基于Seatunnel最新2.3.5版本分布式集群安装部署指南(小白版)
基于Seatunnel2.3.5版本分布式集群安装部署
- 1.环境准备
- 2.JDK安装
- 3.Maven安装
- 4.Seatunnel在master节点安装部署配置
- 4.1.下载Seatunnel安装包
- 4.2.解压下载好的tar.gz包
- 4.3.下载连接器
- 4.4.配置Seatunnel的系统环境变量
- 4.5.配置 SeaTunnel Engine服务 JVM参数
- 4.6.配置文件中集群相关参数修改
- 4.6.1.SEATUNNEL配置文件修改
- 4.6.2.SEATUNNEL Engine服务配置文件修改
- 4.6.3.SEATUNNEL Engine客户端配置文件修改
- 5.分布式集群安装部署
- 5.1.创建日志目录
- 5.2.添加服务分发集群脚本
- 5.3.Seatunnel服务分发到集群其他主机
- 5.4.Seatunnel服务系统环境配置文件分发到集群其他主机
- 6.基于Spark/flink引擎的Seatunnel集群配置
- 7.Seatunnel集群常用管理命令
- 8.Seatunnel集群任务测试验证
1.环境准备
分布式集群基本环境准备,请参考我的另一篇文章dolphinscheduler分布式集群部署指南(小白版)中的环境准备小节进行配置
| IP地址 | 主机名 | 角色说明 |
|---|---|---|
| 10.10.3.10 | hadoop1001 | master节点 |
| 10.10.3.11 | hadoop1002 | slave节点 |
| 10.10.3.12 | hadoop1003 | slave节点 |
| 10.10.3.13 | hadoop1004 | slave节点 |
| 10.10.3.14 | hadoop1005 | slave节点 |
2.JDK安装
这部分跳过,很简单,基本随便找个博客文章照着配置就能搞定。
3.Maven安装
这部分跳过,很简单,基本随便找个博客文章照着配置就能搞定。
也可以不安装, 直接将Seatunnel2.3.5的源码下载到本地, 通过本地的mave把所有需要用到的连接器插件先下载下来再上传到安装目录下的$SEATUNNEL_HOME/lib目录和$SEATUNNEL_HOME/connectors/seatunnel目录下也是可以的, 这样就不需要安装Maven了。
4.Seatunnel在master节点安装部署配置
4.1.下载Seatunnel安装包
Seatunnel安装包下载
下载Seatunnel安装包上传到master节点hadoop1001的/opt/packages目录下
4.2.解压下载好的tar.gz包
tar -zxvf /opt/packages/apache-seatunnel-2.3.5-bin.tar.gz -C /opt/software
(3)查看Seatunnel使用的脚本
进入Seatunnel安装目录
cd /opt/software/apache-seatunnel-2.3.5

install-plugin.sh --安装连接器脚本seatunnel-cluster.sh -–集群模式启动脚本seatunnel-cluster.sh --本地模式启动脚本start-seatunnel-flink-13-connector-v2.sh –-flink1.2-1.4版本引擎启动脚本start-seatunnel-flink-15-connector-v2.sh –-flink1.5-1.6版本引擎启动脚本start-seatunnel-spark-2-connector-v2.sh –-saprk2.x版本引擎启动脚本start-seatunnel-spark-3-connector-v2.sh –-saprk3.x版本引擎启动脚本
4.3.下载连接器
这里可以直接将Seatunnel2.3.5的源码下载到本地,
修改install-plugin.cmd脚本,通过调用本地的mave把所有需要用到的连接器插件先下载下来再上传到安装目录下的$SEATUNNEL_HOME/lib目录和$SEATUNNEL_HOME/connectors/seatunnel目录下也可以
进入Seatunnel安装目录
cd /opt/software/apache-seatunnel-2.3.5
修改install-plugin.sh脚本, 切换成本地自定义安装的maven进行插件下载安装。

