数据迁移到 Django 模型表:详尽指南
数据迁移是许多应用程序开发过程中必不可少的一部分。在这篇文章中,我们将详细分析和总结如何通过一个定制的 Django 管理命令,将数据从 MySQL 数据库迁移到 Django 模型表中。这种方法可以确保数据在多个数据库之间有效且安全地迁移,同时避免了手动操作的繁琐和错误。
项目概览
我们将实现一个 Django 管理命令,该命令将从 MySQL 数据库中提取数据并批量插入到 Django 模型表中。这个过程将使用事务处理来确保数据一致性,并通过记录偏移量来支持断点续传。
代码详解
首先,我们需要定义一个 Django 管理命令。以下是完整的代码:
import os
import traceback
import mysql.connector
from django.db import transaction
from mysql.connector import Error
from django.core.management.base import BaseCommand
from myapp.models import HotSearchTermsReportABAdb_config = {# MySQL 数据库配置
}class Command(BaseCommand):help = '数据迁移到 Django 模型表'def handle(self, *args, **kwargs):try:db_conn = mysql.connector.connect(**db_config)db_cursor = db_conn.cursor()self.stdout.write(self.style.SUCCESS("正在连接数据库"))except Error as e:self.stdout.write(self.style.ERROR(f"连接过程中出现异常:{e}"))self.stdout.write(self.style.ERROR(str(traceback.format_exc())))returnperiod = '最新'fetch_sql = f"""SELECT search_rank, search_term FROM hot_terms_table WHERE period = '{period}' LIMIT %s OFFSET %s;"""# 批量大小batch_size = 5000# 读取偏移量offset = self.get_last_offset()total_rows_transferred = 0try:while True:db_cursor.execute(fetch_sql, (batch_size, offset))batch_data = db_cursor.fetchall()if not batch_data:break # 如果没有更多的数据,退出循环# 将batch_data转换为HotSearchTermsReportABA对象列表objects = [HotSearchTermsReportABA(search_rank=row[0],search_term=row[1]) for row in batch_data]with transaction.atomic(): # 开启事务# 在Django中批量创建对象HotSearchTermsReportABA.objects.bulk_create(objects)# 更新偏移量和总条数offset += batch_sizetotal_rows_transferred += len(batch_data)self.stdout.write(self.style.SUCCESS(f"{len(batch_data)} 行数据已在此批中转移。"))self.stdout.write(self.style.SUCCESS(f"总共完成将 {total_rows_transferred} 行数据转移。"))# 更新文件中的偏移量self.update_last_offset(offset)except Error as e:self.stdout.write(self.style.ERROR(f"传输过程中出现异常:{e}"))self.stdout.write(self.style.ERROR(str(traceback.format_exc())))finally:# 关闭所有连接和游标if db_cursor:db_cursor.close()if db_conn:db_conn.close()def get_last_offset(self):# 从文件中读取偏移量offset_file = 'migration_offset.txt'if os.path.exists(offset_file):with open(offset_file, 'r') as file:return int(file.read().strip())return 0def update_last_offset(self, offset):# 将偏移量写入文件offset_file = 'migration_offset.txt'with open(offset_file, 'w') as file:file.write(str(offset))# python manage.py migrate_data代码分析
数据库连接
首先,代码尝试连接到 MySQL 数据库。如果连接失败,会捕获异常并输出错误信息。
try:db_conn = mysql.connector.connect(**db_config)db_cursor = db_conn.cursor()self.stdout.write(self.style.SUCCESS("正在连接数据库"))
except Error as e:self.stdout.write(self.style.ERROR(f"连接过程中出现异常:{e}"))self.stdout.write(self.style.ERROR(str(traceback.format_exc())))returnSQL 查询与数据提取
接下来,代码定义了一个 SQL 查询语句,用于从 hot_search_terms_report 表中获取数据。使用 LIMIT 和 OFFSET 实现分页读取数据。
period = '最新'
fetch_sql = f"""SELECT search_rank, search_term FROM hot_terms_table WHERE period = '{period}' LIMIT %s OFFSET %s;
"""
batch_size = 5000
offset = self.get_last_offset()
total_rows_transferred = 0数据迁移与事务处理
代码使用一个循环来分页读取数据,并将数据转换为 Django 模型对象,然后使用事务处理将数据批量插入到 Django 数据库中。事务处理确保数据的一致性,即使在插入过程中发生错误,也能回滚事务。
try:while True:db_cursor.execute(fetch_sql, (batch_size, offset))batch_data = db_cursor.fetchall()if not batch_data:break # 如果没有更多的数据,退出循环objects = [HotSearchTermsReportABA(search_rank=row[0],search_term=row[1]) for row in batch_data]with transaction.atomic():HotSearchTermsReportABA.objects.bulk_create(objects)offset += batch_sizetotal_rows_transferred += len(batch_data)self.stdout.write(self.style.SUCCESS(f"{len(batch_data)} 行数据已在此批中转移。"))self.stdout.write(self.style.SUCCESS(f"总共完成了将 {total_rows_transferred} 行数据转移。"))self.update_last_offset(offset)偏移量管理
为了支持断点续传,代码会将每次读取的数据偏移量存储在一个文件中。下次运行时,会从该文件读取偏移量,继续上次未完成的迁移任务。
def get_last_offset(self):offset_file = 'migration_offset.txt'if os.path.exists(offset_file):with open(offset_file, 'r') as file:return int(file.read().strip())return 0def update_last_offset(self, offset):offset_file = 'migration_offset.txt'with open(offset_file, 'w') as file:file.write(str(offset))使用方法
-
配置数据库连接: 在
db_config中填写你的 MySQL 数据库连接配置。 -
创建 Django 管理命令: 将上述代码保存为
management/commands/migrate_data.py文件。 -
运行命令: 使用以下命令运行数据迁移:
python manage.py migrate_data总结
通过这种方法,我们可以实现从 MySQL 数据库到 Django 模型表的高效、安全的数据迁移。事务处理和偏移量管理的引入,不仅确保了数据的一致性和完整性,还为大规模数据迁移提供了良好的支持。这种方法同样适用于其他类似的数据迁移任务,具有很高的通用性和实用性。
作者:pycode
链接:https://juejin.cn/post/7382931501607059490
相关文章:

数据迁移到 Django 模型表:详尽指南
数据迁移是许多应用程序开发过程中必不可少的一部分。在这篇文章中,我们将详细分析和总结如何通过一个定制的 Django 管理命令,将数据从 MySQL 数据库迁移到 Django 模型表中。这种方法可以确保数据在多个数据库之间有效且安全地迁移,同时避免…...

代码随想三刷二叉树篇4
代码随想三刷二叉树篇4 617. 合并二叉树题目代码 700. 二叉搜索树中的搜索题目代码 98. 验证二叉搜索树题目代码 530. 二叉搜索树的最小绝对差题目代码 501. 二叉搜索树中的众数题目代码 236. 二叉树的最近公共祖先题目代码 617. 合并二叉树 题目 链接 代码 /*** Definitio…...

『大模型笔记』如何让小型语言模型发挥作用!
如何让小型语言模型发挥作用! 文章目录 一. 如何让小型语言模型发挥作用!不可能的可能性小模型的潜力创新方法与突破实践与验证过滤系统与数据质量小模型的逐步改进信息理论蒸馏方法(新工作InfoSum)总结与展望Infini-Gram与N-gram模型的新时代后缀数组与高速计算二. 参考文献…...

jnp.diag
jnp.diag 是 JAX 库中用于创建对角矩阵或提取对角线元素的函数。具体功能取决于输入的形状: 当输入是一维数组时,jnp.diag 创建一个以该数组为对角线元素的对角矩阵。当输入是二维数组时,jnp.diag 提取并返回对角线元素。 函数签名 jnp.di…...

bert文本分类微调笔记
Bert实现文本分类微调Demo import random from collections import namedtuple 有四种文本需要做分类,请使用bert处理这个分类问题 # 使用namedtuple定义一个类别(Category),包含两个字段:名称(name)和样例(samples) Category namedtuple(Ca…...

运维:k8s常用命令大全
Kubernetes是一个强大的容器编排平台,不管是运维、开发还是测试或多或少都会接触到,熟练的掌握k8s可大大提高工作效率和强化自身技能。 集群管理 1. 查看集群节点状态: kubectl get nodes 2. 查看集群资源使用情况: kubectl top nodes 3. 查看集群…...

