MYSQL 索引下推 45讲
刘老师群里,看到一位小友 问<MYSQL 45讲>林晓斌的回答
大意是一个组合索引 (a,b,c) 条件 a > 5 and a <10 and b='123', 这样的情况下是如何?
林老师给的回答是 A>5 ,然后下推B='123'
小友 问 "为什么不是先 进行范围查询,然后在索引下推 b='123'?"
然后就没有然后了....
说真的,不是我有意踩林老师, 我只是说<MYSQL 45 讲>吃个半饱, 大脑半醒半睡,好比晚上2点睡,早上被8点闹钟催醒. 上午在公司里梦游状态样.
极客这种课程,视乎给人感觉不全面,不细致.相对于等同价格的书来说,性价比太低了.
以前买了一本ORACLE ACE写的一本MYSQL入门的书.书中把BINLOG CACHE 归类于共享内存.
高鹏(八怪)说BINLOG CAHCE是线程的内存.
ACE 看来就是个荣誉技术编辑&总编.
MYSQL 产生大量数据的过程
我们做个实验,用上面链接的表和数据!
添加个组合索引
KEY `idx_age_income_education` (`age`,`income_year`,`top_education`)我们还是先讲下索引下推是什么鬼?
在很早很早以前 MYSQL 分为一阴一阳两面. SERVER层负责阳的一面,引擎层负责阴的一面.
在这里我们记住一点就是服务层server负责过虑结果集, 只要执行计划有WHERE字眼,说明服务层执行了过滤操作, 另外ROW+FILER % 也可以窥爱一下.
引擎层返回服务层要的数据! 一个SQL有多个WHERE 条件,我们看哪个条件能命中引擎层的二级索引. 我们就把这个条件传给引擎层.引擎层通过这个条件筛选数据,然后返回,服务层再用剩余的条件,进一步筛选过滤(FILTER)记录,积累到NET_BUF满后就发生给客户.
引擎层一般会预读,大约是100条件记录,然后一条,一条给服务层,服务层判断一条记录,再问引擎要一条.
上面一般过程,不必牢记! 重点是 为什么不把服务层过滤条件,全拿到引擎层做呢? 其实都是内存操作,在引擎层还是服务层差距不大.
那为什么要ICP呢? 所以重点是索引, 是服务层把更多的条件,下推到索引上.是引擎上的二级索引.
通过索引过滤掉更多不符合条件的记录. 这样减少去读聚集索引!
一般二级索引都被内存缓存,聚集索引相对较大,不易缓存在内存里.读聚集索引可能要发生IO操作. 能通过ICP优化,能更多减少不必要的IO操作!
MYSQL 专业叫法是 读聚集索引, ORACLE 叫法是 回表! 回表和读聚集索引功能是类似的, 回表操作是直接从索引获得物理ID,直接定位到表具体行.而MYSQL读二级索引获得逻辑ID,还要通过主键聚集索引,根节点,分支节点,再到页节点,多了两次IO操作. 每个逻辑ID都要多两次IO操作. 比回表多了很多次IO操作.再说MYSQL是16K一个页,ORACLE是8K一个页. 优化思路是一样的,实现细节是有区别的. 算法一样,数据结构不一样. 作为MYSQL DBA. 如果还有OCP,COM,ACE头衔,自然不能说"回表",太LOW!
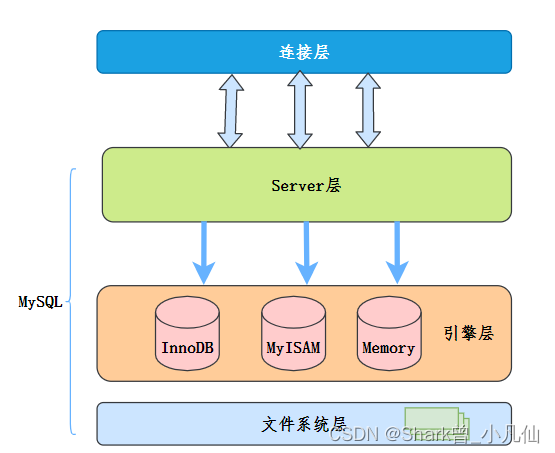
MySQL服务层负责SQL语法解析、生成执行计划等,并调用存储引擎层去执行数据的存储和检索。
索引下推的下推其实就是指将部分上层(服务层)负责的事情,交给了下层(引擎层)去处理。
我们来具体看一下,在没有使用ICP的情况下,MySQL的查询:
-
存储引擎读取索引记录;
-
根据索引中的主键值,定位并读取完整的行记录;
-
存储引擎把记录交给
Server层去检测该记录是否满足WHERE条件。
使用ICP的情况下,查询过程:
-
存储引擎读取索引记录(不是完整的行记录);
-
判断
WHERE条件部分能否用索引中的列来做检查,条件不满足,则处理下一行索引记录; -
条件满足,使用索引中的主键去定位并读取完整的行记录(就是所谓的回表);
-
存储引擎把记录交给
Server层,Server层检测该记录是否满足WHERE条件的其余部分。
我们还可以看一下执行计划,
看到Extra一列里Using index condition,这就是用到了索引下推。
-
只能用于
range、ref、eq_ref、ref_or_null访问方法; -
只能用于
InnoDB和MyISAM存储引擎及其分区表; -
对
InnoDB存储引擎来说,索引下推只适用于二级索引(也叫辅助索引);
我们使用下面SQL 看下执行计划 根据上面说只要EXTAR using index condition 使用索引条件 这英文取得让人误会. 为啥不多加个单词"using index pushdown condition "
select * from dba_test.personal_identity_info where age > 35 and income_year > 10000 and income_year < 20000 and top_education='大学' ;
-- NO ICP key_len=10 rows=75 filtered=8.28 Extra=Using where select * from dba_test.personal_identity_info where age >= 35 and age <= 65;
-- ICP key_len=1 rows=206 filtered=100 Extra=Using index condition select * from dba_test.personal_identity_info where age > 35 and age < 65;
-- ICP key_len=1 rows=196 filtered=100 Extra=Using index condition select * from dba_test.personal_identity_info where age > 35 and age < 65 and top_education='大学';
-- NO ICP key_len=10 rows=75 filtered=19.6 Extra=Using where select * from dba_test.personal_identity_info where age > 35 and age < 65 and income_year > 10000 ;
-- ICP key_len=1 rows=196 filtered=33.33 Extra=Using index conditionselect * from dba_test.personal_identity_info where age >= 35 and age <= 65 and income_year > 10000;
-- ICP key_len=6 rows=206 filtered=33.33 Extra=Using index conditionselect * from dba_test.personal_identity_info where age = 35 and income_year > 10000 and income_year < 20000 and top_education='大学' ;
-- ICP key_len=6 rows=1 filtered=7.50 Extra=Using index conditionselect * from dba_test.personal_identity_info where income_year > 10000 and income_year < 20000 and top_education='大学' ;-- NO ICP key_len=10 rows=75 filtered=11.11 Extra=Using where从上面八种情况,或许可以推导出,只要WHERE条件命中了组合索引第一个字段.
它一定会走索引! 其它条件命中组合索引其它字段,也能走索引.
ICP条件1:WHERE条件命中索引第一个字段.
ICP条件2:WHERE其它条件能命中组合索引其它字段,不过不能有等值查询
select * from dba_test.personal_identity_info where age >= 35 and age <= 65 and top_education='大学';
-- NO ICP key_len=10 rows=75 filtered=20.60 Extra=Using where select * from dba_test.personal_identity_info where age between 35 and 65 and top_education='大学';
-- NO ICP key_len=10 rows=75 filtered=20.60 Extra=Using where另外两个情况下,还是其它WHERE条件命中组合索引且等值 ICP就失效 我的MYSQL 是 8.0.24. 索引下推是开启的
