LLM主流开源代表模型
LLM主流开源大模型介绍

1 LLM主流大模型类别
随着ChatGPT迅速火爆,引发了大模型的时代变革,国内外各大公司也快速跟进生成式AI市场,近百款大模型发布及应用。
目前,市面上已经开源了各种类型的大语言模型,本章节我们主要介绍其中的三大类:
-
ChatGLM-6B:衍生的大模型(wenda、ChatSQL等)
-
LLaMA:衍生的大模型(Alpaca、Vicuna、BELLE、Phoenix、Chimera等)
-
Bloom:衍生的大模型(Bloomz、BELLE、Phoenix等)
2 ChatGLM-6B模型
ChatGLM-6B 是清华大学提出的一个开源、支持中英双语的对话语言模型,基于 General Language Model (GLM) 架构,具有 62 亿参数。该模型使用了和 ChatGPT 相似的技术,经过约 1T 标识符的中英双语训练(中英文比例为 1:1),辅以监督微调、反馈自助、人类反馈强化学习等技术的加持,62 亿参数的 ChatGLM-6B 已经能生成相当符合人类偏好的回答(目前中文支持最好)。
2.1 训练目标
GLM是一种基于自回归空白填充目标的通用预训练框架。GLM 将 NLU 任务转化为包含任务描述的完形填空问题,可以通过自回归生成的方式来回答。自回归空白填充目标是指在输入文本中随机挖去一些连续的文本片段,然后训练模型按照任意顺序重建这些片段。完形填空问题是指在输入文本中用一个特殊的符号(如[MASK])替换掉一个或多个词,然后训练模型预测被替换掉的词。
GLM的实现思想(训练目标):
- 原始文本 x = [ x 1 , x 2 , . . . , x 6 ] x=[x_1, x_2,...,x_6] x=[x1,x2,...,x6]随机进行连续 mask,这里假设 mask 掉 [ x 3 ] [x_3] [x3]和 [ x 5 , x 6 ] [x_5,x_6] [x5,x6] .
- 将 [ x 3 ] [x_3] [x3]和 [ x 5 , x 6 ] [x_5,x_6] [x5,x6] 替换为 [M] 标志,并打乱 Part B 的顺序。为了捕捉跨度之间的内在联系,随机交换跨度的顺序。
- GLM 自回归地生成 Part B。 每个片段在输入时前面加上 [S],在输出时后面加上 [E]。 二维位置编码表示不同片段之间和片段内部的位置关系。
- 自注意力掩码。 灰色区域被掩盖。Part A 的词语可以自我看到(图蓝色框),但不能看到 Part B。 Part B 的词语可以看到 Part A 和 Part B 中的前面的词语(图黄色和绿色框对应两个片段)。 [M] := [MASK],[S] := [START],[E] := [END]
注意:
Position1 和 Position2 是输入的二维编码,第一个维度表示片段在原始文本中的相对位置,第二个维度表示片段内部的相对位置。
假设原始文本是 x = [ x 1 , x 2 , . . . , x 6 ] x=[x_1, x_2,...,x_6] x=[x1,x2,...,x6],其中 [ x 3 ] [x_3] [x3]和 [ x 5 , x 6 ] [x_5,x_6] [x5,x6] 被挖去。那么,被挖去的片段在第一个维度上的位置编码就是它们在原始文本中的索引,即 [ x 3 ] [x_3] [x3]来自片段 3, [ x 5 , x 6 ] [x_5,x_6] [x5,x6] 来自片段 5。在第二个维度上的位置编码就是它们在片段中的索引,即 0 和 1。因此, x 3 x_3 x3的二维位置编码是[3, 0], x 5 x_5 x5的二维位置编码是[5, 0], x 6 x_6 x6 的二维编码是[5, 1]。
同样,我们可以得到 x 1 x_1 x1的二维位置编码是[1, 0], x 2 x_2 x2的位置编码是[2, 0], x 4 x_4 x4的位置编码是[4, 0]。
2.2 模型结构
ChatGLM-6B 采用了 prefix decoder-only 的 transformer 模型框架,在输入上采用双向的注意力机制,在输出上采用单向注意力机制。
相比原始Decoder模块,模型结构有如下改动点:
- embedding 层梯度缩减:为了提升训练稳定性,减小了 embedding 层的梯度。梯度缩减的效果相当于把 embedding 层的梯度缩小了 10 倍,减小了梯度的范数。
