ResNet 原理剖析以及代码复现
原理
ResNet 解决了什么问题?
一言以蔽之:解决了深度的神经网络难以训练的问题。
具体的说,理论上神经网络的深度越深,其训练效果应该越好,但实际上并非如此,层数越深会导致越差的结果并且容易产生梯度爆炸或梯度消失等问题。
ResNet 怎么解决的?
提出了一个残差学习网络的框架,该框架解决了上述问题。
残差网络的架构
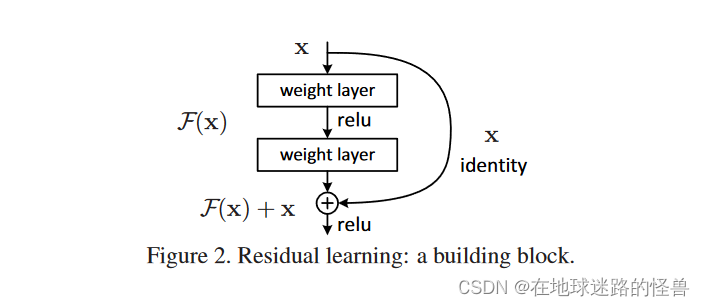
整个架构如上图所示。
首先我们要学习的东西是 H(x),假设现在已经有了一个浅的网络,然后我们要在上面新加一些层,让网络变得更深,如果按传统的做法那么新加的层就继续跟之前一样进行学习就行了。但是现在在新加的层中我们不直接去学 H(x),而是应该去学 H(x) - x。x 就是之前比较浅的网络已经学到的那个东西,也就是在新加的层中不去重新学个东西而只是学学到的东西和真实的东西二者之间的残差 H(x) - x,然后该层最后的输出结果 F(x) 再加上原始数据 x 就是最终结果也就是 F(x) + x ,此时优化的目标就不再是原始的 H(x),而是 H(x) - x 这个东西。
这就是 ResNet 的核心思想。
我感觉有一篇文章讲的很好,可以参考一下:ResNet网络详细讲解
下面是论文原文的描述:
在本文中,我们通过引入一个深度残差学习框架来解决退化问题。我们不希望每几个堆叠层直接拟合一个期望的底层映射,而是明确地让这些层拟合一个残差映射。在形式上,我们将期望的底层映射表示为H ( x ),并让堆叠的非线性层拟合F ( x )的另一个映射:= H ( x ) - x。原始映射被重铸成F ( x ) + x。我们假设优化残差映射比优化原始的、未引用的映射更容易。在极端情况下,如果一个恒等映射是最优的,那么将残差推到零比用一堆非线性层拟合一个恒等映射更容易。
F ( x ) + x的表达式可以通过具有"捷径连接"的前馈神经网络来实现(图2 )。快捷方式连接[ 2、33、48]是那些跳过一个或多个层的连接。在我们的例子中,快捷连接只是执行身份映射,它们的输出被添加到堆叠层的输出中(图2 )。身份捷径连接既不增加额外的参数,也不增加计算复杂度。整个网络仍然可以通过反向传播的SGD进行端到端的训练,并且可以很容易地使用公共库(例如, Caffe )实现,无需修改求解器。
我们在ImageNet [ 35 ]上进行了全面的实验来展示退化问题并评估我们的方法。研究表明:
1 )我们的深度残差网络易于优化,但对应的"普通"网络(简单地堆叠层)在深度增加时表现出更高的训练误差;
2 )我们的深度残差网络可以很容易地从大幅增加的深度中获得精度增益,产生的结果明显优于以前的网络。
在ImageNet分类数据集上[ 35 ],我们通过极深的残差网络获得了优异的结果。我们的152层残差网络是ImageNet上有史以来最深层的网络,但仍比VGG网络具有更低的复杂度[ 40 ]。我们的集成在ImageNet测试集上有3.57 %的top - 5误差,并在ILSVRC 2015分类竞赛中获得第一名。在其他识别任务上也具有出色的泛化性能,并引领我们在ILSVRC & COCO 2015竞赛中进一步获得第1名:ImageNet检测、ImageNet定位、COCO检测和COCO分割。这有力的证据表明,残差学习原理具有一般性,我们预期它在其他视觉和非视觉问题中也适用。
代码复现
这里给出我自己的模型代码:
import torch
from torch import nn# 基本残差块
class BasicBlock(nn.Module):expansion = 1"""参数解释:in_ch:输入通道数block_ch:输出通道数stride:步长,通过该参数我们就可以实现网络结构中特征图Size减半、通道数增加一倍的效果downSample:其本身也是一个网络,用来实现残差网络中的跳跃连接(也就是论文中虚线和实线)同时跳跃连接也是用来区别基本残差块和瓶颈残差块的,二者区别如下:基本残差块:输入输出通道数相同瓶颈残差块:输入输出通道数不同,需要进行升维操作才能对位相加另外二者的结构不同,可以通过论文看到"""def __init__(self, in_ch, block_ch, stride=1, downSample=None):super().__init__()self.downSample = downSample# 从网络结构图中可以看到,先进行第一层卷积self.conv1 = nn.Conv2d(in_ch, block_ch, kernel_size=3, stride=stride, padding=1, bias=False)# 在网络模型中添加一个二维批归一化(Batch Normalization)层。# 批归一化是一种用于加速神经网络训练并提高其性能的技术,类似于将上面所输出的数据进行了统一整理self.bn1 = nn.BatchNorm2d(block_ch)# 激活函数self.relu1 = nn.ReLU()# 第二层卷积self.conv2 = nn.Conv2d(block_ch, block_ch * self.expansion, kernel_size=3, stride=1, padding=1, bias=False)self.bn2 = nn.BatchNorm2d(block_ch * self.expansion)self.relu2 = nn.ReLU()def forward(self, x):identity = x# 如果downSample参数不为空,说明其需要升维(也就是论文中虚线的样子)if self.downSample is not None:# 升维,让输入输出的通道数对齐identity = self.downSample(x)out = self.relu1(self.bn1(self.conv1(x)))out = self.bn2(self.conv2(out))# 这里就是论文中的输出与原始输入进对位相加的步骤out += identity# 对位相加结束后再进行 relu 函数的激活,然后输出结果return self.relu2(out)# 瓶颈残差块