select @@optimizer_switch;
/*
index_merge=on,index_merge_union=on,index_merge_sort_union=on,
index_merge_intersection=on,engine_condition_pushdown=on,
index_condition_pushdown=on,mrr=on,
mrr_cost_based=on,block_nested_loop=on,batched_key_access=off,
materialization=on,semijoin=on,
loosescan=on,firstmatch=on,duplicateweedout=on,
subquery_materialization_cost_based=on,
use_index_extensions=on,condition_fanout_filter=on,derived_merge=on,
use_invisible_indexes=off,skip_scan=on,hash_join=on,
subquery_to_derived=off,prefer_ordering_index=on,
hypergraph_optimizer=off,derived_condition_pushdown=on
*/set optimizer_switch="index_condition_pushdown=off";
set optimizer_switch="index_condition_pushdown=on";我们还可以explain format=tree 看的更清楚
explain FORMAT=tree select * from dba_test.personal_identity_info where age > 35 and age < 65 and top_education='大学' and income_year > 10000;
/*
-> Filter: ((personal_identity_info.age > 35) and (personal_identity_info.age < 65) and (personal_identity_info.income_year > 10000)) (cost=7.24 rows=5)-> Index lookup on personal_identity_info using idx_personal_identity_info_top_education (top_education='大学') (cost=7.24 rows=75)
*/ explain FORMAT=tree select * from dba_test.personal_identity_info where age >= 35 and age <= 65 and top_education='大学' and income_year > 10000;
/*
-> Filter: ((personal_identity_info.age >= 35) and (personal_identity_info.age <= 65) and (personal_identity_info.income_year > 10000)) (cost=7.26 rows=5)-> Index lookup on personal_identity_info using idx_personal_identity_info_top_education (top_education='大学') (cost=7.26 rows=75)
*/explain FORMAT=tree select * from dba_test.personal_identity_info where age > 35 and income_year > 10000 and income_year < 20000 and top_education='大学' ;
/*
-> Filter: ((personal_identity_info.age > 35) and (personal_identity_info.income_year > 10000) and (personal_identity_info.income_year < 20000)) (cost=7.37 rows=6)-> Index lookup on personal_identity_info using idx_personal_identity_info_top_education (top_education='大学') (cost=7.37 rows=75)
*/explain FORMAT=tree select * from dba_test.personal_identity_info where age = 35 and income_year > 10000 and income_year < 20000 and top_education='大学' ;
/*
-> Index range scan on personal_identity_info using idx_age_income_education, with index condition: ((personal_identity_info.age = 35) and (personal_identity_info.income_year > 10000) and (personal_identity_info.income_year < 20000) and (personal_identity_info.top_education = '大学')) (cost=0.71 rows=1)
*/explain FORMAT=tree select * from dba_test.personal_identity_info where age > 35 and age < 65;
/*
-> Index range scan on personal_identity_info using idx_age_income_education, with index condition: ((personal_identity_info.age > 35) and (personal_identity_info.age < 65)) (cost=88.46 rows=196)
*/
explain FORMAT=tree select * from dba_test.personal_identity_info where age = 35 and income_year > 10000 ;
/*
-> Index range scan on personal_identity_info using idx_age_income_education, with index condition: ((personal_identity_info.age = 35) and (personal_identity_info.income_year > 10000)) (cost=3.86 rows=8)
*/前三个没有下推,后三个下推了,从中可推导出,ICP可以推进多个条件.
另外 推导出
ICP条件3:WHER条件命中组合索引第一个字段且是等值也生效.
看起来条件2和条件3有点冲突,其实不冲突!
一般来说,命中索引的只有一个WHER条件.
这个经验来自ORACLE,MYSQL通过EXPLAIN FORMAT=TREE是看不出来的.
这样只能跟踪源码才可知,跟踪源码是件很累的事情,成本高收益低!
以上胡说八道
此刘老师,不是那个刘老师! 那个刘老师太那个了,200号人捐款4.2万.
说是他自己用个脚本换来的,然后捐给武汉.自己独占了荣誉.
也没感谢大家捐款,也没在公号列出感谢名单.培训也就是培训脚本
如何使用! 说白了就是PPT宣传你的脚本有多么多么厉害.
online脚本套用ORACLE官方脚本SQLHC.
好像 搞得大家200号人 没有良心没有善心,就冲着你的牛X脚本来的?
还搞个PDF污蔑我. 只能忽悠没有脑子的小年轻!
脚本有鸟用,谁敢把来历不明的脚本,用在生产环境中?
8千行再套用个SQLHC,我没有精力去分析代码,
早就扔在上上家公司的办公电脑里!
相关文章:
MYSQL 索引下推 45讲
刘老师群里,看到一位小友 问<MYSQL 45讲>林晓斌的回答 大意是一个组合索引 (a,b,c) 条件 a > 5 and a <10 and b123, 这样的情况下是如何? 林老师给的回答是 A>5 ,然后下推B123 小友 问 "为什么不是先 进行范围查询,然后在索引下推 b123?" 然后就…...