- layer normalization:采用了基于 Deep Norm 的 post layer norm。
- 激活函数:替换ReLU激活函数采用了 GeLU 激活函数。
- GeLU的特点:
- 相比ReLU稳定且高效
- 缓解梯度消失
- GeLU的特点:
- 位置编码:去除了绝对位置编码,采用了旋转位置编码 RoPE。
2.3 模型配置(6B)
| 配置 | 数据 |
|---|---|
| 参数 | 6.2B |
| 隐藏层维度 | 4096 |
| 层数 | 28 |
| 注意力头数 | 32 |
| 训练数据 | 1T |
| 词表大小 | 130528 |
| 最大长度 | 2048 |
2.4 硬件要求
| 量化等级 | 最低GPU显存(推理) | 最低GPU显存(高效参数微调) |
|---|---|---|
| FP16(无量化) | 13GB | 14GB |
| INT8 | 10GB | 9GB |
| INT4 | 6GB | 7GB |
2.5 模型特点
优点:
-
较低的部署门槛: INT4 精度下,只需6GB显存,使得 ChatGLM-6B 可以部署在消费级显卡上进行推理。
-
更长的序列长度: 相比 GLM-10B(序列长度1024),ChatGLM2-6B 序列长度达32K,支持更长对话和应用。
-
人类类意图对齐训练
缺点:
-
模型容量小,相对较弱的模型记忆和语言能力。
-
较弱的多轮对话能力。
2.6 衍生应用
LangChain-ChatGLM:基于 LangChain 的 ChatGLM 应用,实现基于可扩展知识库的问答。
闻达:大型语言模型调用平台,基于 ChatGLM-6B 实现了类 ChatPDF 功能
3 LLaMA模型
LLaMA(Large Language Model Meta AI),由 Meta AI 于2023年发布的一个开放且高效的大型基础语言模型,共有 7B、13B、33B、65B(650 亿)四种版本。
LLaMA训练数据是以英语为主的拉丁语系,另外还包含了来自 GitHub 的代码数据。训练数据以英文为主,不包含中韩日文,所有训练数据都是开源的。其中LLaMA-65B 和 LLaMA-33B 是在 1.4万亿 (1.4T) 个 token上训练的,而最小的模型 LLaMA-7B 和LLaMA-13B 是在 1万亿 (1T) 个 token 上训练的。
3.1 训练目标
在训练目标上,LLaMA 的训练目标是语言模型,即根据已有的上文去预测下一个词。
关于tokenizer,LLaMA 的训练语料以英文为主,使用了 Sentence Piece 作为 tokenizer,词表大小只有 32000。词表里的中文 token 很少,只有几百个,LLaMA tokenizer 对中文分词的编码效率比较低。
3.2 模型结构
和 GPT 系列一样,LLaMA 模型也是 Decoder-only`架构,但结合前人的工作做了一些改进,比如:
-
Pre-normalization:为了提高训练稳定性,没有使用传统的 post layer norm,而是使用了 pre layer Norm,同时使用 RMSNorm归一化函数(RMS Norm的主要区别在于去掉了减去均值的部分,简化了Layer Norm 的计算,可以在减少约 7%∼64% 的计算时间)。
-
layer normalization:采用了基于 Deep Norm 的 post layer norm。
-
激活函数:将 ReLU 非线性替换为 SwiGLU 激活函数。
-
位置编码:去除了绝对位置编码,采用了旋转位置编码 RoPE。
3.3 模型配置(7B)
| 配置 | 数据 |
|---|---|
| 参数 | 6.7B |
| 隐藏层维度 | 4096 |
| 层数 | 32 |
| 注意力头数 | 32 |
| 训练数据 | 1T |
| 词表大小 | 32000 |
| 最大长度 | 2048 |
3.4 硬件要求
65B的模型,在2048个80G的A100 GPU上,可以达到380 tokens/sec/GPU的速度。训练1.4T tokens需要21天。
3.5 模型特点
优点:
-
具有 130 亿参数的 LLaMA 模型「在大多数基准上」可以胜过 GPT-3( 参数量达 1750 亿)。
