SOFTS: 时间序列预测的最新模型以及Python使用示例
近年来,深度学习一直在时间序列预测中追赶着提升树模型,其中新的架构已经逐渐为最先进的性能设定了新的标准。
这一切都始于2020年的N-BEATS,然后是2022年的NHITS。2023年,PatchTST和TSMixer被提出,最近的iTransformer进一步提高了深度学习预测模型的性能。
这是2024年4月《SOFTS: Efficient Multivariate Time Series Forecasting with Series-Core Fusion》中提出的新模型,采用集中策略来学习不同序列之间的交互,从而在多变量预测任务中获得最先进的性能。
在本文中,我们详细探讨了SOFTS的体系结构,并介绍新的STar聚合调度(STAD)模块,该模块负责学习时间序列之间的交互。然后,我们测试将该模型应用于单变量和多变量预测场景,并与其他模型作为对比。
SOFTS介绍
SOFTS是 Series-cOre Fused Time Series的缩写,背后的动机来自于长期多元预测对决策至关重要的认识:
首先我们一直研究Transformer的模型,它们试图通过使用补丁嵌入和通道独立等技术(如PatchTST)来降低Transformer的复杂性。但是由于通道独立性,消除了每个序列之间的相互作用,因此可能会忽略预测信息。
iTransformer 通过嵌入整个序列部分地解决了这个问题,并通过注意机制处理它们。但是基于transformer的模型在计算上是复杂的,并且需要更多的时间来训练非常大的数据集。
另一方面有一些基于mlp的模型。这些模型通常很快,并产生非常强的结果,但当存在许多序列时,它们的性能往往会下降。
所以出现了SOFTS:研究人员建议使用基于mlp的STAD模块。由于是基于MLP的,所以训练速度很快。并且STAD模块,它允许学习每个序列之间的关系,就像注意力机制一样,但计算效率更高。
SOFTS架构
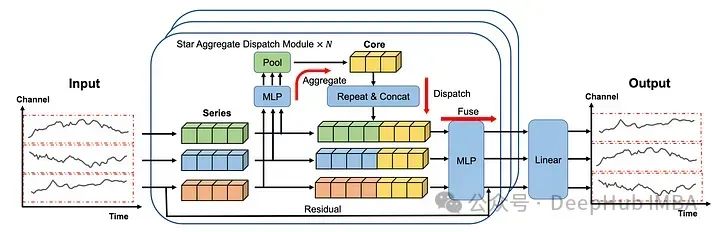
在上图中可以看到每个序列都是单独嵌入的,就像在iTransformer 中一样。
然后将嵌入发送到STAD模块。每个序列之间的交互都是集中学习的,然后再分配到各个系列并融合在一起。
最后再通过线性层产生预测。
这个体系结构中有很多东西需要分析,我们下面更详细地研究每个组件。
1、归一化与嵌入
首先使用归一化来校准输入序列的分布。使用了可逆实例的归一化(RevIn)。它将数据以单位方差的平均值为中心。然后每个系列分别进行嵌入,就像在iTransformer 模型。
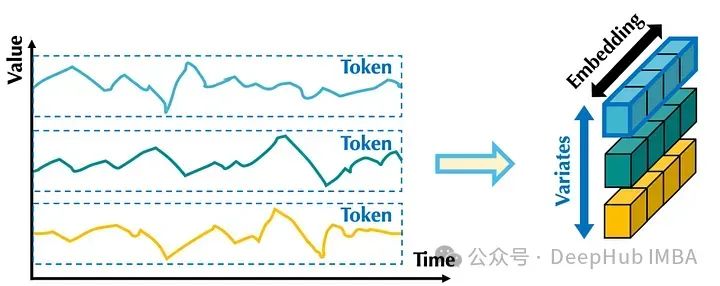
在上图中我们可以看到,嵌入整个序列就像应用补丁嵌入,其中补丁长度等于输入序列的长度。
这样,嵌入就包含了整个序列在所有时间步长的信息。
然后将嵌入式系列发送到STAD模块。
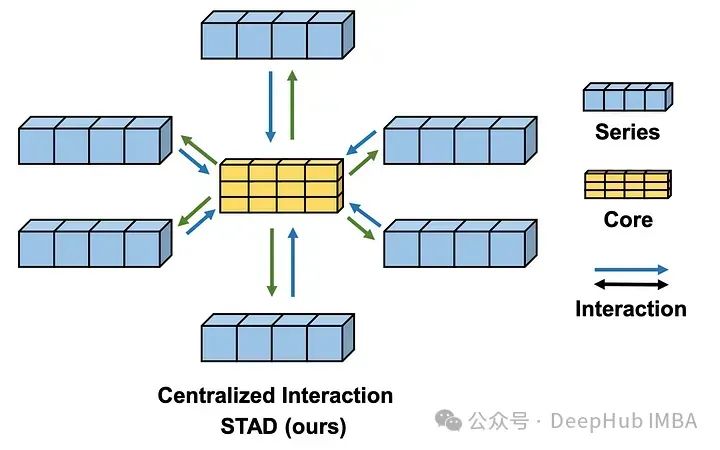
2、STar Aggregate-Dispatch (STAD)
STAD模块是soft模型与其他预测方法的真正区别。使用集中式策略来查找所有时间序列之间的相互作用。
嵌入的序列首先通过MLP和池化层,然后将这个学习到的表示连接起来形成核(上图中的黄色块表示)。
核构建好了以后就进入了“重复”和“连接”的步骤,在这个步骤中,核表示被分派给每个系列。
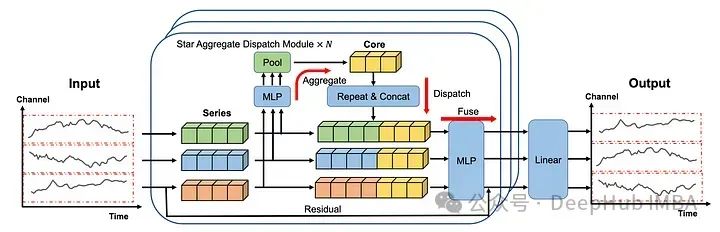
MLP和池化层未捕获的信息还可以通过残差连接添加到核表示中。然后在融合(fuse)操作的过程中,核表示及其对应系列的残差都通过MLP层发送。最后的线性层采用STAD模块的输出来生成每个序列的最终预测。
与其他捕获通道交互的方法(如注意力机制)相比,STAD模块的主要优点之一是它降低了复杂性。
因为STAD模块具有线性复杂度,而注意力机制具有二次复杂度,这意味着STAD在技术上可以更有效地处理具有多个序列的大型数据集。
下面我们来实际使用SOFTS进行单变量和多变量场景的测试。
使用SOFTS预测
这里,我们使用 Electricity Transformer dataset 数据集。
这个数据集跟踪了中国某省两个地区的变压器油温。每小时和每15分钟采样一个数据集,总共有四个数据集。
我门使用neuralforecast库中的SOFTS实现,这是官方认可的库,并且这样我们可以直接使用和测试不同预测模型的进行对比。
在撰写本文时,SOFTS还没有集成在的neuralforecast版本中,所以我们需要使用源代码进行安装。
pip install git+https://github.com/Nixtla/neuralforecast.git
然后就是从导入包开始。使用datasetsforecast以所需格式加载数据集,以便使用neuralforecast训练模型,并使用utilsforecast评估模型的性能。这就是我们使用neuralforecast的原因,因为他都是一套的
import pandas as pdimport numpy as npimport matplotlib.pyplot as pltfrom datasetsforecast.long_horizon import LongHorizonfrom neuralforecast.core import NeuralForecastfrom neuralforecast.losses.pytorch import MAE, MSEfrom neuralforecast.models import SOFTS, PatchTST, TSMixer, iTransformerfrom utilsforecast.losses import mae, msefrom utilsforecast.evaluation import evaluate
编写一个函数来帮助加载数据集,以及它们的标准测试大小、验证大小和频率。