PHP基础之错误与异常
文章目录 1 错误1.1 简介1.2 简单错误处理1.2.1 使用die1.2.2 die和exit区别 1.3 自定义错误处理1.3.1 定义1.3.2 创建错误函数 1.4 触发错误1.5 抑制错误1.5.1 行内错误抑制 2 异常2.1 引言2.2 什么是异常2.3 Try、throw、catch、finally2.4 自定义异常2.5 设置顶层异常处理器…...
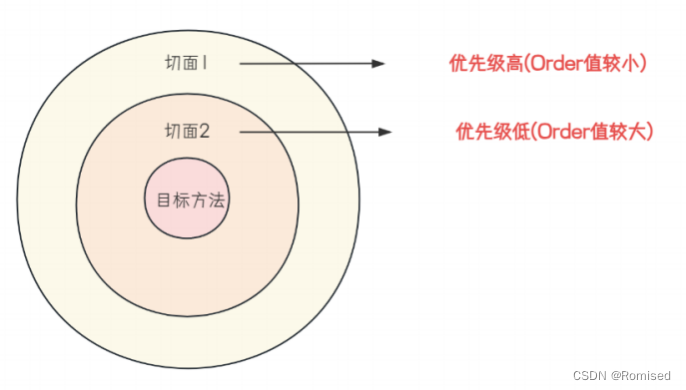
详解Spring AOP(一)
目录 1. AOP概述 2.Spring AOP快速入门 2.1引入AOP依赖 2.2编写AOP程序 3.Spring AOP核心概念 3.1切点(PointCut) 3.2连接点(Join Point) 3.3通知(Advice) 3.4切面(Aspect) …...
)
读者写者问题(读者优先、公平竞争、写者优先)
1.读者优先 当有读者进程进行读时,允许多个读者同时读,但不允许写者写;当有写者进程进行写时,不允许其他写者写,也不允许读者读 读者算法: p(r_mutex); //申请修改read_count if read_count0:p(mutex); …...
-- Easyexcel)
Springboot开发之 Excel 处理工具(二)-- Easyexcel
一、Easyexcel 简介 EasyExcel是一个基于Java的Excel处理工具库,它的核心设计理念是快速、简洁,并且能够有效解决处理大文件时的内存溢出问题。使用EasyExcel,开发者可以在几乎不需要考虑性能和内存消耗的情况下,轻松实现Excel文…...

6月27日云技术研讨会 | 中央集中架构新车型功能和网络测试解决方案
会议摘要 “软件定义汽车”新时代下,整车电气电气架构向中央-区域集中式发展已成为行业共识,车型架构的变革带来更复杂的整车功能定义、更多的新技术的应用(如SOA服务化、TSN等)和更短的车型研发周期,对整车和新产品研…...

微信小程序生命周期
微信小程序的生命周期包括两个主要部分:应用生命周期和页面生命周期。下面我将详细介绍它们的具体内容。 应用生命周期 onLaunch: 触发时机:小程序初始化完成时(全局只触发一次)。 用途:通常用于进行一些…...

【JS重点15】原型对象概述
目录 一:构造函数缺陷 二:原型 1 原型是是什么 2 原型对象的作用 3 原型对象this指向问题 4 利用原型对象添加方法 给JS内置构造函数Array添加最大值方法 给JS内置构造函数Array添加求和方法 三:Constructor属性 四:如何…...

Java之Hutool/Guava/Apache Commons工具包项目实践
概述 Hutool是一个Java工具包,提供了丰富的工具类和方法,目的是简化开发任务提高开发效率;适用于需要快速开发和实现多种功能的场景,适合项目需要处理字符串、日期、文件等常见任务时~ toBeBetterJavaer/docs/common-tool/StringUtils.md at master itwanger/toBeBetterJavae…...

哈喽GPT-4o——对GPT-4o 提示词的思考与看法
目录 一、提示词二、常用的提示词案例1、写作助理2、改写为小红书风格3、英语翻译和改写4、论文式回答5、主题解构6、提问助手7、Nature风格润色8、结构总结9、编程助手10、充当终端/解释器 大家好,我是哪吒。 最近,ChatGPT在网络上广受欢迎,…...

《计算机英语》 Unit 3 Software Engineering 软件工程
Section A Software Engineering Methodologies 软件工程方法论 Software development is an engineering process. 软件开发是一个工程过程。 The goal of researchers in software engineering is to find principles that guide the software development process and lea…...

2024-6-18(沉默Spring,Springboot)
1.Spring小结 我们最后再来体会一下用 Spring 创建对象的过程: 通过 ApplicationContext 这个 IoC 容器的入口,用它的两个具体的实现子类,从 class path 或者 file path 中读取数据,用 getBean() 获取具体的 bean instance。 那…...
Java热部署:让应用更新如丝般顺滑,告别繁琐重启!
目录 手动启动热部署 自动启动热部署 参与热部署监控的文件范围配置 关闭热部署 什么是热部署?简单说就是你程序改了,现在要重新启动服务器,嫌麻烦?不用重启,服务器会自己悄悄的把更新后的程序给重新加载一遍&…...