注意,如果你需要使用这种方式需要保证你的本地已经安装了apache-maven(>=3.6.3),并且已经给maven配置了系统环境变量。
下载完成之后将/opt/software/seatunnel-2.3.5/connectors下的所有的jar包都拷贝到·/opt/software/seatunnel-2.3.5/connectors/seatunnel目录下以及/opt/software/seatunnel-2.3.5/lib目录下
mkdir -p /opt/software/apache-seatunnel-2.3.5/connectors/seatunnel/cp /opt/software/apache-seatunnel-2.3.5/connectors/*.jar /opt/software/apache-seatunnel-2.3.5/connectors/seatunnel/cp /opt/software/apache-seatunnel-2.3.5/connectors/seatunnel/* /opt/software/seatunnel-2.3.5/lib/
操作完成结果如下:
/opt/software/apache-seatunnel-2.3.5/connectors/seatunnel/目录下如下图:

/opt/software/seatunnel-2.3.5/lib/目录下如下图:

4.4.配置Seatunnel的系统环境变量
- 编辑
/etc/profile.d/seatunnel.sh
vim /etc/profile.d/seatunnel.sh
- 在文件中添加以下内容配置环境变量
export SEATUNNEL_HOME=/opt/software/apache-seatunnel-2.3.5
export PATH=$PATH:$SEATUNNEL_HOME/bin
wq!保存退出, 一定要保存退出。
- 系统环境变量立即生效
source /etc/profile
- 验证系统环境变量是否生效
echo $SEATUNNEL_HOME
命令行输出如下,说明配置成功

4.5.配置 SeaTunnel Engine服务 JVM参数
将 JVM 参数选项添加到$SEATUNNEL_HOME/bin/seatunnel-cluster.sh文件的开头
JAVA_OPTS="-Xms2G -Xmx2G"

4.6.配置文件中集群相关参数修改
主要针对``$SEATUNNEL_HOME/config/`以下三个文件进行修改

修改具体说明一下每个文件都要修改的配置项
现在seatunnel的官方已经出了中文版本的文档, 如果觉得我写的很乱,或者有问题,可以直接查看官方文档 Apache Seatunnel官网中文文档传送门
4.6.1.SEATUNNEL配置文件修改
SEATUNNEL配置$SEATUNNEL_HOME/config/seatunnel.yaml文件
因为我这里已经按照了hadoop的集群, 可以直接使用HDFS api 读写文件,存储直接使用默认的HDFS,当然你也可以使用其他的存储类型,具体的参数配置可以参考官网说明。

修改参数如下:
seatunnel:engine:history-job-expire-minutes: 1440backup-count: 1queue-type: blockingqueueprint-execution-info-interval: 60print-job-metrics-info-interval: 60slot-service:dynamic-slot: truecheckpoint:interval: 10000timeout: 60000storage:type: hdfsmax-retained: 3plugin-config:namespace: /tmp/seatunnel/checkpoint_snapshotstorage.type: hdfs# 主要就是修改了hdfs的URI,其它参数使用了系统默认参数fs.defaultFS: hdfs://hadoop1001:8020
4.6.2.SEATUNNEL Engine服务配置文件修改
SEATUNNEL Engine配置$SEATUNNEL_HOME/config/hazelcast.yaml文件
具体的配置项的解释说明请查看 配置 SeaTunnel Engine 服务
hazelcast:# seatunnel集群的名称, 这这个集群名称需要和SEATUNNEL Engine客户端配置文件中集群名称保持一致cluster-name: st-etlnetwork:rest-api:enabled: trueendpoint-groups:CLUSTER_WRITE:enabled: trueDATA:enabled: truejoin:tcp-ip:enabled: true# 需要部署Seatunnel集群的主机列表member-list:- hadoop1001- hadoop1002- hadoop1003- hadoop1004- hadoop1005port:auto-increment: false# 默认的端口是5801,需要确认这个端口未被系统占用port: 5801properties:hazelcast.invocation.max.retry.count: 20hazelcast.tcp.join.port.try.count: 30hazelcast.logging.type: log4j2hazelcast.operation.generic.thread.count: 50
4.6.3.SEATUNNEL Engine客户端配置文件修改
SEATUNNEL Engine配置$SEATUNNEL_HOME/config/hazelcast-client.yaml文件
具体的配置项的解释说明请查看 配置 SeaTunnel Engine 客户端
hazelcast-client:# seatunnel集群的名称, 这这个集群名称需要和SEATUNNEL Engine服务配置文件中集群名称保持一致cluster-name: st-etlproperties:hazelcast.logging.type: log4j2connection-strategy:connection-retry:cluster-connect-timeout-millis: 3000network:# SEATUNNEL Engine服务列表cluster-members:- hadoop1001:5801- hadoop1002:5801- hadoop1003:5801- hadoop1004:5801- hadoop1005:5801
通过以上操作, 单台机器上的seatunnel服务就安装配置完成了。现在我们进行分布式集群部署。
5.分布式集群安装部署
5.1.创建日志目录
我们提前在seatunnel的安装目录下创建一个日志目录,后续seatunnel集群启动之后日志文件会保存再改目录下,在seatunnel服务分发到其他节点之前,先进行该操作。
mkdir -p /opt/software/apache-seatunnel-2.3.5/logs