-
可以在单块 V100 GPU 上运行;而最大的 650 亿参数的 LLaMA 模型可以媲美谷歌的 Chinchilla-70B 和 PaLM-540B。
缺点:
-
会产生偏见性、有毒或者虚假的内容.
-
在中文上效果差,训练语料不包含中文或者一个汉字切分为多个 token,编码效率低,模型学习难度大。
3.6 衍生应用
Alpaca: 斯坦福大学在 52k 条英文指令遵循数据集上微调了 7B 规模的 LLaMA。
Vicuna: 加州大学伯克利分校在 ShareGPT 收集的用户共享对话数据上,微调了 13B 规模的 LLaMA。
BELLE: 链家仅使用由 ChatGPT 生产的数据,对 LLaMA 进行了指令微调,并针对中文进行了优化。
Chinese LLaMA:
- 扩充中文词表:常见做法:在中文语料上使用 Sentence Piece 训练一个中文 tokenizer,使用了 20000 个中文词汇。然后将中文 tokenizer 与原始的 LLaMA tokenizer 合并起来,通过组合二者的词汇表,最终获得一个合并的 tokenizer,称为 Chinese LLaMA tokenizer。词表大小为 49953。
4 BLOOM模型
BLOOM系列模型是由 Hugging Face公司的BigScience 团队训练的大语言模型。训练数据包含了英语、中文、法语、西班牙语、葡萄牙语等共 46 种语言,另外还包含 13 种编程语言。1.5TB 经过去重和清洗的文本,转换为 350B 的 tokens。训练数据的语言分布如下图所示,可以看到中文语料占比为 16.2%
按照模型参数量,BLOOM 模型有 560M、1.1B、1.7B、3B、7.1B 和 176B 这几个不同参数规模的模型。
4.1 训练目标
在训练目标上,LLaMA 的训练目标是语言模型,即根据已有的上文去预测下一个词。
关于tokenizer,BLOOM 在多语种语料上使用 Byte Pair Encoding(BPE)算法进行训练得到 tokenizer,词表大小为 250880。
4.2 模型结构
和 GPT 系列一样,LLaMA 模型也是 Decoder-only 架构,但结合前人的工作做了一些改进,比如:
- embedding layer norm:在 embedding 层后添加了一个 layer normalization,来使训练更加稳定。
- layer normalization:为了提升训练的稳定性,没有使用传统的 post layer norm,而是使用了 pre layer Norm。
- 激活函数:采用了 GeLU 激活函数。
- 位置编码:去除了绝对位置编码,采用了相对位置编码 ALiBi。相比于绝对位置编码,ALiBi 的外推性更好,即虽然训练阶段的最大序列长度为 2048,模型在推理过程中可以处理更长的序列。
4.3 模型配置(176B)
| 配置 | 数据 |
|---|---|
| 参数 | 176B |
| 隐藏层维度 | 14336 |
| 层数 | 70 |
| 注意力头数 | 112 |
| 训练数据 | 366B |
| 词表大小 | 250880 |
| 最大长度 | 2048 |
4.4 硬件要求
176B-BLOOM 模型在384 张 NVIDIA A100 80GB GPU上,训练于 2022 年 3 月至 7 月期间,耗时约 3.5 个月完成 (约 100 万计算时),算力成本超过300万欧元
4.5 模型特点
优点:
- 具有良好的多语言适应性,能够在多种语言间进行切换,且无需重新训练
缺点:
- 会产生偏见性、有毒或者虚假的内容.
4.6 衍生应用
轩辕: 金融领域大模型,度小满在 BLOOM-176B 的基础上针对中文通用领域和金融领域进行了针对性的预训练与微调。
BELLE: 链家仅使用由 ChatGPT 生产的数据,对 BLOOMZ-7B1-mt 进行了指令微调。
小结
主要介绍了LLM主流的开源大模型,对不同模型架构、训练目标、优缺点进行了分析和总结。
相关文章:
LLM主流开源代表模型
LLM主流开源大模型介绍 1 LLM主流大模型类别 随着ChatGPT迅速火爆,引发了大模型的时代变革,国内外各大公司也快速跟进生成式AI市场,近百款大模型发布及应用。 目前,市面上已经开源了各种类型的大语言模型,本章节我们…...