CentOS7服务器中安装openCV4.8的教程
参考链接:Centos7环境下cmake3.25的编译与安装 参考链接:Linux安装或者升级cmake,例子为v3.10.2升级到v3.25.0(自己指定版本) 参考链接:Linux安装Opencv(C) 一、下载资源 1.下载cmake3.25.0的压缩包&am…...
Java课程设计:基于swing的贪吃蛇小游戏
文章目录 一、项目介绍二、核心代码三、项目展示四、源码获取 一、项目介绍 贪吃蛇是一款经典的休闲益智游戏,自问世以来便深受广大用户的喜爱。这个游戏的基本玩法是控制一条不断增长的蛇,目标是吃掉屏幕上出现的食物,同时避免撞到边缘或自身。随着游戏的进行,蛇的身体会越长…...

【HarmonyOS】HUAWEI DevEco Studio 下载地址汇总
目录 OpenHarmony 4.x Releases 4.1 Release4.0 Release OpenHarmony 3.x Releases 3.2.1 Release3.2 Release3.1.3 Release3.1.2 Release3.1.1 Release3.1 Release 说明 Full SDK:面向OEM厂商提供,包含了需要使用系统权限的系统接口。 Public SDK&am…...
)
华为OD刷题C卷 - 每日刷题30(小明找位置,分隔均衡字符串)
1、(小明找位置): 这段代码是解决“小明找位置”的问题。它提供了一个Java类Main,其中包含main方法和getResult方法,用于帮助小明快速找到他在排队中应该站的位置。 main方法首先读取已排列好的小朋友的学号数组和小…...

