【机器学习】基于Transformer架构的移动设备图像分类模型MobileViT
1.引言
1.1. MobileViT是什么?
MobileViT是一种基于Transformer的轻量级视觉模型,专为移动端设备上的图像分类任务而设计。
- 背景与目的:
- MobileViT由Google在2021年提出,旨在解决移动设备上的实时图像分类需求。
- 与传统的卷积神经网络(CNN)相比,MobileViT在保持高性能的同时,显著降低了计算复杂度和内存需求,从而更适应移动设备的计算能力。
- 技术特点:
- 轻量级与移动友好:MobileViT通过引入轻量级的Transformer模块和有效的降维策略,大幅减少了模型的参数数量和计算复杂度,使其能够在移动设备上高效运行。
- 基于Transformer:MobileViT采用了Transformer架构,通过自注意力机制捕获图像的全局上下文信息,提高了模型的泛化能力和准确性。
- 优化方法:MobileViT采用了一系列优化方法,如混合精度训练和自适应模型调整等,进一步提高了在移动设备上的运行效率。
- 性能表现:
- 在多个图像分类数据集上,MobileViT均取得了与现有轻量级CNN模型相当或更优的性能。例如,在ImageNet-1k数据集上,MobileViT在大约600万个参数的情况下达到了78.4%的Top-1准确率。
- MobileViT显示出更好的泛化能力,即使在使用大量数据增强的情况下,也能更好地预测未知数据集上的表现。
- 与其他基于Transformer的模型相比,MobileViT对超参数的调整相对健壮,对L2正则化等超参数的敏感度较低。
- 适用场景:MobileViT特别适用于需要实时图像分类的移动端应用,如智能手机、平板电脑等。其轻量级和高效的特点使得它成为移动视觉任务中的理想选择。
综合而言,MobileViT通过结合轻量级的Transformer架构和优化的设计,成功实现了在移动设备上高效、准确的图像分类。其优秀的性能、泛化能力和对超参数的鲁棒性使得它在移动视觉领域具有广泛的应用前景。
1.2.Transformer架构的特点
Transformer架构最初由谷歌大脑在2017年的论文《Attention Is All You Need》中提出,是一种基于自注意力机制的序列到序列(Seq2Seq)模型。自提出以来,该模型在自然语言处理(NLP)和计算机视觉(CV)等领域取得了显著的成功,并多次达到该领域内的最佳效果(SOTA)。
- 核心思想
Transformer架构的核心思想是使用自注意力机制(self-attention mechanism)来建立输入序列的表示。相比于传统的循环神经网络(RNN)架构,Transformer能够并行地处理整个序列,而不是按顺序逐步处理,从而提高了计算效率。
- 架构组成
Transformer架构主要由两个主要组件组成:编码器(Encoder)和解码器(Decoder)。
-
编码器(Encoder):
-
主要负责将输入序列转化为一种中间表示形式,这种表示形式能够捕捉输入序列中的上下文信息。
-
编码器由多个相同的层堆叠而成,每个层都包含自注意力机制和前馈神经网络(Feed-Forward Neural Network)。
-
自注意力机制允许模型在序列内的任意位置间直接建立依赖,从而更好地理解数据的上下文关系。
-
位置编码(Positional Encoding)用于提供关于单词在序列中位置的信息,因为Transformer不使用基于顺序的结构。
-
解码器(Decoder):
-
主要负责根据编码器的输出和之前的解码输出,生成新的序列。
-
解码器同样由多个相同的层堆叠而成,其结构与编码器类似,但还包含了一个额外的自注意力层和一个编码器-解码器注意力层。
-
编码器-解码器注意力层允许解码器关注编码器输出的不同位置,从而帮助生成准确的输出序列。
- 特点与优势
- 并行处理能力:Transformer能够并行地处理整个序列,而不是像RNN那样按顺序逐步处理,这大大提高了计算效率。
- 长距离依赖建模能力:通过自注意力机制,Transformer能够建模输入序列中的长距离依赖关系,这在处理长序列时尤为重要。
- 多头注意力机制:Transformer采用多头注意力机制,允许模型同时学习数据的不同表示,每个“头”关注序列的不同部分,这有助于模型捕捉更丰富的信息。
- 灵活性:Transformer架构非常灵活,可以应用于各种序列生成任务,如机器翻译、文本摘要、语音识别等。
综合而言,Transformer架构在自然语言处理领域特别流行,例如BERT和GPT等预训练语言模型就是从Transformer中衍生出来的。此外,Transformer架构也被广泛应用于计算机视觉领域,如图像分类、目标检测等任务。在智能驾驶领域,Transformer架构也被用于感知、预测和决策等各个环节。
1.3. 研究内容
在本文的例子中,我们将介绍并实现MobileViT架构,该架构是由Mehta等人提出的,它融合了Transformer(由Vaswani等人开创)和卷积神经网络的优点。通过Transformer,MobileViT能够捕获图像中的长距离依赖关系,从而生成全局表示;而卷积操作则帮助模型捕捉图像中的局部空间关系。
MobileViT的设计不仅结合了Transformer和卷积的特性,还作为一个通用且移动友好的骨干网络,适用于各种图像识别任务。据研究结果显示,在性能方面,MobileViT相比其他复杂度相近或更高的模型(如MobileNetV3)具有优势,同时保持了在移动设备上的高效运行。
请注意,为了成功运行这个示例,您需要安装TensorFlow 2.13或更高版本。
1.4. 研究意义
随着移动设备应用的广泛普及,图像分类等计算机视觉任务在移动设备上的需求日益增长。然而,传统的深度学习模型,特别是基于卷积神经网络(CNN)的模型,往往面临着计算资源和存储需求的限制,难以在移动设备上高效运行。因此,开发轻量级、高效的深度学习模型成为了一个迫切的研究需求。
MobileViT模型通过融合Transformer和卷积神经网络的优势,为解决移动设备上的图像分类问题提供了新的思路。它利用Transformer的自注意力机制捕捉图像中的长距离依赖关系,同时结合卷积操作捕捉局部空间关系,从而在保持高性能的同时降低了计算复杂度和内存需求。相比传统的轻量级CNN模型,MobileViT在多个图像分类数据集上均取得了优异的性能,证明了其在移动设备图像分类任务中的有效性和实用性。
MobileViT的研究不仅具有理论价值,还具有重要的实际应用前景。它能够为移动设备上的实时图像处理任务提供高效的解决方案,为用户带来更好的使用体验。随着移动设备性能的不断提升和计算资源的持续优化,MobileViT有望在更多领域得到应用,推动移动设备上的计算机视觉技术向前发展。同时,MobileViT的研究也为其他轻量级深度学习模型的设计和优化提供了有益的参考。
2. 部署MobileViT
2.1.设置
2.1.1.导入函数库
# 导入必要的库
import os
import tensorflow as tf # 设置Keras的后端为TensorFlow(虽然Keras现在默认后端就是TensorFlow,但这里显式设置以确保环境配置正确)
os.environ["KERAS_BACKEND"] = "tensorflow" # 导入Keras库以及相关的layers和backend模块
import keras
from keras import layers
from keras import backend as K # 导入tensorflow_datasets库,用于加载数据集
import tensorflow_datasets as tfds # 禁用tensorflow_datasets在加载数据时的进度条显示,以避免在输出中显示额外的进度信息
tfds.disable_progress_bar()
2.2.2.设置超参数
# 这些值来自表4。
patch_size = 4 # 2x2,用于Transformer块。
image_size = 256 # 输入图像的尺寸。
expansion_factor = 2 # MobileNetV2块的扩展因子。
这段代码定义了三个变量,分别用于设置Transformer块的Patch大小、输入图像的尺寸以及MobileNetV2块的扩展因子。这些参数对于构建MobileViT模型是必要的。
2.2.构建MobileViT
MobileViT架构是一个专为移动设备设计的图像分类模型,它巧妙地结合了Transformer和卷积神经网络的优点,以实现高效且准确的图像识别。
1. 输入处理
在模型的初始阶段,输入图像首先通过一系列带步长的3x3卷积层进行处理。这些卷积层不仅用于提取图像的初步特征,还通过调整步长来逐步降低特征图的分辨率,从而减少后续层的计算量。
2. MobileNetV2风格倒置残差块
在特征提取的过程中,MobileViT采用了MobileNetV2风格的倒置残差块进行特征转换和降采样。这些倒置残差块首先通过1x1卷积进行通道扩展,然后利用深度可分离卷积进行空间特征提取,最后再通过1x1卷积将特征图通道数恢复到原始大小。通过这种方式,倒置残差块能够在不增加过多计算量的前提下,有效地提高模型的特征提取能力。
3. MobileViT块
MobileViT架构的核心在于其独特的MobileViT块。这些块结合了Transformer和卷积神经网络的优点,旨在捕获图像中的长距离依赖关系和局部空间关系。具体来说,MobileViT块首先通过自注意力机制(如多头自注意力)计算特征图中不同位置之间的相关性,从而捕获长距离依赖关系。然后,它利用卷积操作对特征图进行局部空间特征的提取和融合。通过这种方式,MobileViT块能够同时利用Transformer的全局建模能力和卷积神经网络的局部特征提取能力,从而实现更高效、更准确的图像识别。
4. 输出层
经过多个MobileViT块的堆叠后,模型最终通过全局平均池化层将特征图转换为固定长度的特征向量。然后,这些特征向量被送入一个全连接层进行分类。全连接层的输出节点数与类别数相同,通过softmax函数计算每个类别的概率分布。
总体而言,MobileViT架构通过结合Transformer和卷积神经网络的优点,实现了在移动设备上进行高效、准确的图像分类。其独特的MobileViT块能够有效地捕获图像中的长距离依赖关系和局部空间关系,从而提高了模型的性能。同时,MobileViT架构还采用了MobileNetV2风格的倒置残差块进行特征转换和降采样,进一步提高了模型的计算效率。这些特点使得MobileViT成为了一个优秀的移动设备图像分类模型。
2.2.1.构建MobileViT
# 定义卷积块函数,用于构建卷积层。
def conv_block(x, filters=16, kernel_size=3, strides=2):# 创建二维卷积层。conv_layer = layers.Conv2D(filters, # 过滤器数量kernel_size, # 卷积核大小strides=strides, # 步长activation=keras.activations.swish, # 激活函数padding="same", # 填充方式)return conv_layer(x) # 返回卷积后的输出# 根据输入尺寸和卷积核大小,计算正确的填充量。
def correct_pad(inputs, kernel_size):# 根据图像数据格式确定图像维度。img_dim = 2 if backend.image_data_format() == "channels_first" else 1input_size = inputs.shape[img_dim : (img_dim + 2)]# 将卷积核大小转换为元组,如果它是一个整数。if isinstance(kernel_size, int):kernel_size = (kernel_size, kernel_size)# 计算调整值,用于确保卷积后尺寸的正确性。if input_size[0] is None:adjust = (1, 1)else:adjust = (1 - input_size[0] % 2, 1 - input_size[1] % 2)correct = (kernel_size[0] // 2, kernel_size[1] // 2)# 返回需要添加的填充量。return ((correct[0] - adjust[0], correct[0]),(correct[1] - adjust[1], correct[1]),)# 定义反残差块,用于构建轻量级卷积神经网络中的反残差结构。
def inverted_residual_block(x, expanded_channels, output_channels, strides=1):# 使用1x1卷积进行通道扩展。m = layers.Conv2D(expanded_channels, 1, padding="same", use_bias=False)(x)m = layers.BatchNormalization()(m)m = keras.activations.swish(m)# 如果步长大于1,则使用零填充。if strides == 2:m = layers.ZeroPadding2D(padding=correct_pad(m, 3))(m)# 使用深度可分离卷积进行空间维度的降采样。m = layers.DepthwiseConv2D(3, strides=strides, padding="same" if strides == 1 else "valid", use_bias=False)(m)m = layers.BatchNormalization()(m)m = keras.activations.swish(m)# 使用1x1卷积将通道数降至输出通道数。m = layers.Conv2D(output_channels, 1, padding="same", use_bias=False)(m)m = layers.BatchNormalization()(m)# 如果步长为1且输入输出通道数相同,则使用残差连接。if keras.ops.equal(x.shape[-1], output_channels) and strides == 1:return layers.Add()([m, x])return m# 定义多层感知机(MLP)函数,用于Transformer中的前馈网络。
def mlp(x, hidden_units, dropout_rate):for units in hidden_units:x = layers.Dense(units, activation=keras.activations.swish)(x)x = layers.Dropout(dropout_rate)(x)return x# 定义Transformer块函数,用于构建Transformer模型中的自注意力机制。
def transformer_block(x, transformer_layers, projection_dim, num_heads=2):for _ in range(transformer_layers):# 第一层归一化。x1 = layers.LayerNormalization(epsilon=1e-6)(x)# 创建多头注意力层。attention_output = layers.MultiHeadAttention(num_heads=num_heads, key_dim=projection_dim, dropout=0.1)(x1, x1)# 第一个残差连接。x2 = layers.Add()([attention_output, x])# 第二层归一化。x3 = layers.LayerNormalization(epsilon=1e-6)(x2)# MLP。x3 = mlp(x3,hidden_units=[x.shape[-1] * 2, x.shape[-1]],dropout_rate=0.1,)# 第二个残差连接。x = layers.Add()([x3, x2])return x# 定义MobileViT块,结合了局部特征提取和全局特征提取。
def mobilevit_block(x, num_blocks, projection_dim, strides=1):# 使用卷积进行局部特征提取。local_features = conv_block(x, filters=projection_dim, strides=strides)local_features = conv_block(local_features, filters=projection_dim, kernel_size=1, strides=strides)# 将特征图划分为不重叠的patches,并通过Transformer块处理。num_patches = int((local_features.shape[1] * local_features.shape[2]) / patch_size)non_overlapping_patches = layers.Reshape((patch_size, num_patches, projection_dim))(local_features)global_features = transformer_block(non_overlapping_patches, num_blocks, projection_dim)# 将Transformer的输出重新整理成特征图的形状。folded_feature_map = layers.Reshape((*local_features.shape[1:-1], projection_dim))(global_features)# 使用1x1卷积将特征图的通道数调整为与输入匹配,并与输入特征图进行拼接。folded_feature_map = conv_block(folded_feature_map, filters=x.shape[-1], kernel_size=1, strides=strides)local_global_features = layers.Concatenate(axis=-1)([x, folded_feature_map])# 使用卷积层融合局部和全局特征。local_global_features = conv_block(local_global_features, filters=projection_dim, strides=strides)return local_global_features
上述代码定义了一系列用于构建和操作深度学习模型,特别是MobileViT模型的函数。
-
conv_block:
- 功能:创建一个卷积块,包含卷积层、激活函数(Swish)和批量归一化。
- 用途:用于提取图像特征,可以作为更复杂模型的一部分。
-
correct_pad:
- 功能:计算进行卷积操作时所需的填充量,以确保输出尺寸正确。
- 用途:在对输入图像进行卷积操作之前调整边界填充。
-
inverted_residual_block:
- 功能:实现MobileNetV2中的反残差结构,包含点卷积、深度卷积和批量归一化。
- 用途:构建轻量级网络结构,用于减少模型参数和计算量。
-
mlp:
- 功能:实现多层感知机(MLP),用于Transformer中的前馈网络部分。
- 用途:在Transformer模型中进行特征的非线性变换。
-
transformer_block:
- 功能:构建Transformer块,包含多头自注意力机制和前馈网络。
- 用途:处理序列数据,捕获长距离依赖关系,用于图像的全局特征提取。
-
mobilevit_block:
- 功能:结合局部特征提取(通过卷积)和全局特征提取(通过Transformer)的MobileViT块。
- 用途:作为MobileViT模型的核心组件,实现图像的高效特征提取和表示。
整体来看,这些函数共同构成了一个深度学习模型的框架,特别是针对移动设备优化的视觉Transformer模型(MobileViT)。它们涵盖了从数据预处理(如填充和归一化)到特征提取(卷积和Transformer操作)的各个步骤,最终实现图像分类或其他视觉任务。
2.2.2.实例化MobileViT块
关于MobileViT块的深入解析:
在MobileViT架构中,MobileViT块是关键组成部分,它融合了卷积和Transformer的优势。首先,输入的特征表示(A)通过一系列卷积层,这些卷积层专注于捕获图像中的局部细节和空间关系。这些特征图的典型形状是(h, w, num_channels),其中h代表高度,w代表宽度,num_channels是通道数。
随后,这些特征图被分割成一系列非重叠的小补丁(patches),每个补丁的大小为p×p,其中p表示补丁的边长。这些小补丁被重新组织成一个二维数组,形状为(p^2, n, num_channels),其中n表示整个图像中被分割成的补丁数量,计算公式为n = (h * w) / (p * p)。这个过程可以看作是“展开”操作,将二维特征图转化为一个包含多个补丁的一维序列。
接下来,这个一维序列通过Transformer块进行处理。Transformer块利用自注意力机制来捕获补丁之间的全局依赖关系,从而能够捕捉图像中的长距离依赖。这种全局建模能力是Transformer架构的核心优势,尤其对于理解复杂图像结构和识别高级别概念非常有效。
经过Transformer块处理后,输出向量(B)再次被“折叠”回二维特征图的形状(h, w, num_channels)。这个过程与之前的“展开”操作相反,它将一维序列重新组织成二维特征图,以便后续处理。
最后,原始的特征表示(A)和经过Transformer处理后的特征表示(B)通过两个额外的卷积层进行融合。这两个卷积层的作用是将局部和全局特征进行结合,生成更加丰富的特征表示。值得注意的是,在这个过程中,特征图的空间分辨率保持不变,这有助于保持模型对图像细节的敏感度。
从某种角度来看,MobileViT块可以被视为一种特殊的卷积块,它结合了卷积的局部特征提取能力和Transformer的全局建模能力。这种设计使得MobileViT架构能够在保持较低计算复杂度的同时,实现较高的图像分类准确率。
在构建MobileViT架构时,多个MobileViT块被组合在一起,形成一个完整的网络结构。以下是从原始论文中引用的示意图,展示了MobileViT架构的一个具体实例(如XXS变体):(请注意,由于这里不能直接插入图像,我们将省略具体的示意图。)
