Hadoop 2.0:主流开源云架构(四)
目录
- 五、Hadoop 2.0访问接口
- (一)访问接口综述
- (二)浏览器接口
- (三)命令行接口
- 六、Hadoop 2.0编程接口
- (一)HDFS编程
- (二)Yarn编程
五、Hadoop 2.0访问接口
(一)访问接口综述
Hadoop 2.0分为相互独立的几个模块,访问各个模块的方式也是相互独立的,但每个模块访问方式可分为:浏览器接口、Shell接口和编程接口。
(二)浏览器接口
| Web地址 | 配置文件 | 配置参数 | |
|---|---|---|---|
| HDFS | http://NameNodeHostName:50070 | hdfs-site.xml | {dfs.namenode.http-address} |
| Yarn | http://ResourceManagerHostName:8088 | yarn-site.xml | {yarn.resourcemanager.webapp.address} |
| MapReduce | http://JobHistoryHostName:19888 | mapred-site.xml | {mapreduce.jobhistory.webapp.address} |
在Hadoop 2.0里,MapReduce是Yarn不可缺少的模块,这里的JobHistory是一个任务独立模块,用来查看历史任务,和MapReduce并行处理算法无关。
(三)命令行接口
1. HDFS
以tar包方式部署时,其执行方式是HADOOP_HOME/bin/hdfs,当以完全模式部署时,使用HDFS用户执行hdfs即可。

2. Yarn
以tar包方式部署时,其执行方式是HADOOP_HOME/bin/yarn,当以完全模式部署时,使用Yarn用户执行yarn即可。

每一条命令都包含若干条子命令,Yarn的Shell命令也主要分为用户命令和管理员命令。
3. Hadoop
以tar包方式部署时,其执行方式是HADOOP_HOME/bin/Hadoop,当以完全模式部署时,在终端直接执行hadoop。

这个脚本既包含HDFS里最常用命令fs(即HDFS里的dfs),又包含Yarn里最常用命令jar,可以说是HDFS和Yarn的结合体。此外,distcp用mapreduce来实现两个Hadoop集群之间大规模数据复制。
4. 其他常用命令
sbin/目录下的脚本主要分为两种类型:启停服务脚本和管理服务脚本。其中,脚本hadoop-daemon.sh可单独用于启动本机服务,方便本机调试,start/stop类脚本适用于管理整个集群,读者只要在命令行下直接使用这些脚本,它会自动提示使用方法。