SOFTS: 时间序列预测的最新模型以及Python使用示例
近年来,深度学习一直在时间序列预测中追赶着提升树模型,其中新的架构已经逐渐为最先进的性能设定了新的标准。 这一切都始于2020年的N-BEATS,然后是2022年的NHITS。2023年,PatchTST和TSMixer被提出,最近的iTransforme…...

C++ 取近似值
描述 写出一个程序,接受一个正浮点数值,输出该数值的近似整数值。如果小数点后数值大于等于 0.5 ,向上取整;小于 0.5 ,则向下取整。 数据范围:保证输入的数字在 32 位浮点数范围内 输入描述: 输入一个正…...

云原生系列之Docker常用命令
🌹作者主页:青花锁 🌹简介:Java领域优质创作者🏆、Java微服务架构公号作者😄 🌹简历模板、学习资料、面试题库、技术互助 🌹文末获取联系方式 📝 系列文章目录 云原生之…...
opencv_GUI
图像入门 import numpy as np import cv2 as cv # 用灰度模式加载图像 img cv.imread(C:/Users/HP/Downloads/basketball.png, 0)# 即使图像路径错误,它也不会抛出任何错误,但是打印 img会给你Nonecv.imshow(image, img) cv.waitKey(5000) # 一个键盘绑…...

FlowUs轻量化AI:趁这波升级专业版,全年无限AI助力笔记产出与二次编写
在数字时代,信息管理与知识产出的效率直接影响个人的生产力。FlowUs作为一款集笔记、文档、多维表、文件夹于一体的新一代知识管理平台,其轻量化AI的加入更是如虎添翼。特别是在活动期间,升级专业版将带来全年无限AI使用次数,让每…...

Day 22:2786. 访问数组中的位置使分数最大
Leetcode 2786. 访问数组中的位置使分数最大 给你一个下标从 0 开始的整数数组 nums 和一个正整数 x 。 你 一开始 在数组的位置 0 处,你可以按照下述规则访问数组中的其他位置: 如果你当前在位置 i ,那么你可以移动到满足 i < j 的 任意 …...