def create_mobilevit(num_classes=5):# 定义输入层,假设输入图像大小为 image_size x image_size,具有3个颜色通道。inputs = keras.Input((image_size, image_size, 3))# 对输入图像进行归一化处理,将像素值缩放到0到1之间。x = layers.Rescaling(scale=1.0 / 255)(inputs)# 开始卷积干线部分,使用 conv_block 函数创建第一个卷积层。x = conv_block(x, filters=16)# 使用 inverted_residual_block 函数创建 MobileNetV2 风格的反残差块。x = inverted_residual_block(x, expanded_channels=16 * expansion_factor, output_channels=16)# 使用 MV2 块进行下采样。# 第一次下采样,步长为2,输出通道数增加到24。x = inverted_residual_block(x, expanded_channels=16 * expansion_factor, output_channels=24, strides=2)# 继续使用 MV2 块进行特征提取,保持通道数不变。x = inverted_residual_block(x, expanded_channels=24 * expansion_factor, output_channels=24)# 再次使用 MV2 块进行特征提取。x = inverted_residual_block(x, expanded_channels=24 * expansion_factor, output_channels=24)# 第一个 MV2 块到 MobileViT 块的转换。# 第二次下采样,步长为2,输出通道数增加到48。x = inverted_residual_block(x, expanded_channels=24 * expansion_factor, output_channels=48, strides=2)# 使用 mobilevit_block 函数创建 MobileViT 块,包含2个 Transformer 层。x = mobilevit_block(x, num_blocks=2, projection_dim=64)# 第二个 MV2 块到 MobileViT 块的转换。# 继续下采样,步长为2,输出通道数增加到64。x = inverted_residual_block(x, expanded_channels=64 * expansion_factor, output_channels=64, strides=2)# 使用 mobilevit_block 函数创建 MobileViT 块,包含4个 Transformer 层。x = mobilevit_block(x, num_blocks=4, projection_dim=80)# 第三个 MV2 块到 MobileViT 块的转换。# 再次下采样,步长为2,输出通道数增加到80。x = inverted_residual_block(x, expanded_channels=80 * expansion_factor, output_channels=80, strides=2)# 使用 mobilevit_block 函数创建 MobileViT 块,包含3个 Transformer 层。x = mobilevit_block(x, num_blocks=3, projection_dim=96)# 使用 conv_block 进行1x1卷积,用于通道数的调整。x = conv_block(x, filters=320, kernel_size=1, strides=1)# 分类头,使用全局平均池化层和全连接层进行分类。x = layers.GlobalAvgPool2D()(x)outputs = layers.Dense(num_classes, activation="softmax")(x)# 创建 Keras 模型,输入为之前定义的 inputs,输出为分类结果 outputs。return keras.Model(inputs, outputs)# 实例化 MobileViT 模型,类别数默认为5。
mobilevit_xxs = create_mobilevit()
# 打印模型的概述信息,包括每层的输出形状和参数数量。
mobilevit_xxs.summary()
这段代码定义了一个创建MobileViT模型的函数 create_mobilevit,并实例化了这个模型,然后打印出了模型的概述。
-
函数定义:
create_mobilevit: 这个函数接受一个参数num_classes,表示分类任务的类别数,默认为5。
-
输入层:
inputs: 使用keras.Input定义模型的输入,假设输入图像的大小是image_size x image_size,具有3个颜色通道。
-
数据预处理:
Rescaling: 对输入图像进行重缩放,归一化到[0,1]区间。
-
初始卷积层:
conv_block: 应用一个卷积块作为模型的起始部分。
-
反残差块:
inverted_residual_block: 使用MobileNetV2中的反残差结构进行下采样和特征提取。
-
MobileViT块:
mobilevit_block: 结合了卷积和Transformer结构的MobileViT块,用于提取局部和全局特征。
-
分类头:
GlobalAvgPool2D: 使用全局平均池化层来减少特征的空间维度。Dense: 使用全连接层进行分类,激活函数为Softmax,输出类别概率。
-
模型实例化:
mobilevit_xxs: 调用create_mobilevit函数实例化MobileViT模型。
-
模型概述:
summary: 打印模型的概述信息,包括每层的名称、输出形状和参数数量。
这个函数构建了一个轻量级的深度学习模型,适用于移动设备上的图像分类任务。模型结合了卷积神经网络的局部特征提取能力和Transformer的全局特征提取能力,通过多个MobileViT块和反残差块进行特征提取,最终通过分类头输出预测结果。通过调用 mobilevit_xxs.summary(),用户可以快速了解模型的结构和参数量。
2.3 数据预处理
2.3.1.加载数据
我们将使用 tf_flowers 数据集来演示该模型。与其他基于Transformer的架构不同,MobileViT使用了一个简单的数据增强流程,这主要是因为它具有CNN(卷积神经网络)的特性。
# 定义批次大小和自动调优参数
batch_size = 64
auto = tf.data.AUTOTUNE
# 定义在训练时使用的更大的图像尺寸
resize_bigger = 280
# 定义类别数
num_classes = 5# 定义数据预处理函数
def preprocess_dataset(is_training=True):# 定义内部函数,用于处理单个图像和标签def _pp(image, label):if is_training:# 如果是在训练阶段,先将图像调整到更大的分辨率,然后随机裁剪到所需的尺寸image = tf.image.resize(image, (resize_bigger, resize_bigger))image = tf.image.random_crop(image, (image_size, image_size, 3))# 随机水平翻转图像image = tf.image.random_flip_left_right(image)else:# 如果是在测试或验证阶段,直接将图像调整到所需的尺寸image = tf.image.resize(image, (image_size, image_size))# 将标签转换为独热编码label = tf.one_hot(label, depth=num_classes)return image, label# 返回内部函数return _pp# 定义数据集准备函数
def prepare_dataset(dataset, is_training=True):# 如果是在训练阶段,先对数据集进行洗牌if is_training:dataset = dataset.shuffle(batch_size * 10)# 使用映射函数并行地应用预处理函数dataset = dataset.map(preprocess_dataset(is_training), num_parallel_calls=auto)# 将数据集分批并使用预取操作优化性能return dataset.batch(batch_size).prefetch(auto)
这段代码定义了两个函数,preprocess_dataset 和 prepare_dataset,用于准备和预处理数据集。preprocess_dataset 函数根据是否处于训练阶段,对图像执行不同的预处理操作,包括调整图像大小、随机裁剪、随机水平翻转和标签的独热编码。prepare_dataset 函数则用于对整个数据集应用预处理函数,并进行洗牌、分批处理和预取操作,以优化数据加载过程。
2.3.2. 数据预处理
# 使用 TensorFlow Datasets 库加载 tf_flowers 数据集,分为训练集和验证集。
# 训练集占90%,验证集占10%。
train_dataset, val_dataset = tfds.load("tf_flowers", split=["train[:90%]", "train[90%:]"], as_supervised=True
)# 获取训练集和验证集的样本数量。
num_train = train_dataset.cardinality()
num_val = val_dataset.cardinality()# 打印训练集和验证集的样本数量。
print(f"Number of training examples: {num_train}") # 训练样本数
print(f"Number of validation examples: {num_val}") # 验证样本数# 使用之前定义的 prepare_dataset 函数准备训练集和验证集。
# 训练集使用 is_training=True 进行数据增强。
train_dataset = prepare_dataset(train_dataset, is_training=True)
# 验证集使用 is_training=False,不进行数据增强。
val_dataset = prepare_dataset(val_dataset, is_training=False)
这段代码首先使用 TensorFlow Datasets (TFDS) 库加载了 tf_flowers 数据集,并将其划分为训练集和验证集,其中训练集占据了90%,验证集占据了剩余的10%。as_supervised=True 参数意味着数据集中的标签已经是监督信号,不需要进一步处理。
接着,通过调用 cardinality() 方法获取了训练集和验证集中样本的数量,并打印出来,以便了解数据集的规模。
最后,调用 prepare_dataset 函数对训练集和验证集进行进一步的准备,包括数据增强、批处理和预取操作。训练集的 is_training 参数设置为 True 以应用数据增强,而验证集的 is_training 参数设置为 False,通常不进行数据增强,以保持数据的原始分布。
2.4.训练MobileViT 模型
# 设置学习率和标签平滑因子。
learning_rate = 0.002
label_smoothing_factor = 0.1# 设置训练周期数。
epochs = 30# 创建 Adam 优化器并设置学习率。
optimizer = keras.optimizers.Adam(learning_rate=learning_rate)# 创建分类交叉熵损失函数,并设置标签平滑因子。
loss_fn = keras.losses.CategoricalCrossentropy(label_smoothing=label_smoothing_factor)# 定义运行实验的函数。
def run_experiment(epochs=epochs):# 创建 MobileViT 模型实例。mobilevit_xxs = create_mobilevit(num_classes=num_classes)# 编译模型,指定优化器、损失函数和评价指标。mobilevit_xxs.compile(optimizer=optimizer, loss=loss_fn, metrics=["accuracy"])# 设置检查点回调函数,保存验证准确率最高的模型权重。checkpoint_filepath = "/tmp/checkpoint.weights.h5"checkpoint_callback = keras.callbacks.ModelCheckpoint(checkpoint_filepath,monitor="val_accuracy",save_best_only=True,save_weights_only=True, # 指定仅保存模型权重)# 训练模型,使用训练数据集和验证数据集。mobilevit_xxs.fit(train_dataset,validation_data=val_dataset,epochs=epochs,callbacks=[checkpoint_callback],)# 加载最佳模型权重。mobilevit_xxs.load_weights(checkpoint_filepath)# 在验证数据集上评估模型,并打印准确率。_, accuracy = mobilevit_xxs.evaluate(val_dataset)print(f"Validation accuracy: {round(accuracy * 100, 2)}%") # 打印验证准确率return mobilevit_xxs# 调用实验函数,开始训练和评估过程。
mobilevit_xxs = run_experiment()
这段代码首先设置了模型训练所需的一些关键参数,包括学习率、标签平滑因子和训练周期数。然后定义了优化器和损失函数,其中损失函数采用了标签平滑技术,有助于提高模型的泛化能力。
run_experiment 函数负责创建 MobileViT 模型实例、编译模型、设置检查点回调、训练模型以及在验证集上评估模型的性能。训练过程中使用了早停法(Early Stopping)来保存最佳模型权重,避免过拟合。最后,函数返回训练好的模型,并打印出验证集上的准确率。
2.5.MobileViT与TFLite
结果和TFLite转换:使用大约一百万个参数,在256x256分辨率下达到约85%的top-1准确率是一个出色的结果。这款MobileViT模型与TensorFlow Lite(TFLite)完全兼容,可以使用以下代码进行转换:
以下是添加了中文注释的代码:
# 将模型序列化为 SavedModel 格式并保存到 "mobilevit_xxs" 文件夹。
tf.saved_model.save(mobilevit_xxs, "mobilevit_xxs")# 将 SavedModel 转换为 TFLite 格式。这里使用的是 TFLite 中的后训练动态范围量化。
converter = tf.lite.TFLiteConverter.from_saved_model("mobilevit_xxs")
# 设置优化类型为默认优化。
converter.optimizations = [tf.lite.Optimize.DEFAULT]
# 设置支持的操作集,包括 TensorFlow Lite 内置操作和 TensorFlow 操作。
converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS, # 启用 TensorFlow Lite 操作。tf.lite.OpsSet.SELECT_TF_OPS, # 启用 TensorFlow 操作。
]# 执行转换操作,得到 TFLite 模型。
tflite_model = converter.convert()# 将转换后的 TFLite 模型写入文件 "mobilevit_xxs.tflite"。
with open("mobilevit_xxs.tflite", "wb") as f:f.write(tflite_model)
这段代码首先将训练好的 mobilevit_xxs 模型序列化并保存为 SavedModel 格式。SavedModel 是 TensorFlow 的一种模型格式,可以保存模型结构、权重和训练配置。
然后,使用 tf.lite.TFLiteConverter 将 SavedModel 转换为 TFLite 格式。TFLite 是 TensorFlow 的轻量级解决方案,适用于移动和嵌入式设备。在转换过程中,设置了优化选项以减小模型大小并提高运行效率,并指定了模型支持的操作集。
最后,将转换后的 TFLite 模型写入到一个名为 “mobilevit_xxs.tflite” 的文件中。这样得到的 TFLite 模型可以被部署到移动设备或其它边缘设备上,进行高效的推理计算。
3. 总结与展望
3.1 总结
本文详细介绍了MobileViT模型的设计原理、架构组成以及在移动设备图像分类任务中的应用。MobileViT作为一种结合了Transformer和CNN优势的轻量级模型,已经在多个标准数据集上展现出了卓越的性能。以下是对全文内容的总结:
-
MobileViT架构:介绍了MobileViT的基本概念,包括其设计背景、技术特点、性能表现和适用场景。MobileViT通过轻量化的Transformer模块和有效的降维策略,实现了在移动设备上的高效运行。
-
Transformer架构特点:分析了Transformer架构的核心思想、组成组件和优势,特别是在并行处理能力和长距离依赖建模方面的表现。
-
研究内容:探讨了MobileViT的研究意义,包括其在移动设备上的应用需求、理论价值和实际应用前景。
-
模型部署:提供了使用TensorFlow和TFLite部署MobileViT模型的详细步骤,包括数据预处理、模型构建、训练和转换为TFLite格式。
-
模型结构与训练结果:附录中列出了MobileViT模型的具体结构和参数量,以及模型训练过程中的损失和准确率变化情况。
3.2 展望
虽然MobileViT在移动设备图像分类任务上取得了显著的成果,但仍有诸多方向值得未来的研究和探索:
-
模型优化:尽管MobileViT已经进行了轻量化设计,但仍有进一步优化模型结构和参数空间的潜力,以适应更多样化的移动设备。
-
多任务学习:将MobileViT扩展到多任务学习框架中,例如同时进行图像分类、目标检测和分割等任务。
-
跨领域应用:探索MobileViT在其他领域的应用,如视频处理、医疗影像分析等,以验证其泛化能力。
-
鲁棒性研究:研究MobileViT在不同环境和条件下的性能表现,提高模型的鲁棒性。
-
实时性能:针对实时应用场景,进一步优化MobileViT的推理速度和能耗效率。
-
模型压缩与加速:研究模型剪枝、量化等模型压缩技术,以减小模型大小和加速推理过程。
-
开源社区贡献:通过开源项目和社区合作,推动MobileViT的进一步开发和应用。
综上所述,MobileViT作为一种新型的移动视觉模型,不仅在理论上具有创新性,而且在实际应用中具有广泛的前景。随着移动设备计算能力的不断提升和深度学习技术的不断进步,MobileViT有望在未来的移动视觉领域发挥更大的作用。
附录1:模型结构
Model: "model"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_1 (InputLayer) [(None, 256, 256, 3) 0
__________________________________________________________________________________________________
rescaling (Rescaling) (None, 256, 256, 3) 0 input_1[0][0]
__________________________________________________________________________________________________
conv2d (Conv2D) (None, 128, 128, 16) 448 rescaling[0][0]
__________________________________________________________________________________________________
conv2d_1 (Conv2D) (None, 128, 128, 32) 512 conv2d[0][0]
__________________________________________________________________________________________________
batch_normalization (BatchNorma (None, 128, 128, 32) 128 conv2d_1[0][0]
__________________________________________________________________________________________________
tf.nn.silu (TFOpLambda) (None, 128, 128, 32) 0 batch_normalization[0][0]
__________________________________________________________________________________________________
depthwise_conv2d (DepthwiseConv (None, 128, 128, 32) 288 tf.nn.silu[0][0]
__________________________________________________________________________________________________
batch_normalization_1 (BatchNor (None, 128, 128, 32) 128 depthwise_conv2d[0][0]
__________________________________________________________________________________________________
tf.nn.silu_1 (TFOpLambda) (None, 128, 128, 32) 0 batch_normalization_1[0][0]
__________________________________________________________________________________________________
conv2d_2 (Conv2D) (None, 128, 128, 16) 512 tf.nn.silu_1[0][0]
__________________________________________________________________________________________________
batch_normalization_2 (BatchNor (None, 128, 128, 16) 64 conv2d_2[0][0]
__________________________________________________________________________________________________
add (Add) (None, 128, 128, 16) 0 batch_normalization_2[0][0] conv2d[0][0]
__________________________________________________________________________________________________
conv2d_3 (Conv2D) (None, 128, 128, 32) 512 add[0][0]
__________________________________________________________________________________________________
batch_normalization_3 (BatchNor (None, 128, 128, 32) 128 conv2d_3[0][0]
__________________________________________________________________________________________________
tf.nn.silu_2 (TFOpLambda) (None, 128, 128, 32) 0 batch_normalization_3[0][0]