class Bottleneck(nn.Module):# 从论文的网络结构图中不难发现,瓶颈残差块在第三层卷积时通道数会放大四倍# 因此定义一个 expansion 变量expansion = 4"""参数解释:in_ch:输入通道数block_ch:输出通道数stride:步长,通过该参数我们就可以实现网络结构中特征图Size减半、通道数增加一倍的效果downSample:其本身也是一个网络,用来实现残差网络中的跳跃连接(也就是论文中虚线和实线)同时跳跃连接也是用来区别基本残差块和瓶颈残差块的,二者区别如下:基本残差块:输入输出通道数相同瓶颈残差块:输入输出通道数不同,需要进行升维操作才能对位相加另外二者的结构不同,可以通过论文看到"""def __init__(self, in_ch, block_ch, stride=1, downSample=None):super().__init__()self.downSample = downSample# 从网络结构图中可以看到,先进行第一层卷积self.conv1 = nn.Conv2d(in_ch, block_ch, kernel_size=1, stride=stride, bias=False)# 在网络模型中添加一个二维批归一化(Batch Normalization)层。# 批归一化是一种用于加速神经网络训练并提高其性能的技术,类似于将上面所输出的数据进行了统一整理self.bn1 = nn.BatchNorm2d(block_ch)# 激活函数self.relu1 = nn.ReLU()# 第二层卷积self.conv2 = nn.Conv2d(block_ch, block_ch, kernel_size=3, stride=1, padding=1, bias=False)self.bn2 = nn.BatchNorm2d(block_ch)self.relu2 = nn.ReLU()# 第三层卷积self.conv3 = nn.Conv2d(block_ch, block_ch * self.expansion, kernel_size=1, stride=1, bias=False)self.bn3 = nn.BatchNorm2d(block_ch * self.expansion)self.relu3 = nn.ReLU()def forward(self, x):identity = x# 如果downSample参数不为空,说明其需要升维(也就是论文中虚线的样子)if self.downSample is not None:# 升维,让输入输出的通道数对齐identity = self.downSample(x)out = self.relu1(self.bn1(self.conv1(x)))out = self.relu2(self.bn2(self.conv2(out)))out = self.bn3(self.conv3(out))# 这里就是论文中的输出与原始输入进对位相加的步骤out += identity# 对位相加结束后再进行 relu 函数的激活,然后输出结果return self.relu3(out)# 残差网络
class ResNet(nn.Module):"""in_ch: 默认为3,因为残差网络就是用来图片分类的,所以输入通道数默认为 3num_classes:分类的数量,默认设置为100,即 100 种分类block:用来区别是 基本残差块 还是 瓶颈残差块block_num:每个残差块所需要堆叠的次数(也是论文中提供的有)"""def __init__(self, in_ch=3, num_classes=100, block=Bottleneck, block_num=[3, 4, 6, 3]):super().__init__()# 因为在各层之间通道数会发生变化,因此要进行跟踪self.in_ch = in_ch# 对于残差网络来说,不管是什么类型其一开始都要进行 7x7 的卷积和 3x3 的池化# 因此我们直接照搬即可(论文中已经有了)self.conv1 = nn.Conv2d(in_ch, 64, kernel_size=7, stride=2, padding=3, bias=False)self.bn1 = nn.BatchNorm2d(64)self.maxpool1 = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)self.in_ch = 64# 将残差块堆叠起来,形成一个一个的残差层,进而构建成ResNetself.layer1 = self._make_layer(block, 64, block_num[0], stride=1)self.layer2 = self._make_layer(block, 128, block_num[1], stride=2)self.layer3 = self._make_layer(block, 256, block_num[2], stride=2)self.layer4 = self._make_layer(block, 512, block_num[3], stride=2)# 最后是全连接层,做预测的self.fc_layer = nn.Sequential(nn.Linear(512*block.expansion*7*7, num_classes),nn.Softmax(dim=-1))def _make_layer(self, block, block_ch, block_num, stride=2):layers = []downSample = nn.Conv2d(self.in_ch, block_ch * block.expansion, kernel_size=1, stride=stride)layers += [block(self.in_ch, block_ch, stride=stride, downSample=downSample)]self.in_ch = block_ch * block.expansionfor _ in range(1, block_num):layers += [block(self.in_ch, block_ch)]return nn.Sequential(*layers)def forward(self, x):out = self.maxpool1(self.bn1(self.conv1(x))) #(1, 3, 224, 224) -> (1, 64, 56, 56)out = self.layer1(out)out = self.layer2(out)out = self.layer3(out)out = self.layer4(out)out = out.reshape(out.shape[0], -1)out = self.fc_layer(out)return outif __name__ == '__main__':# 接下来进行测试# 这行代码创建了一个形状为 (1, 3, 224, 224) 的四维张量 x,# 其中包含了一个大小为 1 的批次中的一个 224x224 像素的 RGB 图像。x = torch.randn(1, 3, 224, 224)resnet = ResNet(in_ch=3, num_classes=100, block=Bottleneck, block_num=[2, 2, 2, 2])y = resnet(x)print(y.shape)相关文章:
ResNet 原理剖析以及代码复现
原理 ResNet 解决了什么问题? 一言以蔽之:解决了深度的神经网络难以训练的问题。 具体的说,理论上神经网络的深度越深,其训练效果应该越好,但实际上并非如此,层数越深会导致越差的结果并且容易产生梯度爆炸…...
数据结构(十)图
文章目录 图的简介图的定义图的结构图的分类无向图有向图带权图(Wighted Graph) 图的存储邻接矩阵(Adjacency Matrix)邻接表代码实现 图的遍历深度优先搜索(DFS,Depth Fisrt Search)遍历抖索过程…...

