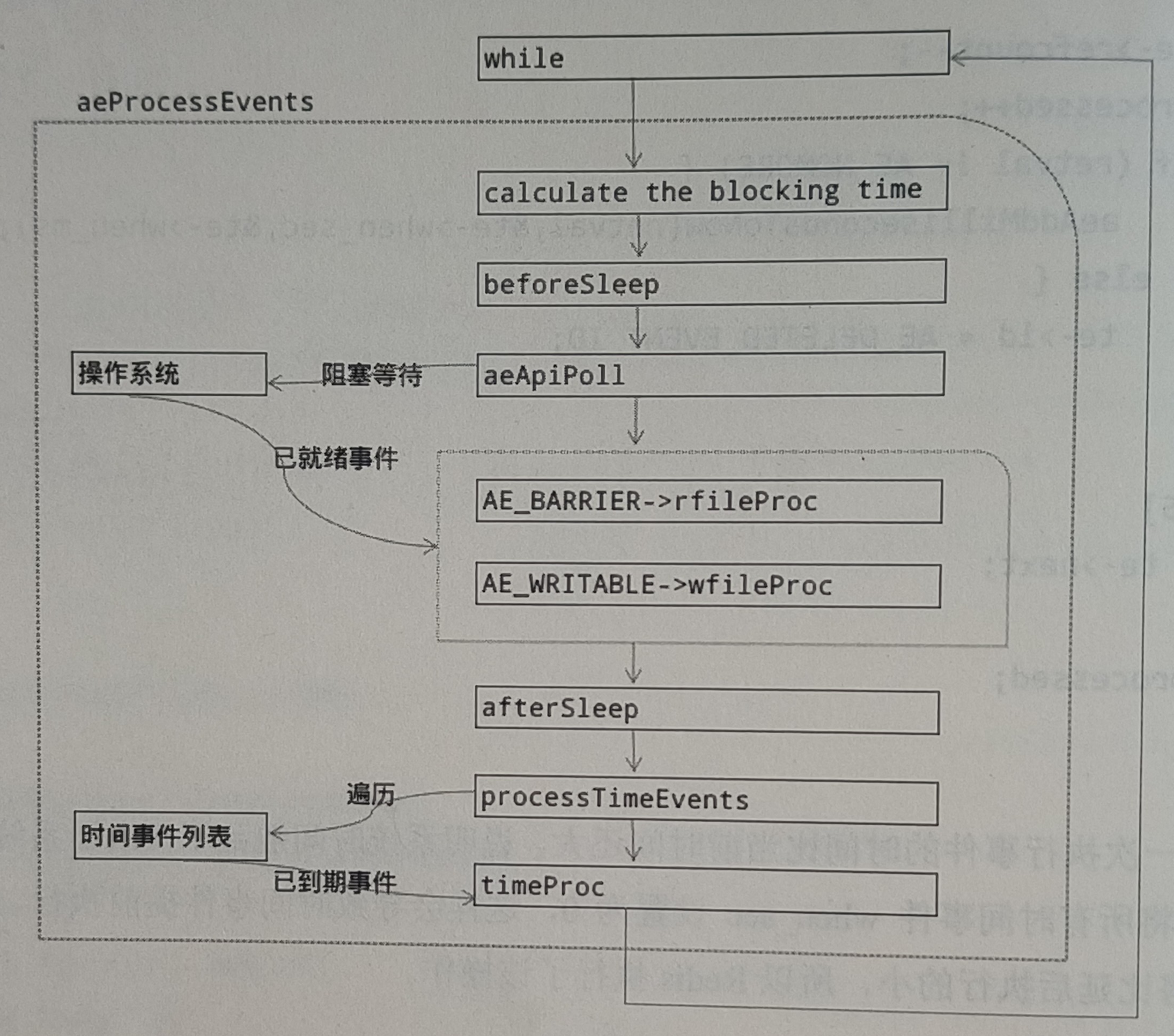
Redis 事件机制 - AE 抽象层
Redis 服务器是一个事件驱动程序,它主要处理如下两种事件: 文件事件:利用 I/O 复用机制,监听 Socket 等文件描述符上发生的事件。这类事件主要由客户端(或其他Redis 服务器)发送网络请求触发。时间事件&am…...
Java | Leetcode Java题解之第118题杨辉三角
题目: 题解: class Solution {public List<List<Integer>> generate(int numRows) {List<List<Integer>> ret new ArrayList<List<Integer>>();for (int i 0; i < numRows; i) {List<Integer> row new…...