六、Hadoop 2.0编程接口
(一)HDFS编程

1. HDFS编程实例
【例1】 请编写一简单程序,要求实现在HDFS里新建文件myfile,并且写入内容“china cstor cstor cstor china”。
代码如下:
public class Write {public static void main(String[] args) throws IOException {Configuration conf = new Configuration(); //实例化配置文件Path inFile = new Path("/user/joe/myfile"); //命名一个文件FileSystem hdfs = FileSystem.get(conf); //获取文件系统FSDataOutputStream OutputStream = hdfs.create(inFile); //获取文件流outputStream.writeUTF("china cstor cstor cstor china"); //使用流向文件里写内容outputStream.flush();outputStream.close();}
}
假定程序打包后称为hdfsOperate.jar,并假定以joe用户执行程序,主类为Write,主类前为包名,则命令执行如下:
[joe@cMaster~]$ hadoop jar hdfsOperate.jar cn.cstor.data.hadoop.hdfs.write.Write
成功执行上述命令后,可使用如下两种方式确认文件已经写入HDFS。
第一种方式:使用Shell接口,以joe用户执行如下命令:
[joe@cMaster~]$ hdfs dfs -cat ls #类似于Linux的ls,列举HDFS文件
[joe@cMaster~]$ hdfs dfs -cat myfile #类似于Linux的cat,查看文件
第二种方式:使用Web接口,浏览器地址栏打开http://namenodeHostName:50070,点击Browse the filesystem,进入文件系统,接着查看文件/user/jioe/myfile即可。
【例2】 请编写一简单程序,要求输出HDFS里刚写入的文件myfile的内容。
代码如下:
public class Read {public static void main(String[] args) throws IOException {Configuration conf = new Configuration();Path inFile = new Path("/user/joe/myfile"); //HDFS里欲读取文件的绝对路径FileSystem hdfs = FileSystem.get(conf);FSDataIutputStream inputStream = hdfs.open(inFile); //获取输出流System.out.println("myfile:"+inputStream.readUTF()); //使用输出流读取文件inputStream.close();}
}
下面是命令执行方式及其结果:
[joe@cMaster~]# hadoop jar hdfsOperate.jar cn.cstor.data.hadoop.hdfs.read.Read
myfile: china cstor cstor china
【例3】 请编写一简单代码,要求输出HDFS里文件myfile相关属性(如文件大小、拥有者、集群副本数,最近修改时间等)。
代码如下:
public class Status {public static void main(String[] args)throws Exception {Configuration conf = new Configuration();Path file = new Path("/user/joe/myfile");System.out.println("FileName:"+file.getName());FileSystem hdfs = file.getFileSystem(conf);FileStatus[] fileStatus = hdfs.listStatus(file);for (FileStatus status: fileStatus) {System.out.println("FileOwner:"+status.getOwner());System.out.println("FileReplication:"+status.getReplication();System.out.println("FileModificationTime:"+new Date(status.getModificationTime());System.out.println("FileBlockSize:"+status.getBlockSize());}}
}
程序执行方式及其结果如下:
[joe@cMaster~] Hadoop jar hdfsOperate.jar cn.cstor.data.Hadoop.hdfs.file.Status
FileName: myfile
FileOwner: joe
FileReplication: 3
FileModification Time: Tue Nov 12 05:24:02 PST 2013
上面我们通过三个例题介绍了HDFS文件最常用操作,但这仅仅是三个小演示程序,在真正处理HDFS文件流时,可以使用缓冲流将底层文件流一层层包装,可大大提高读取效率。
2. HDFS编程基础
(1)Hadoop统一配置文件类Configuration
Hadoop的每一个实体(Common,HDFS,Yarn)都有与其相对应的配置文件,Configuration类是联系几个配置文件的统一接口。
Hadoop各模块间传递的一切值都必须通过Configuration类实现,其他方式均无法获取程序设置的参数,若想实现参数最好使用Configuration类的get和set方法。
(2)取得HDFS文件系统接口
在Hadoop源代码中,HDFS相关代码大都存放在org.apache.Hadoop.hdfs包里。但是,我们编写代码操作HDFS里的文件时,不可以调用这些代码,而是通过org.apache.hadoop.fs包里的FileSystem类实现。