Openharmony的usb从框架到hdf驱动流程梳理
HDF框架实现了用户层与内核层进行通信的管理框架,关于其简易通信示例在以下两篇博文中有所介绍, 一个例子了解通过Openharmony的HDF框架实现简易驱动的流程https://blog.csdn.net/procedurecode/article/details/128906246 Openharmony的用户态应用通过HDF框架驱动消息机制…...
Apache Doris 基础 -- 数据表设计(数据模型)
Versions: 2.1 1、模型概览 本主题从逻辑角度介绍了Doris中的数据模型,以便您可以在不同的业务场景中更好地使用Doris。 基本概念 本文主要从逻辑的角度描述Doris的数据模型,旨在帮助用户在不同的场景更好地利用Doris。 在Doris中,数据在…...

“雪糕刺客”爆改“红薯刺客”,钟薛高给了消费品牌哪些启示?
夏日袭来,一支价格高昂却让人眼前一亮的雪糕,曾一度成为市场热议的焦点。然而,随着消费者对性价比的日益关注,曾经的“雪糕刺客”钟薛高,其创始人林盛近期以直播带货红薯开启他的还债之路,高打情怀“直播自…...
多输入多输出非线性对象的模型预测控制—Matlab实现
本示例展示了如何在 Simulink 中设计多输入多输出对象的闭环模型预测控制。该对象有三个操纵变量和两个测量输出。 一、非线性对象的线性化 运行该示例需要同时安装 Simulink 和 Simulink Control Design。 % 检查是否同时安装了 Simulink 和 Simulink Control Design if ~m…...

多项分布模拟及 Seaborn 可视化教程
多项分布 简介 多项分布是二项分布的推广,它描述了在 n 次独立试验中,k 种不同事件分别出现次数的离散概率分布。与二项分布只能有两种结果(例如成功/失败)不同,多项分布可以有 k 种(k ≥ 2)及…...

学计算机,我错了吗?
今天,我的一位朋友告诉我,终于找到一家小公司入职,年前 1 月辞职,本想休息一段时间,没成想,休息到 6 月份,现在程序员真的越来越难找工作了。 肯定有人在想,现在这种行情࿰…...

学习小心意——简单的循坏语句
for循坏 基本语法格式 for 变量 in 序列:代码块 示例代码如下 for i in range(10):print(i)#输出结果:0 1 2 3 4 5 6 7 8 9 简单案例代码如下 利用for语句遍历序列 # 遍历字符串打印每个字母 for letter in "python":print(letter)# 遍历列表并打印每个元素 a …...

