具有 Hudi、MinIO 和 HMS 的现代数据湖

Apache Hudi 已成为管理现代数据湖的领先开放表格式之一,直接在现代数据湖中提供核心仓库和数据库功能。这在很大程度上要归功于 Hudi 提供了表、事务、更新/删除、高级索引、流式摄取服务、数据聚类/压缩优化和并发控制等高级功能。
我们已经探讨了 MinIO 和 Hudi 如何协同构建现代数据湖。这篇博文旨在建立在这些知识的基础上,并提供利用 Hive 元存储服务 (HMS) 的 Hudi 和 MinIO 的替代实现。部分源于Hadoop生态系统的起源故事,Hudi的许多大规模数据实现仍然利用HMS。通常,从遗留系统迁移的故事涉及某种程度的混合,因为所有涉及的产品中最好的产品都被用来取得成功。
Hudi 谈 MinIO:一个成功的组合
Hudi 从依赖 HDFS 到云原生对象存储(如 MinIO)的演变与数据行业从单一和不适当的传统解决方案的转变完全吻合。MinIO 的性能、可扩展性和成本效益使其成为存储和管理 Hudi 数据的理想选择。此外,Hudi 针对现代数据中的 Apache Spark、Flink、Presto、Trino、StarRocks 等的优化与 MinIO 无缝集成,以实现大规模的云原生性能。这种兼容性代表了现代数据湖架构中的一种重要模式。

HMS集成:增强数据治理和管理
虽然Hudi提供了开箱即用的核心数据管理功能,但与HMS的集成增加了另一层控制和可见性。以下是HMS集成如何使大规模Hudi部署受益:
-
改进数据治理:HMS集中管理元数据,实现数据湖的一致访问控制、沿袭跟踪和审计。这可确保数据质量、合规性并简化治理流程。
-
简化架构管理:在HMS内定义和实施Hudi表的架构,确保跨流水线和应用的数据一致性和兼容性。HMS模式演进功能允许在不破坏管道的情况下适应不断变化的数据结构。
-
增强的可见性和发现性:HMS为您的所有数据资产(包括Hudi表)提供中央目录。这有助于分析师和数据科学家轻松发现和探索数据。
入门:满足先决条件
要完成本教程,您需要设置一些软件。以下是您需要的内容的细分:
-
Docker 引擎:这个强大的工具允许您在称为容器的标准化软件单元中打包和运行应用程序。
-
Docker Compose:它充当业务流程协调程序,简化多容器应用程序的管理。它有助于轻松定义和运行复杂的应用程序。
**安装:**如果您要重新开始,Docker 桌面安装程序提供了一个方便的一站式解决方案,用于在特定平台(Windows、macOS 或 Linux)上安装 Docker 和 Docker Compose。这通常被证明比单独下载和安装它们更容易。
安装 Docker Desktop 或 Docker 和 Docker Compose 的组合后,可以通过在终端中运行以下命令来验证它们的存在:
docker-compose --version
请注意,本教程是为 linux/amd64 构建的,要使其适用于 Mac M2 芯片,您还需要安装 Rosetta 2。您可以通过运行以下命令在终端窗口中执行此操作:
softwareupdate --install-rosetta
在 Docker 桌面设置中,您还需要启用使用 Rosetta 在 Apple Silicone 上进行 x86_64/amd64 二进制仿真。为此,请导航到“设置”→“常规”,然后选中“罗塞塔”框,如下所示。

在MinIO上将HMS与Hudi集成
本教程使用 StarRock 的 demo 存储库。克隆在此处找到的存储库。在终端窗口中,导航到 documentation-samples 目录,然后 hudi 导航到文件夹,然后运行以下命令:
docker compose up
运行上述命令后,您应该会看到 StarRocks、HMS 和 MinIO 已启动并运行。
访问 MinIO 控制台 http://localhost:9000/ 并使用凭证登录 admin:password ,以查看存储桶 warehouse 是否已自动创建。

