Linux基础IO【II】真的很详细
目录
一.文件描述符
1.重新理解文件
1.推论
2.证明
2.理解文件描述符
1.文件描述符的分配规则
3.如何理解文件操作的本质?
4.输入重定向和输出重定向
1.原理
2.代码实现重定向
3.dup函数
编辑
4.命令行中实现重定向
二.关于缓冲区
1.现象
2.重新理解缓冲区
3.缓冲区刷新策略问题
4.缓冲区的位置
编辑
5.如何解释刚刚的现象呢?
总结
今天,我们接着在上一篇文章的基础上,继续学习基础IO。观看本文章之前,建议先看:Linux基础IO【I】,那,我们就开始吧!

一.文件描述符
1.重新理解文件
文件操作的本质:进程和被打开文件之间的关系。
1.推论
我们先用一段代码和一个现象来引出我们今天要讨论的问题:
上码:
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <assert.h>
#include <string.h>
#include <unistd.h>
//我没有指明具体的路径,采用了字符串拼接的方式。
#define FILE_NAME(number) "log.txt" #numberint main()
{umask(0);int fd1 = open(FILE_NAME(1), O_WRONLY | O_CREAT, 0666);int fd2 = open(FILE_NAME(2), O_WRONLY | O_CREAT, 0666);int fd3 = open(FILE_NAME(3), O_WRONLY | O_CREAT, 0666);int fd4 = open(FILE_NAME(4), O_WRONLY | O_CREAT, 0666);int fd5 = open(FILE_NAME(5), O_WRONLY | O_CREAT, 0666);printf("fd1:%d\n", fd1);printf("fd2:%d\n", fd2);printf("fd3:%d\n", fd3);printf("fd4:%d\n", fd4);printf("fd5:%d\n", fd5);close(fd1);close(fd2);close(fd3);close(fd4);close(fd5);
}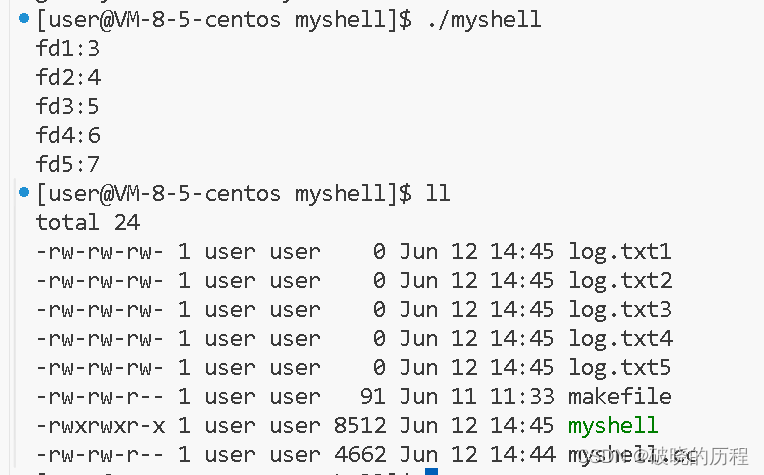
看到输出的结果,各位大佬想到了什么?我想到了数组的下标。也许这和数组有这千丝万缕的关系,但我们都只是猜测,接下来就证明我们的猜测。
首先我们可以利用现在掌握的知识推导出这样一条逻辑链:
- 进程可以打开多个文件吗?可以,而且我们刚刚已经证实了。
- 所以系统中一定会存在大量的被打开的文件。
- 所以操作系统要不要把这些被打开的文件给管理起来?要。
- 所以如何管理?先描述,再组织。
- 操作系统为了管理这些文件,一定会在内核中创建相应的数据结构来表示文件。
- 这个数据结构就是struct_file结构体。里面包含了我们所需的大量的属性。
我们回到刚刚代码的运行结果上来:
为什么从3开始,0,1,2分别表示的是什么?
其实系统为一个处于运行态的进程默认打开了3个文件(3个标准输入输出流):
- stdin(标准输入流) :对应的是键盘。
- stdout(标准输出流): 对应的是显示器。
- stderr(标准错误流) :对应的是显示器。
上面我们提及的struct_file结构体在内核中的数据如下:
/** Open file table structure*/
struct files_struct {/** read mostly part*/atomic_t count;bool resize_in_progress;wait_queue_head_t resize_wait;struct fdtable __rcu *fdt;struct fdtable fdtab;/** written part on a separate cache line in SMP*/spinlock_t file_lock ____cacheline_aligned_in_smp;unsigned int next_fd;unsigned long close_on_exec_init[1];unsigned long open_fds_init[1];unsigned long full_fds_bits_init[1];struct file __rcu * fd_array[NR_OPEN_DEFAULT];
};
struct file {union {struct llist_node fu_llist;struct rcu_head fu_rcuhead;} f_u;struct path f_path;struct inode *f_inode; /* cached value */const struct file_operations *f_op;spinlock_t f_lock;enum rw_hint f_write_hint;atomic_long_t f_count;unsigned int f_flags;fmode_t f_mode;struct mutex f_pos_lock;loff_t f_pos;struct fown_struct f_owner;const struct cred *f_cred;struct file_ra_state f_ra;u64 f_version;
#ifdef CONFIG_SECURITYvoid *f_security;
#endif/* needed for tty driver, and maybe others */void *private_data;#ifdef CONFIG_EPOLLstruct list_head f_ep_links;struct list_head f_tfile_llink;
#endif /* #ifdef CONFIG_EPOLL */struct address_space *f_mapping;errseq_t f_wb_err;
}
2.证明

