在Ubuntu 16.04上安装和配置Elasticsearch的方法
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站。
简介
Elasticsearch 是一个用于实时分布式搜索和数据分析的平台。它因易用性、强大功能和可扩展性而备受欢迎。
Elasticsearch 支持 RESTful 操作。这意味着您可以使用 HTTP 方法(GET、POST、PUT、DELETE 等)与 HTTP URI(/collection/entry)结合使用来操作您的数据。直观的 RESTful 方法既方便开发者又用户友好,这也是 Elasticsearch 受欢迎的原因之一。
Elasticsearch 是一款免费且开源的软件,由 Elastic 公司提供支持。这种组合使其适用于个人测试到企业集成等各种场景。
本文将介绍 Elasticsearch,并向您展示如何安装、配置、保护和开始使用它。
先决条件
在按照本教程操作之前,您需要:
-
通过按照《使用 Ubuntu 16.04 进行初始服务器设置》设置好的 Ubuntu 16.04 Droplet,包括创建一个 sudo 非根用户。
-
安装了 Oracle JDK 8,您可以按照这篇 Java 安装文章中的“安装 Oracle JDK”部分进行操作。
除非另有说明,本教程中需要 root 权限的所有命令都应该以具有 sudo 权限的非根用户身份运行。
步骤 1 — 下载并安装 Elasticsearch
Elasticsearch 可以直接从 elastic.co 以 zip、tar.gz、deb 或 rpm 包的形式下载。对于 Ubuntu,最好使用 deb(Debian)包,它会安装运行 Elasticsearch 所需的一切。
首先,更新您的软件包索引。
sudo apt-get update
下载最新的 Elasticsearch 版本,本文撰写时为 2.3.1。
wget https://download.elastic.co/elasticsearch/release/org/elasticsearch/distribution/deb/elasticsearch/2.3.1/elasticsearch-2.3.1.deb
然后按照通常的 Ubuntu 方法使用 dpkg 进行安装。
sudo dpkg -i elasticsearch-2.3.1.deb
这将导致 Elasticsearch 安装在 /usr/share/elasticsearch/,其配置文件放置在 /etc/elasticsearch,并将其 init 脚本添加到 /etc/init.d/elasticsearch。
为了确保 Elasticsearch 随服务器自动启动和停止,将其 init 脚本添加到默认运行级别。
sudo systemctl enable elasticsearch.service
在首次启动 Elasticsearch 之前,请查看下一节关于推荐的最小配置。
步骤 2 — 配置 Elasticsearch
现在 Elasticsearch 及其 Java 依赖已安装,是时候配置 Elasticsearch 了。Elasticsearch 配置文件位于 /etc/elasticsearch 目录中。有两个文件:
-
elasticsearch.yml配置 Elasticsearch 服务器设置。这是存储所有选项(除了日志选项)的地方,这也是我们主要关注的文件。 -
logging.yml提供日志配置。一开始,您不必编辑此文件。您可以保留所有默认的日志选项。您可以在/var/log/elasticsearch中找到生成的日志。
在任何 Elasticsearch 服务器上自定义的第一个变量是 elasticsearch.yml 中的 node.name 和 cluster.name。正如它们的名称所示,node.name 指定服务器(节点)的名称,以及后者所关联的集群。
如果您不自定义这些变量,node.name 将根据 Droplet 主机名自动分配。cluster.name 将自动设置为默认集群的名称。
cluster.name 值被 Elasticsearch 的自动发现功能用于自动发现和关联 Elasticsearch 节点到一个集群。因此,如果您不更改默认值,您可能会在集群中找到不需要的节点,这些节点在同一网络上被发现。
开始使用 nano 或您喜欢的文本编辑器编辑主要的 elasticsearch.yml 配置文件。
sudo nano /etc/elasticsearch/elasticsearch.yml
删除 cluster.name 和 node.name 行开头的 # 字符以取消注释,然后更新它们的值。您在 /etc/elasticsearch/elasticsearch.yml 文件中的第一个配置更改应该如下所示:
. . .
cluster.name: mycluster1
node.name: "My First Node"
. . .
这是您可以使用 Elasticsearch 的最小设置。但是,建议继续阅读配置部分,以更全面地了解和微调 Elasticsearch。
Elasticsearch 的一个特别重要的设置是服务器的角色,即主服务器或从服务器。主服务器 负责集群的健康和稳定性。在具有大量集群节点的大型部署中,建议有多个专用主服务器。通常,专用主服务器不会存储数据或创建索引。因此,不应该有被过载的机会,从而危及集群的健康。
从服务器 用作可以加载数据任务的工作节点。即使从节点过载,只要有其他节点可以承担额外负载,集群的健康就不会受到严重影响。
