聊一聊UDF/UDTF/UDAF是什么,开发要点及如何使用?
背景介绍
UDF来源于Hive,Hive可以允许用户编写自己定义的函数UDF,然后在查询中进行使用。星环Inceptor中的UDF开发规范与Hive相同,目前有3种UDF:
A. UDF--以单个数据行为参数,输出单个数据行;
UDF(User Defined Function),即用户自定义函数,能结合SQL语句一起使用,更好地表达复杂的业务逻辑,一般以单个数据行为参数,输出单个数据行;比如数学函数、字符串函数、时间函数、拼接函数
B. UDTF: 以一个数据行为参数,输出多个数据行为一个表作为输出;
UDTF(User Defined Table Function),即用户自定义表函数,它与UDF类似。区别在于UDF只能实现一对一,而它用来实现多(行/列)对多(行/列)数据的处理逻辑。一般以一个数据行为参数,输出多个数据行为一个表作为输出,如lateral、view、explore;
C. UDAF: 以多个数据行为参数,输出一个数据行;
UDAF(User Defined Aggregate Function),用户自定义聚合函数,是由用户自主定义的,用法同如MAX、MIN和SUM已定义的聚合函数一样的处理函数。而且,不同于只能处理标量数据的系统定义的聚合函数,UDAF的可以接受并处理更广泛的数据类型,如用对象类型、隐式类型或者LOB存储的多媒体数据。由于UDAF也属于聚合函数中的一种,同样也需要与GROUPBY结合使用。
一般UDAF以多个数据行为参数,接收多个数据行,并输出一个数据行,比如COUNT、MAX;
UDF、UDTF、UDAF的开发要点及使用DEMO
星环Quark计算引擎中内置了很多函数,同时支持用户自行扩展,按规则添加后即可在sql执行过程中使用,目前支持UDF、UDTF、UDAF三种类型,一般UDF应用场景较多,后面将着重介绍UDF的开发与使用。UDAF及UDTF将主要介绍开发要点以及Demo示例。
Quark的UDF接口兼容开源Hive的UDF接口,用户可以参考开源Hive的UDF手册,或者直接把开源Hive的UDF迁移到Quark上。
UDF
Quark数据类型
| Quark类型 | Java原始类型 | Java包装类 | hadoop.hive.ioWritable |
|---|---|---|---|
| tinyint | byte | Byte | ByteWritable |
| smallint | short | Short | ShortWritable |
| int | int | Integer | IntWritable |
| bigint | long | Long | LongWritable |
| string | - | String | Text |
| char | char | Character | HiveCharWritable |
| boolean | boolean | Boolean | BooleanWritable |
| float | float | Float | FloatWritable |
| double | double | Double | DoubleWritable |
| decimal | - | BigDecimal | HiveDecimalWritable |
| date | - | Date | DateWritable |
| array | - | List | ArrayListWritable |
| Map<K,V> | - | Map<K.V> | HashMapWritable |
UDF函数
Quark 提供了两个实现 UDF 的方式:
第一种:继承 UDF 类
- 优点:实现简单;支持Quark的基本类型、数组和Map;支持函数重载。
- 缺点:逻辑较为简单,只适合用于实现简单的函数
第二种:继承 GenericUDF 类
- 优点:支持任意长度、任意类型的参数;可以根据参数个数和类型实现不同的逻辑;资源消耗更低;可以实现初始化和关闭资源的逻辑(initialize、close)。
- 缺点:实现比继承UDF要复杂一些
一般在以下几种场景下考虑使用GenericUDF:
- 传参情况复杂,比如某UDF要传参数有多种数量或多种类型的情况,在UDF中支持这种场景我们需要实现N个不同的evaluate()方法分别对应N种场景的传参,在GenericUDF我们只需在一个方法内加上判断逻辑,对不同的输入路由到不同的处理逻辑上即可。还有比如某UDF参数既要支持String list参数,也要支持Integer list参数。你可能认为我们只要继续多重载方法就好了,但是Java不支持同一个方法重载参数只有泛型类型不一样,所以该场景只能用GenericUDF。
- 需要传非Writable的或复杂数据类型作为参数。比如嵌套数据结构,传入Map的key-value中的value为list数据类型,或者比如数据域数量不确定的Struct结构,都更适合使用GenericUDF在运行时捕获数据的内部构造。
- 该UDF被大量、高频地使用,所以从收益上考虑,会尽可能地优化一切可以优化的地方,则GenericUDF相比UDF在operator中避免了多次反射转化的资源消耗(后面会细讲),更适合被考虑。
- 该UDF函数功能未来预期的重构、扩展场景较多,需要做得足够可扩展,则GenericUDF在这方面更优秀。
pom文件的依赖导入
UDF开发依赖<dependency><groupId>org.apache.hive</groupId><artifactId>inceptor-exec</artifactId><version>xxx</version>
</dependency>继承示例
1.继承 UDF 类
该方式实现简单,只需新建一个类继承org.apache.hadoop.hive.ql.exec.UDF;
继承UDF类必须实现evaluate方法且返回值类型不能为 void,支持定义多个evaluate方法不同参数列表用于处理不同类型数据;
可通过完善@Description展示UDF用法 UDF样例。
import org.apache.hadoop.hive.ql.exec.UDF;
import org.apache.hadoop.hive.ql.exec.Description;@Description(name="my_plus",value="my_plus() - if string, do concat; if integer, do plus",extended = "Example : \n >select my_plus('a', 'b');\n >ab\n >select my_plus(3, 5);\n >8"
)
/*** 实现UDF函数,若字符串执行拼接,int类型执行加法运算。*/
public class AddUDF extends UDF {/*** 编写一个函数,要求如下:* 1. 函数名必须为 evaluate* 2. 参数和返回值类型可以为:Java基本类型、Java包装类、org.apache.hadoop.io.Writable等类型、List、Map* 3. 函数一定要有返回值,不能为 void*/public String evaluate(String... parameters) {if (parameters == null || parameters.length == 0) {return null;}StringBuilder sb = new StringBuilder();for (String param : parameters) {sb.append(param);}return sb.toString();}/*** 支持函数重载*/public int evaluate(IntWritable... parameters) {if (parameters == null || parameters.length == 0) {return 0;}long sum = 0;for (IntWritable currentNum : parameters) {sum = Math.addExact(sum, currentNum.get());}return (int) sum;}
}2.继承 GenericUDF 类
GenericUDF相比与UDF功能更丰富,支持所有参数类型,实现起来也更加复杂。org.apache.hadoop.hive.ql.udf.generic.GenericUDF API提供了一个通用的接口将任何数据类型的对象当作泛型Object去调用和输出,参数类型由ObjectInspector封装;参数Writable类由DeferredObject封装,使用时简单类型可直接从Writable获取,复杂类型可由ObjectInspector解析。
Java的ObjectInspector类,用于帮助Quark了解复杂对象的内部架构,通过创建特定的ObjectInspector对象替代创建具体类对象,在内存中储存某类对象的信息。在UDF中,ObjectInspector用于帮助Hive引擎将HQL转成MR Job时确定输入和输出的数据类型。Hive语句会生成MapReduce Job执行,所以使用的是Hadoop数据格式,不是编写UDF的Java的数据类型,比如Java的int在Hadoop为IntWritable,String在Hadoop为Text格式,所以我们需要将UDF内的Java数据类型转成正确的Hadoop数据类型以支持Hive将HQL生成MapReduce Job。
继承 GenericUDF 后,必须实现以下三个方法:
public class MyCountUDF extends GenericUDF {private PrimitiveObjectInspector.PrimitiveCategory[] inputType;private transient ObjectInspectorConverters.Converter intConverter;private transient ObjectInspectorConverters.Converter longConverter;// 初始化@Overridepublic ObjectInspector initialize(ObjectInspector[] arguments) throws UDFArgumentException {}// DeferredObject封装实际参数的对应Writable类@Overridepublic Object evaluate(DeferredObject[] deferredObjects) throws HiveException {}// 函数信息@Overridepublic String getDisplayString(String[] strings) {}
}initialize()方法只在 GenericUDF 初始化时被调用一次,执行一些初始化操作,包括:参数个数检查;参数类型检查与转换;确定返回值类型。
a. 参数个数检查;
可通过 arguments 数组的长度来判断函数参数的个数:
// 检查该记录是否传过来正确的参数数量,arguments的长度不为2时,则抛出异常if (arguments.length != 2) {throw new UDFArgumentLengthException("arrayContainsExample only takes 2 arguments: List<T>, T");}b. 参数类型检查与转换;
针对该UDF的每个参数,initialize()方法都会收到一个对应的ObjectInspector参数,通过遍历ObjectInspector数组检查每个参数类型,根据参数类型构造ObjectInspectorConverters.Converter,用于将Hive传递的参数类型转换为对应的Writable封装对象ObjectInspector,供后续统一处理。
ObjectInspector内部有一个枚举类 Category,代表了当前 ObjectInspector 的类型。
public interface ObjectInspector extends Cloneable {public static enum Category {PRIMITIVE, // Hive原始类型LIST, // Hive数组MAP, // Hive MapSTRUCT, // 结构体UNION // 联合体};
}Quark原始类型又细分了多种子类型,PrimitiveObjectInspector 实现了 ObjectInspector,可以更加具体的表示对应的Hive原始类型。
