AI大模型探索之路-实战篇15: Agent智能数据分析平台之整合封装Tools和Memory功能代码
系列篇章💥
AI大模型探索之路-实战篇4:深入DB-GPT数据应用开发框架调研
AI大模型探索之路-实战篇5:探索Open Interpreter开放代码解释器调研
AI大模型探索之路-实战篇6:掌握Function Calling的详细流程
AI大模型探索之路-实战篇7:Function Calling技术实战自动生成函数
AI大模型探索之路-实战篇8:多轮对话与Function Calling技术应用
AI大模型探索之路-实战篇9:探究Agent智能数据分析平台的架构与功能
AI大模型探索之路-实战篇10:数据预处理的艺术:构建Agent智能数据分析平台的基础
AI大模型探索之路-实战篇11: Function Calling技术整合:强化Agent智能数据分析平台功能
AI大模型探索之路-实战篇12: 构建互动式Agent智能数据分析平台:实现多轮对话控制
AI大模型探索之路-实战篇13: 从对话到报告:打造能记录和分析的Agent智能数据分析平台
AI大模型探索之路-实战篇14: 集成本地Python代码解释器:强化Agent智能数据分析平台
目录
- 系列篇章💥
- 一、前言
- 二、Memory功能实现之在线云盘类封装
- 1、创建OpenAi客户端
- 2、定义本地云盘文件目录创建方法
- 3、定义doc文档创建方法
- 4、定义文件内容追加方法
- 5、定义获取文件内容的方法
- 6、定义清理文件内容的方法
- 7、定义获取文件列表的方法
- 8、定义文件重命名的方法
- 9、定义删除文件的方法
- 10、定义追加图片的方法
- 11、定义一个云盘文件操作类
- 三、Memory功能实现之消息工具类封装
- 1、定义消息管理类
- 2、测试-查看消息管理器
- 3、测试-追加消息
- 4、测试-删除消息
- 5、添加背景知识
- 四、Tools功能之函数封装
- 1、获取表结构基本信息(工具函数)
- 2、提取SQL数据到python变量(辅助函数)
- 3、python代码解释器(工具函数)
- 4、function函数信息生成器(辅助函数)
- 5、function函数调用辅助类
- 三、结语
一、前言
在前面篇章中我们实现了Agent智能数据分析平台中的Tools和Memory相关代码落地实践,本文中我们将对这两大块功能代码进行整合封装。
二、Memory功能实现之在线云盘类封装
1、创建OpenAi客户端
## 导入依赖
import openai
import os
import numpy as np
import pandas as pd
import json
import io
from openai import OpenAI
import inspect
import pymysql
import tiktoken
from docx import Document
import matplotlib.pyplot as plt
import seaborn as sns
import tempfile
import ast
from IPython.display import display, Markdown, Code
import shutil
import copy
from openai import APIConnectionError,AuthenticationErroropenai.api_key = os.getenv("OPENAI_API_KEY")client = OpenAI(api_key=openai.api_key)
2、定义本地云盘文件目录创建方法
import osdef create_or_get_folder(folder_name):"""根据项目创建云盘目录"""base_path = "/root/autodl-tmp/iquery项目/iquery云盘"full_path = os.path.join(base_path, folder_name)# 如果目录不存在,则创建它if not os.path.exists(full_path):os.makedirs(full_path)print(f"目录 {folder_name} 创建成功")else:print(f"目录 {folder_name} 已存在")return full_path
print(create_or_get_folder(folder_name = "测试函数"))

3、定义doc文档创建方法
def create_or_get_doc(folder_name, doc_name):"""创建或获取文件路径"""base_path = "/root/autodl-tmp/iquery项目/iquery云盘"full_path_folder=os.path.join(base_path,folder_name)file_path_doc = os.path.join(base_path+"/"+folder_name, f'{doc_name}.doc')# 检查目录是否存在,如果不存在则创建if not os.path.exists(full_path_folder):os.makedirs(full_path_folder)# 检查文件是否存在if os.path.exists(file_path_doc):# 文件存在,打开并追加内容document = Document(file_path_doc)else:# 文件不存在,创建一个新的文档对象document = Document()# 保存文档document.save(file_path_doc)return file_path_doc
create_or_get_doc(folder_name="测试函数",doc_name="数据分析")

4、定义文件内容追加方法
def append_content_in_doc(folder_name, doc_name, qa_string):""""往文件里追加内容@param folder_name=目录名,doc_name=文件名,qa_string=追加的内容"""base_path = "/root/autodl-tmp/iquery项目/iquery云盘"## 目录地址full_path_folder=base_path+"/"+folder_name## 文件地址full_path_doc = os.path.join(full_path_folder, doc_name)+".doc" # 检查目录是否存在,如果不存在则创建if not os.path.exists(full_path_folder):os.makedirs(full_path_folder)# 检查文件是否存在if os.path.exists(full_path_doc):# 文件存在,打开并追加内容document = Document(full_path_doc)else:# 文件不存在,创建一个新的文档对象document = Document()# 追加内容document.add_paragraph(qa_string)# 保存文档document.save(full_path_doc)print(f"内容已追加到 {doc_name}")测试
my_dict = "天青色等烟雨,而我在等你"
append_content_in_doc(folder_name="测试函数",doc_name="数据分析",qa_string=my_dict)