__________________________________________________________________________________________________
zero_padding2d (ZeroPadding2D) (None, 129, 129, 32) 0 tf.nn.silu_2[0][0]
__________________________________________________________________________________________________
depthwise_conv2d_1 (DepthwiseCo (None, 64, 64, 32) 288 zero_padding2d[0][0]
__________________________________________________________________________________________________
batch_normalization_4 (BatchNor (None, 64, 64, 32) 128 depthwise_conv2d_1[0][0]
__________________________________________________________________________________________________
tf.nn.silu_3 (TFOpLambda) (None, 64, 64, 32) 0 batch_normalization_4[0][0]
__________________________________________________________________________________________________
conv2d_4 (Conv2D) (None, 64, 64, 24) 768 tf.nn.silu_3[0][0]
__________________________________________________________________________________________________
batch_normalization_5 (BatchNor (None, 64, 64, 24) 96 conv2d_4[0][0]
__________________________________________________________________________________________________
conv2d_5 (Conv2D) (None, 64, 64, 48) 1152 batch_normalization_5[0][0]
__________________________________________________________________________________________________
batch_normalization_6 (BatchNor (None, 64, 64, 48) 192 conv2d_5[0][0]
__________________________________________________________________________________________________
tf.nn.silu_4 (TFOpLambda) (None, 64, 64, 48) 0 batch_normalization_6[0][0]
__________________________________________________________________________________________________
depthwise_conv2d_2 (DepthwiseCo (None, 64, 64, 48) 432 tf.nn.silu_4[0][0]
__________________________________________________________________________________________________
batch_normalization_7 (BatchNor (None, 64, 64, 48) 192 depthwise_conv2d_2[0][0]
__________________________________________________________________________________________________
tf.nn.silu_5 (TFOpLambda) (None, 64, 64, 48) 0 batch_normalization_7[0][0]
__________________________________________________________________________________________________
conv2d_6 (Conv2D) (None, 64, 64, 24) 1152 tf.nn.silu_5[0][0]
__________________________________________________________________________________________________
batch_normalization_8 (BatchNor (None, 64, 64, 24) 96 conv2d_6[0][0]
__________________________________________________________________________________________________
add_1 (Add) (None, 64, 64, 24) 0 batch_normalization_8[0][0] batch_normalization_5[0][0]
__________________________________________________________________________________________________
conv2d_7 (Conv2D) (None, 64, 64, 48) 1152 add_1[0][0]
__________________________________________________________________________________________________
batch_normalization_9 (BatchNor (None, 64, 64, 48) 192 conv2d_7[0][0]
__________________________________________________________________________________________________
tf.nn.silu_6 (TFOpLambda) (None, 64, 64, 48) 0 batch_normalization_9[0][0]
__________________________________________________________________________________________________
depthwise_conv2d_3 (DepthwiseCo (None, 64, 64, 48) 432 tf.nn.silu_6[0][0]
__________________________________________________________________________________________________
batch_normalization_10 (BatchNo (None, 64, 64, 48) 192 depthwise_conv2d_3[0][0]
__________________________________________________________________________________________________
tf.nn.silu_7 (TFOpLambda) (None, 64, 64, 48) 0 batch_normalization_10[0][0]
__________________________________________________________________________________________________
conv2d_8 (Conv2D) (None, 64, 64, 24) 1152 tf.nn.silu_7[0][0]
__________________________________________________________________________________________________
batch_normalization_11 (BatchNo (None, 64, 64, 24) 96 conv2d_8[0][0]
__________________________________________________________________________________________________
add_2 (Add) (None, 64, 64, 24) 0 batch_normalization_11[0][0] add_1[0][0]
__________________________________________________________________________________________________
conv2d_9 (Conv2D) (None, 64, 64, 48) 1152 add_2[0][0]
__________________________________________________________________________________________________
batch_normalization_12 (BatchNo (None, 64, 64, 48) 192 conv2d_9[0][0]
__________________________________________________________________________________________________
tf.nn.silu_8 (TFOpLambda) (None, 64, 64, 48) 0 batch_normalization_12[0][0]
__________________________________________________________________________________________________
zero_padding2d_1 (ZeroPadding2D (None, 65, 65, 48) 0 tf.nn.silu_8[0][0]
__________________________________________________________________________________________________
depthwise_conv2d_4 (DepthwiseCo (None, 32, 32, 48) 432 zero_padding2d_1[0][0]
__________________________________________________________________________________________________
batch_normalization_13 (BatchNo (None, 32, 32, 48) 192 depthwise_conv2d_4[0][0]
__________________________________________________________________________________________________
tf.nn.silu_9 (TFOpLambda) (None, 32, 32, 48) 0 batch_normalization_13[0][0]
__________________________________________________________________________________________________
conv2d_10 (Conv2D) (None, 32, 32, 48) 2304 tf.nn.silu_9[0][0]
__________________________________________________________________________________________________
batch_normalization_14 (BatchNo (None, 32, 32, 48) 192 conv2d_10[0][0]
__________________________________________________________________________________________________
conv2d_11 (Conv2D) (None, 32, 32, 64) 27712 batch_normalization_14[0][0]
__________________________________________________________________________________________________
conv2d_12 (Conv2D) (None, 32, 32, 64) 4160 conv2d_11[0][0]
__________________________________________________________________________________________________
reshape (Reshape) (None, 4, 256, 64) 0 conv2d_12[0][0]
__________________________________________________________________________________________________
layer_normalization (LayerNorma (None, 4, 256, 64) 128 reshape[0][0]
__________________________________________________________________________________________________
multi_head_attention (MultiHead (None, 4, 256, 64) 33216 layer_normalization[0][0] layer_normalization[0][0]
__________________________________________________________________________________________________
add_3 (Add) (None, 4, 256, 64) 0 multi_head_attention[0][0] reshape[0][0]
__________________________________________________________________________________________________
layer_normalization_1 (LayerNor (None, 4, 256, 64) 128 add_3[0][0]
__________________________________________________________________________________________________
dense (Dense) (None, 4, 256, 128) 8320 layer_normalization_1[0][0]
__________________________________________________________________________________________________
dropout (Dropout) (None, 4, 256, 128) 0 dense[0][0]
__________________________________________________________________________________________________
dense_1 (Dense) (None, 4, 256, 64) 8256 dropout[0][0]
__________________________________________________________________________________________________
dropout_1 (Dropout) (None, 4, 256, 64) 0 dense_1[0][0]
__________________________________________________________________________________________________
add_4 (Add) (None, 4, 256, 64) 0 dropout_1[0][0] add_3[0][0]
__________________________________________________________________________________________________
layer_normalization_2 (LayerNor (None, 4, 256, 64) 128 add_4[0][0]
__________________________________________________________________________________________________
multi_head_attention_1 (MultiHe (None, 4, 256, 64) 33216 layer_normalization_2[0][0] layer_normalization_2[0][0]
__________________________________________________________________________________________________
add_5 (Add) (None, 4, 256, 64) 0 multi_head_attention_1[0][0] add_4[0][0]
__________________________________________________________________________________________________
layer_normalization_3 (LayerNor (None, 4, 256, 64) 128 add_5[0][0]
__________________________________________________________________________________________________
dense_2 (Dense) (None, 4, 256, 128) 8320 layer_normalization_3[0][0]
__________________________________________________________________________________________________
dropout_2 (Dropout) (None, 4, 256, 128) 0 dense_2[0][0]
__________________________________________________________________________________________________
dense_3 (Dense) (None, 4, 256, 64) 8256 dropout_2[0][0]
__________________________________________________________________________________________________
dropout_3 (Dropout) (None, 4, 256, 64) 0 dense_3[0][0]
__________________________________________________________________________________________________
add_6 (Add) (None, 4, 256, 64) 0 dropout_3[0][0] add_5[0][0]
__________________________________________________________________________________________________
reshape_1 (Reshape) (None, 32, 32, 64) 0 add_6[0][0]
__________________________________________________________________________________________________
conv2d_13 (Conv2D) (None, 32, 32, 48) 3120 reshape_1[0][0]
__________________________________________________________________________________________________
concatenate (Concatenate) (None, 32, 32, 96) 0 batch_normalization_14[0][0] conv2d_13[0][0]
__________________________________________________________________________________________________
conv2d_14 (Conv2D) (None, 32, 32, 64) 55360 concatenate[0][0]
__________________________________________________________________________________________________
conv2d_15 (Conv2D) (None, 32, 32, 128) 8192 conv2d_14[0][0]
__________________________________________________________________________________________________
batch_normalization_15 (BatchNo (None, 32, 32, 128) 512 conv2d_15[0][0]
__________________________________________________________________________________________________
tf.nn.silu_10 (TFOpLambda) (None, 32, 32, 128) 0 batch_normalization_15[0][0]