public interface PrimitiveObjectInspector extends ObjectInspector {/*** The primitive types supported by Quark.*/public static enum PrimitiveCategory {VOID, BOOLEAN, BYTE, SHORT, INT, LONG, FLOAT, DOUBLE, STRING,DATE, TIMESTAMP, BINARY, DECIMAL, VARCHAR, CHAR, INTERVAL_YEAR_MONTH, INTERVAL_DAY_TIME,UNKNOWN};
}参数类型检查与转换示例:
for (int i = 0; i < length; i++) { // 遍历每个参数ObjectInspector currentOI = arguments[i];ObjectInspector.Category type = currentOI.getCategory(); // 获取参数类型if (type != ObjectInspector.Category.PRIMITIVE) { // 检查参数类型throw new UDFArgumentException("The function my_count need PRIMITIVE Category, but get " + type);}PrimitiveObjectInspector.PrimitiveCategory primitiveType =((PrimitiveObjectInspector) currentOI).getPrimitiveCategory();inputType[i] = primitiveType;switch (primitiveType) { // 参数类型转换case INT:if (intConverter == null) {ObjectInspector intOI = PrimitiveObjectInspectorFactory.getPrimitiveWritableObjectInspector(primitiveType);intConverter = ObjectInspectorConverters.getConverter(currentOI, intOI);}break;case LONG:if (longConverter == null) {ObjectInspector longOI = PrimitiveObjectInspectorFactory.getPrimitiveWritableObjectInspector(primitiveType);longConverter = ObjectInspectorConverters.getConverter(currentOI, longOI);}break;default:throw new UDFArgumentException("The function my_count need INT OR BIGINT, but get " + primitiveType);}
}c. 确定函数返回值类型
initialize() 需要 return 一个 ObjectInspector 实例,用于表示自定义UDF返回值类型。initialize() 的返回值决定了 evaluate() 的返回值类型。创建ObjectInspector时,不要用new的方式创建,应该用工厂模式去创建以保证相同类型的ObjectInspector只有一个实例,且同一个ObjectInspector可以在代码中多处被使用。
// 自定义UDF返回值类型为Long
return PrimitiveObjectInspectorFactory.writableLongObjectInspector;完整的 initialize() 函数
public ObjectInspector initialize(ObjectInspector[] arguments) throws UDFArgumentException {int length = arguments.length;inputType = new PrimitiveObjectInspector.PrimitiveCategory[length];for (int i = 0; i < length; i++) {ObjectInspector currentOI = arguments[i];ObjectInspector.Category type = currentOI.getCategory();if (type != ObjectInspector.Category.PRIMITIVE) {throw new UDFArgumentException("The function my_count need PRIMITIVE Category, but get " + type);}PrimitiveObjectInspector.PrimitiveCategory primitiveType =((PrimitiveObjectInspector) currentOI).getPrimitiveCategory();inputType[i] = primitiveType;switch (primitiveType) {case INT:if (intConverter == null) {ObjectInspector intOI = PrimitiveObjectInspectorFactory.getPrimitiveWritableObjectInspector(primitiveType);intConverter = ObjectInspectorConverters.getConverter(currentOI, intOI);}break;case LONG:if (longConverter == null) {ObjectInspector longOI = PrimitiveObjectInspectorFactory.getPrimitiveWritableObjectInspector(primitiveType);longConverter = ObjectInspectorConverters.getConverter(currentOI, longOI);}break;default:throw new UDFArgumentException("The function my_count need INT OR BIGINT, but get " + primitiveType);}}return PrimitiveObjectInspectorFactory.writableLongObjectInspector;}evaluate()方法是GenericUDF的核心方法,自定义UDF的实现逻辑。代码实现步骤可以分为三部分:参数接收;自定义UDF核心逻辑;返回处理结果。
第一步:参数接收
evaluate() 的参数就是 自定义UDF 的参数。
/*** Evaluate the GenericUDF with the arguments.** @param arguments* The arguments as DeferedObject, use DeferedObject.get() to get the* actual argument Object. The Objects can be inspected by the* ObjectInspectors passed in the initialize call.* @return The*/
public abstract Object evaluate(DeferredObject[] arguments)throws HiveException;通过源码注释可知,DeferedObject.get() 可以获取参数的值。
/*** A Defered Object allows us to do lazy-evaluation and short-circuiting.* GenericUDF use DeferedObject to pass arguments.*/
public static interface DeferredObject {void prepare(int version) throws HiveException;Object get() throws HiveException;
};再看看 DeferredObject 的源码,DeferedObject.get() 返回的是 Object,传入的参数不同,会是不同的Java类型。
第二步:自定义UDF核心逻辑
这一部分根据实际项目需求自行编写。
第三步:返回处理结果
这一步和 initialize() 的返回值一一对应,基本类型返回值有两种:Writable类型 和 Java包装类型:
- 在 initialize 指定的返回值类型为 Writable类型 时,在 evaluate() 中 return 的就应该是对应的 Writable实例。
- 在 initialize 指定的返回值类型为 Java包装类型 时,在 evaluate() 中 return 的就应该是对应的 Java包装类实例。
evalute()示例
@Overridepublic Object evaluate(DeferredObject[] deferredObjects) throws HiveException {LongWritable out = new LongWritable();for (int i = 0; i < deferredObjects.length; i++) {PrimitiveObjectInspector.PrimitiveCategory type = this.inputType[i];Object param = deferredObjects[i].get();switch (type) {case INT:Object intObject = intConverter.convert(param);out.set(Math.addExact(out.get(), ((IntWritable) intObject).get()));break;case LONG:Object longObject = longConverter.convert(param);out.set(Math.addExact(out.get(), ((LongWritable) longObject).get()));break;default:throw new IllegalStateException("Unexpected type in MyCountUDF evaluate : " + type);}}return out;}getDisplayString() 返回的是 explain 时展示的信息。这里不能return null,否则可能在运行时抛出空指针异常。
@Override
public String getDisplayString(String[] strings) {return "my_count(" + Joiner.on(", ").join(strings) + ")";
}自定义GenericUDF完整示例
@Description(name="my_count",value="my_count(...) - count int or long type numbers",extended = "Example :\n >select my_count(3, 5);\n >8\n >select my_count(3, 5, 25);\n >33"
)