大家有没有好奇过:为什么我们C库函数fopen的返回值类型是FILE*,FILE是什么?当时老师肯定没给我们讲清楚,因为当时我们的知识储备不够。但现在,我们有必要知道FILE其实就是一个结构体类型。
//stdio.h
typedef struct _iobuf
{char* _ptr; //文件输入的下一个位置int _cnt; //当前缓冲区的相对位置char* _base; //文件初始位置int _flag; //文件标志int _file; //文件有效性int _charbuf; //缓冲区是否可读取int _bufsiz; //缓冲区字节数char* _tmpfname; //临时文件名
} FILE;
这3个标准输入输出流既然是文件,操作系统必定为其在系统中创建一个对应的struct file结构体。
为了证明我们的判断,我们可以:调用struct file内部的一个变量。
操作系统底层底层是用文件描述符来标识一个文件的。纵所周知,C文件操作函数是对系统接口的封装。所以FILE结构体中一定隐藏着一个字段来储存文件描述符。而且stdin,stdout,stderr都是FILE*类型的变量,
所以:
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <assert.h>
#include <string.h>
#include <unistd.h>
// 我没有指明具体的路径,采用了字符串拼接的方式。
#define FILE_NAME(number) "log.txt" #numberint main()
{printf("stdin:%d\n", stdin->_fileno);//调用struct file内部的一个变量printf("stdout:%d\n", stdout->_fileno);printf("stderr:%d\n", stderr->_fileno);umask(0);int fd1 = open(FILE_NAME(1), O_WRONLY | O_CREAT, 0666);int fd2 = open(FILE_NAME(2), O_WRONLY | O_CREAT, 0666);int fd3 = open(FILE_NAME(3), O_WRONLY | O_CREAT, 0666);int fd4 = open(FILE_NAME(4), O_WRONLY | O_CREAT, 0666);int fd5 = open(FILE_NAME(5), O_WRONLY | O_CREAT, 0666);printf("fd1:%d\n", fd1);printf("fd2:%d\n", fd2);printf("fd3:%d\n", fd3);printf("fd4:%d\n", fd4);printf("fd5:%d\n", fd5);close(fd1);close(fd2);close(fd3);close(fd4);close(fd5);
}
来啦,终于来啦!!终于证明我们的推断。
2.理解文件描述符
进程中打开的文件都有一个唯一的文件描述符,用来标识这个文件,进而对文件进行相关操作。其实,我们之前就接触到了文件描述符,我们简单回忆一下:
- 调用open函数的返回值,就是一个文件描述符。只不过,我们打开的文件的文件描述符默认是从3开始的,0.1.2是系统自动为进程打开的。
- 调用close传入的参数。
- 调用write,read函数的第一个参数。
可见,文件描述符对我们进行文件操作有多么重要。文件描述符就像一个人身份证,在一个进程中具有唯一性。
文件描述符fd的取值范围:文件描述符的取值范围通常是从0到系统定义的最大文件描述符值。
当Linux新建一个进程时,会自动创建3个文件描述符0、1和2,分别对应标准输入、标准输出和错误输出。C库中与文件描述符对应的是文件指针,与文件描述符0、1和2类似,我们可以直接使用文件指针stdin、stdout和stderr。意味着stdin、stdout和stderr是“自动打开”的文件指针。
在Linux系统中,文件描述符0、1和2分别有以下含义:
- 文件描述符0(STDIN_FILENO):它是标准输入文件描述符,通常与进程的标准输入流(stdin)相关联。它用于接收来自用户或其他进程的输入数据。默认情况下,它通常与终端或控制台的键盘输入相关联。
- 文件描述符1(STDOUT_FILENO):它是标准输出文件描述符,通常与进程的标准输出流(stdout)相关联。它用于向终端或控制台输出数据,例如程序的正常输出、结果和信息。
