机器学习(一)
机器学习
- 1.机器学习概述
- 1.1 人工智能概述
- 1.1.1 机器学习与人工智能、深度学习的关系
- 1.1.2 人工智能的起点
- 1.1.3 机器学习、深度学习能做什么?
- 1.2 什么是机器学习?
- 1.2.1 定义
- 1.2.2 数据集的构成
- 1.3 机器学习算法
- 1.4 机器学习开发流程
- 2.特征工程
- 2.1 数据集
- 2.1.1 可用数据集
- 2.1.2 Sklearn数据集
- 2.1.3 数据集的划分
- 2.2 特征工程介绍
- 2.2.1 为什么要做特征工程
- 2.2.2 什么是特征工程
- 2.3 特征提取
- 2.3.1 概念
- 2.3.2 特征提取API
- 2.3.3 字典特征提取
- 2.3.4 文本特征提取
- 2.3.5 TF-IDF文本特征提取
- 2.4 特征预处理
- 2.4.1 特征预处理API
- 2.4.2 归一化
- 2.4.3 API
- 2.4.4 标准化
- 2.4.5 API
- 2.4.6 总结
- 2.5特征降维
- 2.5.1 标量、向量、矩阵、张量的关系
- 2.5.2 降维概念
- 2.5.3 降维的两种方式
- 2.5.4 特征选择
1.机器学习概述
1.1 人工智能概述
1.1.1 机器学习与人工智能、深度学习的关系
机器学习是人工智能的一个实现途径,而深度学习是机器学习的一个方法发展而来。
1.1.2 人工智能的起点
1.1.3 机器学习、深度学习能做什么?
应用领域:网络搜索、识别人类语言、自动驾驶、计算机视觉、传统预测、图形识别、自然语言处理。
AGI为Artificial General Intelligence的首字母缩写,意为人工通用智能。它是一种可以执行复杂任务的人工智能,能够完全模仿人类智能的行为。
1.2 什么是机器学习?
1.2.1 定义
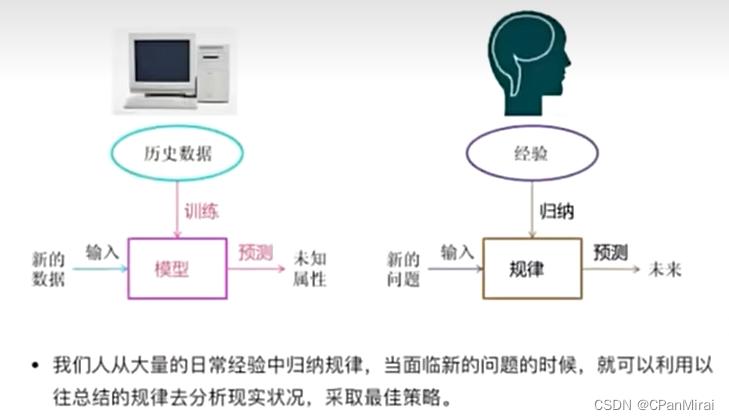
机器学习是从数据中自动分析获取模型,并利用模型对未知数据进行预测。
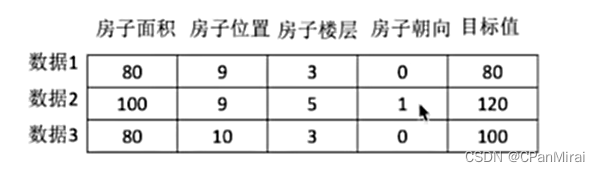
1.2.2 数据集的构成
结构: 特征值 + 目标值
注:
对于每一行数据可以称为样本。
有些数据集可以没有目标值。(需要采用聚类算法这些,进行分类。)
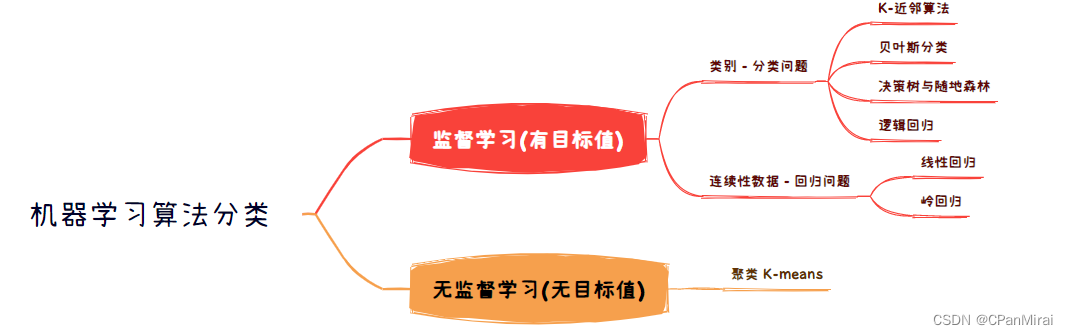
1.3 机器学习算法
1.4 机器学习开发流程
- 获取数据
- 数据处理(缺失值、坏点等等)
- 特征工程(让数据变得更容易被机器学习算法使用的数据)
- 机器学习算法训练(之后得到模型)
- 模型评估
- 应用