DNS 解析过程
文章目录 简介特点查询方式⚡️1. 浏览器缓存2. 系统缓存(hosts文件)3. 路由器缓存4. 本地域名服务器5. 根域名服务器6. 顶级域名服务器7. 权限域名服务器8. 本地域名服务器缓存并返回9. 操作系统缓存并返回10. 浏览器缓存并访问流程图 总结 简介 DNS&a…...

Golang | Leetcode Golang题解之第118题杨辉三角
题目: 题解: func generate(numRows int) [][]int {ans : make([][]int, numRows)for i : range ans {ans[i] make([]int, i1)ans[i][0] 1ans[i][i] 1for j : 1; j < i; j {ans[i][j] ans[i-1][j] ans[i-1][j-1]}}return ans }...

操作系统实验——线程与进程
如果代码或文章中,有什么错误或疑惑,欢迎交流沟通哦~ ## 进程与线程的区别 1. **各自定义**: 进程是操作系统进行资源分配和调度的一个独立单位,具有一定独立功能的程序关于某个数据集合的依次运行活动。 线程被称为轻量级的进程…...
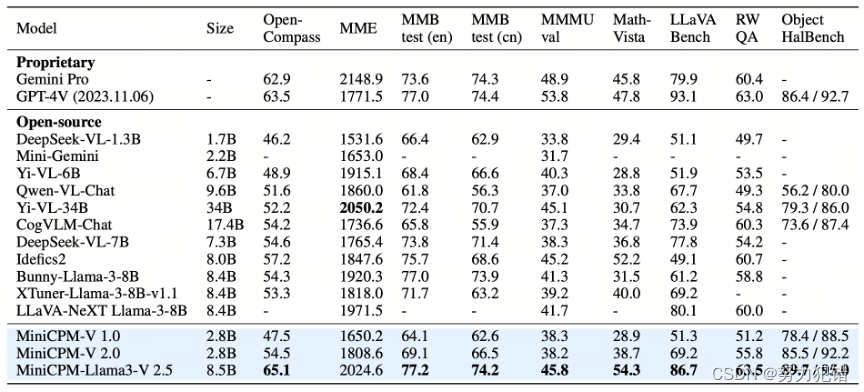
最强端侧多模态模型MiniCPM-V 2.5,8B 参数,性能超越 GPT-4V 和 Gemini Pro
前言 近年来,人工智能领域掀起了一股大模型热潮,然而大模型的巨大参数量级和高昂的算力需求,限制了其在端侧设备上的应用。为了打破这一局限,面壁智能推出了 MiniCPM 模型家族,致力于打造高性能、低参数量的端侧模型。…...
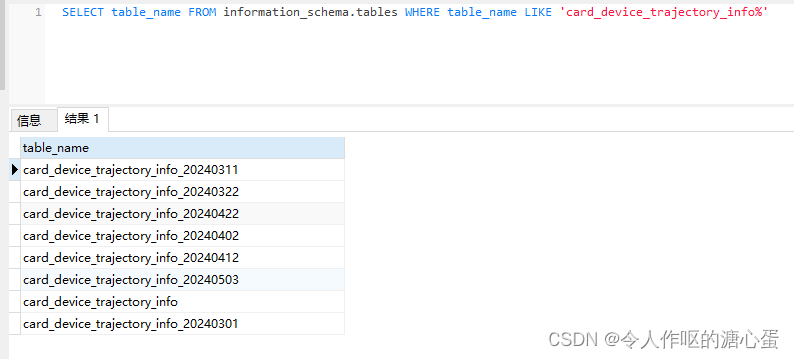
Spring Boot中如何查询PGSQL分表后的数据
数据库用的pgsql,在表数据超过100w条的时候执行定时任务进行了分表,分表后表名命名为原的表名后面拼接时间,如原表名是card_device_trajectory_info,分表后拼接时间后得到card_device_trajectory_info_20240503,然后分…...