四数之和-力扣
本题在三数之和的基础上,再增加一重循环进行解答 首先注意的点是,一级剪枝处理,target > 0 && nums[i] > target 此处只有整数才可剪枝处理,如果target为负数,nums[i] < target,也不能代…...
JS 中怎么删除数组元素?有哪几种方法?
正文开始之前推荐一位宝藏博主免费分享的学习教程,学起来! 编号学习链接1Cesium: 保姆级教程+源码示例2openlayers: 保姆级教程+源码示例3Leaflet: 保姆级教程+源码示例4MapboxGL: 保姆级教程+源码示例splice() JavaScript中的splice()方法是一个内置的数组对象函数, 用于…...

Git如何将pre-commit也提交到仓库
我一开始准备将pre-commit提交到仓库进行备份的,但是却发现提交不了,即使我使用强制提交都不行。 (main) $ git add ./.git/hooks/pre-commit(main) $ git status On branch main nothing to commit, working tree clean# 强制提交(main) $ git add -f .…...

vmware中Ubuntu虚拟机和本地电脑Win10互相ping通
初始状态 使用vmware17版本安装的Ubuntu的20版本,安装之后什么配置都要不懂,然后进行下述配置。 初始的时候是NAT,没动的. 设置 点击右键编辑“属性” 常规选择“启用”: 高级选择全部: 打开网络配置,右键属…...