C++ 类方法解析:内外定义、参数、访问控制与静态方法详解
C 类方法 类方法,也称为成员函数,是属于类的函数。它们用于操作或查询类数据,并封装在类定义中。类方法可以分为两种类型: 类内定义方法: 直接在类定义内部声明和定义方法。类外定义方法: 在类定义内部声明方法,并在…...
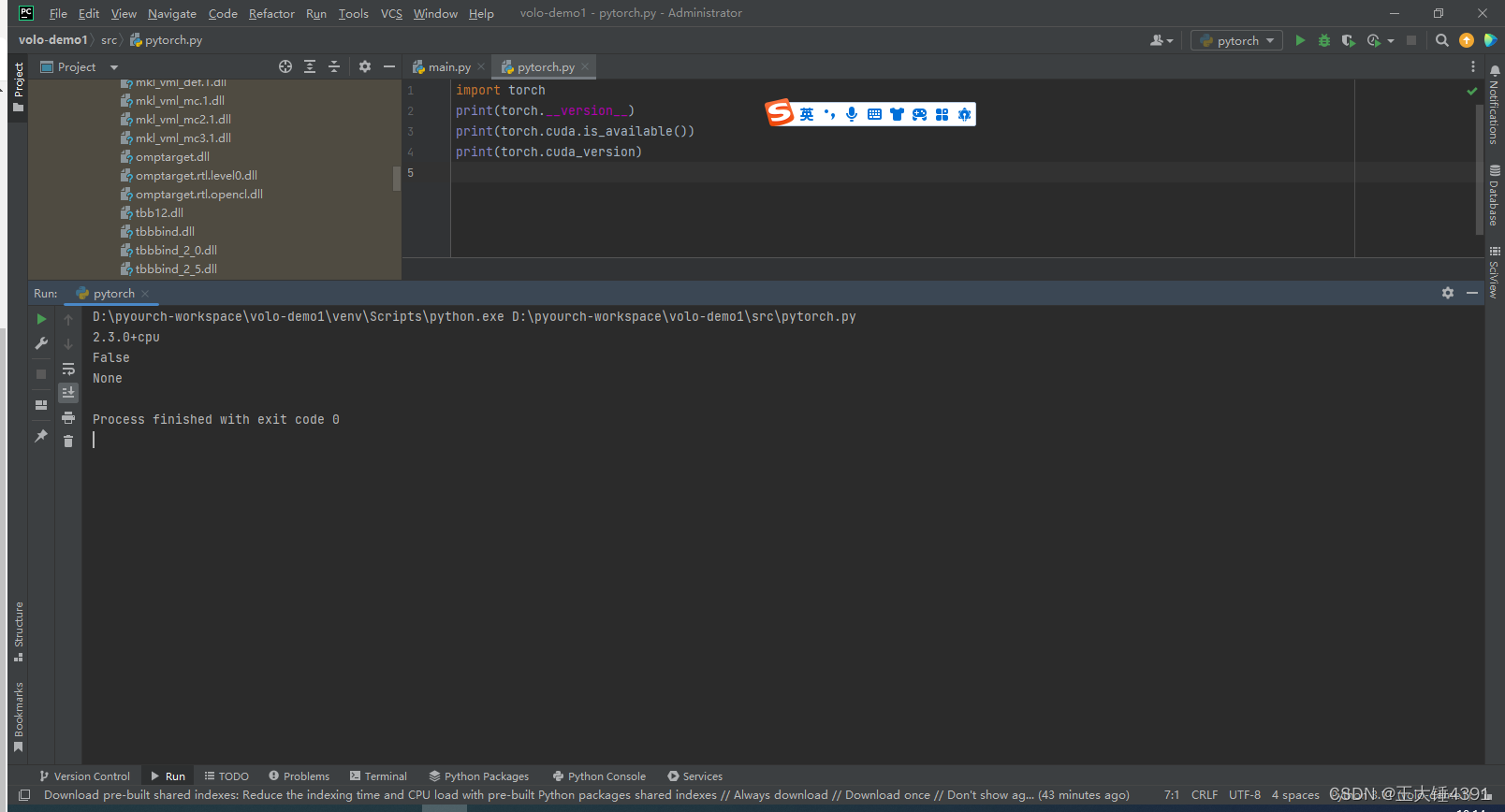
pytorch+YOLOv8-1
1.工具开发 2.idea配置pytorch环境 默认安装新版本torch pip install torch 3.pytorch验证 4. print(torch.cuda.is_available()) 输出结果为 False 说明我只能用cpu...

JavaScript 基础 - 对象
对象 对象是一种无序的数据集合,可以详细的描述描述某个事物。 注意数组是有序的数据集合。它由属性和方法两部分构成。 语法 声明一个对象类型的变量与之前声明一个数值或字符串类型的变量没有本质上的区别。 <script>let 对象名 {属性名:属性值…...

代码随想录第23天|回溯part3 组合与分割
39.组合总和 class Solution { public:vector<vector<int>> res;vector<int> path;void backTracking(vector<int>& candidates,int target,int sum,int n,int step){if(n > 150) return;if(sum > target) return;if(sum target){res.push_…...

nginx和proxy_protocol协议
目录 1. 引言2. HTTP server的配置3. Stream server的配置3.1 作为proxy_protocol的前端服务器3.2 作为proxy_protocol的后端服务器1. 引言 proxy_protocol 是haproxy开发的一种用于在代理服务器和后端服务器之间传递客户端连接信息的协议。使用 proxy_protocol 的主要优势是能…...