微信小程序毕业设计-小区疫情防控系统项目开发实战(附源码+论文)
大家好!我是程序猿老A,感谢您阅读本文,欢迎一键三连哦。 💞当前专栏:微信小程序毕业设计 精彩专栏推荐👇🏻👇🏻👇🏻 🎀 Python毕业设计…...
PyTorch -- RNN 快速实践
RNN Layer torch.nn.RNN(input_size,hidden_size,num_layers,batch_first) input_size: 输入的编码维度hidden_size: 隐含层的维数num_layers: 隐含层的层数batch_first: True 指定输入的参数顺序为: x:[batch, seq_len, input_size]h0:[batc…...

pySLAM体素重建技术:TSDF与高斯泼溅的深度解析
pySLAM体素重建技术:TSDF与高斯泼溅的深度解析 【免费下载链接】pyslam pySLAM is a hybrid Python/C Visual SLAM pipeline supporting monocular, stereo, and RGB-D cameras. It provides a broad set of modern local and global feature extractors, multiple …...

如何快速掌握Unity资产编辑:面向开发者的完整教程
如何快速掌握Unity资产编辑:面向开发者的完整教程 【免费下载链接】UABEA c# uabe for newer versions of unity 项目地址: https://gitcode.com/gh_mirrors/ua/UABEA UABEA是一款专业的Unity Asset Bundle编辑器,专为游戏开发者和模组制作者设计…...

2026AIGC 短剧出海全链路落地服务测评
2026 年 AIGC 短剧出海行业已迈入精细化商业落地阶段,专业全链路服务商与AI 视频生成平台的赛道分化成为行业发展的核心特征,二者依托差异化的服务模式、能力体系与价值输出,精准覆盖不同出海主体的需求场景。集之互动作为深耕短剧出海领域的…...

百度网盘下载加速终极方案:免费解锁满速下载的完整指南
百度网盘下载加速终极方案:免费解锁满速下载的完整指南 【免费下载链接】baidupcs-web 项目地址: https://gitcode.com/gh_mirrors/ba/baidupcs-web 还在为百度网盘下载速度只有几十KB/s而烦恼吗?你是否曾经面对大文件下载时感到绝望?…...

实战演练:基于快马平台生成电商全流程自动化测试并与Jenkins集成
今天想和大家分享一个最近用InsCode(快马)平台完成的电商自动化测试实战项目。这个项目模拟了真实电商平台的核心业务流程,从用户注册登录到完成支付的全流程测试,特别适合需要快速搭建自动化测试体系的小伙伴参考。 项目背景与设计思路 电商系统的稳定…...

终极指南:activate-linux项目如何实现WebAssembly移植与浏览器环境运行
终极指南:activate-linux项目如何实现WebAssembly移植与浏览器环境运行 【免费下载链接】activate-linux The "Activate Windows" watermark ported to Linux 项目地址: https://gitcode.com/gh_mirrors/ac/activate-linux activate-linux是一个有…...

从根源到优化:Visual C++ Redistributable AIO工具的5个技术维度解析
从根源到优化:Visual C Redistributable AIO工具的5个技术维度解析 【免费下载链接】vcredist AIO Repack for latest Microsoft Visual C Redistributable Runtimes 项目地址: https://gitcode.com/gh_mirrors/vc/vcredist 问题溯源:运行库故障的…...

DAMO-YOLO手机检测WebUI多摄像头管理:RTSP流统一调度方案
DAMO-YOLO手机检测WebUI多摄像头管理:RTSP流统一调度方案 1. 项目概述 1.1 系统简介 这是一个基于DAMO-YOLO和TinyNAS技术的实时手机检测系统,专门针对多摄像头监控场景设计。系统通过WebUI界面统一管理多个RTSP流摄像头,实现手机设备的自…...

如何通过HFS哈氏训练改善注意力缺陷儿童的集中程度?
通过HFS哈氏训练提升注意力缺陷儿童的集中技巧 HFS哈氏训练是一种针对注意力缺陷儿童的有效方法,旨在提升他们的集中技巧。这种训练通过特定的游戏和活动,帮助儿童培养注意力控制能力。首先,家长和教育者可以引导孩子参与简短且有趣的任务&am…...

如何快速掌握yuzu模拟器:Switch游戏在电脑上流畅运行的终极指南
如何快速掌握yuzu模拟器:Switch游戏在电脑上流畅运行的终极指南 【免费下载链接】yuzu 任天堂 Switch 模拟器 项目地址: https://gitcode.com/GitHub_Trending/yu/yuzu yuzu模拟器是目前最流行的任天堂Switch开源模拟器,让玩家能够在Windows、Lin…...