- 文件描述符2(STDERR_FILENO):它是标准错误文件描述符,通常与进程的标准错误流(stderr)相关联。它用于输出错误消息、警告和异常信息到终端或控制台。与标准输出不同,标准错误通常用于输出与程序执行相关的错误和调试信息。
这些文件描述符是在进程创建时自动打开的,并且可以在程序运行期间使用。它们是程序与用户、终端和操作系统之间进行输入和输出交互的重要通道。通过合理地使用这些文件描述符,程序可以接收输入、输出结果,并提供错误和调试信息,以实现与用户的交互和数据处理。
1.文件描述符的分配规则
文件描述符的分配规则为:从0开始查找,使用最小的且没有占用的文件描述符。
所以:我们是否可是手动的关闭,系统为我们自动带的3个文件呢?so try!
先试着关闭一下0号文件描述符对应的标准输入流
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <assert.h>
#include <string.h>
#include <unistd.h>
// 我没有指明具体的路径,采用了字符串拼接的方式。
#define FILE_NAME(number) "log.txt" #numberint main()
{close(0);umask(0);int fd1 = open(FILE_NAME(1), O_WRONLY | O_CREAT, 0666);int fd2 = open(FILE_NAME(2), O_WRONLY | O_CREAT, 0666);int fd3 = open(FILE_NAME(3), O_WRONLY | O_CREAT, 0666);int fd4 = open(FILE_NAME(4), O_WRONLY | O_CREAT, 0666);int fd5 = open(FILE_NAME(5), O_WRONLY | O_CREAT, 0666);printf("fd1:%d\n", fd1);printf("fd2:%d\n", fd2);printf("fd3:%d\n", fd3);printf("fd4:%d\n", fd4);printf("fd5:%d\n", fd5);close(fd1);close(fd2);close(fd3);close(fd4);close(fd5);
}结果,我们自己打开的文件就把0号文件描述符给占用了。接着,我们试试关闭之后写入受什么影响。
没关闭之前:
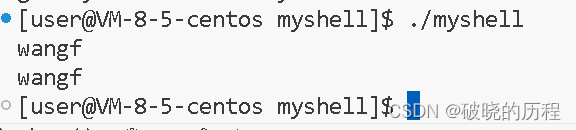
#include<stdio.h>
#include<unistd.h>
#include<string.h>
int main()
{//close(0);char buffer[1024];memset(buffer,0,sizeof(buffer));scanf("%s",buffer);printf("%s\n",buffer);
}
关闭后:
#include<stdio.h>
#include<unistd.h>
#include<string.h>
int main()
{close(0);char buffer[1024];memset(buffer,0,sizeof(buffer));scanf("%s",buffer);printf("%s\n",buffer);
}
我们发现:scanf函数直接无法使用,输入功能无法使用。原因是什么?
这是因为我们将0号文件描述符关闭后,0号文件描述符就不指向标准输入流了。但是当使用输入函数输入时,他们仍然会向0号中输入,但0号已经不指向输入流了,所以就无法完成输入。
大家也可以自行将1号文件描述符和2号文件描述符试着关闭一下,观察一下关闭前后有什么不同之处。
3.如何理解文件操作的本质?
- 我们说:文件操作的本质是进程和被打开文件之间的关系。对这句话我们应该如何理解呢?
- 文件描述符为什么就是数组的下标呢?
- 如何理解键盘,显示器也是文件?
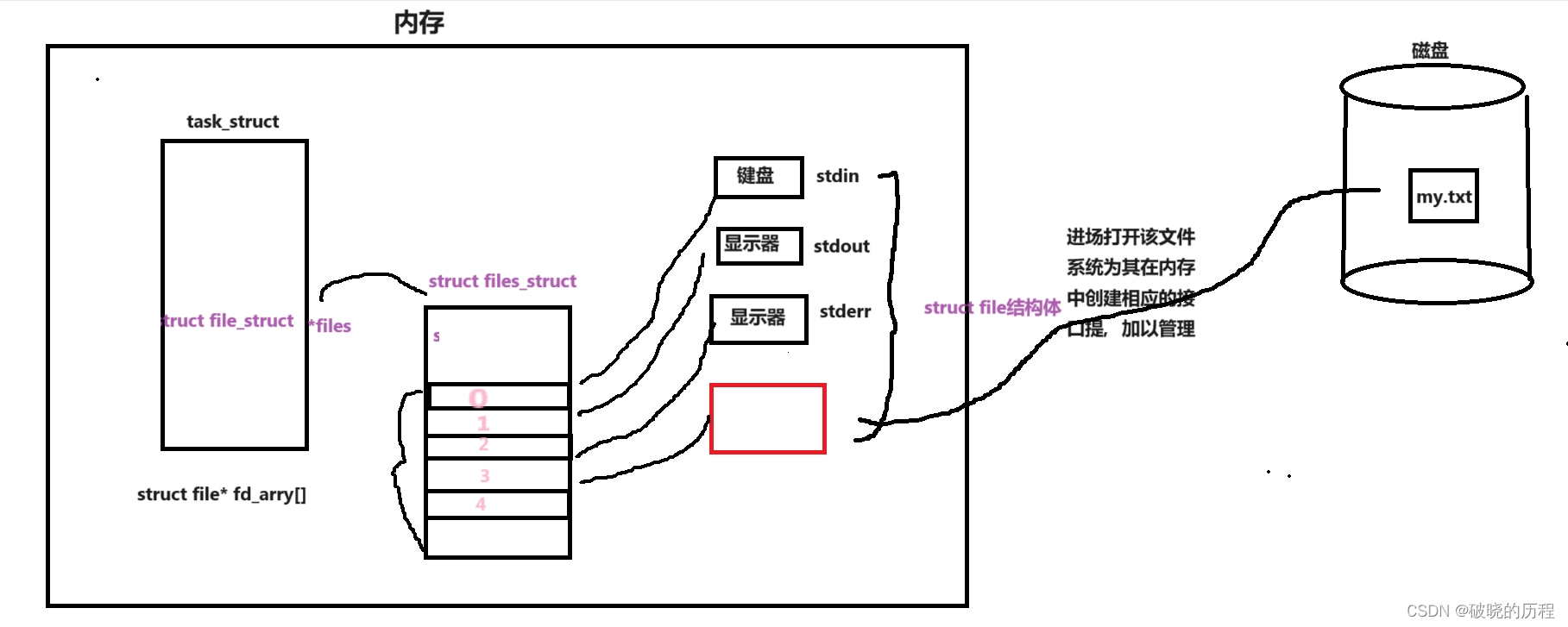
如上图:
进程想要打开位于磁盘上的my.txt文件,文件加载到内存之后,操作系统为了管理该文件,为其创建了一个struct file结构体来保存该文件的属性信息。此时,内存中已经存在系统默认打开的标准输入流,标准输出流,标准错误流对应的struct file结构体。但是,系统中有很多进程,,一定会有大量被打开的文件,进程如何分清个哪文件属于该进程呢?我们知道task_struct结构体保存着关于该进程的所有属性。其中有一个struct file_struct*类型的指针files,指向一个struct file_struct 类型的结构体,该结构体中存在着一个struct file*类型的数组,数组的元素为struct file*类型。正好存放指向我们为每一个文件创建的struct file结构体的指针。所以,根据这个数组,我们就会很顺利的找到每一个文件的struct file结构体。进而找到每一个属于该进程的文件,然后对文件进行相关操作。由于数组的下标具有很好的唯一性,所以系统就向上层返回存放文件的struct file结构体指针的元素下标,供上层函数利用这个下标对文件进行操作。
通过这段文字,相信大家已经对我们刚刚提出的几个问题已经有了答案!
4.输入重定向和输出重定向
1.原理
重定向的原理就是:上层调用的fd不变,在内核中更改fd对应的struct file*地址。
如下图:
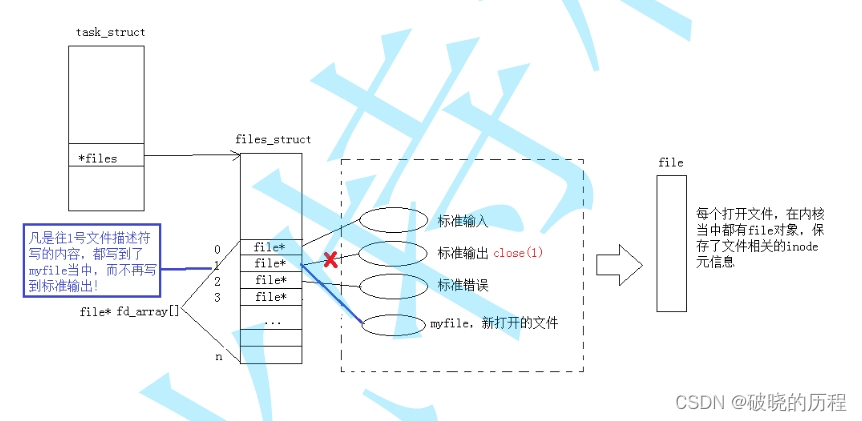
我们调用了close(1)关闭了输出文件流。然后打开了myfile文件,根据文件描述符的分配规则(从0开始查找最小且没有被占用的充当自己的文件描述符)。myfile的文件描述符。但是上层并不知道输入文件流对应的文件描述符已经发生改变,所以当调用printf函数时,仍然向1号文件描述符中输出。但是1号描述符对应的地址已发生改变,变为myfile,所以本想使用printf往显示器中输入的东西就会输入到myfile文件中。这就是输出重定向。
输入重定向和输出重定向原理是一样的,只不过输入重定向关闭的是输入流,输出重定向关闭的是输出文件流。
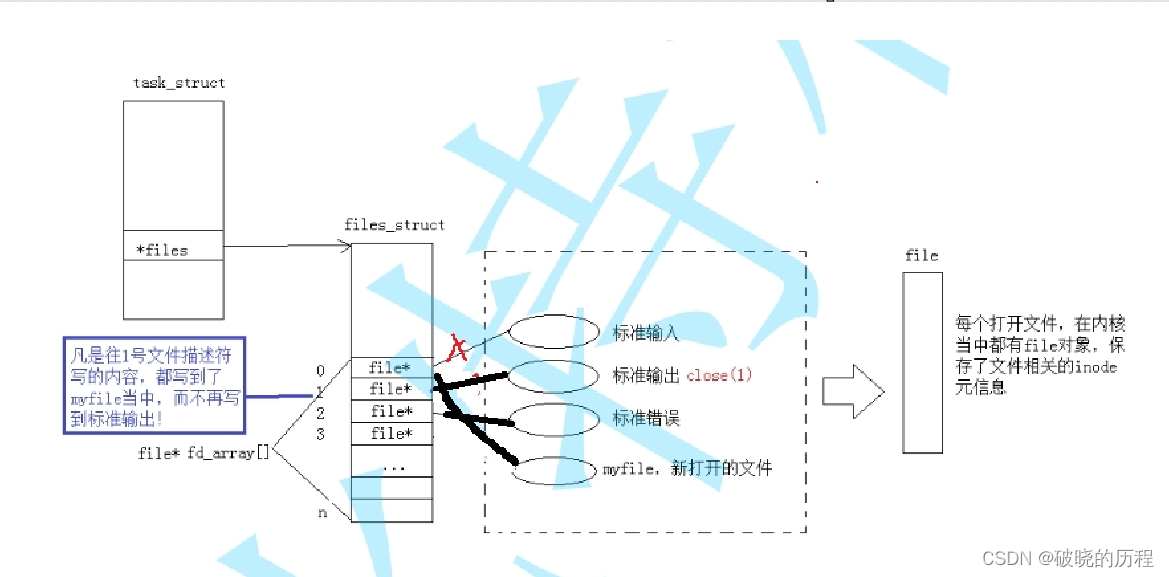
我们调用了close(0)关闭了输入文件流。然后打开了myfile文件,根据文件描述符的分配规则(从0开始查找最小且没有被占用的充当自己的文件描述符)。myfile的文件描述符。但是上层并不知道输入文件流对应的文件描述符已经发生改变,所以当调用printf函数时,仍然向0号文件描述符中输出。但是0号描述符对应的地址已发生改变,变为myfile,所以就会输入到myfile文件中。这就是输入重定向。
2.代码实现重定向
说了这么多,是不是该实现一下了:
先来实现一下输出重定向:
#include<stdio.h>
#include<unistd.h>
#include<string.h>
#include<sys/stat.h>
#include<sys/types.h>
#include<fcntl.h>
int main()
{close(1);umask(0); int n=open("wang.txt",O_RDWR|O_CREAT,0666);printf("wanghan");close(n);
}
什么鬼?失蒜了?,其实,这时候我们输出的内容都在缓冲区内,没被刷新出来,我们需要手动刷新一下缓冲区。把代码修改一下:
#include<stdio.h>
#include<unistd.h>
#include<string.h>
#include<sys/stat.h>
#include<sys/types.h>
#include<fcntl.h>
int main()
{close(1);umask(0); int n=open("wang.txt",O_RDWR|O_CREAT,0666);printf("wanghan");fflush(stdout);//刷新缓冲区close(n);
}
看,我们想要打印在显示器中的东西,就被我们成功输出到了指定的文件中。
接着,我们尝试一下写输入重定向:
#include<stdio.h>
#include<unistd.h>
#include<string.h>
#include<sys/stat.h>
#include<sys/types.h>
#include<fcntl.h>
int main()
{close(0);umask(0); int n=open("wang.txt",O_RDWR|O_CREAT,0666);scanf("%d",stdin);char arr[1024]="conglution you,you are successful";write(0,arr,strlen(arr));close(n);
}
但是,这搞个重定向这么复杂,是不是有点太low了?所以专门用于重定向的函数就出现了。
3.dup函数