5.2.添加服务分发集群脚本
这个脚本可以生效需要满足以下三点:
- 需要分发服务的每台主机上都已经安装了
rsync服务 - 集群的域名都已经进行映射
- 脚本执行的主机上已经设置了SSH免密登录其他节点
在hadoop1001主机上添加集群服务分发脚本,直接添加到/usr/bin目录(免得还需要配合子系统环境变量)
vim /usr/bin/data_rsync
脚本内容如下:
#!/bin/bash
#1 获取输入参数个数,如果没有参数,直接退出
pcount=$#
if((pcount==0)); then
echo no args;
exit;
fi#2 获取文件名称
p1=$1
fname=`basename $p1`
echo fname=$fname#3 获取上级目录到绝对路径
pdir=`cd -P $(dirname $p1); pwd`
echo pdir=$pdir#4 获取当前用户名称
user=`whoami`#5 循环()
for((host=2; host<=5; host++)); doecho ------------------- hadoop$host --------------rsync -av $pdir/$fname $user@hadoop100$host:$pdir
done
配置脚本的执行权限
chmod 777 /usr/bin/data_rsync
5.3.Seatunnel服务分发到集群其他主机
执行以下命令完成服务分发
data_rsync /opt/software/seatunnel-2.3.5
如下图说明同步分发完成

检查hadoop1001~1005的主机上/opt/software/目录下是否成功同步了seatunnel-2.3.5安装包
5.4.Seatunnel服务系统环境配置文件分发到集群其他主机
执行以下命令完成服务分发
data_rsync /etc/profile.d/seatunnel.sh


分发完成之后, 登录依次ssh登录到每台服务(hadoop1001~hadoop1004)上,让Seatunnel的系统环境变量立即生效。
- 系统环境变量立即生效
source /etc/profile
- 验证系统环境变量是否生效
echo $SEATUNNEL_HOME
命令行输出如下,说明配置成功
通过以上操作,我们的Seatunnel分布式集群基本就安装完毕了,下面我们继续完成spark引擎和flink引擎配置。
6.基于Spark/flink引擎的Seatunnel集群配置
首先需要部署spark和Flink集群, 这个应该也挺简单了,不会可以自行百度, 实在搞不定私信留言我再输出一个spark和Flink集群安装部署的文章。
我这里已经安装部署了spark和Flink集群, 所以不需要再进行spark集群的部署配置了,这里直接说明如何完成基于spark/Flink引擎的Seatunnel集群配置。
其他这个也很简单, 我们只需要修改seatunnel的环境配置脚本即可,将里面的spark的安装目录路径修改成我们本地的spark安装目录即可
vim $SEATUNNEL_HOME/config/seatunnel-env.sh

