昇思25天学习打卡营第11天|基于MindSpore通过GPT实现情感分类
学AI还能赢奖品?每天30分钟,25天打通AI任督二脉 (qq.com)

基于MindSpore通过GPT实现情感分类
%%capture captured_output
# 实验环境已经预装了mindspore==2.2.14,如需更换mindspore版本,可更改下面mindspore的版本号
!pip uninstall mindspore -y
!pip install -i https://pypi.mirrors.ustc.edu.cn/simple mindspore==2.2.14# 该案例在 mindnlp 0.3.1 版本完成适配,如果发现案例跑不通,可以指定mindnlp版本,执行`!pip install mindnlp==0.3.1`
!pip install mindnlp
!pip install jieba
%env HF_ENDPOINT=https://hf-mirror.comimport osimport mindspore
from mindspore.dataset import text, GeneratorDataset, transforms
from mindspore import nnfrom mindnlp.dataset import load_datasetfrom mindnlp._legacy.engine import Trainer, Evaluator
from mindnlp._legacy.engine.callbacks import CheckpointCallback, BestModelCallback
from mindnlp._legacy.metrics import Accuracyimdb_ds = load_dataset('imdb', split=['train', 'test'])
imdb_train = imdb_ds['train']
imdb_test = imdb_ds['test']imdb_train.get_dataset_size()加载IMDB数据集。将IMDB数据集分为训练集和测试集。IMDB (Internet Movie Database) 数据集包含来自著名在线电影数据库 IMDB 的电影评论。每条评论都被标注为正面(positive)或负面(negative),因此该数据集是一个二分类问题,也就是情感分类问题。
import numpy as npdef process_dataset(dataset, tokenizer, max_seq_len=512, batch_size=4, shuffle=False):is_ascend = mindspore.get_context('device_target') == 'Ascend'def tokenize(text):if is_ascend:tokenized = tokenizer(text, padding='max_length', truncation=True, max_length=max_seq_len)else:tokenized = tokenizer(text, truncation=True, max_length=max_seq_len)return tokenized['input_ids'], tokenized['attention_mask']if shuffle:dataset = dataset.shuffle(batch_size)# map datasetdataset = dataset.map(operations=[tokenize], input_columns="text", output_columns=['input_ids', 'attention_mask'])dataset = dataset.map(operations=transforms.TypeCast(mindspore.int32), input_columns="label", output_columns="labels")# batch datasetif is_ascend:dataset = dataset.batch(batch_size)else:dataset = dataset.padded_batch(batch_size, pad_info={'input_ids': (None, tokenizer.pad_token_id),'attention_mask': (None, 0)})return dataset定义数据预处理函数。这个函数输入参数为数据集、分词器(GPT Tokenizer)以及一些可选参数,如最大序列长度、批量大小和是否打乱数据。预处理包括将文本转换为模型可以理解的输入格式(如input_ids和attention_mask),并将标签转换为整数类型。
from mindnlp.transformers import GPTTokenizer
# tokenizer
gpt_tokenizer = GPTTokenizer.from_pretrained('openai-gpt')# add sepcial token: <PAD>
special_tokens_dict = {"bos_token": "<bos>","eos_token": "<eos>","pad_token": "<pad>",
}
num_added_toks = gpt_tokenizer.add_special_tokens(special_tokens_dict)加载GPT分词器并增加特殊标记。
# split train dataset into train and valid datasets
imdb_train, imdb_val = imdb_train.split([0.7, 0.3])将训练集划分为训练集和验证集。
dataset_train = process_dataset(imdb_train, gpt_tokenizer, shuffle=True)
dataset_val = process_dataset(imdb_val, gpt_tokenizer)
dataset_test = process_dataset(imdb_test, gpt_tokenizer)用 process_dataset 函数对训练集、验证集和测试集进行处理,得到相应的数据集对象。
next(dataset_train.create_tuple_iterator())from mindnlp.transformers import GPTForSequenceClassification
from mindspore.experimental.optim import Adam# set bert config and define parameters for training
model = GPTForSequenceClassification.from_pretrained('openai-gpt', num_labels=2)
model.config.pad_token_id = gpt_tokenizer.pad_token_id
model.resize_token_embeddings(model.config.vocab_size + 3)optimizer = nn.Adam(model.trainable_params(), learning_rate=2e-5)metric = Accuracy()# define callbacks to save checkpoints
ckpoint_cb = CheckpointCallback(save_path='checkpoint', ckpt_name='gpt_imdb_finetune', epochs=1, keep_checkpoint_max=2)
best_model_cb = BestModelCallback(save_path='checkpoint', ckpt_name='gpt_imdb_finetune_best', auto_load=True)trainer = Trainer(network=model, train_dataset=dataset_train,eval_dataset=dataset_train, metrics=metric,epochs=1, optimizer=optimizer, callbacks=[ckpoint_cb, best_model_cb],jit=False)导入 GPTForSequenceClassification 模型和 Adam 优化器。设置GPT模型的配置信息,包括pad_token_id和词汇表大小。使用Adam优化器对模型的可训练参数进行优化(从这里没有看出是更新部分参数,还是全部参数,有可能是部分参数。通常会改变最后一层分类器的权重和偏置,其他层的权重被冻结不变或者只微小更新些许参数。)。
Accuracy作为评价指标。
定义回调函数用于保存检查点:
- CheckpointCallback:用于定期保存模型权重,save_path 指定了保存路径,ckpt_name保存文件的前缀,epochs=1 每个epoch保存一次,keep_checkpoint_max=2 表示最多保留2个检查点文件。
- BestModelCallback:用于保存验证集上表现最好的模型,auto_load=True表示在训练结束后自动加载最优模型的权重。
创建 Trainer 对象,传入以下参数:
- network:要训练的模型。
- train_dataset:训练数据集。
- eval_dataset:验证数据集。
- metrics:评估指标。
- epochs:训练轮数。
- optimizer:优化器。
- callbacks:回调函数列表,包括检查点保存和最佳模型保存。
- jit:是否启用JIT编译,这里设置为False。
trainer.run(tgt_columns="labels")通过 Trainer 的 run 方法启动训练,指定了训练过程中的目标标签列为 "labels"。
evaluator = Evaluator(network=model, eval_dataset=dataset_test, metrics=metric)
evaluator.run(tgt_columns="labels")创建 Evaluator 对象,传入以下参数:
- network:要评估的模型。
- eval_dataset:测试数据集。
- metrics:评估指标。