确定服务器角色的设置称为 node.master。默认情况下,节点是主节点。如果您只有一个 Elasticsearch 节点,应该将此选项保留为默认的 true 值,因为至少需要一个主节点。或者,如果希望将节点配置为从节点,请将变量 node.master 分配为 false 值,如下所示:
. . .
node.master: false
. . .
另一个重要的配置选项是 node.data,它确定节点是否存储数据。在大多数情况下,此选项应该保持其默认值(true),但有两种情况下您可能希望不在节点上存储数据。一种情况是当节点是之前提到的专用主节点时。另一种情况是当节点仅用于从其他节点获取数据和聚合结果时。在后一种情况下,节点将充当 搜索负载均衡器。
同样,如果您只有一个 Elasticsearch 节点,您不应更改此值。否则,要禁用本地存储数据,请将 node.data 指定为 false,如下所示:
. . .
node.data: false
. . .
在具有许多节点的较大 Elasticsearch 部署中,另外两个重要选项是 index.number_of_shards 和 index.number_of_replicas。前者确定索引将被分割成多少片或 分片。后者定义将分布在集群中的副本数量。拥有更多分片可以提高索引性能,而拥有更多副本可以加快搜索速度。
默认情况下,分片数为 5,副本数为 1。假设您仍在单个节点上探索和测试 Elasticsearch,您可以从一个分片和零副本开始。因此,它们的值应该设置如下:
. . .
index.number_of_shards: 1
index.number_of_replicas: 0
. . .
您可能有兴趣更改的最后一个设置是 path.data,它确定数据存储的路径。默认路径是 /var/lib/elasticsearch。在生产环境中,建议您为存储 Elasticsearch 数据使用专用分区和挂载点。在最佳情况下,这个专用分区将是一个单独的存储介质,它将提供更好的性能和数据隔离。您可以通过如下方式指定不同的 path.data 路径:
. . .
path.data: /media/different_media
. . .
一旦您做出所有更改,请保存并退出文件。现在您可以首次启动 Elasticsearch。
sudo systemctl start elasticsearch
在尝试使用它之前,请给 Elasticsearch 一些时间完全启动。否则,您可能会收到关于无法连接的错误。
第三步 —— 安全配置 Elasticsearch
默认情况下,Elasticsearch 没有内置安全性,可以被可以访问 HTTP API 的任何人控制。这并不总是一个安全风险,因为 Elasticsearch 只监听回环接口(即 127.0.0.1),只能在本地访问。因此,不可能进行公共访问,只要所有服务器用户都是受信任的,或者这是一个专用的 Elasticsearch 服务器,你的 Elasticsearch 就足够安全。
但是,如果你希望加强安全性,首先要做的是启用身份验证。身份验证由商业版的 Shield 插件提供。不幸的是,这个插件不是免费的,但你可以使用免费的 30 天试用来测试它。它的官方页面有很好的安装和配置说明。你可能需要额外了解的唯一一件事是 Elasticsearch 插件安装管理器的路径是 /usr/share/elasticsearch/bin/plugin。
如果你不想使用商业插件,但仍然需要允许远程访问 HTTP API,你至少可以通过 Ubuntu 的默认防火墙 UFW(Uncomplicated Firewall)限制网络暴露。默认情况下,UFW 已安装但未启用。如果你决定使用它,请按照以下步骤操作:
首先,创建规则以允许任何所需的服务。你至少需要允许 SSH,以便可以登录服务器。要允许 SSH 的全球访问,可以将端口 22 加入白名单。
sudo ufw allow 22
然后允许对受信任的远程主机(例如 TRUSTED_IP)的默认 Elasticsearch HTTP API 端口(TCP 9200)的访问,如下所示:
sudo ufw allow from TRUSTED_IP to any port 9200
之后,使用以下命令启用 UFW:
sudo ufw enable
最后,使用以下命令检查 UFW 的状态:
sudo ufw status
如果你已经正确指定了规则,输出应该如下所示:
[secondary_label Output of java -version]
Status: activeTo Action From
-- ------ ----
9200 ALLOW TRUSTED_IP
22 ALLOW Anywhere
22 (v6) ALLOW Anywhere (v6)
确认 UFW 已启用并保护 Elasticsearch 端口 9200 后,你可以允许 Elasticsearch 监听外部连接。要做到这一点,再次打开 elasticsearch.yml 配置文件。
sudo nano /etc/elasticsearch/elasticsearch.yml
找到包含 network.bind_host 的行,通过删除行首的 # 字符来取消注释,并将值更改为 0.0.0.0,使其如下所示:
. . .
network.host: 0.0.0.0
. . .
我们指定了 0.0.0.0,以便 Elasticsearch 监听所有接口和绑定的 IP。如果你希望它只监听特定接口,可以在 0.0.0.0 的位置指定其 IP。