脚本内容如下:
#设置spark分布式集群的安装目录
SPARK_HOME=${SPARK_HOME:-/opt/software/spark}
#设置flink分布式集群的安装目录
FLINK_HOME=${FLINK_HOME:-/opt/software/flink}
保存退出。
然后将这个配置文件的修改同步到集群其他主机
data_rsync /opt/software/seatunnel-2.3.5/config/seatunnel-env.sh
重启Seatunnel集群即可。
7.Seatunnel集群常用管理命令
- 1)启动集群(需要在集群每台节点上都执行)
nohup $SEATUNNEL_HOME/bin/seatunnel-cluster.sh 2>&1 &
- 2)停止集群(需要在集群每台节点上都执行)
$SEATUNNEL_HOME/bin/stop-seatunnel-cluster.sh
3)默认引擎任务提交命令
$SEATUNNEL_HOME/bin/seatunnel.sh --config /opt/software/seatunnel-2.3.5/config/app-config/v2.batch.config.template
4)spark2.X版本引擎任务提交命令
$SEATUNNEL_HOME/bin/start-seatunnel-spark-2-connector-v2.sh --master local[4] --deploy-mode client --config /opt/software/seatunnel-2.3.5/config/app-config/v2.batch.config.template
5)spark3.X版本引擎任务提交命令
$SEATUNNEL_HOME/bin/start-seatunnel-spark-3-connector-v2.sh --master local[4] --deploy-mode client --config /opt/software/seatunnel-2.3.5/config/app-config/v2.batch.config.template
6)flink低版本引擎任务提交命令(Flink版本1.12.x到1.14.x)
$SEATUNNEL_HOME/bin/start-seatunnel-flink-13-connector-v2.sh --config /opt/software/seatunnel-2.3.5/config/app-config/v2.streaming.conf.template
7)flink高版本引擎任务提交命令(Flink版本1.15.x到1.16.x)
$SEATUNNEL_HOME/bin/start-seatunnel-flink-15-connector-v2.sh --config /opt/software/seatunnel-2.3.5/config/app-config/v2.streaming.conf.template
8.Seatunnel集群任务测试验证
在hadoop1001上执行基于spark引擎的任务提交进行测试验证, 验证之前需要保证集群服务正常启动
ps -ef|grep seatunnel
如下图,说明集群正常启动

提交测试任务
$SEATUNNEL_HOME/bin/start-seatunnel-spark-2-connector-v2.sh --master local[4] --deploy-mode client --config /opt/software/seatunnel-2.3.5/config/app-config/v2.batch.config.template
任务处理过程打印如下日志,说明集群配置正常,就可以创建其他数据处理的任务。



通过以上部署及验证,Seatunnel集群已经全部安装配置好了, 用起来吧。后续计划把Seatunnel结合Dolphinscheduler任务调度在实际业务中的使用再输出一篇文章。
如果觉得文章写的还不错,喜欢的童鞋们请点赞收藏,送你一送小红花哈。~
相关文章:
基于Seatunnel最新2.3.5版本分布式集群安装部署指南(小白版)
基于Seatunnel2.3.5版本分布式集群安装部署 1.环境准备2.JDK安装3.Maven安装4.Seatunnel在master节点安装部署配置4.1.下载Seatunnel安装包4.2.解压下载好的tar.gz包4.3.下载连接器4.4.配置Seatunnel的系统环境变量4.5.配置 SeaTunnel Engine服务 JVM参数4.6.配置文件中集群相关…...
SSM小区疫情防控系统-计算机毕业设计源码03748
摘 要 随着社会的发展,社会的各行各业都在利用信息化时代的优势。计算机的优势和普及使得各种信息系统的开发成为必需。 小区疫情防控系统,主要的模块包括查看首页、轮播图(轮播图管理)、社区公告管理(社区公告&#…...

英伟达算法岗面试,问的贼专业。。。
节前,我们星球组织了一场算法岗技术&面试讨论会,邀请了一些互联网大厂朋友、参加社招和校招面试的同学。 针对算法岗技术趋势、大模型落地项目经验分享、新手如何入门算法岗、该如何准备、面试常考点分享等热门话题进行了深入的讨论。 合集&#x…...