【pytorch】数据转换/增强后保存
数据转换 from PIL import Image from pathlib import Path import matplotlib.pyplot as plt import numpy as npimport torch import torchvision.transforms as Tplt.rcParams["savefig.bbox"] = tight # orig_im...
超越Devin!姚班带队,他们创大模型编程新世界纪录
超越Devin!SWEBench排行榜上迎来了新玩家—— StarShip CodeGen Agent,姚班带队初创公司OpenCSG出品,以23.67%的成绩获得全球第二名的成绩。 同时创造了非GPT-4o基模的最高纪录(SOTA)。 我们都知道,SWEBe…...

江苏大信环境科技有限公司:环保领域的开拓者与引领者
2009 年,江苏大信环境科技有限公司在宜兴环保科技工业园成立。自创立之始,该公司便笃定坚守“诚信为本、以质量求生存、以创新谋发展”这一经营理念,全力以赴为客户构建专业的工业有机废气治理整体解决方案,进而成为国家高新技术企…...

关于 Bean 容器的注入方式,99 % 的人都答不全!
引言:在使用 Spring 框架开发应用程序时,依赖注入是一个至关重要的概念。而对于 Bean 容器的注入方式,虽然我们可能都有一定的了解,但实际上很多人在被问及这个问题时可能并不能完整地回答。本文将深入探讨 Spring 中 Bean 容器的…...

Spring的@Async注解及其用途
Spring 的 Async 注解是 Spring Framework 4.2 版本引入的功能,它用于支持异步方法执行。当一个方法标注了 Async,Spring 会在一个单独的线程中调用该方法,从而不会阻塞主线程的执行。 Async 注解的用途: 提高性能:通…...
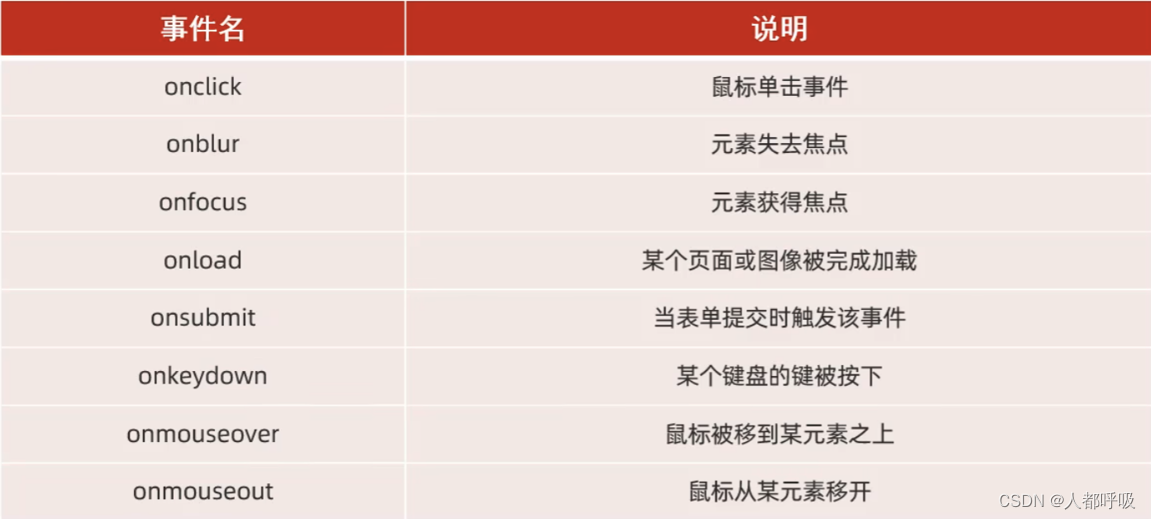
JS(DOM、事件)
DOM 概念:Document Object Model,文档对象模型。将标记语言的各个组成部分封装为对应的对象: Document:整个文档对象Element:元素对象Attribute:属性对象Text:文本对象Comment:注释对象 JavaScript通过DOM,就能够对HTML进行操作: 改变 HTML 元素的内…...

学习小心意——python的构造方法和析构方法
构造方法和析构方法分别用于初始化对象的属性和释放类占有的资源 构造方法_init_() 语法格式如下: class 类名:def __init__(self, 参数1, 参数2, ...):# 初始化代码self.属性1 参数1self.属性2 参数2# ... 示例代码如下 class Student:def __init__(self):s…...