FileSystem类是Hadoop访问文件系统的抽象类,它不仅可以获取HDFS文件系统服务,也可以获取其他文件系统(比如本地文件系统)服务,为程序员访问各类文件系统提供统一接口。
(3)HDFS常用流和文件状态类
Common还提供了一些处理HDFS文件的常用流:fs包下的FSDataInputStream,io包下的缓冲流DataInputBuffer,util包下的LineReader等等。用户可以和Java流相互配合使用。
(二)Yarn编程
Yarn是一个资源管理框架,由ResourceManager(RM)和NodeManager(NM)。但RM和NM不参与计算逻辑。称由ApplicationMaster和Client组成的处理逻辑相同的一类任务为逻辑实体,可以定义Map型、MapReduce型、MapReduceMap型和CPU密集型任务。
1. 概念和流程
在资源管理框架中,RM负责资源分配,NodeManager负责管理本地资源。在计算框架中,Client负责提交任务,RM启动任务对应的ApplicationMaster。
(1)编程时使用的协议
① ApplicationClientProtocol:Client<–>ResourceManager。
Client通知RM启动任务(如要求RM启动ApplicationMaster),获取任务状态或终止任务时使用的协议。
② ApplicationMasterProtocol:ApplicationMaster<–>ResourceManager。
ApplicationMaster向RM注册/注销申请资源时用到的协议。
③ ContainerManager:ApplicationMaster<–>NodeManager。
ApplicationMaster启动/停止获取NM上的Container状态信息时所用的协议。
(2)一个Yarn任务的执行流程简析
Client提交任务时,通过调用ApplicationClientProtocol#getNewApplication从RM获取一个ApplicationId,然后再通过ApplicationClientProtocol#submitApplication提交任务。
ApplicationMaster则负责此次任务的处理全过程,RM会选定一个Container来启动ApplicationMaster,ApplicationMaster会通过心跳包与RM保持通信,ApplicationMaster须向RM注销自己。
(3)编程步骤小结
① Client端
步骤1:获取ApplicationId
步骤2:提交任务
② ApplicationMaster端
步骤1:注册
步骤2:申请资源
步骤3:启动Container
步骤4:重复步骤2、3,直至任务完成
步骤5:注销
Yarn提供了三个Application-Master实现:DistributedShell、unmanaged-am-launcher、MapReduce。
2. 实例分析
DistributedShell是Yarn自带的一个应用程序编程实例,相当于Yarn编程中的“Hello World”,它的功能是并行执行用户提交的Shell命令或Shell脚本。
从Hadoop官方网站下载Hadoop-2.2.0-src.tar.gz(Hadoop源码包)并解压后,依次进入Hadoop-yarn-project\Hadoop-yarn\Hadoop-yarn-applications,下面就是Yarn自带的两个Yarn编程实例。
Client主要向RM提交任务,ApplicationMaster向RM申请资源,并与NM协商启动Container完成任务。
(1)Client类主要代码:
YarnClient yarnClient = YarnClient.createYarnClient(); //新建Yarn客户端
yarnClient.start(); //启动Yarn客户端
YarnClientApplication app = yarnClient.createApplication(); //获取提交程序句柄
ApplicationSubmissionContext appContext = app.getApplicationSubmissionContext(); //获取上下文句柄
ApplicationId appId = appContext.getApplicationId(); //获取RM分配的appId
appContext.setResource(capability); //设置任务其他信息举例
appContext.setQueue(amQueue);
appContext.setPriority(priority);//实例化ApplicationMaster对应的Container
ContainerLaunchContext amContainer = Records.newRecord(ContainerLaunchContext.class);
amContainer.setCommands(commands); //参数commands为用户预执行的Shell命令
appContext.setAMContainerSpec(amContainer); //指定ApplicationMaster的Container
yarnClient.submitApplication(appContext); //提交作业
从代码中能看到,关于RPC的代码已经被上一层代码封装了,Client端编程简单地说就是获取YarmClientApplication,接着设置ApplicationSubmissionContext,最后提交任务。
(2)ApplicationMaster类最主要代码:
//新建RM代理
AMRMClientAsync amRMClient = AMRMClientAsync.createAMRMClientAsync(1000, allocListener);
amRMClient.init(conf);
amRMClient.start();
//向RM注册
amRMClient.registerApplicationMaster(appMasterHostname, appMasterRpcPort, appMasterTrackingUrl);
containerListener = createNMCallbackHandler();
//新建NM代理
NMClientAsync nmClientAsync = new NMClientAsyncImpl(containerListener);
nmClientAsync.init(conf);
nmClientAsync.start();
//向RM申请资源
for(int i=0; i<numTotalContainers; ++i) {ContainerRequest containerAsk = setupContainerAskForRM();amRMClient.addContainerRequest(containerAsk);
}
numRequestedContainers.set(numTotalContainers);
//设置Container上下文
ContainerLaunchContext ctx = Records.newRecord(ContainerLaunchContext.class);
ctx.setCommands(commands);
//要求NM启动Container
nmClientAsync.startContainerAsync(container, ctx);
//containerListener汇报此NM完成任务后,关闭此NM
nmClientAsync.stop();
//向RM注销
amRMClient.unregisterApplicationMaster(appStatus, appMessage, null);
amRMClient.stop();
源码中的ApplicationMaster有1000行,上述代码给出了源码里最重要的几个步骤。
3. 代码执行方式
默认情况下Yarn包里已经有分布式Shell的代码了,可以使用任何用户执行如下命令:
$Hadoop jar /usr/lib/Hadoop-yarn/Hadoop-yarn-applications-distributedshell.jar
> org.apache.Hadoop.yarn.applications.distributedshell.Client
> -jar /usr/lib/Hadoop-yarn/Hadoop-yarn-applications-distributedshell.jar
> -shell_command '/bin/date' -num_containers 100
4. 实例分析-MapReduce