def load_data(name):if name == "ettm1":Y_df, *_ = LongHorizon.load(directory='./', group='ETTm1')Y_df = Y_df[Y_df['unique_id'] == 'OT'] # univariate datasetY_df['ds'] = pd.to_datetime(Y_df['ds'])val_size = 11520test_size = 11520freq = '15T'elif name == "ettm2":Y_df, *_ = LongHorizon.load(directory='./', group='ETTm2')Y_df['ds'] = pd.to_datetime(Y_df['ds']) val_size = 11520test_size = 11520freq = '15T'return Y_df, val_size, test_size, freq
然后就可以对ETTm1数据集进行单变量预测。
1、单变量预测
加载ETTm1数据集,将预测范围设置为96个时间步长。
可以测试更多的预测长度,但我们这里只使用96。
Y_df, val_size, test_size, freq = load_data('ettm1')horizon = 96
然后初始化不同的模型,我们将soft与TSMixer, iTransformer和PatchTST进行比较。
所有模型都使用的默认配置将最大训练步数设置为1000,如果三次后验证损失没有改善,则停止训练。
models = [SOFTS(h=horizon, input_size=3*horizon, n_series=1, max_steps=1000, early_stop_patience_steps=3),TSMixer(h=horizon, input_size=3*horizon, n_series=1, max_steps=1000, early_stop_patience_steps=3),iTransformer(h=horizon, input_size=3*horizon, n_series=1, max_steps=1000, early_stop_patience_steps=3),PatchTST(h=horizon, input_size=3*horizon, max_steps=1000, early_stop_patience_steps=3)]
然后初始化NeuralForecast对象训练模型。并使用交叉验证来获得多个预测窗口,更好地评估每个模型的性能。
nf = NeuralForecast(models=models, freq=freq)nf_preds = nf.cross_validation(df=Y_df, val_size=val_size, test_size=test_size, n_windows=None)nf_preds = nf_preds.reset_index()
评估计算了每个模型的平均绝对误差(MAE)和均方误差(MSE)。因为之前的数据是缩放的,因此报告的指标也是缩放的。
ettm1_evaluation = evaluate(df=nf_preds, metrics=[mae, mse], models=['SOFTS', 'TSMixer', 'iTransformer', 'PatchTST'])
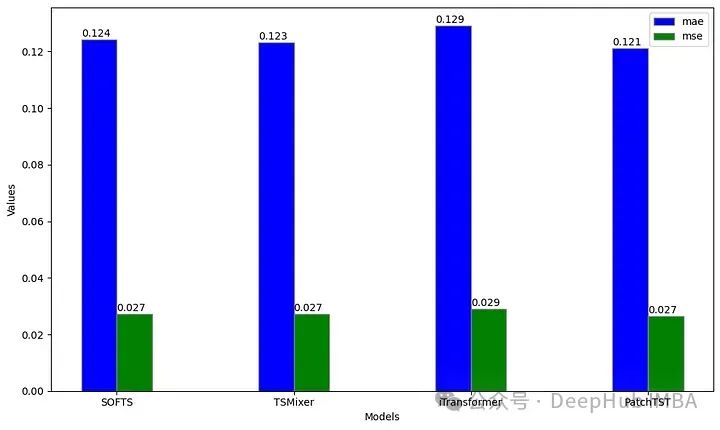
从上图可以看出,PatchTST的MAE最低,而softts、TSMixer和PatchTST的MSE是一样的。在这种特殊情况下,PatchTST仍然是总体上最好的模型。
这并不奇怪,因为PatchTST在这个数据集中是出了名的好,特别是对于单变量任务。下面我们开始测试多变量场景。
2、多变量预测
使用相同的load_data函数,我们现在为这个多变量场景使用ETTm2数据集。
Y_df, val_size, test_size, freq = load_data('ettm2')horizon = 96
然后简单地初始化每个模型。我们只使用多变量模型来学习序列之间的相互作用,所以不会使用PatchTST,因为它应用通道独立性(意味着每个序列被单独处理)。
然后保留了与单变量场景中相同的超参数。只将n_series更改为7,因为有7个时间序列相互作用。
models = [SOFTS(h=horizon, input_size=3*horizon, n_series=7, max_steps=1000, early_stop_patience_steps=3, scaler_type='identity', valid_loss=MAE()),TSMixer(h=horizon, input_size=3*horizon, n_series=7, max_steps=1000, early_stop_patience_steps=3, scaler_type='identity', valid_loss=MAE()),iTransformer(h=horizon, input_size=3*horizon, n_series=7, max_steps=1000, early_stop_patience_steps=3, scaler_type='identity', valid_loss=MAE())]
训练所有的模型并进行预测。
nf = NeuralForecast(models=models, freq='15min')nf_preds = nf.cross_validation(df=Y_df, val_size=val_size, test_size=test_size, n_windows=None)nf_preds = nf_preds.reset_index()
最后使用MAE和MSE来评估每个模型的性能。
ettm2_evaluation = evaluate(df=nf_preds, metrics=[mae, mse], models=['SOFTS', 'TSMixer', 'iTransformer'])