__________________________________________________________________________________________________
zero_padding2d_2 (ZeroPadding2D (None, 33, 33, 128) 0 tf.nn.silu_10[0][0]
__________________________________________________________________________________________________
depthwise_conv2d_5 (DepthwiseCo (None, 16, 16, 128) 1152 zero_padding2d_2[0][0]
__________________________________________________________________________________________________
batch_normalization_16 (BatchNo (None, 16, 16, 128) 512 depthwise_conv2d_5[0][0]
__________________________________________________________________________________________________
tf.nn.silu_11 (TFOpLambda) (None, 16, 16, 128) 0 batch_normalization_16[0][0]
__________________________________________________________________________________________________
conv2d_16 (Conv2D) (None, 16, 16, 64) 8192 tf.nn.silu_11[0][0]
__________________________________________________________________________________________________
batch_normalization_17 (BatchNo (None, 16, 16, 64) 256 conv2d_16[0][0]
__________________________________________________________________________________________________
conv2d_17 (Conv2D) (None, 16, 16, 80) 46160 batch_normalization_17[0][0]
__________________________________________________________________________________________________
conv2d_18 (Conv2D) (None, 16, 16, 80) 6480 conv2d_17[0][0]
__________________________________________________________________________________________________
reshape_2 (Reshape) (None, 4, 64, 80) 0 conv2d_18[0][0]
__________________________________________________________________________________________________
layer_normalization_4 (LayerNor (None, 4, 64, 80) 160 reshape_2[0][0]
__________________________________________________________________________________________________
multi_head_attention_2 (MultiHe (None, 4, 64, 80) 51760 layer_normalization_4[0][0] layer_normalization_4[0][0]
__________________________________________________________________________________________________
add_7 (Add) (None, 4, 64, 80) 0 multi_head_attention_2[0][0] reshape_2[0][0]
__________________________________________________________________________________________________
layer_normalization_5 (LayerNor (None, 4, 64, 80) 160 add_7[0][0]
__________________________________________________________________________________________________
dense_4 (Dense) (None, 4, 64, 160) 12960 layer_normalization_5[0][0]
__________________________________________________________________________________________________
dropout_4 (Dropout) (None, 4, 64, 160) 0 dense_4[0][0]
__________________________________________________________________________________________________
dense_5 (Dense) (None, 4, 64, 80) 12880 dropout_4[0][0]
__________________________________________________________________________________________________
dropout_5 (Dropout) (None, 4, 64, 80) 0 dense_5[0][0]
__________________________________________________________________________________________________
add_8 (Add) (None, 4, 64, 80) 0 dropout_5[0][0] add_7[0][0]
__________________________________________________________________________________________________
layer_normalization_6 (LayerNor (None, 4, 64, 80) 160 add_8[0][0]
__________________________________________________________________________________________________
multi_head_attention_3 (MultiHe (None, 4, 64, 80) 51760 layer_normalization_6[0][0] layer_normalization_6[0][0]
__________________________________________________________________________________________________
add_9 (Add) (None, 4, 64, 80) 0 multi_head_attention_3[0][0] add_8[0][0]
__________________________________________________________________________________________________
layer_normalization_7 (LayerNor (None, 4, 64, 80) 160 add_9[0][0]
__________________________________________________________________________________________________
dense_6 (Dense) (None, 4, 64, 160) 12960 layer_normalization_7[0][0]
__________________________________________________________________________________________________
dropout_6 (Dropout) (None, 4, 64, 160) 0 dense_6[0][0]
__________________________________________________________________________________________________
dense_7 (Dense) (None, 4, 64, 80) 12880 dropout_6[0][0]
__________________________________________________________________________________________________
dropout_7 (Dropout) (None, 4, 64, 80) 0 dense_7[0][0]
__________________________________________________________________________________________________
add_10 (Add) (None, 4, 64, 80) 0 dropout_7[0][0] add_9[0][0]
__________________________________________________________________________________________________
layer_normalization_8 (LayerNor (None, 4, 64, 80) 160 add_10[0][0]
__________________________________________________________________________________________________
multi_head_attention_4 (MultiHe (None, 4, 64, 80) 51760 layer_normalization_8[0][0] layer_normalization_8[0][0]
__________________________________________________________________________________________________
add_11 (Add) (None, 4, 64, 80) 0 multi_head_attention_4[0][0] add_10[0][0]
__________________________________________________________________________________________________
layer_normalization_9 (LayerNor (None, 4, 64, 80) 160 add_11[0][0]
__________________________________________________________________________________________________
dense_8 (Dense) (None, 4, 64, 160) 12960 layer_normalization_9[0][0]
__________________________________________________________________________________________________
dropout_8 (Dropout) (None, 4, 64, 160) 0 dense_8[0][0]
__________________________________________________________________________________________________
dense_9 (Dense) (None, 4, 64, 80) 12880 dropout_8[0][0]
__________________________________________________________________________________________________
dropout_9 (Dropout) (None, 4, 64, 80) 0 dense_9[0][0]
__________________________________________________________________________________________________
add_12 (Add) (None, 4, 64, 80) 0 dropout_9[0][0] add_11[0][0]
__________________________________________________________________________________________________
layer_normalization_10 (LayerNo (None, 4, 64, 80) 160 add_12[0][0]
__________________________________________________________________________________________________
multi_head_attention_5 (MultiHe (None, 4, 64, 80) 51760 layer_normalization_10[0][0] layer_normalization_10[0][0]
__________________________________________________________________________________________________
add_13 (Add) (None, 4, 64, 80) 0 multi_head_attention_5[0][0] add_12[0][0]
__________________________________________________________________________________________________
layer_normalization_11 (LayerNo (None, 4, 64, 80) 160 add_13[0][0]
__________________________________________________________________________________________________
dense_10 (Dense) (None, 4, 64, 160) 12960 layer_normalization_11[0][0]
__________________________________________________________________________________________________
dropout_10 (Dropout) (None, 4, 64, 160) 0 dense_10[0][0]
__________________________________________________________________________________________________
dense_11 (Dense) (None, 4, 64, 80) 12880 dropout_10[0][0]
__________________________________________________________________________________________________
dropout_11 (Dropout) (None, 4, 64, 80) 0 dense_11[0][0]
__________________________________________________________________________________________________
add_14 (Add) (None, 4, 64, 80) 0 dropout_11[0][0] add_13[0][0]
__________________________________________________________________________________________________
reshape_3 (Reshape) (None, 16, 16, 80) 0 add_14[0][0]
__________________________________________________________________________________________________
conv2d_19 (Conv2D) (None, 16, 16, 64) 5184 reshape_3[0][0]
__________________________________________________________________________________________________
concatenate_1 (Concatenate) (None, 16, 16, 128) 0 batch_normalization_17[0][0] conv2d_19[0][0]
__________________________________________________________________________________________________
conv2d_20 (Conv2D) (None, 16, 16, 80) 92240 concatenate_1[0][0]
__________________________________________________________________________________________________
conv2d_21 (Conv2D) (None, 16, 16, 160) 12800 conv2d_20[0][0]
__________________________________________________________________________________________________
batch_normalization_18 (BatchNo (None, 16, 16, 160) 640 conv2d_21[0][0]
__________________________________________________________________________________________________
tf.nn.silu_12 (TFOpLambda) (None, 16, 16, 160) 0 batch_normalization_18[0][0]
__________________________________________________________________________________________________
zero_padding2d_3 (ZeroPadding2D (None, 17, 17, 160) 0 tf.nn.silu_12[0][0]
__________________________________________________________________________________________________
depthwise_conv2d_6 (DepthwiseCo (None, 8, 8, 160) 1440 zero_padding2d_3[0][0]
__________________________________________________________________________________________________
batch_normalization_19 (BatchNo (None, 8, 8, 160) 640 depthwise_conv2d_6[0][0]
__________________________________________________________________________________________________
tf.nn.silu_13 (TFOpLambda) (None, 8, 8, 160) 0 batch_normalization_19[0][0]
__________________________________________________________________________________________________
conv2d_22 (Conv2D) (None, 8, 8, 80) 12800 tf.nn.silu_13[0][0]
__________________________________________________________________________________________________
batch_normalization_20 (BatchNo (None, 8, 8, 80) 320 conv2d_22[0][0]
__________________________________________________________________________________________________
conv2d_23 (Conv2D) (None, 8, 8, 96) 69216 batch_normalization_20[0][0]
__________________________________________________________________________________________________
conv2d_24 (Conv2D) (None, 8, 8, 96) 9312 conv2d_23[0][0]
__________________________________________________________________________________________________
reshape_4 (Reshape) (None, 4, 16, 96) 0 conv2d_24[0][0]
__________________________________________________________________________________________________
layer_normalization_12 (LayerNo (None, 4, 16, 96) 192 reshape_4[0][0]