使用 Spark Scala 插入数据
执行以下命令,访问 spark-hudi 容器内的shell。
docker exec -it hudi-spark-hudi-1 /bin/bash
然后运行以下命令,这将带您进入 Spark REPL:
/spark-3.2.1-bin-hadoop3.2/bin/spark-shell
进入 shell 后,执行以下 Scala 行以创建数据库、表并将数据插入该表中:
import org.apache.spark.sql.functions._
import org.apache.spark.sql.types._
import org.apache.spark.sql.Row
import org.apache.spark.sql.SaveMode._
import org.apache.hudi.DataSourceReadOptions._
import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.config.HoodieWriteConfig._
import scala.collection.JavaConversions._val schema = StructType(Array(StructField("language", StringType, true),StructField("users", StringType, true),StructField("id", StringType, true)
))val rowData= Seq(Row("Java", "20000", "a"),Row("Python", "100000", "b"),Row("Scala", "3000", "c")
)val df = spark.createDataFrame(rowData, schema)val databaseName = "hudi_sample"
val tableName = "hudi_coders_hive"
val basePath = "s3a://warehouse/hudi_coders"df.write.format("hudi").option(org.apache.hudi.config.HoodieWriteConfig.TABLE_NAME, tableName).option(RECORDKEY_FIELD_OPT_KEY, "id").option(PARTITIONPATH_FIELD_OPT_KEY, "language").option(PRECOMBINE_FIELD_OPT_KEY, "users").option("hoodie.datasource.write.hive_style_partitioning", "true").option("hoodie.datasource.hive_sync.enable", "true").option("hoodie.datasource.hive_sync.mode", "hms").option("hoodie.datasource.hive_sync.database", databaseName).option("hoodie.datasource.hive_sync.table", tableName).option("hoodie.datasource.hive_sync.partition_fields", "language").option("hoodie.datasource.hive_sync.partition_extractor_class", "org.apache.hudi.hive.MultiPartKeysValueExtractor").option("hoodie.datasource.hive_sync.metastore.uris", "thrift://hive-metastore:9083").mode(Overwrite).save(basePath)
就是这样。您现在已经使用 Hudi 和 HMS 设置了 MinIO 数据湖。导航回以 http://localhost:9000/ 查看您的仓库文件夹是否已填充。
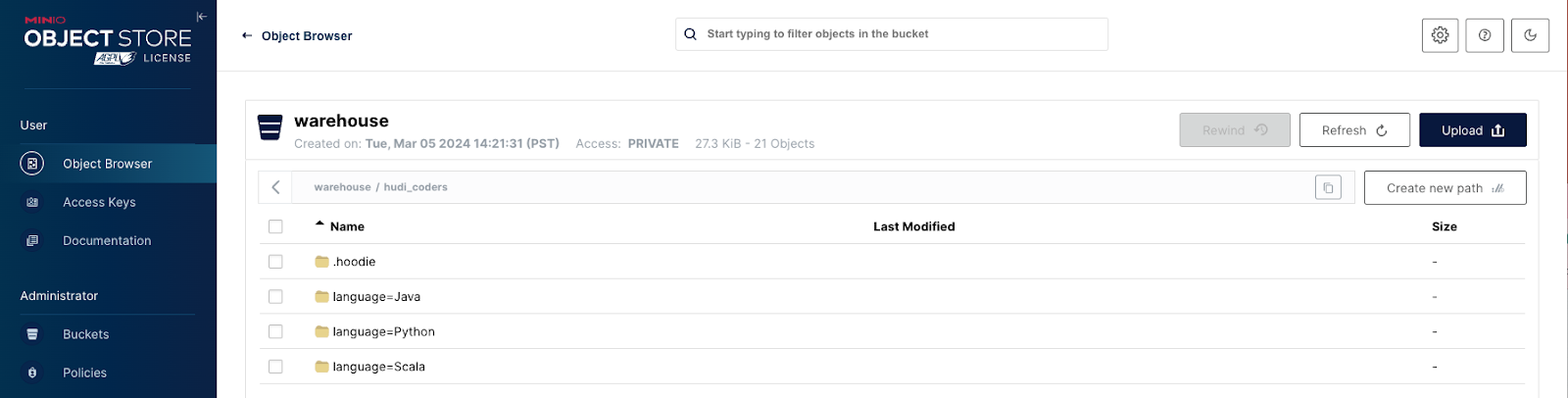
数据探索
您可以选择通过在同一 Shell 中利用以下 Scala 来进一步探索您的数据。
val hudiDF = spark.read.format("hudi").load(basePath + "/*/*")hudiDF.show()val languageUserCount = hudiDF.groupBy("language").agg(sum("users").as("total_users"))
languageUserCount.show()val uniqueLanguages = hudiDF.select("language").distinct()
uniqueLanguages.show()// Stop the Spark session
System.exit(0)
立即开始构建云原生现代数据湖
Hudi、MinIO和HMS无缝协作,为构建和管理大规模现代数据湖提供全面的解决方案。通过集成这些技术,您可以获得释放数据全部潜力所需的敏捷性、可扩展性和安全性。
相关文章:
具有 Hudi、MinIO 和 HMS 的现代数据湖
Apache Hudi 已成为管理现代数据湖的领先开放表格式之一,直接在现代数据湖中提供核心仓库和数据库功能。这在很大程度上要归功于 Hudi 提供了表、事务、更新/删除、高级索引、流式摄取服务、数据聚类/压缩优化和并发控制等高级功能。 我们已经探讨了 MinIO 和 Hudi…...
32.基于分隔符解决黏包和半包
LineBasedFrameDecoder 基于换行/n (linux)或回车换行/r/n(windows)进行分割。 使用LIneBasedFrameDecoder构造方法,需要设定一个最大长度。 如果超过了最大长度,还是没有找到换行符,就这位这个数据段太长了,抛出ToolLongFrameException DelimiterBasedFrameDecoder …...
)
2024-6-19(沉默springboot)
1.spring开启事务支持 事务在逻辑上是一组操作,要么执行,要不都不执行。主要是针对数据库而言的,比如说 MySQL。 业务场景eg: public void savePosts(PostsParam postsParam) {// 保存文章save(posts);// 处理标签insertOrUpdateTag(posts…...