用MindSpore通过GPT实现情感分类(Sentiment Classification)的示例。首先加载了IMDB影评数据集,并将其划分为训练集、验证集和测试集。然后使用GPTTokenizer对文本进行了标记化和转换。接下来,使用GPTForSequenceClassification构建了情感分类模型,并定义了优化器和评估指标。使用Trainer进行模型的训练,并设置了保存检查点的回调函数。训练完成后,通过Evaluator对测试集进行评估,输出分类准确率。通过对IMDB影评数据集进行训练和评估,模型可以自动进行情感分类,识别出正面或负面情感。
相关文章:
昇思25天学习打卡营第11天|基于MindSpore通过GPT实现情感分类
学AI还能赢奖品?每天30分钟,25天打通AI任督二脉 (qq.com) 基于MindSpore通过GPT实现情感分类 %%capture captured_output # 实验环境已经预装了mindspore2.2.14,如需更换mindspore版本,可更改下面mindspore的版本号 !pip uninsta…...

【Python】变量与基本数据类型
个人主页:【😊个人主页】 系列专栏:【❤️Python】 文章目录 前言变量声明变量变量的命名规则 变量赋值多个变量赋值 标准数据类型变量的使用方式存储和访问数据:参与逻辑运算和数学运算在函数间传递数据构建复杂的数据结构 NameE…...