要使上述设置生效,使用以下命令重新启动 Elasticsearch:
sudo systemctl restart elasticsearch
之后,尝试从受信任的主机连接到 Elasticsearch。如果无法连接,请确保 UFW 正常工作,并且已正确指定了 network.host 变量。
第四步 —— 测试 Elasticsearch
到目前为止,Elasticsearch 应该在端口 9200 上运行。你可以使用 curl,这个命令行客户端 URL 传输工具和一个简单的 GET 请求来测试它。
curl -X GET 'http://localhost:9200'
你应该会看到以下响应:
[secondary_label Output of curl]
{"name" : "My First Node","cluster_name" : "mycluster1","version" : {"number" : "2.3.1","build_hash" : "bd980929010aef404e7cb0843e61d0665269fc39","build_timestamp" : "2016-04-04T12:25:05Z","build_snapshot" : false,"lucene_version" : "5.5.0"},"tagline" : "You Know, for Search"
}
如果你看到类似上面的响应,说明 Elasticsearch 正常工作。如果没有,请确保你已正确遵循安装说明,并且已允许 Elasticsearch 充分启动。
要对 Elasticsearch 进行更彻底的检查,执行以下命令:
curl -XGET 'http://localhost:9200/_nodes?pretty'
在上述命令的输出中,你可以看到并验证节点、集群、应用程序路径、模块等的所有当前设置。
第五步 — 使用 Elasticsearch
要开始使用 Elasticsearch,让我们首先添加一些数据。如前所述,Elasticsearch 使用 RESTful API,响应通常的 CRUD 命令:create(创建)、read(读取)、update(更新)和 delete(删除)。为了使用它,我们将再次使用 curl。
您可以使用以下命令添加您的第一个条目:
curl -X POST 'http://localhost:9200/tutorial/helloworld/1' -d '{ "message": "Hello World!" }'
您应该会看到以下响应:
{"_index":"tutorial","_type":"helloworld","_id":"1","_version":1,"_shards":{"total":2,"successful":1,"failed":0},"created":true}
通过 curl,我们向 Elasticsearch 服务器发送了一个 HTTP POST 请求。请求的 URI 是 /tutorial/helloworld/1,带有几个参数:
tutorial是 Elasticsearch 中数据的索引。helloworld是类型。1是上述索引和类型下我们条目的 id。
您可以使用 HTTP GET 请求检索这个第一个条目。
curl -X GET 'http://localhost:9200/tutorial/helloworld/1'
结果应该如下所示:
{"_index":"tutorial","_type":"helloworld","_id":"1","_version":1,"found":true,"_source":{ "message": "Hello World!" }}
要修改现有条目,您可以使用 HTTP PUT 请求。
curl -X PUT 'localhost:9200/tutorial/helloworld/1?pretty' -d '
{"message": "Hello People!"
}'
Elasticsearch 应该会确认成功修改,如下所示:
{"_index" : "tutorial","_type" : "helloworld","_id" : "1","_version" : 2,"_shards" : {"total" : 2,"successful" : 1,"failed" : 0},"created" : false
}
在上面的示例中,我们将第一个条目的 message 修改为 “Hello People!”。因此,版本号已自动增加到 2。
您可能已经注意到上述请求中的额外参数 pretty。它启用了人类可读的格式,这样您可以将每个数据字段写在新的一行上。当检索数据并获得更好的输出时,您也可以使结果“漂亮化”:
curl -X GET 'http://localhost:9200/tutorial/helloworld/1?pretty'
现在响应将以更好的格式呈现:
{"_index" : "tutorial","_type" : "helloworld","_id" : "1","_version" : 2,"found" : true,"_source" : {"message" : "Hello People!"}
}
到目前为止,我们已经向 Elasticsearch 添加了数据并进行了查询。要了解其他操作,请查看 API 文档。
结论
这就是安装、配置和开始使用 Elasticsearch 有多么容易。一旦您已经足够熟悉手动查询,您的下一个任务将是从您的应用程序开始使用它。
相关文章:

在Ubuntu 16.04上安装和配置Elasticsearch的方法
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站。 简介 Elasticsearch 是一个用于实时分布式搜索和数据分析的平台。它因易用性、强大功能和可扩展性而备受欢迎。 Elasticsearch 支持 R…...

C#给SqlSugar封装一个单例类
.NET兼职社区 可以直接用,轻量方便,无需重复造轮子。 这里只对CRUD进行封装,我的应用比较简单。 using SqlSugar; using System.Collections.Generic;namespace MusicApp.Assist {internal class SqlSugarAssist{private static readonly ob…...
)
Postman接口测试工具的原理及应用详解(六)
本系列文章简介: 在当今软件开发的世界中,接口测试作为保证软件质量的重要一环,其重要性不言而喻。随着前后端分离开发模式的普及,接口测试已成为连接前后端开发的桥梁,确保前后端之间的数据交互准确无误。在这样的背景…...

【算法 之插入排序 原理及案例】
插入排序原理: 插入排序(Insertion Sort)是一种简单直观的排序算法。它的工作原理是通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入。插入排序在实现上,通常…...
第一节:如何开发第一个spring boot3.x项目(自学Spring boot 3.x的第一天)
大家好,我是网创有方,从今天开始,我会记录每篇我自学spring boot3.x的经验。只要我不偷懒,学完应该很快,哈哈,更新速度尽可能快,想和大佬们一块讨论,如果需要讨论的欢迎一起评论区留…...

JS逆向:由 words 、sigBytes 引发的一系列思考与实践
【作者主页】:小鱼神1024 【擅长领域】:JS逆向、小程序逆向、AST还原、验证码突防、Python开发、浏览器插件开发、React前端开发、NestJS后端开发等等 在做JS逆向时,你是否经常看到 words 和 sigBytes 这两个属性呢,比如ÿ…...
)
计算机的错误计算(十五)
摘要 介绍历史上由于计算精度问题引起的灾难或事件。 今天换个话题,说说历史上曾经发生过的一些事件。 1961 年 , 美国麻省理工学院气象学家洛伦兹在仿真天气预报时 , 将 0.506127 舍入到 0.506 , 所得计算结果大相径庭 ! 这种“差之毫厘 , 谬以千里”的现象…...