5、定义获取文件内容的方法
## 实现根据项目和文件获取文件内容的方法from docx import Document
import osdef get_file_content(folder_name, doc_name):"""实现根据项目名和文件名获取文件内容的方法@param project_name:项目名,file_name:文件名@return 文件内容"""# 构建文件的完整路径base_path = "/root/autodl-tmp/iquery项目/iquery云盘"file_path = os.path.join(folder_name, doc_name)full_path = os.path.join(base_path, file_path)+".doc"# 确保文件存在if not os.path.exists(full_path):return "文件不存在"try:# 加载文档doc = Document(full_path)content = []# 遍历文档中的每个段落,并收集文本for para in doc.paragraphs:content.append(para.text)# 将所有段落文本合并成一个字符串返回return '\n'.join(content)except Exception as e:return f"读取文件时发生错误: {e}"
测试
get_file_content(folder_name="测试函数",doc_name="数据分析")
6、定义清理文件内容的方法
from docx import Documentdef clear_content_in_doc(folder_name, doc_name):# 打开文档base_path = "/root/autodl-tmp/iquery项目/iquery云盘"file_path = os.path.join(base_path+"/"+folder_name, f'{doc_name}.doc')doc = Document(file_path)# 遍历每一个段落,设置其文本为空字符串for p in doc.paragraphs:for run in p.runs:run.text = ''# 保存修改后的文档doc.save(file_path)print("文档内容清除完毕")
测试
clear_content_in_doc(folder_name="测试函数",doc_name="数据分析")
7、定义获取文件列表的方法
def list_files_in_folder(folder_name):"""列举当前文件夹的全部文件"""base_path = "/root/autodl-tmp/iquery项目/iquery云盘"full_path = os.path.join(base_path,folder_name )file_names = [f for f in os.listdir(full_path) if os.path.isfile(os.path.join(full_path, f))]return file_names
测试
list_files_in_folder(folder_name="测试函数")
8、定义文件重命名的方法
def rename_doc(folder_name, doc_name, new_name):"""修改指定的文档名称"""base_path = "/root/autodl-tmp/iquery项目/iquery云盘"file_path = os.path.join(base_path+"/"+folder_name, f'{doc_name}.doc')new_file_path = os.path.join(base_path+"/"+folder_name, f'{new_name}.doc')# 重命名文件os.rename(file_path, new_file_path)return new_name
测试
rename_doc(folder_name="测试函数",doc_name="数据分析",new_name="数据可视化分析报告")
9、定义删除文件的方法
def delete_all_files_in_folder(folder_name):"""删除某文件夹内全部文件"""# 定义要删除的目录路径base_path = "/root/autodl-tmp/iquery项目/iquery云盘"full_path = os.path.join(base_path,folder_name)# 遍历整个目录for filename in os.listdir(full_path):# 构造文件或者文件夹的绝对路径file_path = os.path.join(full_path, filename)try:# 如果是文件,则删除文件if os.path.isfile(file_path) or os.path.islink(file_path):os.unlink(file_path)# 如果是文件夹,则删除文件夹elif os.path.isdir(file_path):shutil.rmtree(file_path)print("文件已清除完毕")except Exception as e:print('Failed to delete %s. Reason: %s' % (file_path, e))
测试
delete_all_files_in_folder(folder_name = "测试函数")
10、定义追加图片的方法
from docx import Document
import matplotlib.pyplot as plt
import os
import tempfiledef append_img_in_doc(folder_name, doc_name, img):""""往文件里追加图片@param folder_name=目录名,doc_name=文件名,img=图片对象,数据类型为matplotlib.figure.Figure对象"""base_path = "/root/autodl-tmp/iquery项目/iquery云盘"## 目录地址full_path_folder=base_path+"/"+folder_name## 文件地址full_path_doc = os.path.join(full_path_folder, doc_name)+".doc"# 检查目录是否存在,如果不存在则创建if not os.path.exists(full_path_folder):os.makedirs(full_path_folder)# 检查文件是否存在if os.path.exists(full_path_doc):print(full_path_doc)# 文件存在,打开并追加内容document = Document(full_path_doc)else:# 文件不存在,创建一个新的文档对象document = Document()# 追加图片# 将matplotlib的Figure对象保存为临时图片文件with tempfile.NamedTemporaryFile(delete=False, suffix='.png') as tmpfile:img.savefig(tmpfile.name, format='png')# 将图片插入到.docx文档中document.add_picture(tmpfile.name)# 保存文档document.save(full_path_doc)print(f"图片已追加到 {doc_name}")
import matplotlib.pyplot as plt# 创建一个图形
fig, ax = plt.subplots()
ax.plot([1, 2, 3, 4, 5])

append_img_in_doc(folder_name="测试函数",doc_name="数据分析",img=fig)

11、定义一个云盘文件操作类
class CloudFile():"""用于操作云盘文件"""def __init__(self, project_name, part_name, doc_content = None):# 项目名称,即项目文件夹名称self.project_name = project_name# 项目某部分名称,即项目文件名称self.part_name = part_name# 项目文件夹ID# 若项目文件夹ID为空,则获取项目文件夹IDfolder_path=create_or_get_folder(folder_name=project_name)# 创建时获取当前项目中其他文件名称列表self.doc_list = list_files_in_folder(folder_name=project_name)file_path = create_or_get_doc(folder_name=project_name, doc_name=part_name)# 项目文件具体内容,相当于多轮对话内容self.doc_content = doc_content# 若初始content不为空,则将其追加入文档内if doc_content != None:append_content_in_doc(folder_name=project_name, doc_name=part_name, dict_list=doc_content)def get_doc_content(self):"""根据项目某文件的文件ID,获取对应的文件内容""" self.doc_content = get_file_content(folder_name=self.project_name, doc_name=self.part_name)return self.doc_contentdef append_doc_content(self, content):"""根据项目某文件的文件ID,追加文件内容""" append_content_in_doc(folder_name=self.project_name,doc_name=self.part_name, dict_list=content)def clear_content(self):"""清空某文件内的全部内容""" clear_content_in_doc(folder_name=self.project_name, doc_name=self.part_name)def delete_all_files(self):"""删除当前项目文件夹内的全部文件""" delete_all_files_in_folder(folder_name=self.project_name)def update_doc_list(self):"""更新当前项目文件夹内的全部文件名称"""self.doc_list = list_files_in_folder(folder_name=self.project_name)def rename_doc(self, new_name):"""修改当前文件名称"""self.part_name = rename_doc_in_drive(folder_name=self.project_name, doc_name=self.part_name, new_name=new_name)
本地存储测试
c1 = CloudFile(project_name='测试项目', part_name='测试文档1')