2.特征工程
2.1 数据集
2.1.1 可用数据集
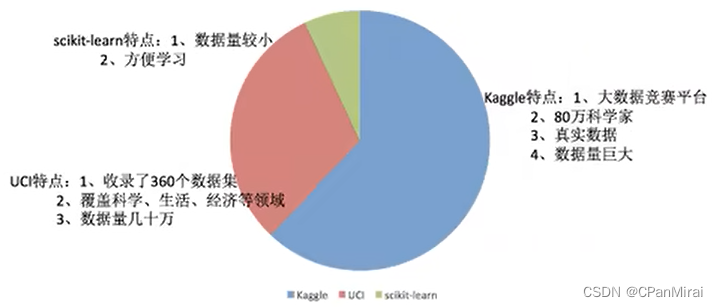
Kaggle网址:Find Open Datasets and Machine Learning Projects | Kaggle
UCI网址:UCI 机器学习存储库
scikit-learn网址:scikit-learn: machine learning in Python — scikit-learn 1.5.0 documentation
2.1.2 Scikit-learn工具介绍
- python语言的机器学习的工具
- Scikit-learn包含许多机器学习算法的实现
2.1.3 安装
pip install Scikit-learn# 如果有多个python版本的话,需要指定,以3.12为例
pip3.12 install Scikit-learn
完了之后,可以查看自己是否安装成功。
pip list
2.1.2 Sklearn数据集
# * 表示的是数据集的名字# 获取小规模数据集,数据包含在datasets里
sklearn.datasets.load_*()# 获取大型数据集,需要从网络下载,默认是 ~/scikit_learn_data/
# datahome : 标识数据集下载的目录
# subset:'train' 或 'test' 或 'all' 可选,选择要加载的数据集
sklearn.datasets.fetch_*(datahome = None,subset = "train")# 两种方法的返回的数据值
# load和fetch返回的数据类型datasets.base.Bunch(字典格式),这个是继承自字典# data: 特征值数据数组,是[n_samples * n_features]的二维numpy*ndarray数组# target: 标签数组,是n_samples 的一维numpy * ndarray数组# DESCR: 数据描述# feature_names: 特征名# target_names: 标签名
示例:
from sklearn.datasets import load_irisdef datasets_demo():"""sklearn数据集使用:return:"""# 获取数据集iris = load_iris()print("鸢尾花数据集:\n", iris)print("鸢尾花数据集描述:\n", iris["DESCR"])print("鸢尾花数据集特征值的名字:\n", iris.feature_names)print("鸢尾花数据集特征值的形状:\n", iris.data, iris.data.shape)return Noneif __name__ == '__main__':datasets_demo()2.1.3 数据集的划分
机器学习数据集会划分为两个部分:
- 训练数据:用于训练 , 构建模型
- 测试数据:在模型检验中使用,评估模型是否有效
数据集划分API
- sklearn.model_selection.train_test_split(arrays,*options)
- x 数据集的特征值
- y 数据集的标签值
- test_size 测试集的大小,一般为float
- random_state 随机数种子,不同的种子会造成不同的随机采样结果。
- return 训练集特征值,测试集特征值、训练集目标值、测试集目标值
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_splitdef datasets_demo():"""sklearn数据集使用:return:"""# 获取数据集iris = load_iris()# 数据集划分x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2)print("训练集特征值:\n", x_train, x_train.shape)print("训练集目标值:\n", y_train, y_train.shape)print("测试集特征值:\n", x_test, x_test.shape)print("测试集目标值:\n", y_test, y_test.shape)return Noneif __name__ == '__main__':datasets_demo()2.2 特征工程介绍
2.2.1 为什么要做特征工程
数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限。
2.2.2 什么是特征工程
特征工程是使用专业背景知识和技巧处理数据,使得特征能在机器学习算法上发挥更好的作用的过程。
- 意义:会直接影响机器学习的效果。
在特征工程里面,我们使用的是sklearn,而不是pandas(数据清洗、数据处理)。
2.3 特征提取
2.3.1 概念
将任意数据(如文本或图像)转换为可用于机器学习的数字特征
- 字典特征提取(特征离散化)
- 文本特征提取
- 图像特征提取
2.3.2 特征提取API
sklearn.feature_extraction
2.3.3 字典特征提取
类别 -> one-hot编码
向量用一维数组进行表示
sklearn.feature_extraction.DictVetorizer(sparse = True,...)
# sparse(稀疏) = True: 会把该矩阵采用三元组进行存储,只存储不为零的元素,按照(行,列,值)存储,目的是为了节约空间
# sparse(稀疏) = False: 按照正常矩阵存储Dictverorizer.fit_transform(x) x:字典或包含字典的迭代器返回值:返回sparse矩阵
应用场景:
当数据集中类别特征比较多
- 如果不是字典,则将数据集特征 --> 字典类型,否则不用
- 利用DictVetorizer进行转换
示例:
from sklearn.feature_extraction import DictVectorizerdef dict_demo():city_dict = [{'city': '北京', 'temperature': 100}, {'city': '上海', 'temperature': 60},{'city': '深圳', 'temperature': 30}, ]# 1. 实例化对象transformer = DictVectorizer(sparse=False)# 2. 调用fit_transform方法city_dict = transformer.fit_transform(city_dict)# 3. 打印矩阵特征值名称print("city_dict_feature:\n", transformer.get_feature_names_out())# 4. 打印矩阵内容print("city_dict:\n", city_dict)return Noneif __name__ == '__main__':dict_demo()2.3.4 文本特征提取
作用:对文本数据进行特征值化
sklearn.feature_extraction.text.CountVectorizer(stop_words=[]) # stop_words 里面可以写不需要分类的词 返回值为词频矩阵CountVectorizer.fit_transform(X) # X : 文本或包含文本字符串的可迭代对象 返回值:返回sparse矩阵CountVectorizer.inverse_transform(X) # X : array数组或sparse矩阵 返回值:转换之前的数据格式CountVectorizer.get_feature_names() # 返回值:单词列表
示例(英文句子)
from sklearn.feature_extraction.text import CountVectorizerdef count_demo():dict_list = ["life is short,I like python", "life is too long,I dislike python"]# 1. 实例化对象transfer = CountVectorizer()# 2. 调用fit_transform方法dict_list = transfer.fit_transform(dict_list)# 3. 打印特征名称print("feature_names:\n", transfer.get_feature_names_out())# 4. 打印结果print("dict_list:\n", dict_list)# 5. 换行为数组print("dict_list:\n", dict_list.toarray())# 6. 把特征名按照顺序排序print("vocabulary:\n", transfer.vocabulary_)# 7. 调用inverse_transform方法print("inverse_transform:\n", transfer.inverse_transform(dict_list))returnif __name__ == '__main__':count_demo()示例(中文句子)
from sklearn.feature_extraction.text import CountVectorizerdef count_demo():dict_list = ["生活不能等待别人来安排,要自己去争取和奋斗;","而不论其结果是喜是悲,但可以慰藉的是,你总不枉在这世界上活了一场。","有了这样的认识,你就会珍重生活,而不会玩世不恭;同时,也会给人自身注入一种强大的内在力量。"]# 1. 实例化对象transfer = CountVectorizer()# 2. 调用fit_transform方法dict_list = transfer.fit_transform(dict_list)# 3. 打印特征名称print("feature_names:\n", transfer.get_feature_names_out())# 4. 打印结果print("dict_list:\n", dict_list)# 5. 换行为数组print("dict_list:\n", dict_list.toarray())# 6. 把特征名按照顺序排序print("vocabulary:\n", transfer.vocabulary_)# 7. 调用inverse_transform方法print("inverse_transform:\n", transfer.inverse_transform(dict_list))returnif __name__ == '__main__':count_demo()由于中文没有空格,采用上面的方法处理不好,我们使用空格进行分割,如果句子多的话,太麻烦,所以我们使用jieba库来处理。
# 利用pip下载
pip install jieba# 查看
pip list
示例:中文(使用jieba)
from sklearn.feature_extraction.text import CountVectorizer
import jiebadef cut_word(text):"""中文分词,text为字符串:param text::return:"""return " ".join(list(jieba.cut(text)))def count_chinese_demo():"""中文文本特征抽取,自动分词:return:"""data = ["生活不能等待别人来安排,要自己去争取和奋斗;","而不论其结果是喜是悲,但可以慰藉的是,你总不枉在这世界上活了一场。","有了这样的认识,你就会珍重生活,而不会玩世不恭;同时,也会给人自身注入一种强大的内在力量。"]data_new = []# 1. 遍历data列表for sent in data:# 2. 中文分词data_new.append(cut_word(sent))print(data_new)# 3. 实例化对象transfer = CountVectorizer()# 4. 提取特征data_list = transfer.fit_transform(data_new)# 5. 打印特征名称print("特征名称\n", transfer.get_feature_names_out())# 6. 打印结果print("data_list\n", data_list)# 7. 转换为数组print(data_list.toarray())# 8. 把特征名称按照顺序排序print("特征名称排序\n", transfer.vocabulary_)# 9. 调用inverse_transform方法print("还原\n", transfer.inverse_transform(data_list))return Noneif __name__ == '__main__':count_chinese_demo()前面的,我们使用是根据单词出现的次数进行分类,但是有的单词在每篇文章中都出现很高,没有区分度。
我们希望找到在一个类别的文章,出现的次数很多,但是在其他类别的文章中出现很少。
2.3.5 TF-IDF文本特征提取
- TF-IDF的主要思想是:如果某个词或短语在一篇文章中出现的概率高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合来分类。
- TF-IDF作用:用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。
利用下面公式进行计算
# TF(词频):指的是某一个给定的词语在该文件中出现的频率
# IDF(逆向文档频率):是一个词语普遍重要性的度量。某一特定词语的IDF,可以由总文件数目除以包含该词语的文件的数目,把其取以10为底的对数就可以得到
TF-IDF = TF(词频) * IDF(逆向文档频率)
API
sklearn.feature_extraction.text.TfidfVectorizer(stop_words=None) # 返回词的权重矩阵TfidfVectorizer.fit_transform(X) # X : 文本或包含文本字符串的可迭代对象 返回值:返回sparse矩阵TfidfVectorizer.inverse_transform(X) # X : array数组或sparse矩阵 返回值:转换之前的数据格式TfidfVectorizer.get_feature_names() # 返回值:单词列表
示例:
from sklearn.feature_extraction.text import TfidfVectorizer
import jiebadef cut_word(text):"""中文分词,text为字符串:param text::return:"""return " ".join(list(jieba.cut(text)))def count_chinese_demo():"""中文文本特征抽取,自动分词:return:"""data = ["生活不能等待别人来安排,要自己去争取和奋斗;","而不论其结果是喜是悲,但可以慰藉的是,你总不枉在这 世界上活了一场。","有了这样的认识,你就会珍重生活,而不会玩世不恭;同时,也会给人自身注入一种强大的内在力量。"]data_new = []# 1. 遍历data列表for sent in data:# 2. 中文分词data_new.append(cut_word(sent))print(data_new)# 3. 实例化对象transfer = TfidfVectorizer()# 4. 提取特征data_list = transfer.fit_transform(data_new)# 5. 打印特征名称print("特征名称\n", transfer.get_feature_names_out())# 6. 打印结果print("data_list\n", data_list)# 7. 转换为数组print(data_list.toarray())# 8. 把特征名称按照顺序排序print("特征名称排序\n", transfer.vocabulary_)# 9. 调用inverse_transform方法print("还原\n", transfer.inverse_transform(data_list))return Noneif __name__ == '__main__':count_chinese_demo()2.4 特征预处理
通过一些转换函数将特征数据转换成更合适算法模型的特征数据过程。
数值型数据的无量纲化:
- 归一化
- 标准化
进行归一化/标准化是因为:
- 特征的单位或者大小相差较大,或者某特征的方差相比其他的特征要大出几个数量级,容易影响(支配)目标结果,使得一些算法无法学习到其他的特征。
2.4.1 特征预处理API
sklearn.preprocessing
2.4.2 归一化
-
定义:通过对原始数据进行变换把数据映射到(默认[0,1])之间。
-
公式