| InputFormat | TextInputFormat |
|---|---|
| RecordReader | LineRecordReader |
| InputSplit | FileSplit |
| Map | IdentityMapper |
| Combine | 不使用 |
| Partitioner | HashPartitioner |
| GroupCompatator | 不使用 |
| Reduce | IdentityReducer |
| OutputFormat | FileOutputFormat |
| RecordWriter | LineRecordWriter |
| OutputCommitter | FileOutputCommitter |
MapReduce编程示例——WordCount
下面是MapReduce自带的最简单代码, MapReduce算法实现统计文章中单词出现次数,源代码如下:
public class WordCount//定义map类,一般继承自Mapper类,里面实现读取单词,写出<单词,1>public static class TokenizerMapper extends Mapperc<Object, Text, Text, Int Writable> {private final static Int Writale one = new IntWritable(1);private Text word = new Text();//map方法,划分一行文本,读一单词写出一个<单词,1>public void map(Object key, Text value, Context context)throws IOException, InterruptedException {StringTokenizer itr = new StringTokenizer(value.toString());while(itr.hasMoreTokens()) {word.set(itr.nextToken());context.write(word, one); //写出<单词,1>}}} //定义reduce类,对相同的单词,把它们<K,VList>中的VList值全部相加
public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {private IntWritable result = new IntWritable();public void reduce(Text key, Iterable<IntWritable> values, Context context throws IOException, InterruptedException {int sum = 0;for(IntWritable val: values) {sum += val.get(); //相当于<cstor,1><cstor,1>,将两个1相加}result.set(sum);context.write(key,result); //写出这个单词,和这个单词出现次数<单词,单词出现次数>}}public static void main(String[] args) throws Exception { //主方法,函数入口Configuration conf = new Configuration(); //实例化配置文件类Job job = new Job(conf, "WordCount"); //实例化Job类job.setInputFormatClass(TextInputFormat.class); //指定使用默认输入格式类TextInputFormat.setInputPaths(job, inputPaths); //设置待处理文件的位置job.setJarByClass(WordCount.class); //设置主类名job.setMapperClass(TokenizerMapper.class); //指定使用上述自定义Map类job.setMapOutputKeyClass(Text.class); //指定Map类输出的<K,V>,K类型job.setMapOutputValueClass(IntWritable.class); //指定Map类输出的-K,V>,V类型job.setPartitionerClass(HashPartitioner.class); //指定使用默认的HashPartitioner类job.setReducerClass(IntSumReducer.class); //指定使用上述自定义Reduce类job.setNumReduceTasks(Integer.parseInt(numOfReducer); //指定Reduce个数job.setOutputKeyClass(Text.class); //指定Reduce类输出的<K,V>K类型job.setOutputValueClass(Text.class); //指定Reduce类输出的<K,V>,V类型job.setOutputFormatClass(TextOutputFormat.class); //指定使用默认输出格式类TextOutputFormat.setOutputPath(job, outputDir); //设置输出结果文件位置System.exit(job.waitForCompletion(true)?0:1); //提交任务并监控任务状态}
}
相关文章:
Hadoop 2.0:主流开源云架构(四)
目录 五、Hadoop 2.0访问接口(一)访问接口综述(二)浏览器接口(三)命令行接口 六、Hadoop 2.0编程接口(一)HDFS编程(二)Yarn编程 五、Hadoop 2.0访问接口 &am…...