三、Memory功能实现之消息工具类封装
1、定义消息管理类
class MessageManager():"""MessageManager,用于创建Chat模型能够接收和解读的messages对象。该对象是原始Chat模型接收的\messages对象的更高级表现形式,MessageManager类对象将字典类型的list作为其属性之一,同时还能\能区分系统消息和历史对话消息,并且能够自行计算当前对话的token量,并执能够在append的同时删\减最早对话消息,从而能够更加顺畅的输入大模型并完成多轮对话需求。"""def __init__(self, system_content_list=[], question='你好。',tokens_thr=None, project=None):self.system_content_list = system_content_list# 系统消息文档列表,相当于外部输入文档列表system_messages = []# 除系统消息外历史对话消息history_messages = []# 用于保存全部消息的listmessages_all = []# 系统消息字符串system_content = ''# 历史消息字符串,此时为用户输入信息history_content = question# 系统消息+历史消息字符串content_all = ''# 输入到messages中系统消息个数,初始情况为0num_of_system_messages = 0# 全部信息的token数量all_tokens_count = 0encoding = tiktoken.encoding_for_model("gpt-3.5-turbo")# 将外部输入文档列表依次保存为系统消息if system_content_list != []: for content in system_content_list:system_messages.append({"role": "system", "content": content})# 同时进行全文档拼接system_content += content# 计算系统消息tokensystem_tokens_count = len(encoding.encode(system_content))# 拼接系统消息messages_all += system_messages# 计算系统消息个数num_of_system_messages = len(system_content_list)# 若存在最大token数量限制if tokens_thr != None:# 若系统消息超出限制if system_tokens_count >= tokens_thr:print("system_messages的tokens数量超出限制,当前系统消息将不会被输入模型") # 删除系统消息system_messages = []messages_all = []# 系统消息个数清零num_of_system_messages = 0# 系统消息token数清零system_tokens_count = 0all_tokens_count += system_tokens_count# 创建首次对话消息history_messages = [{"role": "user", "content": question}]# 创建全部消息列表messages_all += history_messages# 计算用户问题tokenuser_tokens_count = len(encoding.encode(question))# 计算总token数all_tokens_count += user_tokens_count# 若存在最大token限制if tokens_thr != None:# 若超出最大token限制if all_tokens_count >= tokens_thr:print("当前用户问题的tokens数量超出限制,该消息无法被输入到模型中") # 同时清空系统消息和用户消息history_messages = []system_messages = []messages_all = []num_of_system_messages = 0all_tokens_count = 0# 全部messages信息self.messages = messages_all# system_messages信息self.system_messages = system_messages# user_messages信息self.history_messages = history_messages# messages信息中全部content的token数量self.tokens_count = all_tokens_count# 系统信息数量self.num_of_system_messages = num_of_system_messages# 最大token数量阈值self.tokens_thr = tokens_thr# token数计算编码方式self.encoding = tiktoken.encoding_for_model("gpt-3.5-turbo")# message挂靠的项目self.project = project# 删除部分对话信息def messages_pop(self, manual=False, index=None):def reduce_tokens(index):drop_message = self.history_messages.pop(index)self.tokens_count -= len(self.encoding.encode(str(drop_message)))if self.tokens_thr is not None:while self.tokens_count >= self.tokens_thr:reduce_tokens(-1)if manual:if index is None:reduce_tokens(-1)elif 0 <= index < len(self.history_messages) or index == -1:reduce_tokens(index)else:raise ValueError("Invalid index value: {}".format(index))# 更新messagesself.messages = self.system_messages + self.history_messages# 增加部分对话信息def messages_append(self, new_messages):# 若是单独一个字典,或JSON格式字典if type(new_messages) is dict or type(new_messages) is openai.types.chat.chat_completion_message.ChatCompletionMessage:self.messages.append(new_messages)self.tokens_count += len(self.encoding.encode(str(new_messages)))# 若新消息也是MessageManager对象elif isinstance(new_messages, MessageManager):self.messages += new_messages.messagesself.tokens_count += new_messages.tokens_count# 重新更新history_messagesself.history_messages = self.messages[self.num_of_system_messages: ]# 再执行pop,若有需要,则会删除部分历史消息self.messages_pop()# 复制信息def copy(self):# 创建一个新的 MessageManager 对象,复制所有重要的属性system_content_str_list = [message["content"] for message in self.system_messages]new_obj = MessageManager(system_content_list=copy.deepcopy(system_content_str_list), # 使用深复制来复制系统消息question=self.history_messages[0]["content"] if self.history_messages else '',tokens_thr=self.tokens_thr)# 复制任何其他需要复制的属性new_obj.history_messages = copy.deepcopy(self.history_messages) # 使用深复制来复制历史消息new_obj.messages = copy.deepcopy(self.messages) # 使用深复制来复制所有消息new_obj.tokens_count = self.tokens_countnew_obj.num_of_system_messages = self.num_of_system_messagesreturn new_obj# 增加系统消息def add_system_messages(self, new_system_content):system_content_list = self.system_content_listsystem_messages = []# 若是字符串,则将其转化为listif type(new_system_content) == str:new_system_content = [new_system_content]system_content_list.extend(new_system_content)new_system_content_str = ''for content in new_system_content:new_system_content_str += contentnew_token_count = len(self.encoding.encode(str(new_system_content_str)))self.tokens_count += new_token_countself.system_content_list = system_content_listfor message in system_content_list:system_messages.append({"role": "system", "content": message})self.system_messages = system_messagesself.num_of_system_messages = len(system_content_list)self.messages = system_messages + self.history_messages# 再执行pop,若有需要,则会删除部分历史消息self.messages_pop()# 删除系统消息def delete_system_messages(self):system_content_list = self.system_content_listif system_content_list != []:system_content_str = ''for content in system_content_list:system_content_str += contentdelete_token_count = len(self.encoding.encode(str(system_content_str)))self.tokens_count -= delete_token_countself.num_of_system_messages = 0self.system_content_list = []self.system_messages = []self.messages = self.history_messages# 清除对话消息中的function消息def delete_function_messages(self):# 用于删除外部函数消息history_messages = self.history_messages# 从后向前迭代列表for index in range(len(history_messages) - 1, -1, -1):message = history_messages[index]## 这儿估计有问题if message.get("function_call") or message.get("role") == "function":self.messages_pop(manual=True, index=index)
2、测试-查看消息管理器
msg1 = MessageManager()
msg1.system_messages