2.4.3 API
sklearn.preprocessing.MinMaxScaler(feature_range=(0,1))MinMaxScalar.fit_transform(X)X: numpy arrayg格式的数据[n_samples,n_features] # n_samples(样本数即一行的数据) * n_features(有几个特征)返回值:转换后的形状相同的array
示例:
from sklearn.datasets import load_iris
from sklearn.preprocessing import MinMaxScalerdef minmax_demo():"""归一化:return:"""# 1. 获取数据iris = load_iris()# 2. 实例化转换器类minmax = MinMaxScaler()# 3. 调用fit_transform()方法iris.data = minmax.fit_transform(iris.data)# 4. 打印print(iris.data)return Noneif __name__ == '__main__':minmax_demo()使用归一化的时候,里面需要借助min/max,如果这两个值是异常值,则最后计算的结果会受到影响。所以这种方法鲁棒性比较差,只适合于传统精确小数据的场景。
2.4.4 标准化
-
定义:通过对原始数据进行变换把数据变换到均值为0,标准差为1范围内。
-
公式:
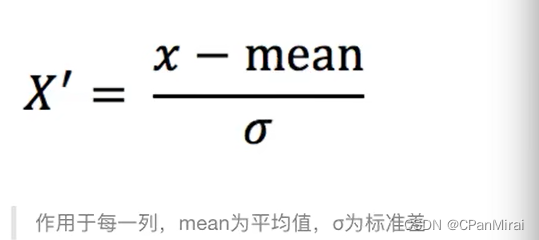
2.4.5 API
sklearn.preprocessing.StandardScaler()处理之后,对每列来说,所有数据聚集再均值为0、标准差为1附近StandardScaler.fit_transform(X)X : numpy array格式的数据[n_samples,n_features]返回值:转换后形状相同的array
示例:
from sklearn.datasets import load_iris
from sklearn.preprocessing import StandardScalerdef standard_demo():"""标准化:return:"""# 1. 获取数据iris = load_iris()# 2. 实例化转换器类minmax = StandardScaler()# 3. 调用fit_transform()方法iris.data = minmax.fit_transform(iris.data)# 4. 打印print(iris.data)return Noneif __name__ == '__main__':standard_demo()在已有样本足够多的情况下比较稳定,适合去处理现代嘈杂大数据场景。
2.4.6 总结
- 对于归一化来说:如果出现异常点,影响了最大值和最小值,那么结果显示会发生变化
- 对于标准化来说:如果出现异常点,由于具有一定数据量,少量的异常点对于平均值的影响并不大,从而标准差改变较小
2.5特征降维
2.5.1 标量、向量、矩阵、张量的关系