制作img文件
安装软件包 sudo apt-get install dosfstools dump parted kpartx 创建空白img文件 sudo dd if/dev/zero ofraspberrypi.img bs1M count4000 给img文件分区 sudo parted raspberrypi.img --script -- mklabel msdos sudo parted raspberrypi.img --script -- mkpart primar…...

GB28181视频汇聚平台EasyCVR接入Ehome设备视频播放出现异常是什么原因?
多协议接入视频汇聚平台EasyCVR视频监控系统采用了开放式的架构,系统可兼容多协议接入,包括市场标准协议:国标GB/T 28181协议、GA/T 1400协议、JT808、RTMP、RTSP/Onvif协议;以及主流厂家私有协议及SDK,如:…...

Java利用poi实现word,excel,ppt,pdf等各类型文档密码检测
介绍 最近工作上需要对word,excel,ppt,pdf等各类型文档密码检测,对文件进行分类,有密码的和没密码的做区分。查了一堆资料和GPT都不是很满意,最后东拼西凑搞了个相对全面的检测工具代码类,希望能给需要的人带来帮助。 说明 这段…...

顺序表与链表学习笔记
顺序表及其结构定义 (1)结构定义 顺序存储: 顺序表的元素按顺序存储在一块连续的内存区域中,每个元素占用相同大小的存储空间。通过数组实现,每个元素可以通过下标快速访问。 存储密度高: 因为顺序表使用…...
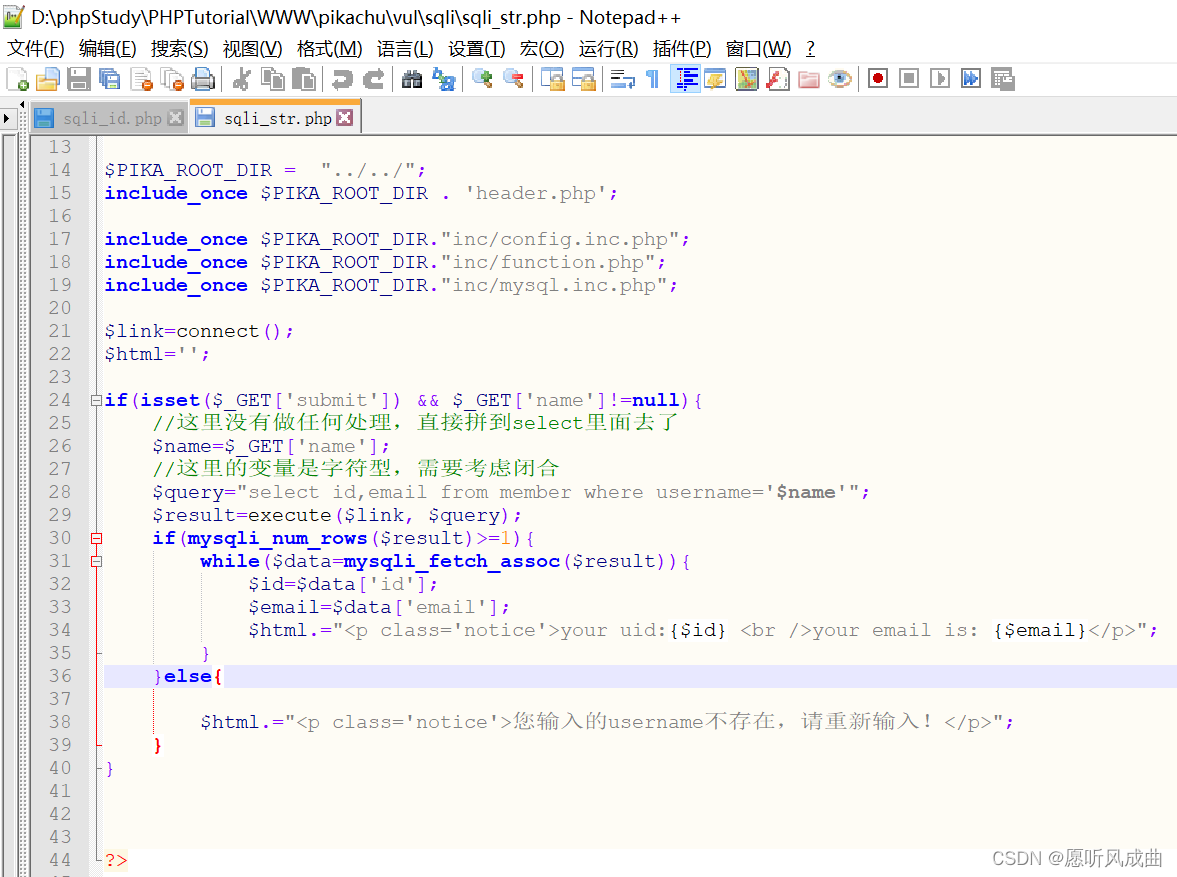
2.SQL注入-字符型
SQL注入-字符型(get) 输入kobe查询出现id和邮箱 猜测语句,字符在数据库中需要用到单引号或者双引号 select 字段1,字段2 from 表名 where usernamekobe;在数据库中查询对应的kobe,根据上图对应上。 select id,email from member where usernamekobe;编写payload语…...