比较含退格的字符串-力扣
做这道题时出现了许多问题 第一次做题思路是使用双指针去解决,快慢指针遇到字母则前进,遇到 # 则慢指针退1,最开始并未考虑到 slowindex < 0 ,从而导致越界。第二个问题在于,在最后判断两个字符串是否相同时,最初使…...

NSSCTF-Web题目4
[SWPUCTF 2021 新生赛]hardrce 1、题目 2、知识点 rce:远程代码执行、url取反编码 3、解题思路 打开题目 出现一段代码,审计源代码 题目需要我们通过get方式输入变量wllm的值 但是变量的值被过滤了,不能输入字母和\t、\n等值 所以我们需…...

7. CSS 网格布局
CSS3引入了强大的网格布局(Grid Layout),它提供了一种二维的布局方式,使得创建复杂的网页布局变得更加简单和直观。通过定义行和列,我们可以精确控制网页元素的排列和对齐。本章将详细介绍网格布局的基本概念和属性&am…...

如何配置才能连接远程服务器上的 redis server ?
文章目录 Intro修改点 Intro 以阿里云服为例。 首先,我在我买的阿里云服务器中以下载源码、手动编译的方式安装了 redis-server,操作流程见:Ubuntu redis 下载解压配置使用及密码管理 && 包管理工具联网安装。 接着,我…...
MindSpore实践图神经网络之环境篇
MindSpore在Windows11系统下的环境配置。 MindSpore环境配置大概分为三步:(1)安装Python环境,(2)安装MindSpore,(3)验证是否成功 如果是GPU环境还需安装CUDA等环境&…...

MVS net笔记和理解
文章目录 传统的方法有什么缺陷吗?MVSnet深度的预估 传统的方法有什么缺陷吗? 传统的mvs算法它对图像的光照要求相对较高,但是在实际中要保证照片的光照效果很好是很难的。所以传统算法对镜面反射,白墙这种的重建效果就比较差。 …...
)
Linux 编译屏障之 ACCESS_ONCE()
文章目录 1. 前言2. 背景3. 为什么要有 ACCESS_ONCE() ?4. ACCESS_ONCE() 代码实现5. ACCESS_ONCE() 实例分析6. ACCESS() 的演进7. 结语8. 参考资料 1. 前言 限于作者能力水平,本文可能存在谬误,因此而给读者带来的损失,作者不做…...

Discuz!X3.4论坛网站公安备案号怎样放到网站底部?
Discuz!网站的工信部备案号都知道在后台——全局——站点信息——网站备案信息代码填写,那公安备案号要添加在哪里呢?并没有看到公安备案号填写栏,今天驰网飞飞和你分享 1)工信部备案号和公安备案号统一填写到网站备案…...

LPDDR6带宽预计将翻倍增长:应对低功耗挑战与AI时代能源需求激增
在当前科技发展的背景下,低能耗问题成为了业界关注的焦点。国际能源署(IEA)近期报告显示,日常的数字活动对电力消耗产生显著影响——每次Google搜索平均消耗0.3瓦时(Wh),而向OpenAI的ChatGPT提出的每一次请求则消耗2.9…...

云原生架构内涵_3.主要架构模式
云原生架构有非常多的架构模式,这里列举一些对应用收益更大的主要架构模式,如服务化架构模式、Mesh化架构模式、Serverless模式、存储计算分离模式、分布式事务模式、可观测架构、事件驱动架构等。 1.服务化架构模式 服务化架构是云时代构建云原生应用的…...

宏基因组分析流程(Metagenomic workflow)202405|持续更新
Logs 增加R包pctax内的一些帮助上游分析的小脚本(2024.03.03)增加Mmseqs2用于去冗余,基因聚类的速度非常快,且随序列量线性增长(2024.03.12)更新全文细节(2024.05.29) 注意&#x…...
)
一千题,No.0037(组个最小数)
给定数字 0-9 各若干个。你可以以任意顺序排列这些数字,但必须全部使用。目标是使得最后得到的数尽可能小(注意 0 不能做首位)。例如:给定两个 0,两个 1,三个 5,一个 8,我们得到的最…...