2.5.2 降维概念
指的某些限定条件下,降低随机变量(特征)个数,得到一组“不相关”主变量的过程。(也就是线代里面的极大无关组)
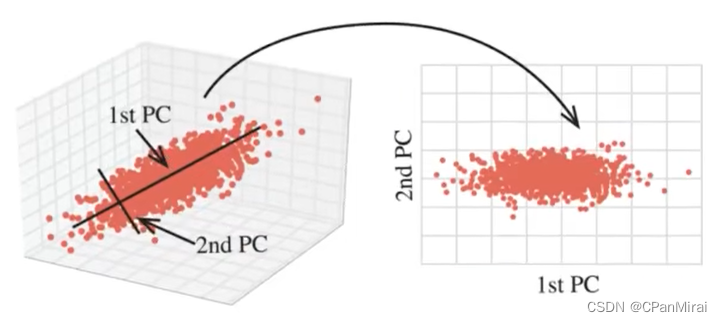
补充:我们在进行训练的时候,使用的是特征进行学习。如果特征本身存在问题或特征之间相关性较强,对于算法学习预测会影响比较大。
2.5.3 降维的两种方式
- 特征选择
- 主成分分析
2.5.4 特征选择
-
定义:数据中包含冗余或者是相关变量(或称特征、属性、指标等),旨在从原有特征中找出主要特征。
-
方法
-
Filter(过滤式):主要探究特征本身特点、特征与特征和目标值之间关系
-
方差选择法:低方差特征过滤
-
相关系数:衡量特征与特征之间的相关程度
皮尔森相关系数:反映变量之间相关关系密切程度的统计指标

相关系统的值介于-1 到 +1 之间 ,即-1 <= r <= +1,其性质如下:
当 r > 0 时,表示两变量正相关,r < 0 时,两变量为负相关。
当 |r| = 1 时,表示两变量为 完全相关,当 r = 0 时,表示两变量间不相关。
当 0 < |r| < 1时,表示两变量存在一定程度的相关。且 |r|越接近 1,两变量间线性程度越密切;|r|越接近0,表示两变量的线性相关越弱。
一般可划分为三级:|r| < 0.4为低度相关;0.4 <= |r| <=0.7 为显著性相关;0.7 < |r| < 1为高度线性相关
API
from scipy.stats import pearsonr# x:(N,) array_like# y:(N,) array_like # Returns:(statistic,value) -
API
sklearn.feature_selection.VarianceThreshold(threshold = 0.0) # 删除所有低方差特征Variable.fit_transform(X)X: numpy array格式的数据[n_samples,n_features]# 返回值:训练集差异低于threshold的特征将被删除,默认保留所有非零方差特征。 -
示例
from sklearn.datasets import load_iris from sklearn.feature_selection import VarianceThresholddef variance_demo():"""低方差过滤,就是过滤掉方差小的特征,默认为 0:return:"""# 1. 获取数据iris = load_iris()# 2. 实例化转换器类variance = VarianceThreshold()# 3. 调用fit_transform()方法iris.data = variance.fit_transform(iris.data)# 4. 打印print(iris.data)return Noneif __name__ == '__main__':variance_demo()
-
-
Embedded(嵌入式):算法自动选择特征
- 决策树
- 正则化
- 深度学习
-
相关文章:
机器学习(一)
机器学习 1.机器学习概述1.1 人工智能概述1.1.1 机器学习与人工智能、深度学习的关系1.1.2 人工智能的起点1.1.3 机器学习、深度学习能做什么? 1.2 什么是机器学习?1.2.1 定义1.2.2 数据集的构成 1.3 机器学习算法1.4 机器学习开发流程 2.特征工程2.1 数…...
)
【深度学习】python之人工智能应用篇——图像生成技术(一)
说明: 两篇文章根据应用场景代码示例区分,其他内容相同。 图像生成技术(一):包含游戏角色项目实例代码、图像编辑和修复任务的示例代码和图像分类的Python代码示例 图像生成技术(二):…...