上图中可以看到到当在96的水平上预测时,TSMixer large在ETTm2数据集上的表现优于iTransformer和soft。
虽然这与soft论文的结果相矛盾,这是因为我们没有进行超参数优化,并且使用了96个时间步长的固定范围。
这个实验的结果可能不太令人印象深刻,我们只在固定预测范围的单个数据集上进行了测试,所以这不是SOFTS性能的稳健基准,同时也说明了SOFTS在使用时可能需要更多的时间来进行超参数的优化。
总结
SOFTS是一个很有前途的基于mlp的多元预测模型,STAD模块是一种集中式方法,用于学习时间序列之间的相互作用,其计算强度低于注意力机制。这使得模型能够有效地处理具有许多并发时间序列的大型数据集。
虽然在我们的实验中,SOFTS的性能可能看起来有点平淡无奇,但请记住,这并不代表其性能的稳健基准,因为我们只在固定视界的单个数据集上进行了测试。
但是SOFTS的思路还是非常好的,比如使用集中式学习时间序列之间的相互作用,并且使用低强度的计算来保证数据计算的效率,这都是值得我们学习的地方。
并且每个问题都需要其独特的解决方案,所以将SOFTS作为特定场景的一个测试选项是一个明智的选择。
SOFTS: Efficient Multivariate Time Series Forecasting with Series-Core Fusion
https://avoid.overfit.cn/post/6254097fd18d479ba7fd85efcc49abac
相关文章:
SOFTS: 时间序列预测的最新模型以及Python使用示例
近年来,深度学习一直在时间序列预测中追赶着提升树模型,其中新的架构已经逐渐为最先进的性能设定了新的标准。 这一切都始于2020年的N-BEATS,然后是2022年的NHITS。2023年,PatchTST和TSMixer被提出,最近的iTransforme…...