GIS之arcgis系列09:arcpy实现克里金差值
矢量点数据经过克里金差值后可以转换成栅格数据,那么就需要了解一下什么是克里金差值。 什么是克里金法? IDW(反距离加权法)和样条函数法插值工具被称为确定性插值方法,因为这些方法直接基于周围的测量值或确定生成表面的平滑度的指定数学公式。第二类…...
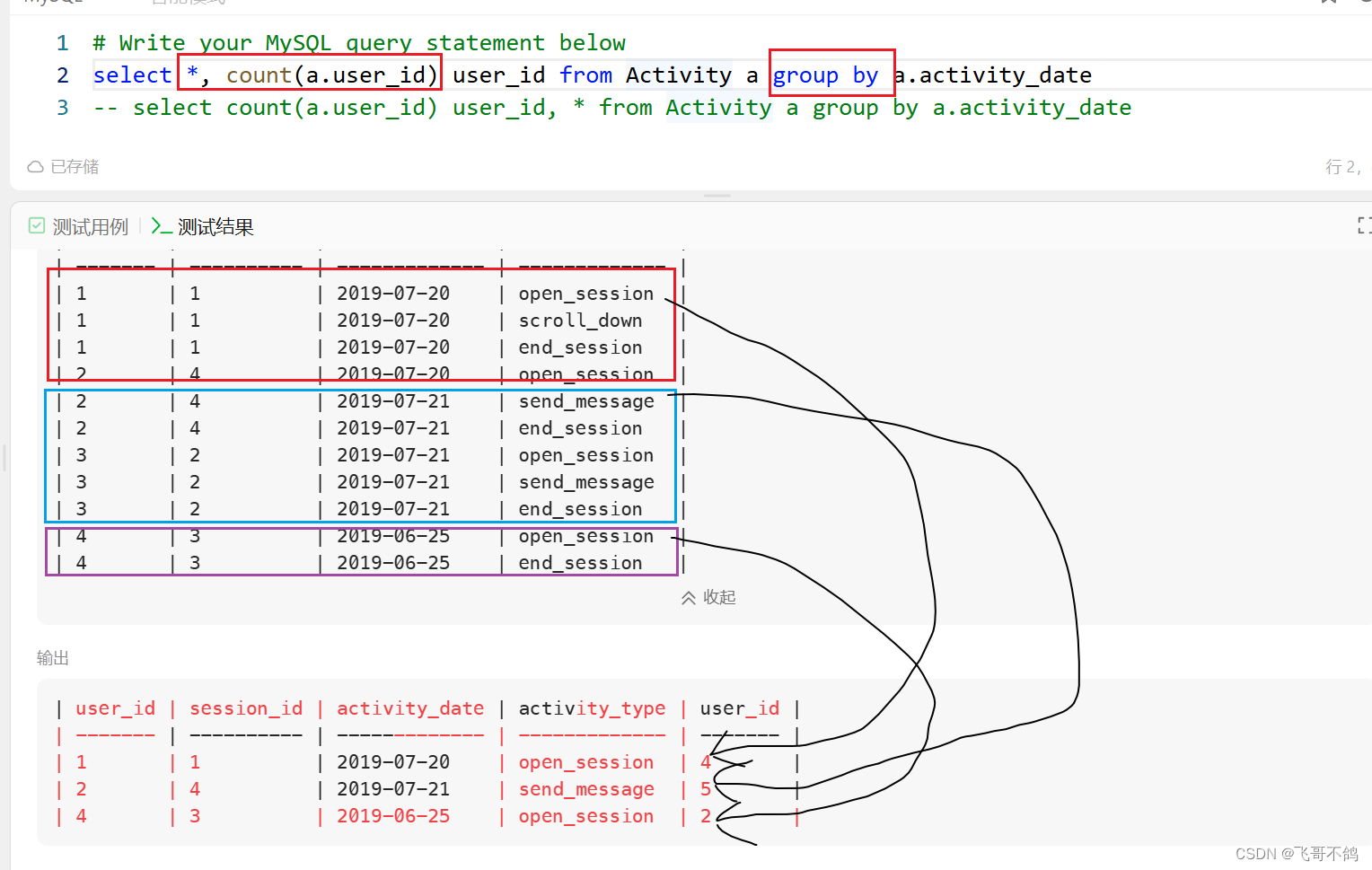
MySQL的group by与count(), *字段使用问题
文章目录 问题group by到底做了什么举个例子简单来说为什么select字段,count()不能和*共同使用总结 问题 这是一段摘抄自MySQL官网的文字。其大致意思是MySQL拓展了group by的使用,MySQL允许选择没有出现在group by中的字段。换句话说,标准SQ…...

Java——面向对象进阶(二)
前言: 多态,包,final关键字,权限修饰符和代码块 文章目录 一、多态1.1 概念1.2 多态存在条件1.3 多态中调用成员的特点1.4 instanceof关键字 二、包三、权限修饰符四、final 关键字4.1 修饰类4.2 修饰方法4.3 修饰变量 五、代码块…...

49.Python-web框架-Django解决多语言redirect时把post改为get的问题
目录 1.背景 2.思路 3.寻找 Find and Replace 4.再次运行程序,POST来了 5.小结 1.背景 昨天在练习一个Django功能时,把form的method设置为POST,但是实际提交时,一直是GET方法。最后发现这是与多语言相关,django前面…...