如何学习一个新技能
1. 提出想法 2.找到学习方法,学习路径 3.开始学 参考视频:如何成为超速学习者?快速学会任何新技能!_哔哩哔哩_bilibili...

sklearn之logistic回归
文章目录 logistic回归logit logistic回归 logistic regression被称之为logistic回归,对于logistic这个单词来说,他本身的翻译其实不太容易,比较有名的译法是对数几率回归,我也认为这种译法是比较合适的,虽然并非logi…...
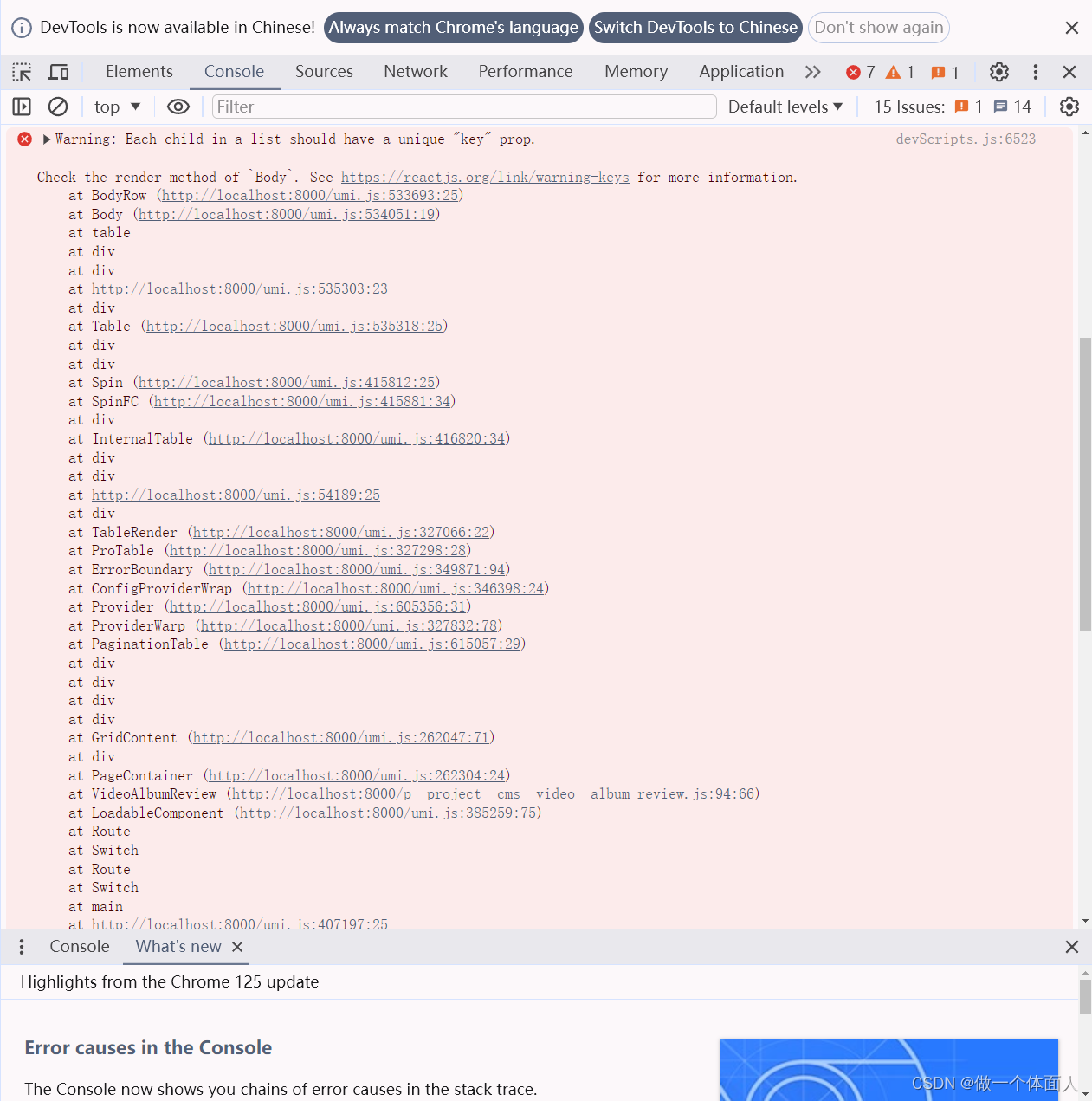
Warning: Each child in a list should have a unique “key“ prop.
问题描述: 使用ProTable的时候,报错如下 原因分析: 