3、测试-追加消息
msg1.history_messages

msg1.messages_append({"role": "user", "content": "你好,有什么可以帮你?"})
msg1.history_messages

4、测试-删除消息
msg1.messages_pop(manual=True, index=-1)
msg1.history_messages

5、添加背景知识
# 数据字典文件
with open('/root/autodl-tmp/iquery项目/data/数据字典/iquery数据字典.md', 'r', encoding='utf-8') as f:data_dictionary = f.read()
# 数据分析报告编写专家文档
with open('/root/autodl-tmp/iquery项目/data/业务知识/本公司数据分析师业务介绍.md', 'r', encoding='utf-8') as f:da_instruct = f.read()
msg2 = MessageManager(system_content_list=[data_dictionary, da_instruct])
msg2.system_messages
输出

四、Tools功能之函数封装
1、获取表结构基本信息(工具函数)
定义一个SQL工具函数,用于获取表结构信息,作为大模型生成SQL的背景知识
## mysql hive sparksql
def sql_inter(sql_query, g='globals()'):"""用于获取iquery数据库中各张表的有关相关信息,\核心功能是将输入的SQL代码传输至iquery数据库所在的MySQL环境中进行运行,\并最终返回SQL代码运行结果。需要注意的是,本函数是借助pymysql来连接MySQL数据库。:param sql_query: 字符串形式的SQL查询语句,用于执行对MySQL中iquery数据库中各张表进行查询,并获得各表中的各类相关信息:param g: g,字符串形式变量,表示环境变量,无需设置,保持默认参数即可:return:sql_query在MySQL中的运行结果。"""mysql_pw = "iquery_agent"connection = pymysql.connect(host='localhost', # 数据库地址user='iquery_agent', # 数据库用户名passwd=mysql_pw, # 数据库密码db='iquery', # 数据库名charset='utf8' # 字符集选择utf8)try:with connection.cursor() as cursor:# SQL查询语句sql = sql_querycursor.execute(sql)# 获取查询结果results = cursor.fetchall()finally:connection.close()return json.dumps(results)
sql_inter(sql_query='SELECT COUNT(*) FROM user_demographics;', g=globals())
2、提取SQL数据到python变量(辅助函数)
定义一个辅助函数,用于将查询到的记录提取保存到本地python变量中
def extract_data(sql_query,df_name,g='globals()'):"""用于借助pymysql,将MySQL中的iquery数据库中的表读取并保存到本地Python环境中。:param sql_query: 字符串形式的SQL查询语句,用于提取MySQL中iquery数据库中的某张表。:param df_name: 将MySQL数据库中提取的表格进行本地保存时的变量名,以字符串形式表示。:param g: g,字符串形式变量,表示环境变量,无需设置,保持默认参数即可:return:表格读取和保存结果"""mysql_pw = "iquery_agent"connection = pymysql.connect(host='localhost', # 数据库地址user='iquery_agent', # 数据库用户名passwd=mysql_pw, # 数据库密码db='iquery', # 数据库名charset='utf8' # 字符集选择utf8)globals()[df_name] = pd.read_sql(sql_query, connection)return "已成功完成%s变量创建" % df_name
extract_data(sql_query = 'SELECT * FROM user_demographics;', df_name = 'user_demographics_df', g = globals())

从python变量中取出数据查看
user_demographics_df.head()