理解Es的DSL语法(二):聚合
前一篇已经系统介绍过查询语法,详细可直接看上一篇文章(理解DSL语法(一)),本篇主要介绍DSL中的另一部分:聚合 理解Es中的聚合 虽然Elasticsearch 是一个基于 Lucene 的搜索引擎,但…...
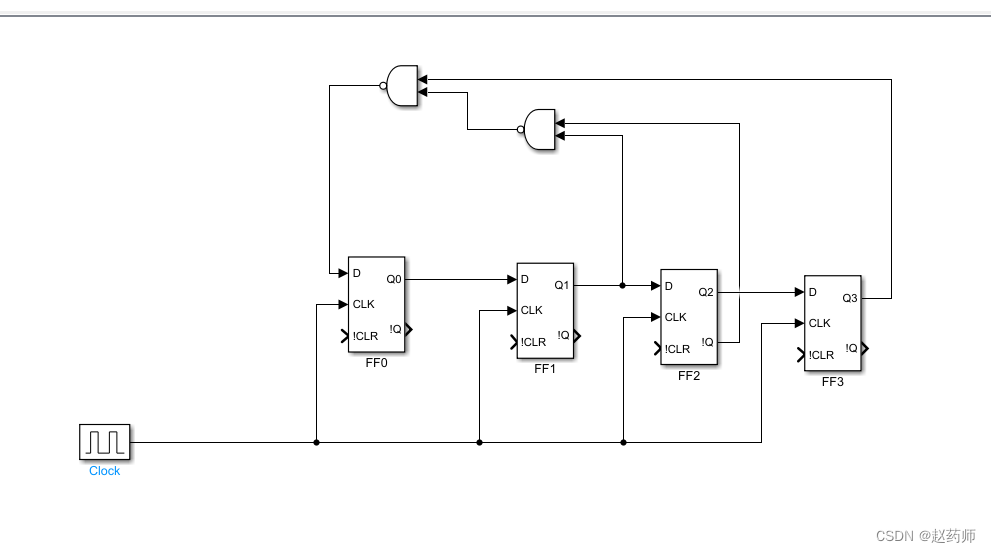
matlab-2-simulink-小白教程-如何绘制电路图进行电路仿真
以上述电路图为例:包含D触发器,时钟CLK,与非门 一、启动simulink的三种方式 方式1 在MATLAB的命令行窗口输入“Simulink”命令。 方式2 在MATLAB主窗口的“主页”选项卡中,单击“SIMULINK”命令组中的Simulink命令按钮。 方式3 从MATLAB…...

CSS从入门到精通——背景样式
目录 背景颜色 任务描述 相关知识 背景色 编程要求 背景图片 任务描述 相关知识 背景图片 设置背景图片 平铺背景图像 任务要求 背景定位与背景关联 任务描述 相关知识 背景定位 背景关联 简写背景 编程要求 背景颜色 任务描述 本关任务:在本关…...
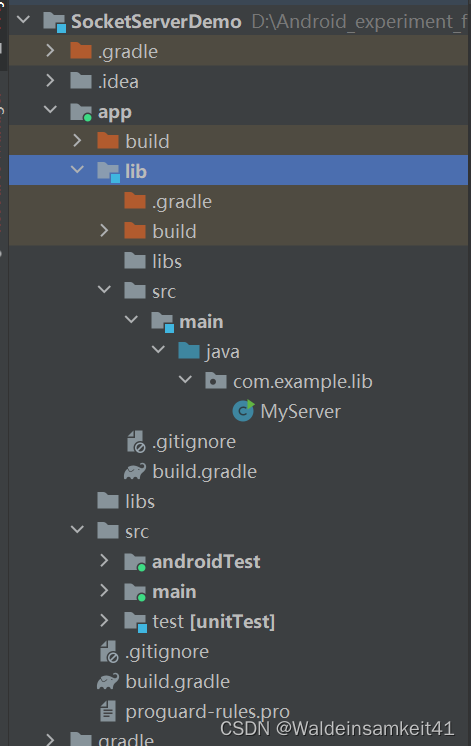
网络编程---Java飞机大战联机
解析服务器端代码 代码是放在app/lib下的src下的main/java,而与之前放在app/src/main下路径不同 Main函数 Main函数里只放着创建MyServer类的一行 public static void main(String args[]){new MyServer();} MyServer构造函数 1.获取本机IP地址 //获取本机IP地…...