PythonSQL应用随笔4——PySpark创建SQL临时表
零、前言 Python中直接跑SQL,可以很好的解决数据导过来导过去的问题,本文方法主要针对大运算量时,如何更好地让Python和SQL打好配合。 工具:Zeppelin 语法:PySpark(Apache Spark的Python API)…...

C# OpenCvSharp 矩阵计算-determinant、trace、eigen、calcCovarMatrix、solve
🚀 在C#中使用OpenCvSharp库进行矩阵操作和图像处理 在C#中使用OpenCvSharp库,可以实现各种矩阵操作和图像处理功能。以下是对所列函数的详细解释和示例,包括运算过程和结果。📊✨ 1. determinant - 计算行列式 🧮 定义: double determinant(InputArray mtx); 参数…...

知识普及:什么是边缘计算(Edge Computing)?
边缘计算是一种分布式计算架构,它将数据处理、存储和服务功能移近数据产生的边缘位置,即接近数据源和用户的位置,而不是依赖中心化的数据中心或云计算平台。边缘计算的核心思想是在靠近终端设备的位置进行数据处理,以降低延迟、减…...

大型企业IT基础架构和应用运维体系
大型企业IT基础架构和应用运维体系 在数字化转型的浪潮中,大型企业面临着日益复杂的IT环境。高效的IT基础架构和应用运维体系,是确保企业业务连续性和竞争力的关键。本文将探讨大型企业如何构建强健的IT基础架构,并建立高效的应用运维体系&a…...
【源码】16国语言交易所源码/币币交易+期权交易+秒合约交易+永续合约+交割合约+新币申购+投资理财/手机端uniapp纯源码+PC纯源码+后端PHP
测试环境:Linux系统CentOS7.6、宝塔面板、Nginx、PHP7.3、MySQL5.6,根目录public,伪静态laravel5,开启ssl证书 语言:16种,看图 这套带前端uniapp纯源码,手机端和pc端都有纯源码,后…...

word空白页删除不了怎么办?
上方菜单栏点击“视图”,下方点击“大纲视图”。找到文档分页符的位置。将光标放在要删除的分节符前,按下键盘上的“Delet”键删除分页符。...
Java web应用性能分析之【prometheus+Grafana监控springboot服务和服务器监控】
Java web应用性能分析之【java进程问题分析概叙】-CSDN博客 Java web应用性能分析之【java进程问题分析工具】-CSDN博客 Java web应用性能分析之【jvisualvm远程连接云服务器】-CSDN博客 Java web应用性能分析之【java进程问题分析定位】-CSDN博客 Java web应用性能分析之【…...

JavaEE——声明式事务管理案例:实现用户登录
一、案例要求 本案例要求在控制台输入用户名密码,如果用户账号密码正确则显示用户所属班级,如果登录失败则显示登录失败。实现用户登录项目运行成功后控制台效果如下所示。 欢迎来到学生管理系统 请输入用户名: zhangsan 请输入zhangsan的密…...