java 非srping 使用r2dbc操作mysql 增删改查代码
要在Java中使用R2DBC操作MySQL,首先需要添加相关依赖。在Maven项目中,可以在pom.xml文件中添加以下依赖: <dependency><groupId>dev.miku</groupId><artifactId>r2dbc-mysql</artifactId><version>0.8.…...

假冒国企现形记:股权变更视角下的甄别分析
启信慧眼-启信宝企业版 假冒国企公告2024-06-07,中粮集团有限公司官网发布《关于冒名中粮企业名单公告》。公告显示,”有不法分子通过伪造相关材料等方式,以我集团子公司名义开展业务,进行虚假宣传。经核实,上述公司假…...

Django 使用Apscheduler执行定时任务
Apscheduler 介绍 核心组件: 调度器、作业存储、执行器、触发器 调度器 BlockingScheduler 阻塞的调度器,适用于脚本 BackgroundScheduler 后台调度器,适用于非阻塞的应用如Web应用 AsyncIOScheduler 适用于 asyncio 的调度器 GeventSchedu…...
Shopee API接口:获取搜索栏生成的商品结果列表
一、引言 此接口可以高效获取搜索栏生成的商品结果列表。本文将详细介绍这一核心功能,并探讨其在实际应用中的价值。 二、核心功能介绍——获取搜索栏生成的商品结果列表 请求API及返回示例 http://api.xxxx.com/sp/ll/search/item?keywordiphone&page1&am…...
选择门店收银系统要考虑哪些方面?美业系统Java源码分享私
开店前的一个重要事件就是选择门店收银软件/系统,尤其是针对美容、医美等美业门店,一个优秀专业的系统十分重要,它必须贴合门店的经营需求,提供更全面、便捷、高效的管理功能,帮助提升门店的服务质量和经营效益。 以下…...
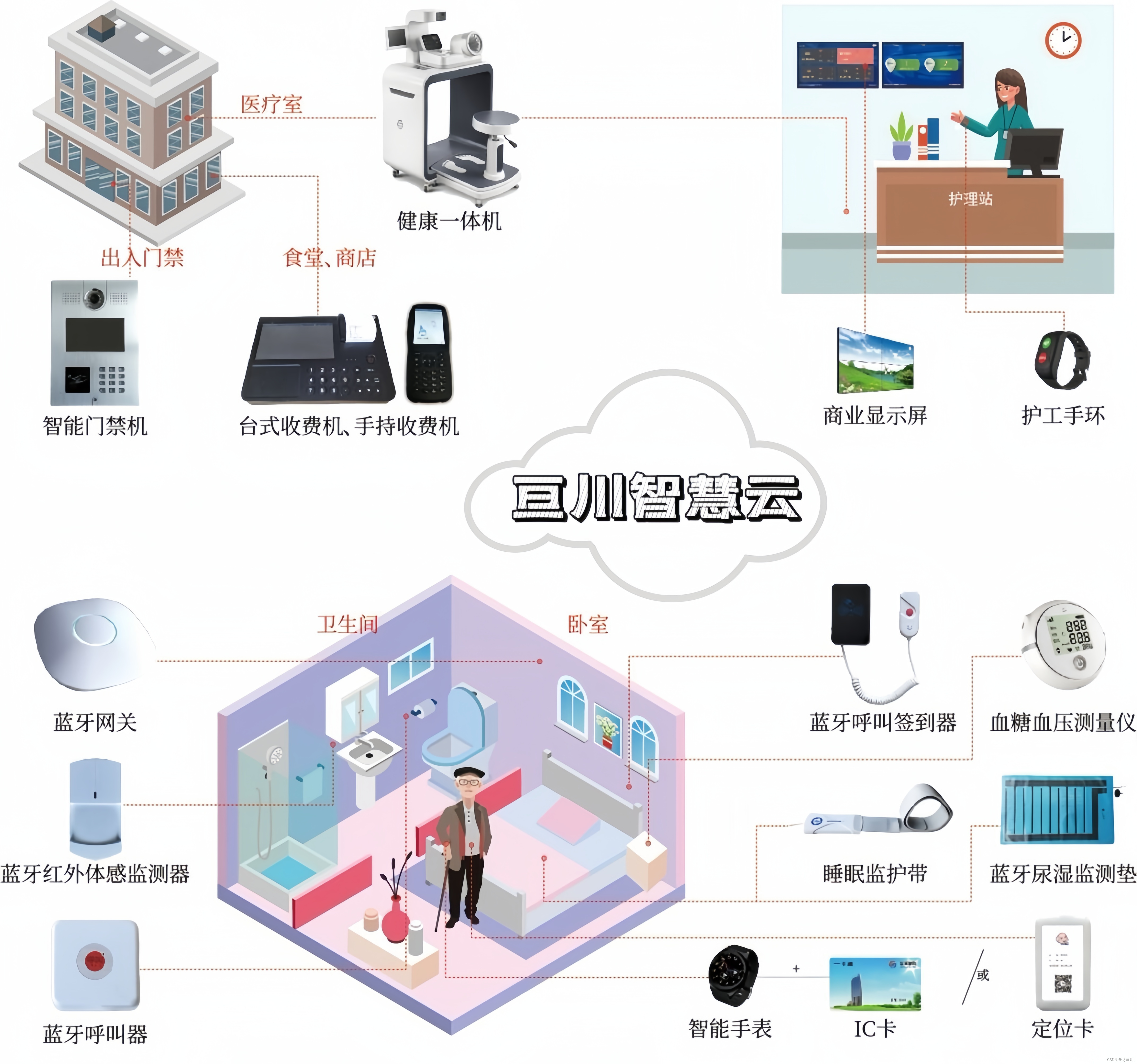
智慧养老的养老方式及其技术实现与趋势
智慧养老是一种借助现代信息技术手段,为老年人提供更高效、便捷、个性化服务的养老模式。以下是一些常见的智慧养老方式: 1. 远程健康监测系统 通过智能穿戴设备,如手环、手表等,实时收集老年人的生理数据,如心率、血…...