其中,我们最常用的就是dup2。


返回值:
- 如果成功,返回newfd。
- 如果失败,返回-1。
原理:将oldfd中的struct file结构体地址拷贝到newfd中。
实例:
输出重定向
#include<stdio.h>
#include<unistd.h>
#include<string.h>
#include<sys/stat.h>
#include<sys/types.h>
#include<fcntl.h>
int main()
{umask(0); int n=open("wang.txt",O_RDWR|O_CREAT|O_TRUNC);dup2(n,1);//尝试写一下输出重定向。printf("successful");fflush(stdout);close(n);
}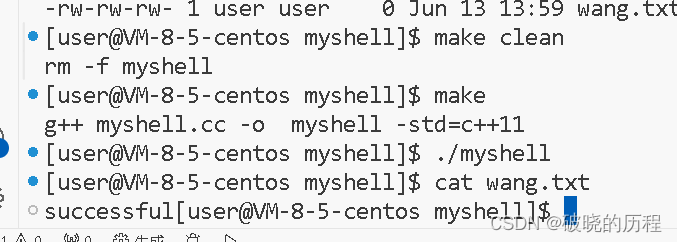
达到了我们的预期效果。
输入重定向
#include<stdio.h>
#include<unistd.h>
#include<string.h>
#include<sys/stat.h>
#include<sys/types.h>
#include<fcntl.h>
int main()
{int n=open("wang.txt",O_RDWR);dup2(n,0);//尝试写一下输入重定向。char buffer[64];while(1){printf(">");if(fgets(buffer,sizeof buffer,stdin)==nullptr) break; printf("%s",buffer);}close(n);return 0;
}

4.命令行中实现重定向
我们在命令行中,通过输入相关指令也可以实现重定向的功能:
'>':输入重定向
'>>':追加重定向
'<<':输出重定向这些命令底层都是用dup实现的,大家感兴趣的可以尝试写一下代码。
二.关于缓冲区
1.现象
#include<stdio.h>
#include<stdlib.h>
#include<unistd.h>
#include<string.h>
int main()
{//C接口printf("hello printf\n");fprintf(stdout,(char*)"hello fprintf\n");fputs("hello fputs\n",stdout);//系统接口char *msg="hello write\n";write(1,msg,strlen(msg));fork();return 0;}
我们观察到:把运行结果重定向到文件中时,C语言函数都被打印了2次,唯独操作系统接口被打印了一次。这是为什么?但是我们知道这种现象一定和缓冲区有关。
2.重新理解缓冲区
缓冲区本质就是一段内存!!谁申请的?属于谁?为什么要申请 ?
我们先来一个故事乐呵一下:
张三在广东,他的好朋友李四在北京。他们俩关系嘎嘎好,所以,张三总喜欢把自己用过的东西送给李四,比如包浆的键盘等等。头一开始,张三 都是骑车或者坐火车亲自把东西给李四送过。一来一会都得花小半个月的时间。有一次,舍友对他说:"咱们楼下不是有顺丰嘛,你干嘛不快递给他寄过去呢?"。一语点醒梦中人啊!!从那以后,张三就给李四发快递给他送东西。这样,张三就可以有时间学习和干其他事情了。所以人们都喜欢用快递发送东西,节省时间。
广东就相当于内存,北京就相当于磁盘,张三就相当于一个进程,楼下的顺丰就相当于内存中的缓冲区。内存往磁盘中写东西是非常慢的,就像张三亲自给李四送东西一样。那么缓冲区的意义是什么呢?节省进程进行数据IO的时间
但是,我们并没有做让数据写入到缓冲区的操作呀?
我们使用的fwrite函数,与其把它当做一个文件写入函数,不如把它当做一个拷贝函数,将数据从缓冲区拷贝到“内存”或“外设”。
3.缓冲区刷新策略问题
同样的数据量 ,一次性全部写入到磁盘中,和多次少量写入到外设中,哪种效率最高?
毫无疑问,一次性写入磁盘中效率最高,因为数据的读取和写入占用的时间很短,大部分时间都用来等待外设就绪。
缓冲区一定会结合自己的设备,定制自己的刷新策略:
- 行刷新:即行缓存,对应的设备就是显示器,我们试用的“\n”采用的刷新方式都是行刷新。虽然使用将数据一次刷新到显示器上效率最高,但是人类更习惯于按行读取内容,所以为了给用户更好的体验,使用行刷新更好。
- 立即刷新:相当于没有缓冲区。
- 缓冲区满:全刷新,常用于向磁盘文件中写入。效率最高。
有两种情况不符合刷新策略的规定
- 用户强制刷新,比如fflush(stdout)。
- 进程退出,一般都要刷新缓冲区。
4.缓冲区的位置
缓冲区在哪?指的是什么缓冲区?
首先,我们可以肯定:这个缓冲区一定不在内核中,因为如果缓冲区在内核中,write也会打印两次。
我们之前谈论的所有的缓冲区,都指的是用户级语言层面给我们提供的缓冲区。
我们之前提到过:stdout,stdin,stderr的类型都是FILE*类型,FILE是一个结构体,该结构体中除了包含一个fd,还有一个缓冲区。所以我们强制刷新缓冲区调用fflush时,都要传入一个FILE*类型的指针;我们在关闭一个进程调用fclose时,也要传入一个FILE*类型的指针。因为FILE结构体内部包含一个缓冲区。
如图:

5.如何解释刚刚的现象呢?
明白了上面的内容,我们就能够明白刚刚的现象了。
没有进行重定向。stdout默认使用的是行刷新,在进程调用fork()之前,三条C语言函数打印的信息已经显示到了显示器上(外设)。FILE内部的缓冲区不存在对应的数据了。
如果进行了重定向,写入不再是显示器,而是磁盘文件,采用的刷新策略是缓冲区满再刷新。之前的3条打印的信息,虽然带来‘\n’,但是不足以让stdout缓冲区写满。数据并没有被刷新。执行fork时,stdout属于父进程。创建子进程时,紧接着就是进程退出,谁先退出,就要先进行缓冲区刷新(也就是修改数据,发生写时拷贝)。父子进程在退出时都会刷新一次缓冲区,所以就会打印两次。
write为什么没有被打印两次呢?
上面的过程和write无关,因为write没有FILE,而用的是fd,也就无法使用C语言层面的缓冲区。
总结
- C语言的一些IO接口需要熟练掌握,例如fwrite,fread等等。明白C文件函数和系统接口之间的关系。C函数是底层库函数的封装。
- 当前当前路径是根据进程的cwd来决定的,C语言默认打开三个流:stdin、stdout、stderr。他们三个 分别占用0、1、2三个文件描述符。
- 系统层面的IO交互接口有 write、open、close、read等需要理解。
- 文件=内容+属性;一个文件是否为空都会存在属性,而操作系统为了维护文件的属性,先描述再组织,将文件的属性组织为一个结构体file,而 每个file以双链表的形式相连。
- 因为Linux下一切皆文件,所以文件也需要被组织起来,于是file结构体的指针file*被组织起来封装在一个叫做files_struct 指针数组内,而数组下标就是 文件描述符。
- 重定向是 根据更改文件描述符的指向的struct file结构体 做到的,可以使用dup2接口做调整。
- 缓冲区本质上是一块内存区域,而缓冲区分为系统层缓冲区和语言层缓冲区,在C语言中缓冲区被封装在FILE结构体内,每一个文件都有自己的缓冲区。
- 缓冲区满了会刷新到内核中,而 刷新的本质就是写入。
写到最后,本文到这里就结束了,谢谢大家观看,如果文中有什么错误,欢迎大家批评指正!!

相关文章:
Linux基础IO【II】真的很详细
目录 一.文件描述符 1.重新理解文件 1.推论 2.证明 2.理解文件描述符 1.文件描述符的分配规则 3.如何理解文件操作的本质? 4.输入重定向和输出重定向 1.原理 2.代码实现重定向 3.dup函数 编辑 4.命令行中实现重定向 二.关于缓冲区 1.现象 …...

【C++】模板及模板的特化
目录 一,模板 1,函数模板 什么是函数模板 函数模板原理 函数模板的实例化 推演(隐式)实例化 显示实例化 模板的参数的匹配原则 2,类模板 什么是类模板 类模板的实例化 二,模板的特化 1,类模板的特化 全特化…...
2001-2023年上市公司数字化转型测算数据(含原始数据+处理代码+计算结果)
2001-2023年上市公司数字化转型测算数据(含原始数据处理代码计算结果)(吴非) 1、时间:2001-2023年 2、来源:上市公司年报 3、指标:行业代码、行业名称、证券简称、是否发生ST或ST或PT、是否发生暂停上市…...
ICRA 2024:基于视觉触觉传感器的物体表⾯分类的Sim2Real双层适应⽅法
⼈们通常通过视觉来感知物体表⾯的性质,但有时需要通过触觉信息来补充或替代视觉信息。在机器⼈感知物体属性⽅⾯,基于视觉的触觉传感器是⽬前的最新技术,因为它们可以产⽣与表⾯接触的⾼分辨率 RGB 触觉图像。然⽽,这些图像需要⼤…...
)
代理模式(设计模式)
文章目录 静态代理动态代理代理模式的应用场景动态代理和静态代理的区别 代理模式就是给一个对象提供一个代理,并由代理对象控制对原对象的引用。它使得客户不能直接与真正的目标对象通信。代理对象是目标对象的代表,其他需要与这个目标对象打交道的操作…...