【数据结构】【版本1.1】【线性时代】——单链表
快乐的流畅:个人主页 个人专栏:《算法神殿》《数据结构世界》《进击的C》 远方有一堆篝火,在为久候之人燃烧! 文章目录 引言一、顺序表的问题二、链表的概念三、单链表的模拟实现3.1 定义3.2 打印3.3 创建新节点3.4 头插3.5 尾插3…...
【计算机毕业设计】258基于微信小程序的课堂点名系统
🙊作者简介:拥有多年开发工作经验,分享技术代码帮助学生学习,独立完成自己的项目或者毕业设计。 代码可以私聊博主获取。🌹赠送计算机毕业设计600个选题excel文件,帮助大学选题。赠送开题报告模板ÿ…...

common.js和es6中模块引入的区别
common.js CommonJS 是一种模块系统,主要用于 Node.js 环境。它使用 require 函数来引入模块,并使用 module.exports 来导出模块。 语法: 导出模块: // moduleA.js const name Jo; module.exports name;// 或者导出一个对象…...

关于对pagination.js源代码进行修改且引入项目使用
实现效果 使用定时器对组件进行每秒请求,每过固定时间之后,进行下一页项目请求,进行到最后一页请求的时候返回第一页。 首先引入js插件 <script src"./js/pagination.js" type"text/javascript"></script>…...

《思考总结》
思考总结 ==标题==:卷积操作的作用1. **特征提取**2. **参数共享**3. **降维和数据压缩**4. **提升计算效率**5. **平滑和去噪**卷积操作示例输入图像卷积核卷积过程总结==标题==:上卷积什么是上卷积(反卷积/转置卷积)上卷积的作用上卷积的实现1. **最近邻插值(Nearest Ne…...
使用QT绘制简单的动态数据折线图
两个核心类时QChart和QLineSeries 下面这个示例代码中,定时器每隔一段时间将曲线图中的数据点向右移动 一个单位,同时调整横坐标轴的范围,实现了一次滚动对应移动一个数据点的效果。 QLineSeries最多容纳40961024个点 #include <QtWidg…...

Linux-centos7 nvm使用
NVM下载使用 文件夹创建拉取nvm包在~/.bashrc的末尾,添加如下语句验证nvm是否安装成功 文件夹创建 mkdir /root/home/software/拉取nvm包 cd /root/home/software/ wget https://github.com/nvm-sh/nvm/archive/refs/tags/v0.38.0.tar.gz tar xvzf v0.38.0.tar.g…...

【Linux】Linux环境基础开发工具_6
文章目录 四、Linux环境基础开发工具gdb 未完待续 四、Linux环境基础开发工具 gdb 我们已经可以写代码了,也能够执行代码了,但是代码错了该如何调试呢?Linux中可以使用 gdb 工具进行调试。 我们写一个简单的程序: 但是我们尝试…...