在Ubuntu 14.04上安装和配置Elasticsearch的方法
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站。 简介 Elasticsearch 是一个用于实时分布式搜索和数据分析的平台。它因易用性、强大功能和可扩展性而备受欢迎。 Elasticsearch 支持 R…...

C++:inline关键字nullptr
inline关键字 C中inline使用关键点强调 (1)inline是一种“用于实现的关键字”,而不是一种“用于声明的关键字”,所以关键字 inline 必须与函数定义体放在一起,而不是和声明放在一起 (2)如果希望在多个c文件中使用,则inline函数应…...

数字信号处理实验三(IIR数字滤波器设计)
IIR数字滤波器设计(2学时) 要求: 产生一复合信号序列,该序列包含幅度相同的28Hz、50Hz、100Hz、150Hz的单音(单频)信号;其中,50Hz及其谐波为工频干扰(注:采样…...

Why is Kafka fast?(Kafka性能基石)
Kafka概述 Why is kafka fast? 思考一下,当我们在讨论Kafka快的时候我们是在谈论什么呢?What does it even mean that Kafka is fast? 我们是在谈论kafka的低延迟(low latency)还是在讨论吞吐量(through…...

Linux下的SSH详解及Ubuntu教程
前言 SSH(Secure Shell)是一种用于计算机之间安全通信的协议,广泛应用于远程登录、系统管理和文件传输等场景。本文将详细介绍SSH在Linux系统(特别是Ubuntu)下的使用,包括安装、配置、密钥管理和常见应用&…...
MobPush HarmonyOS NEXT 版本集成指南
开发工具:DevEco Studio 集成方式:在线集成 HarmonyOS API支持:> 11 集成前准备 注册账号 使用MobSDK之前,需要先在MobTech官网注册开发者账号,并获取MobTech提供的AppKey和AppSecret,详情可以点击查…...

什么是封装?为什么要封装?
什么是封装? 封装是计算机科学中的一个重要概念,尤其在面向对象编程(OOP)中占据核心地位。封装主要指的是将数据(属性)和对这些数据的操作(方法)组合在一个单元中(我们称…...
远程桌面无法复制粘贴文件到本地怎么办?
远程桌面不能复制粘贴问题 Windows远程桌面为我们提供了随时随地访问文件和数据的便捷途径,大大提升了工作和生活的效率。然而,在使用过程中,我们也可能遇到一些问题。例如,在通过远程桌面传输文件时,常常会出现无法复…...