3、python代码解释器(工具函数)
def python_inter(py_code,g='globals()'):"""用于对iquery数据库中各张数据表进行查询和处理,并获取最终查询或处理结果。:param py_code: 字符串形式的Python代码,用于执行对iquery数据库中各张数据表进行操作:param g: g,字符串形式变量,表示环境变量,无需设置,保持默认参数即可:return:代码运行的最终结果""" # 添加图片对象,如果存在绘图代码,则创建fig对象py_code = insert_fig_object(py_code)global_vars_before = set(globals().keys())try:exec(py_code, globals())except Exception as e:return str(e)global_vars_after = set(globals().keys())new_vars = global_vars_after - global_vars_beforeif new_vars:result = {var: globals()[var] for var in new_vars}return str(result)else:try:return str(eval(py_code, globals()))except Exception as e:return "已经顺利执行代码"
检查图形对象,赋值给fig(方便通过全局变量fig进行统一的绘图对象操作)
def insert_fig_object(code_str,g='globals()'):"""为图片创建fig对象:param g: g,字符串形式变量,表示环境变量,无需设置,保持默认参数即可"""#print("开始画图了")global fig# 检查是否已存在 fig 对象的创建if 'fig = plt.figure' in code_str or 'fig, ax = plt.subplots()' in code_str:return code_str # 如果存在,则返回原始代码字符串# 定义可能的库别名和全名plot_aliases = ['plt.', 'matplotlib.pyplot.','plot']sns_aliases = ['sns.', 'seaborn.']# 寻找第一次出现绘图相关代码的位置first_plot_occurrence = min((code_str.find(alias) for alias in plot_aliases + sns_aliases if code_str.find(alias) >= 0), default=-1)# 如果找到绘图代码,则在该位置之前插入 fig 对象的创建if first_plot_occurrence != -1:plt_figure_index = code_str.find('plt.figure')if plt_figure_index != -1:# 寻找 plt.figure 后的括号位置,以确定是否有参数closing_bracket_index = code_str.find(')', plt_figure_index)# 如果找到了 plt.figure(),则替换为 fig = plt.figure()modified_str = code_str[:plt_figure_index] + 'fig = ' + code_str[plt_figure_index:closing_bracket_index + 1] + code_str[closing_bracket_index + 1:]else:modified_str = code_str[:first_plot_occurrence] + 'fig = plt.figure()\n' + code_str[first_plot_occurrence:]return modified_strelse:return code_str # 如果没有找到绘图代码,则返回原始代码字符串
图形绘制代码测试
import matplotlib.pyplot as plt
# 数据
categories = ['Category 1', 'Category 2', 'Category 3', 'Category 4']
values = [4, 7, 1, 8]# 创建 Figure 对象
fig, ax = plt.subplots()# 在 Axes 对象 ax 上创建条形图
ax.bar(categories, values)# 添加标题和标签
ax.set_title('Bar Chart Example')
ax.set_xlabel('Categories')
ax.set_ylabel('Values')# 显示图表
plt.show()

insert_fig_object方法测试
code_string = """
import matplotlib.pyplot as plt
# 数据
categories = ['Category 1', 'Category 2', 'Category 3', 'Category 4']
values = [4, 7, 1, 8]# 创建 Figure 对象
fig, ax = plt.subplots()# 在 Axes 对象 ax 上创建条形图
ax.bar(categories, values)# 添加标题和标签
ax.set_title('Bar Chart Example')
ax.set_xlabel('Categories')
ax.set_ylabel('Values')# 显示图表
plt.show()
"""
print(insert_fig_object(code_str = code_string, g=globals()))

python_inter(py_code = code_string, g=globals())

查看fig对象

4、function函数信息生成器(辅助函数)
定义一个用于生成function calling 函数信息的,辅助函数(为了保证稳定性,实践使用是最好手工编写,避免大模型生成的结构体不太稳定)
def auto_functions(functions_list):"""Chat模型的functions参数编写函数:param functions_list: 包含一个或者多个函数对象的列表;:return:满足Chat模型functions参数要求的functions对象"""def functions_generate(functions_list):# 创建空列表,用于保存每个函数的描述字典functions = []# 对每个外部函数进行循环for function in functions_list:# 读取函数对象的函数说明function_description = inspect.getdoc(function)# 读取函数的函数名字符串function_name = function.__name__system_prompt = '以下是某的函数说明:%s' % function_descriptionuser_prompt = '根据这个函数的函数说明,请帮我创建一个JSON格式的字典,这个字典有如下5点要求:\1.字典总共有三个键值对;\2.第一个键值对的Key是字符串name,value是该函数的名字:%s,也是字符串;\3.第二个键值对的Key是字符串description,value是该函数的函数的功能说明,也是字符串;\4.第三个键值对的Key是字符串parameters,value是一个JSON Schema对象,用于说明该函数的参数输入规范。\5.输出结果必须是一个JSON格式的字典,只输出这个字典即可,前后不需要任何前后修饰或说明的语句' % function_nameresponse = client.chat.completions.create(model="gpt-3.5-turbo",messages=[{"role": "system", "content": system_prompt},{"role": "user", "content": user_prompt}])json_function_description=json.loads(response.choices[0].message.content.replace("```","").replace("json",""))json_str={"type": "function","function":json_function_description}functions.append(json_str)return functionsmax_attempts = 4attempts = 0while attempts < max_attempts:try:functions = functions_generate(functions_list)break # 如果代码成功执行,跳出循环except Exception as e:attempts += 1 # 增加尝试次数print("发生错误:", e)if attempts == max_attempts:print("已达到最大尝试次数,程序终止。")raise # 重新引发最后一个异常else:print("正在重新运行...")return functions
5、function函数调用辅助类
负责承接外部函数调用时相关功能支持。
类属性包括外部函数列表、外部函数参数说明列表、以及调用方式说明三项。
class AvailableFunctions():"""外部函数类,主要负责承接外部函数调用时相关功能支持。类属性包括外部函数列表、外部函数参数说明列表、以及调用方式说明三项。"""def __init__(self, functions_list=[], functions=[], function_call="auto"):self.functions_list = functions_listself.functions = functionsself.functions_dic = Noneself.function_call = None# 当外部函数列表不为空、且外部函数参数解释为空时,调用auto_functions创建外部函数解释列表if functions_list != []:self.functions_dic = {func.__name__: func for func in functions_list}self.function_call = function_callif functions == []:self.functions = auto_functions(functions_list)# 增加外部函数方法,并且同时可以更换外部函数调用规则def add_function(self, new_function, function_description=None, function_call_update=None):self.functions_list.append(new_function)self.functions_dic[new_function.__name__] = new_functionif function_description == None:new_function_description = auto_functions([new_function])self.functions.append(new_function_description)else:self.functions.append(function_description)if function_call_update != None:self.function_call = function_call_update
af = AvailableFunctions(functions_list=[sql_inter, extract_data, python_inter])
af.functions_list