__________________________________________________________________________________________________
multi_head_attention_6 (MultiHe (None, 4, 16, 96) 74400 layer_normalization_12[0][0] layer_normalization_12[0][0]
__________________________________________________________________________________________________
add_15 (Add) (None, 4, 16, 96) 0 multi_head_attention_6[0][0] reshape_4[0][0]
__________________________________________________________________________________________________
layer_normalization_13 (LayerNo (None, 4, 16, 96) 192 add_15[0][0]
__________________________________________________________________________________________________
dense_12 (Dense) (None, 4, 16, 192) 18624 layer_normalization_13[0][0]
__________________________________________________________________________________________________
dropout_12 (Dropout) (None, 4, 16, 192) 0 dense_12[0][0]
__________________________________________________________________________________________________
dense_13 (Dense) (None, 4, 16, 96) 18528 dropout_12[0][0]
__________________________________________________________________________________________________
dropout_13 (Dropout) (None, 4, 16, 96) 0 dense_13[0][0]
__________________________________________________________________________________________________
add_16 (Add) (None, 4, 16, 96) 0 dropout_13[0][0] add_15[0][0]
__________________________________________________________________________________________________
layer_normalization_14 (LayerNo (None, 4, 16, 96) 192 add_16[0][0]
__________________________________________________________________________________________________
multi_head_attention_7 (MultiHe (None, 4, 16, 96) 74400 layer_normalization_14[0][0] layer_normalization_14[0][0]
__________________________________________________________________________________________________
add_17 (Add) (None, 4, 16, 96) 0 multi_head_attention_7[0][0] add_16[0][0]
__________________________________________________________________________________________________
layer_normalization_15 (LayerNo (None, 4, 16, 96) 192 add_17[0][0]
__________________________________________________________________________________________________
dense_14 (Dense) (None, 4, 16, 192) 18624 layer_normalization_15[0][0]
__________________________________________________________________________________________________
dropout_14 (Dropout) (None, 4, 16, 192) 0 dense_14[0][0]
__________________________________________________________________________________________________
dense_15 (Dense) (None, 4, 16, 96) 18528 dropout_14[0][0]
__________________________________________________________________________________________________
dropout_15 (Dropout) (None, 4, 16, 96) 0 dense_15[0][0]
__________________________________________________________________________________________________
add_18 (Add) (None, 4, 16, 96) 0 dropout_15[0][0] add_17[0][0]
__________________________________________________________________________________________________
layer_normalization_16 (LayerNo (None, 4, 16, 96) 192 add_18[0][0]
__________________________________________________________________________________________________
multi_head_attention_8 (MultiHe (None, 4, 16, 96) 74400 layer_normalization_16[0][0] layer_normalization_16[0][0]
__________________________________________________________________________________________________
add_19 (Add) (None, 4, 16, 96) 0 multi_head_attention_8[0][0] add_18[0][0]
__________________________________________________________________________________________________
layer_normalization_17 (LayerNo (None, 4, 16, 96) 192 add_19[0][0]
__________________________________________________________________________________________________
dense_16 (Dense) (None, 4, 16, 192) 18624 layer_normalization_17[0][0]
__________________________________________________________________________________________________
dropout_16 (Dropout) (None, 4, 16, 192) 0 dense_16[0][0]
__________________________________________________________________________________________________
dense_17 (Dense) (None, 4, 16, 96) 18528 dropout_16[0][0]
__________________________________________________________________________________________________
dropout_17 (Dropout) (None, 4, 16, 96) 0 dense_17[0][0]
__________________________________________________________________________________________________
add_20 (Add) (None, 4, 16, 96) 0 dropout_17[0][0] add_19[0][0]
__________________________________________________________________________________________________
reshape_5 (Reshape) (None, 8, 8, 96) 0 add_20[0][0]
__________________________________________________________________________________________________
conv2d_25 (Conv2D) (None, 8, 8, 80) 7760 reshape_5[0][0]
__________________________________________________________________________________________________
concatenate_2 (Concatenate) (None, 8, 8, 160) 0 batch_normalization_20[0][0] conv2d_25[0][0]
__________________________________________________________________________________________________
conv2d_26 (Conv2D) (None, 8, 8, 96) 138336 concatenate_2[0][0]
__________________________________________________________________________________________________
conv2d_27 (Conv2D) (None, 8, 8, 320) 31040 conv2d_26[0][0]
__________________________________________________________________________________________________
global_average_pooling2d (Globa (None, 320) 0 conv2d_27[0][0]
__________________________________________________________________________________________________
dense_18 (Dense) (None, 5) 1605 global_average_pooling2d[0][0]
==================================================================================================
Total params: 1,307,621
Trainable params: 1,305,077
Non-trainable params: 2,544
附录2:模型训练结果
Epoch 1/30
52/52 [==============================] - 47s 459ms/step - loss: 1.3397 - accuracy: 0.4832 - val_loss: 1.7250 - val_accuracy: 0.1662
Epoch 2/30
52/52 [==============================] - 21s 404ms/step - loss: 1.1167 - accuracy: 0.6210 - val_loss: 1.9844 - val_accuracy: 0.1907
Epoch 3/30
52/52 [==============================] - 21s 403ms/step - loss: 1.0217 - accuracy: 0.6709 - val_loss: 1.8187 - val_accuracy: 0.1907
Epoch 4/30
52/52 [==============================] - 21s 409ms/step - loss: 0.9682 - accuracy: 0.7048 - val_loss: 2.0329 - val_accuracy: 0.1907
Epoch 5/30
52/52 [==============================] - 21s 408ms/step - loss: 0.9552 - accuracy: 0.7196 - val_loss: 2.1150 - val_accuracy: 0.1907
Epoch 6/30
52/52 [==============================] - 21s 407ms/step - loss: 0.9186 - accuracy: 0.7318 - val_loss: 2.9713 - val_accuracy: 0.1907
Epoch 7/30
52/52 [==============================] - 21s 407ms/step - loss: 0.8986 - accuracy: 0.7457 - val_loss: 3.2062 - val_accuracy: 0.1907
Epoch 8/30
52/52 [==============================] - 21s 408ms/step - loss: 0.8831 - accuracy: 0.7542 - val_loss: 3.8631 - val_accuracy: 0.1907
Epoch 9/30
52/52 [==============================] - 21s 408ms/step - loss: 0.8433 - accuracy: 0.7714 - val_loss: 1.8029 - val_accuracy: 0.3542
Epoch 10/30
52/52 [==============================] - 21s 408ms/step - loss: 0.8489 - accuracy: 0.7763 - val_loss: 1.7920 - val_accuracy: 0.4796
Epoch 11/30
52/52 [==============================] - 21s 409ms/step - loss: 0.8256 - accuracy: 0.7884 - val_loss: 1.4992 - val_accuracy: 0.5477
Epoch 12/30
52/52 [==============================] - 21s 407ms/step - loss: 0.7859 - accuracy: 0.8123 - val_loss: 0.9236 - val_accuracy: 0.7330
Epoch 13/30
52/52 [==============================] - 21s 409ms/step - loss: 0.7702 - accuracy: 0.8159 - val_loss: 0.8059 - val_accuracy: 0.8011
Epoch 14/30
52/52 [==============================] - 21s 403ms/step - loss: 0.7670 - accuracy: 0.8153 - val_loss: 1.1535 - val_accuracy: 0.7084
Epoch 15/30
52/52 [==============================] - 21s 408ms/step - loss: 0.7332 - accuracy: 0.8344 - val_loss: 0.7746 - val_accuracy: 0.8147
Epoch 16/30
52/52 [==============================] - 21s 404ms/step - loss: 0.7284 - accuracy: 0.8335 - val_loss: 1.0342 - val_accuracy: 0.7330
Epoch 17/30
52/52 [==============================] - 21s 409ms/step - loss: 0.7484 - accuracy: 0.8262 - val_loss: 1.0523 - val_accuracy: 0.7112
Epoch 18/30
52/52 [==============================] - 21s 408ms/step - loss: 0.7209 - accuracy: 0.8450 - val_loss: 0.8146 - val_accuracy: 0.8174
Epoch 19/30
52/52 [==============================] - 21s 409ms/step - loss: 0.7141 - accuracy: 0.8435 - val_loss: 0.8016 - val_accuracy: 0.7875
Epoch 20/30
52/52 [==============================] - 21s 410ms/step - loss: 0.7075 - accuracy: 0.8435 - val_loss: 0.9352 - val_accuracy: 0.7439
Epoch 21/30
52/52 [==============================] - 21s 406ms/step - loss: 0.7066 - accuracy: 0.8504 - val_loss: 1.0171 - val_accuracy: 0.7139
Epoch 22/30
52/52 [==============================] - 21s 405ms/step - loss: 0.6913 - accuracy: 0.8532 - val_loss: 0.7059 - val_accuracy: 0.8610
Epoch 23/30
52/52 [==============================] - 21s 408ms/step - loss: 0.6681 - accuracy: 0.8671 - val_loss: 0.8007 - val_accuracy: 0.8147
Epoch 24/30
52/52 [==============================] - 21s 409ms/step - loss: 0.6636 - accuracy: 0.8747 - val_loss: 0.9490 - val_accuracy: 0.7302
Epoch 25/30
52/52 [==============================] - 21s 408ms/step - loss: 0.6637 - accuracy: 0.8722 - val_loss: 0.6913 - val_accuracy: 0.8556
Epoch 26/30
52/52 [==============================] - 21s 406ms/step - loss: 0.6443 - accuracy: 0.8837 - val_loss: 1.0483 - val_accuracy: 0.7139
Epoch 27/30
52/52 [==============================] - 21s 407ms/step - loss: 0.6555 - accuracy: 0.8695 - val_loss: 0.9448 - val_accuracy: 0.7602
Epoch 28/30
52/52 [==============================] - 21s 409ms/step - loss: 0.6409 - accuracy: 0.8807 - val_loss: 0.9337 - val_accuracy: 0.7302
Epoch 29/30
52/52 [==============================] - 21s 408ms/step - loss: 0.6300 - accuracy: 0.8910 - val_loss: 0.7461 - val_accuracy: 0.8256
Epoch 30/30
52/52 [==============================] - 21s 408ms/step - loss: 0.6093 - accuracy: 0.8968 - val_loss: 0.8651 - val_accuracy: 0.7766
6/6 [==============================] - 0s 65ms/step - loss: 0.7059 - accuracy: 0.8610
Validation accuracy: 86.1%
相关文章:
【机器学习】基于Transformer架构的移动设备图像分类模型MobileViT
1.引言 1.1. MobileViT是什么? MobileViT是一种基于Transformer的轻量级视觉模型,专为移动端设备上的图像分类任务而设计。 背景与目的: MobileViT由Google在2021年提出,旨在解决移动设备上的实时图像分类需求。与传统的卷积神…...