C++函数参数传递
C 函数传参 在C中,函数传递参数的方式主要有三种: 按值传递(pass by value)按引用传递(pass by reference)按指针传递(pass by pointer)。 比较与总结 按值传递:适用…...

软考初级网络管理员_09_网络单选题
1.下列Internet应用中对实时性要求最高的是()。 电子邮件 Web浏览 FTP文件传输 IP电话 2.在Internet中的大多数服务(如WWW、FTP等)都采用()模型。 星型 主机/终端 客户机/服务器 网状 3.子网掩码的作用是()。 可以用来寻找网关 可以区分IP和MAC 可以识别子网 可以…...

曲线拟合 | 二次B样条拟合曲线
B 样条曲线拟合实例:能平滑化曲线 1. 实例1 为MASS包中mcycle数据集。它测试了一系列模拟的交通车事故中,头部的加速度,以此来评估头盔的性能。times为撞击时间(ms),accel为加速度(g)。首先导入数据&#…...

delphi FDMemTable1.SourceView遍历各行数据,取任意行数据无需Next移动指针了。TFDDatSView
for m : 0 to FDMemTable1.SourceView.Rows.Count - 1 do begin if FDMemTable_SP.SourceView.Rows.ItemsI[m].GetData(0) varNull then Continue; end; 9行7列的值。 FDMemTable1.Data.DataView.Rows.ItemsI[9].ValueI[7]; FDMemTable1.Table.Ro…...

为什么选择 ABBYY FineReader PDF ?
帮助用户们对PDF文件进行快速的编辑处理,同时也可以快速识别PDF文件里的文字内容,并且可以让用户们进行文本编辑,所以可以有效提升办公效率。 ABBYY-ABBYY Finereader 15 Win-安装包:https://souurl.cn/OY2L3m 高级转换功能 ABBY…...
php遇到的问题
1、 underfined at line 3 in xxx.php , 错误提示,注释这行代码 // error_reporting(DEBUG ? E_ALL : 0); 目录:config/config.php...
零基础入门学用Arduino 第二部分(二)
重要的内容写在前面: 该系列是以up主太极创客的零基础入门学用Arduino教程为基础制作的学习笔记。个人把这个教程学完之后,整体感觉是很好的,如果有条件的可以先学习一些相关课程,学起来会更加轻松,相关课程有数字电路…...
旅游行业电商平台:数字化转型的引擎与未来发展趋势
引言 旅游行业数字化转型的背景和重要性 随着信息技术的飞速发展,数字化转型成为各行业发展的必然趋势。旅游行业,作为一个高度依赖信息和服务的领域,数字化转型尤为重要。通过数字化手段,旅游行业能够实现资源的高效配置、服务的…...
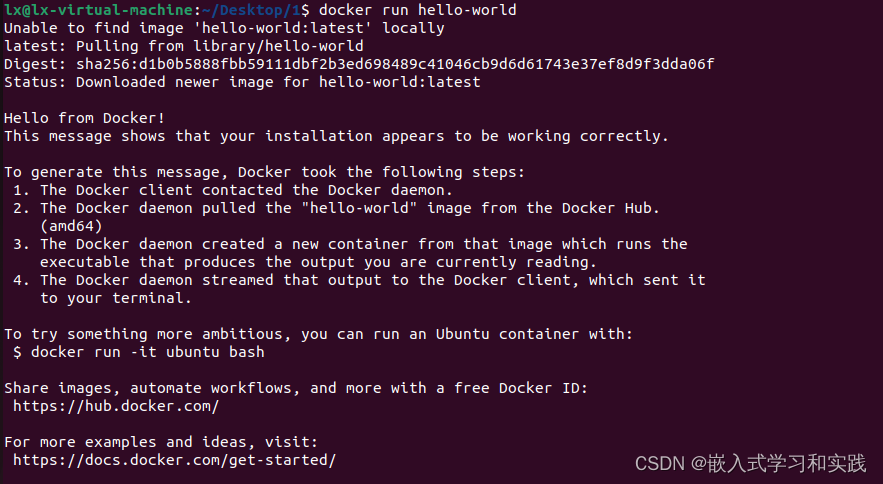
Ubuntu 22.04安装 docker
安装过程和指令 # 1.升级 apt sudo apt update # 2.安装docker sudo apt install docker.io docker-compose # 3.将当前用户加入 docker组 sudo usermod -aG docker ${USER} # 4. 重启 # 5. 查看镜像 docker ps -a 或者 docker images # 6. 下载镜像 docker pull hello-world …...

【Gitlab】访问默认PostgreSQL数据库
本地访问PostgreSQL gitlab有可以直接访问内部PostgreSQL的命令 sudo gitlab-rails dbconsole # 或者 sudo gitlab-psql -d gitlabhq_production效果截图 常用SQL # 查看用户状态 select id,name,email,state,last_sign_in_at,updated_at,last_credential_check_at,last_act…...

乐鑫ESP32-C3芯片应用,启明云端WT32C3-S5模组:简化产品硬件设计
在数字化浪潮的推动下,物联网(IoT)正迅速成为连接现实世界与数字世界的桥梁。芯片作为智能设备的心脏,其重要性不言而喻。 乐鑫推出的ESP32-C3芯片以其卓越的性能和丰富的功能,为智能物联网领域带来了新的活力,我将带您深入了解这…...