af.functions_dic

af.function_call

af.functions
输出:
[{'type': 'function','function': {'name': 'sql_inter','description': '用于获取iquery数据库中各张表的有关相关信息,核心功能是将输入的SQL代码传输至iquery数据库所在的MySQL环境中进行运行,并最终返回SQL代码运行结果。','parameters': {'type': 'object','properties': {'sql_query': {'type': 'string','description': '字符串形式的SQL查询语句,用于执行对MySQL中iquery数据库中各张表进行查询,并获得各表中的各类相关信息。'},'g': {'type': 'string','description': 'g,字符串形式变量,表示环境变量,无需设置,保持默认参数即可。'}},'required': ['sql_query', 'g']}}},{'type': 'function','function': {'name': 'extract_data','description': '用于借助pymysql,将MySQL中的iquery数据库中的表读取并保存到本地Python环境中。','parameters': {'type': 'object','properties': {'sql_query': {'type': 'string','description': '字符串形式的SQL查询语句,用于提取MySQL中iquery数据库中的某张表。'},'df_name': {'type': 'string','description': '将MySQL数据库中提取的表格进行本地保存时的变量名,以字符串形式表示。'},'g': {'type': 'string', 'description': 'g,字符串形式变量,表示环境变量,无需设置,保持默认参数即可'}},'required': ['sql_query', 'df_name']}}},{'type': 'function','function': {'name': 'python_inter','description': '用于对iquery数据库中各张数据表进行查询和处理,并获取最终查询或处理结果。','parameters': {'$schema': 'http://-schema.org/draft-07/schema#','type': 'object','properties': {'py_code': {'type': 'string','description': '字符串形式的Python代码,用于执行对iquery数据库中各张数据表进行操作'},'g': {'type': 'string', 'description': 'g,字符串形式变量,表示环境变量,无需设置,保持默认参数即可'}},'required': ['py_code', 'g']}}}]
三、结语
本文中我们封装落地了Agent智能数据分析平台中的Tools和Memory相关代码,下一篇章中我将落地实践Agent智能数据分析平台的核心模块Plan,探索发掘人类意图,优化整个决策流程。

🎯🔖更多专栏系列文章:AIGC-AI大模型探索之路
😎 作者介绍:我是寻道AI小兵,资深程序老猿,从业10年+、互联网系统架构师,目前专注于AIGC的探索。
📖 技术交流:建立有技术交流群,可以扫码👇 加入社群,500本各类编程书籍、AI教程、AI工具等你领取!
如果文章内容对您有所触动,别忘了点赞、⭐关注,收藏!加入我,让我们携手同行AI的探索之旅,一起开启智能时代的大门!
相关文章:
AI大模型探索之路-实战篇15: Agent智能数据分析平台之整合封装Tools和Memory功能代码
系列篇章💥 AI大模型探索之路-实战篇4:深入DB-GPT数据应用开发框架调研 AI大模型探索之路-实战篇5:探索Open Interpreter开放代码解释器调研 AI大模型探索之路-实战篇6:掌握Function Calling的详细流程 AI大模型探索之路-实战篇7…...

CV每日论文--2024.6.4
1、Mixed Diffusion for 3D Indoor Scene Synthesis 中文 标题:用于 3D 室内场景合成的混合扩散 简介:这篇论文提出了一种名为MiDiffusion的混合离散-连续扩散模型,用于从给定的房间类型、平面图和可能存在的物体中合成逼真的3D室内场景。 作者指出,该…...

Android bw_costly_<iface>链
测试时关注到bw_costly_链 因为和iface有关。猜测这个链是动态生成的。 开关数据业务测试,果然关闭数据业务后,bw_OUTPUT中不再会调用bw_costly_rmnet_data3,也没有bw_costly_rmnet_data3这个链了。 再次打开数据业务后出现了bw_costly_rmnet…...

TypeScript 项目,自身 package 是 A,它引用了 B package。项目编译时,选择依赖版本的机制是什么?
在 TypeScript 项目中,当 package A 引用了 package B,编译 A 的过程中,B package 将按照 B package 自身的 package.json 文件中指定的各个库的版本进行编译,而不是按照 A package 中的库版本。 每个 package 都有自己的依赖项和…...

【数据结构】链表----头结点的作用
链表是一种常见的数据结构,由一系列节点(Node)组成,每个节点包含数据和指向下一个节点的指针。链表的头结点(Head Node)也称为哨兵位,是链表的起点,通常有以下几个重要作用ÿ…...
(CVPRW,2024)可学习的提示:遥感领域小样本语义分割
文章目录 相关资料摘要引言方法训练基础类别新类别推理 相关资料 论文:Learnable Prompt for Few-Shot Semantic Segmentation in Remote Sensing Domain 代码:https://github.com/SteveImmanuel/OEM-Few-Shot-Learnable-Prompt 摘要 小样本分割是一项…...

tinyrenderer-切线空间法线贴图
法线贴图 法线贴图分两种,一种是模型空间中的,一种是切线空间中的 模型空间中的法线贴图的rgb代表着每个渲染像素法线的xyz,与顶点坐标处于一个空间,图片是五颜六色的。 切线空间中的法线贴图的rgb同样对应xyz,是切线…...
C++的vector使用优化
我们在上一章说了如何使用这个vector动态数组,这章我们说说如何更好的使用它以及它是如何工作的。当你创建一个vector,然后使用push_back添加元素,当当前的vector的内存不够时,会从内存中的旧位置复制到内存中的新位置,…...