解决用Three.js实现嘴型和语音同步时只能播放部分部位的问题 Three.js同时渲染播放多个组件变形动画的方法
前言 参考这篇文章ThreeJSChatGPT 实现前端3D数字人AI互动,前面搭后端、训练模型组内小伙伴都没有什么问题,到前端的时候,脸部就出问题了。看我是怎么解决的。 好文章啊,可惜百度前几个都找不到,o(╥﹏╥)o 问题情况 …...
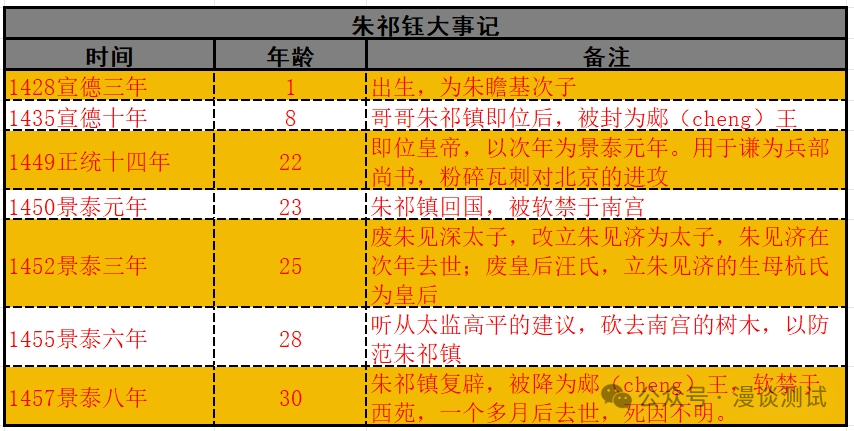
阅读笔记:明朝那些事儿太监弄乱的王朝
阅读豆评高分作品《明朝那些事儿太监弄乱的王朝》第三部,截止到今天告一段落了,前两部皇帝,太子相对比较少,了解故事的主线,分支不算多,记忆起来还能应付过来,第三部皇帝,太子更换的…...
算法第六天:力扣第977题有序数组的平方
一、977.有序数组的平方的链接与题目描述 977. 有序数组的平方的链接如下所示:https://leetcode.cn/problems/squares-of-a-sorted-array/description/https://leetcode.cn/problems/squares-of-a-sorted-array/description/ 给你一个按 非递减顺序 排序的整数数组…...

设计模式学习(二)工厂模式——工厂方法模式
设计模式学习(二)工厂模式——工厂方法模式 前言工厂方法模式简介示例优点缺点使用场景 前言 前一篇文章介绍了简单工厂模式,提到了简单工厂模式的缺点(违反开闭原则,扩展困难),本文要介绍的工…...

TCP与UDP案例
udp不会做拆分整合什么的 多大就是多大...

Adaboost集成学习 | Matlab实现基于CNN-LSTM-Adaboost集成学习时间序列预测(股票价格预测)
目录 效果一览基本介绍模型设计程序设计参考资料 效果一览 基本介绍 Adaboost集成学习 | Matlab实现基于CNN-LSTM-Adaboost集成学习时间序列预测(股票价格预测) 模型设计 融合Adaboost的CNN-LSTM模型的时间序列预测,下面是一个基本的框架。 …...

你焦虑了吗
前段时间,无意间在图书馆看到一本书《认知觉醒》,书中提到了焦虑的相关话题,从焦虑的根源,焦虑的形式,如何破解焦虑给了我点启示,分享给一下。 引语: 焦虑肯定是你的老朋友了,它总像…...

一键分析Bulk转录组数据
我们前面介绍了经典的转录组分析流程:Hisat2 Stringtie,可以帮助用户快速获得基因的表达量矩阵。 云上生信,未来已来 | 转录组标准分析流程重磅上线! RNA STAR 也是一款非常流行的转录组数据分析工具。它不仅可以将测序 Reads 比…...
Django DetailView视图
Django的DetailView是一个用于显示单个对象详情的视图。下面是一个使用DetailView来显示单个书籍详情的例子。 1,添加视图 Test/app3/views.py from django.shortcuts import render# Create your views here. from django.views.generic import ListView from .m…...
openGauss学习笔记-300 openGauss AI特性-AI4DB数据库自治运维-DBMind的AI子功能-SQL Rewriter SQL语句改写
文章目录 openGauss学习笔记-300 openGauss AI特性-AI4DB数据库自治运维-DBMind的AI子功能-SQL Rewriter SQL语句改写300.1 概述300.2 使用指导300.2.1 前提条件300.2.2 使用方法示例300.3 获取帮助300.4 命令参考300.5 常见问题处理openGauss学习笔记-300 openGauss AI特性-AI…...

typescript-泛型
typescript-泛型 泛型程序设计是一种编程风格或编程范式,允许在程序中定义形式类型参数,然后再泛型实例化时候使用实际类型参数来替代形式类型参数,通过泛型,可以定义通用的数据结构或类型,这种数据结构或类型仅仅再它…...