three.js 第八节 - gltf加载器、解码器
// ts-nocheck // 引入three.js import * as THREE from three // 导入轨道控制器 import { OrbitControls } from three/examples/jsm/controls/OrbitControls // 导入hdr加载器(专门加载hdr的) import { RGBELoader } from three/examples/jsm/loaders…...
Aquila-Med LLM:开创性的全流程开源医疗语言模型
论文链接:https://arxiv.org/pdf/2406.12182 开源链接:https://huggingface.co/BAAI/AquilaMed-RL http://open.flopsera.com/flopsera-open/details/AquilaMed_SFT http://open.flopsera.com/flopsera-open/details/AquilaMed_DPO 近年来…...

快速排序总结
标准模版 交换法 单函数法 public static void quickSort(int[] arr, int start, int end) {if (start > end) {return;}int idx start;int pivot arr[idx];int left start, right end;while (left < right) {while (left < right && arr[right] > …...
探索Linux的奇妙世界:第二关---Linux的基本指令1
1. xshell与服务器的连接 想必大家在看过上一期视频时已经搭建好了Linux的环境了并且已经下好了终端---xshell了吧?让我来带大家看一看下好了是什么样子的: 第一次登陆会让你连接你的服务器,就是我们买的云服务器,买完之后需要把公网地址ip复制过来进行链接,需要用户名和密码连…...

荒野大镖客2启动找不到emp.dll的7个修复方法,轻松解决dll丢失的办法
一、emp.dll文件丢失的常见原因 安装或更新问题:在软件或游戏的安装过程中,可能由于安装程序未能正确复制文件到目标目录,或在更新过程中文件被意外覆盖或删除,导致emp.dll文件丢失。 安全软件误删:某些安全软件可能…...

数据库精选题(三)(SQL语言精选题)(按语句类型分类)
🌈 个人主页:十二月的猫-CSDN博客 🔥 系列专栏: 🏀数据库 💪🏻 十二月的寒冬阻挡不了春天的脚步,十二点的黑夜遮蔽不住黎明的曙光 目录 前言 创建语句 创建表 创建视图 创建索引…...

Spring Boot + Apache Tika 实现文档内容解析
文章目录 1. 环境准备2. 创建 Spring Boot 项目2.1 初始化项目2.2 添加 Apache Tika 依赖 3. 创建文档解析服务3.1 创建服务类3.2 创建控制器类 4. 配置和运行4.1 配置 Apache Tika 数据文件4.2 运行应用程序 5. 测试和验证5.1 使用 Postman 或 cURL 进行测试 6. 注意事项和优化…...

AcWing 255. 第K小数
自己想出来的,感觉要容易想到,使用可持久化线段树,时间上要比y的慢一倍。大体思想就是,我们从小到大依次加入一个数,每加入一个就记录一个版本,线段树里记录区间里数的数量,在查询时,…...

Nginx - 反向代理、负载均衡、动静分离、底层原理(案例实战分析)
目录 Nginx 开始 概述 安装(非 Docker) 配置环境变量 常用命令 配置文件概述 location 路径匹配方式 配置反向代理 实现效果 准备工作 具体配置 效果演示 配置负载均衡 实现效果 准备工作 具体配置 实现效果 其他负载均衡策略 配置动…...