public class MyCountUDF extends GenericUDF {private PrimitiveObjectInspector.PrimitiveCategory[] inputType;private transient ObjectInspectorConverters.Converter intConverter;private transient ObjectInspectorConverters.Converter longConverter;@Overridepublic ObjectInspector initialize(ObjectInspector[] objectInspectors) throws UDFArgumentException {int length = objectInspectors.length;inputType = new PrimitiveObjectInspector.PrimitiveCategory[length];for (int i = 0; i < length; i++) {ObjectInspector currentOI = objectInspectors[i];ObjectInspector.Category type = currentOI.getCategory();if (type != ObjectInspector.Category.PRIMITIVE) {throw new UDFArgumentException("The function my_count need PRIMITIVE Category, but get " + type);}PrimitiveObjectInspector.PrimitiveCategory primitiveType =((PrimitiveObjectInspector) currentOI).getPrimitiveCategory();inputType[i] = primitiveType;switch (primitiveType) {case INT:if (intConverter == null) {ObjectInspector intOI = PrimitiveObjectInspectorFactory.getPrimitiveWritableObjectInspector(primitiveType);intConverter = ObjectInspectorConverters.getConverter(currentOI, intOI);}break;case LONG:if (longConverter == null) {ObjectInspector longOI = PrimitiveObjectInspectorFactory.getPrimitiveWritableObjectInspector(primitiveType);longConverter = ObjectInspectorConverters.getConverter(currentOI, longOI);}break;default:throw new UDFArgumentException("The function my_count need INT OR BIGINT, but get " + primitiveType);}}return PrimitiveObjectInspectorFactory.writableLongObjectInspector;}@Overridepublic Object evaluate(DeferredObject[] deferredObjects) throws HiveException {LongWritable out = new LongWritable();for (int i = 0; i < deferredObjects.length; i++) {PrimitiveObjectInspector.PrimitiveCategory type = this.inputType[i];Object param = deferredObjects[i].get();switch (type) {case INT:Object intObject = intConverter.convert(param);out.set(Math.addExact(out.get(), ((IntWritable) intObject).get()));break;case LONG:Object longObject = longConverter.convert(param);out.set(Math.addExact(out.get(), ((LongWritable) longObject).get()));break;default:throw new IllegalStateException("Unexpected type in MyCountUDF evaluate : " + type);}}return out;}@Overridepublic String getDisplayString(String[] strings) {return "my_count(" + Joiner.on(", ").join(strings) + ")";}
}UDTF
UDTF函数作用都是输入一行数据,将该行数据拆分、并返回多行数据。不同的UDTF函数只是拆分的原理不同、作用的数据格式不同而已。
适用场景
- 流应用中对数据处理,如:字符串解析,hyperbase数据删除,时间段去重,时间段统计
- 数仓数集应用中需要将单行转换为多行,inceptor内置多种UDTF,如:explode,inline,json_tuple等
注意:返回UDTF结果的同时查询其他对象,须引用关键字 LATERAL VIEW
UDTF开发要点
1. 实现UDTF函数需要继承org.apache.hadoop.hive.ql.udf.generic.GenericUDTF
2. 然后重写/实现initialize, process, close三个方法
A. initialize初始化验证,返回字段名和字段类型
initialize初始化:UDTF首先会调用initialize方法,此方法返回UDTF的返回行的信息(返回个数,类型,名称)。initialize针对任务调一次, 作用是定义输出字段的列名、和输出字段的数据类型。
initialize方法示例
@Override/*** 返回数据类型:StructObjectInspector* 定义输出数据的列名、和数据类型。*/public StructObjectInspector initialize(StructObjectInspector argOIs) throws UDFArgumentException {List<String> fieldNames = new ArrayList<String>(); //fieldNames为输出的字段名fieldNames.add("world");List<ObjectInspector> fieldOIs = new ArrayList<ObjectInspector>(); //类型,列输出类型fieldOIs.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);return ObjectInspectorFactory.getStandardStructObjectInspector(fieldNames, fieldOIs);}B. 初始化完成后,调用process方法,对传入的参数进行处理,通过forword()方法把结果返回
process:初始化完成后,会调用process方法,对传入的参数进行处理,可以通过forword()方法把结果写出。process传入一行数据写出去多次,传入一行数据输出多行数据,如:mapreduce单词计数。process针对每行数据调用一次该方法。在initialize初始化的时候,定义输出字段的数据类型是集合,调用forward()将数据写入到一个缓冲区,写入缓冲区的数据也要是集合。
process方法示例
//数据的集合private List<String> dataList = new ArrayList<String>();/*** process(Object[] objects) 参数是一个数组,但是hive中的explode函数接受的是一个,一进多出* @param args* @throws HiveException*/public void process(Object[] args) throws HiveException {//我们现在的需求是传入一个数据,在传入一个分割符//1.获取数据String data = args[0].toString();//2.获取分割符String splitKey = args[1].toString();//3.切分数据,得到一个数组String[] words = data.split(splitKey);//4.想把words里面的数据全部写出去。类似在map方法中,通过context.write方法// 定义是集合、写出去是一个string,类型不匹配,写出也要写出一个集合for (String word : words) {//5.将数据放置集合,EG:传入"hello,world,hdfs"---->写出需要写n次,hello\worlddataList.clear();//清空数据集合dataList.add(word);//5.写出数据的操作forward(dataList);}}C. 最后调用close()方法进行清理工作
最后close()方法调用,对需要清理的方法进行清理,close()方法针对整个任务调一次
UDTF DEMO
下面UDTF 实现的是字符串的分拆,多行输出
package io.transwarp.udtf;
import java.util.ArrayList;
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.exec.UDFArgumentLengthException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDTF;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspectorFactory;
import org.apache.hadoop.hive.serde2.objectinspector.StructObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
public class SplitUDF extends GenericUDTF{@Overridepublic void close() throws HiveException {// TODO Auto-generated method stub}@Overridepublic StructObjectInspector initialize(ObjectInspector[] arg0) throws UDFArgumentException {// TODO Auto-generated method stubif(arg0.length != 1){throw new UDFArgumentLengthException("SplitString only takes one argument");}if(arg0[0].getCategory() != ObjectInspector.Category.PRIMITIVE){throw new UDFArgumentException("SplitString only takes string as a parameter");}ArrayList<String> fieldNames = new ArrayList<>();ArrayList<ObjectInspector> fieldOIs = new ArrayList<>();fieldNames.add("col1");fieldOIs.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);fieldNames.add("col2");fieldOIs.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);return ObjectInspectorFactory.getStandardStructObjectInspector(fieldNames, fieldOIs);}@Overridepublic void process(Object[] arg0) throws HiveException {// TODO Auto-generated method stubString input = arg0[0].toString();String[] inputSplits = input.split("#");for (int i = 0; i < inputSplits.length; i++) {try {String[] result = inputSplits[i].split(":");forward(result);} catch (Exception e) {continue;}}}
}执行效果如下:
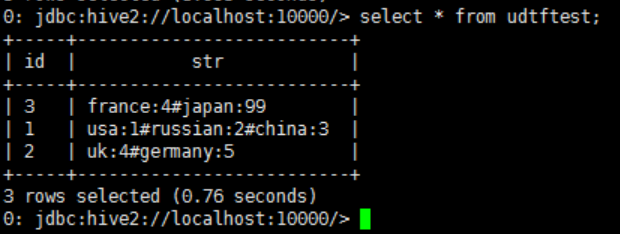