Wireshark网络协议分析与故障排查实战指南
1. Wireshark网络分析入门指南作为一名网络工程师,我使用Wireshark进行网络故障排查已有8年时间。这款开源网络协议分析器确实改变了我的工作方式,让我能够直观地"看到"网络流量。记得第一次使用Wireshark分析一个棘手的TCP连接问题时…...
)
【2026年最新600套毕设项目分享】springboot校园二手交易系统(14339)
有需要的同学,源代码和配套文档领取,加文章最下方的名片哦 一、项目演示 项目演示视频 二、资料介绍 完整源代码(前后端源代码SQL脚本)配套文档(LWPPT开题报告/任务书)远程调试控屏包运行一键启动项目&…...

在Ubuntu 22.04上搞定SRILM 1.7.3:从下载到`make test`成功的保姆级记录
在Ubuntu 22.04上搞定SRILM 1.7.3:从下载到make test成功的保姆级记录 如果你正在Ubuntu 22.04上折腾SRILM 1.7.3,大概率已经发现那些老掉牙的教程根本不管用。别担心,这篇实战记录会带你避开所有新系统环境下的坑——从依赖项安装到Makefile…...

Steam Depot清单自动化工具:Onekey实现游戏数据高效管理的完整方案
Steam Depot清单自动化工具:Onekey实现游戏数据高效管理的完整方案 【免费下载链接】Onekey Onekey Steam Depot Manifest Downloader 项目地址: https://gitcode.com/gh_mirrors/one/Onekey 在游戏开发与玩家社区中,获取和管理Steam游戏清单一直…...

云原生下的PostgreSQL高可用实战:在K8s里用StatefulSet和Patroni API告别VIP和HAProxy
云原生时代的PostgreSQL高可用架构:基于Kubernetes与Patroni的实践指南 当企业的数据库基础设施全面转向云原生环境时,传统基于虚拟机的高可用方案显得格格不入。在Kubernetes生态中,StatefulSet控制器和Patroni的Kubernetes原生集成让我们能…...

Harbor集成Trivy实现镜像安全扫描:从安装到离线环境配置全指南
1. 为什么需要Harbor集成Trivy进行镜像安全扫描 在容器化部署成为主流的今天,一个NGINX镜像可能隐藏着数十个安全漏洞而不自知。去年某金融公司就曾因为使用了存在高危漏洞的Redis镜像,导致数据泄露事件。这种案例让我深刻意识到:镜像安全扫描…...

UFS4.0协议之电源与信号完整性设计探析
1. UFS4.0协议的核心电源架构解析 第一次拆解UFS4.0存储芯片时,我被其电源系统的精密设计震撼到了。与早期版本相比,UFS4.0将供电网络细分为VCC(2.5V)、VCCQ(1.2V)和VCCQ2(1.8V)三级…...

5大核心功能深度解析:AltDrag如何重新定义Windows窗口管理效率
5大核心功能深度解析:AltDrag如何重新定义Windows窗口管理效率 【免费下载链接】altdrag :file_folder: Easily drag windows when pressing the alt key. (Windows) 项目地址: https://gitcode.com/gh_mirrors/al/altdrag 在Windows系统中,窗口管…...

告别手动敲命令:用Rancher 2.9.2的Web界面,5分钟搞定K8S 1.26集群的Nginx部署
告别手动敲命令:用Rancher 2.9.2的Web界面,5分钟搞定K8S 1.26集群的Nginx部署 在Kubernetes的世界里,部署一个简单的Nginx服务往往需要编写复杂的YAML文件,记忆各种kubectl命令参数,这对于刚接触K8S的开发者或小型运维…...

【深度学习OFDM信号处理】Deep-Waveform:基于复值神经网络的端到端OFDM接收机设计与实现【附MATLAB/Python代码】
1. 为什么需要深度学习处理OFDM信号? 传统OFDM接收机依赖离散傅里叶变换(DFT)进行时频域转换,这种固定算法在面对复杂无线环境时存在明显局限。我在实际项目中遇到过这样的情况:当信道出现严重多径衰落时,传…...