思维导图之计算机网络整体框架
高清自行访问:计算机网络整体框架 (yuque.com)...

P7771 【模板】欧拉路径
网址如下: P7771 【模板】欧拉路径 - 洛谷 | 计算机科学教育新生态 (luogu.com.cn) 忘掉了输出欧拉回路的方法,搞了我好久 关于欧拉回路的知识可以看我之前的博客: 一点关于欧拉回路的总结-CSDN博客 代码如下: #include<q…...
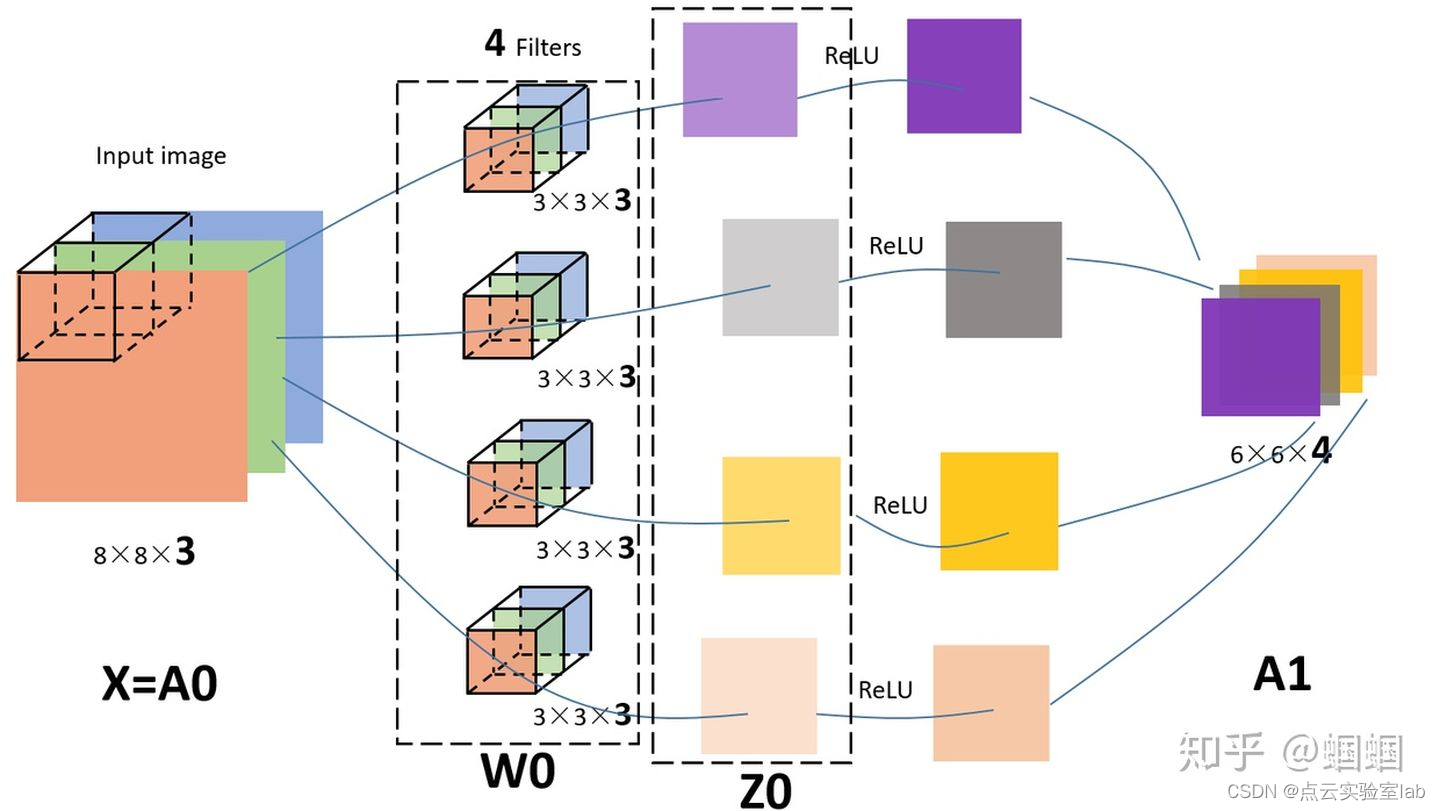
卷积神经网络(CNN)理解
1、引言(卷积概念) 在介绍CNN中卷积概念之前,先介绍一个数字图像中“边缘检测edge detection”案例,以加深对卷积的认识。图中为大小8X8的灰度图片,图片中数值表示该像素的灰度值。像素值越大,颜色越亮&…...