从零开始精通Onvif之用户管理
💡 如果想阅读最新的文章,或者有技术问题需要交流和沟通,可搜索并关注微信公众号“希望睿智”。 概述 用户管理是Onvif协议的重要组成部分,它允许系统管理员通过网络接口创建、删除、修改用户账户,并分配不同的权限&am…...
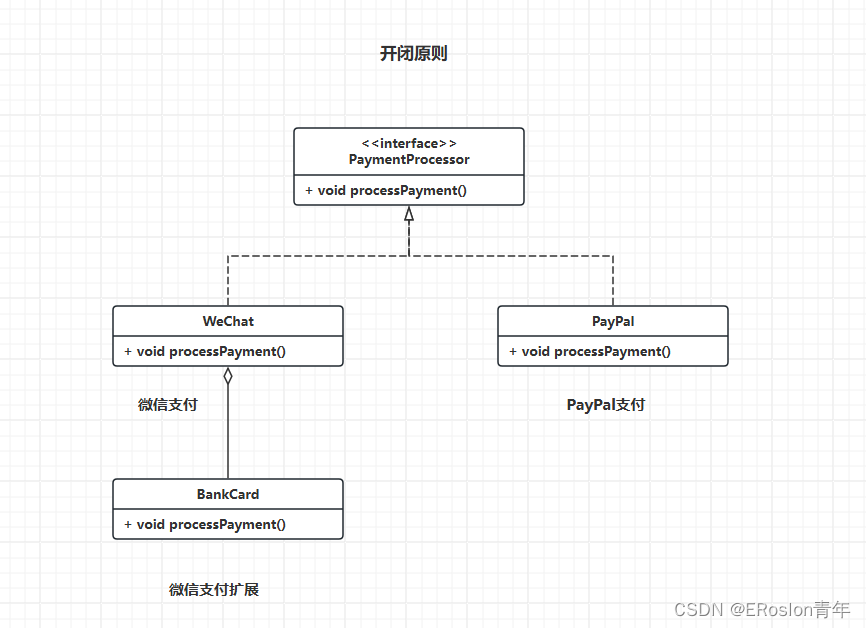
设计模式——设计模式原则
设计模式 设计模式示例代码库地址: https://gitee.com/Jasonpupil/designPatterns 设计模式原则 单一职责原则(SPS): 又称单一功能原则,面向对象五个基本原则(SOLID)之一 原则定义…...
链表中环的入口节点
链表中环的入口节点 描述 链表中环的入口节点 给一个长度为n链表,若其中包含环,请找出该链表的环的入口结点,否则,返回null。 数据范围: n≤10000, 1<结点值<10000 要求:空间复杂度 O(1)…...

STL——函数对象,谓词
一、函数对象 1.函数对象概念 概念: 重载函数调用操作符的类,其对象常称为函数对象。 函数对象使用重载的()时,行为类似函数调用,也叫仿函数。 本质: 函数对象(仿函数)是一个类,不是一个函数。 2.函数对象…...

【区分vue2和vue3下的element UI Descriptions 描述列表组件,分别详细介绍属性,事件,方法如何使用,并举例】
在 Element UI(为 Vue 2 设计)和 Element Plus(为 Vue 3 设计)中,Descriptions(描述列表)组件通常用于展示一系列的结构化信息。然而,需要明确的是,Element UI 官方库中并…...

atcoder abc 358
A welcome to AtCoder Land 题目: 思路:字符串比较 代码: #include <bits/stdc.h>using namespace std;int main() {string a, b;cin >> a >> b;if(a "AtCoder" && b "Land") cout <&…...
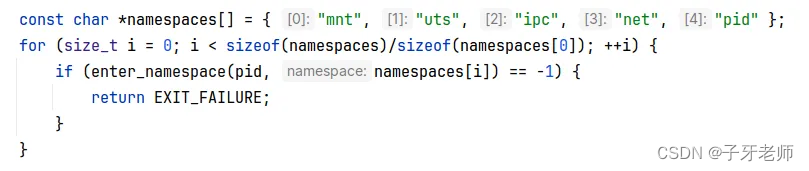
手写docker:你先玩转namespace再来吧
哈喽,我是子牙老师。今天咱们聊聊Linux namespace 瓦特?你没听过namespace?那有必要科普一下了:namespace是Linux内核提供的一种软件性质的资源隔离机制。容器化技术,比如docker,就是基于这样的机制实现的…...