如何使用UDTF
将UDTF打包后,放在inceptor server 所在节点之上(建议不要放在/user/lib/hive/lib/下),之后在连接inceptor执行以下命令,生成临时函数(server有效,重启inceptor失效)
add jar /tmp/timestampUDF.jar
drop temporary function timestamp_ms;
create temporary function timestamp_ms as 'io.transwarp.udf.ToTimestamp';select date, timestamp_ms(date) from table1;UDAF
正如前面所说,UDAF是由用户自主定义的,虽然UDAF的使用可以方便对数据的运算处理,但是使用它的数量建议不要过多,因为UDAF的数量增长和性能下降成线性关系。另外,如果存在大量的嵌套UDAF,系统的性能也会降低,建议用户在可能的情况下写一个没有嵌套或者嵌套较少的UDAF实现相同功能来提高性能。
UDAF开发要点
1. 用户的UDAF必须继承了org.apache.hadoop.hive.ql.exec.UDAF;
2. 用户的UDAF必须包含至少一个实现了org.apache.hadoop.hive.ql.exec的静态类,诸如常见的实现了 UDAFEvaluator。
3. 一个计算函数必须实现的5个方法的具体含义如下:
- - init():主要是负责初始化计算函数并且重设其内部状态,一般就是重设其内部字段。一般在静态类中定义一个内部字段来存放最终的结果。
- - iterate():每一次对一个新值进行聚集计算时候都会调用该方法,计算函数会根据聚集计算结果更新内部状态。当输入值合法或者正确计算了,则就返回true。
- - terminatePartial():Hive需要部分聚集结果的时候会调用该方法,必须要返回一个封装了聚集计算当前状态的对象。
- - merge():Hive进行合并一个部分聚集和另一个部分聚集的时候会调用该方法。
- - terminate():Hive最终聚集结果的时候就会调用该方法。计算函数需要把状态作为一个值返回给用户。
UDAF DEMO
下面的UDAF DEMO目标是实现找到最大值功能,以表中某一字段为参数,返回最大值。
package udaf.transwarp.io;
import org.apache.hadoop.hive.ql.exec.UDAF;
import org.apache.hadoop.hive.ql.exec.UDAFEvaluator;
import org.apache.hadoop.io.IntWritable;//UDAF是输入多个数据行,产生一个数据行
//用户自定义的UDAF必须是继承了UDAF,且内部包含多个实现了exec的静态类
public class MaxiNumber extends UDAF{public static class MaxiNumberIntUDAFEvaluator implements UDAFEvaluator{//最终结果private IntWritable result;//负责初始化计算函数并设置它的内部状态,result是存放最终结果的@Overridepublic void init() {result=null;}//每次对一个新值进行聚集计算都会调用iterate方法public boolean iterate(IntWritable value){if(value==null)return false;if(result==null)result=new IntWritable(value.get());elseresult.set(Math.max(result.get(), value.get()));return true;}//Hive需要部分聚集结果的时候会调用该方法//会返回一个封装了聚集计算当前状态的对象public IntWritable terminatePartial(){return result;}//合并两个部分聚集值会调用这个方法public boolean merge(IntWritable other){return iterate(other);}//Hive需要最终聚集结果时候会调用该方法public IntWritable terminate(){return result;}}
}UDF 的打包与使用
操作前提
将开发好自定义UDF函数的项目打包成jar包,注意:jar 包中的自定义UDF 类名,不能和现有UDF 类,在包名+类名上,完全相同。
部署方式
常见的UDF部署方式有以下三种:
- 把UDF固化到image里,重新打image(推荐);
- 其次是通过创建临时UDF(add jar + temporary function)的方式;
- 创建永久UDF(hdfs jar+permanent function)的方式(可行,但不是很推荐);
方式一 固化UDF
- 视频示例(仅作示范,详情查看下方文字)
此方式的核心逻辑是把UDF jar包放到image的/usr/lib/inceptor/下面,重新制作image。具体步骤如下:
以更换inceptor中的inceptor_2.10-1.1.0-transwarp-6.1.0.jar为例:
1. 进入inceptor image
docker run -it <inceptor_image_id> bash
![]()
2. 打开另一个terminal
3. 替换container中的jar包
docker cp <jar包名称> <container_id>:/usr/lib/inceptor/ <jar包名称>
4. commit修改记录
docker commit <container_id> REPOSITORY:TAG
5. 打开manager管理页面重新启动inceptor服务
6.重启完成后即可查看quark server的pod下/usr/lib/inceptor/是否有新增的jar包