一个简单的Oracle函数
CREATE OR REPLACE FUNCTION getyj_zhibiao_value(p_name IN varchar2, p_index IN varchar2) RETURN NUMBER IS -- 定义返回的指标值变量 v_result NUMBER; -- 定义临时变量来存储查询到的指标值 v_index1 VARCHAR2(50); v_index2 VARCHAR2(50); …...
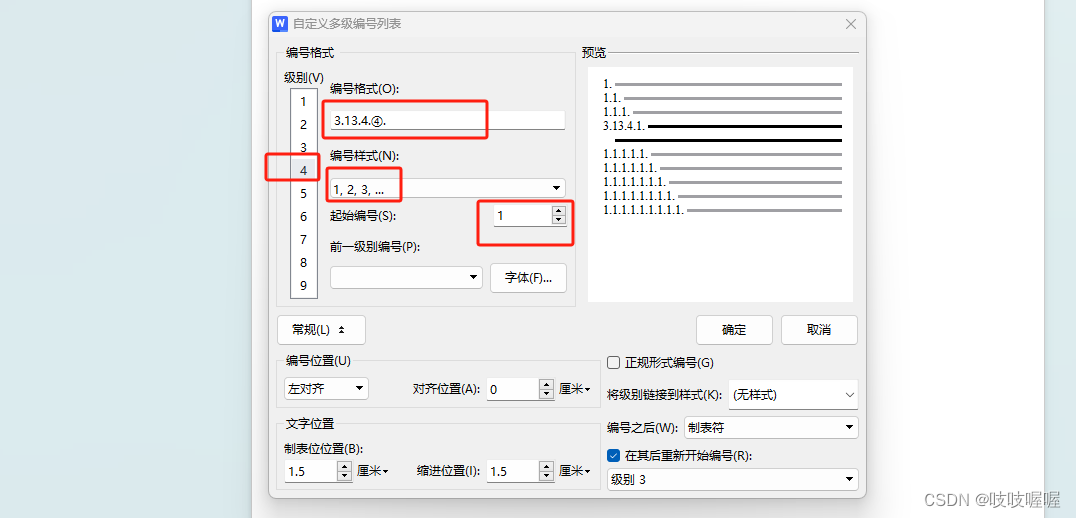
word中根据上级设置下级编号
如上级是3.13.4,如下图 现在想设置下级编码跟随上级逐级显示成3.13.4.1 则在标题功能说明这点击顶部菜单栏的编号按钮,如下图 然后,选择自定义编号-自定义列表-自定义按钮 然后重点是编号格式这一栏,需要手动填写下前三级的编号&…...

【康复学习--LeetCode每日一题】2786. 访问数组中的位置使分数最大
题目描述: 给你一个下标从 0 开始的整数数组 nums 和一个正整数 x 。 你一开始 在数组的位置 0 处,你可以按照下述规则访问数组中的其他位置: 如果你当前在位置 i ,那么你可以移动到满足 i < j 的 任意 位置 j 。 对于你访问的…...