C++ 取近似值
描述 写出一个程序,接受一个正浮点数值,输出该数值的近似整数值。如果小数点后数值大于等于 0.5 ,向上取整;小于 0.5 ,则向下取整。 数据范围:保证输入的数字在 32 位浮点数范围内 输入描述: 输入一个正…...

云原生系列之Docker常用命令
🌹作者主页:青花锁 🌹简介:Java领域优质创作者🏆、Java微服务架构公号作者😄 🌹简历模板、学习资料、面试题库、技术互助 🌹文末获取联系方式 📝 系列文章目录 云原生之…...
opencv_GUI
图像入门 import numpy as np import cv2 as cv # 用灰度模式加载图像 img cv.imread(C:/Users/HP/Downloads/basketball.png, 0)# 即使图像路径错误,它也不会抛出任何错误,但是打印 img会给你Nonecv.imshow(image, img) cv.waitKey(5000) # 一个键盘绑…...

FlowUs轻量化AI:趁这波升级专业版,全年无限AI助力笔记产出与二次编写
在数字时代,信息管理与知识产出的效率直接影响个人的生产力。FlowUs作为一款集笔记、文档、多维表、文件夹于一体的新一代知识管理平台,其轻量化AI的加入更是如虎添翼。特别是在活动期间,升级专业版将带来全年无限AI使用次数,让每…...

Day 22:2786. 访问数组中的位置使分数最大
Leetcode 2786. 访问数组中的位置使分数最大 给你一个下标从 0 开始的整数数组 nums 和一个正整数 x 。 你 一开始 在数组的位置 0 处,你可以按照下述规则访问数组中的其他位置: 如果你当前在位置 i ,那么你可以移动到满足 i < j 的 任意 …...

理解Es的DSL语法(二):聚合
前一篇已经系统介绍过查询语法,详细可直接看上一篇文章(理解DSL语法(一)),本篇主要介绍DSL中的另一部分:聚合 理解Es中的聚合 虽然Elasticsearch 是一个基于 Lucene 的搜索引擎,但…...
matlab-2-simulink-小白教程-如何绘制电路图进行电路仿真
以上述电路图为例:包含D触发器,时钟CLK,与非门 一、启动simulink的三种方式 方式1 在MATLAB的命令行窗口输入“Simulink”命令。 方式2 在MATLAB主窗口的“主页”选项卡中,单击“SIMULINK”命令组中的Simulink命令按钮。 方式3 从MATLAB…...