方式二 创建临时UDF
- 视频示例(仅作示范,详情查看下方文字)
1. 查看已存在jar包
LIST JAR;
2. 添加jar包
ADD JAR[S] <local_path>;
// Local_path是jar包所在Inceptor server节点的路径。![]()
3. 创建临时UDF
CREATE TEMPORARY FUNCTION [<db_name>.]<function_name> AS <class_name>;临时UDF在Inceptor重启后失效。如果需要更新临时UDF,需要重启Inceptor重新创建该临时UDF。
示例:
![]()
4. 验证临时UDF
SELECT [<db_name>.]<function_name>() FROM SYSTEM.DUAL;
5. 删除临时UDF
DROP TEMPORARY FUNCTION <if exists> <function_name>;方式三 创建永久UDF
建议优先选取前两种方式,此方式虽然可行但不推荐,故仅介绍基础命令,暂无视频提供。
1. 查看已存在jar包
LIST JAR;2. 添加jar包
ADD JAR[S] <local_or_hdfs_path>;
//Local_path是Inceptor server节点的路径。保证hive用户对jar所在的目录有读权限。3. 创建永久UDF
CREATE PERMANENT FUNCTION [<db_name>.]<function_name> AS <class_name>;如果Inceptor不在local mode,那么资源的地址也必须是非本地URI,比如HDFS地址。
4. 验证永久UDF
SELECT [<db_name>.]<function_name>() FROM SYSTEM.DUAL;
5. 删除永久UDF
DROP PERMANENT FUNCTION <if exists> <function_name>;
相关文章:
聊一聊UDF/UDTF/UDAF是什么,开发要点及如何使用?
背景介绍 UDF来源于Hive,Hive可以允许用户编写自己定义的函数UDF,然后在查询中进行使用。星环Inceptor中的UDF开发规范与Hive相同,目前有3种UDF: A. UDF--以单个数据行为参数,输出单个数据行; UDF&#…...