Unity按键表大全
Unity键值对应表# KeyCode是由Event.keyCode返回的。这些直接映射到键盘上的物理键,以下是键值对应列表: 常用键# Backspace 退格键 Delete Delete键 TabTab键 Clear Clear键 Return 回车键 Pause 暂停键 Escape ESC键 Space 空格键 小键盘# …...

第一周java。2
方法的作用 将重复的代码包装起来,写成方法,提高代码的复用性。 方法的语法 方法的语法格式如下 : [修饰符] 方法返回值类型 方法名(形参列表) { //由零条到多条可执行性语句组成的方法体return 返回值; } 定义方法语法格式的详细说明如下…...

Arduino - Keypad 键盘
Arduino - Keypad Arduino - Keypad The keypad is widely used in many devices such as door lock, ATM, calculator… 键盘广泛应用于门锁、ATM、计算器等多种设备中。 In this tutorial, we will learn: 在本教程中,我们将学习: How to use key…...

国产芯片方案/蓝牙咖啡电子秤方案研发
咖啡电子秤芯片方案精确值可做到分度值0.1g的精准称重,并带有过载提示、自动归零、去皮称重、压低报警等功能,工作电压在2.4V~3.6V之间,满足于咖啡电子秤的电压使用。同时咖啡电子秤PCBA设计可支持四个单位显示,分别为:g、lb、oz、…...

reactjs18 中使用@reduxjs/toolkit同步异步数据的使用
react18 中使用reduxjs/toolkit 1.安装依赖包 yarn add reduxjs/toolkit react-redux2.创建 store 根目录下面创建 store 文件夹,然后创建 index.js 文件。 import { configureStore } from "reduxjs/toolkit"; import { counterReducer } from "…...
剧本杀小程序:助力商家发展,提高游戏体验
近几年,剧本杀游戏已经成为了当下年轻人娱乐的游戏社交方式。与其他游戏相比,剧本杀游戏具有强大的社交性,玩家在游戏中既可以推理玩游戏,也可以与其他玩家交流互动,提高玩家的游戏体验感。 随着互联网的发展…...
pikachu靶场 利用Rce上传一句话木马案例(工具:中国蚁剑)
目录 一、准备靶场,进入RCE 二、测试写入文件 三、使用中国蚁剑 一、准备靶场,进入RCE 我这里用的是pikachu 打开pikachu靶场,选择 RCE > exec "ping" 测试是否存在 Rce 漏洞 因为我们猜测在这个 ping 功能是直接调用系统…...

CenterOS7安装java
CenterOS7安装java #进入安装目录 cd /usr/local/soft/java#wget下载java8 #直接进入官网选择相应的版本进行下载,然后把下载链接复制下来就可以下载了 #不时间的下载链接不一样 wget http://download.oracle.com/otn-pub/java/jdk/8u181-b13/96a7b8442fe848ef90c9…...