根据报错内容可以分析出,表格数据缺少唯一key, <PaginationTablecolumns{columns}pagination{{pageSize: 10,current: 1,showSizeChanger: true,showQuickJum…...
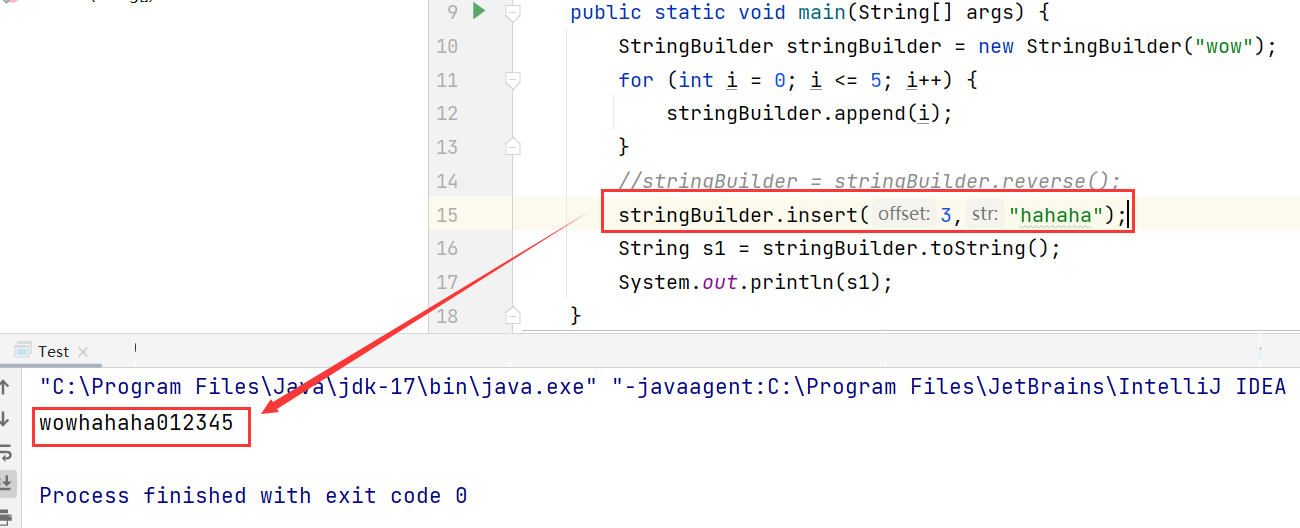
JavaSE:StringBuilder和StringBuffer类
1、引言 在上一篇文章中,我们理解了字符串的常用方法,细心的同学大概已经发现,不管是将字符串中的字符转变为大写或小写,或是完成字符串的替换,又或是去除空白字符等等,只要涉及到字符串的修改,…...

C语言在线编程网站:探索编程的奥秘与深度
C语言在线编程网站:探索编程的奥秘与深度 在数字世界的浩瀚海洋中,编程已成为连接现实与虚拟的桥梁。而C语言,作为编程领域的经典之作,其深度与广度令无数探索者着迷。为了满足广大编程爱好者的需求,C语言在线编程网站…...