Redis宣布商用后,Redis国产化替代方案有那些?
一、背景 Redis作为使用最为广泛的开源缓存中间件,现已成为IT开发中必不可少的核心组件。官方修改协议印证了“开源”不意味着“无偿使用”,相关限制或将对基于开源Redis提供中间件产品的厂商,及提供Redis服务的云厂商产生一定影响。 二、国…...
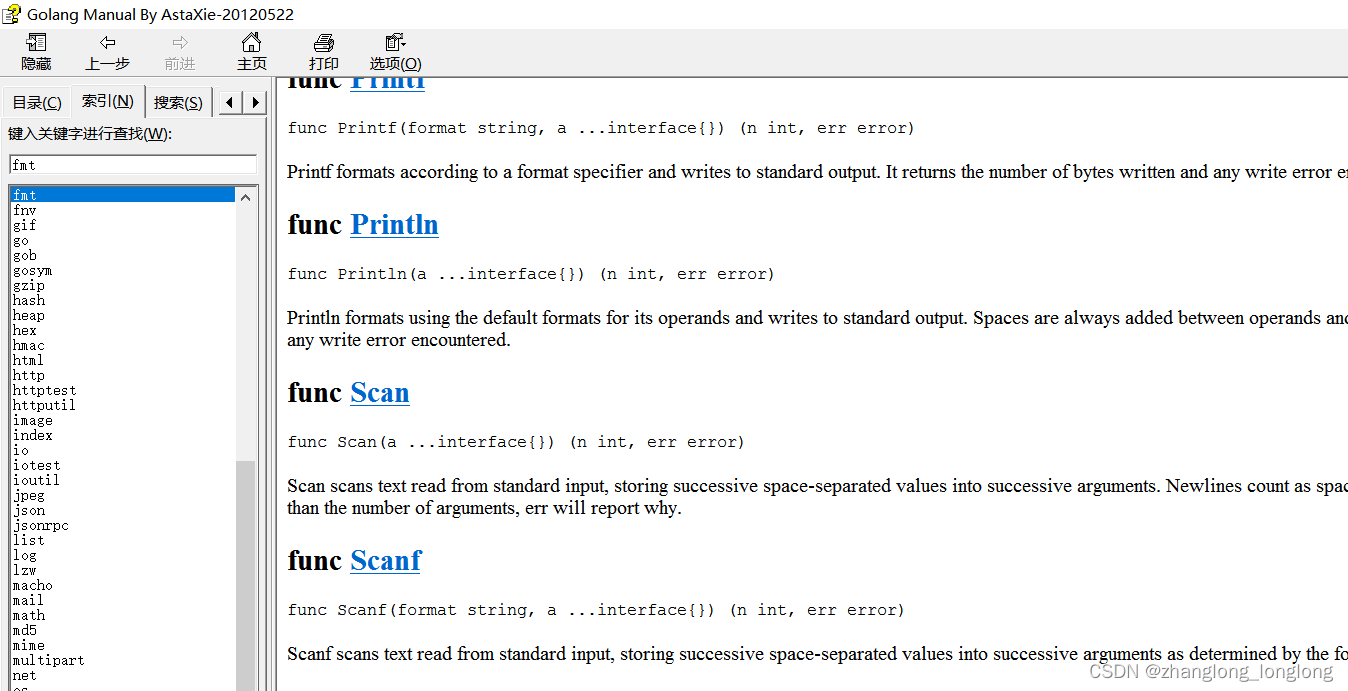
Go API
Go语言提供了大量的标准库,因此 google 公司也为这些标准库提供了相应的API文档,用于告诉开发者如何使用这些标准库,以及标准库包含的方法。官方位置:https://golang.org Golang中文网在线标准库文档: https://studygolang.com/p…...
基于STM32的简易智能家居设计(嘉立创支持)
一、项目功能概述 1、OLED显示温湿度、空气质量,并可以设置报警阈值 2、设置4个继电器开关,分别控制灯、空调、开关、风扇 3、设计一个离线语音识别系统,可以语音控制打开指定开关、并且可以显示识别命令词到OLED屏上 4、OLED实时显示&#…...
【YOLOv5/v7改进系列】改进池化层为RT-DETR的AIFI
一、导言 Real-Time DEtection TRansformer(RT-DETR),是一种实时端到端目标检测器,克服了Non-Maximum Suppression(NMS)对速度和准确性的影响。通过设计高效的混合编码器和不确定性最小化查询选择…...
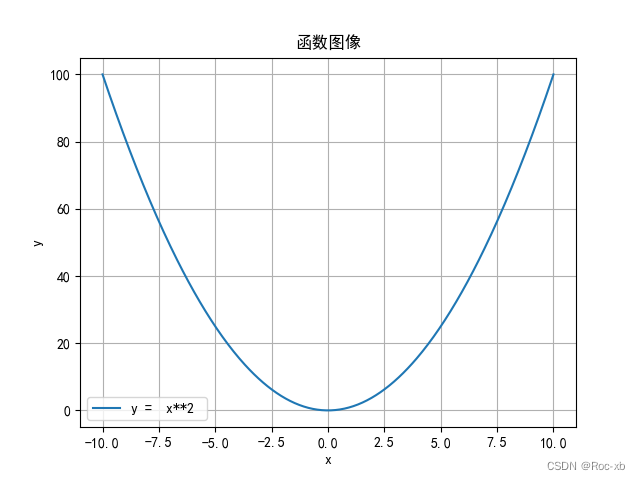
使用Python和Matplotlib绘制复杂数学函数图像
本文介绍了如何使用Python编程语言和Matplotlib库来绘制复杂的数学函数图像。通过引入NumPy库的数学函数,我们可以处理包括指数函数在内的各种复杂表达式。本文详细讲解了如何设置中文字体以确保在图像中正确显示中文标题和标签,并提供了一个完整的代码示例,用户可以通过输入…...
)
用仓颉语言搞定编译原理实验:从正则表达式到DFA的保姆级实现(附完整代码)
用仓颉语言实现编译原理实验:从正则表达式到DFA的实战指南 第一次接触编译原理实验时,看着那些晦涩的算法描述和数学符号,我完全不知道如何下手。直到用仓颉语言完整实现了从正则表达式到NFA再到DFA的转换过程,才真正理解了这些概…...