CSS从入门到精通——背景样式
目录 背景颜色 任务描述 相关知识 背景色 编程要求 背景图片 任务描述 相关知识 背景图片 设置背景图片 平铺背景图像 任务要求 背景定位与背景关联 任务描述 相关知识 背景定位 背景关联 简写背景 编程要求 背景颜色 任务描述 本关任务:在本关…...
网络编程---Java飞机大战联机
解析服务器端代码 代码是放在app/lib下的src下的main/java,而与之前放在app/src/main下路径不同 Main函数 Main函数里只放着创建MyServer类的一行 public static void main(String args[]){new MyServer();} MyServer构造函数 1.获取本机IP地址 //获取本机IP地…...

一个简单的Oracle函数
CREATE OR REPLACE FUNCTION getyj_zhibiao_value(p_name IN varchar2, p_index IN varchar2) RETURN NUMBER IS -- 定义返回的指标值变量 v_result NUMBER; -- 定义临时变量来存储查询到的指标值 v_index1 VARCHAR2(50); v_index2 VARCHAR2(50); …...
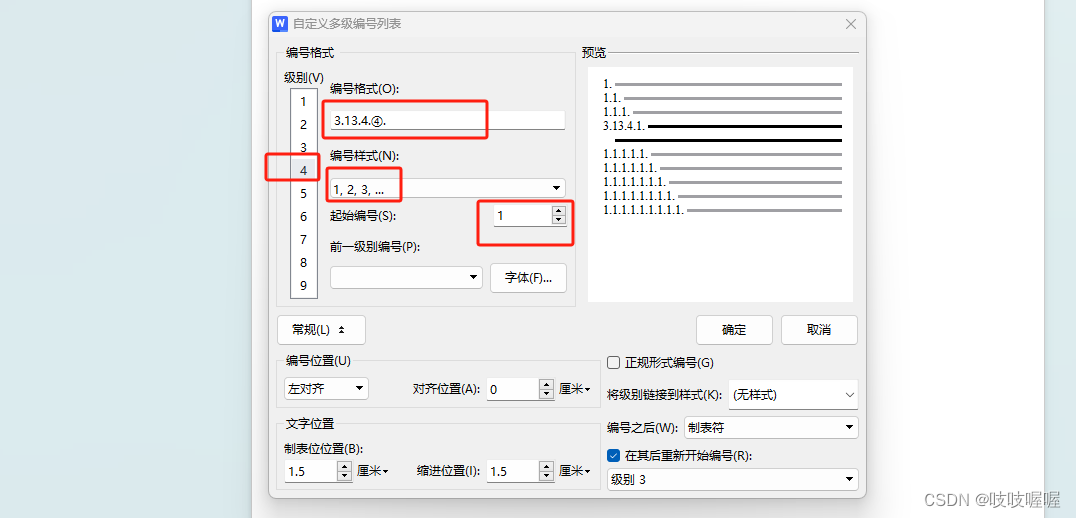
word中根据上级设置下级编号
如上级是3.13.4,如下图 现在想设置下级编码跟随上级逐级显示成3.13.4.1 则在标题功能说明这点击顶部菜单栏的编号按钮,如下图 然后,选择自定义编号-自定义列表-自定义按钮 然后重点是编号格式这一栏,需要手动填写下前三级的编号&…...

【康复学习--LeetCode每日一题】2786. 访问数组中的位置使分数最大
题目描述: 给你一个下标从 0 开始的整数数组 nums 和一个正整数 x 。 你一开始 在数组的位置 0 处,你可以按照下述规则访问数组中的其他位置: 如果你当前在位置 i ,那么你可以移动到满足 i < j 的 任意 位置 j 。 对于你访问的…...