Android 之广播监听网络变化
网络状态变化监听帮助类 NetBroadcastReceiverHelper public class NetBroadcastReceiverHelper {private static final String TAG "NetBroadcastReceiverHelper";private static final String NET_CHANGE_ACTION "android.net.conn.CONNECTIVITY_CHANGE&qu…...

SAP 梳理思路
蓝图 业务/需求背景 解决方案 配置 操作手册 程序 优化...

告别插线!用ESP32的OTA Web Updater实现无线烧录,保姆级避坑指南
ESP32无线固件更新全攻略:从零构建OTA Web Updater系统 引言:为什么需要无线更新? 想象一下,你精心设计的智能温室控制系统已经安装在屋顶的密闭箱体中,突然发现需要修复一个关键的温度传感器逻辑错误。传统方式需要…...

告别手动Coding:用EB tresos Studio配置TC3xx芯片MCAL的保姆级图文指南
告别手动Coding:用EB tresos Studio配置TC3xx芯片MCAL的保姆级图文指南 当TC3xx系列芯片遇上AUTOSAR架构,传统寄存器级开发方式正在被图形化配置彻底革新。对于每天需要面对微控制器底层驱动的嵌入式工程师而言,EB tresos Studio提供的可视化…...

RTX 40系列显卡需求强劲的背后:技术迭代、AI驱动与市场理性回归
1. 项目概述:从“矿难”到“复苏”,显卡市场的十字路口“显卡最坏的日子过去了?”——这大概是过去两年里,每一个关注PC硬件、游戏或者内容创作的玩家和从业者,心里反复掂量过无数次的问题。从2020年底开始,…...

Grounding DINO实战评测:对比GLIP、OV-DETR,在COCO和LVIS数据集上到底强在哪?
Grounding DINO技术解析:多模态开放集检测的突破与实践 在计算机视觉与自然语言处理的交叉领域,开放集目标检测正经历着前所未有的技术革新。传统检测模型受限于预定义类别集的桎梏,而新一代多模态大模型通过融合视觉与语言信号,实…...

serverless-http 与主流框架兼容性测试:Express、Koa、Hapi、Fastify 全面对比
serverless-http 与主流框架兼容性测试:Express、Koa、Hapi、Fastify 全面对比 【免费下载链接】serverless-http Use your existing middleware framework (e.g. Express, Koa) in AWS Lambda 🎉 项目地址: https://gitcode.com/gh_mirrors/se/server…...

Formation:macOS前端开发环境一键配置终极指南
Formation:macOS前端开发环境一键配置终极指南 【免费下载链接】formation 💻 macOS setup script for front-end development 项目地址: https://gitcode.com/gh_mirrors/fo/formation Formation是一款专为macOS设计的前端开发环境配置脚本&…...
的演进与实战选择)
从U盘到高端SSD:一文搞懂FTL映射表(块/页/混合)的演进与实战选择
从U盘到高端SSD:一文搞懂FTL映射表(块/页/混合)的演进与实战选择 存储设备的性能差异往往隐藏在底层算法的设计哲学中。当你在电商平台对比两款SSD时,是否思考过为什么同样标称1TB容量的产品,价格能相差数倍ÿ…...

2026年盲审前论文降AI攻略:盲审提交前AIGC超标免费4.8元知网达标完整处理方案
2026年盲审前论文降AI攻略:盲审提交前AIGC超标免费4.8元知网达标完整处理方案 答辩前三天,AI率还有74%。 翻遍论坛找方法,最终用嘎嘎降AI(www.aigcleaner.com)把74%降到6.8%,4.8元,当天搞定。…...

主从结合,安全互联:Anybus工业通信解决方案全栈升级
HMS亮相2026 PROFINET技术路演杭州站,展出全新Anybus SoM及全栈PROFINET方案,助力设备商应对CRA与机械法规双重合规挑战。 5月14日,由PI China主办的2026 PROFINET技术路演(杭州站)在西玥酒店圆满举行。HMS华东区OEM销…...