突破性创新:Midscene.js如何用AI视觉驱动重塑跨平台自动化测试
突破性创新:Midscene.js如何用AI视觉驱动重塑跨平台自动化测试 【免费下载链接】midscene AI-powered, vision-driven UI automation for every platform. 项目地址: https://gitcode.com/GitHub_Trending/mid/midscene 在当今复杂的软件生态中,跨…...

GenAIScript:用脚本化AI工作流提升代码生成效率与工程化实践
1. 项目概述:当AI遇上代码生成,GenAIScript带来了什么?如果你最近在关注AI如何改变开发工作流,特别是微软在AI领域的动作,那么microsoft/genaiscript这个项目绝对值得你花时间深入研究。这不仅仅是一个简单的代码生成工…...

模型服务化部署:用vLLM/Ollama搭建高并发API,支持流式输出与多轮对话
系列导读 你现在看到的是《本地大模型私有化部署与优化:从入门到生产级实战》的第 3/10 篇,当前这篇会重点解决:让你的本地模型像ChatGPT一样提供稳定API,支持真实业务场景的并发请求。 上一篇回顾:第 2 篇《模型下载与转换实战:从HuggingFace到GGUF/SafeTensors,格式…...

Spek音频频谱分析器:从声音可视化到音频质量检测的完整指南
Spek音频频谱分析器:从声音可视化到音频质量检测的完整指南 【免费下载链接】spek Acoustic spectrum analyser 项目地址: https://gitcode.com/gh_mirrors/sp/spek 当你打开一个音频文件,听到杂音或失真时,是否想过如何精确诊断问题所…...

基于树莓派与AstroPrint搭建无线3D打印控制中心实战指南
1. 项目概述:为什么需要无线3D打印控制?如果你和我一样,是个喜欢折腾3D打印机的创客或爱好者,那你肯定经历过这样的场景:为了打印一个模型,需要先在电脑上用切片软件生成G-code文件,然后找到读卡…...

黑金AX301开发板+HS-04模块:FPGA超声波测距从原理到数码管显示的保姆级教程
黑金AX301开发板实战:基于HS-04模块的FPGA超声波测距系统设计 当超声波传感器遇到FPGA,我们能创造出怎样的精准测距系统?本文将带你从硬件连接到Verilog编码,完整实现一个基于黑金AX301开发板和HS-04超声波模块的测距系统。不同于…...

应对开放式目标检测精度与速度瓶颈:GroundingDINO配置实战选择策略
应对开放式目标检测精度与速度瓶颈:GroundingDINO配置实战选择策略 【免费下载链接】GroundingDINO [ECCV 2024] Official implementation of the paper "Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection" 项…...

从FOC电机库偷师:手把手教你用C语言写一个自己的“数学加速库”
从FOC电机库偷师:手把手教你用C语言写一个自己的"数学加速库" 在嵌入式开发领域,性能优化永远是个绕不开的话题。当你在STM32上跑电机控制算法时,突然发现三角函数计算成了瓶颈;当你处理传感器数据时,浮点运…...

Qt表格控件QTableWidget的5个高级玩法:自定义表头、单元格合并、右键菜单你都会了吗?
Qt表格控件QTableWidget的5个高级玩法实战指南 在桌面应用开发中,表格控件一直是数据展示和交互的核心组件。Qt框架提供的QTableWidget以其灵活性和强大功能,成为开发者构建专业级表格界面的首选工具。但很多开发者仅停留在基础使用层面,未能…...

Spinning Up模型保存终极指南:checkpoint管理完整教程
Spinning Up模型保存终极指南:checkpoint管理完整教程 【免费下载链接】spinningup An educational resource to help anyone learn deep reinforcement learning. 项目地址: https://gitcode.com/gh_mirrors/sp/spinningup 深度强化学习训练过程中ÿ…...