配置Nginx二级域名
一、环境 (一)配置 1.服务器 linux CentOS 2.反向代理 Nginx 3.开放端口 云服务器开放端口80和443 二、域名备案 (一)腾讯云 1.腾讯云域名备案流程 备注:一级域名备案后,二级域名可以不用再备案&a…...

LeetCode——判断回文数
给你一个整数 x ,如果 x 是一个回文整数,返回 true ;否则,返回 false 。 回文数是指正序(从左向右)和倒序(从右向左)读都是一样的整数。 例如,121 是回文,而 …...
)
shell:使用结构化语句(for、while循环)
1. for命令 下面是bash shell中for命令的基本格式。 for var in list docommands done每次for命令遍历值列表,它都会将列表中的下个值赋给$test变量。$test变量可以像for 命令语句中的其他脚本变量一样使用。在最后一次迭代后,$test变量的值会在shell脚…...
数据结构_绪论
1.数据结构的研究内容 研究数据的特性和数据之间的关系 用计算机解决一个问题的步骤 1.具体问题抽象成数学模型 实质: 分析问题--->提取操作对象--->找出操作对象之间的关系(数据结构)--->用数学语言描述 操作对象对象之间的关系 2.设计算法 3.编程,调试,运行 …...

AI自动生成角色和情节连续的漫画,中山大学联想提出AutoStudio,可以多轮交互式连续生成并保持主题一致性。
中山大学和联想研究院提出AutoStudio: 是一种无需训练的多代理框架,用于多轮交互式图像生成,能够在生成多样化图像的同时保持主体一致性。 AutoStudio 采用三个基于 LLM 的智能体来解释人类意图并为 SD 模型生成适当的布局指导。此外,还引入…...