react 重新加载子组件
在React中,要重新加载某个子组件,你可以通过改变该组件的key属性来强制它重新渲染。这是因为React会在key变化时销毁旧的组件实例并创建一个新的实例。 多的不说直接上代码 import React, { useState } from react; import ChildComponent from ../chil…...
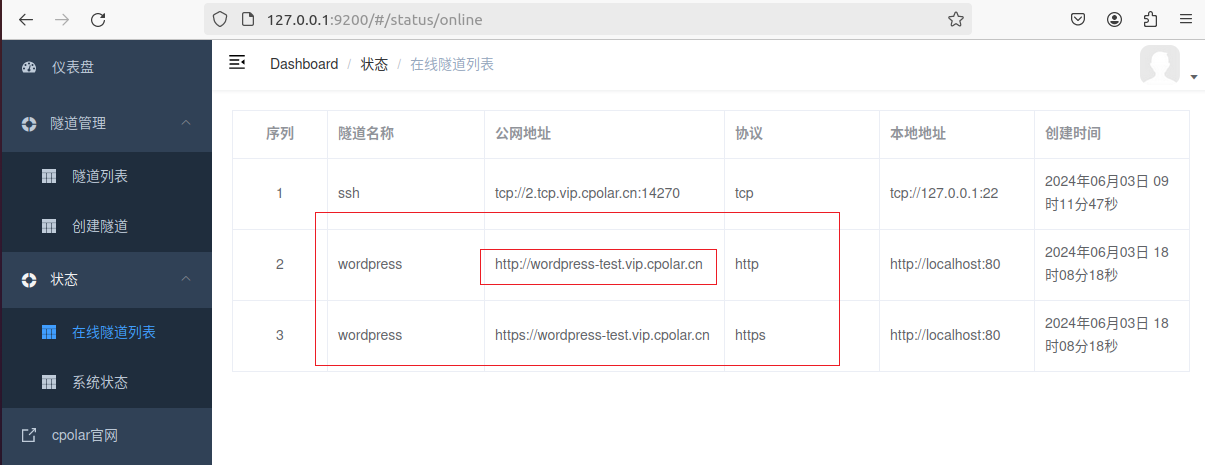
从零开始使用WordPress搭建个人网站并一键发布公网详细教程
文章目录 前言1. 搭建网站:安装WordPress2. 搭建网站:创建WordPress数据库3. 搭建网站:安装相对URL插件4. 搭建网站:内网穿透发布网站4.1 命令行方式:4.2. 配置wordpress公网地址 5. 固定WordPress公网地址5.1. 固定地…...

浅谈chrome引擎
Chrome引擎主要包括其浏览器内核Blink、JavaScript引擎V8以及其渲染、网络、安全等子系统。下面我将对这些关键部分进行简要说明分析 1. Blink浏览器内核 Blink是Google开发的浏览器排版引擎,自Chrome 28版本起替代了Webkit作为Chrome的渲染引擎。Blink基于Webkit…...

【常用知识点-Java】创建文件夹
Author:赵志乾 Date:2024-07-04 Declaration:All Right Reserved!!! 1. 简介 java.io.File提供了mkdir()和mkdirs()方法创建文件夹,两者区别:mkdir()仅创建单层文件夹,如…...

【JavaScript脚本宇宙】颜色处理神器大比拼:哪款JavaScript库最适合你?
提升设计与开发效率:深入解析六大颜色处理库 前言 在现代前端开发中,颜色处理是设计和用户体验的重要组成部分。无论是网页设计、数据可视化还是图形设计,都需要强大的颜色处理功能来实现多样化的视觉效果。本文将探讨几种流行的JavaScript…...
怎么录制电脑内部声音?好用的录音软件分享,看这篇就够了!
如何录制电脑内部声音?平时使用电脑工作,难免会遇到需要录音的情况。好用的录音软件有很多,也有部分录屏工具也支持录音功能。 那么如何录制电脑内部声音呢?本文整理了几个录制电脑内部声音的方法,如果你需要在电脑上录…...