BG3ModManager终极指南:如何轻松管理博德之门3模组避免游戏崩溃?
BG3ModManager终极指南:如何轻松管理博德之门3模组避免游戏崩溃? 【免费下载链接】BG3ModManager A mod manager for Baldurs Gate 3. This is the only official source! 项目地址: https://gitcode.com/gh_mirrors/bg/BG3ModManager BG3ModMana…...

为什么你的Ziatype输出总是发灰?3分钟定位CMYK→RGB色域坍缩根源并一键修复
更多请点击: https://intelliparadigm.com 第一章:Ziatype印相发灰现象的直观诊断与认知重构 Ziatype是一种基于铁-银工艺的古典摄影印相法,其典型特征是高对比度、深沉黑位与细腻中间调。然而在实际操作中,“发灰”(…...

工业HMI系统核心技术解析与TI解决方案实践
1. 工业HMI系统概述人机界面(HMI)系统是现代工业自动化不可或缺的核心组件,它如同工厂的"神经中枢",将复杂的机器语言转化为直观的可视化信息。想象一下,当操作员站在一台大型工业设备前,不再需要…...
:团雾识别+车流量统计全流程落地)
【YOLO26实战全攻略】20——智慧交通(二):团雾识别+车流量统计全流程落地
摘要:团雾作为高速公路"流动杀手",常导致能见度骤降、事故频发,而传统监测手段响应滞后、统计粗放;车流量数据则是交通管控的核心依据,但精细化分类统计一直是行业痛点。本文基于YOLO26的边缘友好特性,结合FAENet特征增强网络与ByteTrack跟踪算法,打造了一套&…...

电源完整性设计:电容模型、去耦策略与测量验证实战解析
1. 电容与去耦:从概念到实战的深度解析上周我们聊了聊去耦电容在电源完整性设计中的一些基本概念和时机选择,算是开了个头。这周咱们继续深入,把这块硬骨头啃得更透一些。很多工程师,尤其是刚入行的朋友,常常觉得电容选…...

嵌入式产品如何通过RTOS选型抢占市场先机
1. 项目概述:为什么“上市时机”是嵌入式产品的生死线在嵌入式系统开发这个行当里摸爬滚打了十几年,我见过太多团队把“功能实现”和“性能达标”作为项目的终极目标,却在一个更根本的问题上栽了跟头:上市时机。你可能觉得&#x…...

Arm DDT:高性能计算并行程序调试利器
1. Arm DDT调试工具概述Arm DDT(Distributed Debugging Tool)是Arm公司开发的一款专业级并行程序调试工具,专为高性能计算(HPC)领域设计。作为Arm Forge工具套件的重要组成部分,DDT提供了强大的MPI程序调试…...

Faust.js实战:用Next.js构建高性能Headless WordPress前端
1. 项目概述:当WordPress遇见现代前端如果你和我一样,在过去几年里深度参与过企业级WordPress项目,那你一定对那个经典的“两难困境”记忆犹新:一方面,WordPress的后台管理体验和内容生态无可匹敌,是内容团…...

大模型压缩实战:量化、剪枝与知识蒸馏技术解析与应用
1. 项目概述:当大模型遇见“瘦身”革命最近在跟几个做AI应用落地的朋友聊天,大家普遍都在吐槽一个事儿:现在的大语言模型(LLM)能力是强,但动辄几十亿、上百亿的参数规模,部署成本高得吓人&#…...

独立开发者如何借助taotoken模型广场低成本验证产品创意
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 独立开发者如何借助Taotoken模型广场低成本验证产品创意 对于资源有限的独立开发者或小型工作室而言,验证一个需要AI功…...