grub引导LinuxMint
注意事项:文件系统必须是FAT32 安装 sudo apt install gparted -y 分区管理软件 使用gparted分区和查看设备路径 sudo apt-get install grub-efi-amd64 #/dev/sdd1 是需要制作分区引导的设备路径 sudo mount /dev/sdd1 /mnt/123 #bios sudo grub-install --targe…...

Hadoop 2.0:主流开源云架构(四)
目录 五、Hadoop 2.0访问接口(一)访问接口综述(二)浏览器接口(三)命令行接口 六、Hadoop 2.0编程接口(一)HDFS编程(二)Yarn编程 五、Hadoop 2.0访问接口 &am…...

PythonSQL应用随笔4——PySpark创建SQL临时表
零、前言 Python中直接跑SQL,可以很好的解决数据导过来导过去的问题,本文方法主要针对大运算量时,如何更好地让Python和SQL打好配合。 工具:Zeppelin 语法:PySpark(Apache Spark的Python API)…...

C# OpenCvSharp 矩阵计算-determinant、trace、eigen、calcCovarMatrix、solve
🚀 在C#中使用OpenCvSharp库进行矩阵操作和图像处理 在C#中使用OpenCvSharp库,可以实现各种矩阵操作和图像处理功能。以下是对所列函数的详细解释和示例,包括运算过程和结果。📊✨ 1. determinant - 计算行列式 🧮 定义: double determinant(InputArray mtx); 参数…...