ios CCNSDate.m
// // CCNSDate.h // CCFC // // Created by xichen on 11-12-17. // Copyright 2011年 ccteam. All rights reserved. //#import <Foundation/Foundation.h>interface NSDate(cc)// 获取系统时间(yyyy-MM-dd HH:mm:ss.SSS格式)(NSString *)getSystemTimeStr;// prin…...
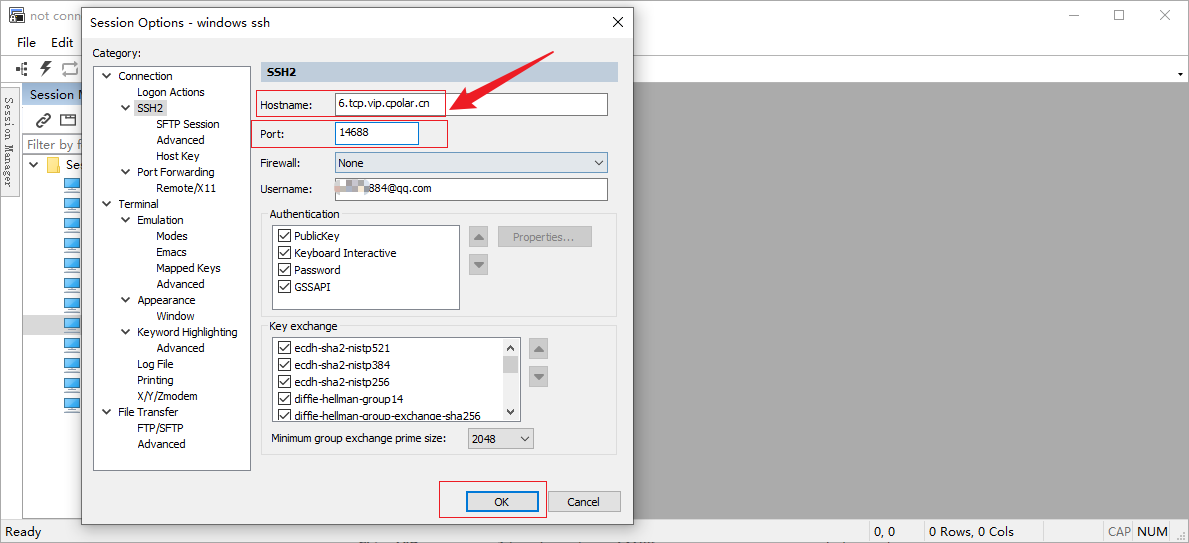
Windows系统安装SSH服务结合内网穿透配置公网地址远程ssh连接
前言 在当今的数字化转型时代,远程连接和管理计算机已成为日常工作中不可或缺的一部分。对于 Windows 用户而言,SSH(Secure Shell)协议提供了一种安全、高效的远程访问和命令执行方式。SSH 不仅提供了加密的通信通道,…...
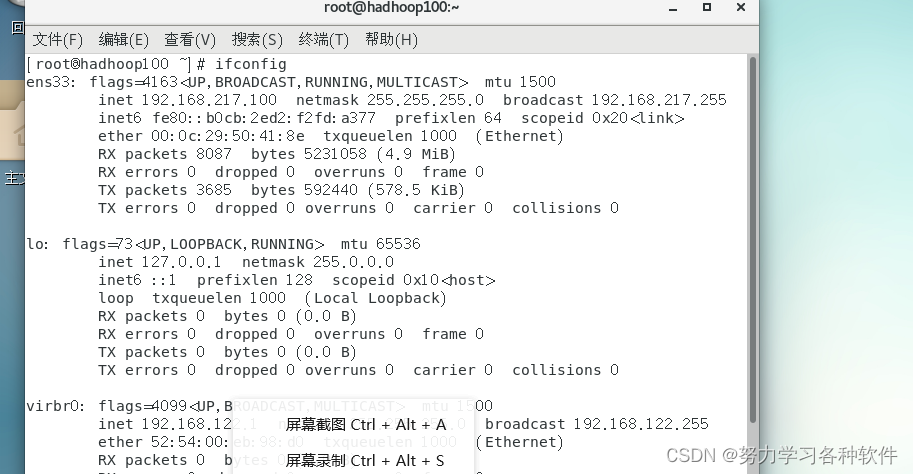
虚拟机与主机的联通
本地光纤分配地址给路由器--》连结路由器是连结局域网--》由路由器分配IP地址 因此在网站上搜索的IP与本机的IP是不一样的 1.windows查看主机IP地址 在终端输入 2.linux虚拟机查看ip 3.主机是否联通虚拟机ping加ip...

2024年中国网络安全市场全景图 -百度下载
是自2018年开始,数说安全发布的第七版全景图。 企业数智化转型加速已经促使网络安全成为全社会关注的焦点,在网络安全边界不断扩大,新理念、新产品、新技术不断融合发展的进程中,数说安全始终秉承科学的方法论,以遵循…...