bash和sh区别
bash 和 sh 是两种常用的 Unix Shell,它们有一些区别,特别是在功能和兼容性方面。以下是一些主要的区别: 1. **历史与实现**: - sh(Bourne Shell)是第一个 Unix Shell,最初由 Stephen Bourn…...
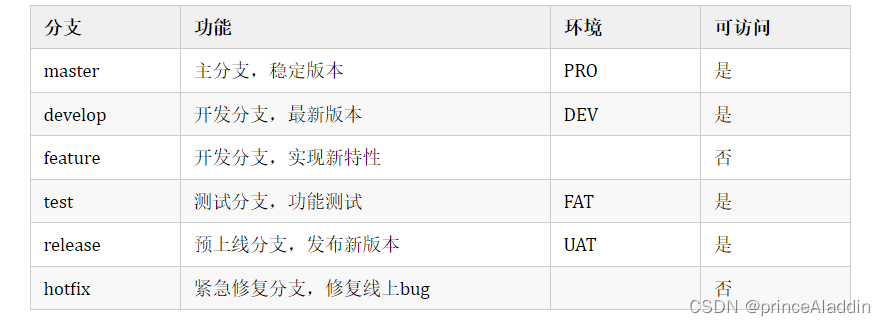
Git 代码管理规范 !
分支命名 master 分支 master 为主分支,也是用于部署生产环境的分支,需要确保master分支稳定性。master 分支一般由 release 以及 hotfix 分支合并,任何时间都不能直接修改代码。 develop 分支 develop 为开发环境分支,始终保持最…...

MGRS坐标
一 概述 MGRS坐标系统,即军事格网参考系统,是北约(NATO)军事组织使用的标准坐标系统。它基于UTM(通用横向墨卡托)系统,并将每个UTM区域进一步划分为100km100km的小方块。这些方块通过两个相连的字母标识,其…...

FreeRTOS简单内核实现4 临界段
文章目录 0、思考与回答0.1、思考一0.2、思考二0.3、思考三 1、关中断1.1、带返回值1.2、不带返回值 2、开中断3、临界段4、应用 0、思考与回答 0.1、思考一 为什么需要临界段? 有时候我们需要部分代码一旦这开始执行,则不允许任何中断打断࿰…...

Scala的字符串插值
Scala的字符串插值 期待您的关注 ☀Scala学习笔记 目录 Scala的字符串插值 1. s插值器: 2. f插值器: 3. raw插值器: 在Scala中,字符串插值是一种方便的方式,可以在字符串中插入变量或表达式的值。Scala支持三种类型…...
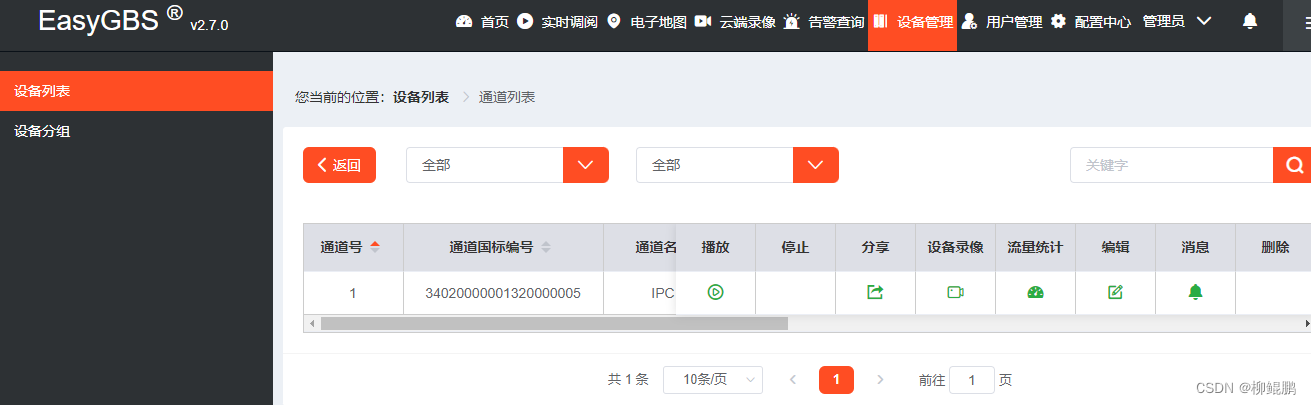
EasyGBS服务器和终端配置
服务器配置 修改easygbs.ini sip/host为本机IP,否则终端能登录,无法视频。 [sip] host192.168.3.190 终端用于登录的用户名和密码 default_usertest default_passwordtest1234 default_guest_userguest default_guest_passwordtest1234终端配置 关…...

git配置2-不同的代码托管平台配置不同的ssh key
1. 配置单个ssh key 1.1. 原理1.2. 生成 ssh key1.3. 代码托管平台配置公钥 2. 配置多个ssh key 2.1. 应用场景2.2. 生成两个不同的key2.3. 修改config文件2.4. 配置代码托管平台2.5. 测试是否成功 1. 配置单个ssh key 1.1. 原理 使用ssh命令行工具(git安装成功…...