PV PVC
默写 1 如何将pod创建在指定的Node节点上 node亲和、pod亲和、pod反亲和: 调度策略 匹配标签 操作符 nodeAffinity 主机 In,NotIn,Exists,DoesNotExist,Gt,Lt podAffinity …...

深入理解Nginx配置文件:全面指南
Nginx 是一个高性能的 HTTP 服务器和反向代理服务器,也是一个电子邮件(IMAP/POP3)代理服务器。由于其高效性和灵活性,Nginx 被广泛应用于各种 web 服务中。本文将详细介绍 Nginx 配置文件的结构和主要配置项,帮助你深入…...

570-‘基于坠落机制改进的混沌麻雀算法SSACD‘在23个标准测试函数上可直接运行Matlab语言
570-基于坠落机制改进的混沌麻雀算法SSACD在23个标准测试函数测试可直接运行 Matlab语言 改进点如下: 1.首先,引入Sinusoidal混沌映射和变尺度混沌策略对种群进行初始化,提高种群多样性使算法具备跳出局部最优解的能力 2.其次,引入…...

【多模态实战】Swift框架高效微调Qwen2-VL:从SFT到RLHF的完整指南
1. 为什么选择Swift框架微调Qwen2-VL 第一次接触Qwen2-VL这个多模态大模型时,我被它强大的图文理解能力惊艳到了。但真正让我惊喜的是发现Swift框架能让模型微调变得如此简单。记得当时为了测试一个定制化需求,传统方法需要写上百行训练代码,…...

WindowsCleaner:智能化解救C盘空间危机的开源解决方案
WindowsCleaner:智能化解救C盘空间危机的开源解决方案 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner 一、痛点剖析:C盘空间管理的深层困境…...

BepInEx Linux环境实战指南:从部署到故障解决
BepInEx Linux环境实战指南:从部署到故障解决 【免费下载链接】BepInEx Unity / XNA game patcher and plugin framework 项目地址: https://gitcode.com/GitHub_Trending/be/BepInEx 引言:Linux玩家的Mod困境 作为Linux平台的Unity游戏玩家&…...
)
Mac新手必看:保姆级教程教你用阿里源加速Homebrew安装(附一键脚本)
Mac新手必备:用阿里云镜像极速部署Homebrew全攻略 刚入手MacBook的你,可能正摩拳擦掌准备搭建开发环境。但当你在终端输入brew install python后,进度条却像蜗牛爬行——这不是你的网络问题,而是Homebrew默认从GitHub拉取资源时&a…...

AI 模型推理引擎性能比较
AI模型推理引擎性能比较:解锁高效计算的秘密 在人工智能技术快速发展的今天,AI模型推理引擎的性能直接决定了实际应用的效率和成本。无论是云端服务还是边缘设备,选择一款高效的推理引擎可以大幅提升响应速度、降低资源消耗。本文将从计算速…...

实时数据复制技术在大数据平台中的应用与实践
实时数据复制技术在大数据平台中的应用与实践关键词:实时数据复制、大数据平台、CDC(变更数据捕获)、数据同步、数据一致性、分布式系统、ETL摘要:本文深入探讨了实时数据复制技术在大数据平台中的核心应用场景与实践方法。我们将…...

论文被吐槽逻辑乱?,有哪些真正实测靠谱的的降AI率工具推荐?
毕业论文降AIGC率,优先选语义重构 去AI痕迹 降查重率的工具,免费与付费结合最稳妥。下面按中文、英文、免费/付费分类推荐,附实测效果与适用场景。 一、中文论文降重工具(最常用) 1. 千笔AI(综合全能首选…...

淘宝淘金币自动化脚本:每天节省20分钟的终极解决方案
淘宝淘金币自动化脚本:每天节省20分钟的终极解决方案 【免费下载链接】taojinbi 淘宝淘金币自动执行脚本,包含蚂蚁森林收取能量,芭芭农场全任务,解放你的双手 项目地址: https://gitcode.com/gh_mirrors/ta/taojinbi 淘宝淘…...

突破性全流程AI科研助手:AI-Scientist-v2重塑科学探索范式
突破性全流程AI科研助手:AI-Scientist-v2重塑科学探索范式 【免费下载链接】AI-Scientist-v2 The AI Scientist-v2: Workshop-Level Automated Scientific Discovery via Agentic Tree Search 项目地址: https://gitcode.com/GitHub_Trending/ai/AI-Scientist-v2 …...