知识普及:什么是边缘计算(Edge Computing)?
边缘计算是一种分布式计算架构,它将数据处理、存储和服务功能移近数据产生的边缘位置,即接近数据源和用户的位置,而不是依赖中心化的数据中心或云计算平台。边缘计算的核心思想是在靠近终端设备的位置进行数据处理,以降低延迟、减…...

大型企业IT基础架构和应用运维体系
大型企业IT基础架构和应用运维体系 在数字化转型的浪潮中,大型企业面临着日益复杂的IT环境。高效的IT基础架构和应用运维体系,是确保企业业务连续性和竞争力的关键。本文将探讨大型企业如何构建强健的IT基础架构,并建立高效的应用运维体系&a…...
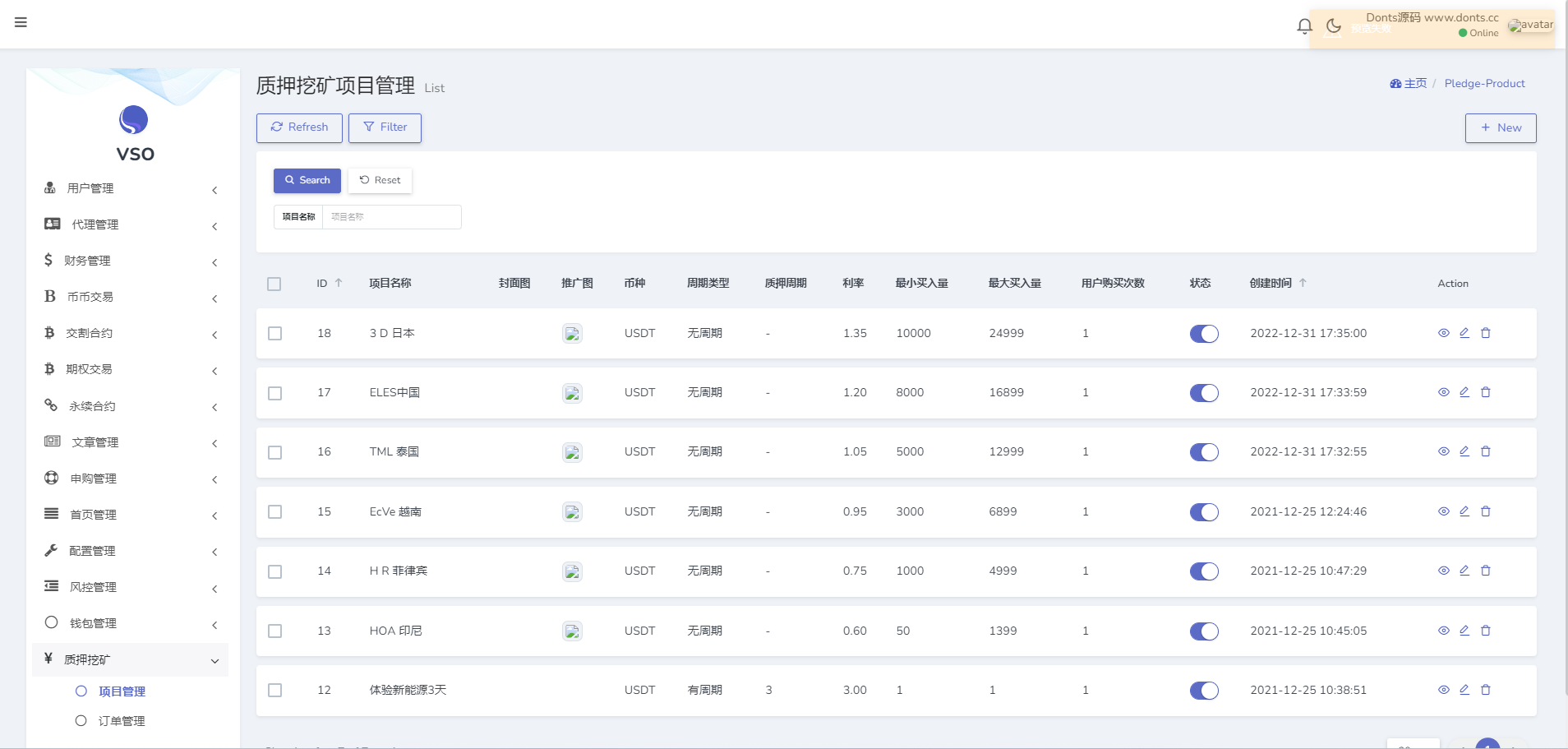
【源码】16国语言交易所源码/币币交易+期权交易+秒合约交易+永续合约+交割合约+新币申购+投资理财/手机端uniapp纯源码+PC纯源码+后端PHP
测试环境:Linux系统CentOS7.6、宝塔面板、Nginx、PHP7.3、MySQL5.6,根目录public,伪静态laravel5,开启ssl证书 语言:16种,看图 这套带前端uniapp纯源码,手机端和pc端都有纯源码,后…...

word空白页删除不了怎么办?
上方菜单栏点击“视图”,下方点击“大纲视图”。找到文档分页符的位置。将光标放在要删除的分节符前,按下键盘上的“Delet”键删除分页符。...
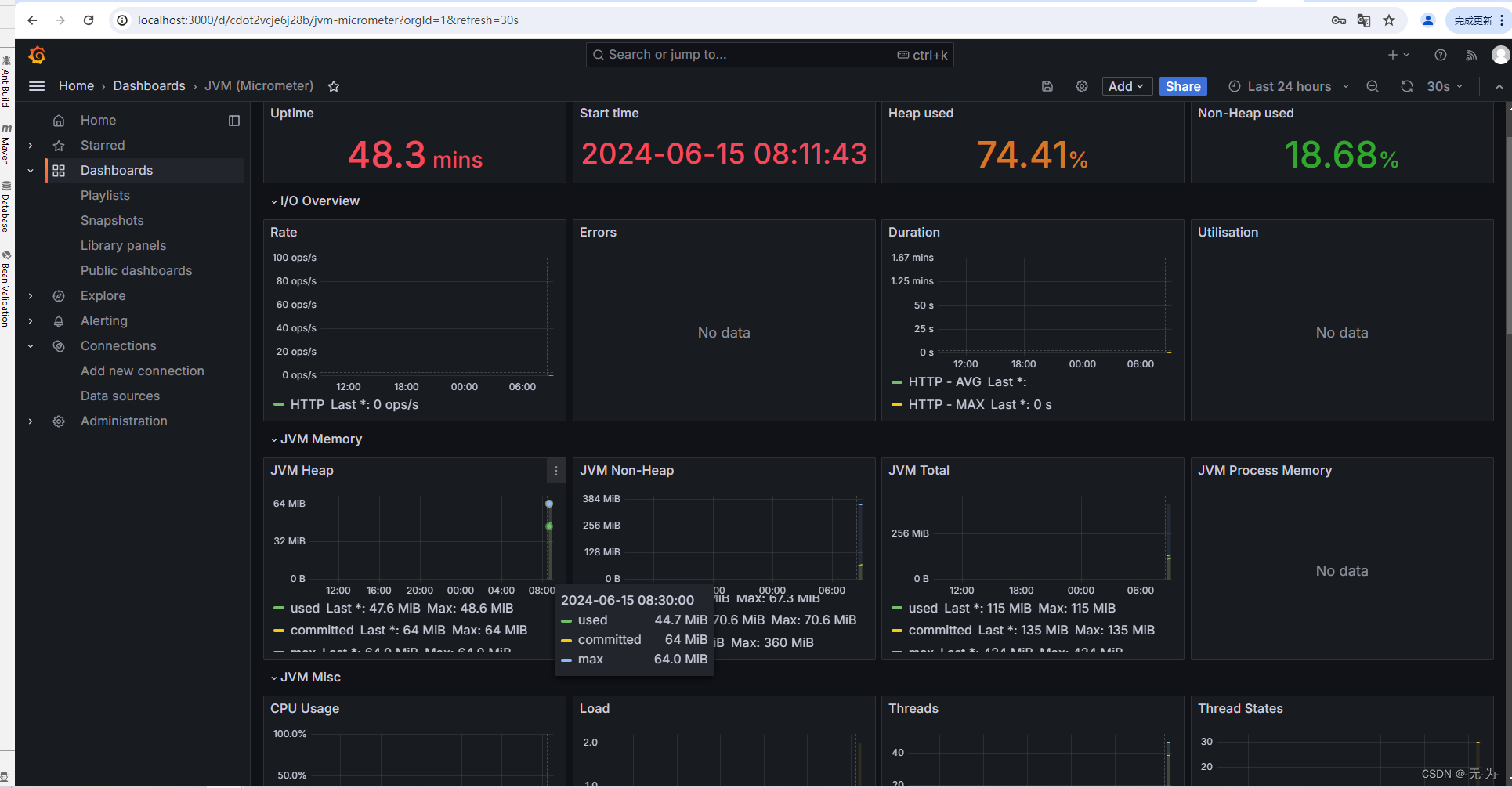
Java web应用性能分析之【prometheus+Grafana监控springboot服务和服务器监控】
Java web应用性能分析之【java进程问题分析概叙】-CSDN博客 Java web应用性能分析之【java进程问题分析工具】-CSDN博客 Java web应用性能分析之【jvisualvm远程连接云服务器】-CSDN博客 Java web应用性能分析之【java进程问题分析定位】-CSDN博客 Java web应用性能分析之【…...