安卓位置伪装的终极指南:3步掌握应用级虚拟定位
安卓位置伪装的终极指南:3步掌握应用级虚拟定位 【免费下载链接】FakeLocation Xposed module to mock locations per app. 项目地址: https://gitcode.com/gh_mirrors/fak/FakeLocation 你是否曾因社交软件暴露真实位置而感到不安?是否需要在不同…...

【Midjourney提示词黄金公式】:20年AI视觉专家亲授7大风格锚点+3层语义嵌套技巧
更多请点击: https://intelliparadigm.com 第一章:Midjourney提示词黄金公式的底层逻辑 Midjourney 的提示词(Prompt)并非自由文本堆砌,而是一套具有语法优先级与语义权重的结构化指令系统。其“黄金公式”——主体 …...

在VSCode+GCC+STM32环境中实现非阻塞式串口调试:中断驱动的printf重定向实践
1. 为什么需要非阻塞式串口调试 在嵌入式开发中,串口调试就像是我们和硬件对话的"嘴巴"和"耳朵"。想象一下,当你和朋友聊天时,如果每次说话都要等对方完全听完才能做其他事情,那该有多难受?传统的…...

cliclick 开发者指南:从源码编译到自定义Action开发
cliclick 开发者指南:从源码编译到自定义Action开发 【免费下载链接】cliclick macOS CLI tool for emulating mouse and keyboard events 项目地址: https://gitcode.com/gh_mirrors/cl/cliclick cliclick 是一款强大的 macOS 命令行工具,用于模…...

基于LLM的AI新闻智能体:自动化信息采集与周报生成实战
1. 项目概述:一个能自动追踪AI新闻的智能体 最近在GitHub上看到一个挺有意思的项目,叫 ai-news-weekly-agent 。光看名字,你大概能猜到它是个和AI新闻相关的自动化工具。没错,它的核心目标就是扮演一个“AI新闻周刊编辑”的角色…...

为什么你的v8出图突然“高级感崩塌”?3分钟定位色彩语义锚点失效+实时修复模板
更多请点击: https://intelliparadigm.com 第一章:为什么你的v8出图突然“高级感崩塌”? V8 引擎本身并不直接“出图”——这一表述实为开发者对前端渲染链路中某环节异常的戏谑指代。真正崩塌的,往往是基于 V8 驱动的 Canvas/We…...

WindowsCleaner完整解析:如何用开源工具彻底解决Windows系统卡顿和C盘爆红问题
WindowsCleaner完整解析:如何用开源工具彻底解决Windows系统卡顿和C盘爆红问题 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner 你是否曾经在关键时刻被…...

IoTDB与TimechoDB深度解析
全球物联网设备将在2025年突破416亿台,每天产生79.4ZB的数据,相当于8000多万个1TB硬盘才能装下。面对这场数据海啸,传统数据库纷纷“侧漏”,时序数据库成为企业数字化升级的“救生艇”。 本文将从五大核心维度,系统剖…...

面试时被问“你的缺点是什么”,这样回答反而加分
面试中,当面试官看似随意地问出“你的缺点是什么”时,空气往往会突然安静几秒。对软件测试工程师而言,这个问题尤其微妙——我们每天都在和“找茬”打交道,对缺陷和风险有着本能的敏感。然而,面试官抛出这个问题&#…...

《魔兽世界》怀旧服:纳克萨玛斯教官拉苏维奥斯战术详解与实战心得
1. 教官拉苏维奥斯战斗机制解析 教官拉苏维奥斯作为纳克萨玛斯军事区的守门BOSS,其战斗核心在于学员控制循环与仇恨管理的双重考验。这个BOSS战最特别的地方在于,你需要同时应对教官本体的高伤害和四名学员的协同作战。很多团队第一次开荒时容易忽略学员…...