注册安全分析报告:PingPong
前言 由于网站注册入口容易被黑客攻击,存在如下安全问题: 暴力破解密码,造成用户信息泄露短信盗刷的安全问题,影响业务及导致用户投诉带来经济损失,尤其是后付费客户,风险巨大,造成亏损无底洞 …...

北京交通大学校内邮箱配置指南:Windows与Mac系统自带邮件应用全攻略
1. 为什么需要配置校内邮箱? 作为北京交通大学的师生,校内邮箱是重要的通讯工具。无论是接收学校通知、提交作业,还是与导师同学沟通,都需要用到这个官方邮箱。很多同学第一次使用时,可能会被各种服务器设置搞得一头雾…...

避坑指南:在昇腾Atlas服务器部署FunASR说话人分离模型时,如何解决Torch_npu版本冲突和依赖问题
昇腾Atlas服务器部署FunASR说话人分离模型的实战避坑手册 当你在昇腾Atlas服务器上第一次尝试部署FunASR说话人分离模型时,可能会遇到各种意想不到的问题。从Torch_npu版本冲突到CANN兼容性问题,再到量化配置的坑,每一步都可能让你陷入调试的…...

剪映API技术解析:如何通过代码驱动实现视频剪辑自动化与效率革命
剪映API技术解析:如何通过代码驱动实现视频剪辑自动化与效率革命 【免费下载链接】JianYingApi Third Party JianYing Api. 第三方剪映Api 项目地址: https://gitcode.com/gh_mirrors/ji/JianYingApi 在视频内容创作进入工业化生产的今天,传统手动…...

3个维度解锁抖音内容采集:从个人创作到企业运营的效率革命
3个维度解锁抖音内容采集:从个人创作到企业运营的效率革命 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback s…...

零root权限+40%成本下降!OpenClaw Podman容器化部署全攻略,AWS Graviton+ECR打造AI Agent生产环境
本文已收录于《OpenClaw 实战指南》专栏,所有方案均经过AWS生产环境反复验证,覆盖从环境初始化到高可用集群部署全流程,附可直接复制的标准化部署脚本、Dockerfile模板、IAM权限配置与高频踩坑解决方案,适合AI Agent开发者、DevOp…...
正确配对Linkage Mapper和Circuitscape?)
生态安全格局分析第一步:如何为你的ArcGIS版本(10.0-10.8/Pro)正确配对Linkage Mapper和Circuitscape?
生态安全格局分析工具链的版本兼容性全解析:从ArcGIS到Linkage Mapper的精准匹配 当你在深夜的办公室里盯着屏幕,反复尝试让Linkage Mapper与Circuitscape协同工作时,是否曾因版本不匹配而遭遇令人崩溃的错误提示?作为生态安全格局…...

PptxGenJS:重新定义JavaScript驱动的演示文稿自动化
PptxGenJS:重新定义JavaScript驱动的演示文稿自动化 【免费下载链接】PptxGenJS Build PowerPoint presentations with JavaScript. Works with Node, React, web browsers, and more. 项目地址: https://gitcode.com/gh_mirrors/pp/PptxGenJS 在当今数据驱动…...

幻兽帕鲁跨平台存档修复与数据迁移完全指南:解决GUID冲突的5步实战方案
幻兽帕鲁跨平台存档修复与数据迁移完全指南:解决GUID冲突的5步实战方案 【免费下载链接】palworld-host-save-fix Fixes the bug which forces a player to create a new character when they already have a save. Useful for migrating maps from co-op to dedica…...

5个核心功能彻底解决暗黑2单机玩家的终极痛点:PlugY完全指南
5个核心功能彻底解决暗黑2单机玩家的终极痛点:PlugY完全指南 【免费下载链接】PlugY PlugY, The Survival Kit - Plug-in for Diablo II Lord of Destruction 项目地址: https://gitcode.com/gh_mirrors/pl/PlugY 还在为暗黑破坏神2单机模式中储物空间不足而…...

如何提升桌面互动体验?BongoCat的个性化配置方案
如何提升桌面互动体验?BongoCat的个性化配置方案 【免费下载链接】BongoCat 🐱 跨平台互动桌宠 BongoCat,为桌面增添乐趣! 项目地址: https://gitcode.com/gh_mirrors/bong/BongoCat 在数字化工作与娱乐日益融合的今天&…...