JavaEE——声明式事务管理案例:实现用户登录
一、案例要求 本案例要求在控制台输入用户名密码,如果用户账号密码正确则显示用户所属班级,如果登录失败则显示登录失败。实现用户登录项目运行成功后控制台效果如下所示。 欢迎来到学生管理系统 请输入用户名: zhangsan 请输入zhangsan的密…...

解决用Three.js实现嘴型和语音同步时只能播放部分部位的问题 Three.js同时渲染播放多个组件变形动画的方法
前言 参考这篇文章ThreeJSChatGPT 实现前端3D数字人AI互动,前面搭后端、训练模型组内小伙伴都没有什么问题,到前端的时候,脸部就出问题了。看我是怎么解决的。 好文章啊,可惜百度前几个都找不到,o(╥﹏╥)o 问题情况 …...
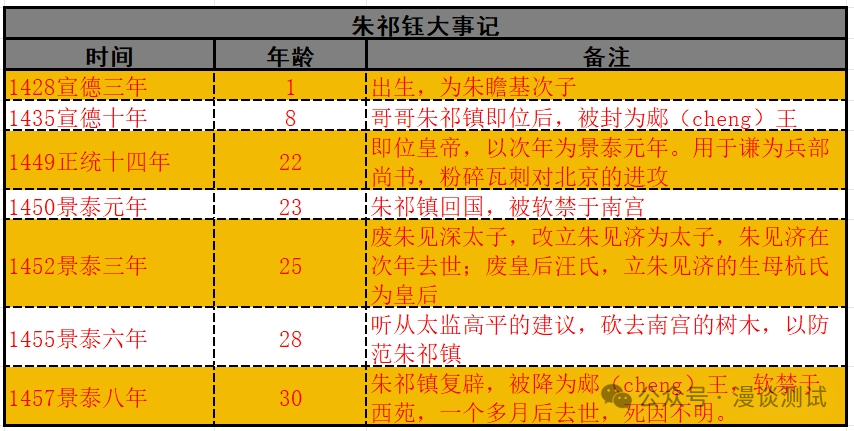
阅读笔记:明朝那些事儿太监弄乱的王朝
阅读豆评高分作品《明朝那些事儿太监弄乱的王朝》第三部,截止到今天告一段落了,前两部皇帝,太子相对比较少,了解故事的主线,分支不算多,记忆起来还能应付过来,第三部皇帝,太子更换的…...
算法第六天:力扣第977题有序数组的平方
一、977.有序数组的平方的链接与题目描述 977. 有序数组的平方的链接如下所示:https://leetcode.cn/problems/squares-of-a-sorted-array/description/https://leetcode.cn/problems/squares-of-a-sorted-array/description/ 给你一个按 非递减顺序 排序的整数数组…...

设计模式学习(二)工厂模式——工厂方法模式
设计模式学习(二)工厂模式——工厂方法模式 前言工厂方法模式简介示例优点缺点使用场景 前言 前一篇文章介绍了简单工厂模式,提到了简单工厂模式的缺点(违反开闭原则,扩展困难),本文要介绍的工…...

TCP与UDP案例
udp不会做拆分整合什么的 多大就是多大...

Adaboost集成学习 | Matlab实现基于CNN-LSTM-Adaboost集成学习时间序列预测(股票价格预测)
目录 效果一览基本介绍模型设计程序设计参考资料 效果一览 基本介绍 Adaboost集成学习 | Matlab实现基于CNN-LSTM-Adaboost集成学习时间序列预测(股票价格预测) 模型设计 融合Adaboost的CNN-LSTM模型的时间序列预测,下面是一个基本的框架。 …...

你焦虑了吗
前段时间,无意间在图书馆看到一本书《认知觉醒》,书中提到了焦虑的相关话题,从焦虑的根源,焦虑的形式,如何破解焦虑给了我点启示,分享给一下。 引语: 焦虑肯定是你的老朋友了,它总像…...

一键分析Bulk转录组数据
我们前面介绍了经典的转录组分析流程:Hisat2 Stringtie,可以帮助用户快速获得基因的表达量矩阵。 云上生信,未来已来 | 转录组标准分析流程重磅上线! RNA STAR 也是一款非常流行的转录组数据分析工具。它不仅可以将测序 Reads 比…...
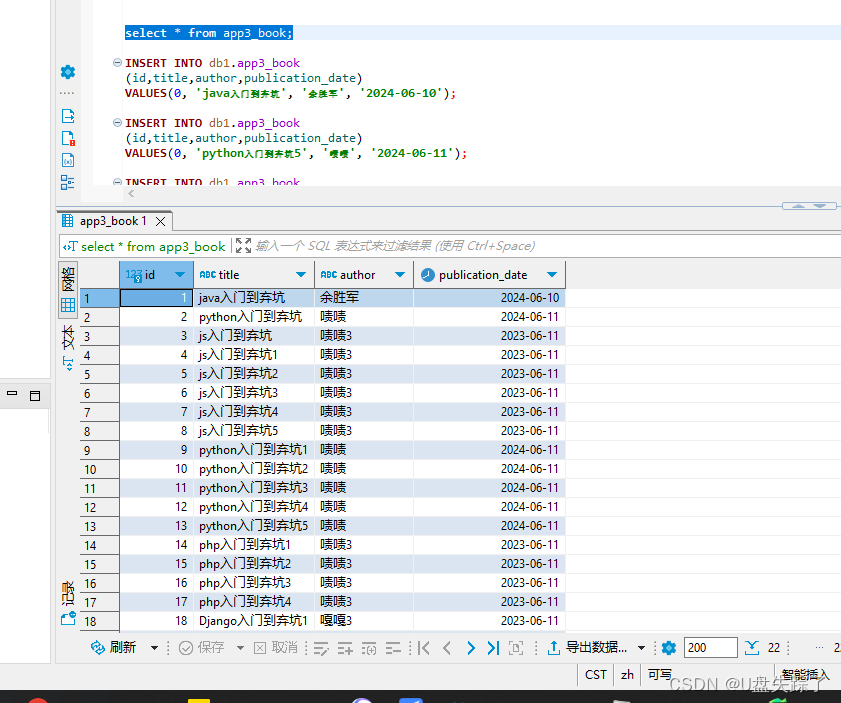
Django DetailView视图
Django的DetailView是一个用于显示单个对象详情的视图。下面是一个使用DetailView来显示单个书籍详情的例子。 1,添加视图 Test/app3/views.py from django.shortcuts import render# Create your views here. from django.views.generic import ListView from .m…...

Nintendo Switch游戏安装终极指南:3种方法解决所有格式兼容问题
Nintendo Switch游戏安装终极指南:3种方法解决所有格式兼容问题 【免费下载链接】Awoo-Installer A No-Bullshit NSP, NSZ, XCI, and XCZ Installer for Nintendo Switch 项目地址: https://gitcode.com/gh_mirrors/aw/Awoo-Installer 还在为Nintendo Switch…...

SmartNIC如何优化AI流水线与网络计算卸载
1. SmartNIC与AI流水线的联姻:网络计算卸载的技术革命 在分布式AI推理场景中,我们常常遇到一个令人头疼的现象:当GPU计算单元满载运行时,CPU利用率也常常飙升至90%以上。这种资源争用并非来自模型推理本身,而是源于那些…...

OpenClaw-Skills:模块化自动化技能库的设计、开发与编排实战
1. 项目概述与核心价值最近在GitHub上看到一个挺有意思的项目,叫blessonism/openclaw-skills。光看名字,你可能会有点摸不着头脑,这“OpenClaw”和“Skills”组合在一起,到底想干什么?作为一个在开源社区和自动化工具领…...

芯片入门必看:CPU、MCU、SoC、GPU、TPU、NPU
本文首先介绍了芯片的基础分类,包括模拟/数字芯片和逻辑/计算芯片。接着,对8类核心芯片进行了通俗解析,包括CPU、MCU、SoC、GPU、TPU、NPU、FPGA和DSP,涵盖了它们的定义、用途、类型和代表性标的。最后,文章从通用性和…...

ComfyUI-WanVideoWrapper:一站式AI视频生成插件解决方案
ComfyUI-WanVideoWrapper:一站式AI视频生成插件解决方案 【免费下载链接】ComfyUI-WanVideoWrapper 项目地址: https://gitcode.com/GitHub_Trending/co/ComfyUI-WanVideoWrapper ComfyUI-WanVideoWrapper是一个专为ComfyUI设计的视频生成插件包装器&#x…...

Cartographer闭环优化里的‘分支定界’:一个机器人SLAM工程师的实战笔记与避坑心得
Cartographer闭环优化中的分支定界算法:工程实践与性能调优指南 在SLAM(即时定位与地图构建)领域,闭环检测的准确性直接决定了系统长期运行的稳定性。作为Cartographer算法的核心组件之一,分支定界(Branch …...

为OpenClaw智能体工作流配置持久化的大模型服务支持
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为OpenClaw智能体工作流配置持久化的大模型服务支持 在构建基于OpenClaw的智能体工作流时,一个稳定、可靠的后端大模型…...

工程师视角:最低成本脱碳路径与气候解决方案的工程化思维
1. 项目概述:一封关于气候与经济的公开信最近在EE Times上读到一封写给埃隆马斯克的公开信,作者格伦温瑞布提出了一些关于气候变化和联邦预算赤字的想法,挺有意思的。这封信的核心不是空谈环保理念,而是从一个工程师和务实主义者的…...

用o1-preview构建端到端水质分类系统
1. 项目概述:用 o1-preview 构建端到端水质分类系统的真实复现手记 我做机器学习项目快十年了,从最早手动调参、写 Makefile 编译模型,到后来用 MLflow 跟踪实验、用 Flask 封装 API,再到如今用 Docker 打包上云——整个流程早已刻…...

基于Claude API的智能代理框架:从架构设计到实战应用
1. 项目概述:一个面向Claude API的智能代理框架最近在折腾AI应用开发,特别是围绕Anthropic的Claude模型构建自动化工作流时,发现了一个挺有意思的开源项目——CLAUDGENCY。这个项目由开发者Aviralx77创建,本质上是一个专门为Claud…...