bash和sh区别
bash 和 sh 是两种常用的 Unix Shell,它们有一些区别,特别是在功能和兼容性方面。以下是一些主要的区别: 1. **历史与实现**: - sh(Bourne Shell)是第一个 Unix Shell,最初由 Stephen Bourn…...
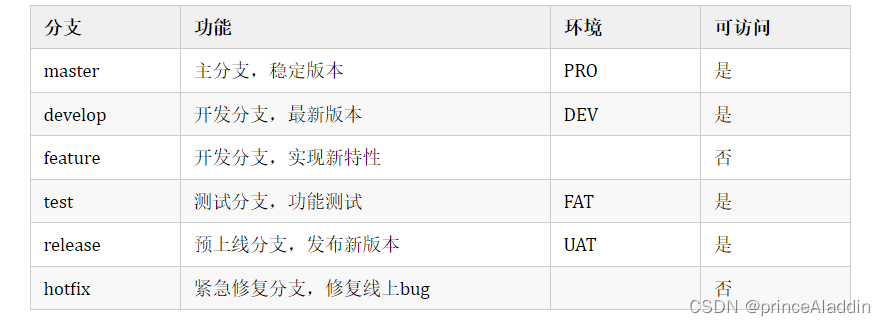
Git 代码管理规范 !
分支命名 master 分支 master 为主分支,也是用于部署生产环境的分支,需要确保master分支稳定性。master 分支一般由 release 以及 hotfix 分支合并,任何时间都不能直接修改代码。 develop 分支 develop 为开发环境分支,始终保持最…...
)
别再复制官网代码了!Vue + Ant Design 图标与分隔符的本地化实战(附避坑指南)
Vue Ant Design 图标与分隔符的本地化实战指南 在Vue项目中使用Ant Design Vue组件库时,很多开发者习惯直接从官网复制示例代码。然而,这种"拿来主义"常常导致项目运行时出现图标不显示、样式依赖CDN资源等问题。本文将带你从零开始ÿ…...

3步开启游戏自动化革命:智能助手解放你的游戏时间
3步开启游戏自动化革命:智能助手解放你的游戏时间 【免费下载链接】MaaAssistantArknights 《明日方舟》小助手,全日常一键长草!| A one-click tool for the daily tasks of Arknights, supporting all clients. 项目地址: https://gitcode…...


终极iOS越狱完整指南:5个步骤解锁iPhone隐藏功能
终极iOS越狱完整指南:5个步骤解锁iPhone隐藏功能 【免费下载链接】Jailbreak iOS 26.4 - 26, 17 - 17.7.5 & iOS 18 - 18.7.3 Jailbreak Tools, Cydia/Sileo/Zebra Tweaks & Jailbreak News Updates || AI Jailbreak Finder 👇 项目地址: http…...

Atmosphere-stable:Nintendo Switch自制系统的技术架构深度剖析与实战指南
Atmosphere-stable:Nintendo Switch自制系统的技术架构深度剖析与实战指南 【免费下载链接】Atmosphere-stable 大气层整合包系统稳定版 项目地址: https://gitcode.com/gh_mirrors/at/Atmosphere-stable 在Nintendo Switch自制系统领域,Atmosphe…...

AI Agent Harness Engineering 的安全攻防:你的智能体如何被欺骗、劫持与利用
AI Agent Harness Engineering 安全攻防深度解析:你的智能体如何被欺骗、劫持与利用 关键词 AI Agent安全、Harness工程、Prompt注入、工具劫持、智能体攻防、LLM安全、权限逃逸 摘要 随着AI Agent从概念验证走向大规模产业落地,作为智能体控制平面的Harness层已成为攻防…...

[GESP202512 C++ 三级] 判断题第 9 题
【题目描述】 给定一个正整数 a ,当需要计算 -a 的补码时,有这样一个计算技巧:将 a 的二进制形式从右往左扫描,遇到第一个 1 之后,将找到的第一个 1 左边的所有位都取反,能得到 -a 的补码。 答:…...

使用kern工具自动化构建Linux内核:从原理到实战
1. 项目概述:一个内核构建与管理的瑞士军刀如果你曾经尝试过编译Linux内核,或者需要为特定的硬件、研究项目定制一个内核,那么你大概率体验过这个过程:下载源码、配置成千上万个选项、解决依赖、漫长编译,最后可能因为…...

Synology API v0.8架构重构:企业级NAS自动化管理Python SDK深度解析
Synology API v0.8架构重构:企业级NAS自动化管理Python SDK深度解析 【免费下载链接】synology-api A Python wrapper around Synology API 项目地址: https://gitcode.com/gh_mirrors/sy/synology-api Synology API v0.8版本标志着该项目在企业级NAS自动化管…...

ASCII艺术乱码修复:ascii-fix工具解决终端编码兼容性问题
1. 项目概述:当字符艺术遇上编码乱码如果你经常在终端里折腾,或者喜欢用命令行工具处理文本,那你肯定遇到过这种情况:一个精心设计的ASCII艺术Logo,或者一个结构清晰的表格,在某个终端或编辑器里打开时&…...