SkillVLA:通过技能复用应对双-臂操纵中的组合多样性
26年3月来自新加坡国立、北京中关村学院、上海创新研究院、上海AI实验室、上海交大和复旦的论文“SkillVLA: Tackling Combinatorial Diversity in Dual-Arm Manipulation via Skill Reuse”。 视觉-语言-动作(VLA)模型近期取得的进展,已充分…...

千亿镁合金产业集群正在成形:成都、抚州、池州的新版图
一个新赛道的地理坐标 如果要在中国地图上标注一条正在成形的新兴产业集群走廊,高强镁合金这条线,值得被认真画出来。 成都龙泉驿——江西抚州临川——安徽池州高新区,三个坐标,三条生产线,一家公司,两年内…...

告别鼠标手!5分钟上手开源鼠标连点器MouseClick,轻松实现自动化点击
告别鼠标手!5分钟上手开源鼠标连点器MouseClick,轻松实现自动化点击 【免费下载链接】MouseClick 🖱️ MouseClick 🖱️ 是一款功能强大的鼠标连点器和管理工具,采用 QT Widget 开发 ,具备跨平台兼容性 。软…...

关联规则挖掘在Calabi-Yau流形Hodge数分析中的应用与复现
1. 项目概述:当数据挖掘遇见高维几何在理论物理和代数几何的交叉领域,Calabi-Yau流形一直扮演着核心角色。这些具有特殊拓扑结构的空间,不仅是弦理论中额外维度紧化的关键候选者,其本身丰富的数学性质也吸引着无数研究者。然而&am…...
)
别再死磕USB HID了!用ESP32的Arduino框架手把手教你实现蓝牙鼠标键盘(附完整代码)
ESP32蓝牙HID实战:零基础打造自定义键盘鼠标 手里那块吃灰的ESP32开发板终于能派上用场了!上周我用它做了个无线演示控制器,在会议室里走着就能翻PPT,同事们都问是怎么实现的。其实秘诀就在于ESP32的蓝牙HID功能——不需要任何USB…...

CUDA并行计算与FSR框架优化实践
1. CUDA并行计算与FSR框架概述在GPU加速计算领域,CUDA(Compute Unified Device Architecture)作为NVIDIA推出的并行计算平台和编程模型,已经成为高性能计算的事实标准。其核心设计理念是将计算任务分解为网格(Grid&…...

简单学习 --> SSE
我们使用AI时,AI对我们说的话不会一次性把全部内容弹出来,而是会像流水一样,一点点吐出来,那么这种丝滑的交互体验,背后的核心就是 SSE (Server-Sent Events)。 什么是 SSE? SSE(Server-Sent …...

GEO优化可以覆盖哪些搜索平台
这是一个非常现实的问题。企业投放资源做GEO,当然希望覆盖面越广越好。那么GEO优化到底能覆盖哪些平台?覆盖到什么程度?不同平台的GEO逻辑有什么差异?GEO平台覆盖的三个层级第一层级:通用大模型AI平台(核心…...

BiliBiliCCSubtitle终极指南:5个实战技巧高效下载B站字幕
BiliBiliCCSubtitle终极指南:5个实战技巧高效下载B站字幕 【免费下载链接】BiliBiliCCSubtitle 一个用于下载B站(哔哩哔哩)CC字幕及转换的工具; 项目地址: https://gitcode.com/gh_mirrors/bi/BiliBiliCCSubtitle 还在为无法保存B站视频字幕而烦恼࿱…...

基于LSTM自编码器的家用电器功耗异常检测系统构建指南
1. 项目概述:从能耗洞察到智能干预我们每天都在和各种家用电器打交道,从清晨唤醒你的咖啡机,到深夜还在默默工作的路由器。你有没有想过,这些看似微不足道的设备,其背后隐藏的能耗模式,其实大有文章&#x…...