算法刷题【二分法】
题目: 注意题目中说明了数据时非递减的,那么这样就存在二分性,能够实现logn的复杂度。二分法每次只能取寻找特定的某一个值,所以我们要分别求左端点和有端点。 分析第一组用例得到结果如下: 成功找到左端点8 由此可知࿰…...
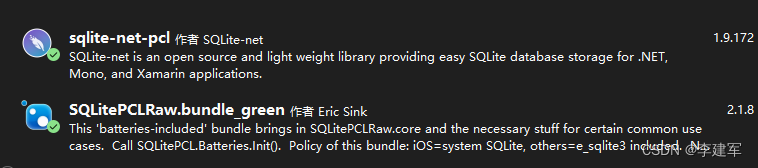
.NET MAUI Sqlite程序应用-数据库配置(一)
项目名称:Ownership(权籍信息采集) 一、安装 NuGet 包 安装 sqlite-net-pcl 安装 SQLitePCLRawEx.bundle_green 二、创建多个表及相关字段 Models\OwnershipItem.cs using SQLite;namespace Ownership.Models {public class fa_rural_base//基础数据…...
基于WPF技术的换热站智能监控系统09--封装水泵对象
1、添加用户控件 2、编写水泵UI 控件中用到了Viewbox控件,Viewbox控件是WPF中一个简单的缩放工具,它可以帮助你放大或缩小单个元素,同时保持其宽高比。通过样式和属性设置,你可以创建出既美观又功能丰富的用户界面。在实际开发中…...

GLM+vLLM 部署调用
GLMvLLM 部署调用 vLLM 简介 vLLM 框架是一个高效的大型语言模型(LLM)推理和部署服务系统,具备以下特性: 高效的内存管理:通过 PagedAttention 算法,vLLM 实现了对 KV 缓存的高效管理,减少了…...

SAP 生产订单批量创建与下达实战:基于 BAPI_PRODORD_CREATE 的自动化方案
1. 为什么需要批量创建生产订单? 在制造业的实际业务场景中,生产计划部门经常需要根据销售订单、预测数据或库存情况,一次性生成大量生产订单。想象一下,一个汽车零部件工厂每月要处理上千个零部件的生产计划,如果每个…...

RK3576开发板调试EC11编码器,一分钟就失灵?原来是XL9535芯片这个引脚没上拉
RK3576开发板EC11编码器调试:XL9535中断引脚上拉缺失引发的"一分钟失灵"之谜 刚拿到RK3576开发板时,我满心期待地接上了EC11旋转编码器进行测试——上电后旋转旋钮,系统响应灵敏,GPIO中断触发准确。但正当我准备庆祝调试…...

Visual C++组件维护完全指南:从问题诊断到系统优化
Visual C组件维护完全指南:从问题诊断到系统优化 【免费下载链接】vcredist AIO Repack for latest Microsoft Visual C Redistributable Runtimes 项目地址: https://gitcode.com/gh_mirrors/vc/vcredist Visual C组件维护是Windows系统稳定运行的关键环节&…...

Akagi技术深度解析:开源雀魂AI辅助工具完全实战指南
Akagi技术深度解析:开源雀魂AI辅助工具完全实战指南 【免费下载链接】Akagi 支持雀魂、天鳳、麻雀一番街、天月麻將,能夠使用自定義的AI模型實時分析對局並給出建議,內建Mortal AI作為示例。 Supports Majsoul, Tenhou, Riichi City, Amatsuk…...

HsMod:炉石传说个性化增强工具 玩家的全方位游戏体验优化方案
HsMod:炉石传说个性化增强工具 玩家的全方位游戏体验优化方案 【免费下载链接】HsMod Hearthstone Modify Based on BepInEx 项目地址: https://gitcode.com/GitHub_Trending/hs/HsMod 你是否曾因炉石传说中繁琐的操作流程而感到沮丧?是否希望拥有…...

InoDriverShop参数设置避坑指南:如何避免伺服系统调试中的常见错误
InoDriverShop参数设置避坑指南:如何避免伺服系统调试中的常见错误 伺服系统调试是工业自动化领域中的关键环节,而InoDriverShop作为一款功能强大的伺服驱动配置工具,其参数设置的准确性直接影响到设备的运行性能。本文将深入剖析新手工程师…...

别再混淆了!一文讲透NvDecoder里ulNumDecodeSurfaces和ulNumOutputSurfaces到底怎么用
深入解析NvDecoder:解码缓存与输出缓存的本质区别与实战配置 在视频处理领域,NVIDIA的硬件解码器(NVDEC)因其出色的性能和高效的资源利用率而广受开发者青睐。然而,对于许多中高级开发者来说,NvDecoder中ul…...
)
药物研发新思路:共价对接工具AutoDock4实战指南(附避坑技巧)
药物研发新思路:共价对接工具AutoDock4实战指南(附避坑技巧) 在当今药物研发领域,共价抑制剂因其独特的作用机制和显著的治疗优势正受到前所未有的关注。与传统非共价药物相比,这类分子能与靶蛋白形成稳定的共价键&…...

施密特触发器在智能家居中的7个隐藏用法:从空调变频到漏电保护
施密特触发器在智能家居中的7个隐藏用法:从空调变频到漏电保护 智能家居的普及让我们的生活更加便捷,但背后支撑这些设备的电子技术却鲜为人知。施密特触发器作为一种基础的电子元件,在智能家居系统中扮演着关键角色。它不仅能解决信号抖动问…...
)
快速掌握C#语言基础知识点(17.委托)
关注我的动态 namespace _17.委托 {public delegate void doMyAction(); //委托,无参,无返回值public delegate int doPlus(int a, int b);//委托,有参,有返回值internal class Program{//委托成员变量public static doMyAction a…...