Databend 开源周报第 149 期
Databend 是一款现代云数仓。专为弹性和高效设计,为您的大规模分析需求保驾护航。自由且开源。即刻体验云服务:https://app.databend.cn 。 Whats On In Databend 探索 Databend 本周新进展,遇到更贴近你心意的 Databend 。 支持递归公共表…...
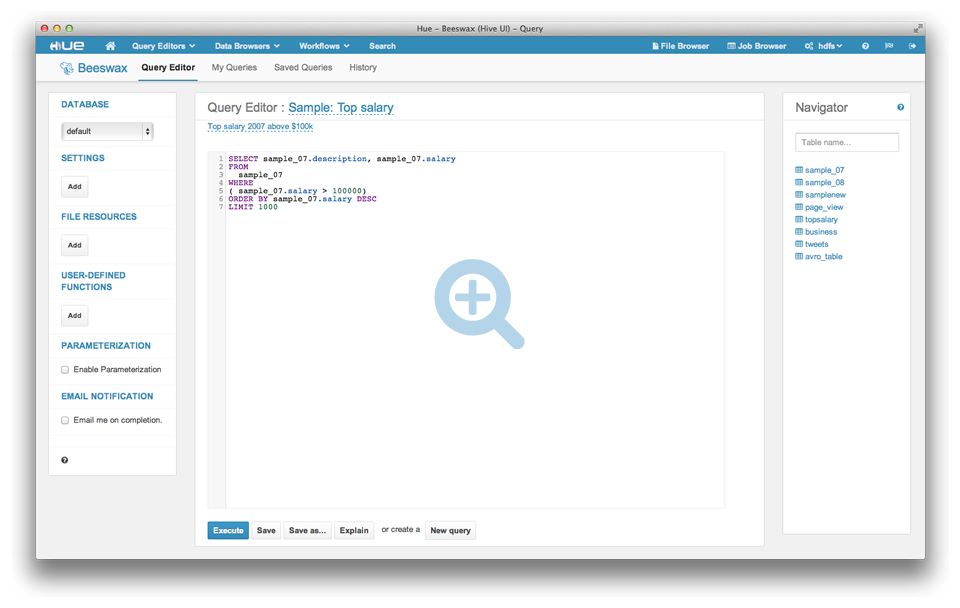
Hue Hadoop 图形化用户界面 BYD
软件简介 Hue 是运营和开发 Hadoop 应用的图形化用户界面。Hue 程序被整合到一个类似桌面的环境,以 web 程序的形式发布,对于单独的用户来说不需要额外的安装。...
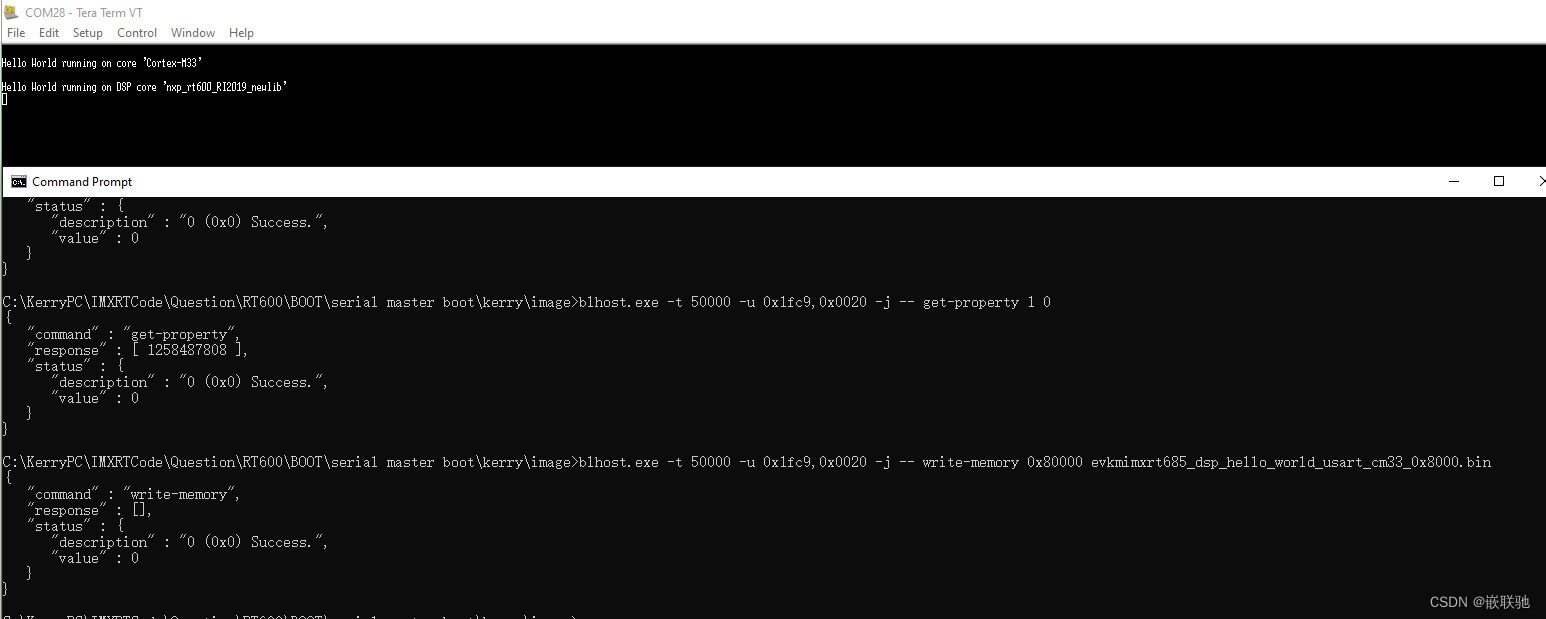
【经验分享】RT600 serial boot mode测试
【经验分享】RT600 serial boot mode测试 一, 文档描述二, Serial boot mode测试2.1 evkmimxrt685_gpio_led_output 工程测试2.2 evkmimxrt685_dsp_hello_world_usart_cm33工程测试 一, 文档描述 RT600的启动模式共支持4种: 1&am…...