【经典面试题】RabbitMQ如何防止重复消费?
RabbitMQ的消息消费是有确认机制的,正常情况下,消费者在消费消息成功后,会发送一个确认消息,消息队列接收到之后,就会将该消息从消息队列中删除,下次也就不会再投递了。 但是如果存在网络延迟的问题&#…...

如何自己录制教学视频?零基础也能上手
随着在线教育的蓬勃发展,录制教学视频成为了教师和教育工作者们不可或缺的一项技能。无论是为了远程教学、课程分享还是知识普及,教学视频的录制都变得愈发重要。可是如何自己录制教学视频呢?本文将介绍两种录制教学视频的方法,这…...

【android】用 ExpandableListView 来实现 TreeView树形菜单视图
使用 ExpandableListView 来实现 TreeView 创建一个 ExpandableListAdapter 来为其提供数据。以下演示了如何使用 ExpandableListView 来展示树形结构的数据: 首先,在布局文件中添加 ExpandableListView: <ExpandableListViewandroid:i…...

策略模式与函数式编程应用
策略模式 | 单一职责原则(Single Responsibility Principle, SRP):islenone和islentwo分别根据特定条件返回电话号码 函数式编程: ‘’ if pd.isna(self.note1) else len(re.findall(r’\d, self.note1)) 重复代码: 当…...

docker原理记录C-N-A
docker原理 容器技术的兴起源于 PaaS 技术的普及 Docker 项目通过“容器镜像”,解决了应用打包这个根本性难题容器本身没有价值,有价值的是“容器编排”Cgroups 和 Namespace Cgroups 技术是用来制造约束的主要手段,而Namespace 技术则是用…...

【LeetCode】每日一题:二叉树的层次遍历
给你二叉树的根节点 root ,返回其节点值的 层序遍历 。 (即逐层地,从左到右访问所有节点)。 解题思路 水题 AC代码 # Definition for a binary tree node. # class TreeNode: # def __init__(self, val0, leftNone, rightN…...
单体架构改造为微服务架构之痛点解析
1.微服务职责划分之痛 1.1 痛点描述 微服务的难点在于无法对一些特定职责进行清晰划分,比如某个特定职责应该归属于服务A还是服务B? 1.2 为服务划分原则的痛点 1.2.1 根据存放主要数据的服务所在进行划分 比如一个能根据商品ID找出商品信息的接口,把…...

马面裙的故事:汉服如何通过直播电商实现产业跃迁
【潮汐商业评论/原创】 波澜壮阔的千里江山在马面裙的百褶上展开,织金花纹在女性的步伐之间若隐若现,从明清到现代,如今马面裙又流行了回来,成为女性的流行单品,2024年春节期间,马面裙更是成为华夏女孩们的…...

SaaS产品运营:维护四个不同类型的合作伙伴的实战指南
在SaaS(软件即服务)行业的竞争中,与合作伙伴建立并维护良好关系至关重要。不同类型的合作伙伴对于产品的推广、市场覆盖和用户增长都起着不同的作用。如何有效维护这四种类型合作伙伴?看个案例一起学习吧。 一、合作伙伴的四种类型…...

【监控】3.配置 Grafana 以使用 Prometheus 数据源
1 访问 Grafana 打开浏览器,访问 http://localhost:3000(默认端口)。使用默认的用户名和密码 admin/admin 登录。 2 添加 Prometheus 数据源 进入 Grafana 仪表板,点击左侧菜单中的“Configuration” -> “Data Sources”。…...

【LinuxC语言】网络编程中粘包问题
文章目录 前言什么叫做粘包问题粘包问题如何解决?总结前言 在进行网络编程时,我们经常会遇到一个非常常见但又往往被忽视的问题,那就是"粘包"问题。粘包是指在基于TCP/IP协议的数据传输过程中,由于TCP/IP协议是基于字节流的,这就可能会导致多个数据包被一起接收…...