关于stm32的复用和重映射问题
目录 需求IO口的复用和重映射使用复用复用加重映射 总结参考资料 需求 一开始使用stm32c8t6,想实现pwm输出,但是原电路固定在芯片的引脚PB10和PB11上,查看了下引脚的功能,需要使用到复用功能。让改引脚作为定时器PWM的输出IO口。…...

遍历数组1
package demo; import java.util.ArrayList; public class Arrilist { public static void main(String[] args) { ArrayList<String>listnew ArrayList<>(); list.add("汤神"); list.add("yyx"); list.add("hong go…...

Go语言 一些问题了解
一、读取文件数据,是阻塞还是非阻塞的? 分两种情况:常规读取文件数据,和网络IO读取数据 1. 常规读取文件数据: io.Reader 和 bufio.Reader 是阻塞进行的。 bufio.Reader 提供缓冲的读取操作,意味着数据是…...

C++ Primer 第五版 第15章 面向对象程序设计
面向对象程序设计基于三个基本概念:数据抽象、继承和动态绑定。 继承和动态绑定对编写程序有两方面的影响:一是我们可以更容易地定义与其他类相似但不完全相同的新类;二是在使用这些彼此相似的类编写程序时,我们可以在一定程度上…...
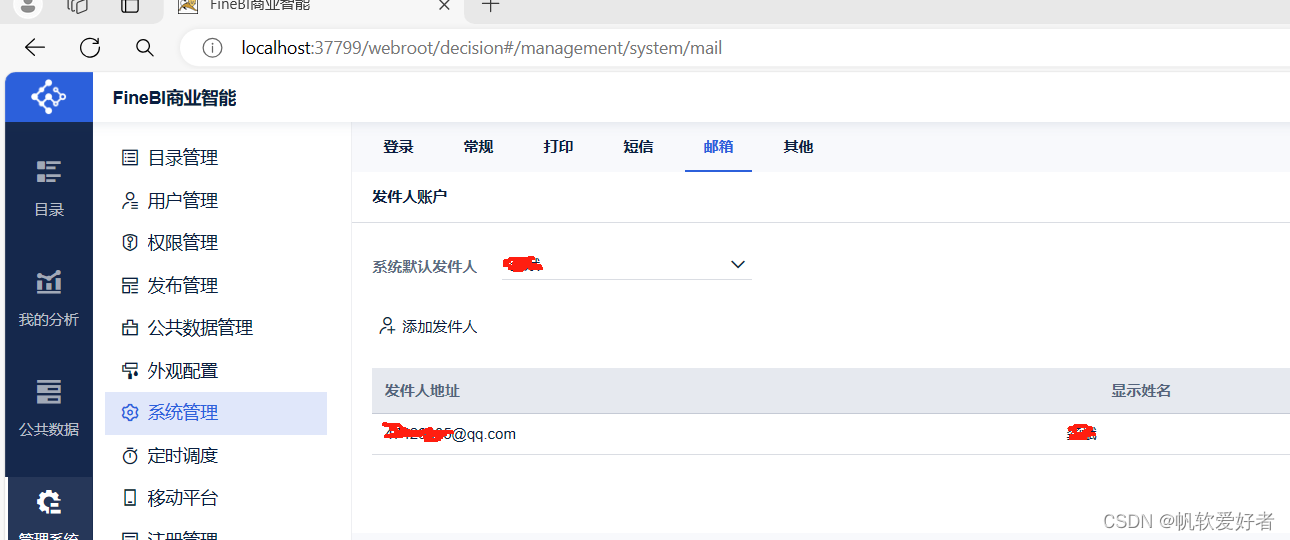
finebi或者finereport发邮件
我们二次开发中,如果想利用产品自带的发邮件的功能,来发送自己的邮件内容。 首先 决策系统中邮件相关信息要配置好之后: 这里配好了发件人,以及默认发件人后, private void sendEmail(String content,String subject)…...

基于聚类和回归分析方法探究蓝莓产量影响因素与预测模型研究
🌟欢迎来到 我的博客 —— 探索技术的无限可能! 🌟博客的简介(文章目录) 目录 背景数据说明数据来源思考 正文数据预处理数据读取数据预览数据处理 相关性分析聚类分析数据处理确定聚类数建立k均值聚类模型 多元线性回…...

【数据结构】从前序与中序遍历,或中序与后序遍历序列,构造二叉树
欢迎浏览高耳机的博客 希望我们彼此都有更好的收获 感谢三连支持! 首先,根据先序遍历可以确定根节点E,再在中序遍历中通过E确定左树和右数 ; 设立inBegin和inEnd,通过这两个参数的游走,来进行子树的创建&a…...

ARM公司发展历程
Arm从1990年成立前开始,历经漫长岁月树立各项公司里程碑及产品成就,一步步成为全球最普及的运算平台。 添加图片注释,不超过 140 字(可选) Acorn 时期 1978年,Chris Curry和Hermann Hauser共同创立了Acorn…...