七种不同类型测宽仪技术参数 看看哪种能用于您的产线?
在线测宽仪种类众多,原理不同,产品不同,型号不同,其技术参数也各不相同。不同的测量范围与测量精度,适用于不同规格的板材,看看您的板材能适用于哪种范围。 1、单测头平行光测宽仪 点光源发射的光经过发射…...

【GO】rotatelogs库和sirupsen/logrus库实现日志功能的实践用例
“github.com/sirupsen/logrus” 是一个 Go 语言的日志库,它提供了一种简单、灵活的方式来记录日志。该库的主要特点包括: 支持多种日志输出目标,如控制台、文件等。 支持日志轮转,可以按照时间或文件大小进行轮转。 支持日志格式…...

Arc2Face - 一张图生成逼真的多风格人脸,本地一键整合包下载
Arc2Face是用于人脸的基础模型训练,可批量生成超高质量主题的AI人脸艺术风格照,完美复制人脸。只需一张照片,几秒钟,即可批量生成超高质量主题的AI人脸艺术风格照,完美复制人脸。 Arc2Face 是一个创新的开源项目&…...
swiper 幻灯片
index.html <!DOCTYPE html> <html lang"en"> <head> <meta charset"utf-8"> <title>swiper全屏响应式幻灯片代码</title> <meta name"viewport" content"widthdevice-width, initial-scale1, min…...

Ubuntu 使用Vscode的一些技巧 ROS
Ubuntu VSCode的一些设置(ROS) 导入工作空间 推荐只导入工作空间下的src目录 如果将整个工作空间导入VSCode,那么这个src就变成了次级目录,容易在写程序的时候把本应该添加到具体工程src目录里的代码文件给误添加到这个catkin_w…...

JS中的三种事件模型
JavaScript 中的事件模型主要有三种: 传统事件模型(DOM Level 0)标准事件模型(DOM Level 2)IE 事件模型(非标准,仅限于旧版本的 Internet Explorer) 下面分别介绍这三种事件模型&…...
AlphaAvatar:从单目视频重建可驱动3D数字人的混合表示框架
1. 项目概述:从“数字人”到“阿尔法化身”的进化最近在数字人、虚拟形象生成这个圈子里,AlphaAvatar这个名字开始被频繁提及。它不是一个简单的换脸工具,也不是一个预设的3D模型库,而是一个旨在从单目视频中,高质量、…...

AI与Web3融合:Solana开发者工具箱core-ai架构解析与实践
1. 项目概述:当AI遇见Web3,一个开发者工具箱的诞生最近在Web3和AI的交叉领域里折腾,发现了一个挺有意思的项目——helius-tech-labs/core-ai。这名字听起来就很有野心,core(核心)和ai(人工智能&…...

Cyber Engine Tweaks完整指南:5步掌握《赛博朋克2077》终极脚本框架
Cyber Engine Tweaks完整指南:5步掌握《赛博朋克2077》终极脚本框架 【免费下载链接】CyberEngineTweaks Cyberpunk 2077 tweaks, hacks and scripting framework 项目地址: https://gitcode.com/gh_mirrors/cy/CyberEngineTweaks Cyber Engine Tweaks是一个…...

Go语言装饰器模式:功能扩展
Go语言装饰器模式:功能扩展 1. 装饰器实现 type Component interface {Operation() string }type ConcreteComponent struct{}func (c *ConcreteComponent) Operation() string {return "ConcreteComponent" }type Decorator struct {component Component…...

Arm DSTREAM调试接口设计与JTAG/SWD协议详解
1. Arm DSTREAM系统与调试接口设计指南1.1 调试接口技术基础1.1.1 JTAG协议架构解析JTAG(Joint Test Action Group)标准IEEE 1149.1定义了五线制调试接口:TCK:测试时钟,同步所有JTAG操作TMS:测试模式选择&a…...

2026 国产桌面 AI 智能体横向评测:博云 BoClaw vs AutoClaw vs QClaw vs MaxClaw vs WorkBuddy
一、引言2026 年初,一款名为 OpenClaw 的开源 AI 智能体框架以创纪录的速度蹿红全球——短短数月突破 30 万 GitHub Star,Token 使用量一度占据 OpenRouter 平台总量的约 13%。它之所以引发轰动,核心在于首次让 AI 真正实现从“动口”到“动手…...

LLM赋能网页抓取:基于ChatGPT的智能数据提取实战指南
1. 项目概述与核心价值最近在数据采集和自动化领域,一个名为“oxylabs/chatgpt-web-scraping”的项目引起了我的注意。乍一看,这像是把两个热门概念——大型语言模型(LLM)和网页抓取(Web Scraping)——强行…...

AI赋能效率革命:用ChatGPT+Markdown一键生成Xmind/ProcessOn专业流程图
1. 为什么需要AI辅助图表制作? 在日常工作和学习中,我们经常需要制作各种图表来梳理思路或展示信息。传统方式要么依赖专业软件操作(比如反复拖拽图形元件),要么需要手动调整格式排版,整个过程往往要花费半…...

AMD处理器硬件深度调试终极方案:SMUDebugTool完全实战手册
AMD处理器硬件深度调试终极方案:SMUDebugTool完全实战手册 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: https:…...

浏览器扩展开发实战:光标交互防火墙的设计与实现
1. 项目概述与核心价值最近在折腾浏览器插件开发,偶然在GitHub上看到了一个名为“Raidu Firewall Cursor Extension”的项目。光看这个名字,就让我这个对网络安全和效率工具都感兴趣的老码农眼前一亮。这玩意儿本质上是一个浏览器扩展,但它把…...