notepad-- Markdown实时预览功能高效使用全攻略
notepad-- Markdown实时预览功能高效使用全攻略 【免费下载链接】notepad-- 一个支持windows/linux/mac的文本编辑器,目标是做中国人自己的编辑器,来自中国。 项目地址: https://gitcode.com/GitHub_Trending/no/notepad-- 作为一款支持Windows、…...

ROS 2 手眼标定完整方案
我给你整理ROS 2 中最稳定、最常用、工业级可用的手眼眼标定包,包含安装、使用、命令、区别,直接照着用就行。 一、ROS 2 首选手眼标定包:easy_handeye2 github 地址:https://github.com/IFL-CAMP/easy_handeye2 这是 easy_hand…...

数据库课程设计智能指导:Phi-4-mini-reasoning辅助ER图设计与SQL优化
数据库课程设计智能指导:Phi-4-mini-reasoning辅助ER图设计与SQL优化 1. 课程设计的痛点与解决方案 每到学期中段,计算机专业的学生们都会面临一个共同挑战——数据库课程设计。从需求分析到ER图设计,再到SQL语句编写,每个环节都…...

3分钟掌握Playnite便携版:打造你的移动游戏库管理中心
3分钟掌握Playnite便携版:打造你的移动游戏库管理中心 【免费下载链接】Playnite Video game library manager with support for wide range of 3rd party libraries and game emulation support, providing one unified interface for your games. 项目地址: htt…...
)
STM32F103C8T6+TJA1042+UTA0403:手把手教你搭建CAN通讯测试环境(附完整接线图)
STM32F103C8T6TJA1042UTA0403:从零构建工业级CAN总线测试平台 第一次接触CAN总线的工程师往往会被物理层连接的各种细节困扰——为什么收发器需要独立供电?STB引脚悬空会导致什么后果?如何避免共模干扰?本文将用实验室级精度拆解S…...
)
YOLOv8鹰眼目标检测实战:一键部署,实时识别80种物体(附WebUI)
YOLOv8鹰眼目标检测实战:一键部署,实时识别80种物体(附WebUI) 1. 项目概述 1.1 什么是YOLOv8鹰眼目标检测 YOLOv8鹰眼目标检测是基于Ultralytics最新YOLOv8模型的工业级解决方案。它能够在毫秒级别完成图像中多达80类物体的识别…...

终极指南:DXVK如何彻底改变Linux游戏体验的5大关键优势
终极指南:DXVK如何彻底改变Linux游戏体验的5大关键优势 【免费下载链接】dxvk Vulkan-based implementation of D3D8, 9, 10 and 11 for Linux / Wine 项目地址: https://gitcode.com/gh_mirrors/dx/dxvk 在Linux上畅玩Windows独占3D游戏曾经是天方夜谭&…...

ncmdump:解决网易云音乐NCM格式限制的轻量级转换方案
ncmdump:解决网易云音乐NCM格式限制的轻量级转换方案 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 一、音乐自由的阻碍:NCM格式的隐形枷锁 🎵 你是否经历过这样的场景:精心收藏的网…...

小白也能懂:雪女-斗罗大陆-造相Z-Turbo文生图模型使用详解
小白也能懂:雪女-斗罗大陆-造相Z-Turbo文生图模型使用详解 1. 模型介绍 1.1 什么是雪女-斗罗大陆-造相Z-Turbo 雪女-斗罗大陆-造相Z-Turbo是一款专门用于生成《斗罗大陆》风格图片的AI模型,特别擅长创作与"雪女"角色相关的精美图像。这个模…...