C# :IQueryable IEnumerable
文章目录 1. IEnumerable2. IQueryable3. LINQ to SQL4. IEnumerable & IQueryable4.1 Expression4.2 Provider 1. IEnumerable namespace System.Collections: public interface IEnumerable {public IEnumerator GetEnumerator (); }public interface IEnumerator {pubi…...

三、生成RPM包
文章目录 1、编译生成so、bin 通过此工程编译生成so\bin文件 2、将so\bin打包到rpm中 ###### 1.生成可执行文件、库文件 ######### cmake_minimum_required(VERSION 3.15)project(compute) set(target zls_bin) set(target2 libcompute.so) # 依赖的头文件 include_directori…...

单实例11.2.0.4迁移到11.2.0.4RAC_使用rman异机恢复
保命法则:先备份再操作,磁盘空间紧张无法备份就让满足,给自己留退路。 场景说明: 1.本文档的环境为同平台、不同版本(操作系统版本可以不同,数据库版本相同),源机器和目标机器部分…...
)
MySQL之查询性能优化(二)
查询性能优化 慢查询基础:优化数据访问 查询性能低下最基本的原因是访问的数据太多。某些查询可能不可避免地需要筛选大量数据,但这并不场景。大部分性能低下的查询都可以通过减少访问的数据量的方式进行优化。对于低效的查询,我们发现通过下面两个步骤…...
)、awk与浮点数运算【20260404】)
Shell运算详解:expr、$(())、awk与浮点数运算【20260404】
文章目录 Shell运算详解:expr、$(())、awk与浮点数运算 1. Shell整数运算基础 1.1 expr 命令 1.2 $(( )) 算术扩展 2. awk 数值运算 2.1 awk 基础运算 2.2 awk 处理数据文件 3. 浮点数运算解决方案 3.1 使用bc进行浮点运算 3.2 使用awk进行浮点运算 4. 系统管理实战案例 4.1 案…...

拯救者BIOS终极解锁:告别隐藏设置,完全掌控你的笔记本电脑
拯救者BIOS终极解锁:告别隐藏设置,完全掌控你的笔记本电脑 【免费下载链接】LEGION_Y7000Series_Insyde_Advanced_Settings_Tools 支持一键修改 Insyde BIOS 隐藏选项的小工具,例如关闭CFG LOCK、修改DVMT等等 项目地址: https://gitcode.c…...

如何通过ReadCat实现纯净小说阅读:开源无广告解决方案
如何通过ReadCat实现纯净小说阅读:开源无广告解决方案 【免费下载链接】read-cat 一款免费、开源、简洁、纯净、无广告的小说阅读器 项目地址: https://gitcode.com/gh_mirrors/re/read-cat 在信息过载的数字时代,每打开一个阅读应用都要面对弹窗…...
踩坑实录:从I2C上拉到坐标翻转的完整避坑指南)
ESP32S3驱动微雪2.8寸屏(CST328触摸IC)踩坑实录:从I2C上拉到坐标翻转的完整避坑指南
ESP32S3驱动CST328触摸屏实战避坑指南:从I2C配置到LVGL集成的完整解决方案 刚拿到微雪2.8寸屏时,我本以为按照常规流程就能快速集成触摸功能,没想到CST328这颗冷门触摸IC给了我当头一棒。市面上几乎找不到完整的ESP-IDF驱动实现,海…...

KuiTest:基于大模型通识的UI交互遍历测试
在技术领域,我们常常被那些闪耀的、可见的成果所吸引。今天,这个焦点无疑是大语言模型技术。它们的流畅对话、惊人的创造力,让我们得以一窥未来的轮廓。然而,作为在企业一线构建、部署和维护复杂系统的实践者,我们深知…...
重构学术文档翻译:PDFMathTranslate如何突破格式保留与公式处理技术瓶颈
重构学术文档翻译:PDFMathTranslate如何突破格式保留与公式处理技术瓶颈 【免费下载链接】PDFMathTranslate PDF scientific paper translation with preserved formats - 基于 AI 完整保留排版的 PDF 文档全文双语翻译,支持 Google/DeepL/Ollama/OpenAI…...

FRCRN语音降噪工具实战教程:单麦16k音频一键去噪保姆级指南
FRCRN语音降噪工具实战教程:单麦16k音频一键去噪保姆级指南 1. 快速了解FRCRN语音降噪 你是不是经常遇到这样的困扰:录制的语音通话背景噪音太大,播客内容被环境声干扰,或者重要的会议录音听不清楚人声?FRCRN语音降噪…...

霜儿-汉服-造相Z-Turbo应用指南:打造你的江南庭院古风AI摄影师
霜儿-汉服-造相Z-Turbo应用指南:打造你的江南庭院古风AI摄影师 1. 模型介绍与核心功能 1.1 什么是霜儿-汉服-造相Z-Turbo 霜儿-汉服-造相Z-Turbo是一款专注于生成古风汉服人像的AI文生图模型。它基于强大的Z-Image-Turbo基础模型,通过LoRA(…...

FireRedASR Pro开箱即用:基于Streamlit的交互界面,操作超直观
FireRedASR Pro开箱即用:基于Streamlit的交互界面,操作超直观 1. 工具概览与核心优势 FireRedASR Pro是一款基于工业级语音识别模型开发的本地化工具,特别适合需要快速部署语音转文字功能的开发者和研究者。与传统的ASR解决方案相比&#x…...

从天气预报到股票分析:用Python实战理解随机过程与概率论基础
从天气预报到股票分析:用Python实战理解随机过程与概率论基础 天气预报的准确率为何忽高忽低?股票价格的波动背后隐藏着怎样的数学规律?这些看似不相关的问题,其实都指向同一个核心概念——随机过程。作为概率论的延伸,…...