Docker之jekins的安装
jekins官网地址:Jenkins Plugins (https://plugins.jenkins.io/) jekins 的docker 官方地址:https://hub.docker.com/r/jenkins/jenkins jekins 的docker 允许命令文档地址: docker/README.md at master jenkinsci…...

# bash: chkconfig: command not found 解决方法
bash: chkconfig: command not found 解决方法 一、chkconfig 错误描述: 这个错误表明在 Bash 环境下,尝试执行 chkconfig 命令,但是系统找不到这个命令。chkconfig 命令是一个用于管理 Linux 系统中服务的启动和停止的工具,通常…...

Linux线程互斥锁
目录 🚩看现象,说原因 🚩解决方案 🚩互斥锁 🚀关于互斥锁的理解 🚀关于原子性的理解 🚀如何理解加锁和解锁是原子的 🚩对互斥锁的简单封装 引言 大家有任何疑问,可…...
)
用Python+CCA算法搞定SSVEP脑电信号识别:从理论到代码实战(附GitHub源码)
PythonCCA算法实现SSVEP脑电信号识别实战指南 在脑机接口研究领域,稳态视觉诱发电位(SSVEP)因其高信噪比和稳定特性成为热门研究方向。典型相关分析(CCA)作为SSVEP信号处理的经典算法,以其数学优雅和实现简…...

开源AI工具集Muse:模块化架构与创意工作流实践指南
1. 项目概述:一个面向创意工作者的开源AI工具集最近在开源社区里,一个名为myths-labs/muse的项目引起了我的注意。乍一看这个名字,你可能会联想到艺术灵感,但实际上,它是一个定位非常精准的开发者工具集合。简单来说&a…...

Windows NFSv4.1客户端终极指南:让Windows系统无缝访问NFS服务器
Windows NFSv4.1客户端终极指南:让Windows系统无缝访问NFS服务器 【免费下载链接】ms-nfs41-client NFSv4.1 Client for Windows 项目地址: https://gitcode.com/gh_mirrors/ms/ms-nfs41-client 想要在Windows系统中像操作本地文件一样访问远程NFS服务器吗&a…...

青年教师评副高‘捷径’:这6本被低估的SSCI,认可度不输顶刊!
01 Academic Medicine期刊分区影响因子自引率年文章数教育学1区5.211.5%252篇投稿参考:美国医学院协会(AAMC)官方期刊,审稿周期 2–3 个月,录用率≈20%;可选非 OA 模式免版面费,适合具有实践转…...

AI智能体构建实战:从架构设计到工程落地的关键挑战与解决方案
1. 项目概述:揭开AI智能体构建的隐秘面纱 “构建AI智能体”,这听起来像是当下最酷、最前沿的技术话题。无论是科技新闻还是行业论坛,你都能看到无数关于智能体如何自动化工作流、理解复杂指令、甚至自主决策的激动人心的讨论。然而࿰…...

免费公式识别神器:img2latex-mathpix本地部署完全指南
免费公式识别神器:img2latex-mathpix本地部署完全指南 【免费下载链接】img2latex-mathpix Mathpix has changed their billing policy and no longer has free monthly API requests. This repo is now archived and will not receive any updates for the foresee…...

如何通过命名规范降低代码维护成本:7个命名技巧提升长期项目质量
如何通过命名规范降低代码维护成本:7个命名技巧提升长期项目质量 【免费下载链接】naming-cheatsheet Comprehensive language-agnostic guidelines on variables naming. Home of the A/HC/LC pattern. 项目地址: https://gitcode.com/gh_mirrors/na/naming-chea…...

便民服务渠道智慧整合融通方案
便民服务渠道智慧整合融通方案 目录 第1章项目概述 7 1.1项目背景 7 1.2项目建设目标 7 1.2.1总体目标 8 1.2.2具体目标 8 1.3项目建设范围 9 1.3.1渠道整合范围 9 1.3.2业务覆盖范围 10 1.3.3系统建设范围 10 1.4项目建设意义 11 1.4.1对群众的意义 11 1.4.2对政府的意义 11 …...

从零到一:深入拆解 I/O 多路复用的前世今生与实战选型
1. 从单线程阻塞到多路复用:I/O模型的进化史 第一次写网络程序时,你可能遇到过这样的场景:服务器在accept()一个客户端连接后,整个程序就像被冻住一样,直到这个客户端发送数据才能继续运行。这就是最原始的阻塞I/O模型…...

车载以太网调试‘直连’方案揭秘:不用MCU,如何用两颗PHY芯片搞定100M转换?
车载以太网调试直连方案:两颗PHY芯片实现100M转换的技术解析 在车载电子系统日益复杂的今天,以太网技术凭借其高带宽和可靠性优势,正逐步取代传统的CAN总线成为车载网络的主流选择。然而,当工程师需要调试这些车载以太网设备时&am…...